spss多元回归分析案例
SPSS多元回归分析实例
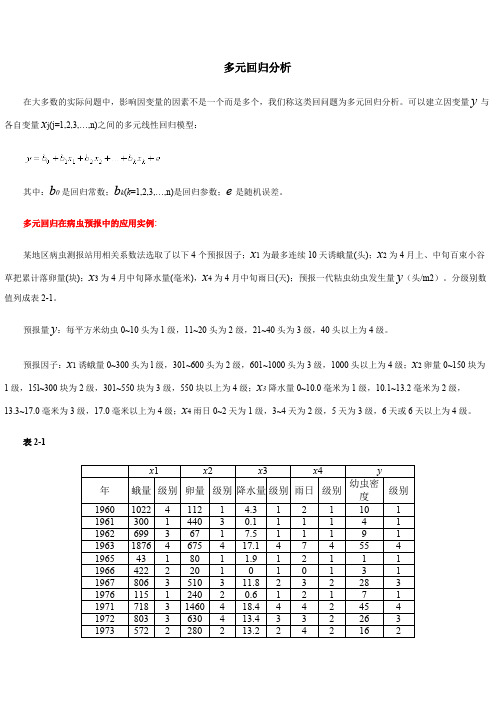
t i e an dl l t 多元回归分析在大多数的实际问题中,影响因变量的因素不是一个而是多个,我们称这类回问题为多元回归分析。
可以建立因变量y 与各自变量x j (j=1,2,3,…,n)之间的多元线性回归模型:其中:b 0是回归常数;b k (k =1,2,3,…,n)是回归参数;e 是随机误差。
多元回归在病虫预报中的应用实例:某地区病虫测报站用相关系数法选取了以下4个预报因子;x 1为最多连续10天诱蛾量(头);x 2为4月上、中旬百束小谷草把累计落卵量(块);x 3为4月中旬降水量(毫米),x 4为4月中旬雨日(天);预报一代粘虫幼虫发生量y (头/m2)。
分级别数值列成表2-1。
预报量y :每平方米幼虫0~10头为1级,11~20头为2级,21~40头为3级,40头以上为4级。
预报因子:x 1诱蛾量0~300头为l 级,301~600头为2级,601~1000头为3级,1000头以上为4级;x 2卵量0~150块为1级,15l~300块为2级,301~550块为3级,550块以上为4级;x 3降水量0~10.0毫米为1级,10.1~13.2毫米为2级,13.3~17.0毫米为3级,17.0毫米以上为4级;x 4雨日0~2天为1级,3~4天为2级,5天为3级,6天或6天以上为4级。
表2-1x 1x 2x 3x 4y 年 蛾量 级别 卵量 级别 降水量 级别 雨日 级别 幼虫密度级别1960102241121 4.31211011961300144030.111141196269936717.511191196318764675417.14745541965431801 1.9121111966422220101013119678063510311.82322831976115124020.612171197171831460418.444245419728033630413.433226319735722280213.224216219742641330342.243219219751981165271.84532331976461214017.515328319777693640444.7432444197825516510101112数据保存在“DATA6-5.SAV”文件中。
SPSS多元线性回归分析实例操作步骤
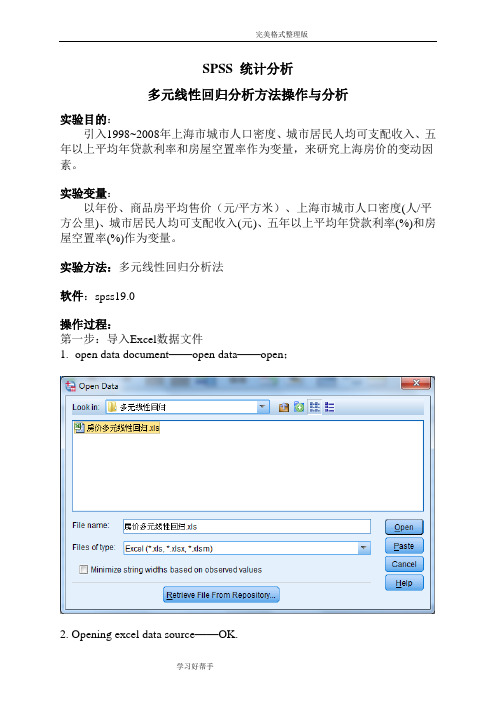
SPSS 统计分析多元线性回归分析方法操作与分析实验目的:引入1998~2008年上海市城市人口密度、城市居民人均可支配收入、五年以上平均年贷款利率和房屋空置率作为变量,来研究上海房价的变动因素。
实验变量:以年份、商品房平均售价(元/平方米)、上海市城市人口密度(人/平方公里)、城市居民人均可支配收入(元)、五年以上平均年贷款利率(%)和房屋空置率(%)作为变量。
实验方法:多元线性回归分析法软件:spss19.0操作过程:第一步:导入Excel数据文件1.open data document——open data——open;2. Opening excel data source——OK.第二步:1.在最上面菜单里面选中Analyze——Regression——Linear ,Dependent(因变量)选择商品房平均售价,Independents(自变量)选择城市人口密度、城市居民人均可支配收入、五年以上平均年贷款利率、房屋空置率;Method 选择Stepwise.进入如下界面:2.点击右侧Statistics,勾选Regression Coefficients(回归系数)选项组中的Estimates;勾选Residuals(残差)选项组中的Durbin-Watson、Casewise diagnostics默认;接着选择Model fit、Collinearity diagnotics;点击Continue.3.点击右侧Plots,选择*ZPRED(标准化预测值)作为纵轴变量,选择DEPENDNT(因变量)作为横轴变量;勾选选项组中的Standardized Residual Plots(标准化残差图)中的Histogram、Normal probability plot;点击Continue.4.点击右侧Save,勾选Predicted Vaniues(预测值)和Residuals(残差)选项组中的Unstandardized;点击Continue.5.点击右侧Options,默认,点击Continue.6.返回主对话框,单击OK.输出结果分析:1.引入/剔除变量表Variables Entered/Removed aModel Variables Entered Variables Removed Method1 城市人口密度(人/平方公里) . Stepwise (Criteria:Probability-of-F-to-enter<= .050,Probability-of-F-to-remove >=.100).2 城市居民人均可支配收入(元) . Stepwise (Criteria:Probability-of-F-to-enter<= .050,Probability-of-F-to-remove >=.100).a. Dependent Variable: 商品房平均售价(元/平方米)该表显示模型最先引入变量城市人口密度(人/平方公里),第二个引入模型的是变量城市居民人均可支配收入(元),没有变量被剔除。
SPSS多元线性回归分析报告实例操作步骤

SPSS 统计分析多元线性回归分析方法操作与分析实验目的:引入1998~2008年上海市城市人口密度、城市居民人均可支配收入、五年以上平均年贷款利率和房屋空置率作为变量,来研究上海房价的变动因素。
实验变量:以年份、商品房平均售价(元/平方米)、上海市城市人口密度(人/平方公里)、城市居民人均可支配收入(元)、五年以上平均年贷款利率(%)和房屋空置率(%)作为变量。
实验方法:多元线性回归分析法软件:spss19.0操作过程:第一步:导入Excel数据文件1.open data document——open data——open;2. Opening excel data source——OK.第二步:1.在最上面菜单里面选中Analyze——Regression——Linear ,Dependent(因变量)选择商品房平均售价,Independents(自变量)选择城市人口密度、城市居民人均可支配收入、五年以上平均年贷款利率、房屋空置率;Method 选择Stepwise.进入如下界面:2.点击右侧Statistics,勾选Regression Coefficients(回归系数)选项组中的Estimates;勾选Residuals(残差)选项组中的Durbin-Watson、Casewise diagnostics默认;接着选择Model fit、Collinearity diagnotics;点击Continue.3.点击右侧Plots,选择*ZPRED(标准化预测值)作为纵轴变量,选择DEPENDNT(因变量)作为横轴变量;勾选选项组中的Standardized Residual Plots(标准化残差图)中的Histogram、Normal probability plot;点击Continue.4.点击右侧Save,勾选Predicted Vaniues(预测值)和Residuals(残差)选项组中的Unstandardized;点击Continue.5.点击右侧Options,默认,点击Continue.6.返回主对话框,单击OK.输出结果分析:1.引入/剔除变量表Variables Entered/Removed aModel Variables Entered Variables Removed Method1 城市人口密度(人/平方公里) . Stepwise (Criteria:Probability-of-F-to-enter<= .050,Probability-of-F-to-remove >=.100).2 城市居民人均可支配收入(元) . Stepwise (Criteria:Probability-of-F-to-enter<= .050,Probability-of-F-to-remove >=.100).a. Dependent Variable: 商品房平均售价(元/平方米)该表显示模型最先引入变量城市人口密度(人/平方公里),第二个引入模型的是变量城市居民人均可支配收入(元),没有变量被剔除。
SPSS多元回归分析报告实例
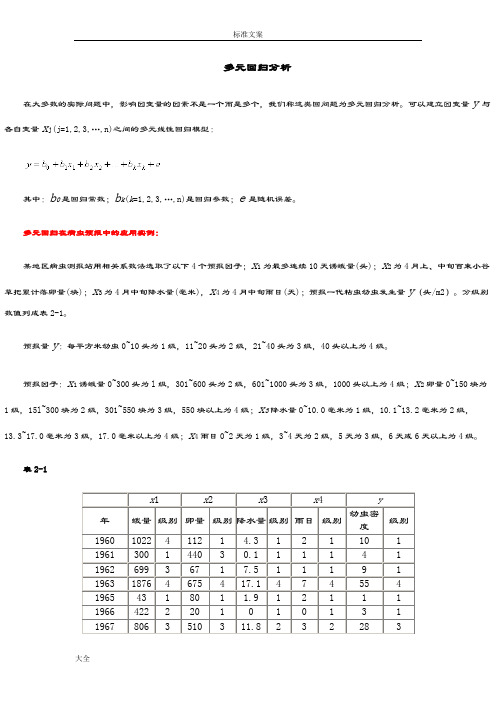
多元回归分析在大多数的实际问题中,影响因变量的因素不是一个而是多个,我们称这类回问题为多元回归分析。
可以建立因变量y与各自变量x j(j=1,2,3,…,n)之间的多元线性回归模型:其中:b0是回归常数;b k(k=1,2,3,…,n)是回归参数;e是随机误差。
多元回归在病虫预报中的应用实例:某地区病虫测报站用相关系数法选取了以下4个预报因子;x1为最多连续10天诱蛾量(头);x2为4月上、中旬百束小谷草把累计落卵量(块);x3为4月中旬降水量(毫米),x4为4月中旬雨日(天);预报一代粘虫幼虫发生量y(头/m2)。
分级别数值列成表2-1。
预报量y:每平方米幼虫0~10头为1级,11~20头为2级,21~40头为3级,40头以上为4级。
预报因子:x1诱蛾量0~300头为l级,301~600头为2级,601~1000头为3级,1000头以上为4级;x2卵量0~150块为1级,15l~300块为2级,301~550块为3级,550块以上为4级;x3降水量0~10.0毫米为1级,10.1~13.2毫米为2级,13.3~17.0毫米为3级,17.0毫米以上为4级;x4雨日0~2天为1级,3~4天为2级,5天为3级,6天或6天以上为4级。
表2-1x1 x2 x3 x4 y年蛾量级别卵量级别降水量级别雨日级别幼虫密度级别1960 1022 4 112 1 4.3 1 2 1 10 1 1961 300 1 440 3 0.1 1 1 1 4 1 1962 699 3 67 1 7.5 1 1 1 9 1 1963 1876 4 675 4 17.1 4 7 4 55 4 1965 43 1 80 1 1.9 1 2 1 1 1 1966 422 2 20 1 0 1 0 1 3 1 1967 806 3 510 3 11.8 2 3 2 28 3数据保存在“DATA6-5.SAV”文件中。
1)准备分析数据在SPSS数据编辑窗口中,创建“年份”、“蛾量”、“卵量”、“降水量”、“雨日”和“幼虫密度”变量,并输入数据。
SPSS实验多元线性回归分析12

这里我们以总成绩作为因变量Y,平时成绩和期中成绩分别作为自变量X1,X2,建立的多元回归模型为:
Байду номын сангаас2,估计参数,建立回归预测模型
利用SPSS可得一下结果:
Variables Entered/Removedb
Model
Variables Entered
Variables Removed
1183.800
19
a. Predictors: (Constant),期中成绩,平时成绩
b. Dependent Variable:总成绩
注释:从表中可得拟合方程的F统计量值为7.586,相应的P值为0.000说明,拟合方程是显著的。是具有统计意义的。
Coefficientsa
Model
Unstandardized Coefficients
Method
1
期中成绩,平时成绩a
.
Enter
a. All requested variables entered.
b. Dependent Variable:总成绩
注释:根据这个表的结果我们可以初步的知道,经过检验自变量X1,X2是可以加入到准备估计的回归方程中作为变量的。
Model Summaryb
Standardized Coefficients
t
Sig.
95% Confidence Interval for B
Correlations
Collinearity Statistics
B
Std. Error
Beta
Lower Bound
Upper Bound
Zero-order
SPSS多元回归分析

多元回归分析影响因变量的因素不是一个而是多个,我们称这类回问题为多元回归分析。
可以建立因变量y与各自变量x j(j=1,2,3,…,n)之间的多元线性回归模型:其中:b0是回归常数;b k(k=1,2,3,…,n)是回归参数;e是随机误差。
多元回归在病虫预报中的应用实例:某地区病虫测报站用相关系数法选取了以下4个预报因子;x1为最多连续10天诱蛾量(头);x2为4月上、中旬百束小谷草把累计落卵量(块);x3为4月中旬降水量(毫米),x4为4月中旬雨日(天);预报一代粘虫幼虫发生量y (头/m2)。
分级别数值列成表2-1。
预报量y:每平方米幼虫0~10头为1级,11~20头为2级,21~40头为3级,40头以上为4级。
预报因子:x1诱蛾量0~300头为l级,301~600头为2级,601~1000头为3级,1000头以上为4级;x2卵量0~150块为1级,15l~300块为2级,301~550块为3级,550块以上为4级;x3降水量0~10.0毫米为1级,10.1~13.2毫米为2级,13.3~17.0毫米为3级,17.0毫米以上为4级;x4雨日0~2天为1级,3~4天为2级,5天为3级,6天或6天以上为4级。
表2-1数据保存在“DATA6-5.SAV”文件中。
1)准备分析数据在SPSS数据编辑窗口中,创建“年份”、“蛾量”、“卵量”、“降水量”、“雨日”和“幼虫密度”变量,并输入数据。
再创建蛾量、卵量、降水量、雨日和幼虫密度的分级变量“x1”、“x2”、“x3”、“x4”和“y”,它们对应的分级数值可以在SPSS数据编辑窗口中通过计算产生。
编辑后的数据显示如图2-1。
图2-1或者打开已存在的数据文件“DATA6-5.SAV”。
2)启动线性回归过程单击SPSS主菜单的“Analyze”下的“Regression”中“Linear”项,将打开如图2-2所示的线性回归过程窗口。
图2-2 线性回归对话窗口3) 设置分析变量设置因变量:用鼠标选中左边变量列表中的“幼虫密度[y]”变量,然后点击“Dependent”栏左边的向右拉按钮,该变量就移到“Dependent”因变量显示栏里。
SPSS多元回归分析实例(最新整理)

多元回归分析在大多数的实际问题中,影响因变量的因素不是一个而是多个,我们称这类回问题为多元回归分析。
可以建立因变量y与各自变量x j(j=1,2,3,…,n)之间的多元线性回归模型:其中:b0是回归常数;b k(k=1,2,3,…,n)是回归参数;e是随机误差。
多元回归在病虫预报中的应用实例:某地区病虫测报站用相关系数法选取了以下4个预报因子;x1为最多连续10天诱蛾量(头);x2为4月上、中旬百束小谷草把累计落卵量(块);x3为4月中旬降水量(毫米),x4为4月中旬雨日(天);预报一代粘虫幼虫发生量y(头/m2)。
分级别数值列成表2-1。
预报量y:每平方米幼虫0~10头为1级,11~20头为2级,21~40头为3级,40头以上为4级。
预报因子:x1诱蛾量0~300头为l级,301~600头为2级,601~1000头为3级,1000头以上为4级;x2卵量0~150块为1级,15l~300块为2级,301~550块为3级,550块以上为4级;x3降水量0~10.0毫米为1级,10.1~13.2毫米为2级,13.3~17.0毫米为3级,17.0毫米以上为4级;x4雨日0~2天为1级,3~4天为2级,5天为3级,6天或6天以上为4级。
表2-1x1 x2 x3 x4 y年蛾量级别卵量级别降水量级别雨日级别幼虫密度级别1960102241121 4.3121101 1961300144030.111141 196269936717.511191 196318764675417.1474554 1965431801 1.912111 19664222201010131 19678063510311.8232283 1976115124020.612171 197171831460418.4442454 19728033630413.4332263 19735722280213.224216219742641330342.243219219751981165271.84532331976461214017.515328319777693640444.7432444197825516510101112数据保存在“DATA6-5.SAV”文件中。
多元回归分析SPSS案例39328讲课讲稿

多元回归分析S P S S 案例39328多元回归分析在大多数的实际问题中,影响因变量的因素不是一个而是多个,我们称这类回问题为多元回归分析。
可以建立因变量y与各自变量x j(j=1,2,3,…,n)之间的多元线性回归模型:其中:b0是回归常数;b k(k=1,2,3,…,n)是回归参数;e是随机误差。
多元回归在病虫预报中的应用实例:某地区病虫测报站用相关系数法选取了以下4个预报因子;x1为最多连续10天诱蛾量(头);x2为4月上、中旬百束小谷草把累计落卵量(块);x3为4月中旬降水量(毫米),x4为4月中旬雨日(天);预报一代粘虫幼虫发生量y(头/m2)。
分级别数值列成表2-1。
预报量y:每平方米幼虫0~10头为1级,11~20头为2级,21~40头为3级,40头以上为4级。
预报因子:x1诱蛾量0~300头为l级,301~600头为2级,601~1000头为3级,1000头以上为4级;x2卵量0~150块为1级,15l~300块为2级,301~550块为3级,550块以上为4级;x3降水量0~10.0毫米为1级,10.1~13.2毫米为2级,13.3~17.0毫米为3级,17.0毫米以上为4级;x4雨日0~2天为1级,3~4天为2级,5天为3级,6天或6天以上为4级。
表2-1x1 x2 x3 x4 y年蛾量级别卵量级别降水量级别雨日级别幼虫密度级别1960 1022 4 112 1 4.3 1 2 1 10 1 1961 300 1 440 3 0.1 1 1 1 4 1 1962 699 3 67 1 7.5 1 1 1 9 1 1963 1876 4 675 4 17.1 4 7 4 55 4 1965 43 1 80 1 1.9 1 2 1 1 1 1966 422 2 20 1 0 1 0 1 3 1 1967 806 3 510 3 11.8 2 3 2 28 3 1976 115 1 240 2 0.6 1 2 1 7 1 1971 718 3 1460 4 18.4 4 4 2 45 4数据保存在“DATA6-5.SAV”文件中。
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
企业管理
对居民消费率影响因素的探究
---以湖北省为例改革开放以来,我国经济始终保持着高速增长的趋势,三十多年间综合国力得到显著增强,但我国居民消费率一直偏低,甚至一直有下降的趋势。
居民消费率的偏低必然会导致我国内需的不足,进而会影响我国经济的长期健康发展。
本模型以湖北省1995年-2010年数据为例,探究各因素对居民消费率的影响及多元关系。
(注:计算我国居民的消费率,用居民的人均消费除以人均GDP,得到居民的消费率)。
通常来说,影响居民消费率的因素是多方面的,如:居民总收入,人均GDP,人口结构状况1(儿童抚养系数,老年抚养系数),居民消费价格指数增长率等因素。
1.人口年龄结构一种比较精准的描述是:儿童抚养系数(0-14岁人口与 15-64岁人口的比值)、老年抚养系数(65岁及以上人口与15-64岁人口的比值〉或总抚养系数(儿童和老年抚养系数之和)。
0-14岁人口比例与65岁及以上人口比例可由《湖北省统计年鉴》查得。
一、计量经济模型分析
(一)、数据搜集
根据以上分析,本模型在影响居民消费率因素中引入6个解释变量。
X1:居民总收入(亿元),
X2:人口增长率(‰),X3:居民消费价格指数增长率,X4:少儿抚养系数,X5:老年抚养系数,X6:居民消费占收入比重(%)。
Y :消费率(%) X1:总收入(亿元) X2:人口增长率(‰) X3:居民消
费价格指
数增长率
X4:少儿抚养系数 X5:老年抚养系数 X6:居民消
费比重(%)
1995 51.96 1590.75 9.27 17.1 45.3 9.42 68.9 1997 50.35 2033.68 8.12 2.8 41.1 9.44 70.72 2000 44.96 2247.25 3.7 0.4 39 9.57 70.93 2001 45.54 2139.71 2.44 0.7 37.83 9.72 82.6 2002 46.32 2406.55 2.21 -0.4 36.18 9.81 81.09 2003 45.99 2594.61 2.32 2.2 34.43 9.87 84.33 2004 43.54 2660.11 2.4 4.9 32.69 9.8 92.2 2005 42.27 3172.41 3.05 2.9 31.09 9.73 87.8 2006 41.02 3538.4 3.13 1.6 30.17 9.9 88.3 2007 39.75 4168.52 3.23 4.8 29.46 10.04 88.99 2008 37.3 4852.58 2.71 6.3 28.62 10.1 87.07 2009 34.38 5335.54 3.48 -0.4 28.05 10.25 83.52 2010 32.5 6248.75 4.34 2.9 27.83 10.41 82.2
(二)、计量经济学模型建立
假定各个影响因素与Y 的关系是线性的,则多元线性回归模型为:
ε
βββββββ++++++=+6655443322110x x x x x x y t 利用spss 统计分析软件输出分析结果如下:
表1
这部分被结果说明在对模型进行回归分析时所采用的方法是全部引入法Enter 。
表3
X2 13 13 13 13 13 13 13 X3 13 13 13 13 13 13 13 X6 13 13 13 13 13 13 13 X5 13 13 13 13 13 13 13 X4
13
13
13
13
13
13
13
这部分列出了各变量之间的相关性,从表格可以看出Y 与X1的相关性最大。
且自变量之间也存在相关性,如X1与X5,X1与X4,相关系数分别为0.932和0.877,表明他们之间也存在相关性。
表4
这部分结果得到的是常用统计量,相关系数R=0.991,判定系数=0.982,调
整的判定系数=0.964,回归估计的标准误差S=1.09150。
说明样本的回归效
果比较好。
表5
ANOVA b
Model Sum of Squares
df
Mean Square
F Sig. 1
Regression 389.015 6 64.836 54.421
.000a
Residual 7.148 6 1.191
Total
396.163
12
a. Predictors: (Constant), X4, X3, X2, X6, X1, X5
b. Dependent Variable: Y
该表格是方差分析表,从这部分结果看出:统计量F=54.421,显著性水平的值P 值为0,说明因变量与自变量的线性关系明显。
Sum of Squares 一栏中分别代表回归平方和为389.015,、残差平方和7.148、总平方和为396.163.
Model Summary b Model R R Square
Adjusted R
Square
Std. Error of the
Estimate
Durbin-Watson
1
.991a
.982
.964
1.09150
2.710
a. Predictors: (Constant), X4, X3, X2, X6, X1, X5
b. Dependent Variable: Y
表6
该表格为回归系数分析,其中Unstandardized Coefficients为非标准化系数,Standardized Coefficients为标准化系数,t为回归系数检验统计量,Sig.为相伴概率值。
从表格中可以看出该多元线性回归方程:
Y=-33.364-0.006X
1+0.861X
2
+0.036X
3
+0.527X
4
+12.715X
5
-0.091X
6
+ε
二、计量经济学检验
(一)、多重共线性的检验及修正
①、检验多重共线性
从“表3 相关系数矩阵”中可以看出,个个解释变量之间的相关程度较高,所以应该存在多重共线性。
②、多重共线性的修正——逐步迭代法
运用spss软件中的剔除变量法,选择stepwise逐步回归。
输出表7:进入与剔除变量表。
可以看到进入变量为X1与X2.
表8:
表8是模型的概况,我们看到下图中标出来的五个参数,分别是负相关系数、决定系数、校正决定系数、随机误差的估计值和D-W值,这些值(除了随机误差的估计值,D-W越接近2越好)都是越大表明模型的效果越好,根据比较,第二个模型应该是最好的。
表9:方差分析表
方差分析表,四个模型都给出了方差分析的结果,这个表格可以检验是否所有偏回归系数全为0,sig值小于0.05可以证明模型的偏回归系数至少有一个不为零。
表10:参数检验
参数的检验,这个表格给出了对偏回归系数和标准偏回归系数的检验,偏回归系数用于不同模型的比较,标准偏回归系数用于同一个模型的不同系数的检验,其值越大表明对因变量的影响越大。
综上可得:模型2为最优模型。
得出回归方程
Y=52.497-0.004X1+0.056X2+ε
(二)、异方差的检验
输出残差图:如图1
从图1看出,e2并不随x的增大而变化,表明模型不存在异方差。
(三)、自相关检验--用D-W检验
由输出结果表8得:DW= 1.983,查表得DL=0.861 ,DU=1.562,
4-DU=2.438所以DU<DW<4-DU=2.438,因此误差项之间不存在自相关性。
(四)、统计检验
1.拟合优度检验:由表8相关系数R=0.988,判定系数=0.976,调整的判
定系数=0.971,回归估计的标准误差S=0。
9673。
说明样本的回归效果比较好。
2.F值检验:由表9F=202.632。
查表得,置信度为95%,自由度为1,12的F临
界值为4.474,F值远远大于临界值,则说明模型显著。
3.t检验
由表10,β0,β1,β2的t值分别问52.686,-17.599,4.293。
查表得,t检验的临界值为1.771。
说明回归方程对各个变量均有显著影响。
(五)、模型结果
因为最终进入模型的两个变量间不存在共线问题,各解释变量无异方差,D-W检验显示各误差项之间不存在自相关性。
Y =52.497-0.004X1+0.056X2+ε
三、经济意义检验
模型估计结果表明:
在假定其他解释变量不变的情况下,湖北居民总收入每增加1亿元其居民消费率降低0.004;在假定其他解释变量不变的情况下,人口增长率每提高1个千分点,居民消费率将增加0.056;
:。