SAS中的描述性统计过程
几种描述性统计分分析的SAS过程

几种描述性统计分分析的SAS过程描述性统计是统计学中的一种方法,用于总结和描述数据集的主要特征。
它有助于了解数据的整体分布、偏差和离散性等。
SAS(统计分析系统)是一种流行的统计软件,具有丰富的分析功能。
以下是几种常用的SAS过程,用于执行描述性统计分析。
1.PROCMEANS:PROCMEANS是一种计算统计指标的SAS过程,包括均值、总和、最小值、最大值、标准差等。
可以使用该过程对数值变量进行描述性统计,并在输出中显示这些统计指标。
可以通过指定多个变量和分组变量来计算针对不同子组的统计指标。
该过程还可以生成频数和百分比。
2.PROCFREQ:PROCFREQ是一种用于计算分类变量频数和百分比的SAS过程。
它可以计算每个类别的频数,并使用该信息生成频数表。
该过程还可以计算两个或更多分类变量之间的交叉频数表,并计算出每个类别的百分比。
3.PROCUNIVARIATE:PROCUNIVARIATE是一种用于执行单变量分析的SAS过程。
它可以计算变量的均值、标准差、峰度、偏度等统计指标。
该过程可以绘制直方图、箱线图、正态检验图和PP图等,以帮助理解数据的分布特征。
还可以执行分位数分析、离散度分析和异常值识别等。
4.PROCCORR:PROCCORR是一种用于计算变量之间相关性的SAS过程。
它可以计算变量间的皮尔逊相关系数,并使用协方差矩阵和相关系数矩阵来描述变量之间的线性关系。
该过程还可以绘制散点图矩阵和相关系数图,以直观地显示变量之间的关系。
5.PROCGLM:PROCGLM是一种用于执行多因素方差分析的SAS过程。
它可以根据自变量的水平和交互作用来分解因变量的方差,并进行显著性检验。
该过程可以计算组间差异的F值和p值,并生成方差分析表。
PROCGLM还支持使用协变量进行调整的方差分析,以控制对方差的影响。
以上是几种常用的SAS过程,用于执行描述性统计分析。
每个过程都有各自的功能和输出,可以根据数据和分析需求选择合适的过程。
SAS学习系列11.-对数据做简单的描述统计

11. 对数据做简单的描述统计(一)使用proc means描述数据用proc means过程步,可以对数据做简单的描述统计,包括:非缺省值个数、均值、标准差、最大值、最小值等。
基本语法:PROC MEANS data = 数据集<可选项>;V AR 变量列表;CLASS 分组变量;<BY 变量;><WEIGHT 变量;> (加权平均的权数)<FREQ 变量;> (相应观测出现的频数)说明:(1)可选项“MAXDEC = n”用来指定输出结果的小数位数;(2)默认是对数据集的所有数值变量的非缺省值做描述统计,若想包含缺省值,加上可选项“MISSING”;(3)V AR语句指定要做描述统计的变量;CLASS语句指定按分组变量对数据进行分组分别做描述统计;BY语句同CLASS语句(需要事先按BY变量排好序);(4)默认输出非缺省值个数、均值、标准差、最大值、最小值;也可以自己指定需要输出的描述统计量:MAX ——最大值;MIN——最小值;MEAN——均值;MEDIAN——中位数;MODE——众数;N——非缺省值个数;NMISS——缺省值个数;RANGE——极差;STDDEV——标准差;SUM——累和;例1 鲜花销售的数据(C:\MyRawData\Flowers.dat),变量包括顾客ID,销售日期,petunias,snapdragons,marigolds三种花的销量:读取数据,计算新变量销售月份month,并使用proc sort按照月份排序,并使用proc means的by语句来按照月份描述数据。
代码:data sales;infile'c:\MyRawData\Flowers.dat';input CustID $ @9SaleDate MMDDYY10.Petunia SnapDragon Marigold;Month = MONTH(SaleDate);proc sort data = sales;by Month;/* Calculate means by Month for flower sales; */proc means data = sales MAXDEC = 0;by Month;var Petunia SnapDragon Marigold;title'Summary of Flower Sales by Month';run;运行结果:(二)使用统计量有时候需要将统计量存入新数据集,以便进一步做数据分析,或者与原数据集合并。
sas第八章 描述性统计过程
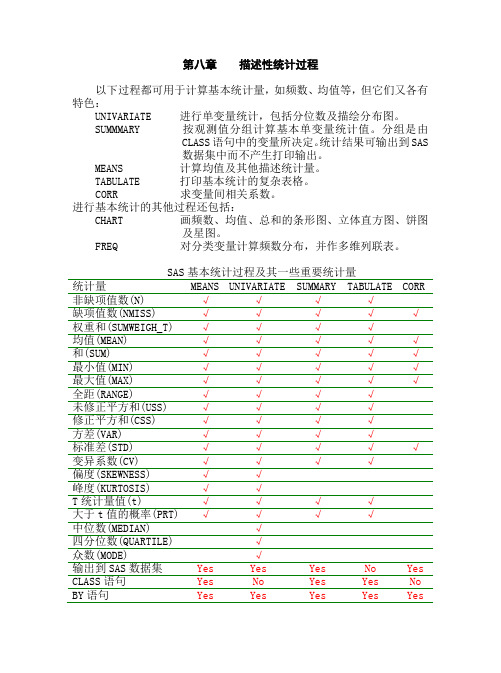
第八章描述性统计过程以下过程都可用于计算基本统计量,如频数、均值等,但它们又各有特色:UNIVARIATE 进行单变量统计,包括分位数及描绘分布图。
SUMMMARY 按观测值分组计算基本单变量统计值。
分组是由CLASS语句中的变量所决定。
统计结果可输出到SAS数据集中而不产生打印输出。
MEANS 计算均值及其他描述统计量。
TABULATE 打印基本统计的复杂表格。
CORR 求变量间相关系数。
进行基本统计的其他过程还包括:CHART 画频数、均值、总和的条形图、立体直方图、饼图及星图。
FREQ 对分类变量计算频数分布,并作多维列联表。
SAS基本统计过程及其一些重要统计量统计量MEANS UNIVARIATE SUMMARY TABULATE CORR 非缺项值数(N) √√√√缺项值数(NMISS) √√√√√权重和(SUMWEIGH_T) √√√√均值(MEAN) √√√√√和(SUM) √√√√√最小值(MIN) √√√√√最大值(MAX) √√√√√全距(RANGE) √√√√未修正平方和(USS) √√√√修正平方和(CSS) √√√√方差(VAR) √√√√标准差(STD) √√√√√变异系数(CV) √√√√偏度(SKEWNESS) √√峰度(KURTOSIS) √√T统计量值(t) √√√√大于t值的概率(PRT) √√√√中位数(MEDIAN) √四分位数(QUARTILE) √众数(MODE) √输出到SAS数据集Yes Yes Yes No Yes CLASS语句Yes No Yes Yes No BY语句Yes Yes Yes Yes Yes第一节 MEANS 过程MEANS过程对数值变量给出简单的描述性统计。
例: 数据集SCORE含有学生三门课程的成绩(见SORT过程),用MEANS 过程可得到: PROC MEANS DATA=SCORE;MEANS过程由下列语句控制:PROC MEANS [选择项];VAR 变量表;BY 变量表;CLASS 变量表;FREQ 变量;WEIGHT 变量;ID 变量表;OUTPUT [选择项];除PROC语句之外的其他语句均为可选语句。
SAS数据分析常用操作指南

SAS数据分析常用操作指南在当今数据驱动的时代,数据分析成为了企业决策、科学研究等领域的重要手段。
SAS 作为一款功能强大的数据分析软件,被广泛应用于各个行业。
本文将为您介绍 SAS 数据分析中的一些常用操作,帮助您更好地处理和分析数据。
一、数据导入与导出数据是分析的基础,首先要将数据导入到 SAS 中。
SAS 支持多种数据格式的导入,如 CSV、Excel、TXT 等。
以下是常见的导入方法:1、通过`PROC IMPORT` 过程导入 CSV 文件```sasPROC IMPORT DATAFILE='your_filecsv'OUT=your_datasetDBMS=CSV REPLACE;RUN;```在上述代码中,将`'your_filecsv'`替换为实际的 CSV 文件路径,`your_dataset` 替换为要创建的数据集名称。
2、从 Excel 文件导入```sasPROC IMPORT DATAFILE='your_filexlsx'OUT=your_datasetDBMS=XLSX REPLACE;RUN;```导出数据同样重要,以便将分析结果分享给他人。
可以使用`PROC EXPORT` 过程将数据集导出为不同格式,例如:```sasPROC EXPORT DATA=your_datasetOUTFILE='your_filecsv'DBMS=CSV REPLACE;RUN;```二、数据清洗与预处理导入的数据往往存在缺失值、异常值等问题,需要进行清洗和预处理。
1、处理缺失值可以使用`PROC MEANS` 过程查看数据集中变量的缺失情况,然后根据具体情况选择合适的处理方法,如删除包含缺失值的观测、用均值或中位数填充等。
2、异常值检测通过绘制箱线图或计算统计量(如均值、标准差)来检测异常值。
对于异常值,可以选择删除或进行修正。
3、数据标准化/归一化为了消除不同变量量纲的影响,常常需要对数据进行标准化或归一化处理。
SAS的基本统计分析

SAS的基本统计分析SAS(统计分析系统)是一种广泛使用的统计分析软件,被广泛应用于数据分析和建模。
它提供了各种强大的统计分析功能,包括描述性统计、推断统计、回归分析、多元分析等。
在本文中,我们将介绍SAS的一些基本统计分析功能。
1.描述性统计分析:描述性统计是对数据集的基本特征进行分析和总结。
SAS提供了各种描述性统计分析功能,包括计算均值、中位数、百分位数、方差、标准差等。
例如,我们可以使用SAS的`MEANS`过程计算数据集中的变量的均值和标准差。
2.推断统计分析:推断统计分析是根据样本数据推断总体的参数估计和假设检验。
SAS提供了一系列的推断统计分析功能,包括参数估计、置信区间估计、假设检验等。
例如,我们可以使用SAS的`TTEST`过程进行两个样本的t检验,或者使用`ANOV`过程进行方差分析。
3.回归分析:回归分析用于研究自变量与因变量之间的关系,并建立预测模型。
在SAS中,我们可以使用`REG`过程进行回归分析。
该过程提供了许多回归模型,如一元线性回归、多元线性回归、逻辑回归等。
我们可以通过回归分析来了解变量之间的关系,发现影响因变量的重要因素,并进行预测。
4.多元分析:多元分析是一种分析多个自变量对因变量的影响的方法。
SAS提供了多种多元分析的方法,如多元方差分析(MANOVA)、主成分分析(PCA)、因子分析等。
我们可以使用SAS的`GLM`过程进行多元方差分析,或者使用`FACTOR`过程进行因子分析。
5.时间序列分析:时间序列分析是一种对时间相关数据进行建模和预测的方法。
SAS提供了一些时间序列分析的功能,如自回归移动平均模型(ARMA)、自回归积分移动平均模型(ARIMA)等。
我们可以使用SAS的`ARIMA`过程进行时间序列分析,拟合ARIMA模型并进行预测。
6.非参数统计分析:非参数统计分析是一种不需要对总体进行任何假设的统计分析方法。
SAS提供了一些非参数统计分析的功能,如Wilcoxon秩和检验、Kruskal-Wallis检验等。
Ch5 SAS基本统计过程 mean uni ttest npar

DF 16 13.8
t Value Pr > |t| 1.81 0.0885 1.85 0.0859
看此表之前应先看下面的方差齐性检验表,由于两组资料 总体方差齐同( P=0.8735,两组资料总体方差齐同),故看 “Equal”一行的结果 :t=1.81,p=0.0885;如果方差不齐, 则看“Unequal”一行的结果。
PROC MEANS [options] [statistics-keywords]; VAR variables; CLASS variables;
该过程除PROC语句(下划线部分)是必须的外,其它的语 句都是可选的。
彭斌
Slide 2
1).PROC MEANS语句
PROC MEANS [options] [statistic-keywords];
彭斌
Slide 17
绘制直方图
➢ 程序语句: PROC UNIVARIATE data= student; Histogram height ; RUN;
➢ 语句选项: 1、拟合正态曲线 Histogram height / normal ; 2、指定直方图的组中值 Histogram height / midpoints=35 40 45 50 55 60 65 70;
左边表中是对应的百分位数;上面表中是极值情况, 列出 5个最大值和5个最小值.
彭斌
Slide 15
(2) 用univariate过程对身高变量进行正态性检验 程序如下: PROC UNIVARIATE data= student normal; VAR height ; RUN;
在这PROC语句中添加选项“normal”即可。
彭斌
Slide 12
SAS描述性统计

统计程式
MEANS过程 MEANS过程
统计程式
例题4.1,进入SAS的显示管理系统,在编辑窗口输入程式: 例题4.1,进入SAS的显示管理系统,在编辑窗口输入程式: 4.1,进入SAS的显示管理系统 ex; 9;输入一个数据集,其中一个变量长度为9 data ex;length name$ 9;输入一个数据集,其中一个变量长度为9 t1- @@; input name sex$ group$ t1-t3 @@;将数据行中的数分别赋给几个变量 Cards; Cards; wangdong 1 1 90 70 60 xueping 2 2 85 95 88 输入一组数据行 让其他SAS SAS语句使用 zhouhua 1 1 77 84 69 heyan 1 2 95 78 88 让其他SAS语句使用 hufang 1 2 78 77 69 zhangqun 1 1 93 91 89 ; maxdec=2;将数据集EX EX中的观测值进行简单描述性统计 proc means maxdec=2;将数据集EX中的观测值进行简单描述性统计 t1-t3; group;按组别将t1 t2、t3中的值分类统计 t1、 var t1-t3;class group;按组别将t1、t2、t3中的值分类统计 maxdec=4; proc means mean std cv maxdec=4;需要描述的变量 t1-t3; group;run; 按组别将t1 t2、t3值的分析结果打印 t1、 var t1-t3; class group;run; 按组别将t1、t2、t3值的分析结果打印
统计程式
MEANS过程 MEANS过程
统计程式
例题4.3,进入SAS的显示管理系统,在编辑窗口输入程式: 例题4.3,进入SAS的显示管理系统,在编辑窗口输入程式: 4.3,进入SAS的显示管理系统 ex; @@;d=xdata ex; input x y @@;d=x-y; Cards; Cards; 11.3 15 15 13.5 12.8 10 11 12 13 12.3 14 13.8 14 13.5 13.5 12 14.7 11.4 13.8 12 ; std; y; proc means n mean std; var x y; prt; d;run; proc means n mean std t prt; var d;run; 程式中的第一个proc means作 的简单的描述性统计, 程式中的第一个proc means作x与y的简单的描述性统计, 第二个proc means作 的总体均值差为0的显著性检验。 第二个proc means作x与y的总体均值差为0的显著性检验。
sas描述性统计分析

28
27
26
散点图
25
24
23
22
21 女 20 1900 1920 1940 1960 1980 2000 男
定性变量的图表示:饼图 定性变量(或属性变量,分类变量 )不能点出直方图、散点图或茎 叶图,但可以描绘出它们各类的 比例。
饼图
定性变量的图表示:条形图
从每一条可以看出讲各种语言的 实际人数,而且分别给出了每 个语种中母语和日常使用的人 数(在图中并排放置)。条形 图显示比例不如饼图直观。
数据的“尺度”
另一个常用的尺度统计量为(样本)标 准差 (standard deviation) 。度量样 本中各数值到均值距离的一种平均。 标准差实际上是方差 (variance) 的平方 根。如果记样本中的观测值为 x1,…,xn,则样本方差为
数据的“尺度”
两个均值一样,但右边的要 “胖”些,方差为左边的一 倍
描述性统计分析
East China JiaoTong University
如 同 给 人 画 像 一 样
数 据 的 描 述
在对数据进行深入加工之前,总 应该对数据有所印象。 可以借助于图形和简单的运算, 来了解数据的一些特征。 由于数据是从总体中产生的,其 特征也反映了总体的特征。对 数据的描述也是对其总体的一 个近似的描述。
其中茎叶图中茎的单位为10cm,而叶子单位为1cm。比如,由于 第一行茎为150cm,因此叶子中的九个数字001223344代表九个数 目150、150、151、152、152、153、153、154、154cm等。每 行左边有一个频数(比如第一行有9个数目,第二行有17个等等); 可以看出最长的一行为从165cm到169cm的一段(有35个数)。
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
SAS中的描述性统计过程(2012-08-01 18:07:01)▼分类:数据分析挖掘标签:杂谈SAS中的描述性统计过程描述性统计指标的计算可以用四个不同的过程来实现,它们分别是means过程、summary过程、univariate过程以及tabulate过程。
它们在功能范围和具体的操作方法上存在一定的差别,下面我们大概了解一下它们的异同点。
相同点:他们均可计算出均数、标准差、方差、标准误、总和、加权值的总和、最大值、最小值、全距、校正的和未校正的离差平方和、变异系数、样本分布位置的t检验统计量、遗漏数据和有效数据个数等,均可应用by语句将样本分割为若干个更小的样本,以便分别进行分析。
不同点:(1)means过程、summary过程、univariate过程可以计算样本的偏度(skewness)和峰度(kurtosis),而tabulate过程不计算这些统计量;(2)univariate过程可以计算出样本的众数(mode),其它三个过程不计算众数;(3)summary过程执行后不会自动给出分析的结果,须引用output语句和print过程来显示分析结果,而其它三个过程则会自动显示分析的结果;(4)univariate过程具有统计制图的功能,其它三个过程则没有;(5)tabulate过程不产生输出资料文件(存储各种输出数据的文件),其它三个均产生输出资料文件。
统计制图的过程均可以实现对样本分布特征的图形表示,一般情况下可以使用的有chart过程、plot过程、gchart过程和gplot过程。
大家有没有发现前两个和后两个只有一个字母‘g’(代表graph)的差别,其实它们之间(只差一个字母g的过程之间)的统计描述功能是相同的,区别仅在于绘制出的图形的复杂和美观程度。
chart过程和plot过程绘制的图形类似于我们用文本字符堆积起来的图形,只能概括地反映出资料分布的大体形状,实际上这两个过程绘制的图形并不能称之为图形,因为他根本就没有涉及一般意义上图形的任何一种元素(如颜色、分辨率等)。
而gchart过程和gplot过程给出的是真正意义上的图形,可以用很多的语句和选项来控制图形的各方面的性质和特征。
chart和gchart与plot和gplot的区别则体现在不同的作图功能,前两个过程可以绘制出的图形主要有条形图(包括横条和竖条)、圆图、环形图和星形图等,后两个过程通常用一个记录中的两个变量值表示点的坐标来绘制图形,如散点图和线图等。
描述性统计过程的一般格式1. means过程的一般格式proc means选项列表;by变量名称(分组变量);class变量名称(分组变量);freq变量名称(数值变量,用以表示相应记录出现的频数)weight变量名称(数值变量,用以表示相应记录的权重系数)var变量名称(待分析的数值变量);run;Proc means语句后的选项主要用来指定所要计算的统计量,默认情况下,Means过程会给出频数、均数、标准差、最大值和最小值等,其余统计量的计算均需要在选项中指定。
class语句所指定的分组变量用来进行分组,而by语句所指定的分组变量是用来将数据分为若干个更小的样本,以便SAS分别在各小样本内进行各自独立的处理。
freq语句和weight语句分别引导代表记录出现频数和权重系数的数值变量。
var语句引导所要进行分析的所有变量的列表,SAS将对var语句所引导的所有变量分别进行描述性统计分析。
summary过程的一般格式proc summary选项列表;by变量名称(分组变量);class变量名称(分组变量);freq变量名称(数值变量,用以表示相应记录出现的频数)weight变量名称(数值变量,用以表示相应记录的权重系数)output <out=数据集名> <统计量关键字=自定义变量名>var变量名称(待分析的数值变量);run;summary过程的格式和means过程可以说是完全相同的,各条语句和选项的含义也是相同的,包括在means过程中未列出的output语句也可以应用于means过程,只是此语句在summary过程应用较多(这样才能将分析结果显示出来),所以才将其列入一般格式中。
output语句用来对分析结果输出为数据文件进行控制,其后的选项可有可无,若无则SAS按照默认方式进行。
“out=数据集名”用来定义输出数据文件的文件名称,文件名的格式和数据步中数据文件名相同。
“统计量关键字=自定义变量名”用来自定义输出数据文件中各种统计量的变量名称,前者是系统定义的(和proc语句后选项中的统计量关键字完全相同),必须正确无误,后者可自行定义。
默认状态下输出统计量只有频数、均数、标准差、最大值和最小值,在默认状态不能满足需要时这一选项则是必需的。
univariate过程的一般格式proc univariate选项列表;by变量名称(分组变量);class变量名称(分组变量);freq变量名称(数值变量,用以表示相应记录出现的频数)weight变量名称(数值变量,用以表示相应记录的权重系数)histogram变量名称/选项列表output <out=数据集名> <统计量关键字=自定义变量名>pctlpts=<百分位数…><指定需要的百分位数>pctlpre=<新变量名列><指定所需百分位数对应的输出变量名>var变量名称(待分析的数值变量);run;univariate过程和以上两个过程的格式非常相似,相同的语句和选项其含义也相同,所不同的是某些统计量只能在univariate过程中计算(如众数),以及univariate过程中所具有的绘图功能。
histogram 语句即用来指示SAS对其后所指定的变量绘制直方图,其后的选项用来指示SAS添加不同类型的拟合图形(如正态分布的分布密度曲线)。
tabulate过程的一般格式proc tabulate选项列表;by变量名称(分组变量);class变量名称(分组变量);freq变量名称(数值变量,用以表示相应记录出现的频数)weight变量名称(数值变量,用以表示相应记录的权重系数)table <<页变量表达式>,<行变量表达式>,<列变量表达式>></表格选项>var变量名称(待分析的数值变量,统计量列入相应的表单元格);run;tabulate过程和上述几个过程的格式也基本相似,相同的语句和选项也代表相同的含义。
最大的不同也是tabulate过程中最为重要的是table语句,他用来定义表格的具体格式以及表格中所要包括的统计量。
gchart过程的一般格式proc gchart选项列表;图形关键词变量名称/选项列表run;proc gplot选项列表;bubble散点图表达式bubble2散点图表达式plot散点图表达式plot2散点图表达式run;从gplot过程的一般格式中我们就可看出,此过程只能绘制两种类型的图形,bubble语句指示SAS绘制泡状散点图,plot语句指示SAS绘制点状散点图。
bubble2语句和plot2语句指示SAS在同一区域内(bubble2和bubble在同一区域,plot2和plot在同一区域)绘制第二个图形,两者的横坐标相同(同一变量),纵坐标分别位于左右两侧(可以是同一变量,也可以是两个不同的变量)。
散点图表达式的一般形式为:(1)bubble和bubble2语句:纵坐标变量名*横坐标变量名=泡尺寸变量名(变量值以泡的大小表示),三者均应为数值变量;(2)plot和plot2语句:纵坐标变量名*横坐标变量名<=n/分类变量名>,此处等号及其后的部分可以省略,此时SAS以默认的散点类型绘制散点图;若等号后为n(n为正整数,是散点类型的编号),SAS则以指定的编号对应的散点类型绘制散点图;若等号后为分类变量名(可为字符型或数值型,为数值型时作为离散型变量处理,每一个值将被当作一个类别),此变量的具体值(或与每个具体值对应的图形)将被作为散点用来绘制散点图。
chart过程和plot过程的一般格式及各选项使用方法分别与gchart过程和gplot过程是基本相同的,不同之处仅在于后两者中涉及到有关三维和图形元素(颜色等)的语句和选项在前两者中是无效的。
例如vbar3d语句在chart过程中无效,bubble语句在plot过程中无效。
其余的语句和选项使用方法完全相同,所以在掌握了gchart过程和gplot过程后,chart过程和plot过程你会不学自通。
(三)描述性统计关键字及其含义SAS中可计算的描述性统计量多达二十余种,大部分可在以上介绍的前四个过程中计算,个别统计量在某些过程中不能计算,大家需要注意,要不然系统显示错误信息时还不知道是怎么回事。
我经常遇到这种情况,系统提示错误(此类提示信息显示在log窗口中)时总是摸不着头脑,费半天劲才能搞明白。
没办法,摸着石头过河嘛!不过这样也并非一无是处,最起码可以积累很多使用经验。
下表(表2.2)列出SAS中可以计算的所有描述性统计量关键字及其含义,供大家使用时参考。
表2.2 SAS中可以计算的描述性统计量关键字及其含义关键字所代表的含义n 有效数据记录数.. . nmiss 缺失数据记录数mean 均数std 标准差stderr 标准误var 方差median 中位数mode 众数cv 变异系数max 最大值min 最小值range 全距sum 总计sumwgt 加权值总计css 校正的离均差平方和uss 未校正的离均差平方和clm 可信限(上下界值)lclm 可信限下侧界值uclm 可信限上侧界值skew(skewness)偏度kurt(kurtosis)峰度t 分布位置假设检验之t统计量probt 上述t统计量对应的概率值.. .q1 第一四分位数q3 第三四分位数qrange 四分位数间距p1 第一百分位数p5 第五百分位数p10 第十百分位数p90 第九十百分位数p95 第九十五百分位数p99 第九十九百分位数分享:。