受限玻尔兹曼机(RBM)学习笔记(七)RBM 训练算法
提升分类受限玻尔兹曼机性能的策略

提升分类受限玻尔兹曼机性能的策略尹静;闫河【摘要】为提高分类受限玻尔兹曼机 (classification restricted Boltzmann machine, ClassRBM) 有限的学习能力, 提出一种基于重构误差的学习助推策略, 提升ClassRBM的分类性能.重构误差是模型生成的数据与原始数据之间的差异, 其会影响模型的性能.通过设置不同的重构误差阈值, 选择重构误差超过阈值的原始数据对强化模型进行训练.测试时, 统计测试数据集中被ClassRBM分错, 且重构误差超过阈值的测试数据, 如果存在这样的测试数据, 错分数据采用强化模型的分类结果.在不同数据集上的测试结果表明, 提出策略能提升ClassRBM的性能.%To increase the limited learning ability of classification restricted Boltzmann machine (ClassRBM) , a learning boosting strategy based on reconstruction error was proposed to improve the classification performance of ClassRBM.The reconstruction error was the difference between the data generated by the model and the original data.This difference affected the performance of the model.Different reconstruction error thresholds were set up, and the enhanced model was trained by the original data whose reconstruction error exceeded the threshold.In testing, the test data which was misclassified using ClassRBM and its reconstruction error exceeded the threshold were counted.If such data existed, the final result of the data was the classification result of the enhanced model.The results on different data sets show that the proposed strategy can improve the performance of ClassRBM.【期刊名称】《计算机工程与设计》【年(卷),期】2019(040)001【总页数】6页(P250-255)【关键词】分类受限玻尔兹曼机;特征学习;提升策略;重构误差;分类性能【作者】尹静;闫河【作者单位】重庆理工大学计算机科学与工程学院,重庆 400054;重庆理工大学计算机科学与工程学院,重庆 400054【正文语种】中文【中图分类】TP1810 引言分类受限玻尔兹曼机(classification restricted Boltzmann machine,ClassRBM)[1]是一个基于能量函数,并自带标签的随机神经网络模型,用于解决各种分类问题。
RBM算法理解
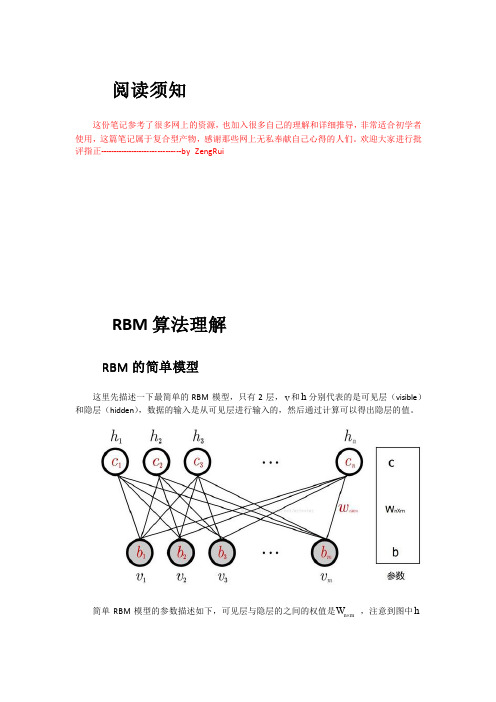
求解,在 CD(contrastive divergence)算法中采样部分扮演着模拟求解梯度的角色。 能量模型需要定义一个能量函数,RBM 能量函数如下:
n m m n
E v, h wij hi v j b j v j ci hi
i 1 j 1 j 1 i 1
简单 RBM 模型的参数描述如下,可见层与隐层的之间的权值是Wnm ,注意到图中 h
有 n 个节点, v 有 m 节点,单个节点用 v j 和 hi 描述,因为是简单 RBM 模型,所以
i, j , v j 0,1 ,hi 0,1 注意这里 0,1 是一个集合,这个集合只有 2 个元素,也就是说
e E v,h
e
v,h
E v,h
(这
里可以将能量函数理解成小球在碗里面具体的一个位置所具有的一个能量, 那么联合概率密 度就是能量也就是这个状态出现的概率) 。 这个概率不是随便定义的,是有统计热力学解释的。 定义了联合概率密度,那么我就可以得到一个分布,现在再回来前面的知识,可以得到 1. 最初是未知分布的数据,求解参数,完全无从下手 2. 将未知分布的数据与能量函数联合在 一起 3. 定义这个能量函数出现的概率,其实也就是对应着未知分布数据一个函数出现的概 率 4 我们可以得到能量函数的概率分布,这个分布就叫 Gibbs 分布,这里不是一个标准的 Gibbs 分布,而是一个特殊的 Gibbs 分布,这个分布有一组参数,其实就是能量函数中的那 几个 W, b, c 。 前面知道了 p v, h
阅读须知
这份笔记参考了很多网上的资源, 也加入很多自己的理解和详细推导, 非常适合初学者 使用,这篇笔记属于复合型产物,感谢那些网上无私奉献自己心得的人们。欢迎大家进行批 评指正-------------------------------by ZengRui
深度学习技术的非监督学习方法教程

深度学习技术的非监督学习方法教程近年来,深度学习技术在计算机视觉、自然语言处理和机器学习等领域取得了显著的成就。
而监督学习方法是传统深度学习的核心,它需要大量标记好的数据进行训练,并且对于训练数据的质量和数量也有较高的要求。
然而,在许多实际场景中,获取大量标记好的数据往往是一项困难和昂贵的任务。
为了解决这个问题,非监督学习方法应运而生。
非监督学习是指对未标记数据进行分析和建模的机器学习方法。
它通过发现数据中的隐藏模式和结构来获得信息,避免了对标记数据的依赖。
在深度学习中,非监督学习方法发挥着重要的作用,能够提供更多的信息和知识,为其他任务如分类、聚类和生成模型等提供支持。
在下面的文章中,我们将介绍几种常见的非监督学习方法,以帮助读者更好地了解深度学习技术的应用。
1. 自编码器(Autoencoder)自编码器是一种无监督学习的神经网络模型。
它包括一个编码器和一个解码器,旨在将输入数据压缩到一个低维表示并重构回输入空间。
自编码器通过最小化输入和重构之间的差异来学习有用的特征表示。
它可以用于特征提取、降维和去噪等任务。
2. 稀疏编码(Sparse Coding)稀疏编码是一种将输入数据表示成稀疏线性组合的方法。
它假设数据可以由少数的基向量表示,并通过最小化表示的稀疏度来学习这些基向量。
稀疏编码可以应用于特征学习、噪声去除、图像修复等任务。
3. 受限玻尔兹曼机(Restricted Boltzmann Machine, RBM)受限玻尔兹曼机是一种生成式模型,可以用于学习数据的概率分布。
RBM通过最大化数据的似然函数来学习模型参数,从而能够生成与原始数据相似的样本。
受限玻尔兹曼机可以应用于生成模型、特征学习和协同过滤等任务。
4. 深度信念网络(Deep Belief Networks, DBN)深度信念网络是由多层受限玻尔兹曼机组成的深度神经网络。
它通过逐层无监督地预训练和有监督的微调来学习数据的表示和分类。
受限玻尔兹曼机结合聚类的特异点挖掘方法

受限玻尔兹曼机结合聚类的特异点挖掘方法摘要:受限玻尔兹曼机(Restricted Boltzmann Machine, RBM)是一种强大的无监督学习模型,它在特征提取和数据降维方面有着广泛的应用。
而聚类是数据挖掘领域中一种常用的无监督学习方法,用于将数据集中的样本按照相似度划分到不同的类别中。
本文将结合受限玻尔兹曼机和聚类方法,提出一种特异点挖掘方法,通过对数据集进行特征提取和聚类分析,挖掘出不符合普遍规律的特异点数据。
实验结果表明,该方法能够有效挖掘出数据集中的特异点,并对异常数据进行有效的识别和分类,具有一定的实用价值。
关键词:受限玻尔兹曼机,聚类,特异点挖掘,异常数据识别一、引言数据挖掘技术在各个领域中都有着广泛的应用,通过对大规模数据集进行分析和挖掘,可以从中发现有价值的信息和规律。
而在数据挖掘的过程中,特异点挖掘是一个重要的研究内容,用于发现数据集中的异常数据,这些异常数据可能是由于错误、欺诈、故障或其他原因产生的。
特异点挖掘在金融风险评估、异常检测、网络安全等领域都有着重要的应用价值。
二、相关工作在数据挖掘领域,特异点挖掘是一个重要的研究课题,已经有很多工作对此进行了深入的探讨。
传统的异常检测方法主要包括基于统计学的方法、基于距离的方法和基于密度的方法等。
基于统计学的方法是通过统计模型来对数据进行分析,如Boxplot、Grubb's test等;基于距离的方法是通过计算样本之间的距离来发现异常点,如K近邻算法、LOF (local outlier factor)算法等;基于密度的方法是通过数据点的密度分布来检测异常点,如LOCI、DBSCAN等。
三、方法描述本文提出一种受限玻尔兹曼机结合聚类的特异点挖掘方法,具体流程如下:1. 数据预处理:首先对数据集进行预处理,包括数据清洗、缺失值处理、标准化等。
这些步骤能够有效提高模型的挖掘效果,并提高异常数据的检测准确率。
2. 受限玻尔兹曼机的训练:使用预处理后的数据集对RBM进行训练,通过优化算法(如梯度下降)来学习数据集中的高阶特征。
深度学习笔记 - RBM
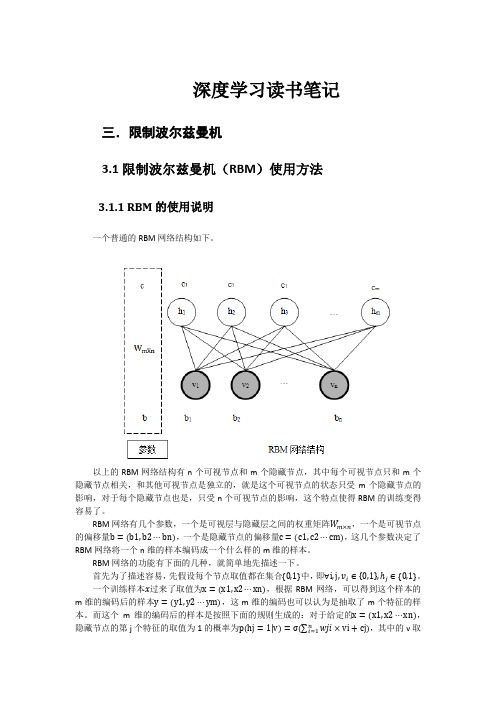
值就是 x,hj 的取值就是 yj,也就是说,编码后的样本 y 的第 j 个位置的取值为 1 的概率是 p(hj = 1|v)。所以,生成 yj 的过程就是:
i)先利用公式p(hj = 1|v) = σ(∑������������=1 ������������������ × vi + cj),根据 x 的值计算概率p(hj = 1|v),其 中 vi 的取值就是 xi 的值。
3.3.2 从能量最小到极大似然
上面我们得到了一个样本和其对应编码的联合概率,也就是得到了一个 Gibbs 分布,我 们引人概率的目的是为了方便求解的。但是我们实际求解的目标是能量最小。
下面来看看怎么从能量最小变成用概率表示。内容是来自《神经网络原理》那本书。 在统计力学上的说法也是——能量低的状态比能量高的状态发生的概率高。 定义一个叫做自由能量的东西,是从统计力学来的概念,
变量之间的相关程度决定了能量的高低。把变量的相关关系用图表示出来,并引入概率测度
方式就构成了概率图模型的能量模型,其实实际中也可以不用概率表示,比如立体匹配中直
接用两个像素点的像素差作为能量,所有像素对之间的能量和最小时的配置即为目标解。
RBM 作为一种概率图模型,引入概率就是为了方便采样,因为在 CD(contrastive divergence)算法中采样部分扮演着模拟求解梯度的角色。
RBM 网络有几个参数,一个是可视层与隐藏层之间的权重矩阵������������×������,一个是可视节点 的偏移量b = (b1, b2 ⋯ bn),一个是隐藏节点的偏移量c = (c1, c2 ⋯ cm),这几个参数决定了 RBM 网络将一个 n 维的样本编码成一个什么样的 m 维的样本。
其中E������表示系统在状态 i 时的能量,T 为开尔文绝对温度,������B为 Boltzmann 常数,Z 为与 状态无关的常数。
深度学习受限玻尔兹曼机

数媒学院-许鹏
Boltzmann Machine—Review—Model
Boltzmann Machine—Review—Algorithm
A more efficient way of collecting the statistics
RBM-Algorithm
现在我们的公式推导就算全部完成了,并且得到了对数似然函数对于各个参数的偏导数,那我们 再具体看一下这个偏导数到底能不能直接计算出来。
RBM-Algorithm
下面我们用图形象化的展示一下现在用于训练RBM的算法:
……
t=0 t=1 t=2 t=infinity
2002-Hinton-Training Products of Experts by Minimizing Contrastive Divergence
hidden units
visible units
RBM-Model
虽然RBM只是BM的层内连接受到了限制,但是在讨论RBM的学习算法和应用场景之前,还是先 为RBM做一个模型定义,用比较严谨的数学方式把它表达出来。
1. 仍然把RBM看成一个能量模型,则可见单元和隐藏单元的总能量为:
2. 我们要使得这个模型的能量减少到一个稳定状态,就需要更新 神经元状态,那么首先要计算某个神经元开启和关闭时的能量差:
……
t=0 t=1 t=2 t=infinity
2002-Hinton-Training Products of Experts by Minimizing Contrastive Divergence
RBM-Contrastive Divergence
受限玻尔兹曼机RBM剖析

根据y的值计算概率p(hj=1|v),其中hj的取值就是yj的值。 2.然后产生一个0到1之间的随机数,如果它小于p(vi=1|h),hi的取值 就是1,否则就是0。
受限玻尔兹曼机
• RBM的基本模型 RBM也可以被视为一个无向图模型。v 为可见层,用于 表示观测数据,h 为隐层,可视为一些特征提取器,W 为 两层之间的连接权重。 对于一组给定的状态(v; h), RBM作为一个系统所具备 的能量定义为
受限玻尔兹曼机
当参数确定时,基于该能量函数,我们可以得到(v; h)的 联合概率分布:
对于一个实际问题,我们最关心的是由RBM所定义的关于 观测数据v的分布,即联合概率分布的边际分布,也称为 似然函数:
受限玻尔兹曼机
由RBM的特殊结构(即层间有连接,层内无连接)可知: 当给定可见单元的状态时,各隐单元的激活状态之间是条 件独立的。此时,第j个隐单元的激活概率为
e ss
果小磁针方向与外场方向一致,则能量也会降低。我们定义总能量:
Esi J
i , j
s s
i
j
H si
i
N
其中J为一个能量耦合常数,E{si}表示系统处于状态组合{si}下的总 能量。求和下标表示对所有相邻的两个小磁针进行求和。我们看到, 如果si=sj,则总能量就会减少J。H表示外界磁场的强度,它是一个参 数,如果外界磁场向上H为正,否则为负。如果某个小磁针的方向与 外场一致,则总能量减少一个单位。
后来,他让他的学生Ernst Ising对一维的Ising模型进行求解,但是并 没有发现相变现象,因此也没有得到更多物理学家的关注。随后,著
名的统计物理学家Lars Onsager于1944年对二维的Ising模型进行了
受限玻尔兹曼机结合聚类的特异点挖掘方法

受限玻尔兹曼机结合聚类的特异点挖掘方法【摘要】受限玻尔兹曼机(Restricted Boltzmann Machine,RBM)是一种深度学习模型,通常用于无监督学习。
本文介绍了受限玻尔兹曼机的基本原理和结构,以及其在聚类分析中的应用。
特异点挖掘方法是一种用于发现数据集中异常值或特殊模式的技术,在本文中我们探讨了如何结合受限玻尔兹曼机和聚类分析来进行特异点挖掘。
具体步骤包括数据预处理、模型训练和特异点挖掘。
通过实验验证,我们展示了受限玻尔兹曼机结合聚类的特异点挖掘方法在数据挖掘领域的有效性和实用性。
未来,这种方法有望在金融、医疗等领域得到广泛应用。
本文系统地介绍了受限玻尔兹曼机结合聚类的特异点挖掘方法,为相关研究提供了重要参考。
【关键词】受限玻尔兹曼机、聚类分析、特异点挖掘、原理、步骤、应用前景、总结、研究背景、研究意义1. 引言1.1 研究背景受限玻尔兹曼机结合聚类的特异点挖掘方法是一种新兴的数据挖掘技术,其在处理复杂数据集中的异常点和离群点方面具有独特的优势。
随着数据挖掘和机器学习领域的不断发展,传统的聚类方法在处理高维、大规模数据时面临着诸多挑战,特异点挖掘方法的需求也日益迫切。
研究受限玻尔兹曼机结合聚类的特异点挖掘方法不仅可以提升数据挖掘任务的效率和准确率,还能够为异常检测、故障诊断、风险预测等实际应用领域带来更为可靠和有效的解决方案。
本文将探讨受限玻尔兹曼机结合聚类的原理和方法,以及其在特异点挖掘中的应用前景和意义。
1.2 研究意义随着数据科学和机器学习技术的快速发展,越来越多的数据被用于各种分析和应用中。
在大数据时代,数据中存在着大量的信息和结构,然而也存在着一些异常或特征点,这些特征点可能包含有用的信息,也可能引起数据分析结果的偏差。
对于数据中的特异点的挖掘成为一项重要的研究任务。
受限玻尔兹曼机结合聚类的特异点挖掘方法的研究意义在于能够提高数据分析的准确性和可解释性。
通过将受限玻尔兹曼机和聚类方法结合起来,可以更好地挖掘数据中的特异点,识别出与其他数据点不同的样本或模式。