实验二 词法分析器的构造
编译原理-实验二-FLEX词法分析器

编译原理-实验⼆-FLEX词法分析器FLEX词法分析器⼀、Lex和Yacc介绍Lex 是⼀种⽣成扫描器的⼯具。
扫描器是⼀种识别⽂本中的词汇模式的程序。
⼀种匹配的常规表达式可能会包含相关的动作。
这⼀动作可能还包括返回⼀个标记。
当 Lex 接收到⽂件或⽂本形式的输⼊时,它试图将⽂本与常规表达式进⾏匹配。
它⼀次读⼊⼀个输⼊字符,直到找到⼀个匹配的模式。
如果能够找到⼀个匹配的模式,Lex 就执⾏相关的动作(可能包括返回⼀个标记)。
另⼀⽅⾯,如果没有可以匹配的常规表达式,将会停⽌进⼀步的处理,Lex 将显⽰⼀个错误消息。
Yacc代表 Yet Another Compiler Compiler 。
Yacc 的 GNU 版叫做 Bison。
它是⼀种⼯具,将任何⼀种编程语⾔的所有语法翻译成针对此种语⾔的 Yacc 语法解析器。
(下载下载flex和bison。
⽹址分别是/packages/flex.htm和/packages/bison.htm。
)⼆、配置环境(win7)①下载flex和bison并安装到D:\GnuWin32(尽量是根⽬录)②由于我们使⽤的flex和bison都是GNU的⼯具,所以为了⽅便,采⽤的C/C++编译器也采⽤GNU的编译器GCC,当然我们需要的也是Windows版本的GCC了。
所以提前准备好VC 6.0③检验是否可以进⾏lex⽂件编译1.新建⽂本⽂件,更改名称为lex.l,敲⼊下⾯代码%{int yywrap(void);%}%%%%int yywrap(void){return 1;}2.新建⽂本⽂件,更改名称为yacc.y,敲⼊下⾯代码%{void yyerror(const char *s);%}%%program:;%%void yyerror(const char *s){}int main(){yyparse();}我们暂且不讨论上⾯代码的意思。
打开控制台,进⼊到刚才所建⽴⽂件(lex.l,yacc.y)所在的⽂件夹。
编译原理实验报告

编译原理实验报告一、实验目的本次编译原理实验的主要目的是通过实践加深对编译原理中词法分析、语法分析、语义分析和代码生成等关键环节的理解,并提高实际动手能力和问题解决能力。
二、实验环境本次实验使用的编程语言为 C/C++,开发工具为 Visual Studio 2019,操作系统为 Windows 10。
三、实验内容(一)词法分析器的设计与实现词法分析是编译过程的第一个阶段,其任务是从输入的源程序中识别出一个个具有独立意义的单词符号。
在本次实验中,我们使用有限自动机的理论来设计词法分析器。
首先,我们定义了单词的种类,包括关键字、标识符、常量、运算符和分隔符等。
然后,根据这些定义,构建了相应的状态转换图,并将其转换为程序代码。
在实现过程中,我们使用了字符扫描和状态转移的方法,逐步读取输入的字符,判断其所属的单词类型,并将其输出。
(二)语法分析器的设计与实现语法分析是编译过程的核心环节之一,其任务是在词法分析的基础上,根据给定的语法规则,判断输入的单词序列是否构成一个合法的句子。
在本次实验中,我们采用了自顶向下的递归下降分析法来实现语法分析器。
首先,我们根据给定的语法规则,编写了相应的递归函数。
每个函数对应一种语法结构,通过对输入单词的判断和递归调用,来确定语法的正确性。
在实现过程中,我们遇到了一些语法歧义的问题,通过仔细分析语法规则和调整函数的实现逻辑,最终解决了这些问题。
(三)语义分析与中间代码生成语义分析的任务是对语法分析所产生的语法树进行语义检查,并生成中间代码。
在本次实验中,我们使用了四元式作为中间代码的表示形式。
在语义分析过程中,我们检查了变量的定义和使用是否合法,类型是否匹配等问题。
同时,根据语法树的结构,生成相应的四元式中间代码。
(四)代码优化代码优化的目的是提高生成代码的质量和效率。
在本次实验中,我们实现了一些基本的代码优化算法,如常量折叠、公共子表达式消除等。
通过对中间代码进行分析和转换,减少了代码的冗余和计算量,提高了代码的执行效率。
词法分析器实验报告

词法分析器实验报告词法分析器实验报告实验目的:设计、编制、调试一个词法分析子程序,识别单词,加深对词法分析原理的理解。
实验要求:该程序要实现的是一个读单词过程,从输入的源程序中,识别出各个具有独立意义的单词,即基本保留字、标识符、常数、运算符、分界符五大类。
并依次输出各个单词的内部编码及单词符号自身值。
(一)实验内容(1)功能描述:对给定的程序通过词法分析器弄够识别一个个单词符号,并以二元式(单词种别码,单词符号的属性值)显示。
而本程序则是通过对给定路径的文件的分析后以单词符号和文字提示显示。
(2)程序结构描述:函数调用格式:函数调用格式函数名(实在参数表 )Switch(m)、 isKey(String string)、isLetter(char c)、实参isDigit(char c)、isOperator(char c)isKey(String string)、isLetter(char c)、调作为表达式isDigit(char c)、isOperator(char c) 用方作为语句 getChar()、judgement()、法函数的递归调用 isOperator(char c) 、isLetter(char c)、isDigit(char c)参数含义:1String string;存放读入的字符串 String str; 存放暂时读入的字符串 char ch; 存放读入的字符 int rs 判断读入的文件是否为空 char []data 存放文件中的数据 int m;通过switch用来判断字符类型,函数之间的调用关系图:mainComplier..judgementisOperate()M=0 getChar( )isDigit()M=4 For(ch )isLetter() M=2Switch(m)isKey() M=3 函数功能:Judgement()判断输入的字符并输出单词符号,返回值为空; getChar() 读取文件的,返回值为空;isLetter(char c) 判断读入的字符是否为字母的,返回值为Boolean类型; switch (m) 判断跳转输出返回值为空;isOperator(char c)判断是否为运算符的,返回值为Boolean类型;isKey(String string)判断是否为关键字的,返回值为Boolean类型;isDigit(char c) 判断读入的字符是否为数字的,返回值为Boolean类型。
C语言词法分析器构造实验报告
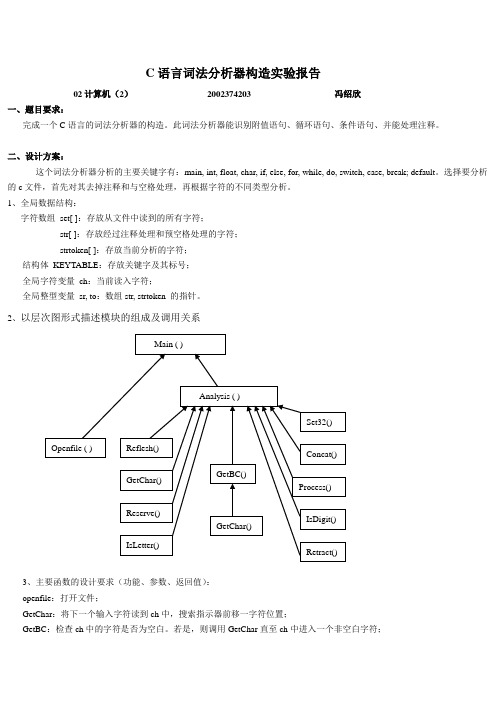
C语言词法分析器构造实验报告02计算机(2)2002374203 冯绍欣一、题目要求:完成一个C语言的词法分析器的构造。
此词法分析器能识别附值语句、循环语句、条件语句、并能处理注释。
二、设计方案:这个词法分析器分析的主要关键字有:main, int, float, char, if, else, for, while, do, switch, case, break; default。
选择要分析的c文件,首先对其去掉注释和与空格处理,再根据字符的不同类型分析。
1、全局数据结构:字符数组set[ ]:存放从文件中读到的所有字符;str[ ]:存放经过注释处理和预空格处理的字符;strtoken[ ]:存放当前分析的字符;结构体KEYTABLE:存放关键字及其标号;全局字符变量ch:当前读入字符;全局整型变量sr, to:数组str, strtoken 的指针。
2、以层次图形式描述模块的组成及调用关系3、主要函数的设计要求(功能、参数、返回值):openfile:打开文件;GetChar:将下一个输入字符读到ch中,搜索指示器前移一字符位置;GetBC:检查ch中的字符是否为空白。
若是,则调用GetChar直至ch中进入一个非空白字符;Concat:将ch中的字符连接到strtoken之后;IsLetter 和IsDigit:布尔函数过程,分别判断ch中的字符是否为字母和数字;Reserve:整型函数过程,对strtoken中的字符串查找关键字表,若是关键字则返回编码,否则返回-1;Retract:将搜索指示器回调一个字符位置,将ch置为空白字符;reflesh:刷新,把strtoken数组置为空;prearrange1:将注释部分置为空格;prearrange2:预处理空格,去掉多余空格;analysis:词法分析;main:主函数。
4、状态转换图:字符a包括:= , & , | , + , --字符b包括:-- , < , > , | , *字符c包括:, , : , ( , ) , { , } , [ , ] , ! ,# , % , ” , / , * , + , -- , > , <, .三、源代码如下:#include <stdio.h>#include <string.h>char set[1000],str[500],strtoken[20];char sign[50][10],constant[50][10];char ch;int sr,to,id=0,st=0;typedef struct keytable /*放置关键字*/{char name[20];int kind;}KEYTABLE;KEYTABLE keyword[]={ /*设置关键字*/{"main",0},{"int",1},{"float",2},{"char",3},{"if",4},{"else",5},{"for",6},{"while",7},{"do",8},{"switch",9},{"case",10},{"break",11},{"default",12},};openfile() /*打开文件*/{FILE *fp;char a,filename[10];int n=0;printf("Input the filename:");gets(filename);if((fp=fopen(filename,"r"))==NULL){printf("cannot open file.\n");exit(0);}elsewhile(!feof(fp)) /*文件不结束,则循环*/{a=getc(fp); /*getc函数带回一个字符,赋给a*/set[n]=a; /*文件的每一个字符都放入set[]数组中*/n++;}fclose(fp); /*关闭文件*/set[n-1]='\0';printf("\n\n-------------------Source Code--------------------------\n\n");puts(set);printf("\n--------------------------------------------------------\n");}reflesh() /*清空strtoken数组*/{to=0; /*全局变量to是strtoken的指示器*/strcpy(strtoken," ");}prearrange1() /*预处理程序1*/{int i,a,b,n=0;do{if(set[n]=='/' && set[n+1]=='*'){a=n; /*记录第一个注释符的位置*/while(!(set[n]=='*' && set[n+1]=='/'))n++;b=n+1; /*记录第二个注释符的位置*/for(i=a;i<=b;i++) /**/set[i]=' '; /*把注释的内容换成空格,等待第二步预处理*/ }n++;}while(set[n]!='\0');}prearrange2() /*预处理程序2*/{int j=0;sr=0; /*全局变量sr是str[]的指示器*/do{if(set[j]==' ' || set[j]=='\n'){while(set[j]==' ' || set[j]=='\n') /*扫描到有连续的空格或换行符*/j++;str[sr]=' '; /*用一个空格代替扫描到的连续空格和换行符放入str[]*/sr++;}else{str[sr]=set[j]; /*若当前字符不为空格或换行符就直接放入str[]*/sr++;j++;}}while(set[j]!='\0');str[sr]='\0';}char GetChar() /*把字符读入全局变量ch中,指示器sr前移*/{ch=str[sr];sr++;return(str[sr-1]);}void GetBC() /*开始读入符号,直至第一个不为空格*/{while(ch==' '){ch=GetChar();}}Concat() /*把ch中的字符放入strtoken[]*/{strtoken[to]=ch;to++; /*全局变量to是strtoken的指示器*/strtoken[to]='\0';}int IsLetter() /*判断是否为字母*/{if((ch>=65 && ch<=90)||(ch>=97 && ch<=122))return(1);else return(0);}int IsDigit() /*判断是否为数字*/{if(ch>=48 && ch<=57)return(1);else return(0);}int Reserve() /*对strtoken中的字符串查找保留字表,若是则返回它的编码,否则返回-1*/ {int i,k=0;for(i=0;i<=20;i++){if(strcmp(strtoken,keyword[i].name)==0){ k=1;return(keyword[i].kind);}}if(k!=1)return(-1);}void Retract() /*指示器sr回调一个字符位置,把ch置为空*/{sr--;}int InsertId(){int i,k;for(i=0;i<id;i++){k=strcmp(strtoken,sign[i]);if(k==0)return(i);}strcpy(sign[id],strtoken); /*插入标识符*/id++;return(id-1);}int InsertConst(){int i,k;for(i=0;i<st;i++){k=strcmp(strtoken,constant[i]);if(k==0)return(i);}strcpy(constant[st],strtoken); /*插入常数*/st++;return(st-1);}void analysis(){int value;reflesh(); /*清空strtoken数组*/prearrange1(); /*预处理,使注释内容换成单个空格,放回set[]中*/prearrange2(); /*预处理,使set[]中连续的空格置换成单个空格,并把set[]的内容放到str[]中*/GetChar();GetBC(); /*读取第一个字符*/while(ch!='\0') /*当不等于结束符,继续执行*/{if(IsLetter()){while(IsLetter() || IsDigit()) /*若第一个是字符,继续读取,直到出现空格*/{Concat();GetChar();}Retract(); /*指示器sr回调一个字符位置,把ch置为空*/value=Reserve(); /*对strtoken中的字符串查找保留字表,若是则返回它的编码,否则返回-1*/ if(value==-1) /*如果返回值是-1,那就是变量,把它输出*/{InsertId(); /*插入标识符*/printf("\n%s",strtoken);getch();}else /*否则就是关键字,也输出*/{printf("\n%s",strtoken);getch();}reflesh();}else if(IsDigit()){while(IsDigit()) /*否则,若第一个是数字,继续读取,知道出现空格*/{Concat();GetChar();}Retract();InsertConst(); /*插入常数*/printf("\n%s",strtoken);getch();reflesh();}elseswitch(ch) /*否则,若是下面的符号,就直接把它输出*/{case ',':case ';':case '(':case ')':case '{':case '}':case '[':case ']':case '!':case '#':case '%':case '"':case '/':case '*':Concat();printf("\n'%s'",strtoken);getch();reflesh();break;default:if(ch=='=' || ch=='&' || ch=='|' || ch=='+' || ch=='-') /*如果是这些符号,继续读取下一个*/ {Concat(); /*判断是否为==,&&,||,++,--的情况*/GetChar();if(ch==strtoken[0])Concat();elseRetract();printf("\n'%s'",strtoken);getch();reflesh();break;}else if(ch=='+' || ch=='-' || ch=='<' || ch=='>' || ch=='!' || ch=='*'){Concat(); /*判断是否为+=,-=,<=,>=,!=,*=的情况*/GetChar();if(ch=='=')Concat();elseRetract();printf("\n'%s'",strtoken);getch();reflesh();break;}else{printf("Error!");getch();break;}}GetChar();GetBC();}}main(){clrscr();openfile();analysis();printf(“analysis is over!”);}五、测试结果:1、分析文件test1.c中的程序:Input the filename:test.c*****************Original Code************************/* HELLO.C -- Hello, world */#include "stdio.h"#include "conio.h"main(){printf("Hello, world\n");getch();}*****************************************************'#'include'"'stdio'.'h'"''#'include'"'conio'.'h'"'main'('')''{'printf'(''"'Hello','worldError!n'"'')'';'getch'('')'';''}'Analysis is over!六、实验总结:这个程序主要参考书上关于词法分析器的设计。
词法分析器实验报告

词法分析器实验报告引言:词法分析器(Lexical Analyzer)是编译器的重要组成部分,其主要任务是将源代码转化为一个个独立的词法单元,为语法分析器提供输入。
在本次实验中,我们设计并实现了一个简单的词法分析器,通过对其功能和性能的测试,评估其在不同场景下的表现。
实验目的:1. 确定词法分析器的输入和输出要求;2. 通过构建适当的正则表达式规则,匹配不同类型的词法单元;3. 实现一个高效的词法分析器,确保在处理大型源代码时性能不受影响;4. 对词法分析器的功能和性能进行测试和评估。
实验过程:1. 设计词法分析器的接口:1.1 确定输入:源代码字符串。
1.2 确定输出:词法单元流,每个词法单元包含类型和对应的字符串值。
2. 构建正则表达式规则:2.1 识别关键字:根据编程语言的关键字列表构建正则表达式规则,将关键字与标识符区分开。
2.2 识别标识符:一般由字母、下划线和数字组成,且以字母或下划线开头。
2.3 识别数字:整数和浮点数可以使用不同的规则来识别。
2.4 识别字符串:使用引号(单引号或双引号)包裹的字符序列。
2.5 识别特殊符号:各类操作符、括号、分号等特殊符号需要单独进行规则设计。
3. 实现词法分析器:3.1 读取源代码字符串:逐个字符读取源代码字符串,并根据正则表达式规则进行匹配。
3.2 保存词法单元:将匹配到的词法单元保存到一个词法单元流中。
3.3 返回词法单元流:将词法单元流返回给调用者。
4. 功能测试:4.1 编写测试用例:针对不同类型的词法单元编写测试用例,包括关键字、标识符、数字、字符串和特殊符号。
4.2 执行测试用例:将测试用例作为输入传递给词法分析器,并检查输出是否和预期一致。
4.3 处理错误情况:测试词法分析器对于错误输入的处理情况,如非法字符等。
5. 性能测试:5.1 构建大型源代码文件:生成包含大量代码行数的源代码文件。
5.2 执行词法分析:使用大型源代码文件作为输入,测试词法分析器的性能。
编译原理实验二LL(1)语法分析实验报告

专题3_LL(1)语法分析设计原理与实现李若森 13281132 计科1301一、理论传授语法分析的设计方法和实现原理;LL(1) 分析表的构造;LL(1)分析过程;LL(1)分析器的构造。
二、目标任务实验项目实现LL(1)分析中控制程序(表驱动程序);完成以下描述算术表达式的 LL(1)文法的LL(1)分析程序。
G[E]:E→TE’E’→ATE’|εT→FT’T’→MFT’|εF→(E)|iA→+|-M→*|/设计说明终结符号i为用户定义的简单变量,即标识符的定义。
加减乘除即运算符。
设计要求(1)输入串应是词法分析的输出二元式序列,即某算术表达式“专题 1”的输出结果,输出为输入串是否为该文法定义的算术表达式的判断结果;(2)LL(1)分析程序应能发现输入串出错;(3)设计两个测试用例(尽可能完备,正确和出错),并给出测试结果。
任务分析重点解决LL(1)表的构造和LL(1)分析器的实现。
三、实现过程实现LL(1)分析器a)将#号放在输入串S的尾部b)S中字符顺序入栈c)反复执行c),任何时候按栈顶Xm和输入ai依据分析表,执行下述三个动作之一。
构造LL(1)分析表构造LL(1)分析表需要得到文法G[E]的FIRST集和FOLLOW集。
构造FIRST(α)构造FOLLOW(A)构造LL(1)分析表算法根据上述算法可得G[E]的LL(1)分析表,如表3-1所示:表3-1 LL(1)分析表主要数据结构pair<int, string>:用pair<int, string>来存储单个二元组。
该对照表由专题1定义。
map<string, int>:存储离散化后的终结符和非终结符。
vector<string>[][]:存储LL(1)分析表函数定义init:void init();功能:初始化LL(1)分析表,关键字及识别码对照表,离散化(非)终结符传入参数:(无)传出参数:(无)返回值:(无)Parse:bool Parse( const vector<PIS> &vec, int &ncol );功能:进行该行的语法分析传入参数:vec:该行二元式序列传出参数:emsg:出错信息epos:出错标识符首字符所在位置返回值:是否成功解析。
词法分析器实验报告
词法分析器实验报告词法分析器实验报告一、引言词法分析器是编译器中的重要组成部分,它负责将源代码分解成一个个的词法单元,为之后的语法分析提供基础。
本实验旨在设计和实现一个简单的词法分析器,以深入理解其工作原理和实现过程。
二、实验目标本实验的目标是设计和实现一个能够对C语言代码进行词法分析的程序。
该程序能够将源代码分解成关键字、标识符、常量、运算符等各种词法单元,并输出其对应的词法类别。
三、实验方法1. 设计词法规则:根据C语言的词法规则,设计相应的正则表达式来描述各种词法单元的模式。
2. 实现词法分析器:利用编程语言(如Python)实现词法分析器,将源代码作为输入,根据词法规则将其分解成各种词法单元,并输出其类别。
3. 测试和调试:编写测试用例,对词法分析器进行测试和调试,确保其能够正确地识别和输出各种词法单元。
四、实验过程1. 设计词法规则:根据C语言的词法规则,我们需要设计正则表达式来描述各种词法单元的模式。
例如,关键字可以使用'|'操作符将所有关键字列举出来,标识符可以使用[a-zA-Z_][a-zA-Z0-9_]*的模式来匹配,常量可以使用[0-9]+的模式来匹配等等。
2. 实现词法分析器:我们选择使用Python来实现词法分析器。
首先,我们需要读取源代码文件,并将其按行分解。
然后,针对每一行的代码,我们使用正则表达式进行匹配,以识别各种词法单元。
最后,我们将识别出的词法单元输出到一个结果文件中。
3. 测试和调试:我们编写了一系列的测试用例,包括各种不同的C语言代码片段,以测试词法分析器的正确性和鲁棒性。
通过逐个测试用例的运行结果,我们可以发现和解决词法分析器中的问题,并进行相应的调试。
五、实验结果经过多次测试和调试,我们的词法分析器能够正确地将C语言代码分解成各种词法单元,并输出其对应的类别。
例如,对于输入的代码片段:```cint main() {int a = 10;printf("Hello, world!\n");return 0;}```我们的词法分析器将输出以下结果:```关键字:int标识符:main运算符:(运算符:)运算符:{关键字:int标识符:a运算符:=常量:10运算符:;标识符:printf运算符:(常量:"Hello, world!\n"运算符:)运算符:;关键字:return常量:0运算符:;```可以看到,词法分析器能够正确地将代码分解成各种词法单元,并输出其对应的类别。
基于LEX的C语言词法分析器
实验二C-语言的词法分析器(基于Lex)1. 课程设计目标自动构造C-语言的的词法分析器,要求能够掌握编译原理的基本理论,,理解编译程序的基本结构,掌握编译各阶段的基本理论和技术,掌握编译程序设计的基本理论和步骤.,增强编写和调试高级语言源程序的能力,掌握词法分析的基本概念和实现方法,熟悉C-语言的各种Token。
2. 分析与设计基于Parser Genarator的词法分析器构造方法Lex输入文件由3个部分组成:定义集(definition),规则集(rule)和辅助程序集(auxiliary routine)或用户程序集(user routine)。
这三个部分由位于新一行第一列的双百分号分开,因此,Lex输入文件的格式如下{definitions}%%{rules}%%{auxiliary routines}而且第一部分用“%{”和“%}”括起来。
第一和第三个部分为C语言的代码和函数定义,第二个部分为一些规则。
定义正则表达式如下ID = letter letter*NUM = digit digit*Letter = a|…|z|A|…|ZDig it = 0|…|9Keyword = else|if|int|return|void|whileSpecial symbol = +|-|*|/|<|<=|>|>=|==|!=|=|;|,|(|)|[|]|{|}|/*|*/White space = “ ”Enter = \n在lex中的构造letter [A-Za-z]digit [0-9]id ({letter}|[_])({letter}|{digit}|[_])*error_id ({digit})+({letter})+num {digit}+whitespace [ \t]+enter [\n]+在Lex中的规则定义构造定义识别保留字规则"int"|"else"|"return"|"void"|"if"|"while"{Upper(yytext,yyleng);printf("%d 行",lineno);printf("%s reserved word\n",yytext);}//保留字定义识别数字规则{num}{printf("%d 行",lineno);printf("%s NUM\n",yytext);}//数字定义识别专用符号规则","|";"|"("|")"|"{"|"}"|"*"|"/"|"+"|"-"|">"|"<"|">="|"<="|"=="|"!="|"="|"/*"|"*/" {printf("%d 行",lineno);printf("%s special symbol\n",yytext);}//特殊符号定义识别标识符规则{id}{printf("%d 行",lineno);printf("%s ID\n",yytext);}//标识符定义识别错误的字符串规则当开头为数字的后面为字母的字符串时,是错误的标识符。
词法分析器的实验报告
词法分析器的实验报告词法分析器的实验报告引言:词法分析器是编译原理中的重要组成部分,它负责将源代码中的字符序列转换为有意义的词法单元,为后续的语法分析提供基础。
本实验旨在设计和实现一个简单的词法分析器,并对其进行测试和评估。
实验设计:1. 词法规则设计:在开始实验之前,我们首先需要设计词法规则,即定义源代码中的合法词法单元。
例如,对于一门类C的语言,我们可以定义关键字(如if、while、int等)、标识符、运算符(如+、-、*等)、分隔符(如()、{}等)等。
2. 有限自动机(DFA)的设计:基于词法规则,我们可以设计一个有限自动机,用于识别和分析源代码中的词法单元。
有限自动机是一个状态转换图,其中每个状态代表一种词法单元,而边表示输入字符的转换关系。
3. 实现代码:根据有限自动机的设计,我们可以使用编程语言(如Python、C++等)实现词法分析器的代码。
代码的主要功能包括读取源代码文件、逐个字符进行词法分析、识别和输出词法单元。
实验过程:1. 词法规则设计:我们以一门简单的算术表达式语言为例,设计了以下词法规则:- 数字:由0-9组成的整数或浮点数。
- 运算符:包括+、-、*、/等。
- 分隔符:包括括号()和逗号,。
- 标识符:以字母开头,由字母和数字组成的字符串。
2. 有限自动机(DFA)的设计:我们基于词法规则,设计了一个简单的有限自动机。
该自动机包含以下状态:- 初始状态:用于读取和识别源代码中的字符。
- 数字状态:用于识别和输出数字。
- 运算符状态:用于识别和输出运算符。
- 分隔符状态:用于识别和输出分隔符。
- 标识符状态:用于识别和输出标识符。
3. 实现代码:我们使用Python编程语言实现了词法分析器的代码。
代码主要包括以下功能:- 读取源代码文件。
- 逐个字符进行词法分析,根据有限自动机的设计进行状态转换。
- 识别和输出词法单元。
实验结果:我们对几个测试样例进行了词法分析,并对结果进行了评估。
词法分析器的构造
实验报告(2015 / 2016学年第二学期)课程名称编译原理实验名称词法分析器的构造实验时间2016 年 4 月 29 日指导单位计算机软件教学中心指导教师学生姓名学院(系)wujun计算机学院、软件学院班级学号专业计算机科学与技术实验报告、实验环境(实验设备)硬件:计算机软件:Visual C ++6.0,'{') ,'int ') ,'a ') ,',') ,'b ') ,';') ,'a ') ,'=') ,'10') ,';') ,'b ') ,'=') ,'a ') ,'+') ,'20') ,';') ,'}')实验原理状态转换图(5 (1 (2 (5 (2 (5 (2 (4 (3 (5 (2 (4 (2 (4 (3 (5 (52、3、实验代码:实验代码:#i nclude <stri ng.h>#in elude <iostream.h>#in elude <fstream>#in clude<stdlib.h>#i nclude<stdio.h>#in clude<ctype.h>struct Char{ //创建一个结构用于存贮关键字char a[15];};typedef struct Char CH;//定义关键字CH keyWord[67]={"auto","break","case","cout","cin","char","const","continue","d efault", "do","double","else","e num","e ndl","extern","float","for","goto","if","mai n", "in clude","int","lo ng","register","return","short","sig ned","sizeof","static","string","struct","switch","typed ef","union","unsigned","void","stdio","whil e", "ci n"."cout"."catch","calss"."ctype"."stdlib"."fstream"."export"."iostream",cout<v"(2,'"vvwordvv"')"vve ndl; }else if(lsDigit(ch)){do{word[i++] = ch; ch = s[++j];}whil e(IsDigit(ch));j--;word[i] = '\0';cout<<"(3,'"<<word<<"')"<<e ndl;}else if(lsSeparator(ch)){word[0] = ch;cout<<"(5,'"<<word<<"')"<<e ndl;}else{word[0] = ch;if(word[0]=='+'||word[0]=='-'||word[0]=='>'||word[0]=='v'||word[0]=='&'||word[0]=='|'){ if(s[j+1]==word[0] || s[j+1]=='='){word[1] = s[++j]; cout<v"(4,'"vvwordvv"')"vve ndl;} elsecout<v"(4,'"vvwordvv"')"vve ndl;}else if(word[0]=='='||word[0]=='*'||word[0]=='/'||word[0]=='!'||word[0]=='%'||word[0]==z){ if (s[j+1] == '='){word[1] = s[++j]; cout<v"(4,'"vvwordvv"')"vve ndl;} elsecout<v"(4,'"vvwordvv"')"vve ndl;}else if (word[0] == '\\'){if (s[j+1] == 'n' ||s[j+1] == 't' || s[j+i]=='\\'||s[j+1]=='0'){ word[1] = s[++j];cout<v"(4,'"vvwordvv"')"vve ndl;} elsecout<v"(4,'"vvwordvv"')"vve ndl;―U输入代码:Please input you code 'ieoid wi th two^ T7): int mainO(int辺,b;//定义a・bd += 10.b - a十12.舛求b的值*/return 0;}??输出结果:系统经HfOl理后的输出(去掉注释和换行):int mainO { int a,b; a +- 10; b - a + 12; return 0; }. 系统经ii预处理冶的输岀〔去掉注释、换行、空格等):intminO {in坦b; a+=10 ; b-a +12 ! returnO !]词袪分析如下: (1,J int')(1,J mair?)(5,J C )(和门(5/ f )(1; int1〕⑵’『)⑸;)(2f' b') E ;)伦J a )(4,7匸)(3,' 10')⑸’:1、⑵'b1)(4,,J、(2/『)(4,1匸)<3,'挖)(1, ?return7)(3,' 0’ )(5/ r)(5, 丁)(2)测试二截图输入代码:Please input you code (end with two* ?'): do [ch = getchar(J ;s[i++] - ch;if(ch == 1\n |I ch== 3) for (int j =0; j < 4;j++) fputc (b, fp);fputc(ch, ip);用Ml e(s[i-l] != ??7| | s[i-2] != J输出结果:系统经过预处理后的输出(±4f注释和换行):,dn C ch = setcha.rO : s[i+*] = ch; if (ch == 1\n" | | ch==| \t* ) f cr L int j =U ;j € 4b j++) fputc (b^ fp) ; f putc (ch, fp); }wiiil日(s[iT] ! = ? 1 || s[i-2] I = ? ?;系统经过预处理后的输出(去掉注釋■换了亍、空梅等)=do 呂e tchar () ; s[i ■*-+■] -ch; if tch==,\n | |ch-=,\t?or (ini j=0; j<4; J-H-)fpoitc(b, fp): fputctch, fp):} flhile(s[i^l] \-r r \ |s[i-2]!=,,):词法分析如T:(1/dD1) (5/C)(2, ' eh J) 任,』)(2,11 get char?) (5/ (!) (5QJ (5/;5) Qd) (5「[') (2/iJ(4,1卄')(妇」) ⑵’山)(5,―)⑸’f )(2?T川)(5,…) 他’\n)(5,…)四、实验小结(包括问题和解决方法、心得体会、意见与建议等)在本实验中,我进一步学习了如何运用输入输出流,对文件进行读写操作。
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
实验二词法分析器的构造
一、实验目的
掌握词法分析器的构造原理,掌握手工编程或LEX编程方法之一。
二、实验内容
编写一个词法分析器,能够将输入的源程序转换为单词序列输出。
三、实验指南
1.正则表达式定义
(1)该语言的关键字:if while do break real true false int char bool float (其中,int、char、bool、float在产生式中为basic)
所有的关键字都是保留字,并且必须是小写。
if|then|else|while|do|break|real|true|false|int|char|bool|float
(2)id和num的正则表达式定义;
letter [A-Za-z]
digit [0-9]
id {letter}({letter}|{digit})*
number {digit}+(\.{digit}+)?(E[+-]?{digit}+)?
(3)专用符号:+ - * / < <= > >= == != = ; , ( ) [ ] { }
relop <|<=|=|<>|>|>=|==|!=|=
addop "+"|"-"|"*"|"/"|";"|","|"("|")"|"["|"]"|"{"|"}"
(4)空格由空白、换行符和制表符组成。
空格通常被忽略,除了它必须分开I D、N U M关键字。
delim [ \t \n ]
ws {delim}+
(5)考虑注释。
注释由/*和*/包含。
注释可以放在任何空白出现的位置,且可以超过一行。
注释不能嵌套。
zhushi "/*"(\"\*\/\"|[^*/]|"*"[^/]|[^*]"/"|\/\*)*"*/"
2.源程序测试示例
要求应自行准备多个源程序片段,运行并测试输出是否合符要求。
示例1:
源程序输入:
{
int i;
if ( i >= 0) i = i + 1;
}
输出token序列如下:
示例2:
源程序片段:
{
int i; int j; float v; float x; float[100] a;
while ( true) {
do i = i + 1; while ( a[i] < v);
do j = j - 1; while ( a[j] > v);
if ( i >= j ) break;
x = a[i]; a[i] = a[j]; a[j] = x;
}
}
实例3:
/**chenhuajie*”/”***/
四、心得体会
通过本次实验,我更加了解正则表达式的用法。
掌握了用flex生成词法程序
的方法。
变编译原理这门课有了更具体的认识。