Web搜索引擎工程作业说明
搜索引擎实习作业

一、搜索引擎的使用实习作业1.大部分搜索引擎都支持逻辑运算符,若要查找“含关键词化学、教育、但不含初中”,该如何检索?写出检索式,分别在百度和Google上进行检索,分别得出总数和反馈结果时间。
化学教育-初中百度为您找到相关结果约26,700,000个化学教育-初中Google找到约149,000,000 条结果(用时0.11 秒)2. 分别在百度和Google上检索网页标题中含有“伦敦奥运会”的网址,写出检索式,写出两个搜索引擎的结果总数和反馈结果时间,并举出3个网址。
(Intitle) Intitle:伦敦奥运会百度为您找到相关结果约896,000个/view/675221.htm//Intitle: 伦敦奥运会Google找到约4,560,000 条结果(用时0.20 秒)//2012/london2012//sports/olympic/2012london/3.请分别用两种搜索引擎检索有关中学化学教学的pdf文件和ppt文件,列出检索式,各试举出2个相关的网址(注明所使用的搜索引擎)。
(filetype)百度中学化学教学filetype:pdf/jpkc/swwjhx/web/zntj/rdwz/swwjhxmt.pdf/jcjy/menu/2010/201012/G371012.pdf中学化学教学filetype:ppt/view/a9da0f2458fb770bf78a5591.html/userfiles/edu/expert_files/sunxu.ppt谷歌中学化学教学filetype:pdf/url?sa=t&rct=j&q=%E4%B8%AD%E5%AD%A6%E5%8C%96%E5%AD%A6%E6%95%99%E5%AD%A6+filetype:pdf&source= web&cd=1&ved=0CCIQFjAA&url=http%3A%2F%%3A811% 2F12%2Fgljx%2Fts012027.pdf&ei=vKNdUOgh7JmJB6LMgaAF&usg=AFQjCNG ysXDv8XtFyUy_Bg2vZ416yjdkhA&cad=rjt/url?sa=t&rct=j&q=%E4%B8%AD%E5%AD%A6%E5%8C%96%E5%AD%A6%E6%95%99%E5%AD%A6+filetype:pdf&source= web&cd=2&ved=0CCYQFjAB&url=http%3A%2F%%2Fzdwz%2F29pian%2F%25E9%25AB%2598%25E8%2580%2583%25E5%258C%2596 %25E5%25AD%25A6%25E5%2591%25BD%25E9%25A2%2598%25E6%2594 %25B9%25E9%259D%25A9%25E4%25B8%258E%25E4%25B8%25AD%25E5 %25AD%25A6%25E5%258C%2596%25E5%25AD%25A6%25E6%2595%2599 %25E5%25AD%25A6%25E5%25AE%259E%25E6%2596%25BD%25E7%25B4 %25A0%25E8%25B4%25A8%25E6%2595%2599%25E8%2582%25B2%25E7% 259A%2584%25E6%2580%259D%25E8%2580%2583.pdf&ei=vKNdUOgh7JmJB 6LMgaAF&usg=AFQjCNGOymS0Sczl4s_rVaCWi_ss3m4xKA&cad=rjt 中学化学教学filetype:ppt/url?sa=t&rct=j&q=+%E4%B8%AD%E5%AD%A6 %E5%8C%96%E5%AD%A6%E6%95%99%E5%AD%A6+filetype:ppt+&source =web&cd=2&ved=0CCcQFjAB&url=http%3A%2F%%2Fxhjxl%2 Fdoc%2F%25E5%258C%2596%25E5%25AD%25A6%25E6%2595%2599%25E5 %25AD%25A6%25E8%25AE%25BA%25E8%25AF%25BE%25E4%25BB%25B 6%2F%25E7%25AC%25AC%25E5%258D%2581%25E7%25AB%25A0%25E6 %2595%2599%25E5%25AD%25A6%25E7%25A0%2594%25E7%25A9%25B6.p pt&ei=t6RdUOTBNKfmiAf_x4CoCA&usg=AFQjCNGcCVOjc3KMl3yZYWsF2Fo Az7oWXQ&cad=rjt/url?sa=t&rct=j&q=+%E4%B8%AD%E5%AD%A6 %E5%8C%96%E5%AD%A6%E6%95%99%E5%AD%A6+filetype:ppt+&source =web&cd=3&ved=0CCwQFjAC&url=http%3A%2F%%2Fxhjxl%2 Fdoc%2F%25E5%258C%2596%25E5%25AD%25A6%25E6%2595%2599%25E5 %25AD%25A6%25E8%25AE%25BA%25E8%25AF%25BE%25E4%25BB%25B 6%2F%25E7%25AC%25AC%25E5%259B%259B%25E7%25AB%25A0%25E5 %258C%2596%25E5%25AD%25A6%25E6%2595%2599%25E5%25AD%25A6 %25E5%258E%259F%25E5%2588%2599%25E3%2580%2581%25E6%2596%2 5B9%25E6%25B3%2595%25E3%2580%2581%25E6%25A8%25A1%25E5%25B C%258F%25E5%2592%258C%25E7%25AD%2596%25E7%2595%25A5.ppt&ei =t6RdUOTBNKfmiAf_x4CoCA&usg=AFQjCNFHCMxj5G7VZZeb0E6WsF4wzg6 CcQ&cad=rjt4. 请检索中学化学新课改的相关资料。
实验项目四 搜索引擎高级功能使用

三.实验步骤(续): 实验步骤(
2.通过搜索引擎搜集商务信息 任务一:通过搜索引擎搜索3家提供“家用臭氧机”产品的 公司,填写下表:
实验项目四
搜索引擎高级功能使用
一.实验目的
会使用搜索引擎的高级搜索 功能; 掌握利用搜索引擎高级搜索 技巧来收集商务信息的技巧。
二. 实验内容
1.浏览国内外常见的搜索引擎网 站; 2.体验不同搜索引擎的高级搜索 功能; 3.利用搜索引擎高级搜索技巧收 集相关信息
三.实验步骤: 实验步骤:
1.掌握搜索引擎高级技巧运用方法,设计搜索命令,填 入下表。
公司名称 1 2 3公司联系 方式公司产 品照片公司网址
三.实验步骤(续): 实验步骤(
任务二:搜索到至少两个专利介绍网 站,并搜索一条关于手机防盗产品的 专利技术:
三.实验步骤(续): 实验步骤(
任务三:某公司的主打产品是“减速机”,现在该公司希 望了解该产品在网络市场中的行情,请根据调查情况填写 下表: 网站名称 1 2 3 网址 注册公 发布产 供应信 求购信 司数量 品数量 息数量 息数量
Web搜索引擎工作原理和体系结构

Web 搜索引擎工作原理和体系结构Web搜索引擎工作原理和体系结构2011-01-29 18:43个数据集合上的程序的话,这个软件系统操作的数据不仅包括内容不可预测的用户查询,还要包括在数量上动态变化的海量网页,并且这些网页不会主动送到系统来,而是需要由系统去抓取。
首先,我们考虑抓取的时机:事先情况下,从网上下载一篇网页大约需要1秒钟左右,因此如果在用户查询的时候即时去网上抓来成千上万的网页,一个个分析处理,和用户的查询匹配,不可能满足搜索引擎的响应时间要求。
不仅如此,这样做的系统效益也不高(会重复抓取太多的网页);面对大量的用户查询,不可能想象每来一个查询,系统就到网上"搜索"一次。
因此我们看到,大规模搜索(直接或者间接1)。
这一批网页如何维护?可以有两种基本的考虑。
定期搜集,每次搜集替换上一次的内容,我们称之为"批量搜集"。
由于每次都是重新来一次,对于大规模搜索引擎来说,每次搜集的时间通常会花几周。
而由于这样做开销较大,通常两次搜集的间隔时间也不会很短(例如早期天网的版本大约每3个月来一次,Google在一段时间曾是每隔28天来一次)。
这样做的好处是系统实现比较简单,主要缺点是"时新性"(freshness)不高,还有重复搜集所带来的额外带宽的消耗。
增量搜集,开始时搜集一批,往后只是(1)搜集新出现的网页,(2)搜集那些在上次搜集后有过改变的网页,(3)发现自从上次搜集后已经不再存在了的网页,并从库中删除。
由于除新闻网站外,许多网页的内容变化并不是很经常的(有研究指出50%网页的平均生命周期大约为50天[Cho and Garcia-Molina,2000],[Cho,2002]),这样做每次搜集的网页量不会很大(例如我们在2003年初估计中国每天有30-50万变化了的网页),于是可以经常启动搜集过程(例如每天)。
30万网页,一台PC机,在一般的网络条件下,半天也就搜集完了。
搜索引擎实习作业

搜索引擎实习作业搜索引擎实习是许多计算机科学和信息技术学生的梦想实习之一。
这个实习机会提供了一个宝贵的学习平台,使学生能够深入了解搜索引擎的运作,并应用所学知识解决实际问题。
本文将介绍搜索引擎实习的意义,并讨论实习期间可能涉及的任务和技术。
搜索引擎在现代信息时代起着至关重要的作用。
它们允许用户在互联网上快速找到所需的信息,无论是通过文本搜索、图像搜索还是音频视频搜索。
为了使搜索引擎能够提供准确、相关和高质量的搜索结果,背后需要强大的技术基础和算法支持。
搜索引擎实习提供了学习和应用这些技术的机会。
在搜索引擎实习期间,实习生可能需要参与不同的任务和项目。
一项常见任务是数据收集和整理。
搜索引擎需要大量的数据来建立索引和生成搜索结果。
实习生可能需要使用网络爬虫工具获取网页数据,并将其整理成可供搜索引擎使用的格式。
这个任务要求实习生具备良好的数据处理和整理能力。
另一个重要的任务是搜索算法的优化。
搜索引擎的核心是搜索算法,它决定了搜索结果的排名和相关性。
实习生可能需要对现有的算法进行评估和改进,以提高搜索引擎的性能和用户体验。
这需要实习生具备扎实的算法和数据结构知识,并且能够灵活运用它们。
搜索引擎实习还提供了深入研究搜索引擎技术的机会。
实习生可以学习和应用各种技术,例如自然语言处理、机器学习和图像处理。
这些技术可以用于改进搜索结果的相关性、提高用户的搜索体验和解决搜索引擎中的各种问题。
实习生可以利用实习期间的时间,深入研究这些技术,并通过实践应用它们。
除了技术知识,搜索引擎实习还提供了锻炼实习生的团队合作和沟通能力的机会。
在搜索引擎团队中,实习生需要与其他团队成员密切合作,共同完成任务和项目。
这要求实习生能够有效地与他人合作,并及时沟通和解决问题。
这种团队合作和沟通经验对于日后的职业发展非常重要。
在搜索引擎实习期间,实习生还可以通过参加技术研讨会和工作坊等活动,扩展自己的专业网络和知识。
这些活动通常由搜索引擎公司组织,邀请专家和业界人士分享最新的搜索引擎技术和发展动态。
搜索引擎软件使用说明书
搜索引擎软件使用说明书1 软件概述1.1 编写目的随着计算机产业的迅猛发展,搜索引擎也应运而生。
用户直接获得自己想要的信息其实是很简单,但是面对着简单的搜索框,很多用户都只是了解大概,要想了解的更彻底关键在于学会怎么来用。
为了用户能够更快更方便的获得想要的信息,本人针对自己开发的搜索引擎包特编写了使用说明书。
1.2 搜索引擎介绍1.2.1 搜索引擎定义搜索引擎主要用于帮助互联网用户查询信息的搜索工具,它以一定的策略在互联网中搜集、发现信息,对信息进行理解、提取、组织及处理,并且能为用户提供检索服务,从而起到信息导航的目的因此,搜索引擎是用来在网上找资料的工具。
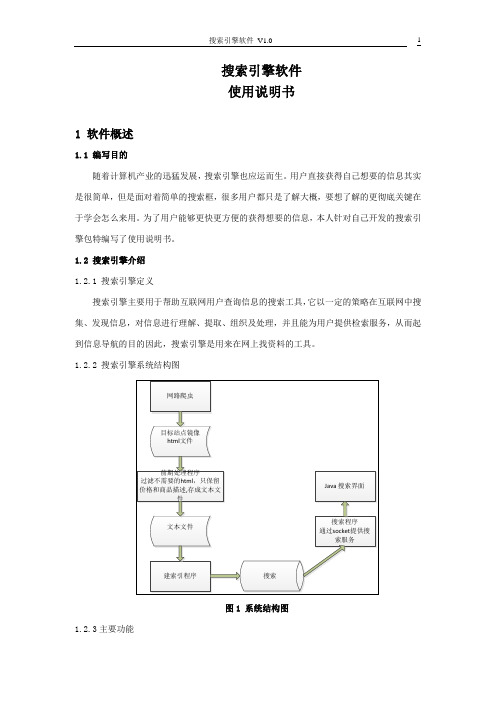
1.2.2 搜索引擎系统结构图1.2.3主要功能本人开发的搜索引擎主要是进行信息检索,从而返回检索结果。
搜索引擎将用户所产生的一些信息列入了排序因素中,具有对各大商城的网站进行抓取、建立索引、搜索比价的功能。
它是网络营销中最重要的组成部分,是向终端客户传递信息的重要环节。
搜索界面如下图:1.2.4 主要特点1.2.4.1 快速地为搜索文件建立索引,支持追加,重建,和不同编码的搜索文件。
1.2.4.2 搜索引擎支持关键字搜索,与或非逻辑搜索,支持按需返回搜索结果。
1.2.4.3 web服务器能快速连接搜索引擎,支持用户的多样化搜索,并展示搜索结果。
2 如何编译fts1. aclocal2. automake --add-missing3. autoconf4. ./configure5. make编译成功以后,在../src/目录下,有index.exe, search.exe 和shutdown.exe。
2.1 index.exeindex.exe是对网络爬虫抓来的网页建立索引,-D源目录,-d索引目录,-R重建索引(只在第一次用),-c 国标或台湾$ ./index -D /cygdrive/c/tf/src/ -d /cygdrive/c/tf/trg -R -c GB2312Start indexing ...Indexing /cygdrive/c/tf/src/Copy of baima.t4i# of Files Processed : 1# of Files Indexed : 1Total Data Processed : 136.242 KB.Average Processing Rate : 45.4141 KBps.Total Time Used : 3 seconds.Total Processor Time Used : 2.875 seconds.CPU Usage : 95.8333%2.2 search.exeSearch.exe 会在已建立的索引上运行一个socket服务器,可以接收多个搜索请求,默认听在端口30001。
WEBs 应用手册说明书

WEBs 应用手册关于霍尼韦尔霍尼韦尔是一家《财富》全球500 强的高科技企业。
我们的高科技解决方案涵盖航空、汽车、楼宇、住宅和工业控制技术,特性材料,以及物联网。
我们致力于将物理世界和数字世界深度融合,利用先进的云计算、数据分析和工业物联网技术解决最为棘手的经济和社会挑战。
在中国,霍尼韦尔长期以创新来推动增长,贯彻“东方服务于东方”和“东方服务于全球”的战略。
霍尼韦尔始创于1885 年,在华历史可以追溯到1935 年,在上海开设了第一个经销机构。
目前,霍尼韦尔四大业务集团均已落户中国,上海是霍尼韦尔亚太区总部,在华员工人数约11,000 人。
同时,霍尼韦尔在中国的30 多个城市拥有50 多家独资公司和合资企业,其中包括20 多家工厂,旨在共同打造万物互联、更智能、更安全和更可持续发展的世界。
欲了解更多公司信息,请访问霍尼韦尔中国网站www. ,或关注霍尼韦尔官方微博和官方微信。
霍尼韦尔霍尼韦尔智能建筑科技集团我们在全球拥有23,000 多名员工。
我们的产品、软件和技术已在全球超过1,000 万栋建筑中使用。
我们的技术确保商业楼宇业主和用户的设施安全、节能、具有可持续性与高生产力。
霍尼韦尔智能建筑科技集团深耕中国40 多年来,参与了30 多个城市的150 多条地铁的建设,为500 多座机场的智慧和安全保驾护航,为600 多家酒店提供智能管理系统,为1000多家医院提供了数字化解决方案。
目录第一部分 (4)霍尼韦尔智慧楼宇系统架构示意图 (4)霍尼韦尔智慧能源管理解决方案 (6)WEBs N4管理软件 (9)霍尼韦尔智慧触控屏 (13)第二部分 (17)系统控制器 WEB 8000 系列 (17)系统控制器 WEB 8000 VAV 专用系列 (21)边缘数据管理器 (24)增强型可编程通用控制器 (27)可编程通用控制器 (30)可编程通用控制器扩展模块 (33)BACnet 可编程通用 / VAV 控制器 (36)Lonworks 可编程通用 / VAV 控制器 (39)VAV 控制器 (43)BACnet 通用控制器 (46)Sylk TM I/O 扩展模块 (49)MVCweb 控制器 (52)UB系列独立控制器 (55)第三部分 (59)房间温控单元 (59)变风量末端墙装模块 (63)WTS3/6 系列温控器 (65)WTS8/9 系列温控器 (69)WS9 系列墙装模块 (73)建筑网络适配器 (76)智能电表 (78)4Ethernet / LANBACnet MS/TP Modbus RTU LonworksKNXSylk BusLightingModbus TCP BACnet IPBACnet IPAlarm Console clientWEB 8000 Web ControllerWEBStation Supervisor智慧触控屏Sylk I/O ModuleLonworks Spyder边缘数据管理器Spyder Universal ControllerPUC BACnet MS/TP Controller霍尼韦尔智慧楼宇系统架构示意图系统示意图仅用于显示设备在系统中的层次关系以及支持的通讯协议具体配置细节请结合实际项目情况,联系霍尼韦尔技术工程师进行架构设计5ElectricitySubmeterBACnet IPBACnet IPHTTPs , BACnet IP , oBIX , SNMP , …WEBs Enterprise Security WEBs Energy AnalyticsHAQ61增强型 BACnet IP ControllerFCU Wall ModuleVAV Controller EM Bus I/O ModuleSylk Bus Wall Module增强型 BACnet IP ControllerEM Bus6霍尼韦尔智慧能源管理解决方案智能高效,机器自学习功能准确分析,快速发现能耗异常功能全面,基于能耗大数据采集、趋势分析、评估诊断和流程控制的闭环管理功能数据准确,具有180多年计量仪表生产、安装与服务的专业知识灵活易用,云平台或本地部署灵活配置和迁移,操作简便扩展性好通过能源可见性、积极应对能耗异常和提高管理人员参与度,用户可以:★ 避免能耗异常波动★ 确保节能投资的投资回报率(ROI)符合预期★ 提高管理效率和降低运营成本研究显示,更多的企业为合规地实现节省成本、提高效率,越来越关注能源管理系统。
Web服务搜索引擎的设计与实现

WS E We ev e erhE g e , 以 G ol S ( bSri sSac ni ) 它 c n og e的搜 索结 以提 高 We b服务搜索 的效率 。并将
搜 索 到 的 We 务 进 行 集 中管 理 , 后 采 用 开 源 的 L cn 对 b服 最 u ee
搜 索到的 We b服务建立索 引 , 提高 We b服务的检索效率。
1 背 景 知 识
公开 、 可访 问 的 WS L文档 都是 放在 We D b服务器 上的 ,
制, 它还具有 自包 含 、 自描述 、 块化和松耦合等特点 。 模 在 We b服务 中, D I 注册 中心 为服务 的发 布和发 现提 U D 供了一个公共平台 。目前 , 越来 越多的企业采 用 We b服务进行 企业业务集成 , 建立起相应的 U D 注 册 中心 , 并 D I 但是 这些 U — D D 注册 中心却是私有 的, I 只在企业范 围 内使用 , 并不对 外发布 ,
G ol We og e的 b服务搜索方法 , 设计与实现 了 We b服务搜索引擎
0 引 言
We b服务 …是 由 U I R 标识 的软件系统 , 其接 口和绑定可 以 通过 X ML进行定义 、 描述和发现 。We b服务支持通过基于互联 网的协议 , 使用 基 于 X ML的消息 与 We b服务 或者其 他 软件 系 统进行直接交互 。它 的出现改变 了传统 的计算模 式 , 形成 了一
sa e do e ne t s e s aae hm.nti pprw ei e di l n da S We e i s erhE g e no e ct r nt t la m ng e I s ae, eds nda e t E( bSr c ac n i )i dr te h i me a w l t h g n mp me e WS v eS n r
实验四 认识搜索引擎

认识搜索引擎检索作业(实验4)一、实验目的1、认识搜索引擎2、了解搜索引擎原理及使用方法3、在线查找搜索引擎学时安排:2学时二、实验内容1、在IE浏览器输入网址:/web/searchengine.htm,或是利用Google搜索引擎查询【认识搜索引擎】,找到该网页,了解搜索引擎的原理极其发展过程。
2、打开/index.htm和/,查看站点中文搜索引擎指南网(搜网)和搜索快报,了解搜索引擎有关新闻、使用技巧、排名规则、以及在商业上的应用。
3、在线查找搜索引擎,列出你所熟悉的中文引擎的前5名,英文引擎的前5名4、列出至少20个搜索引擎(包括一个能够搜索—搜索引擎的引擎,报告中请注明)5、使用不同的英文搜索引擎分别给出歌德巴赫猜想(Goldbach's conjecture)和世界名画《蒙娜丽莎》(Mona Lisa )的英文详细介绍网址,并分别给出内容的英文简介。
6、针对你的选题自选检索词利用英文搜索引擎检索,记录检索结果三、实验报告1、搜索引擎的原理搜索引擎的原理,可以看做三步:从互联网上抓取网页→建立索引数据库→在索引数据库中搜索排序。
2、搜索引擎的使用技巧对于搜索引擎的使用,简单的就是输入你的语言想法。
通过提交获得,这中间就要求你懂得搜索引擎的一个搜索因素。
就是搜索关键字或关键词。
这个一般不会被大众用户所了解,普通用户只是简单的思考就形成一种搜索习惯。
比较准确一点的话就是关键词组,例如:考试模拟题,上海到北京线路等等这些就是关键词组,再比较专业一点的就是关键字,这个主要是一些特殊定义的词,例如:北京旅游,上海酒店,成人高考,一心一意等等。
另一方面就是搜索引擎的专业使用,主要是搜索引擎命令搜索和搜索引擎的分类搜索。
搜索引擎的命令搜索主要有查看网站收录情况,使用site:命令;查看网站的外链情况,使用domain:或者link:命令等。
搜索文档等,使用filetype:文档格式(DOC,PDF,XLS,PPT等);还有使用函数符号搜索,使用加号(+)或者减号(-)号等来匹配内容;其次还有很多函数符号的使用,如:&,intitle,inurl,tag,“”,(),related,url,image等等。
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
Web搜索引擎工程作业说明
姓名--xxx
专业--计算机科学与技术专业
时间--2015.01.01
本次作业所做的是一个微型搜素引擎模型。
为了实现这个模型,我把这个作业分成了四段进行处理,首先是利用爬虫将网站的内容爬下来,之后是html文件处理,然后是建立索引,最后是查询处理。
之所以要将html 处理和索引建立这个两步独立开来的原因是,从运行时间代价和实际来考虑,都是每隔一段时间抓取一次网页并将其解析成txt文本,解析成txt以后立即用建立索引相关的类来进行索引建立的处理。
最后,在这两步的基础之上,我们可以进行任意多次的查询。
而如果把三步都合在一块处理的话,每一次查询都需要爬取网页、解析网页、然后执行查询操作再返回结果,即使是文档数量较小的情况下这样的时间代价也是无法接受的,所以我提交的作业中分三个工程来做这个搜索引擎,如下:
一利用爬虫工具将网站镜像到本地
二工程”Html”是html解析的处理部分。
三工程”Index_Found”是建立索引的部分。
四工程”WWeb”为搜索引擎的核心处理工程,包括交互处理、中间处理、底层数据处理、结果返回处理等。
文件夹E:\a是存放html文件的地方,鉴于没有给老师教html测试文件的必要,此处主要说明有一个parser的文件夹在程序中定义了,需要用到。
Jar文件夹中包含有这个作业运行时需要的所有外jar压缩包。
lucene-test-framework-3.6.2.jar和lucene-core-3.6.2.jar是和索引建立和查询相关的lucene压缩包,htmlparser.Jar是跟html解析相关的压缩包。
要运行这个作业,首先要新建一个server,修改server的相关设置以后将WWeb工程add到服务器(在程序中我设置的将工程加载到webapps),然后开始运行。
如果运行正常,在apache-tomcat-6.0.37(我用的是这个)安装路径下的webapps文件夹下应该会有一个WWeb的工程,这样算是连接上服务器了(如果报错http:404则是连接服务器不成功)。
在进行查询的过程中,先要将lucene的两个jar文件粘贴到tomcat下webapps\WWeb\WEB-INF\lib文件夹中,并将所有html源文件打包放在一个名叫a的文件夹(程序中这么
设置的)中,并将这个文件夹粘贴到webapps\WWeb这个文件中。
因为某些还不知道的原因,tomcat在运行过程中,会将上述的parser文件夹和两个lucene包删除,并保存http:500,这时候需要重新复制、粘贴。
具体步骤如下:
第一步:抓取网页
从网上下载一个Teleport Ultra爬虫软件,从南开校内网上爬取网页,在作业中抓了1000个作为测试例子。
抓取的网页以html形式保存,从新命名各个网页为抓取时的顺序编号(0、1、2、3…)中,我把所有html 网页文件全部保存在了E:\a这个文件夹中。
这个路径在解析html文件的时候在Html工程中的Html_Produce.java类中需要用到,用以寻找解析源文件来解析成txt文件;也需要在controller_servlet类中用到,用以最后找到目标html对应的网页。
第二步:html解析成txt
新建一个工程Html的java工程,在工程中的build路径中添加一个叫做htmlparser.Jar的压缩包,用来调用html解析相关的东西,把html文件构造成一颗树来表示。
然后再在工程下面新建一个类,命名为Html_Produce,这个类的功能就是挨个读取E:\pacongruanjian\parser文件夹下所有html文件,并截取html 中的数字为txt文件名的一部分,txt文件名形如text1.txt、text2.txt。
然后读取html文件中的文本内容,并把他们都出入到相应的txt文件中去。
这一步结束之后,所有解析出来的txt文件都是保存在E:\pacongruanjian\abc文件夹下,这个路径在indexFound这个类中indxFile.java类中对txt文件建立索引的时候需要用到。
第三步:建立索引
新建一个名叫index_Found的工程,在其build路径中添加外部的lucene-test-framework-3.6.2.jar 和lucene-core-3.6.2.jar两个lucene解析包,用来对txt文档建立索引时使用。
在工程下建立一个名为indexFile.java的类,这个类就是调用相关的lucene类、函数来对E:\pacongruanjian\abc文件夹下的txt文
件建立索引,在这个处理过程中产生的与索引相关的所有文件都存在E:\pacongruanjian\index这个文件夹下面,这个路径在web工程下的model_Bean.java类中需要用到,用以寻找到最初的html文件并将其打开,以进行相应的查询。
第四步:新建web工程
按照M-V-C的JSP编程模式连接浏览器和服务器,M指的是model层,主要负责处理底层的数据,并将处理结果返回给controller层;V指的是View,主要负责处理前段与用户的交互,接收用户的输入信息,并将其传递到controller层;C指的是controler,主要负责从前端接收用户输入,并将根据需求将任务分配给model 层的处理函数,在model将处理结果返回以后再讲结果再次返回给View层去。
具体操作是,先新建一个web工程,在其build路径中添加外部的lucene-test-framework-3.6.2.jar和lucene-core-3.6.2.jar两个lucene解析包,用以在索引中查找结果文档名。
对应模型中的View层,首先新建一个jsp文件,这个文件是一个前端界面,用来接收用户的查询,以post 的方式传递到controller_servlet。
新建一个普通java类model_Bean,将其放置在web工程下的ch06package中。
这个类对应的是model 层,这个类负责的工作是接收controller_servlet中传递进来的查询,调用lucene中相应的类、函数进行处理,查找到相关文档,将符合条件的文档的文档名保存在一个string数组中,并将这个string数组返回controller_servlet层。
然后再新建一个servlet类,命名为controller_servlet.java,也是将其放置在ch06package中。
这个类对应的是servlet层,用以接收view层中传递进来的查询语句,然后调用model_Bean层中的查询处理函数进行查询,然后将接收结果进行处理。
对于返回的string数组,每个数组元素表示的是一个txt文档名,由于这个文档名中的数字与其原先的html文档中的数字是一致的,所以可以通过这个数字以及html文件的存储路径找到对应的结果网页。
还需要建立一个web.xml文件。
老师好,由于作业写的比较匆忙,可能有些地方没有调试到位,希望老师海涵。
特别感谢老师这一学期来对我学业的教导,老师辛苦了。
在此祝老师新的一年里,身体健康,工作顺心,家庭和睦,万事如意!。