第十二章 多变量分析方法
统计学中的多变量分析方法

统计学中的多变量分析方法统计学是一门重要的科学领域,它致力于研究如何收集、组织、分析和解释数据。
在统计学中,多变量分析方法是一种常用的技术,用于探究多个变量之间的关系和模式。
本文将介绍多变量分析方法的概念和应用场景。
一、多变量分析方法的概述在统计学中,多变量分析方法是一种通过同时考虑多个变量来研究数据集的方法。
相比传统的单变量分析方法,多变量分析方法可以更全面地探究各个变量之间的关联和影响。
为了帮助研究者更好地理解数据集中变量之间的关系,多变量分析方法提供了多种技术和模型。
其中最常用的方法包括主成分分析、因子分析、聚类分析、判别分析和回归分析。
二、主成分分析主成分分析是一种常见的多变量分析方法,用于减少数据集的维度并提取潜在的主要变量。
通过主成分分析,可以将原始数据转化为一组无关的主成分,这些主成分可以解释数据中大部分的方差。
主成分分析可用于降维、特征选择和数据可视化。
它广泛应用于生物医学、工程学、金融和市场研究等领域,有助于简化复杂数据集的分析过程。
三、因子分析因子分析是一种用于研究多个变量之间关联模式的方法。
它通过将一组观测变量转化为一组潜在的无关因子,来揭示观测变量背后的潜在结构。
因子分析可以用于探究样本中隐藏的潜在因子,如人格特征、消费者满意度和员工工作满意度等。
通过因子分析,研究者可以了解到不同变量之间的潜在关系,并进一步洞察潜在因子对观测变量的解释贡献。
四、聚类分析聚类分析是一种将样本或变量分组成类别的方法。
通过聚类分析,可以根据样本间的相似性或变量间的相关性,将数据集划分为不同的群组。
聚类分析在市场研究、社会科学和生物学等领域得到广泛应用。
它可以用于发现数据集中的隐藏模式和群组,帮助研究者识别并理解不同群体之间的相似性和差异。
五、判别分析判别分析是一种用于解释组间差异和评估变量重要性的统计方法。
它可以帮助研究者确定哪些变量对于区分不同组别的样本最具有预测性。
判别分析在医学研究、社会科学和商业决策等领域得到广泛应用。
多变量分析

噪音变量研究
主焦点
首先研究不可控的噪音变量!
➢ 噪音变量散布产生长期的和严重的平均值移动和散布变化, 从而导致工程不稳定
➢ 如果有可能,我们必须首先在系统地度量重要可控输入变量之前 祛除这些散布源。
可控与不可控
(整个左环)
影响反应 的因子
有影响的 噪音但不 可控制
噪音因子, 我们只能在 实验中操纵
• 在短时间内收集数据并分析,以测定流程能力、稳定性、 及关键输入变量(KPIV’s)和关键输出变量( KPOV’s ),即X’s和Y’s之间的关系
• “多变量分析”应该持续到输出变量的所有范围都被观测 完为止
分析步骤
• 阶段I: - 执行短期流程能力分析:参考流程改善计划的测量阶段 - 根据短期流程能力分析的数据和记录,做出进一步深入
•全部影响因素分析(流程图/鱼刺图) •定性确定关键因素(因果矩阵) •关键因素失效模式分析,评价控制计划,并提出初 步改善措施(快赢)
设计改进并试行
•流程图;FMEA;看板/拉动;防错;快速换型;5S 等等
步骤V:控制(Control)
决定流程控制计划
•控制计划;标准化;流程文件;沟通/培训计划等
目标为收集约30个时间的数据 4.要求小组组员仔细观察并作笔记 5.测量及记录主要流程输出变量值(KPOVs)
阶段I:能力研究
6.运行Capability Six-pack 并观察看: Normal Plot, Histogram SPC Charts (检查Stability, Accuracy)
流程改善方法论TM
• 多变量分析(Multi-Vari study)
流程改善方法论TM
步骤I:定义(Define)
第十二章spss多选变量分析

第1步:打开“大学生择业考虑的因素.sav”文件。
第2步:启动分析过程。点击【分析】【多重响应】【定 义变量集…】。
第3步:设置分析变量。在定义多重响应集的对话框,然后把该 试题的几个选项变量“V1_1”、“V1_2”…“V1_9”选中,点 击向右按钮将它们移动到“集合中的变量”框中。
在“变量编码方式”框里,有“○二分法”、“○类别”两个 单选按钮,
第4步:完成设置。在前面的信息完成设置后,点击【添加 】按钮,则该多选题的定义就添加显示到了右边的“多重 响应集”框内。
注意:如果该数据问 卷中,如果还有其他多 选题,可以继续添加。
第十二章 多选变量分析
第
十 二
12.1 多选变量的编码录入、定义设置
章 12.2 多选变量的描述统计、交叉表分析
另外一个定义模块在菜单【数据】【定义变量集…】中 (也可以在【分析】【定制表】【多重响应集…】中 打开,打开的对话框窗口是一样的)。
在此定义模块进行定义,则数据集会自动保留存储此定义 ,下次打开该数据集,还可以看到和使用该多选题变量的 定义集。以上两种定义模块的对话窗的界面功能基本相似 。
案例:【例12-5】择业中考虑的主要因素有哪些?(多选)
录入:某被试在三个填空中分别选A、C、F,则该被试在对 应的这三个变量选项A、选项C、选项F下分别录入1、2、3, 其他选项则输入0。
第三种题型:全部排序题
案例:【例12-4】以下是研究型教学教师应具备的素质,您
认为其重要性依次排序(最重要的排最前):__、__、__、 __、__。
A、树立正确的价值观,有事业心和责任感;
12.3.1 全部排序题的分析
案例:【例12-6】下列是选择报考研究生时需要考虑的若
统计学中的多变量分析方法

统计学中的多变量分析方法多变量分析是统计学中一个重要的分析方法,用于研究多个变量之间的关系以及它们对观察结果的影响。
多变量分析可以帮助我们从多个维度来解释数据,揭示隐藏在数据背后的规律和结构。
在统计学中,常见的多变量分析方法主要包括回归分析、主成分分析、聚类分析和因子分析等。
下面将对这些方法进行详细介绍。
回归分析是一种用于研究因变量和自变量之间关系的方法。
它通过建立一个数学模型来描述这种关系,并根据数据推断模型的参数。
回归分析可以用于预测因变量的取值,也可以用于确定自变量对因变量的影响程度。
常见的回归分析方法有线性回归、多元线性回归、逻辑回归等。
主成分分析(PCA)是一种通过线性组合将多个相关变量转换为少数几个无关变量的方法。
它可以帮助我们发现数据中的主要结构和模式。
主成分分析的输出是一组新的变量,称为主成分,它们是原始变量的线性组合。
主成分分析可以用于数据降维、数据压缩和特征提取等。
聚类分析是一种将相似的个体或对象归类为一组的方法。
聚类分析基于样本之间的相似性或距离度量,将样本划分为不同的簇。
聚类分析可以用于数据分类、观察群体相似性和发现群组之间的关系等。
常用的聚类分析方法有层次聚类和k均值聚类等。
因子分析是一种用于解释变量之间关系的方法。
它通过将多个观测变量解释为少数几个潜在因子,来揭示数据背后的结构。
因子分析可以帮助我们压缩数据信息、发现共性因子和解释观测变量之间的关系。
常见的因子分析方法有主成分分析和最大似然法等。
此外,还有其他一些多变量分析方法,比如判别分析、典型相关分析、结构方程模型等,它们也在统计学的研究中得到广泛应用。
这些方法在实际研究中可以结合使用,以更全面地分析数据和解释现象。
总结来说,多变量分析是统计学中重要的分析手段,用于研究多个变量之间的关系。
常见的多变量分析方法包括回归分析、主成分分析、聚类分析和因子分析等。
这些方法可以帮助我们从多个维度来理解数据,揭示数据背后的规律和结构。
(整理)因子分析方法——多变量分析
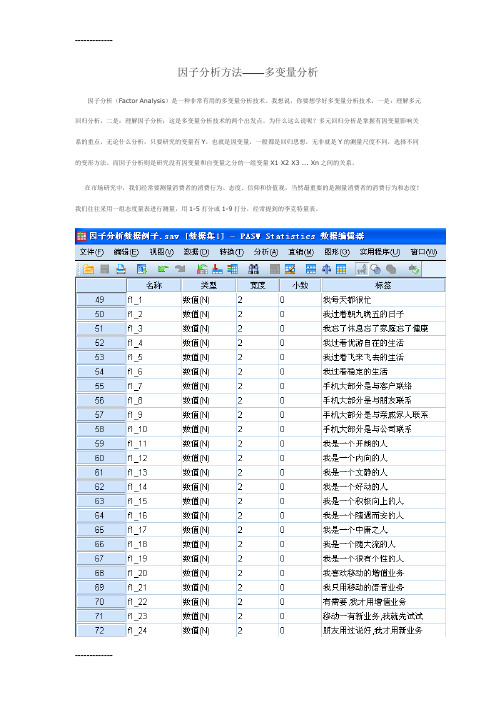
因子分析方法——多变量分析因子分析(Factor Analysis)是一种非常有用的多变量分析技术。
我想说,你要想学好多变量分析技术,一是:理解多元回归分析,二是:理解因子分析;这是多变量分析技术的两个出发点。
为什么这么说呢?多元回归分析是掌握有因变量影响关系的重点,无论什么分析,只要研究的变量有Y,也就是因变量,一般都是回归思想,无非就是Y的测量尺度不同,选择不同的变形方法。
而因子分析则是研究没有因变量和自变量之分的一组变量X1 X2 X3 ... Xn之间的关系。
在市场研究中,我们经常要测量消费者的消费行为、态度、信仰和价值观,当然最重要的是测量消费者的消费行为和态度!我们往往采用一组态度量表进行测量,用1-5打分或1-9打分,经常提到的李克特量表。
上面的数据是我们为了测量消费者的生活方式或者价值观什么的,选择了24个语句,让消费者进行评估,同意还是不同意,像我还是不像,赞成还是不赞成等等,用1-9打分;因子分析有探索性因子分析和证实性因子分析之分,这里我们主要讨论探索性因子分析!证实性因子分析主要采用SEM结构方程式来解决。
从探索性因子分析角度看:∙一种非常实用的多元统计分析方法;∙∙一种探索性变量分析技术;∙∙分析多变量相互依赖关系的方法;∙∙数据和变量的消减技术;∙∙其它细分技术的预处理过程;我们为什么要用因子分析呢?首先,24个可测量的观测变量之间的存在相互依赖关系,并且我们确信某些观测变量指示了潜在的结构-因子,也就是存在潜在的因子;而潜在的因子是不可观测的,例如:真实的满意度水平,购买的倾向性、收获、态度、经济地位、忠诚度、促销、广告效果、品牌形象等,所以,我们必须从多个角度或维度去测量,比如多维度测量购买产品的动机、消费习惯、生活态度和方式等;这样,一组量表,有太多的变量,我们希望能够消减变量,用一个新的、更小的由原始变量集组合成的新变量集作进一步分析。
这就是因子分析的本质,所以在SPSS软件中,因子分析方法归类在消减变量菜单下。
如何进行数据分析中的多变量分析

如何进行数据分析中的多变量分析数据分析中的多变量分析是一种研究多个变量之间关系的方法。
通过多变量分析,我们可以揭示变量之间的相关性、趋势以及相互影响,为我们提供更全面的数据解读和决策依据。
本文将介绍多变量分析的常见方法和步骤,以及如何进行数据预处理和结果解读。
一、简介多变量分析是一种统计分析方法,用于研究多个变量之间的相关性和影响。
与单变量分析相比,多变量分析考虑了多个变量之间的相互关系,能够提供更全面和准确的结果。
常见的多变量分析方法有回归分析、主成分分析和因子分析等。
二、数据预处理在进行多变量分析之前,通常需要对数据进行预处理,以确保数据的质量和可靠性。
预处理包括数据清洗、缺失值处理和异常值检测等。
1. 数据清洗数据清洗是指对数据进行筛选、过滤和处理,以去除错误、重复或无用的数据。
在数据清洗过程中,可以使用数据可视化、统计分析和专业工具等方法,对数据进行筛选和处理,确保数据的质量。
2. 缺失值处理缺失值是指数据样本中存在的未知值或缺失的数据。
在进行多变量分析时,缺失值会影响结果的准确性和可靠性。
常见的缺失值处理方法包括删除含缺失值的样本、插补缺失值和利用模型进行预测等。
3. 异常值检测异常值是指与其他数据明显不同的数据点,可能是由于测量误差、录入错误或个案特殊性等原因引起。
在多变量分析中,异常值可能导致结果偏离实际情况。
通过统计方法、可视化和专业领域知识等,可以对异常值进行识别和处理。
三、多变量分析方法在进行多变量分析时,可以选择适合研究的方法。
以下是几种常见的多变量分析方法:1. 回归分析回归分析用于研究一个或多个自变量对因变量的影响程度和方向。
通过建立回归模型,可以分析变量之间的线性关系,并进行预测和解释。
回归分析包括简单线性回归、多元线性回归和逻辑回归等。
2. 主成分分析主成分分析用于降维和数据可视化,将高维数据转化为低维数据,并保留数据的主要信息。
主成分分析通过寻找变量之间的线性组合,得到新的主成分变量,并解释数据的变异性和结构。
多变量分析方法与相关分析

多变量分析方法与相关分析多变量分析是指研究多个自变量与一个因变量之间的关系的统计方法。
它主要通过建立数学模型来揭示自变量对因变量的影响程度和方向。
多变量分析方法可以帮助研究人员更全面地了解多个自变量对因变量的综合影响,从而提高研究结果的解释力和预测能力。
其中,相关分析是多变量分析方法中的一种重要方法,主要用于分析和评估两个变量之间的线性关系。
多变量分析方法包括回归分析、因子分析、聚类分析和判别分析等。
回归分析是通过建立数学模型来研究因变量与自变量之间的关系的一种方法。
它可以帮助确定自变量对因变量的影响程度和方向,并用于预测目标变量的取值。
回归分析包括简单线性回归和多元线性回归两种形式。
简单线性回归分析通过一个自变量来预测因变量的取值,多元线性回归分析则通过多个自变量来预测因变量的取值。
因子分析是通过统计方法将多个观测变量归纳为几个潜在因子,并分析这些潜在因子与自变量之间的关系。
聚类分析是将具有相似特征的个体分为一组的方法,通过评估不同变量之间的差异来判断个体之间的相似性和差异性。
判别分析则是将属于不同组别的个体通过建立判别函数来进行分类的方法。
相关分析是多变量分析方法中的一种重要方法,用于评估和描述两个变量之间的线性关系。
相关系数是衡量两个变量之间关系强度和方向的统计指标。
常用的相关系数有皮尔逊相关系数和斯皮尔曼相关系数两种。
皮尔逊相关系数是用于度量两个连续变量之间线性关系的指标,取值范围从-1到+1,其中正值表示正相关,负值表示负相关,绝对值越接近1表示关系越强。
斯皮尔曼相关系数是一种非参数统计方法,用于度量两个变量之间的单调关系。
它将每个变量的排名转换为秩次,并计算两个变量的秩次差的相关系数,取值范围从-1到+1,其中正值表示正相关,负值表示负相关,绝对值越接近1表示关系越强。
在实际应用中,多变量分析方法和相关分析可以帮助研究人员更好地理解和解释复杂问题。
例如,在市场研究中,可以使用回归分析来分析产品销量与价格、广告投入和竞争水平等自变量之间的关系,以确定哪些因素对销量的影响最大。
多变量分析方法

多变量分析方法多变量分析方法是一种统计学技术,它用于分析多个自变量对一个或多个因变量的影响关系。
通过探究变量之间的相互作用,多变量分析方法可以帮助我们理解数据背后的关联和趋势,从而作出准确的预测和决策。
在本文中,我们将介绍几种常见的多变量分析方法,并探讨它们在实际问题中的应用。
一、多元线性回归分析多元线性回归分析是一种用于研究多个自变量对一个连续因变量的影响的方法。
通过建立一个线性方程,我们可以根据自变量的值来预测因变量的取值。
在进行多元线性回归分析时,我们需要收集一组包含自变量和因变量数值的样本数据。
然后,通过最小二乘法来估计各个系数,以确保线性方程最符合样本数据。
多元线性回归分析在实际问题中有着广泛的应用。
例如,在市场营销中,我们可以使用多元线性回归分析来探究不同自变量对销售额的影响;在医学研究中,我们可以使用多元线性回归分析来分析多个生物标记物对疾病发展的影响。
二、主成分分析主成分分析是一种用于降维的多变量分析方法。
它可以从原始数据中提取出最具代表性的主要特征,以实现数据简化和可视化。
主成分分析通过将原始数据投影到新的坐标系中,使得每个主成分之间都是不相关的。
通过分析每个主成分的方差贡献率,我们可以确定哪些主成分对数据的解释性最强,从而帮助我们理解数据的结构。
主成分分析在多个领域中都有广泛的应用。
在金融领域,我们可以使用主成分分析来降低股票收益率的维度,以实现投资组合的优化;在生态学研究中,我们可以使用主成分分析来识别影响生物多样性的主要环境因素。
三、聚类分析聚类分析是一种将样本分成不同组别的无监督学习方法。
通过测量样本之间的相似性,聚类分析可以将相似的样本分配到同一个簇中,从而帮助我们发现数据中的隐藏模式和结构。
在进行聚类分析时,我们需要选择适当的距离度量和聚类算法,以确保得到有意义的聚类结果。
聚类分析在市场细分、社交网络分析等领域有着广泛的应用。
例如,在客户细分中,我们可以使用聚类分析来将相似消费者划分到同一个群组中,以实现个性化的营销策略;在社交网络分析中,我们可以使用聚类分析来识别具有相似兴趣和行为的用户群体。
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
Y Y购,该被调查者属于购买者组 Y Y非购,该被调查者属于非购买者组
17
3、回归分析方法及其应用
回归分析是处理自变量x1,x2,x3,…… xn与因变量y之间相关关系的方法,它从 定量的角度寻找变量之间的因果关系, 从而判断某些因素的变化对其他因素的 影响。
18
回归分析法的步骤:
1
2 3 4
9
7 10 8
8
6 7 4
7
6 8 5
5
6 7 购买者平均值
9
8 7 8.2857
9
6 5 6.4286
3
7 6 6.00
非购买者组
1
2 3 4 5
4
3 6 2 1 3.20
4
6 3 4 2 3.80
4
6 3 5 2 4.00
15
非购买者平均值
b P -1 D - 0.016 - 0.00023 5.08571 0.05101 - 0.016 0.04481 - 0.00911 2.62857 - 0.00023 - 0.00911 0.04058 2.0000 0.21692 0.01820 0.05604 Y 0.21692 X1 0.01820X 2 0.05604X 3 购买组 Y 0.21692 8.29 0.01820 6.43 0.05604 6 2.25 非购买组 Y 0.21692 3.2 0.01820 3.8 0.05604 4 0.987
yi b1 x1i b2 x2i b j x ji 式中:yi — —第i个研究对象的判别值 x ji — —第i个研究对象在第j个因素(j= , 3,n)上的观察值 1 2, b j — —第j个因素的比重或判别系数
然后根据所收集到的资料计算出判别临界值yc 作为判别研究对象属于两组之中哪一组的标准。
20
回归系数的计算式如下:
b
x y
i 1 m i i 1
m
i
nx y
xi2 nx 2
a y bx
此外,两变量之间的相关程度如何,利用相关性分析。一般情况下针对 等量尺度问题的相关系数计算式如下: 1 r 1
r
(x
i 1 i
m
i
x )( yi y )
6
例——系统分类法之最短距离法
最短距离法是将距离 最短的两个目标或类 别组合在一起。
d ij min 度进行 调查。其中有两个问题如下:
“您每月大约喝多少瓶啤酒?” “您对‘饮酒是人生的快乐’这句话的看法 如何?”
同意10 9 8 7 6 5 4 3 2 1 不同意
2
n n 如果下季度广告费的支出为80万元时,则产品的销售额为: ˆ Y a bX 344 .27 24 .04 * x 344 .27 24 .04 * 80 2267 .(万元) 5
i
Y b X
1658 24 .04 * 54 .64 344 .27
L1 y
L2 y L11 L12 L21 L22
-49.4 -49.4 -36.4 -36.4 -23.4 -5.4 0.6 -22.4 -167.4 -266.4 -656.0 -65.6 43.56 31.36 43.56 21.16 6.76 0.16 19.36 40.96 40.96 70.56 318.4 31.84 -8.58 -7.28 -8.58 --5.98 -3.38 0.12 1.32 -4.48 -17.28 -31.08 -85.2 -8.52 -8.58 -7.28 -8.58 --5.98 -3.38 0.12 1.32 -4.48 -17.28 -31.08 -85.2 -8.52 1.69 1.69 1.69 1.69 1.69 0.09 0.09 0.49 7.29 13.69 30.1 3.01
8
其中5位顾客的调查结果如下:
顾客 1 2 3 4 5 饮用量(瓶) 20 18 10 4 4 态度 7 10 5 5 3
9
聚类分析的步骤: 1、数据变换 2、计算各样本之间的距离 3、类别合并 4、聚类分析图 1
d ij xi x j yi y j
远东企业公司发展了一种新产品,该公 司在新产品未大量上市前,为安全起见, 将新产品的样品寄给了十二个国家的进 口代理商,要求对该产品给予评估。评 估的因素有三:式样、包装及耐久性。 评分表采用10分制,每一进口代理商并 被要求说明是否愿意购买,调查结果如 下:
14
产品特性 式样 包装 耐久性
购买者组
y b0 b1 x1 b2 x2 bn xn
25
用矩阵表示为:
Y Xb
b0 b1 . b p1 . . bn 1
式中:
Y1 Y2 . Y n 1 . . Yn
Sxx=1744.5
Syy=1035101
Sxy=41944.64
22
2500 2000 1500 1000 500 0 0 20 40 60 80 100
23
判断相关性 相关系数
r
i
X X Y Y X X Y Y
t 2 i t
S xy S xx S yy
置信区间
s
Y Yˆ
n m 1
2
26613 54.38 11 1 1
90%的置信度,置信区间:上限:2267.5+54.39*1.86=2368.8 万元 24 下限:2267.5-54.39*1.86=2166.33万元
多元线性回归分析
多元回归分析处理因变量与多个影响因素 (自变量)的相关性关系。 其线性模型为:
1,X 11,X 12, X 1n 1,X ,X , X 21 22 2n X n p 1,X n1,X n 2, X nn
b ( X ' X ) 1 X ' Y
相关系数的计算式:
26
二元线性回归分析模型
预测公式: Yˆ b
2
2
2
3
4
5
距离 0.04 0.09 0.10
0.29
10
2、判别分析法及其应用
判别分析法是用于判别样本所属类型的 一种多变量统计分析方法 作用于在已知被研究对象已分成若干类 的情况下,确定新的被研究者究竟属于 已知类型中的哪一类。
11
判别分析法的基本原理 判别分析是根据样本数据,确定判别系数
序号 自变量X 因变量Y X2 Y2 XY 预测值 预测值的 误差 51.17 -48.09 13.35 21.65 -83.22 8.69 76.56 -30.91 -72.22 28.61 34.40 误差的平方
1 2 3 4 5 6 7 8 9 10 11 合计
36 42 55 48 45 47 50 61 68 72 77 601.0
x x2 x1 x2
2 1 2 2 2 1 2 2 1 2
2
1
1 2
2
2
b2
x1
x x2 x1 x2
x Y x x xY
1 2
b0 Y b1 x1 b2 x2
27
年份
X1i 人均年收 入(千元 16 17 16 18 20 23 27 29 29 31 226 22.6
0
b1 X 1 b2 X 2 e
式中:
Y nb b x b x xY b x b x b x x x Y b x b x x b x x xY x x x Y b
0 1 1 2 2 1 0 1 1 2 1 2 2 0 2 1 1 2 2 2 1 1 2 2 2
第十二章 多变量分析方法及其应用
1
多变量分析方法在市场研究中应用的 作用
1、简化数据结构,选择变量子集 合 2、对数据进行分类处理、分类研 究、构造分类模式 3、构造模型
2
1、聚类分析方法及其应用
聚类分析的作用:将一些变量、目标、 公司等进行分类组合
3
聚类分析的基本方法原理——就是测量 研究目标之间的相似性,根据相似的程 度将研究目标进行分类。 测量研究目标之间的相似性的方法通常 有两种:
2
r 0.7, 强相关 0.3 r 0.7,中度相关 r 0.3, 弱相关
(x
i 1
m
x )
(y
i 1
m
i
y )2
21
【例】某企业研究企业广告支出费对产品销售额的影响,现获得最 近11个季度有关的统计资料如下表,试分析企业广告支出对销售额 有无显著影响,如果企业下季度准备广告支出80万元,估计企业的 销售额为多少?
41944 .36 1744 .545 *1035101
0.987
2
从散点图和相关系数表明企业广告费支出与产品销售额之间存在强线 性相关关系。可用一次线性相关分析法进行预测。 ˆ 2.预测方程: Y a bX
b a n X i Yi X i Yi n X i2 X i 11 * 1038348 601 * 18237 24 .04 11 * 34581 601 * 601
两目标之间的距离 两目标的关联系数