北航数理统计回归分析大作业
北航数值分析大作业二(纯原创,高分版)

(R_5 ,I_5 )=(-1.493147080915e+000, 0.000000000000e+000)
(R_6 ,I_6 )=(-9.891143464723e-001, 1.084758631502e-001)
-0.8945216982
-0.0993313649
-1.0998317589
0.9132565113
-0.6407977009
0.1946733679
-2.3478783624
2.3720579216
1.8279985523
-1.2630152661
0.6790694668
-0.4672150886
6.220134985374e-001
-1.119962139645e-001
-2.521344456568e+000
-1.306189420531e+000
-3.809101150714e+000
8.132800093357e+000
-1.230295627285e+000
-6.753086301215e-001
而其本质就是
1.令 以及最大迭代步数L;
2.若m≤0,则结束计算,已求出A的全部特征值,判断 或 或m≤2是否成立,成立则转3,否则转4;
3.若 ,则得一个特征值 ,m=m-1,降阶;若 ,则计算矩阵:
的特征值得矩阵A的两个特征值,m=m-2,降阶,转2.;
4.若k≤L,成立则令
k=k+1,转2,否则结束计算,为计算出矩阵A的全部特征值;
北航数理统计第一次大作业

数理统计第一次课程论文广州恒大队在2015赛季亚冠的进球数的多元线性回归模型学号: SY1527205姓名:郭谢有摘要本赛季亚洲冠军联赛,来自中国的球队广州恒大淘宝队最终在决赛中力克阿联酋的迪拜阿赫利队,三年之内第二次夺得亚冠冠军。
为了研究恒大的夺冠过程,本文选取了恒大该赛季亚冠总共15场比赛中的进球数为因变量,对可能影响进球数的射门数、射正数等7个自变量进行统计,并进一步利用统计软件SPSS对以上数据进行了多元逐步线性回归。
最终确定了进球数与各因素之间关系的“最优”回归方程。
关键词:多元线性回归,逐步回归法,广州恒大,SPSS目录摘要 (1)1.引言 (3)2.符号说明 (3)3.数据的采集和整理 (3)3.1数据的采集 (3)3.2建模 (4)4.数据分析及计算 (4)4.结论 (9)参考文献 (10)致谢 (10)1.引言一场足球比赛的进球数说明了一支球队攻击力的强弱,也是决定比赛胜负的至关因素,综合反映出这支球队的实际水平。
而作为竞技体育,足球场上影响进球数的因素很多,为了研究本赛季恒大在亚冠夺冠过程中的14场比赛中进球数与其他一些因素的关系,本论文从搜达足球和新浪体育数据库中查找了进球数和其他7个主要影响因素的数据,包括射门次数、射正次数、传球次数、传中次数、角球次数、抢断次数。
并进一步采用多元逐步回归分析方法对以上因素进行了显著性分析,从而确定了关于恒大在本赛季亚冠中进球数的最优多元线型回归方程。
2.符号说明3.数据的采集和整理3.1数据的采集本文统计数据时,查阅了搜达足球数据库,确定恒大在亚冠14场比赛中的进球数为因变量,并初步选取这14场比赛中的射门次数、射正次数、传球次数、传中次数、角球次数、抢断次数7因素为自变量,具体数据见下表1。
3.2建模本文选取了恒大在亚冠比赛中的进球数作为因变量y,并选取可能对进球数造成影响的因素为自变量,其中对应关系在符号说明中已经列举。
这里构建模型如下:7⋅X i+εy=β0+∑βii=1其中,其中ε为随机误差项,β0为常数项,βi为待估计的参数。
北航应用数理统计大作业多元线性回归

多元线性回归分析摘要:本文查找2011年《中国统计年鉴》,取我国31个省市自治区直辖市2010年的数据,利用SPSS软件对影响居民消费的因素进行讨论构造线性回归模型。
并对模型的回归显著性、拟合度、正态分布等分别进行检验,最终得到最优线性回归模型,寻找影响居民消费的各个因素。
关键字:回归分析;线性;相关系数;正态分布1. 引言变量与变量之间的关系分为确定性关系和非确定性关系,函数表达确定性关系。
研究变量间的非确定性关系,构造变量间经验公式的数理统计方法称为回归分析。
回归分析是指通过提供变量之间的数学表达式来定量描述变量间相关关系的数学过程,这一数学表达式通常称为经验公式。
一方面,研究者可以利用概率统计知识,对这个经验公式的有效性进行判定;另一方面,研究者可以利用经验公式,根据自变量的取值预测因变量的取值。
如果是多个因素作为自变量的时候,还可以通过因素分析,找出哪些自变量对因变量的影响是显著的,哪些是不显著的。
回归分析目前在生物统计、医学统计、经济分析、数据挖掘中得到了广泛的应用。
通过对训练数据进行回归分析得出经验公式,利用经验公式就可以在已知自变量的情况下预测因变量的取值。
实际问题的控制中往往是根据预测结果来进行的,如在商品流通领域,通常用回归分析商品价和与商品需求之间的关系,以便对商品的价格和需求量进行控制。
本文查找2011年《中国统计年鉴》,取我国31个省市自治区直辖市2010年的数据,利用SPSS软件对影响居民消费的因素进行讨论构造多元线性线性回归模型。
以探求影响居民消费水平的各个因素,得到最优线性回归模型。
随后,我们对模型的回归显著性、拟合度、正态分布等分别进行检验,以考察线性回归模型的可信度。
本文将分为5章进行论述。
在第2章,我们介绍多元线性回归模型的概念。
第3章,我们进行模型的建立与数据的收集和整理。
我们在第4章对数据进行处理,得出多元线性回归模型,并对其进行检验。
在第5章,我们进行总结。
北航数理统计答案

北航数理统计答案【篇一:北航数理统计考试题】术部2011年12月2007-2008学年第一学期期末试卷一、(6分,a班不做)设x1,x2,…,xn是来自正态总体n(?,?2)的样本,令t?x?x),试证明t服从t-分布t(2)二、(6分,b班不做)统计量f-f(n,m)分布,证明1f的?(0?1)的分位点x?是1f1??(n,m)。
三、(8分)设总体x的密度函数为?(1??)x?,0?x?1p(x;?)??0,其他?其中???1,是位置参数。
x1,x2,…,xn是来自总体试求参数?的矩估计和极大似然估计。
四、(12分)设总体x的密度函数为?1?x???exp???,x???p(x;?)??????,??0,其它其中???????,?已知,??0,?是未知参数。
x1,x2,…,xn是来自总?体x的简单样本。
(1)试求参数?的一致最小方差无偏估计?;(2)?是否为?的有效估计?证明你的结论。
五、(6分,a班不做)设x1,x2,…,xn是来自正态总体n(?简单样本,y1,y2,…,yn是来自正态总体n(?两样本相互独立,其中?设h0:?1??2,h1:?1??2,1221?,?1)2的,?2)的简单样本,且21,?1,?2,?222是未知参数,???22。
为检验假可令zi?xi?yi, i?1,2,...,n ,???1??2 ,则上述假设检验问题等价于h0:?1?0,h1:?1?0,这样双样本检验问题就变为单检验问题。
基于变换后样本z1,z2,…,zn,在显著性水平?下,试构造检验上述问题的t-检验统计量及相应的拒绝域。
六、(6分,b班不做)设x1,x2,…,xn是来自正态总体n(?简单样本,?0已知,?2未知,试求假设检验问题h0:?2,?)02的??0,h1:?22??02的水平为?的umpt。
七、(6分)根据大作业情况,试简述你在应用线性回归分析解决实际问题时应该注意哪些方面?八、(6分)设方差分析模型为?xij????i??j??ij?2??ij服从正态总体分布n(0,?)且?ij相互独立??i?1,2,...,p;j?1,...,q?pq??和?满足??i?0,??j?0.j?ii?1j?1?总离差平方和pst?sa?sb?se中sa?q?(xi??x),x?i?1x??pqi?1j?11pqij,xi??1qijx?qj?1,且e(se)=(p-1)(q-1)?.?...??p?0的拒绝2试求e(sa),并根据直观分析给出检验假设h0:?1??2域形式。
北航数值分析大作业三
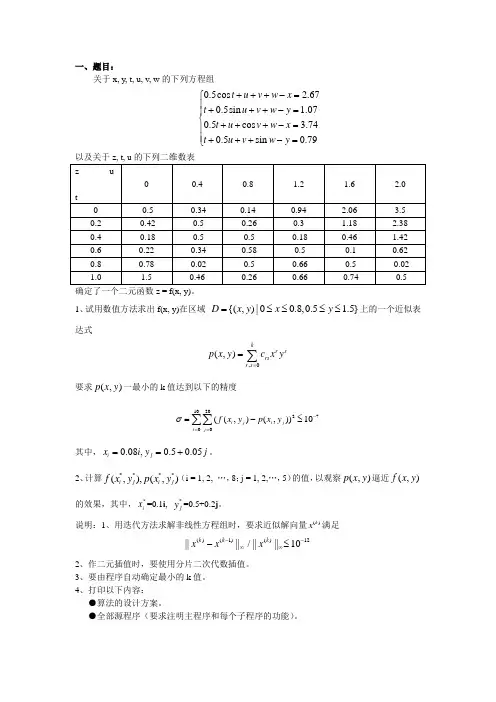
一、题目:关于x, y, t, u, v, w 的下列方程组0.5cos 2.670.5sin 1.070.5cos 3.740.5sin 0.79t u v w x t u v w y t u v w x t u v w y +++-=⎧⎪+++-=⎪⎨+++-=⎪⎪+++-=⎩1、试用数值方法求出f(x, y)在区域 {(,)|00.8,0.5 1.5}D x y x y =≤≤≤≤上的一个近似表达式,0(,)kr s rsr s p x y cx y ==∑要求(,)p x y 一最小的k 值达到以下的精度10202700((,)(,))10i j i j i j f x y p x y σ-===-≤∑∑其中,0.08,0.50.05i j x i y j ==+。
2、计算****(,),(,)i j i j f x y p x y (i = 1, 2, …,8;j = 1, 2,…,5)的值,以观察(,)p x y 逼近(,)f x y 的效果,其中,*i x =0.1i , *j y =0.5+0.2j 。
说明:1、用迭代方法求解非线性方程组时,要求近似解向量()k x 满足()(1)()12||||/||||10k k k x x x --∞∞-≤2、作二元插值时,要使用分片二次代数插值。
3、要由程序自动确定最小的k 值。
4、打印以下内容:●算法的设计方案。
●全部源程序(要求注明主程序和每个子程序的功能)。
●数表:,,i j x y (,)i j f x y (i = 0,1,2,…,10;j = 0,1,2,…,20)。
●选择过程的,k σ值。
●达到精度要求时的,k σ值以及(,)p x y 中的系数rs c (r = 0,1,…,k;s = 0,1,…,k )。
●数表:**,,i j x y ****(,),(,)i j i j f x y p x y (i = 1, 2, ...,8;j = 1, 2, (5)。
数理统计 北航 大作业

北京市财政收入的逐步回归模型研究摘要:财政收入水平高低是反映一国经济实力的重要标志,关系着一个国家经济的发展和社会的进步。
本文根据北京市2012年度统计年鉴,选取了农林牧渔业总产值、工业总产值、建筑业总产值、常驻总人口数、社会消费品零售总额、入境旅游人数、客运量、货运量、全社会固定资产投资以及第三产业总产值,共10个指标,对北京市财政收入及其可能的影响因素进行了研究。
文中运用逐步线性回归方法建立了多元线性回归模型,分析各因素对该地区财政收入的影响;利用SPSS软件进行求解。
通过分析SPSS软件计算的数据,从相关性检验、多重共线性检验、方差分析以及残差分析四个角度,分别对模型合理性进行了验证。
结果表明,北京市财政收入与建筑业总产值和农林牧渔也总产值呈显著线性关系。
其中与建筑业正相关,与农林牧渔业负相关。
关键字:财政收入,多元,逐步线性回归,SPSS1. 引言财政收入是指政府为履行其职能、实施公共政策和提供公共物品与服务需要而集中的一切资金的综合,包括税收、企事业收入、能源交通重点建设基金收入、债务收入、规费收入、罚没收入等[1]。
财政收入水平高低是反映一国经济实力的重要标志,关系着一个国家经济的发展和社会的进步。
因此,研究财政收入的增长及就显得尤为必要[2]。
一个地区的财政收入可能受到诸多因素的影响,如工业总产值、农业总产值、建筑业总产值、人口数等。
本文以北京市为例,以财政收入为因变量,选取农林牧渔业总产值、工业总产值、建筑业总产值、常驻总人口数、社会消费品零售总额、入境旅游人数、客运量、货运量、全社会固定资产投资以及第三产业总产值这10个指标为自变量,利用SPSS统计软件进行回归分析,建立财政收入影响因素模型,分析影响财政收入的主要因素及其影响程度。
2. 理论概述2.1 多元线性回归[3]在许多实际问题中,影响一个事物的因素常常不止一个,采用多元线性回归分析方法可以找出这些因素与事物之间的数量关系。
北航数值分析大作业第一题幂法与反幂法
《数值分析》计算实习题目第一题:1. 算法设计方案(1)1λ,501λ和s λ的值。
1)首先通过幂法求出按模最大的特征值λt1,然后根据λt1进行原点平移求出另一特征值λt2,比较两值大小,数值小的为所求最小特征值λ1,数值大的为是所求最大特征值λ501。
2)使用反幂法求λs ,其中需要解线性方程组。
因为A 为带状线性方程组,此处采用LU 分解法解带状方程组。
(2)与140k λλμλ-5011=+k 最接近的特征值λik 。
通过带有原点平移的反幂法求出与数k μ最接近的特征值 λik 。
(3)2cond(A)和det A 。
1)1=nλλ2cond(A),其中1λ和n λ分别是按模最大和最小特征值。
2)利用步骤(1)中分解矩阵A 得出的LU 矩阵,L 为单位下三角阵,U 为上三角阵,其中U 矩阵的主对角线元素之积即为det A 。
由于A 的元素零元素较多,为节省储存量,将A 的元素存为6×501的数组中,程序中采用get_an_element()函数来从小数组中取出A 中的元素。
2.全部源程序#include <stdio.h>#include <math.h>void init_a();//初始化Adouble get_an_element(int,int);//取A 中的元素函数double powermethod(double);//原点平移的幂法double inversepowermethod(double);//原点平移的反幂法int presolve(double);//三角LU 分解int solve(double [],double []);//解方程组int max(int,int);int min(int,int);double (*u)[502]=new double[502][502];//上三角U 数组double (*l)[502]=new double[502][502];//单位下三角L 数组double a[6][502];//矩阵Aint main(){int i,k;double lambdat1,lambdat2,lambda1,lambda501,lambdas,mu[40],det;init_a();//初始化Alambdat1=powermethod(0);lambdat2=powermethod(lambdat1);lambda1=lambdat1<lambdat2?lambdat1:lambdat2;lambda501=lambdat1>lambdat2?lambdat1:lambdat2;presolve(0);lambdas=inversepowermethod(0);det=1;for(i=1;i<=501;i++)det=det*u[i][i];for (k=1;k<=39;k++){mu[k]=lambda1+k*(lambda501-lambda1)/40;presolve(mu[k]);lambda[k]=inversepowermethod(mu[k]);}printf("------------所有特征值如下------------\n");printf("λ=%1.11e λ=%1.11e\n",lambda1,lambda501);printf("λs=%1.11e\n",lambdas);printf("cond(A)=%1.11e\n",fabs(lambdat1/lambdas));printf("detA=%1.11e \n",det);for (k=1;k<=39;k++){printf("λi%d=%1.11e ",k,lambda[k]);if(k % 3==0) printf("\n");} delete []u;delete []l;//释放堆内存return 0;}void init_a()//初始化A{int i;for (i=3;i<=501;i++) a[1][i]=a[5][502-i]=-0.064;for (i=2;i<=501;i++) a[2][i]=a[4][502-i]=0.16;for (i=1;i<=501;i++) a[3][i]=(1.64-0.024*i)*sin(0.2*i)-0.64*exp(0.1/i); }double get_an_element(int i,int j)//从A中节省存储量的提取元素方法{if (fabs(i-j)<=2) return a[i-j+3][j];else return 0;}double powermethod(double offset)//幂法{int i,x1;double beta=0,prebeta=-1000,yita=0;for (i=1;i<=501;i++)u[i]=1,y[i]=0;//设置初始向量u[]for (int k=1;k<=10000;k++){yita=0;for (i=1;i<=501;i++) yita=sqrt(yita*yita+u[i]*u[i]);for (i=1;i<=501;i++) y[i]=u[i]/yita;for (x1=1;x1<=501;x1++){u[x1]=0;for (int x2=1;x2<=501;x2++)u[x1]=u[x1]+((x1==x2)?(get_an_element(x1,x2)-offset):get_an_element(x1,x2))*y[x2];} prebeta=beta;beta=0;for (i=1;i<=501;i++) beta=beta+ y[i]*u[i];if (fabs((prebeta-beta)/beta)<=1e-12) {printf("offset=%f lambda=%f err=%e k=%d\n",offset,(beta+offset),fabs((prebeta-beta)/beta),k);break;};//输出中间过程,包括偏移量,误差,迭代次数}return (beta+offset);}double inversepowermethod(double offset)//反幂法{int i;double u[502],y[502];double beta=0,prebeta=0,yita=0;for (i=1;i<=501;i++)u[i]=1,y[i]=0; //设置初始向量u[]for (int k=1;k<=10000;k++){yita=0;for (i=1;i<=501;i++) yita=sqrt(yita*yita+u[i]*u[i]);for (i=1;i<=501;i++) y[i]=u[i]/yita;solve(u,y);prebeta=beta;beta=0;for (i=1;i<=501;i++) beta=beta+ y[i]*u[i];beta=1/beta;if (fabs((prebeta-beta)/beta)<=1e-12) {printf("offset=%f lambda=%f err=%e k=%d\n",offset,(beta+offset),fabs((prebeta-beta)/beta),k);break;};//输出中间过程,包括偏移量,误差,迭代次数}return (beta+offset);}int presolve(double offset)//三角LU分解{int i,k,j,t;double sum;for (k=1;k<=501;k++)for (j=1;j<=501;j++){u[k][j]=l[k][j]=0;if (k==j) l[k][j]=1;} //初始化LU矩阵for (k=1;k<=501;k++){for (j=k;j<=min(k+2,501);j++){sum=0;for (t=max(1,max(k-2,j-2)) ; t<=(k-1) ; t++)sum=sum+l[k][t]*u[t][j];u[k][j]=((k==j)?(get_an_element(k,j)-offset):get_an_element(k,j))-sum;}if (k==501) continue;for (i=k+1;i<=min(k+2,501);i++){sum=0;for (t=max(1,max(i-2,k-2));t<=(k-1);t++)sum=sum+l[i][t]*u[t][k];l[i][k]=(((i==k)?(get_an_element(i,k)-offset):get_an_element(i,k))-sum)/u[k][k];}}return 0;}int solve(double x[],double b[])//解方程组{int i,t;double y[502];double sum;y[1]=b[1];for (i=2;i<=501;i++){sum=0;for (t=max(1,i-2);t<=i-1;t++)sum=sum+l[i][t]*y[t];y[i]=b[i]-sum;}x[501]=y[501]/u[501][501];for (i=500;i>=1;i--){sum=0;for (t=i+1;t<=min(i+2,501);t++)sum=sum+u[i][t]*x[t];x[i]=(y[i]-sum)/u[i][i];}return 0;}int max(int x,int y){return (x>y?x:y);}int min(int x,int y){return (x<y?x:y);}3.计算结果结果如下图所示:部分中间结果:给出了偏移量(offset),误差(err),迭代次数(k)4.讨论迭代初始向量的选取对计算结果的影响,并说明原因使用u[i]=1(i=1,2,...,501)作为初始向量进行迭代,可得出以上结果。
数理统计第一次大作业——回归分析
北京市农业经济总产值的逐步回归分析姓名:学号:摘要:农业生产和农村经济是国民经济的基础,影响农村经济总产值的因素有多种,主要包括农林牧渔业。
本文以北京市农业生产和农村经济总产值为对象,首先分析了各种因素的线性相关性,建立回归模型,再利用逐步回归法进行回归分析,得到最符合实际情况的回归模型。
以SPSS 17.0为分析工具,给出了实验结果,并用预测值验证了结论的正确性。
关键词:农业生产和农村经济,线性回归模型,逐步回归分析,SPSS1.引言农林牧渔业统计范围包括辖区内全部农林牧渔业生产单位、非农行业单位附属的农林牧渔业生产活动单位以及农户的农业生产活动。
军委系统的农林牧渔业生产(除军马外)也应包括在内,但不包括农业科学试验机构进行的农业生产。
在近几年中国经济快速增长的带动下,各地区农林牧渔业也得到了突飞猛进的发展。
以北京地区为例,2005年的农业总产值为1993年的6倍。
因此用统计方法研究分析农业总产值对指导国民经济生产,合理有效的进行产业布局,提高生产力等有着重要意义。
表1 北京市农业经济产值及各产品产量统计数据本文以北京市农生产为对象,分析了农业经济总产值与粮食产量、棉花产量、油料产量、蔬菜产量、干鲜果品产量、猪牛羊肉产量、禽蛋产量、水产品产量的关系,并建立农业经济总产值的回归模型。
表1中列出了1999年至2008年间的统计数据(数据来源于北京统计信息网)。
2.线性回归模型的建立2.1 线性回归模型的假设为了研究农业经济总产值与各种农生产量的关系,必须要建立二者之间的数学模型。
数学模型可以有多种形式,比如线性模型,二次模型,指数模型,对数模型等等。
而实际生活中,影响农业经济总产值的因素很多,并且这些因素的影响不能简单的用某一种模型来描述,所以要建立农业经济总产值的数学模型往往是很难的。
但是为了便于研究,我们可以先假定一些前提条件,然后在这些条件下得到简化后的近似模型。
以下我们假定两个前提条件:1) 农产品的价格是不变的。
北航数值分析大作业一
北京航空航天大学数值分析大作业一学院名称自动化专业方向控制工程学号ZY*******学生姓名许阳教师孙玉泉日期2021 年11月26 日设有501501⨯的实对称矩阵A ,⎥⎥⎥⎥⎥⎥⎦⎤⎢⎢⎢⎢⎢⎢⎣⎡=5011A a b c b c c b c b a其中,064.0,16.0),501,,2,1(64.0)2.0sin()024.064.1(1.0-==⋅⋅⋅=--=c b i e i i a ii 。
矩阵A 的特征值为)501,,2,1(⋅⋅⋅=i i λ,并且有||min ||,501150121i i s λλλλλ≤≤=≤⋅⋅⋅≤≤1λ,501λ和s λ的值。
A 的与数4015011λλλμ-+=kk 最接近的特征值)39,,2,1(⋅⋅⋅=k k i λ。
A 的(谱范数)条件数2)A (cond 和行列式detA 。
一 方案设计1 求1λ,501λ和s λ的值。
s λ为按模最小特征值,||min ||5011i i s λλ≤≤=。
可使用反幂法求得。
1λ,501λ分别为最大特征值及最小特征值。
可使用幂法求出按模最大特征值,如结果为正,即为501λ,结果为负,那么为1λ。
使用位移的方式求得另一特征值即可。
2 求A 的与数4015011λλλμ-+=kk 最接近的特征值)39,...,2,1(=k k i λ。
题目可看成求以k μ为偏移量后,按模最小的特征值。
即以k μ为偏移量做位移,使用反幂法求出按模最小特征值后,加上k μ,即为所求。
3 求A 的(谱范数)条件数2)(A cond 和行列式detA 。
矩阵A 为非奇异对称矩阵,可知,||)(min max2λλ=A cond(1-1)其中m ax λ为按模最大特征值,min λ为按模最小特征值。
detA 可由LU 分解得到。
因LU 均为三角阵,那么其主对角线乘积即为A 的行列式。
二 算法实现1 幂法使用如下迭代格式:⎪⎪⎩⎪⎪⎨⎧⋅===⋅⋅⋅=------||max |)|sgn(max ||max /),,(111111)0()0(10k k k k k k k k Tn u u Ay u u u y u u u β任取非零向量 (2-1)终止迭代的控制理论使用εβββ≤--||/||1k k k , 实际使用εβββ≤--||/||||||1k k k(2-2)由于不保存A 矩阵中的零元素,只保存主对角元素a[501]及b,c 值。
北航数理统计第二次数理统计大作业 判别分析
数理统计大作业(二)全国各省发展程度的聚类分析及判别分析指导教师院系名称材料科学与工程院学号学生姓名2015 年 12 月21 日目录全国各省发展程度的聚类分析及判别分析 (1)摘要: (1)引言 (1)1实验方案 (2)1.1数据统计 (2)1.2聚类分析 (3)1.3判别分析 (4)2结果分析与讨论 (5)2.1聚类分析结果 (5)2.2聚类分析结果分析: (8)2.3判别分析结果 (9)2.4 Fisher判别结果分析: (11)参考文献: (16)全国各省发展程度的聚类分析及判别分析摘要:利用SPSS软件对全国31个省、直辖市、自治区(浙江、安徽、甘肃除外)的主要经济指标进行多种聚类分析,分析选择最佳聚类类数,并对浙江、湖南、甘肃进行类型判别分析。
通过这两个方法对全国各省进行发展分类。
本文选取了7项社会发展指标作为决定发展程度的影响因素,其中经济因素为主要因素,同时评估城镇化率和人口素质因素。
各项数据均来自2014年国家统计年鉴。
分析结果表明:北京市和上海市和天津市为同一类;江苏省和山东省和广东省为同一类型;河北、湖北、河南、湖南、四川、辽宁为同一类;其余的为另一类。
关键词:聚类分析、判别分析、发展引言聚类分析是根据研究对象的特征对研究对象进行分类的多元统计分析技术的总称。
它直接比较各事物之间的性质,将性质相近的归为一类,将性质差别较大的归入不同的类。
系统聚类分析又称集群分析,是聚类分析中应用最广的一种方法,它根据样本的多指标(变量)、多个观察数据,定量地确定样品、指标之间存在的相似性或亲疏关系,并据此连结这些样品或指标,归成大小类群,构成分类树状图或冰柱图。
判别分析是根据多种因素(指标)对事物的影响来实现对事物的分类,从而对事物进行判别分类的统计方法。
判别分析适用于已经掌握了历史上分类的每一个类别的若干样品,希望根据这些历史的经验(样品),总结出分类的规律性(判别函数)来指导未来的分类。
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
应用数理统计第一次大作业学号:姓名:班级:2013年12月国家财政收入的多元线性回归模型摘 要本文以多元线性回归为出发点,选取我国自1990至2008年连续19年的财政收入为因变量,初步选取了7个影响因素,并利用统计软件PASW Statistics 17.0对各影响因素进行了筛选,最终确定了能反映财政收入与各因素之间关系的“最优”回归方程:46ˆ578.4790.1990.733yx x =++ 从而得出了结论,最后我们用2009年的数据进行了验证,得出的结果在误差范围内,表明这个模型可以正确反映影响财政收入的各因素的情况。
关键词:多元线性回归,逐步回归法,财政收入,SPSS0符号说明变 量 符号 财政收入 Y 工 业 X 1 农 业 X 2 受灾面积 X 3 建 筑 业 X 4 人 口 X 5 商品销售额X 6进出口总额X71 引言中国作为世界第一大发展中国家,要实现中华民族的伟大复兴,必须把发展放在第一位。
近年来,随着国家经济水平的飞速进步,人民生活水平日益提高,综合国力日渐强大。
经济上的飞速发展并带动了国家财政收入的飞速增加,国家财政的状况对整个社会的发展影响巨大。
政府有了强有力的财政保证才能够对全局进行把握和调控,对于整个国家和社会的健康快速发展有着重要的意义。
所以对国家财政的收入状况进行研究是十分必要的。
国家财政收入的增长,宏观上必然与整个国家的经济有着必然的关系,但是具体到各个方面的影响因素又有着十分复杂的相关原因。
为了研究影响国家财政收入的因素,我们就很有必要对其财政收入和影响财政收入的因素作必要的认识,如果能对他们之间的关系作一下回归,并利用我们所知道的数据建立起回归模型这对我们很有作用。
而影响财政收入的因素有很多,如人口状况、引进的外资总额,第一产业的发展情况,第二产业的发展情况,第三产业的发展情况等等。
本文从国家统计信息网上选取了1990-2009年这20年间的年度财政收入及主要影响因素的数据,包括工业,农业,建筑业,批发和零售贸易餐饮业,人口总数等。
文中主要应用逐步回归的统计方法,对数据进行分析处理,最终得出能够反映各个因素对财政收入影响的最“优”模型。
2解决问题的方法和计算结果2.1 样本数据的选取与整理本文在进行统计时,查阅《中国统计年鉴2010》中收录的1990年至2009年连续20年的全国财政收入为因变量,考虑一些与能源消耗关系密切并且直观上有线性关系的因素,初步选取这十九年的国内总产值、工业总产值、人口总数、建筑业、农业、受灾面积和商品零售总额等因素为自变量,分析它们之间的联系。
根据选择的指标,从《中国统计年鉴2010》查选数据,整理如表2-1所示。
表2-1 1990-2009年财政收入及其影响因素统计表工业(亿元)农业(亿元)受灾面积(千公顷)建筑业(亿元)人口(万人)社会商品零售总额(亿元)财政收入(亿元)国民生产总值(亿元)199018689.227662.13847413451143338300.12937.118718.3 199122088.688157554721564.31158239415.63149.4821826.2 199227724.219084.7513332174.411717110993.73483.3726937.3 19933969310995.5488293253.511851714270.44348.9535260.0 199451353.0315750.5550434653.311985018622.95218.148108.5 199554946.8620340.9458215793.812112123613.86242.259810.5 199662740.1622353.7469898282.212238928360.27407.9970142.5 199768352.6823788.4534299126.512362631252.98651.1478060.8 199867737.1424541.9501451006212476133378.19875.9583024.3 199972707.0424519.14998111152.912578635647.911444.0888479.2 200085673.6624915.85468812497.612674339105.713395.2398000.5 200195448.9826179.65221515361.512762743055.416386.04108068.2 2002110776.4827390.847119.118527.112845348135.918903.64119095.7 2003142271.2229691.854506.323083.812922752516.321715.25135174.0 2004201722.193623937106.25627745.31299885950126396.47159586.7 2005251619.539450.938818.22534552.013075667176.631649.29185808.6 2006316588.9640810.841091.4141557.11314487641038760.2217522.7 2007405177.1348892.935972.2351043.71321298921051321.78267763.7 2008130260.233702.056234.2618743.213280************.35316228.8 2009135239.935226.050223.5122398.81334741489468518.30343464.72.2 模型的建立与分析将数据录入统计软件excel,建立统计数据库,先建立财政收入与各变量的散点图,如图2-1至图2-7所示。
图2-1 财政收入与工业总产值的散点图图2-2 财政收入与农业总产值的散点图图2-3 财政收入与受灾面积的散点图图2-4 财政收入与建筑业的散点图图2-5 财政收入与人口总数的散点图图2-6 财政收入与商品零售总额的散点图图2-7 财政收入与国内总产值的散点图从散点图中看出,国内生产总值、工业生产总值、农业、建筑业、商品零售总额这四个变量与财政收入总量基本呈线性分布;而人口总数虽然也与财政收入存在正比的关系,但是从直观上看线性关系不显著,并且人口因素呈现指数关系。
受灾面积与财政收入总量的关系不明显。
因此为使得到的模型有显著的线性关系,在选取进入回归模型的自变量时,就要进行筛选。
下面给出筛选过程。
(1)将国内生产总值、农业、工业生产总值、建筑业和商品零售总额纳入自变量,逐步回归法,输出结果如图2-8(a)(b)所示。
从结果可以看出,该回归的F值为1600.595,查表得0.95(1,2)18.5F ,显而易见,回归的显著性很好;但是由于在这里我们要分析的是影响财政收入的具体产业,而该结果只说明了财政收入与国民生产总值的相关性很好,并不能说明问题的根本所在。
所以在下面的分析中我们将剔除国民生产总值这个因素做进一步的分析。
Anova b模型平方和df均方F Sig.1回归7.506E917.506E91600.595.000a 残差8.441E7184689341.382图2-8(a)(b) 输出结果(2)将工业生产总值、农工、建筑业和商品零售总额纳入自变量,逐步回归法,输出结果如图2-9(a)(b)(c)所示。
图2-9(a)(b)(c) 输出结果从结果可以看出,该回归的F 值为30.215,查表得0.95(1,3)10.1F =,显而易见,回归的显著性很好;但是对回归系数的显著性来说,从直方图中可以看出,采用以上三个变量作为自变量得到的线性模型仍不是很好。
这个模型也不是理想中的模型,所以下面我们试图根据我们的判断对样本数据进行筛选,力求得出比较理想的模型。
(3)下面我将农业这个变量暂且剔除,只采用工业、建筑业和商品零售总额作为自变量,采用逐步回归法,输出结果如图2-10(a)(b)所示。
从结果可以看出,该回归的F 值为20.219,查表得0.95(1,2)18.5F =,显而易见,回归的显著性很好;但是对回归系数的显著性来说,建筑业的t 检验值为0.0002,查表得3646.2)7(975.0=t ,显然回归系数的显著性不好。
以上检验得到的与利用P 值法(图中的Sig 值)得到的检验结果相符。
因此,采用以上三个变量作为自变量得到的线性模型仍不是很好。
同时可以看出,只对建筑业做回归分析时,F 值为20.19,查表得到0.95(1,7) 5.59F ,这证明一元回归模型和回归系数的显著性都很好。
图2-10(a)(b) 输出结果(4)只将工业和商品零售总额纳入自变量,输出结果如图2-11(a)(b)所示。
图2-11(a)(b) 输出结果从上图结果中可以看出,对这两个变量做回归分析时,F 值为15.39,证明一元回归模型和回归系数的显著性都很好。
2.3 分析结果由以上筛选和分析过程可以看出,财政收入Y 分别对X 7国内总产值、X 1工业总产值、X 4建筑业及商品零售总额X 6进行一元回归分析时,其回归的显著性都很好,但是综合为一个多元回归模型时,则出现了某些系数不显著的现象。
综合比较选取的几个多元模型,将X 4建筑业和X 6商品零售总额纳入自变量时得到的模型效果最为显著,回归方程如下:46ˆ578.479 5.199 4.733yx x =++ 其中10.99F =,20.564R =。
3 结论本次大作业,根据查阅中国统计年鉴,列举了影响财政收入的7个因素。
从直观上考虑,人口总量与受灾面积与财政收入存在线性关系,所以特意把这两个变量列到其中,但是散点图和回归效果显示这2个因素并没有进入逐步回归模型中,由此看来,这两项因素与财政收入存在的关系可能不是严格线性的,或者这种线性关系是长期的线性关系。
另外,在对进入模型的5个因素进行回归时发现,因变量对单独变量的回归性很显著,但是整合成多元回归出现了某些回归系数不显著的现象,具体原因可能是由于数据选取的太少,未能体现出长期线性这一特点。
虽然得到的几个模型系数都不是很显著,但经综合比较,选取了一个较为显著的模型作为最“优”解。
对得到的最“优”回归模型做预测,置信度为95%。
查阅中国统计年鉴,得到2009年的X 4建筑业为22398.8(亿元),X 6商品零售总额为14894(亿元),Y 财政收入为68518.30(亿元),将自变量带入回归方程:46ˆ578.479 1.199 2.733578.479 1.19922398.8 2.7331489468103.9902yx x =++=+⨯+⨯=(亿元)预测区间为))(ˆ),(ˆ(o o o x y x yδδ+-,其中0.975() 2.36462674.56()o x t δ===亿元。