计量作业计量经济学第三版李子奈
(NEW)李子奈《计量经济学》(第3版)课后习题详解

目 录第1章 绪 论第2章 经典单方程计量经济学模型:一元线性回归模型第3章 经典单方程计量经济学模型:多元线性回归模型第4章 经典单方程计量经济学模型:放宽基本假定的模型第5章 经典单方程计量经济学模型:专门问题第6章 联立方程计量经济学模型:理论与方法第7章 扩展的单方程计量经济学模型第8章 时间序列计量经济学模型第9章 计量经济学应用模型第1章 绪 论1什么是计量经济学?计量经济学方法与一般经济数学方法有什么区别?答:(1)计量经济学是经济学的一个分支学科,以揭示经济活动中客观存在的数量关系为主要内容,是由经济理论、统计学和数学三者结合而成的交叉学科。
(2)计量经济学方法通过建立随机的数学方程来描述经济活动,并通过对模型中参数的估计来揭示经济活动中各个因素之间的定量关系,是对经济理论赋予经验内容;而一般经济数学方法是以确定性的数学方程来描述经济活动,揭示的是经济活动中各个因素之间的理论关系。
2计量经济学的研究对象和内容是什么?计量经济学模型研究的经济关系有哪两个基本特征?答:(1)计量经济学的研究对象是经济现象,主要研究的是经济现象中的具体数量规律,即是利用数学方法,依据统计方法所收集和整理到的经济数据,对反映经济现象本质的经济数量关系进行研究。
(2)计量经济学的内容大致包括两个方面:一是方法论,即计量经济学方法或理论计量经济学;二是应用计量经济学。
任何一项计量经济学研究和任何一个计量经济学模型赖以成功的三要素是理论、方法和数据。
(3)计量经济学模型研究的经济关系的两个基本特征是随机关系和因果关系。
3为什么说计量经济学在当代经济学科中占据重要地位?当代计量经济学发展的基本特征与动向是什么?答:(1)计量经济学自20世纪20年代末30年代初形成以来,无论在技术方法还是在应用方面发展都十分迅速,尤其是经过20世纪50年代的发展阶段和60年代的扩张阶段,使其在经济学科占据重要的地位,主要表现在:①在西方大多数大学和学院中,计量经济学的讲授已成为经济学课程表中最具有权威的一部分;②从1969~2003年诺贝尔经济学奖的53位获奖者中有10位是与研究和应用计量经济学有关;③计量经济学方法与其他经济数学方法结合应用得到了长足的发展。
计量经济学实验三--李子奈
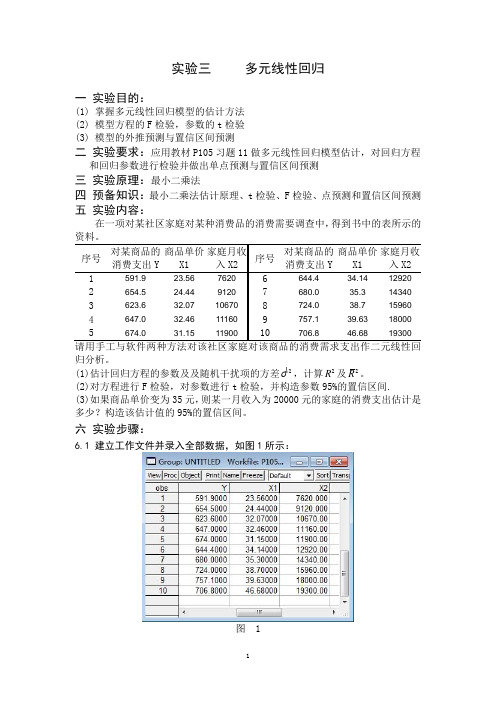
实验三 多元线性回归一 实验目的:(1) 掌握多元线性回归模型的估计方法 (2) 模型方程的F 检验,参数的t 检验 (3) 模型的外推预测与置信区间预测二 实验要求:应用教材P105习题11做多元线性回归模型估计,对回归方程和回归参数进行检验并做出单点预测与置信区间预测 三 实验原理:最小二乘法四 预备知识:最小二乘法估计原理、t 检验、F 检验、点预测和置信区间预测 五 实验内容:在一项对某社区家庭对某种消费品的消费需要调查中,得到书中的表所示的序号对某商品的消费支出Y 商品单价X1 家庭月收入X2 序号对某商品的消费支出Y 商品单价X1 家庭月收入X2 1 591.9 23.56 7620 6 644.4 34.14 12920 2 654.5 24.44 9120 7 680.0 35.3 14340 3 623.6 32.07 10670 8 724.0 38.7 15960 4 647.0 32.46 11160 9 757.1 39.63 18000 5 674.0 31.15 11900 10706.8 46.68 19300 归分析。
(1)估计回归方程的参数及及随机干扰项的方差2,计算2R 及2R 。
(2)对方程进行F 检验,对参数进行t 检验,并构造参数95%的置信区间. (3)如果商品单价变为35元,则某一月收入为20000元的家庭的消费支出估计是多少?构造该估计值的95%的置信区间。
六 实验步骤:6.1 建立工作文件并录入全部数据,如图1所示:图 16.2 建立二元线性回归模型01122Y X X βββ=++点击主界面菜单Quick\Estimate Equation 选项,在弹出的对话框中输入:Y C X1 X2点击确定即可得到回归结果,如图2所示图 2根据图2的信息,得到回归模型的估计结果为:626.51939.790610.02862(15.61)( 3.06)(4.90)Y X X =-+-20.902218R = 20.874281R = .. 1.650804D W =22116.847i e =∑ 32.29408F = (2,7)df =随机干扰项的方差估计值为22116.847302.40677σ∧==6.3 结果的分析与检验 6.3.1 方程的F 检验 回归模型的F 值为:32.29408F =因为在5%的显著性水平下,F 统计量的临界值为0.05(2,7) 4.74F =所以有 0.05(2,7)F F > 所以回归方程通过F 检验,方程显著成立。
计量经济学---第三版-李子奈---课后习题--答案

ÿÿÿÿÿ******************************************************************************************************************************* ***********************ÿÿÿÿÿÿÿÿÿÿÿÿ第一章绪论(一)基本知识类题型1-1.什么是计量经济学?1-3.计量经济学方法与一般经济数学方法有什么区别?它在经济学科体系中的作用和地位是什么?1-6.计量经济学的研究的对象和内容是什么?计量经济学模型研究的经济关系有哪两个基本特征?1-7.试结合一个具体经济问题说明建立与应用计量经济学模型的主要步骤。
1-9.计量经济学模型主要有哪些应用领域?各自的原理是什么?1-12.模型的检验包括几个方面?其具体含义是什么?1-17.下列假想模型是否属于揭示因果关系的计量经济学模型?为什么?⑴ S t其中S t为第t年农村居民储蓄增加额(亿元)、R t为第t年城镇居民可支配收入总额(亿元)。
⑵ S t1其中S t1为第(t1)年底农村居民储蓄余额(亿元)、R t为第t年农村居民纯收入总额(亿元)。
1-18.指出下列假想模型中的错误,并说明理由:(1)RS t RI t其中,RS t为第t年社会消费品零售总额(亿元),RI t为第t年居民收入总额(亿元)(城镇居民可支配收入总额与农村居民纯收入总额之和),IV t为第t年全社会固定资产投资总额1(亿元)。
(2)C t180其中,C、Y分别是城镇居民消费支出和可支配收入。
(3)ln Y t ln K t L t其中,Y、K、L分别是工业总产值、工业生产资金和职工人数。
李子奈《计量经济学》第三版例题及习题的stata解答

第二章例.1(p24)(1)表中E(Y|X=800)即条件均值的求法,将数据直接复制到stata 中。
程序:sum y if x==800程序:程序:(2)图的做法: 程序:twoway(scatter y x )(lfit y x ),title("不同可支配收入水平组家庭消费支出的条件分布图")xtitle("每月可支配收入(元)")ytitle("每月消费支出(元)")xtick(500(500)4000)ytick(0(500)3500)、例.1(p37)将数据直接复制到stata中程序:(1)total xiyixiyi 4974750 1507821 1563822 8385678Total Std. Err. [95% Conf. Interval]return listscalars:-r(skip) = 0r(first) = 1r(k_term) = 0r(k_operator) = 0r(k) = 0r(k_level) = 0r(output) = 1r(b) = 4974750r(se) =g a=r(b) in 1#Scatter表示散点图选项,lfit表示回归线,title表示题目,xtick表示刻度,(500(500)4000)分别表示起始刻度,中间数表示以单位刻度,4000表示最后的刻度。
要注意的是命令中的符号都要用英文字符,否则命令无效。
这个图可以直接复制的,但是由于我的软件出问题,只能直接剪切,所以影响清晰度。
Total表示求和,return list命令可以引用其中的数据,接下来在第一列生成一个新的变量代表xiyi的和,同样生成一个b代表xi平方的,a除以b即可得到batatotal xi2return listg b=r(b) in 1di a/b.67(2)mean Yigen m=r(b) in 1mean Xi(g n=r(b) in 1di m-n*由此得到回归方程:Y=+例.2(p53)程序:(1)回归reg y x(2) >(3) 求X 的样本均值和样本方差:mean xx 11363.69 591.7041 10155.27 12572.11 Mean Std. Err. [95% Conf. Interval] Mean estimation Number of obs = 31sum x ,d (d 表示detail 的省略,这个命令会产生更多的信息)99% 20667.91 20667.91 Kurtosis 4.73926795% 19977.52 19977.52 Skewness 1.69197390% 16015.58 18265.1 Variance 1.09e+0775% 12192.24 16015.58Largest Std. Dev. 3294.46950% 9898.75 Mean 11363.6925% 9267.7 9000.35 Sum of Wgt. 3110% 9000.35 8941.08 Obs 31 5% 8920.59 8920.591% 8871.27 8871.27 Percentiles Smallest xdi r(Var)(特别注意Var 的大小写)例(P56) (1)reg Y X>Source SS df MS Number of obs = 29 F( 1, 27) = 2214.60 Model 2.4819e+09 1 2.4819e+09 Prob > F = 0.0000 Residual 30259023.9 27 1120704.59 R-squared = 0.9880 Adj R-squared = 0.9875 Total 2.5122e+09 28 89720219.8 Root MSE = 1058.6 Y Coef. Std. Err. t P>|t| [95% Conf. Interval]X .4375268 .0092973 47.06 0.000 .4184503 .4566033 _cons 2091.295 334.987 6.24 0.000 1403.959 2778.632(2)图的绘制:twoway (line Y X year),title("中国居民可支配总收入X与消费总支出Y 的变动图")~第三章例(p72)reg Y X1 X2&Source SS df MS Number of obs = 31F( 2, 28) = 560.57Model 166971988 2 83485994.2 Prob > F = 0.0000Residual 4170092.27 28 148931.867 R-squared = 0.9756Adj R-squared = 0.9739Total 171142081 30 5704736.02 Root MSE = 385.92Y Coef. Std. Err. t P>|t| [95% Conf. Interval]X1 .5556438 .0753076 7.38 0.000 .4013831 .7099046X2 .2500854 .1136343 2.20 0.036 .0173161 .4828547_cons 143.3266 260.4032 0.55 0.586 -390.0851 676.7383例.1(p85)g lnP1=ln(P1)g lnP0=ln(P0)g lnQ=ln(Q)g lnX=ln(X)Source SS df MS Number of obs = 22 F( 3, 18) = 258.84 Model .765670868 3 .255223623 Prob > F = 0.0000 Residual .017748183 18 .00098601 R-squared = 0.9773 Adj R-squared = 0.9736 Total .783419051 21 .037305669 Root MSE = .0314 lnQ Coef. Std. Err. t P>|t| [95% Conf. Interval]lnX .5399167 .0365299 14.78 0.000 .4631703 .6166631 lnP1 -.2580119 .1781856 -1.45 0.165 -.632366 .1163422 lnP0 -.2885609 .2051844 -1.41 0.177 -.7196373 .1425155 _cons 5.53195 .0931071 59.41 0.000 5.336339 5.727561 drop lnX lnP1 lnP0g lnXP0=ln(X/P0)g lnP1P0=ln(P1/P0)?reg lnQ lnXP0 lnP1P0Source SS df MS Number of obs = 22F( 2, 19) = 408.93Model .765632331 2 .382816165 Prob > F = 0.0000Residual .01778672 19 .000936143 R-squared = 0.9773Adj R-squared = 0.9749Total .783419051 21 .037305669 Root MSE = .0306lnQ Coef. Std. Err. t P>|t| [95% Conf. Interval]lnXP0 .5344394 .0231984 23.04 0.000 .4858846 .5829942lnP1P0 -.2753473 .1511432 -1.82 0.084 -.5916936 .040999_cons 5.524569 .0831077 66.47 0.000 5.350622 5.698515练习题13(p105)g lnY=ln(Y)g lnK=ln(K)g lnL=ln(L)reg lnY lnK lnLSource SS df MS Number of obs = 31 F( 2, 28) = 59.66 Model 21.6049266 2 10.8024633 Prob > F = 0.0000 Residual 5.07030244 28 .18108223 R-squared = 0.8099 Adj R-squared = 0.7963 Total 26.6752291 30 .889174303 Root MSE = .42554 lnY Coef. Std. Err. t P>|t| [95% Conf. Interval]lnK .6092356 .1763779 3.45 0.002 .2479419 .9705293 lnL .3607965 .2015915 1.79 0.084 -.0521449 .7737378 _cons 1.153994 .7276114 1.59 0.124 -.33645 2.644439第二问:test b_[lnk]+b_[lnl]==1*第四章¥例.4 (P116)(1)回归g lnY=ln(Y)g lnX1=ln(X1)g lnX2=ln(X2)reg lnY lnX1 lnX2Source SS df MS Number of obs = 31 F( 2, 28) = 49.60 Model 2.9609923 2 1.48049615 Prob > F = 0.0000 Residual .835744123 28 .029848004 R-squared = 0.7799 Adj R-squared = 0.7642 Total 3.79673642 30 .126557881 Root MSE = .17277 lnY Coef. Std. Err. t P>|t| [95% Conf. Interval]lnX1 .1502137 .1085379 1.38 0.177 -.072116 .3725435 lnX2 .4774534 .0515951 9.25 0.000 .3717657 .5831412 _cons 3.266068 1.041591 3.14 0.004 1.132465 5.39967于是得到方程:lnY=++(2)绘制参差图:"predict e, residg ei2=e^2scatter ei2 lnX2,title("图异方差性检验图")xtick(6ytick(0predict在回归结束后,需要对拟合值以及残差进行分析,需要使用此命令。
计量经济学李子奈第三版STATA答案

[856.20328+2.356*17.39*sqrt(1+4.5389992), 856.20328-2.356*17.39*sqrt(1+4.5389992) ] =[ 759.77809, 952.51758] 均值E(Y0)的置信区间: 856.20328+2.356*17.39*sqrt(4.5389992), 856.20328-2.356*17.39*sqrt(4.5389992) ] =[ 768.58,943.82]
2
yt xt
• 作为数理经济学模型是正确的,作为计量经济学模型则 不是正确的。计量经济学模型中必须包含随机误差项。 (2) y xt
t
t
正确。作为计量经济学模型它是正确的。该模型是经济计量模型的 理论模型,理论模型由被解释变量、解释变量、随机误差项、待估 计的参数和运算符构成。
• 7.下列假设模型是否属于揭示因果关系的计量经济模型?为什 么? • (1)St=112.0+0.12Rt • 其中St为第t年农村居民储蓄增加额(亿元), Rt为第t年城镇居 民可支配收入总额(亿元)。 • (2)St-1=4432.0+0.30Rt • 其中St-1为第t-1年农村居民储蓄增加额(亿元),Rt为第t年农村 居民可支配收入总额(亿元)。 • 解: (1)式不是揭示因果关系的计量经济模型。根据经济学理 论,储蓄额是由收入决定的,农村居民的储蓄额应由农村居民的 纯收入总额决定,而不是由城镇居民可支配收入总额决定。 (2)式中还存在时间动态上的逻辑错误,当年的收入不可能确 定上一年的储蓄,即今日事件确定昨日(已经发生)的事件。 1
. adjust x1=35 x2=20000,ci stdf Dependent variable: y Command: regress Covariates set to value: x1 = 35, x2 = 20000
《计量经济学》第三版课后题答案李子奈

第一章绪论(一)参考重点:计量经济学的一般建模过程第一章课后题(1.4.5)1.什么是计量经济学?计量经济学方法与一般经济数学方法有什么区别?答:计量经济学是经济学的一个分支学科,是以揭示经济活动中客观存在的数量关系为内容的分支学科,是由经济学、统计学和数学三者结合而成的交叉学科。
计量经济学方法揭示经济活动中各个因素之间的定量关系,用随机性的数学方程加以描述;一般经济数学方法揭示经济活动中各个因素之间的理论关系,用确定性的数学方程加以描述。
4.建立与应用计量经济学模型的主要步骤有哪些?答:建立与应用计量经济学模型的主要步骤如下:(1)设定理论模型,包括选择模型所包含的变量,确定变量之间的数学关系和拟定模型中待估参数的数值范围;(2)收集样本数据,要考虑样本数据的完整性、准确性、可比性和—致性;(3)估计模型参数;(4)检验模型,包括经济意义检验、统计检验、计量经济学检验和模型预测检验。
5.模型的检验包括几个方面?其具体含义是什么?答:模型的检验主要包括:经济意义检验、统计检验、计量经济学检验、模型的预测检验。
在经济意义检验中,需要检验模型是否符合经济意义,检验求得的参数估计值的符号与大小是否与根据人们的经验和经济理论所拟订的期望值相符合;在统计检验中,需要检验模型参数估计值的可靠性,即检验模型的统计学性质;在计量经济学检验中,需要检验模型的计量经济学性质,包括随机扰动项的序列相关检验、异方差性检验、解释变量的多重共线性检验等;模型的预测检验主要检验模型参数估计量的稳定性以及对样本容量变化时的灵敏度,以确定所建立的模型是否可以用于样本观测值以外的范围。
第二章经典单方程计量经济学模型:一元线性回归模型参考重点:1.相关分析与回归分析的概念、联系以及区别?2.总体随机项与样本随机项的区别与联系?3.为什么需要进行拟合优度检验?4.如何缩小置信区间?(P46)由上式可以看出(1).增大样本容量。
样本容量变大,可使样本参数估计量的差减小;同时,在同样置信水平下,n越大,t分布表中的临界值越小。
李子奈第三版计量经济学常考简答题
李子奈第三版计量经济学常考简答题1回归分析与相关分析的联系和区别?回归分析是讨论被解释变量与一个或多个解释变量之间具体依存关系的分析方法。
相关分析是讨论变量之间线性相关程度的分析方法。
联系:两者都是研究非确定性变量间的统计依赖关系,并能度量线性依赖程度大小。
区别:1)研究的目的不同,相关分析着重讨论变量间的关联程度,而回归分析却要进一步探寻变量间具体依赖关系。
2)对变量的处理不同,相关分析堆成的处理相互联系的变量,而回归分析必须明确解释变量与被解释变量。
2什么是随机干扰项?主要包括哪些因素?和残差的区别?随机干扰项是指总体观测值与回归方程理论值之间的偏差。
因素:(1)众多细小因素的影响;(2)未知因素的影响;(3)数据测量误差或残缺;(4)模型形式不完善;(5)变量的内在随机性。
随机误差项与残差不同,残差是样本观测值与回归方程理论值之间的偏差。
残差项是随机误差项的一个样本估计量。
3为什么用可决系数评价拟合优度,而不用残差平方和?可决系数与相关系数的联系和区别?可决系数R*2=ESS/TSS=1-RSS/TSS,含义为由解释变量引起的被解释变量的变化占被解释变量总变化的比重,用来判定回归直线拟合的优劣,该值越大说明拟合得越好,而残差平方和与样本容量关系密切,当样本容量比较小时,残差平方和的值也比较小,尤其是不同样本得到的残差平方和是不能作比较的。
此外作为检验统计量的一般应是相对量而不能用绝对量,因而不能使用残差平方和判断模型的拟合优度。
4、简述最小二乘估计量的特征及高斯马尔可夫定理。
答:(1)线性性,即它是否是另一随机变量的线性函数;(2)无偏性,即它的均值或期望值是否等于总体的真实值;(3)有效性,即它是否在所有线性无偏估计量中具有最小方差。
(4)渐近无偏性,即样本容量趋于无穷大时,是否它的均值序列趋于总体真值;(5)一致性,即样本容量趋于无穷大时,它是否依概率收敛于总体的真值;(6)渐近有效性,即样本容量趋于无穷大时,是否它在所有的一致估计量中具有最小的渐近方差。
《计量经济学》李子奈第三版课后习题Eviews实验报告
《计量经济学》实验报告实验一:EViews5.0软件安装及基本操作1.Eviews5.0的安装过程解压安装包,双击“Setup.exe”,选择安装路径进行安装;安装完毕后,复制“eviews5.0破解文件夹”下的“eviews5.reg文件”和“eviews5.exe文件”到安装目录下;双击“Eviews5.reg”进行注册,安装完毕。
2.基本操作(数据来源于李子奈版课后习题P61.12)运行Eviews,依次单击file→new→work file→unstructed→observation 31。
命令栏中输入“data y gdp”,打开“y gdp”表,接下来将数据输入其中。
做出“y gdp”的散点图,依次单击quick→graph→scatter→gdp y。
结果如下:开始进行LS回归:回归方程为:Y = -10.39340931 + 0.0710********GDP对回归方程做检验:斜率项t值9.59大于t在5%显著水平下的检验值2.045,拒绝零假设;截距项t 值0.121小于2.045,接受零假设。
可决系数0.76,拟合较好,方程F检验值91.99通过F检验。
下面进行预测:拓展工作空间:打开work file窗口,单击 Proc→Structure,将End date 的数据31→32;确定预测值的起止日期:打开work file窗口,点击Quick→Sample,填入“1 32”。
打开GDP数据表,在GDP的最下方填,按回车键。
在出现的Equation界面,点击Forecast出现相应界面如下:实验二:回归模型的建立与检验(数据来源于李子奈版课后习题P105.11)运行Eviews,依次单击file→new→work file→unstructed→observation 10。
命令栏中输入“data y x1 x2”,打开“y x1 x2”表,接下来将数据输入其中。
开始进行LS回归:估计方程:依次单击view→representations,得到回归方程为:Y = 626.5092847 - 9.790570097*X1 + 0.028*********X2,参数估计完毕。
计量经济学(第三版)李子奈 潘文卿 编著 第二章第12题答案
计量经济学(第三版)李子奈潘文卿编著第二章第12题解题答案P61:1.作散点图,建立税收和GDP的一元线性回归方程,解释斜率经济意义。
1.1散点图图表1税收Y和国内生产总值GDP散的样本点图1.2税收Y随国内总值GDP(X)变化的一元线性回归方程,以及斜率的经济意义。
图表2中国内地税收的平均状态对国内生产总值平均状态的回归∴又回归估计结果可得一元线性回归方程为Y I=-10.6296+0.0710X I斜率的经济意义:表示国内生产总值GDP每1元的变化所引起的税收的平均变化为0.071.2.对建立的回归方程进行检验。
2.1拟合优度检验----可决系数R2统计量从回归估计的结果看,模型拟合还行。
可决系数R2=0.7603,表明税收变化的76.03%可以由国内生产总值GDP的变化来解释。
2.2变量的显著性检验假设:H0:βi=0 H1:βi≠0给定显著性性水平0.05,查t分布表得到临界值t(a/2)(31-2)=2.045i.对于β1,从回归分析结果中斜率的t检验值来看9.591245>2.045,所以在95%的置信度下拒绝原假设H0,即变量X是显著的,通过显著性检验。
ii.对于β0,从回归分析结果中截距t检验值来看-0.1235<2.045, 所以在95%的置信度下接受原假设H0,没有通过显著性检验。
3.若2008年某地区GDP为8500亿元,求该地区税收收入的预测值及预测区间?解:由回归方程Y I=-10.6296+0.0710X I可得该地区税收收入的预测值Y=-10.6296+0.0710x8500=592.8704(亿元)由于国民生产总值X的样本均值和样本方差为:E(X)=8891.126 Vax(X)=5782313在给定95%的置信度水平下,该地区税收收入的预测区间为:=592.704±641.288或(-48.584,1233.992)。
《计量经济学》第三版课后题答案李子奈
第一章绪论【2 】参考重点:计量经济学的一般建模进程第一章课后题(1.4.5)1.什么是计量经济学?计量经济学办法与一般经济数学办法有什么差别?答:计量经济学是经济学的一个分支学科,是以揭示经济运动中客不雅消失的数量关系为内容的分支学科,是由经济学.统计学和数学三者结合而成的交叉学科.计量经济学办法揭示经济运动中各个身分之间的定量关系,用随机性的数学方程加以描写;一般经济数学办法揭示经济运动中各个身分之间的理论关系,用肯定性的数学方程加以描写.4.树立与运用计量经济学模子的重要步骤有哪些?答:树立与运用计量经济学模子的重要步骤如下:(1)设定理论模子,包括选择模子所包含的变量,肯定变量之间的数学关系和拟定模子中待估参数的数值规模;(2)收集样本数据,要斟酌样本数据的完全性.精确性.可比性和—致性;(3)估量模子参数;(4)磨练模子,包括经济意义磨练.统计磨练.计量经济学磨练和模子猜测磨练.5.模子的磨练包括几个方面?其具体寄义是什么?答:模子的磨练重要包括:经济意义磨练.统计磨练.计量经济学磨练.模子的猜测磨练.在经济意义磨练中,须要磨练模子是否相符经济意义,磨练求得的参数估量值的符号与大小是否与根据人们的经验和经济理论所订定的期望值相相符;在统计磨练中,须要磨练模子参数估量值的靠得住性,即磨练模子的统计学性质;在计量经济学磨练中,须要磨练模子的计量经济学性质,包括随机扰动项的序列相干磨练.异方差性磨练.解释变量的多重共线性磨练等;模子的猜测磨练重要磨练模子参数估量量的稳固性以及对样本容量变化时的敏锐度,以肯定所树立的模子是否可以用于样本不雅测值以外的规模.第二章经典单方程计量经济学模子:一元线性回归模子参考重点:1.相干剖析与回归剖析的概念.接洽以及差别?2.总体随机项与样本随机项的差别与接洽?3.为什么须要进行拟合优度磨练?4.若何缩小置信区间?(P46)由上式可以看出(1).增大样本容量.样本容量变大,可使样本参数估量量的标准差减小;同时,在同样置信程度下,n 越大,t 散布表中的临界值越小.(2)进步模子的拟合优度.因为样本参数估量量的标准差和残差平方和呈正比,模子的拟合优度越高,残差平方和应越小.5.以一元线性回归为例,写出β0的假设磨练1).对总体参数提出假设H 0:β0=0,H 1:β0≠02)以原假设H0构造t 统计量,3)由样本盘算其值 4)给定明显性程度α,查t 散布表得临界值t α/2(n-2)0ˆ0ˆββS t =)2(~ˆˆˆ0ˆ0022200--=-=∑∑n t S x n X t i i βββσββαβββββαα-=⨯+<<⨯-1)ˆˆ(ˆˆ22i i s t s t P i i i5)比较,断定若|t|> t α/2(n-2),则谢绝H0,接收H1;若|t|≤ t α/2(n-2),则谢绝H1,接收H0;上届重点:一元线性回归模子的根本假设.随机误差项产生的原因.最小二乘法.参数经济意义.决议系数.第二章PPT里的表(中国居平易近人均花费支出对人均GDP的回归).t磨练(△(平方)代表意义;△(平方)的熟习).可以或许读懂Eviews输出的估量成果第二章课后题(1.3.9.10)1.为什么计量经济学模子的理论方程中必须包含随机干扰项?(经典模子中产生随机误差的原因)答:计量经济学模子考核的是具有因果关系的随机变量间的具体接洽方法.因为是随机变量,意味着影响被解释变量的身分是庞杂的,除了解释变量的影响外,还有其他无法在模子中自力列出的各类身分的影响.如许,理论模子中就必须运用一个称为随机干扰项的变量宋代表所有这些无法在模子中自力表示出来的影响身分,以保证模子在理论上的科学性.3.一元线性回归模子的根本假设重要有哪些?违反根本假设的模子是否不可以估量?答:线性回归模子的根本假设有两大类:一类是关于随机干扰项的,包括零均值,同方差,不序列相干,知足正态散布等假设;另一类是关于解释变量的,重要有:解释变量长短随机的,若是随机变量,则与随机干扰项不相干.现实上,这些假设都是针对通俗最小二乘法的.在违反这些根本假设的情形下,通俗最小二乘估量量就不再是最佳线性无偏估量量,是以运用通俗最小二乘法进行估量己无多大意义.但模子本身照样可以估量的,尤其是可以经由过程最大似然法等其他道理进行估量.假设1. 解释变量X是肯定性变量,不是随机变量;假设2. 随机误差项μ具有零均值.同方差和不序列相干性:E(μi)=0i=1,2, …,nVar (μi)=σμ2 i=1,2, …,nCov(μi, μj )=0i≠j i,j= 1,2, …,n假设3. 随机误差项μ与解释变量X 之间不相干:Cov(X i , μi )=0 i=1,2, …,n假设4.μ屈服零均值.同方差.零协方差的正态散布μi ~N(0, σμ2 ) i=1,2, …,n假设5. 跟着样本容量的无穷增长,解释变量X 的样本方差趋于一有限常数.即∞→→-∑n Q n X X i ,/)(2假设6. 回归模子是精确设定的9.10题为盘算题,见教材P52,答案见P17第三章 经典单方程计量经济学模子:多元线性回归模子上届重点:F 磨练.t 磨练 调剂的样本决议系数.“多元”里为什么要对△(平方)系数进行调剂?第三章课后题(1.2.7.9.10)1.多元线性回归模子的根本假设是什么?在证实最小二乘估量量的无偏性和有用性的进程中,哪些根本假设起了感化?答:多元线性回归模子的根本假定仍然是针对随机干扰项与针对解释变量两大类的假设.针对随机干扰项的假设有:零均值,同方差,无序列相干且屈服正态散布.针对解释量的假设有;解释变量应具有非随机性,假如后随机的,则不能与随机干扰项相干;各解释变量之间不消失(完全)线性相干关系.在证实最小二乘估量量的无偏性中,运用了解释变量非随机或与随机干扰项不相干的假定;在有用性的证实中,运用了随机干扰项同方差且无序列相干的假定.2.在多元线性回归剖析中,t 磨练和F 磨练有何不同?在一元线性回归剖析中二者是否有等价感化?(见教材P70)答:在多元线性回归剖析中,t 磨练常被用作磨练回归方程中各个参数的明显性,而F 磨练则被用作磨练全部回归关系的明显性.各解释变量结合起来对被解释变量有明显的线性关系,并不意味着每一个解释变量分离对被解释变量有明显的线性关系.在一元线性回归剖析中,二者具有等价感化,因为二者都是对配合的假设——解释变量的参数等于零一一进行磨练.7.9.10题为盘算题,见教材P91,答案见P53第四章经典单方程计量经济学模子:放宽根本假定的模子重点控制:参考重点:1.以多元线性回归为例解释异方差性会产生如何的后果?(可能为阐述题)2.磨练.修改异方差性的办法?3.以多元线性回归为例解释序列相干会产生如何的后果?(猜测,矩阵表达式推到)4.磨练.修改序列相干的办法?5.什么是DW磨练法(前提前提)?6.以多元线性回归为例解释多重共线性会产生如何的后果7.磨练.修改多重共线性的办法?8.随机解释变量问题的三种分类?分离造成的后果是什么?9.对象变量法的前提假设1)与所替代的随机解释变量高度相干2)与随机干扰项不相干3)与模子中其他解释变量不相干,以避免消失多重共线性上届重点:异方差.序列相干.多重共线性等违反根本假设的情形产生原因.后果.辨认方法办法.D.W.广义差分法第四章课后题(1.2)1.2题为盘算题,见教材P134,答案见P84第五章经典单方程计量经济学模子:专门问题上届重点:虚拟变量的寄义与设定.滞后变量的寄义.为何参加滞后和虚拟变量第五章课后题(1.3.4.10)1.回归模子中引入虚拟变量的感化是什么?有哪几种根本的引入方法?它们各合实用于什么情形?答:在模子中引入虚拟变量,主如果为了查找某(些)定性身分对解释变量的影响.加法方法与乘法方法是最重要的引入方法.前者重要实用于定性身分对截距项产生影响的情形,后者重要实用于定性身分对斜率项产生影响的情形.除此外,还可以加法与乘法组合的方法引入虚拟变量,这时可测度定性身分对截距项与斜率项同时产生影响的情形.3.滞后变量模子有哪几种类型?散布滞后模子运用OLS办法消失哪些问题?答:滞后变量模子有散布滞后模子和自回归模子两大类,前者只有解释变量及其滞后变量作为模子的解释变量,不包含被解释变量的滞后变量作为模子的解释变量;尔后者则以当期解释变量与被解释变量的若干期滞后变量作为模子的解释变量.散布滞后模子有无穷期的散布滞后模子和有限日的散布滞后模子;自回归模子又以Coyck模子.自顺应预期模子和局部调剂模子最为多见.散布滞后模子运用OLS法消失以下问题:(1)对于无穷期的散布滞后模子,因为样本不雅测值的有限性,使得无法直接对其进行估量.(2)对于有限日的散布滞后模子,运用OLS办法会碰到:没有先验准则肯定滞后期长度,对最大滞后期的肯定往往带有主不雅随便性;假如滞后期较长,因为样本容量有限,当滞后变量数量增长时,必然使得自由度削减,将缺少足够的自由度进行估量和磨练;同名变量滞后值之间可能消失高度线性相干,即模子可能消失高度的多重共线性.4.产生模子设定偏误的重要原因是什么?模子设定偏误的后果以及磨练办法有哪些?答:产生模子设定偏误的原因重要有:模子制订者不熟习响应的理论常识;对经济问题本身熟习不够或不熟习前人的相干工作:模子制订者手头没有相干变量的数据;解释变量无法测量或数据本身消失测量误差.模子设定偏误的后果有:(1)假如漏掉了重要的解释变量,会造成OLS估量量在小样本下有偏,在大样本下非一致;对随机干扰项的方差估量也是有偏的.(2)假如包含了无关的解释变量,尽管OLS估量量具有无偏性与一致性,但不具有最小方差性.(3)假如选择了错误的函数情势,则后果是全方位的,不但会造成估量的参数具有完全不同的经济意义,并且估量成果也不同.对模子设定偏误的磨练办法有:磨练是否含有无关变量,可以运用t磨练与F磨练完成:磨练是否有相干变量的漏掉或函数情势设定偏误,可以运用残差图示法,Ramsey提出的RESET磨练来完成.10.简述约化建模理论与传统理论的异同点?答:Hendry的约化建模理论的焦点是“从一般到简略”的建模思惟,即起首提出一个包括各类身分在内的“一般”模子,然后再经由过程不雅测数据,运用各类磨练对模子进行磨练并化简,最后得到一个相对简略的模子.传统建模理论的主导思惟是“从简略到庞杂”的建模思惟,它起首提出一个简略的模子,然后从各类可能的备选变量中选择恰当的变量进入模子,最后得到一个与数据拟合较好的较为庞杂的模子.从二者的重要接洽上看,它们都以对经济现象的解释为目的,以已有的经济理论为建模根据,以对数据的拟合程度作为模子好坏的重要的剖断标准之一,也都有若干磨练标推.从二者的重要差别上看,传统的建模理论往往更依附于某种单一的经济理论,旧“从一般到简略”的建模理论则更重视将各类不同经济理论纳入到最初的“一般”模子中,甚至更多地是从直觉和经验来树立“一般”的模子;尽管两者都有若干种磨练标准,但约化建模理论从实践上有更大量的诊断性磨练来看每一步建模的可行性,或查找改良模子的路径:与传统建模实践中消失的过渡“数据开采”问题比拟,因为约化建模理论的初估模子是一个包括所有可能变量的“一般”模子,是以也就避免了过度的“数据开采”问题;别的,因为初始模子的“一般”性,所有研讨者在建模的初期往往有着雷同的“起点”,是以,在雷同的约化程序下,最后得到的最终模子也应当是雷同的.而传统建模实践中对统一经济问题往往有各类不同经济理论来解释,假如不同的研讨者采用不同的经济理论建模,得到的最终模子也会不同.当然,因为约化建模理论有更多的磨练,使得建模进程更庞杂,比拟之下,传统建模方轨则加倍“灵巧”.第六章联立方程计量经济学模子理论与办法上届重点:内生变量.外生变量.先定变量.构造式模子.简化式模子.参数关系体系.模子辨认第六章课后题(1.2.3.)1.为什么要树立联立方程计量经济学模子?联立方程计量经济学模子实用于什么样的经济现象?答:经济现象是极为庞杂的,个中诸身分之间的关系,在许多情形下,不是单一方程所能描写的那种简略的单向因果关系,而是互相依存,互为因果的,这时,就必须用联立的计量经济学方程才能描写清晰.所以与单方程实用于单一经济现象的研讨比拟,联立方程计量经济学模子实用于描写庞杂的经济现象,即经济体系.2.联立方程计量经济学模子的辨认状态可以分为几类?其寄义各是什么?答:联立方程计量经济学模子的辨认状态可以分为可辨认和不可辨认,可辨认又分为正好辨认和过度辨认.假如联立方程计量经济学模子中某个构造方程不具有肯定的统计情势,则称该方程为不可辨认,或者根据参数关系体系,在已知简化式参数估量值时,假如不能得到联立方程计量经济学模子中某个构造方程的肯定的构造参数估量值,称该方程为不可辨认.假如一个模子中的所有随机方程都是可以辨认的,则以为该联立方程计量经济学模子体系是可以辨认的.反过来,假如一个模子体系中消失一个不可辨认的随机方程,则以为该联立方程汁量经济学模子体系是不可以辨认的.假如某一个随机方程具有独一一组参数估量量,称其为正好辨认;假如某一个随机方程具有多组参数估量量,称其为过度辨认.3.联立方程计量经济学模子的单方程估量有哪些重要办法?其实用前提和统计性质各是什么?答:单方程估量的重要办法有:狭义的对象变量法(IV),间接最小二乘法(ILS),两阶段最小二乘法(2SLS).狭义的对象变量法(IV)和间接最小二乘法(ILS)只实用于正好辨认的构造方程的估量.两阶段最小二乘法(2SLs)既实用于正好辨认的构造方程,又实用于过度辨认的构造方程.用对象变量法估量的参数,一般情形下,在小样本下是有偏的,但在大样本下是渐近无偏的.假如拔取的对象变量与方程随机干扰项完全不相干,那么其参数估量量是无偏估量量.对于间接最小二乘法,对简化式模子运用通俗最小二乘法得到的参数估量量具有线性性.无偏性.有用性.经由过程多半关系体系盘算得到构造方程的构造参数估量量在小样本下是有偏的,在大样本下是渐近无偏的.采用二阶段最小二乘法得到构造方程的构造参数估量量在小样本下是有偏的,在大样本下是渐近无偏的.补充材料盘算题(一)给出多元线性回归的成果1.断定模子估量的成果若何,拟合后果若何?2.解释每一个参数所代表的经济意义?3.断定有没有违反四个根本假设?盘算题(二)给出数值,盘算:1.t磨练,F磨练的自由度2.在给定明显性程度下参数是否明显?3.估量值是有偏.无偏.有用?盘算题(三)参加虚拟变量D1,D2,D3问:虚拟变量的经济寄义?。
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
计量作业计量经济学第
三版李子奈
文档编制序号:[KKIDT-LLE0828-LLETD298-POI08]
计量经济学第三版李子柰
12 下表是中国内地2007年各地区税收Y和国内生产总值GDP的统计资料。
单位:(亿元)
Y GDP
3357065
594
625
434
9200
88
629
要求,以手工和运用Eviews软件(或其它软件):
(1)做出散点图,建立税收随国内生产总值GDP变化的一元线性回归方程,并解释斜率的经济意义;
(2)对所建立的回归方程进行检验;
(3)若2008年某地区国内生产总值为8500亿元,求该地区税收入的预测值机预测区间。
解:下图是运用Eviews软件分析出的结果。
Dependent Variable: Y
Method: Least Squares
Date: 09/17/11 Time: 15:13
Sample: 2 32
Included observations: 31
Variable Coefficient Std. Error t-Statistic Prob.
GDP
Adjusted R-squared . dependent var
. of regression Akaike info criterion
Sum squared resid 2760310. Schwarz criterion
Log likelihood F-statistic
Durbin-Watson stat Prob(F-statistic)。