sas数据集例题
sas测试题及答案

sas测试题及答案1. SAS中,如何将一个数据集的所有变量的值增加10?A. data dataset; set dataset; +10; run;B. data dataset; set dataset; +10; quit;C. data dataset; set dataset; +10; run;D. data dataset; set dataset; +10;答案:C2. 在SAS中,如何创建一个新的数据集,并将原数据集中的变量`Var1`和`Var2`复制到新数据集中?A. data new_dataset; set old_dataset; Var1 =old_dataset.Var1; Var2 = old_dataset.Var2; run;B. data new_dataset; set old_dataset; Var1 = Var1; Var2 = Var2; run;C. data new_dataset / old_dataset; set old_dataset; Var1 = old_dataset.Var1; Var2 = old_dataset.Var2; run;D. data new_dataset; set old_dataset; Var1 = Var1; Var2 = Var2; quit;答案:A3. SAS中,如何使用`proc print`步骤打印数据集的前10行?A. proc print data=dataset firstobs=10;B. proc print data=dataset firstobs=1 obs=10;C. proc print data=dataset firstobs=10;D. proc print data=dataset firstobs=1 obs=10;答案:B4. 在SAS中,如何使用`if-then`语句来创建一个新的变量`NewVar`,当`Var1`大于10时,`NewVar`的值为`Var1`的两倍,否则为0?A. data dataset; set dataset; if Var1 > 10 then NewVar = 2 * Var1; else NewVar = 0; run;B. data dataset; set dataset; if Var1 > 10 then NewVar = 2 * Var1; NewVar = 0; run;C. data dataset; set dataset; if Var1 > 10 NewVar = 2 *Var1; else NewVar = 0; run;D. data dataset; set dataset; if Var1 > 10 then NewVar = 2 * Var1; else NewVar = 0; quit;答案:A5. SAS中,如何使用`proc means`步骤计算数据集中`Var1`的平均值?A. proc means data=dataset N mean of Var1;B. proc means data=dataset N mean Var1;C. proc means data=dataset N=mean Var1;D. proc means data=dataset N mean Var1;答案:D结束语:以上是SAS测试题及答案,希望能够帮助您更好地理解和掌握SAS编程的基础知识。
sas练习题(打印版)

sas练习题(打印版)### SAS练习题(打印版)#### 一、基础数据操作1. 数据导入- 题目:使用SAS导入一个CSV文件,并列出前5个观测值。
- 答案:使用`PROC IMPORT`过程导入数据,并用`PROC PRINT`展示前5个观测。
2. 数据筛选- 题目:筛选出某列数据大于50的所有观测。
- 答案:使用`WHERE`语句进行筛选。
3. 数据分组- 题目:根据某列数据对数据集进行分组,并计算每组的均值。
- 答案:使用`PROC MEANS`过程和`BY`语句进行分组和计算。
4. 数据排序- 题目:按照某列数据的升序或降序对数据集进行排序。
- 答案:使用`PROC SORT`过程进行排序。
#### 二、描述性统计分析1. 单变量分析- 题目:计算某列数据的均值、中位数、标准差等统计量。
- 答案:使用`PROC UNIVARIATE`过程进行单变量描述性统计分析。
2. 频率分布- 题目:计算某列数据的频数和频率分布。
- 答案:使用`PROC FREQ`过程进行频率分布分析。
3. 相关性分析- 题目:计算两列数据的相关系数。
- 答案:使用`PROC CORR`过程计算相关系数。
#### 三、假设检验1. t检验- 题目:对两组独立样本的均值进行t检验。
- 答案:使用`PROC TTEST`过程进行t检验。
2. 方差分析- 题目:对多个组别数据进行方差分析。
- 答案:使用`PROC ANOVA`过程进行方差分析。
3. 卡方检验- 题目:对分类变量进行卡方检验。
- 答案:使用`PROC FREQ`过程和`CHI2TEST`选项进行卡方检验。
#### 四、回归分析1. 简单线性回归- 题目:使用一个自变量和一个因变量进行简单线性回归分析。
- 答案:使用`PROC REG`过程进行简单线性回归。
2. 多元线性回归- 题目:使用多个自变量和一个因变量进行多元线性回归分析。
- 答案:同样使用`PROC REG`过程,但包括多个自变量。
SAS例题分析
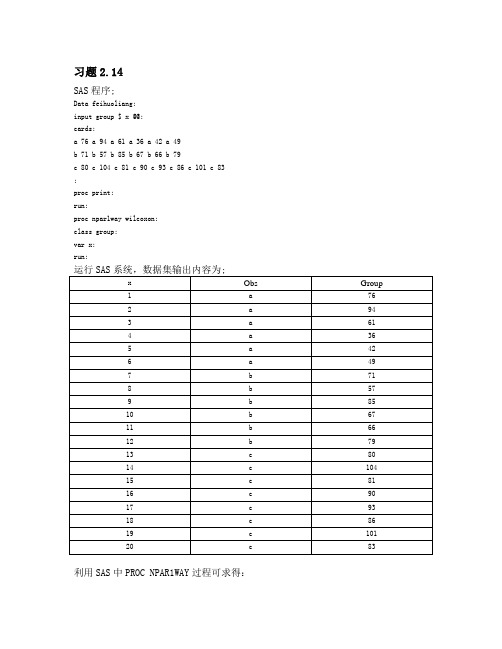
习题2.14SAS程序;Data feihuoliang; input group $ x @@; cards;a 76 a 94 a 61 a 36 a 42 a 49b 71 b 57 b 85 b 67 b 66 b 79c 80 c 104 c 81 c 90 c 93 c 86 c 101 c 83 ; proc print; run; proc npar1way wilcoxon; class group; var x; run;运行SAS系统,数据集输出内容为;x Obs Group1a762a943a614a365a426a497b718b579b8510b6711b6612b7913c8014c10415c8116c9017c9318c8619c10120c83利用SAS中PROC NPAR1WAY过程可求得:从SAS 数据分析来看,三组数据分散程度相差不大利用PROC NPAR1WAY 过程计算,检验3417.92=χ,05.00094.0=<=αP 故认为这一经验可靠.习题2.16SAS 程序:data shengchanzongzhif;input group $ x @@;cards;a 7870.28 a 4359.15 a 11660.43 a 4752.54 a 4791.48b 9251.15 b 4572.12 b 6188.9c 10366.37 c 21645.08 c 15742.51 c 6148.73 c 7614.55 c 4670.53 c 22077.36d 12495.97 d 7581.32 d 7568.89 d 26202.47 d 4828.51 d 1052.85e 3491.57 e 8637.81 e 2282 e 4006.72 e 291.01f 4523.74 f 2276.7 f 641.58 f 710.76 f 3045.26 ; proc print; run; proc npar1way wilcoxon; class group; var x; run;数据集输出内容为:Obs group x1a7870.282a4359.153a11660.434a4752.545a4791.486b9251.157b4572.128b6188.909c10366.3710c21645.0811c15742.5112c6148.7313c7614.5514c4670.5315c22077.3616d12495.9717d7581.3218d7568.8919d26202.4720d4828.5121d1052.8522e3491.5723e8637.8124e2282.0025e4006.7226e291.0127 f 4523.74 28 f 2276.70 29 f 641.58 30 f 710.76 31f3045.26利用SAS 中PROC NPAR1WAY 过程可求得:利用PROC NPAR1WAY 过程计算,检验8243.142=χ,05.00111.0=<=αP ,故各地区生产有明显的差异又有计算输出知,华北、东北、华东、中南、西南、西北的平均得分依次为;17.4,18,23.3,19.5,9.4,5.6,所以平均秩得分由大到小排序为:西北、西南、华北、东北、中南、华东。
判别分析例题及SAS程序

判别分析例题某医院眼科研究糖尿病患者的视网膜病变情况, 视网膜病变分轻、中、重三型。
研究者用年龄(age)、患糖尿病年数(time)、血糖水平(glucose)、视力(vision)、视网膜电图中的a波峰时(at)、a波振幅(av)、b波峰时(bt)、b波振幅(bv)、qp波峰时(qpt)及qp波振幅(qpv)等指标建立判别视网膜病变的分类函数, 以判断糖尿病患者的视网膜病变属于轻、中、重中哪一型。
为此观察131例糖尿病患者,要求其患眼无其他明显眼前段疾患, 眼底无明显其他视网膜疾病和视神经、葡萄膜等疾患,测定了他们的以上各指标值,并根据统一标准诊断其疾患类型,记分类指标名为group。
见表1 (表中仅列出前5例)。
试以此为训练样本, 仅取age,vision,at,bt和qpv 等指标, 求分类函数, 并根据王××的信息: 38岁, 视力1.0, 视网膜图at=14.25, bv=383.39, qpv=43.18判断其视网膜病变属于哪一型。
表1 131例糖尿病患者各指标实测记录(前5例)──────────────────────────────────例号年龄患病血糖视力a波a波b波b波qp波pq波视网膜年数峰时振幅峰时振幅峰时振幅病变程度──────────────────────────────────1 49 2.00 191 1.5 12.25 235.40 52.50 417.57 78.5 27.43 A12 49 2.00 191 1.2 13.50 225.15 52.00 391.20 78.5 46.69 A13 63 4.00 200 1.0 14.25 318.92 53.25 616.35 77.5 35.38 A14 63 4.00 200 0.6 14.00 361.90 55.00 723.30 77.0 47.01 A15 54 10.00 137 0.6 13.75 269.59 55.50 451.27 78.0 33.70 A2──────────────────────────────────解假定样本系从总体中随机抽取,则样本中三种疾患类型的样本量可近似地反映先验概率, 利用SAS的Discrim过程可得分类函数Y1=-181.447+0.473(age)+60.369(vision)+17.708(at)+0.048(bv)+0.364(qpv)Y2=-165.830+0.472(age)+49.782(vision)+17.658(at)+0.034(bv)+0.325(qpv)Y3=-189.228+0.178(age)+43.974(vision)+20.447(at)+0.040(bv)+0.265(qpv)以王××的观察值代入分类函数, 得Y1=-181.447+0.473×38+60.369×1.0+17.708×14.25+0.048×383.39+0.364×43.18 =183.36同样可算得:Y2=180.58, Y3=179.66其中最大者为Y1, 故判断为轻度病变。
统计软件SAS试题及答案(新)

滨州医学院2010~2011学年第一学期《统计软件》试题(A卷)(考试时间:120分钟,满分:100分)用题班级:2008级统计学专业一、数据库整理:(1题共42分)做题要求:按照要求写出程序,书写要符合SAS程序的规则。
随机抽取8名医学生的基础课程成绩与医学专业课程成绩,其成绩数据如表:医学基础课医学专业课解剖组胚生化生理内科外科妇产儿科X1 X2 X3 X4 Y1 Y2 Y3 Y470 64 97 77 59 81 63 8177 53 72 62 76 82 77 7975 82 66 68 62 75 72 8274 84 84 58 78 79 59 8275 68 73 72 77 81 73 7674 70 94 79 66 93 64 8274 84 86 82 79 79 55 78 (1)用input和cards语句将以上数据建立一个永久性数据集a1,逻辑库名exam,存放路径为’ d:\sas\exam1’,数据库内包含8个变量,分别为8门功课成绩,变量名如表中所示;(8分)libname exam ' d:\sas\exam1';data exam.a1;input X1 X2 X3 X4 Y1 Y2 Y3 Y4 @@;cards;70 64 97 77 59 81 63 8177 53 72 62 76 82 77 7975 82 66 68 62 75 72 8274 84 84 58 78 79 59 8275 68 73 72 77 81 73 7674 70 94 79 66 93 64 8274 84 86 82 79 79 55 7868 83 79 66 80 67 66 78;run;(2)用set语句建立临时性数据集a2,且该数据集不包括外科成绩低于80分的学生成绩;(6分)data a2;set exam.a1;if y2>=80then output a2;run;(3)将(1)中建立的数据集拆分成医学基础课与医学专业课两个数据集,数据集名称分别为exam_base与exam_spe,并将妇产命名为gyn。
SAS作业

使用SAS软件完成下列任务:1.对数据集sashelp.class中的身高和体重进行描述性统计分析,计算基本统计量,并给出分析结论。
身高:结论:身高数据共19个,最大值为72,最小值为51.3,相差20.7。
55-65之间的数据最多。
中位数为62.8,平均数为62.3。
数据的标准差为5.1271,方差为26.2869体重:结论:体重数据共19个,最大值为150,最小值为50,相差99.5。
中位数为99.5,平均数为100.026。
数据的标准差为22.7739,方差为518.6522.对数据集中的男生和女生分别进行问题1中的基本统计量的计算,并写出结论身高:结论:男生身高数据共10个,平均数为63.91。
数据的标准差为4.9379,方差为24.3832,对男生身高95%的可能集中于60.3776到67.4424之间。
女生身高数据共9个,平均数为60.5889。
数据的标准差为5.0183,方差为25.1836,对女生身高预测95%的可能集中于56.7315到64.4463之间。
男生的身高相较于女生而言更集中。
男生身高也普遍比女生高一些。
体重:结论:男生体重数据共10个,平均数为108.95。
数据的标准差为22.7272,方差为516.525,对男生身高95%的可能集中于92.692到125.208之间。
女生体重数据共9个,平均数为90.1111。
数据的标准差为19.3839,方差为375.7361,对女生身高预测95%的可能集中于75.2113到105.0109之间。
女生的体重相较于男生而言更集中。
女生体重也普遍比男生轻一些。
3.结合统计图形进一步分析问题1和2。
结论:由图可以看出,身高的数据多集中于55-65之间,体重的数据多集中于90-120之间,身高的数据比体重的数据分布的更加集中,学生之间身高的差异小于体重的差异。
身高体重均呈明显的正态分布。
男生的身高多集中于61.5-67.5之间,体重多集中于82.5-112.5之间女生的身高多集中于55.5-58.5和61.5-64.5之间,体重多集中于75-105之间4.分别计算身高和体重的置信水平为95%的置信区间,给出结论。
SAS综合练习题的(答案)

SAS金融数据处理综合练习题1.创建一包含10000个变量(X1-X10000),100个观测值的SAS数据集。
分别用DATA步,DATA步数组语句和IML过程实现。
(1)用data步实现data test1a;informat x1-x10000 9.2; /*创建100个变量,规定输出格*/do i=1to100; /*做循环*/output;/*每一次循环,输出所有的变量,包括i*/drop i;/*去掉i*/end;run;或者data test1a;format x1-x10000 best12.; /*创建10000个变量x1-x10000,但未有初始化*/do i=1to100; /*创建100个观测*/output;/*且每一个观测都输出到数据集test1a*/end;drop i;run;(2)用data步数组语句实现data test1b;array t{10000} x1-x10000 ;/*创建数组变量*/do i =1to100;/*每个变量有100个观测*/output;/*每一次循环,输出所有的变量,包括i*/drop i;/*去掉i*/end;/*循环结束*/data test1c;array t{10000} x1-x10000;do j=1to100;/*100次观测的循环*/do i = 1to10000;t{i}=i;/*第i个变量等于i*/end;output;/*输出第i次观测的i个变量的值*/end;drop i j;/*去掉i和j*/run;或者data test1b;array t{10000} x1-x10000;do j=1to100;/*100次观测的循环*/do i = 1to10000;t{i}=i;/*第i个变量等于i*/end;output;/*输出第i次观测的i个变量的值*/end;drop i j;/*去掉i和j*/run;(3)用IML过程实现proc iml;/*启用iml环境*/x='x1':'x10000';/*定义数组x1-x10000*/t= j(100,10000,1) ;/*创建100行10000列的. 同元素矩阵*/print t x;/*打印两个矩阵察看*/create test1d from t[colname=x];/*创建数据集c,变量数为列数,观测数为行数,列名更改为变量名,默认逻辑库为临时*/append from t; /*将t中的值填充的数据集中*/show datasets;show contents;/*显示数据集的一些7788的属性*/close test1d;run;quit;或者proc iml;x='x1':'x10000';t= shape(1,100,10000) ;/*shape和j不太一样,顺序是元素,行,列,j的顺序为行,列,元素*/print t x;create test1d from t[colname=x];append from t;show datasets;show contents;close test1d;run;quit;(4)用宏实现%macro names(name,number,obs);data a;%do i=1%to &obs;%do n=1%to &number;&name&n=1;%end;output;%end;run;%mend names;%names(x, 10000,100);2.多种方法创建包含变量X的10000个观测值的SAS数据集。
sas数据分析案例

sas数据分析案例SAS 数据分析案例:销售数据分析背景:某电子产品公司想要了解其产品在不同市场的销售情况,以便制定更好的销售策略。
为了实现这个目标,公司收集了一份包含产品销售数据的数据集。
数据集包括以下字段:- 销售日期:产品被销售的日期- 销售地区:产品被销售的地理位置- 销售额:每次销售的金额- 产品类别:产品的类型- 促销活动:销售是否发生在促销活动期间目标:通过分析销售数据,了解以下信息:1. 不同地区的销售情况:了解不同地区的销售额,哪些地区是公司的热销地区,哪些地区是潜在市场。
2. 产品类别的销售情况:了解不同产品类别的销售额,哪些产品类别是公司的主要销售产品,哪些产品类别需要进一步推动销售。
3. 促销活动效果评估:了解促销活动对销售额的影响,是否可以通过更多的促销活动来提高销售额。
步骤:1. 建立连接:使用 SAS 软件建立与数据集的连接。
2. 数据预处理:对数据进行清洗,包括删除缺失数据、异常值处理等。
3. 地区销售情况分析:- 使用图表展示不同地区的销售额,比较各地区的销售情况。
- 根据销售额,筛选出热销地区和潜在市场,进一步分析销售额的变化趋势。
4. 产品类别销售情况分析:- 使用图表展示不同产品类别的销售额,比较各产品类别的销售情况。
- 根据销售额,筛选出主要销售产品和推动销售的产品类别,进一步分析销售额的变化趋势。
5. 促销活动效果评估:- 对促销活动期间的销售额和非促销活动期间的销售额进行对比,分析促销活动对销售额的影响。
- 根据分析结果,评估促销活动的效果,并提出更好的促销策略。
结果:1. 地区销售情况的分析结果可以帮助公司确定销售重点地区和潜在市场,从而调整营销策略,提高销售额。
2. 产品类别销售情况的分析结果可以帮助公司了解不同产品类别的销售状况,从而决定是否需要加大某些产品类别的推广力度。
3. 促销活动效果评估的结果可以帮助公司了解促销活动对销售额的影响,从而优化促销活动的策划和执行。
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
试
验目的本实验主要练习数据集的导入和导出,建立、删除和保留变量、数据集的合并与拆分,排序、转置等操作。
掌握从已有数据文件建立数据集以及在已有数据集的基础上建立、删除变量;
掌握sas的程序控制的三种基本控制流;
掌握数据数据修正、排序、转置和标准化的过程或语句。
实验内容完成下列各题
一.某班12 名学生3 门功课成绩如下:
用sas的data步建立数据集。
筛选出有一科不及格的学生。
计算每人平均成绩,并按五级制评定综合成绩。
二.教材P141的6,7题。
三.data2_1.sav和data2_2.sav是一组被试(编号1-47)分别做两个量表数据,请把它们合并起来,保存为“量表.sav”,data2_3.sav是另一组被试(编号48-65)做成量表的数据,请把这些数据加到“量表.sav”里,并保存。
1)a1、a5、a30、a43、a49和b2、b6、b19为反向计分,把他们转化为正向。
2)data2_1.sav和data2_2.sav是一组被试(编号1-47)分别做两个量表的
数据,请把它们合并起来,保存为“量表.sav”,data2_3.sa v是另一组被试(编号48-65)做成量表的数据,请把这些数据加到“量表.sav”里,并保存。
3)a1到a25为a量表的第一个维度,a26到a50为第二个维度,b量表只有
一个维度,分别求出三个维度的总分(即所有项目得分相加)。
4)把b量表总分按照从小到大的顺序排列,设置另外一个变量(group),b
量表得分前十名赋值“1”,标签为“高分组”,后十名赋值“3”,标签为“低分组”,其它赋值“2”,标签为“中间组”。
5)各维度总分中如果有缺失,请用该维度的平均分进行替换。
结果分析一、
(1)
data class;
input id biochemistry$physical pathology;
label id='学号' biochemistry='生化' physical='物理' pathology='病理';
cards;
083 68 71 65
084 74 61 68
085 73 75 46
087 75 71 68
084 85 85 87
085 78 79 75
086 80 76 79
089 67 73 71
118 70 54 75
083 70 66 84
084 62 73 65
099 82 70 79
;
run;
proc print data=class label;
run;
(2)
(3)
data class;
input id biochemistry $ physical $ pathology $ ave $ @@; label id='学号' biochemistry='生化' physical='物理' pathology='病理';
ave=mean(biochemistry,physical,pathology);
if ave<60then ave='E';
if60<=ave<70then ave='D';
if70<=ave<=79then ave='C';
if80<=ave<=89then ave='B';
if90<=ave<=100then ave='A';
return;
cards;
083 68 71 65
084 74 61 68
085 73 75 46
087 75 71 68
084 85 85 87
085 78 79 75
086 80 76 79
089 67 73 71
118 70 54 75
083 70 66 84
084 62 73 65
099 82 70 79
;
proc print;
run;
二.
6.
data student;
infile'c:\sasdt\student.txt';
length id $18;
length name $16;
input id $ name $ English conputer; age= 2015-input(substr(id,7,4),4.); if mod(substr(compress(id),17,1),2) then sex='1';
else sex='2';
drop id;
run;
data sas7bdat.mstu;
set student;
if sex=1;
keep name age sex English computer; data sas7bdat.fstu;
set student;
if sex=2;
keep name age sex English computer; run;
proc print;
run;
7.
data student;
infile'c:\sasdt\student.txt';
length id $18;
length name $16;
input id $ name $ English conputer; age= 2015-input(substr(id,7,4),4.); if mod(substr(compress(id),17,1),2) then sex='1';
else sex='2';
drop id;
run;
data sas7bdat.stu90;
set student;
where English>90 and conputer>90; run;
proc print;
run;
三.
首先导入数据集
data liangbiao;
MERGE D1 D2;
data lb;
set liangbiao D3;
proc export data=lb outfile="d:\cym\SAS作业\量表.sav"
REPLACE ;
data lb;
array lb[72] a1-a50 b1-b22;
set lb;
lb(1)=6-lb(1);lb(5)=6-lb(5);lb(30)=6-lb(30);lb(43)=6-lb(43);
lb(49)=6-lb(49);lb(52)=6-lb(52);lb(56)=6-lb(56);lb(69)=6-lb(69);
sum1=sum(of a1-a25);
sum2=sum(of a26-a50);
sum3=sum(of b1-b22);
data lb;
set lb;
proc standard data=lb out=lb replace;
var sum1 sum2 sum3;
run;
proc sort data=lb;
by sum3;
data cheng;
input group @@;
datalines;
1 1 1 1 1 1 1 1 1 1
2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2
2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2
3 3 3 3 3 3 3 3 3 3
run;
data lg;
MERGE lb cheng;
run;
data lg;
set lg;
if (group = 1) then sum='高分组';
if (group = 2) then sum='中间组';
if (group = 3) then sum='低分组';
run;
结果如下:
成
绩教师签名。