第22讲 森林图和漏斗图的解读
Meta分析:解读森林图和漏斗图
Meta分析:解读森林图和漏⽃图前⾯已经介绍过⼆分类资料的Meta分析,今天给⼤家介绍连续性资料的Meta分析实现步骤,解读森林图和漏⽃图。
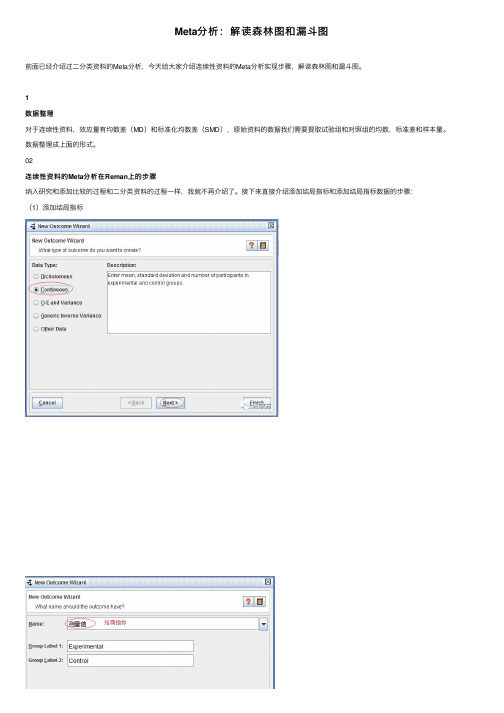
1数据整理对于连续性资料,效应量有均数差(MD)和标准化均数差(SMD),原始资料的数据我们需要提取试验组和对照组的均数,标准差和样本量。
数据整理成上⾯的形式。
02连续性资料的Meta分析在Reman上的步骤纳⼊研究和添加⽐较的过程和⼆分类资料的过程⼀样,我就不再介绍了。
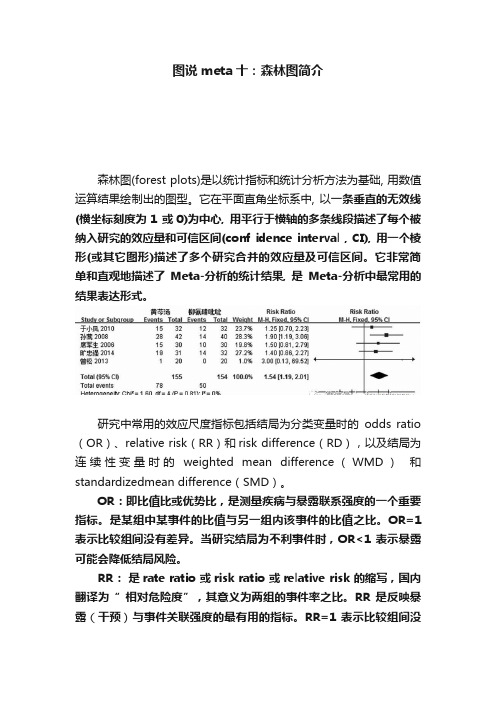
接下来直接介绍添加结局指标和添加结局指标数据的步骤:(1)添加结局指标(2)添加结局指标数据按照上述步骤纳⼊所有的研究:将纳⼊的研究的数据添加到相应的位置,结果如下:(3)解读森林图(3)解读森林图图中的点代表单个研究的效应量,点的⼤⼩代表该研究的权重,即该项研究对Meta分析的贡献度;横线代表该效应值的可信区间;图中的菱形则代表合并后的结果。
图中的直线是⽆效线,⽤于判定合并效应量有⽆统计学意义。
若菱形与该直线相交,则代表两组的差异没有统计学意义。
从上图也能看出异质性检验结果,在Revman中,主要通过Q统计量和I2统计量进⾏异质性检验。
Q统计量是服从⾃由度为K-1的卡⽅分布,本质是卡⽅检验,属于异质性定性分析的⽅法,⼀般认为当P<>上图的异质性检验结果为:Q检验:P=0.02(<0.1); i2="67%">注意纳⼊的研究较少时,Q检验法的检验效能过低,纳⼊的研究很多时,它的检验效能⼜过⾼。
I2值是消除了纳⼊的研究数⽬对检验效能的影响后,通过Q转换得到的,⼀般认为I2统计量较Q统计量敏感。
(4)解读漏⽃图漏⽃图是⼀种以视觉观察来识别是否存在发表偏倚的⽅法,该法以效应量为横坐标,纵坐标为标准误。
⼩样本所得的离散度较⼤,因此常处于漏⽃图的底部,⼤样本离散度则较⼩,因此处于顶部。
正常情况下应该是顶⼩⽽底⼤,如果不是这样,则可能存在较⼤偏倚。
注意漏⽃图的判断存在主观性,并且当纳⼊研究太少时,难以判断对称性,常⽤的判断发表偏倚的⽅法还有Egger法,Begg法,Trim法及计算失安全系数的⽅法,但是Revman只能使⽤漏⽃图。
循证医学重点大题

循证医学重点⼤题名解临床研究证据分级:系统评价和meta分析>随机对照研究>队列研究>病例对照研究>病例系列、病例报告>专家意见>动物实验、实验室研究原始研究证据(primary research evidence):是对直接在患者中进⾏单个有关病因、诊断、预防、治疗和预后等试验研究所获得的第⼀⼿数据,进⾏统计学处理、分析、总结后所得出的结论。
⼆次研究证据(secondary research evidence):尽可能全⾯地收集某⼀问题的全部原始研究证据,进⾏严格评价、整合处理、分析总结后所得出的综合结论,是对多个原始研究证据再加⼯后得到的更⾼层次的证据。
随机对照试验(RCT):是采⽤随机分配的⽅法,将符合要求的研究对象随机分配到试验组或对照组,然后接受相应的试验措施,在⼀致的条件或环境下,同步进⾏研究和观察试验效应,并⽤客观的效应指标,测量试验结果,评价试验设计。
严格评价:指对⼀个研究证据的质量作科学的鉴别,分析它的真实性的程度,即看是否真实可信。
如果是真实可靠的,要进⼀步评价临床医疗是否有重要价值;如果既真实⼜有重要价值,最后要看这些证据是否能适⽤于具体的临床实践,即是否能应⽤于⾃⼰的病⼈的诊治实践以解决病⼈的实际问题。
临床决策分析(clinical decision analysis,CDA):是由临床医师服务⼈员针对疾病的诊断和防治过程中风险及获益的不确定性,在充分调查已有的证据,特别是最新、最佳证据的基础上,结合⾃⼰的临床经验和患者的实际情况,分析⽐较两个或两个以上可选的预备⽅案,从中选择最优者予以实施,从⽽提⾼临床诊治⽔平的过程。
临床实践指南(clinical practice guideline):是是针对特定的临床情况,收集、综合和概括各级临床研究证据,系统制定出帮助医师作出恰当处理的指导意见,⼀般由学术团体制定,卫⽣⾏政主管部门组织。
试验诊断类型(诊断试验类型):病史和体检;实验检查;影像学检查;器械检查;诊断标准。
森林图的详细解读

森林图的详细解读在Meta分析汇总的结果中,最常见的两个图形就是森林图和漏斗图,但是笔者发现在实际的运用中,经常有人误读和误用这两个图形,从今天起,我讲具体介绍一下这两个图形的解读。
1.森林图的定义:森林图是以统计指标和统计分析方法为基础,用数值运算结果绘制出的图型。
它在平面直角坐标系中,以一条垂直的无效线(横坐标刻度为1或0)为中心,用平行于横轴的多条线段描述了每个被纳入研究的效应量和可信区间,用一个棱形(或其它图形)描述了多个研究合并的效应量及可信区间。
它非常简单和直观地描述了Meta分析的统计结果,是Meta分析中最常用的结果表达形式。
2.分类变量中的森林图当某研究RR(OR,RD)的95%CI包含了1,即在森林图中其95%CI的横线与无效竖线相交时,可认为试验组发生率与对照组发生率相等,试验因素无效。
当某研究RR(OR,RD)的95%CI上下限均>1,即在森林图中,其95%CI横线不与无效竖线相交,且该横线落在无效线右侧时,可认为试验组的发生率大于对照组的发生率,若研究者所研究的事件是不利事件(如发病、患病、死亡等)时,试验组的试验因素会增加该不利事件的发生,试验因素为有害因素(危险因素);若研究者所研究的事件是有益事件(如有效、缓解、生存等)时,试验因素会增加该有益事件的发生,试验因素为有益因素。
当某研究的95%CI上下限均小于1,即在森林图中,其95%CI横线不与无效竖线相交,且该横线落在无效线左侧时,可认为试验组的发生率小于对照组的发生率,若研究者所研究的事件是不利事件(如发病、患病、死亡等)时,试验组的试验因素会减少该不利事件的发生,试验因素为有益因素(保护因素);若研究者所研究的事件是有益事件(如有效、缓解、生存等)时,试验因素会减少该有益事件的发生,试验因素为有害因素。
2 连续性变量的森林图当某研究的95%CI包含了0,即在森林图中其95%CI横线与无效竖线(横坐标刻度为0)相交时,可认为试验组某指标的均数与对照组相等,试验因素无效。
图说meta十:森林图简介
图说meta十:森林图简介森林图(forest plots)是以统计指标和统计分析方法为基础, 用数值运算结果绘制出的图型。
它在平面直角坐标系中, 以一条垂直的无效线(横坐标刻度为1 或0)为中心, 用平行于横轴的多条线段描述了每个被纳入研究的效应量和可信区间(conf idence interval , CI), 用一个棱形(或其它图形)描述了多个研究合并的效应量及可信区间。
它非常简单和直观地描述了Meta-分析的统计结果, 是Meta-分析中最常用的结果表达形式。
研究中常用的效应尺度指标包括结局为分类变量时的odds ratio (OR)、relative risk(RR)和risk difference(RD),以及结局为连续性变量时的weighted mean difference(WMD)和standardizedmean difference(SMD)。
OR:即比值比或优势比,是测量疾病与暴露联系强度的一个重要指标。
是某组中某事件的比值与另一组内该事件的比值之比。
OR=1 表示比较组间没有差异。
当研究结局为不利事件时,OR<1 表示暴露可能会降低结局风险。
RR:是rate ratio 或risk ratio 或relative risk 的缩写,国内翻译为“ 相对危险度”,其意义为两组的事件率之比。
RR 是反映暴露(干预)与事件关联强度的最有用的指标。
RR=1 表示比较组间没有差异。
当研究结局为不利事件时,RR<1 表示干预可降低结局风险。
需要注意的是,只有队列研究和随机对照试验结果可以直接获得相对危险度。
RD(risk difference):即危险差,也被称为归因危险度(attributable risk,AR)、绝对风险差(absoluterisk difference)和绝对风险降低率(absolute riskreduction, ARR),是指干预(暴露)组和对照组结局事件发生概率的绝对差值。
几种发表性偏倚评估方法介绍

。
③Ro
sen
tha
l
N
法
fs
是分
别
计
算量值是否为“0”的统计量 U, 根据 U 值进行分
段 ,删除部分无统计意义的研究 ,并计算相应的安全系 数 ,计算公式为〔5〕:
N fs =
∑U 1164
2
-
k
其中 U 为每一个独立研究效应值是否为“0”检验统计
量 , k为已收集的独立研究的个数 。
可能更贴切 。
鉴于 Rosenthal N fs存在的种种问题 , O rw in在 1983 年在 Rosenthal N fs的基础上进行了完善 ,在本文我们称 做 O rw in’s N fs法 。O rw in’s N fs法主要解决以下两个问 题〔6〕: ①O rw in’s N fs法让研究者确定的是总的效应量 变为某一特定值 (而不是“0”)最少需要多少个未发表
在此 ,介绍一种称之为“trim and fill”的方法〔7〕。 The trim and fill法实际上是一种迭代算法 ,先从漏斗 图的阳性面 ( the positive side) (漏斗图中研究文献多 的一边 )去处一些极小样本量的研究 ,重新计算总的 效应量 ,然后将去除的这些原始研究逐步加入到公式 中重新计算 ,如此反复 ,直到漏斗图围绕重新计算的总 的效应量呈左右对称 。 trim and fill法属于一种非参 法 ,计算过程也较为复杂 ,但其作用是较为明显的 ,一 些常用的统计软件 ,如 STATA、Comp rehensive M eta A2 nalysis软件都能执行相应的操作 。利用 trim and fill 法还能大致估计出未发表文献的数量 。
概念定义为 :当 M eta分析结果有统计学意义时 ,为排
《循证医学》理论教学大纲

《循证医学》理论教学大纲第一章循证医学总论(3学时)一教学目的通过对循证医学相关概念及背景的介绍,让学生初步认识循证医学。
二教学要求(一)掌握循证医学的基本概念、实践步骤及方法(二)熟悉循证医学的特点及基本条件(三)了解循证医学发生的背景及学习和实践循证医学的目的和意义三教学内容(一)循证医学的产生和发展1循证医学的产生2循证医学的发展(二)循证医学的定义和特点1循证医学的定义2循证医学的特点(三)实践循证医学的基本条件和方法1实践循证医学的基本条件2循证医学实践的基本步骤和方法第二章怎样在临床实践中发现和提出问题(1学时)一教学目的本章的教学目的是使学生了解提出问题的重要性和问题的来源,并掌握前景问题的构建方法。
二教学要求(一)掌握PICO原则(二)熟悉临床问题的来源与分类(三)了解问题范围的把握原则三教学内容(一)问题及问题的起源1问题的特点2问题的特殊性3 临床问题的来源(二)如何分析问题1问题的种类和构建2提出问题过程中的困难3从患者的角度考虑问题4确定问题的范围第三章证据的分类、分级与推荐(2学时)一教学目的学习临床研究证据的分类,特别是原始研究证据与二次研究证据,学习临床证据的分级标准和来源。
二教学要求(一)掌握证据的分类依据、GRADE证据分级和推荐标准的内涵和关系(二)熟悉临床研究证据分级与推荐系统的演进过程及内容(三)了解其他领域的证据分级系统三教学内容第一节临床研究证据的分类(一)按研究方法分类(二)按研究问题分类(三)按用户需要分类(四)按获得渠道分类第二节临床研究证据的分级第三节临床研究证据的来源(一)数据库资源(二)网站资源(三)杂志(四)会议文献(五)在研和(或)未发表的临床试验第四章循证医学证据来源与检索(4学时)一教学目的通过本章的学习,掌握循证医学证据检索的步骤、方法和注意事项,了解常见的证据来源(数据库)及其特点。
二教学要求(一)掌握循证医学证据检索的步骤(二)了解常见的证据来源(数据库)及其特点(三)了解循证医学选择数据库的标准三教学内容(一)循证医学资源的分类:介绍Brain Haynes提出的循证医学资源模型。
博格达斯量表

博加德斯量表(Bogardus scale)博加德斯量表又称社会距离量表.产生于20世纪20年代,它是美国社会心理学家鲍格达斯于1925年创用的。
这种量表过去一直广泛用于测量人们对种族群体的态度,现在,它也被用来测量人们对职业、社会阶层、宗教群体等事物的态度。
如何利用普查数据-了解人口结构-预测可能的问题-是否和经济发展、资源结构相适应-研究发展与变迁对人口普查形成的整体资料(非个人资料),如果公民和研究机构需要,还可以向统计机构申请获取这些资料。
Meta分析国内翻译为“荟萃分析”,定义是“The statistical analysis of large collection of analysis results from individual studies for the purpose of integrating the findings.”中文翻译:对具备特定条件的、同课题的诸多研究结果进行综合的一类统计方法。
编辑本段Meta 分析的基本步骤 (1)明确简洁地提出需要解决的问题。
(2)制定检索策略,全面广泛地收集随机对照试验。
(3)确定纳入和排除标准,剔除不符合要求的文献。
(4)资料选择和提取,包括原文的结果数据、图表等。
(5)各试验的质量评估和特征描述。
(6)统计学处理。
a.异质性检验(齐性检验)。
b.统计合并效应量(加权合并,计算效应尺度及95%的置信区间)并进行统计推断。
c.图示单个试验的结果和合并后的结果。
d.敏感性分析。
e.通过“失安全数”的计算或采用“倒漏斗图”了解潜在的发表偏倚。
(7)结果解释、作出结论及评价。
(8)维护和更新资料。
Meta 分析Sample:中国人群老年性痴呆发病危险因素的荟萃分析【摘要】 目的探讨中国人群老年性痴呆(AD)发生的主要危险因素,为预防决策提供依据。
方法收集1980年1月至2008年11月国内外公开发表的关于AD发病危险因素独立病例对照研究,并用RevMan软件对这些文献进行荟萃综合定量,采用卡方值和p值分析各研究结果间的统计学异质性。
Meta分析 软件介绍

3)效应指标(Effect Measure): √ Mean Difference
5.3 添加比较和结局
7.为结局添加相关研究
选择:Add study data for the new outcome(为 该结局添加研究数据) 点击:Finish(完成)
8.选择纳入研究:
选择全部4个纳入研究,点击: Finish(完成)
23
5.3 添加比较和结局
5.3 添加比较和结局
4.选择数据类型
数据类型:
1. 二分类资料 2. 连续性资料√ 3. 期望方差 4. 一般倒方差
5. 其他
25
点击:Next(下一步)
5.3 添加比较和结局
5.输入结局名称: 输入名称(Name): CCT
Group label 1: High Fluorine(Experiment) Group label 2: Low Fluorine(control)
5.2 添加纳入研究
5.输入研究发表年份 Year: 2010 点击:Next(下一步) 6.添加研究识别码 不添加,直接点击:Next(下一步)
注:若经注册的临床试验有唯一的注册码。
7.继续添加下一个纳入研究 选择:Add another study in the same s (方案),默认项 Full review(全文)√
点击:Finish(完成) 弹出如下界面:
15
102
5.2 添加纳入研究
1.展开面板
点击:大纲面板中Studies and reference(研究 和参考文献)旁的钥匙图标。再次点击Reference to studies (研究的参考文献)旁的钥匙图标。