eviews面板数据实例分析(包会)
EVIEWS面板数据分析操作教程及实例解析

模型选择对分析结果影响
模型适用性
根据研究目的和数据特征选择合 适的面板数据模型,如固定效应 模型、随机效应模型等。
模型假设
确保所选模型满足基本假设,如 线性关系、误差项独立同分布等 ,否则可能导致结果不准确。
模型比较与选择
通过比较不同模型的拟合优度、 参数显著性等指标,选择最优模 型进行分析。
操作规范性与结果可靠性保障措施
操作步骤规范
结果验证与解读
对分析结果进行验证,确保结果的合理性和准确性 ;同时,正确解读分析结果,避免误导读者。
严格按照EVIEWS软件的操作步骤进行分析 ,避免操作失误或遗漏关键步骤。
数据分析报告
编写详细的数据分析报告,包括数据来源、 处理方法、模型选择、分析结果及解读等, 以便读者全面了解分析过程。
方和来估计模型参数。
广义最小二乘法(GLS)
02
当存在异方差性或自相关性时,采用广义最小二乘法进行参数
估计,以提高估计效率。
最大似然法(ML)
03
适用于随机效应模型等复杂面板数据模型,通过最大化似然函
数来估计模型参数。
模型诊断与检验
残差分析
检查残差是否满足独立同分布等假设条件, 以评估模型的拟合效果。
07 EVIEWS面板数 据分析操作注意 事项
数据质量对分析结果影响
数据来源
确保数据来自可靠、权威的来源,避免使用不准确或存在偏见的数 据。
数据完整性
检查数据是否存在缺失值、异常值或重复值,这些问题可能导致分 析结果失真。
数据处理
对数据进行适当的预处理,如清洗、转换和标准化,以提高数据质量 和一致性。
增强了解决实际问题的能力
通过实例解析和操作演示,学员们学会了如何运用所学知识解决实际问题,提高了分析 问题和解决问题的能力。
详细EVIEWS面板数据分析操作37页PPT

25、学习是劳动,是充满思想的劳动。——乌申斯基
谢谢!
详细EVIEWS面板数据分析操作
31、园日涉以成趣,门虽设而常关。 32、鼓腹无所思。朝起暮归眠。 33、倾壶绝余沥,窥灶不见烟。
34、春秋满四泽,夏云多奇峰,秋月 扬明辉 ,冬岭 秀孤松 。 35、丈夫志四海,我愿不知老。
Hale Waihona Puke 21、要知道对好事的称颂过于夸大,也会招来人们的反感轻蔑和嫉妒。——培根 22、业精于勤,荒于嬉;行成于思,毁于随。——韩愈
使用Eviews进行面板数据操作(有图有真相)

(1)建立混合数据型工作文件
1. 建立一个年度工作文件(1996-2002).(file:)
① file ——new—— workfile——object——new object——pool——OK
1 2
② 在弹出的对话框中输入截面个体的名称缩写——点击sheet,输入变量名
注意:由于无法输入个体名称, 容易产生混乱,因此不建议使用 该方法建立面板数据。
方法一:
① 在变量截面中按住ctrl键,依次选择每个个体的因变量和自变量,点击右键, 选择open——as group,在打开的数据窗口中选择view——graph
② 在弹出的对话框中选择scatter——在multiple中选择single graph-XY pairs OK便可得如下的散点图
在估计结果中点击proc——Make Model可以出现估计结果的联立方 程形式,进一步点击Solve键可以 在弹出的对话框中进行动态和静态 预测。
在估计结果或原始的面包数据窗口中点击view——unit root test
这里默认为 Schwarz检 验,因为在 小样本情况 下Schwarz 检验效果最 好。
GLS权重,通过加 权可以克服异方差
每个个体有共
同的参数 bi
bi 随个体不
同而发生
变
变化
参
数
bi 随个体不 同而发生
模 型
变化
下面为个体固定效应的结果。 点击view——representation可以显示具体的回归方程式。
2. 面板数据的检验
① Hausman检验(要在随机效应结果窗口中进行) 对数据进行随机效应模型估计,在估计结果窗口点击view——Fixed/Random Effects testing——Correlated Random Effect-Hausman Test(6.0以上的 版本才可以)
Eviews案例解析
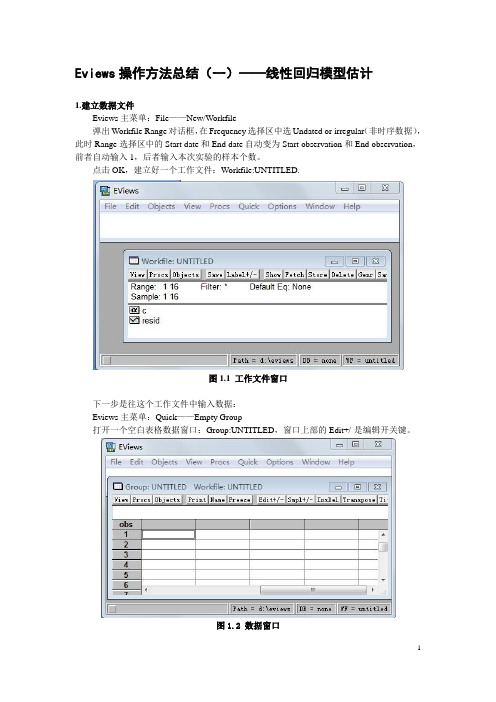
Eviews操作方法总结(一)——线性回归模型估计1.建立数据文件Eviews主菜单:File——New/Workfile弹出Workfile Range对话框,在Frequency选择区中选Undated or irregular(非时序数据),此时Range选择区中的Start date和End date自动变为Start observation和End observation,前者自动输入1,后者输入本次实验的样本个数。
点击OK,建立好一个工作文件:Workfile:UNTITLED.图1.1 工作文件窗口下一步是往这个工作文件中输入数据:Eviews主菜单:Quick——Empty Group打开一个空白表格数据窗口:Group:UNTITLED,窗口上部的Edit+/-是编辑开关键。
图1.2 数据窗口数据表的一行表示一个样本,一列代表一个变量,一般把被解释变量(如Y)放在第一列。
例子:图1.3 数据编辑状态2.画散点图Eviews主菜单:Quick——Graph/Scatter弹出Series List对话框,要求输入画图所用的变量名,对3.1以上版本,应先输入解释变量名,后输入被解释变量名,中间用空格隔开。
图1.4 作图变量输入窗口点OK,得散点图:图1.5 散点图3.OLS(普通最小二乘法)估计,以及线性回归模型的建立与检验Eviews主菜单:Quick——Estimate Equation弹出Equation Specification(方程设定)对话框,依次输入被解释变量Y,系数C(实际的方程中应该包括截距项和斜率项,而软件默认该变量的输出结果为截距项),解释变量X,中间用空格隔开。
在Estimation Setting(估计设定)选择框中,Method框选择LS-Least Squares(NLS and ARMA),Sample框默认为1 16(即样本个数)。
图1.6 方程设定窗口点OK,得方程的估计结果输出表:图1.7 估计结果输出表窗口对应的回归表达式:y i=−0.762928+0.40428x i(-0.624856)(12.11266)R2=0.91289, S.E.=2.036319 上式还可以从图1.7的V iew——Presentation得到:图1.8 回归方程窗口按Stats键可以还原回图1.7的估计结果输出表,按Estimate键可以随时改变估计模型的数学形式、样本范围和估计方法。
eviews面板数据实例分析包会修订版

e v i e w s面板数据实例分析包会修订版IBMT standardization office【IBMT5AB-IBMT08-IBMT2C-ZZT18】1.已知1996—2002年中国东北、华北、华东15个省级地区的居民家庭人均消费(cp,不变价格)和人均收入(ip,不变价格)居民,利用数据(1)建立面板数据(panel data)工作文件;(2)定义序列名并输入数据;(3)估计选择面板模型;(4)面板单位根检验。
年人均消费(consume)和人均收入(income)数据以及消费者价格指数(p)分别见表9.1,9.2和9.3。
表9.1 1996—2002年中国东北、华北、华东15个省级地区的居民家庭人均消费(元)数据199719981999200020012002人均消费1996CONSUMEAH3607.433693.553777.413901.814232.984517.654736.52 CONSUMEBJ5729.526531.816970.837498.488493.498922.7210284.6 CONSUMEFJ4248.474935.955181.455266.695638.746015.116631.68 CONSUMEHB3424.354003.713834.434026.34348.474479.755069.28 CONSUMEHLJ3110.923213.423303.153481.743824.444192.364462.08 CONSUMEJL3037.323408.033449.743661.684020.874337.224973.88CONSUMEJS4057.54533.574889.435010.915323.185532.746042.6 CONSUMEJX2942.113199.613266.813482.333623.563894.514549.32 CONSUMELN3493.023719.913890.743989.934356.064654.425342.64 CONSUMENMG2767.843032.33105.743468.993927.754195.624859.88 CONSUMESD3770.994040.634143.964515.0550225252.415596.32 CONSUMESH6763.126819.946866.418247.698868.199336.110464 CONSUMESX3035.593228.713267.73492.983941.874123.014710.96 CONSUMETJ4679.615204.155471.015851.536121.046987.227191.96 CONSUMEZJ5764.276170.146217.936521.547020.227952.398713.08表9.2 1996—2002年中国东北、华北、华东15个省级地区的居民家庭人均收入(元)数据人均收入1996199719981999200020012002INCOMEAH4512.774599.274770.475064.65293.555668.86032.4 INCOMEBJ7332.017813.168471.989182.7610349.6911577.7812463.92 INCOMEFJ5172.936143.646485.636859.817432.268313.089189.36 INCOMEHB4442.814958.675084.645365.035661.165984.826679.68 INCOMEHLJ3768.314090.724268.54595.144912.885425.876100.56 INCOMEJL3805.534190.584206.644480.0148105340.466260.16 INCOMEJS5185.795765.26017.856538.26800.237375.18177.64 INCOMEJX3780.24071.324251.424720.585103.585506.026335.64 INCOMELN4207.234518.14617.244898.615357.795797.016524.52 INCOMENMG3431.813944.674353.024770.535129.055535.896051 INCOMESD4890.285190.795380.085808.966489.977101.087614.36 INCOMESH8178.488438.898773.110931.6411718.0112883.4613249.8INCOMESX3702.693989.924098.734342.614724.115391.056234.36 INCOMETJ5967.716608.397110.547649.838140.58958.79337.56 INCOMEZJ6955.797358.727836.768427.959279.1610464.6711715.6表9.3 1996—2002年中国东北、华北、华东15个省级地区的消费者物价指数物价指数1996199719981999200020012002PAH109.9101.310097.8100.7100.599PBJ111.6105.3102.4100.6103.5103.198.2PFJ105.9101.799.799.1102.198.799.5PHB107.1103.598.498.199.7100.599PHLJ107.1104.4100.496.898.3100.899.3PJL107.2103.799.29898.6101.399.5(1)建立面板数据工作文件首先建立工作文件。
使用Eviews进行面板数据操作(有详图,包括Hausman检验,单位根检验)

每个个体有共
同的参数 bi
bi 随个体不
同而发生
变
变化
参
数
bi 随个体不 同而发生
模 型
变化
下面为个体固定效应的结果。 点击view——representation可以显示具体的回归方程式。
2. 面板数据的检验
① Hausman检验(要在随机效应结果窗口中进行) 对数据进行随机效应模型估计,在估计结果窗口点击view——Fixed/Random Effects testing——Correlated Random Effect-Hausman Test(6.0以上的 版本才可以)
⑤ 在打开的数据组中点击view——graph——scatter——simple scatter, 便可得到不同时间的散点图。
⑥ 同理,按ctrl键,分别选择ip_i, ip_ah,I p_bj, ip_hb…便可得到不同个体 的散点图。
由于是用同一组数据画出的图形,所以虽然采用的 是不同的方法,但是绘出的两个图形一样。
在估计结果中点击proc——Make Model可以出现估计结果的联立方 程形式,进一步点击Solve键可以 在弹出的对话框中进行动态和静态 预测。
在估计结果或原始的面包数据窗口中点击view——unit root test
这里默认为 Schwarz检 验,因为在 小样本情况 下Schwarz 检验效果最 好。
注意:只有在随机效应估计窗口中才能 进行Hausman检验,只有在固定效应估 计窗口中才能进行似然比检验
Hausman检验的原假设是个体效 应与回归变量无关,应建立随机效 应模型,因此当Hausman值较大, 其对应的P值远小于0.05时,拒绝
详细的EVIEWS面板数据分析操作39页PPT
谢谢!
详细的EVIEWS面板数据分析操作
•
46、寓形宇内复几时,曷不委心任去 留。
•
47、采菊东篱下,悠然见南山。
•
48、啸傲东轩下,聊复得此生。
•
49、勤学如春起之苗,不见其增,日 有所长 。
•
Байду номын сангаас
50、环堵萧然,不蔽风日;短褐穿结 ,箪瓢 屡空, 晏如也 。
61、奢侈是舒适的,否则就不是奢侈 。——CocoCha nel 62、少而好学,如日出之阳;壮而好学 ,如日 中之光 ;志而 好学, 如炳烛 之光。 ——刘 向 63、三军可夺帅也,匹夫不可夺志也。 ——孔 丘 64、人生就是学校。在那里,与其说好 的教师 是幸福 ,不如 说好的 教师是 不幸。 ——海 贝尔 65、接受挑战,就可以享受胜利的喜悦 。——杰纳勒 尔·乔治·S·巴顿
eviews面板数据实例分析(包会)-
eviews面板数据实例分析(包会)-Eviews是一种流行的面板数据分析软件,广泛用于经济学及财务学领域。
本文将以一个面板数据实例为例,介绍Eviews的一些基本功能及应用。
数据说明本数据集为横截面面板数据,共包含11个国家(美国、加拿大、英国、法国、德国、意大利、荷兰、比利时、奥地利、瑞典、日本)在1970年至1986年间的年度数据。
变量说明如下:- gdpercap:人均GDP- invest:投资/GDP比率- consump:消费/GDP比率- inflation:通货膨胀率- popgrowth:人口增长率- literacy:成年人识字率- female:女性劳动力占比数据导入及面板设置首先,在Eviews中新建一个工作文件,并将数据导入。
打开数据文件后,我们可以看到数据已经被正确读入。
然后,我们需要将数据设为面板数据。
在Eviews中,选择“View”菜单下的“Structure of Workfile”选项,可以进入工作文件结构设置。
在弹出的窗口中,选择“Panel Data”选项,并按照数据的属性设置面板变量。
在本例中,我们选择“Country”作为单位维度,“Year”作为时间维度。
设置完成后,Eviews会自动进行面板数据检测。
检测结果显示,数据格式符合面板数据要求。
面板数据描述及汇总统计接下来,我们可以对数据进行初步的描述性统计和汇总统计。
选择“Quick”菜单下的“Descriptive Stats”选项,Eviews会自动生成数据的描述性统计报告,展示各变量在不同国家和不同年份的均值、标准差、最小值、最大值等基本信息。
我们也可以手动计算其他统计量。
例如,选择“Proc”菜单下的“Panel Data”选项,可以对选定的变量进行面板数据汇总统计。
下面是在Eviews中计算人均GDP和消费/GDP比率两个变量的面板均值统计结果:面板数据变量之间的相关性分析在分析面板数据时,我们通常需要考虑不同变量之间的相关性。
eviews面板数据回归分析步骤
eviews面板数据回归分析步骤EViews面板数据回归分析步骤面板数据回归分析是一种常用的经济学研究方法,可以帮助研究人员探究变量之间的关系。
EViews是一种统计软件,提供了丰富的功能来进行面板数据回归分析。
本文将介绍EViews中面板数据回归分析的基本步骤。
第一步:数据准备在进行面板数据回归分析之前,首先需要准备好需要分析的数据集。
在EViews中,可以使用多种方式导入数据,包括从Excel或其他文件格式导入,或者直接在EViews中创建数据。
第二步:设置数据类型在导入或创建数据后,需要将数据设置为面板数据类型。
面板数据包含了多个时间点和多个单位(个体)的变量观测值。
在EViews中,可以通过菜单栏中的"View" -> "Structure" -> "Autodetect"来自动检测数据类型并设置为面板数据。
第三步:查看数据面板在进行面板数据回归分析之前,可以先查看数据面板的基本信息。
在EViews的工作区中,选择要查看的数据,然后点击菜单栏中的"View" -> "Group Statistics" -> "Panel Data",即可显示出数据面板的基本统计信息。
第四步:设定回归模型在EViews中,可以通过命令或拖拽方式来设定回归模型。
首先需要确定因变量和自变量,然后选择回归模型。
EViews支持多种回归模型,例如普通最小二乘回归(OLS)、固定效应模型(Fixed Effects Model)和随机效应模型(Random Effects Model)等。
在设定回归模型时,可以考虑是否添加控制变量和截距项。
第五步:进行回归分析在设定回归模型后,可以进行回归分析。
在EViews中,可以通过点击工具栏上的"Estimate"按钮或通过菜单栏中的"Object" -> "Estimate Equation"来进行回归分析。
详细的EVIEWS面板数据分析操作
至少1个协整向量 65.74 (0.2266)
65.74 (0.2266)
注:加“*”表示在5%的显著性水平下拒绝原假设而接受备择假设。
上述检验结果检验的样本区间为1991-2003年,从表10.8和 表10.9的检验结果可以看出,我国29个省市的城镇居民消费和 收入的面板数据之间存在协整关系。
详细的EVIEWS面板数据分析操作
View/Spreadsheet View:i? m? k?
详细的EVIEWS面板数据分析操作
第二步 分析数据的平稳性(单位根检验) 请点 说明 请点 软件操作 结果 点检验结果1 结果2
详细的EVIEWS面板数据分析操作
分析数据的平稳性(单位根检验)说明 注:所有序列者要检验
原:不稳定(Hadri 除外, Hadri 中 原:稳定)
除此项 外均支 持协整
详细的EVIEWS面板数据分析操作
表10.8 Johansen面板协整检验结果
(选择序列有确定性趋势而协整方程只有截距的情况)
原假设
支
Fisher联合迹统计量 Fisher联合-max统计
持
(p值)
量(p值)
协Leabharlann 整0个协整向量133.4 (0.0000)*
128.7 (0.0000)*
此时不能进行协整检验与直接对原序列进行回归。
◎对序列进行差分或取对数使之变成同阶序列
若变换序列后均为平稳序列可用变换后的序列直接进行回归
思路二 若变换序列后均为同阶非平稳序列,则请点
详细的EVIEWS面板数据分析操作
思路二 变量之间是同阶单整:协整检验
请点协整检验说明 请点 软件操作 结果判定请点 1 2 3 协整检验通过:
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
1.已知1996—2002年中国东北、华北、华东15个省级地区的居民家庭人均消费(cp,不变价格)和人均收入(ip,不变价格)居民,利用数据(1)建立面板数据(panel data)工作文件;(2)定义序列名并输入数据;(3)估计选择面板模型;(4)面板单位根检验。
年人均消费(consume)和人均收入(income)数据以及消费者价格指数(p)分别见表,和。
表1996—2002年中国东北、华北、华东15个省级地区的居民家庭人均消费(元)数据人均消费1996 19971998199920002001 (2002)CONSUMEAHCONSUMEBJ-CONSUMEFJ\CONSUMEHB、CONSUMEHLJ,CONSUMEJLCONSUMEJS【CONSUMEJX》CONSUMELN| CONSUMENMG* CONSUMESD5022CONSUMESH >10464CONSUMESX[CONSUMETJ.CONSUMEZJ:表1996—2002年中国东北、华北、华东15个省级地区的居民家庭人均收入(元)数据人均收入199619971998199920002001·2002INCOMEAH INCOMEBJ)INCOMEFJ(INCOMEHB,INCOMEHLJ^ INCOMEJL4810 INCOMEJS'INCOMEJX,INCOMELN!INCOMENMG? 6051INCOMESDINCOMESH@INCOMESX'INCOMETJ…INCOMEZJ~表1996—2002年中国东北、华北、华东15个省级地区的消费者物价指数物价指数19961997199819992000¥20012002PAH10099 ~PBJPFJ[PHB (99PHLJ、PJL98\PJSPJX% 102101PLN( 100(1)建立面板数据工作文件 首先建立工作文件。
打开工作文件后,过程如下:(建立面板数据库。
PNMG 》PSD)PSH100 100 PSX —PTJ 109 &PZJ101、在窗口中输入15个不同省级地区的标识。
}】(2)定义序列名并输入数据产生3*15个尚未输入数据的变量名。
这样可以通过键盘输入或黏贴的方法数据数据。
(3)估计、选择面板模型打开一个pool窗口,先输入变量后缀(所要使用的变量)。
点击Estimate,打开估计窗口。
A.混合模型的估计方法、左边的Common表示相同系数,即表示不同个体有相同的斜率。
得到如下输出结果:相应的表达式是:、ˆ129.630.76it itCP IP =+ 20.98,4824588r R SSE ==上式表示15个省级地区的城镇人均指出平均占收入的76%。
B.个体固定效应回归模型的估计方法将截距项选择区选Fixed effects (固定效应)得到如下输出结果:相应的表达式为:】1215ˆ515.60.7036.3537.6...198.6it it CP IP D D D =+-+++ (55) 20.99,2270386r R SSE ==其中虚拟变量1215,,...,D D D 的定义是:1,1,2,...,150,i i i D =⎧=⎨⎩如果属于第个个体,其他15个省级地区的城镇人均指出平均占收入70%。
从上面的结果可以看出北京市居民的自发性消费明显高于其他地区。
接下来用F 统计量检验是应该建立混合回归模型,还是个体固定效应回归模型。
0H :i αα=。
模型中不同个体的截距相同(真实模型为混合回归模型)。
1H :模型中不同个体的截距项i α不同(真实模型为个体固定效应回归模型)。
F 统计量定义为:()/[(1)()]()/(1)/()/()r u r u u u SSE SSE NT k NT N k SSE SSE N F SSE NT N k SSE NT N k --------==----'其中r SSE 表示约束模型,即混合估计模型的残差平方和,u SSE 表示非约束模型,即个体固定效应回归模型的残差平方和。
非约束模型比约束模型多了1N -个被估参数。
所以本例中:0.05(4824588227386)/(151)8.1(14,89) 1.82270386/(105151)F F --===--所以推翻原假设,建立个体固定效应回归模型更合理。
C.时点固定效应回归模型的估计方法 将时间选择为固定效应。
·得到如下输出结果:相应的表达式为:127ˆ 2.60.78105.9134.1...93.9it it CP IP D D D =++++- 20.987,4028843R SSE ==其中虚拟变量127,,...,D D D 的定义是:1,0,t D ⎧=⎨⎩如果属于第t 个截面,t=1996,...,2002其他@D.个体随机效应回归模型估计截距项选择Random effects(个体随机效应)—得到如下部分输出结果:相应的表达式是:1215ˆ345.20.72 2.6367.0...106.1it it CP IP D D D =+-+++ 20.98,2979246R SSE ==其中虚拟变量1215,,...,D D D 的定义是:1,0,i D ⎧=⎨⎩如果属于第i 个个体,i=1,2,...,15其他接下来利用Hausman 统计量检验应该建立个体随机效应回归模型还是个体固定效应回归模型。
0H :个体效应与回归变量(it IP )无关(个体随机效应回归模型)-1H :个体效应与回归变量(it IP )相关(个体固定效应回归模型)分析过程如下:得到如下检验结果:>由检验输出结果的上半部分可以看出,Hausman统计量的值是,相对应的概率是,即拒接原假设,应该建立个体固定效应模型。
检验结果的下半部分是Hausman检验中间结果比较。
个体固定效应模型对参数的估计值为,随机效应模型对参数的估计值为。
两个参数的估计量的分布方差的差为。
综上分析,1996—2002年中国东北、华北、华东15个省级地区的居民家庭人均消费和人金收入问题应该建立个体固定效应回归模型。
人均消费平均占人均收入的70%。
随地区不同,自发消费(截距项)存在显著性差异。
(4)面板单位根检验以cp序列为例。
首先在工作文件窗口中打开cp变量的15个数据组。
`单位根检验过程如下:、得到如下检验结果:从上面的检验结果可以看出来,6种检验方法的结论都认为15个cp序列存在单位根。
|【选择IPS检验方法进行单位根检验。
检验结果如下:从上面的结果可以看出,cp面板存在单位根,同时每个个体都存在单位根。
;?2.收集中国2000—2005年各地区城镇居民人均可支配收入X和消费指出Y统计数据如表。
数据是6年的,每一年都有32组数据,共192组观测值。
人均可支配收入和消费支出数据(单位:元)20002001200220032004·2005地区可支配收入消费支出可支配收入消费支出可支配收入消费支出可支配收入消费支出¥可支配收入消费支出可支配收入消费支出X Y X Y X|Y X Y X Y X Y全国[,北京)天津—河北:山西-、内蒙古!辽宁《吉林《、黑龙江[上海)江苏¥、浙江]安|徽福-建江('西山《东河/南湖、…北湖`南广`东广#西【海'南重:庆四~川贵—{州云#南西\藏陕].西甘—肃青}海宁夏新疆首先建立工作文件,打开工作文件后,过程如下:建立面板数据库,并命名为XY。
输入不同省市(包括全国)的标识,如下:点击sheet键,定义变量X和Y。
点击Edit+/-后,在数据窗口键入数据即可。
对模型进行估计,建立个体固定效应回归模型,过程如下:得到如下输出结果:从估计结果可以看出,对于32个省市来说,虽然它们的城镇居民消费倾向相同,但是其城镇居民的自发消费存在显著的差异,其中重庆的城镇居民自发消费最高,其次为西藏、北京、广东;城镇居民自发消费最低的是江西,其次是河南、山东。
注意几点:(1)个体固定效应模型的EViews输出结果中也可以有公共截距项;(2)EViews输出结果中没有给出描述个体效应的截距项相应的标准差和t值。
不认为截距项是模型中的重要参数。
(3)当对个体固定效应模型选择加权估计时,输出结果将给出加权估计和非加权估计两种统计量评价结果。
(4)输出结果的联立方程组形式可以通过点击View选Representations功能获得。
(5)点击View选Wald Coefficient Tests…功能可以对模型的斜率进行Wald检验。
(6)点击View选Residuals/Table,Graphs,Covariance Matrix,Correlation Matrix功能可以分别得到按个体计算的残差序列表,残差序列图,残差序列的方差协方差矩阵,残差序列的相关系数矩阵。
(7)点击Proc选Make Model功能,将会出现估计结果的联立方程形式,进一步点击Solve 键,在随后出现的对话框中可以进行动态和静态预测。