Base64编解码
64位字符串的编码解码[转]
![64位字符串的编码解码[转]](https://img.taocdn.com/s3/m/e44ed65668eae009581b6bd97f1922791688be05.png)
64位字符串的编码解码[转]⼀. Base64的编码规则Base64编码的思想是是采⽤64个基本的ASCII码字符对数据进⾏重新编码。
它将需要编码的数据拆分成字节数组。
以3个字节为⼀组。
按顺序排列24 位数据,再把这24位数据分成4组,即每组6位。
再在每组的的最⾼位前补两个0凑⾜⼀个字节。
这样就把⼀个3字节为⼀组的数据重新编码成了4个字节。
当所要编码的数据的字节数不是3的整倍数,也就是说在分组时最后⼀组不够3个字节。
这时在最后⼀组填充1到2个0字节。
并在最后编码完成后在结尾添加1到2个 “=”。
例:将对ABC进⾏BASE64编码:1、⾸先取ABC对应的ASCII码值。
A(65)B(66)C(67);2、再取⼆进制值A(01000001)B(01000010)C(01000011);3、然后把这三个字节的⼆进制码接起来(010000010100001001000011);4、再以6位为单位分成4个数据块,并在最⾼位填充两个0后形成4个字节的编码后的值,(00010000)(00010100)(00001001)(00000011),其中蓝⾊部分为真实数据;5、再把这四个字节数据转化成10进制数得(16)(20)(9)(3);6、最后根据BASE64给出的64个基本字符表,查出对应的ASCII码字符(Q)(U)(J)(D),这⾥的值实际就是数据在字符表中的索引。
注:BASE64字符表:ABCDEFGHIJKLMNOPQRSTUVWXYZabcdefghijklmnopqrstuvwxyz0123456789+/⼆.解码规则解码过程就是把4个字节再还原成3个字节再根据不同的数据形式把字节数组重新整理成数据。
三. C#中的实现编码:byte[] bytes = Encoding.Default.GetBytes("要转换的字符"); string str = Convert.ToBase64String(bytes);解码:byte[] outputb = Convert.FromBase64String(str); string orgStr = Encoding.Default.GetString(outputb);C#图⽚的Base64编码和解码图⽚的Base64编码:System.IO.MemoryStream m = new System.IO.MemoryStream();System.Drawing.Bitmap bp = new System.Drawing.Bitmap(@“c:\demo.GIF”);bp.Save(m, System.Drawing.Imaging.ImageFormat.Gif);byte[]b= m.GetBuffer();string base64string=Convert.ToBase64String(b);Base64字符串解码:byte[] bt = Convert.FromBase64String(base64string);System.IO.MemoryStream stream = new System.IO.MemoryStream(bt);Bitmap bitmap = new Bitmap(stream);pictureBox1.Image = bitmap;。
Base64编码与解码原理

Base64编码与解码原理Base64编码是使⽤64个可打印ASCII字符(A-Z、a-z、0-9、+、/)将任意字节序列数据编码成ASCII字符串,另有“=”符号⽤作后缀⽤途。
base64索引表base64编码与解码的基础索引表如下base64编码原理(1)base64编码过程Base64将输⼊字符串按字节切分,取得每个字节对应的⼆进制值(若不⾜8⽐特则⾼位补0),然后将这些⼆进制数值串联起来,再按照6⽐特⼀组进⾏切分(因为2^6=64),最后⼀组若不⾜6⽐特则末尾补0。
将每组⼆进制值转换成⼗进制,然后在上述表格中找到对应的符号并串联起来就是Base64编码结果。
由于⼆进制数据是按照8⽐特⼀组进⾏传输,因此Base64按照6⽐特⼀组切分的⼆进制数据必须是24⽐特的倍数(6和8的最⼩公倍数)。
24⽐特就是3个字节,若原字节序列数据长度不是3的倍数时且剩下1个输⼊数据,则在编码结果后加2个=;若剩下2个输⼊数据,则在编码结果后加1个=。
完整的Base64定义可见RFC1421和RFC2045。
因为Base64算法是将3个字节原数据编码为4个字节新数据,所以Base64编码后的数据⽐原始数据略长,为原来的4/3。
(2)简单编码流程下⾯举例对字符串“ABCD”进⾏base64编码:对于不⾜6位的补零(图中浅红⾊的4位),索引为“A”;对于最后不⾜3字节,进⾏补零处理(图中红⾊部分),以“=”替代,因此,“ABCD”的base64编码为:“QUJDRA==”。
base64解码原理(1)base64解码过程base64解码,即是base64编码的逆过程,如果理解了编码过程,解码过程也就容易理解。
将base64编码数据根据编码表分别索引到编码值,然后每4个编码值⼀组组成⼀个24位的数据流,解码为3个字符。
对于末尾位“=”的base64数据,最终取得的4字节数据,需要去掉“=”再进⾏转换。
解码过程可以参考上图,逆向理解:“QUJDRA==” ——>“ABCD”1)将所有字符转化为ASCII 码;2)将ASCII 码转化为8位⼆进制;3)将8位⼆进制3个归成⼀组(不⾜3个在后边补0)共24位,再拆分成4组,每组6位;4)将每组6位的⼆进制转为⼗进制;5)从Base64编码表获取⼗进制对应的Base64编码;(2)base64解码特点base64编码中只包含64个可打印字符,⽽PHP在解码base64时,遇到不在其中的字符时,将会跳过这些字符,仅将合法字符组成⼀个新的字符串进⾏解码。
base64编解码
BASE64编码是一种常用的将二进制数据转换为可打印字符的编码。与HEX显示相比,它占用的空间较小。BASE64编码在RFC 3548(参见扩展阅读)中定义。
1、base64编解码原理
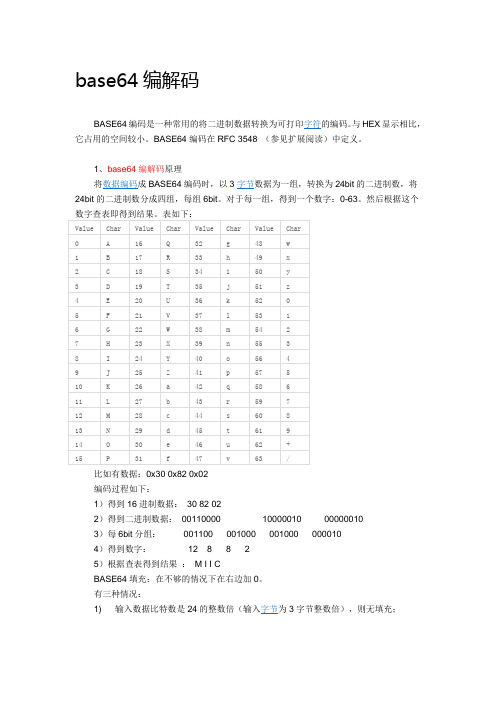
将数据编码成BASE64编码时,以3字节数据为一组,转换为24bit的二进制数,将24bit的二进制数分成四组,每组6bit。对于每一组,得到一个数字:0-63。然后根据这个数字查表即得到结果。表如下:
a
42
q
58
6
11
L
27
b
43
r
59
7
12
M
28
c
44
s
60
8
13
N
29
d
45
t
61
9
14
O
30
e
46
u
62
+
15
P
31
f
47
v
63
/
比如有数据:0x30 0x82 0x02
编码过程如下:
1)得到16进制数据:30 82 02
2)得到二进制数据:00110000 10000010 00000010
3)每6bit分组:001100 001000 001000 000010
3)输入数据最后编码是2个字节(输入数据字节数除3余2),则需要填充1个"=",因为补齐6比特,需要加一个00。
举例如下:
对0x30编码:
1) 0x30的二进制为:00110000
2)分组为:001100 00
3)填充2个00:001100 000000
4)得到数字:12 0Байду номын сангаас
javaBase64编码、解码

javaBase64编码、解码⽬录并⾮所有数据都可以⽤String类型来显⽰(例如字节流数据),但是都可以转为byte数组后进⾏base64编码再转String来显⽰,使⽤的时候再解码成原数据即可。
jdk8提供了Base64的⽀持、使⽤⾮常简单。
只需区分开encode与decode即可。
encode:编码,可以将任意数据进⾏base64编码//byte数组进⾏编码byte[] bytes = new byte[1024];byte[] encode = Base64.getEncoder().encode(bytes);decode:解码,⽤户将进⾏了base64编码的数据还原//编码结果进⾏Base64解码,解码得到的byte数组即为编码源数组byte[] encode = Base64.getDecoder().decode(encode);所有对象类型⽀持Base64编码解码。
java所有对象都是继承了Object的,请看以下代码。
可以确定java的所有对象类型皆可采⽤base64编码后传输,解码获取。
//Base64解码为String类型String str1 = new String(Base64.getDecoder().decode(encode2));System.out.println("原⽂原⽂⽂"+msg1);System.out.println("编码解码后"+str1);//获取 Long 类型Base64编码Object oldObject = new Long("12354687");ByteArrayOutputStream outputStream = new ByteArrayOutputStream();ObjectOutputStream objectOutputStream = new ObjectOutputStream(outputStream);objectOutputStream.writeObject(oldObject);//原对象字节数组byte[] bytes = outputStream.toByteArray();//编码后字节数组byte[] encode3 = Base64.getEncoder().encode(bytes);//解码后字节数组byte[] decode1 = Base64.getDecoder().decode(encode3);//此处可以通过循环判定内容是否变更,由于字节数组内容完全相等,所以”不想等“字符串永不打印if(bytes.length==decode1.length){for (int i = 0; i < decode1.length; i++) {if(bytes[i]!=decode1[i]){System.out.println("不相等");}}}ByteArrayInputStream byteArrayInputStream = new ByteArrayInputStream(decode1);ObjectInputStream objectInputStream = new ObjectInputStream(byteArrayInputStream);Object newObject = objectInputStream.readObject();System.out.println("新旧对象是否相等:"+newObject.equals(oldObject));。
Base64位编码解码

Base64编码说明Base64编码要求把3个8位字节(3*8=24)转化为4个6位的字节(4*6=24),之后在6位的前面补两个0,形成8位一个字节的形式。
如果剩下的字符不足3个字节,则用0填充,输出字符使用'=',因此编码后输出的文本末尾可能会出现1或2个'='。
为了保证所输出的编码位可读字符,Base64制定了一个编码表,以便进行统一转换。
编码表的大小为2^6=64,这也是Base64名称的由来。
Base64编码表码值字符码值字符码值字符码值字符0 A 16 Q 32 g 48 w1 B 17 R 33 h 49 x2 C 18 S 34 i 50 y3 D 19 T 35 j 51 z4 E 20 U 36 k 52 05 F 21 V 37 l 53 16 G 22 W 38 m 54 27 H 23 X 39 n 55 38 I 24 Y 40 o 56 49 J 25 Z 41 p 57 510 K 26 a 42 q 58 611 L 27 b 43 r 59 712 M 28 c 44 s 60 813 N 29 d 45 t 61 914 O 30 e 46 u 62 +15 P 31 f 47 v 63 /原理转码过程例子:3*8=4*6内存1个字符占8位转前: s 1 3先转成ascii:对应 115 49 512进制: 01110011 00110001 001100116个一组(4组)011100110011000100110011然后才有后面的 011100 110011 000100 110011然后计算机是8位8位的存数 6不够,自动就补两个高位0了所有有了高位补0科学计算器输入00011100 00110011 00000100 00110011得到 28 51 4 51查对下照表 c z E z。
c++base64编解码使用示例

c++base64编解码使⽤⽰例base64码简介Base64是⽹络上最常见的⽤于传输8Bit字节代码的编码⽅式之⼀,⼤家可以查看RFC2045~RFC2049,上⾯有MIME的详细规范。
Base64编码可⽤于在HTTP环境下传递较长的标识信息。
例如,在Java Persistence系统Hibernate中,就采⽤了Base64来将⼀个较长的唯⼀标识符(⼀般为128-bit的UUID)编码为⼀个字符串,⽤作HTTP表单和HTTP GET URL中的参数。
在其他应⽤程序中,也常常需要把⼆进制数据编码为适合放在URL(包括隐藏表单域)中的形式。
此时,采⽤Base64编码具有不可读性,即所编码的数据不会被⼈⽤⾁眼所直接看到。
0. 源数据都是8位位宽的数据;1. 相当于分组码,将源数据分为3个⼀组,每⼀组共24bits,采⽤每6位对应⼀个编码码字,那么3*8bits = 4*6its, 将3个数据映射成4个数据,由于编码的码字都是6位长度,换位10进制就是0-63,总共有64中可能性,这也是base64名字的来历;2. 6bits对应10进制数对应的码字如最后的表;C代码编码#include <stdio.h>#include <string.h>// 全局常量定义const char * base64char = "ABCDEFGHIJKLMNOPQRSTUVWXYZabcdefghijklmnopqrstuvwxyz0123456789+/";const char padding_char = '=';/*编码代码* const unsigned char * sourcedata,源数组* char * base64 ,码字保存*/int base64_encode(const unsigned char * sourcedata, char * base64){int i=0, j=0;unsigned char trans_index=0; // 索引是8位,但是⾼两位都为0const int datalength = strlen((const char*)sourcedata);for (; i < datalength; i += 3){// 每三个⼀组,进⾏编码// 要编码的数字的第⼀个trans_index = ((sourcedata[i] >> 2) & 0x3f);base64[j++] = base64char[(int)trans_index];// 第⼆个trans_index = ((sourcedata[i] << 4) & 0x30);if (i + 1 < datalength){trans_index |= ((sourcedata[i + 1] >> 4) & 0x0f);base64[j++] = base64char[(int)trans_index];}else{base64[j++] = base64char[(int)trans_index];base64[j++] = padding_char;base64[j++] = padding_char;break; // 超出总长度,可以直接break}// 第三个trans_index = ((sourcedata[i + 1] << 2) & 0x3c);if (i + 2 < datalength){ // 有的话需要编码2个trans_index |= ((sourcedata[i + 2] >> 6) & 0x03);base64[j++] = base64char[(int)trans_index];trans_index = sourcedata[i + 2] & 0x3f;base64[j++] = base64char[(int)trans_index];}else{base64[j++] = base64char[(int)trans_index];base64[j++] = padding_char;break;}}base64[j] = '\0';return 0;}解码包括两个函数:/** 在字符串中查询特定字符位置索引* const char *str ,字符串* char c,要查找的字符*/inline int num_strchr(const char *str, char c) //{const char *pindex = strchr(str, c);if (NULL == pindex){return -1;}return pindex - str;}/* 解码* const char * base64 码字* unsigned char * dedata,解码恢复的数据*/int base64_decode(const char * base64, unsigned char * dedata){int i = 0, j=0;int trans[4] = {0,0,0,0};for (;base64[i]!='\0';i+=4){// 每四个⼀组,译码成三个字符trans[0] = num_strchr(base64char, base64[i]);trans[1] = num_strchr(base64char, base64[i+1]);// 1/3dedata[j++] = ((trans[0] << 2) & 0xfc) | ((trans[1]>>4) & 0x03);if (base64[i+2] == '='){continue;}else{trans[2] = num_strchr(base64char, base64[i + 2]);}// 2/3dedata[j++] = ((trans[1] << 4) & 0xf0) | ((trans[2] >> 2) & 0x0f);if (base64[i + 3] == '='){continue;}else{trans[3] = num_strchr(base64char, base64[i + 3]);}// 3/3dedata[j++] = ((trans[2] << 6) & 0xc0) | (trans[3] & 0x3f);}dedata[j] = '\0';return 0;}下⾯是其他⽹友的补充可以参考⼀下核⼼代码#include <stdio.h>#include <stdlib.h>#include <string.h>#include <ctype.h>static const char b64_table[65] = "ABCDEFGHIJKLMNOPQRSTUVWXYZabcdefghijklmnopqrstuvwxyz0123456789+/"; static const char reverse_table[128] ={64, 64, 64, 64, 64, 64, 64, 64, 64, 64, 64, 64, 64, 64, 64, 64,64, 64, 64, 64, 64, 64, 64, 64, 64, 64, 64, 64, 64, 64, 64, 64,64, 64, 64, 64, 64, 64, 64, 64, 64, 64, 64, 62, 64, 64, 64, 63,52, 53, 54, 55, 56, 57, 58, 59, 60, 61, 64, 64, 64, 64, 64, 64,64, 0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14,15, 16, 17, 18, 19, 20, 21, 22, 23, 24, 25, 64, 64, 64, 64, 64,64, 26, 27, 28, 29, 30, 31, 32, 33, 34, 35, 36, 37, 38, 39, 40,41, 42, 43, 44, 45, 46, 47, 48, 49, 50, 51, 64, 64, 64, 64, 64};unsigned char *base64_encode(unsigned char *bindata,size_t inlen,unsigned char **out,size_t *outlen) {size_t _outlen = *outlen;unsigned char *_out = NULL;size_t out_pos = 0;if(NULL == *out){_outlen = (inlen / 3 + (inlen%3 != 0)) * 4 + 1;_out = malloc(_outlen);}else{_outlen = *outlen;_out = *out;}memset(_out,'=',_outlen);_out[_outlen-1] = 0;unsigned int bits_collected = 0;unsigned int accumulator = 0;for(int i = 0; i < inlen; i++){accumulator = (accumulator << 8) | (bindata[i] & 0xffu);bits_collected += 8;while (bits_collected >= 6){bits_collected -= 6;_out[out_pos++] = b64_table[(accumulator >> bits_collected) & 0x3fu];}}if(bits_collected >= 6){if(NULL == *out){free(_out);}return NULL;}if (bits_collected > 0){// Any trailing bits that are missing.accumulator <<= 6 - bits_collected;_out[out_pos++] = b64_table[accumulator & 0x3fu];}*outlen = _outlen;*out = _out;return _out;}unsigned char *base64_decode(unsigned char *bindata,size_t inlen,unsigned char **out,size_t *outlen) {size_t _outlen = *outlen;unsigned char *_out = NULL;int bits_collected = 0;unsigned int accumulator = 0;size_t out_pos = 0;if(NULL == *out){_outlen = inlen;_out = malloc(_outlen);}else{_outlen = *outlen;_out = *out;}int c = 0;for(int i = 0; i < inlen; i++){c = bindata[i];if (isspace(c) || c == '='){// Skip whitespace and padding. Be liberal in what you accept.continue;}if ((c > 127) || (c < 0) || (reverse_table[c] > 63)){return NULL;}accumulator = (accumulator << 6) | reverse_table[c];bits_collected += 6;if (bits_collected >= 8){bits_collected -= 8;_out[out_pos++] = (char)((accumulator >> bits_collected) & 0xffu);}}*outlen = _outlen;*out = _out;return _out;}int main(int argc,char *argv[]){unsigned char *str = argv[1];unsigned char *out = 0;size_t len = 0;printf("%s\n",base64_encode(str,strlen(str),&out,&len));unsigned char *_out = 0;size_t _len = 0;printf("%s\n",base64_decode(out,strlen(out),&_out,&_len));return 0;}这篇C语⾔base64编解码的⽂章就介绍到这了,希望⼤家以后多多⽀持。
Base64编码解码(源代码)

Base64编码解码(源代码)Base64 Content-Transfer-Encoding ( RFC2045 ) 可对任何⽂件进⾏base64 编解码,主要⽤于MIME邮件内容编解码// 11111100 0xFC // 11000000 0x3 // 11110000 0xF0 // 00001111 0xF // 11000000 0xC0 // 00111111 0x3Fbyte *lmMimeEncodeBase64(const byte *octetSource, int size) { byte *m_Base64_Table = "ABCDEFGHIJKLMNOPQRSTUVWXYZabcdefghijklmnopqrstuvwxyz0123456789+/";int base64size = (((((size) + 2) / 3) * 4) + 1) / 76 * 78 + 78; //add "/r/n" for each line'byte *strEncode = (byte *)MALLOC(base64size); byte cTemp[4];//By RFC2045 --The encoded output stream must be represented in lines of no more than 76 characters each int LineLength=0; int i, len, j=0;MEMSET(strEncode, 0, base64size);for(i=0; i<size; i+=3) { MEMSET(cTemp,0,4);//cTemp[0]=octetSource[i]; //cTemp[1]=octetSource[i+1]; //cTemp[2]=octetSource[i+2];//len=strlen((char *)cTemp);if(i<size-3){ len = 3; cTemp[0]=octetSource[i]; cTemp[1]=octetSource[i+1]; cTemp[2]=octetSource[i+2]; } else{ len = 0; if(i<size){ cTemp[0]=octetSource[i]; ++len; } if(i<size-1){cTemp[1]=octetSource[i+1]; ++len; } if(i<size-2){ cTemp[2]=octetSource[i+2]; ++len; } //DBGPRINTF("temp[0] = %d", cTemp[0]); //DBGPRINTF("temp[1] = %d", cTemp[1]); //DBGPRINTF("temp[2] = %d",cTemp[2]); //DBGPRINTF("strEncode[0] = %d", ((int)cTemp[0] & 0xFC)>>2); //DBGPRINTF("strEncode[1] = %d",((int)cTemp[0] & 0x3)<<4 | ((int)cTemp[1] & 0xF0)>>4); //DBGPRINTF("strEncode[2] = %d", ((int)cTemp[1] & 0xF)<<2 | ((int)cTemp[2] & 0xC0)>>6); //DBGPRINTF("strEncode[3] = %d", (int)cTemp[2] & 0x3F); //DBGPRINTF("strEncode[0] = %c",m_Base64_Table[((int)cTemp[0] & 0xFC)>>2]); //DBGPRINTF("strEncode[1] = %c", m_Base64_Table[((int)cTemp[0] & 0x3)<<4 | ((int)cTemp[1] & 0xF0)>>4]); //DBGPRINTF("strEncode[2] = %c", m_Base64_Table[((int)cTemp[1] & 0xF)<<2 | ((int)cTemp[2] &0xC0)>>6]); //DBGPRINTF("strEncode[3] = %c", m_Base64_Table[(int)cTemp[2] & 0x3F]); }if(len==3) { strEncode[j++] = m_Base64_Table[((int)cTemp[0] & 0xFC)>>2]; strEncode[j++] =m_Base64_Table[((int)cTemp[0] & 0x3)<<4 | ((int)cTemp[1] & 0xF0)>>4]; strEncode[j++] = m_Base64_Table[((int)cTemp[1] & 0xF) <<2 | ((int)cTemp[2] & 0xC0)>>6]; strEncode[j++] = m_Base64_Table[(int)cTemp[2] & 0x3F]; LineLength+=4;if(LineLength>=76) {strEncode[j++]='/r'; strEncode[j++]='/n'; LineLength=0;} } else if(len==2) { strEncode[j++] =m_Base64_Table[((int)cTemp[0] & 0xFC)>>2]; strEncode[j++] = m_Base64_Table[((int)cTemp[0] & 0x3 )<<4 | ((int)cTemp[1] & 0xF0 )>>4]; strEncode[j++] = m_Base64_Table[((int)cTemp[1] & 0x0F)<<2]; strEncode[j++] = '='; LineLength+=4;if(LineLength>=76) {strEncode[j++]='/r'; strEncode[j++]='/n'; LineLength=0;} } else if(len==1) { strEncode[j++] =m_Base64_Table[((int)cTemp[0] & 0xFC)>>2]; strEncode[j++] = m_Base64_Table[((int)cTemp[0] & 0x3 )<<4]; strEncode[j++] = '='; strEncode[j++] = '='; LineLength+=4; if(LineLength>=76) {strEncode[j++]='/r'; strEncode[j++]='/n'; LineLength=0;} } memset(cTemp,0,4); } //strEncode[j] = '/0'; //DBGPRINTF("--finished encode base64size = %d, j = %d", base64size, j); //for(i=j; i<base64size; i++){ // DBGPRINTF("--rest char is: %c", strEncode[i]); //} return strEncode; }byte GetBase64Value(char ch) { if ((ch >= 'A') && (ch <= 'Z')) return ch - 'A'; if ((ch >= 'a') && (ch <= 'z')) return ch - 'a' + 26; if ((ch >= '0') && (ch <= '9')) return ch - '0' + 52; switch (ch) { case '+': return 62; case '/': return 63; case '=': /* base64 padding */ return 0; default: return 0; } } byte *lmMimeDecodeBase64(const byte *strSource, int *psize) { byte *m_Base64_Table = "ABCDEFGHIJKLMNOPQRSTUVWXYZabcdefghijklmnopqrstuvwxyz0123456789+/"; int i, j, k, size = STRLEN((char *)strSource); int n = 0; //return value byte *octetDecode = (byte *)MALLOC( (((size) - 1) / 4) *3 ); byte cTemp[5]; int Length=0; int asc[4];for(i=0;i<size;i+=4) { MEMSET(cTemp,0,5);cTemp[0]=strSource[i]; cTemp[1]=strSource[i+1]; cTemp[2]=strSource[i+2]; cTemp[3]=strSource[i+3];Length+=4; if(Length==76) { i+=2; Length=0; }for(j=0;j<4;j++) { //if(cTemp[j]=='='){ // asc[j]=0; //}else{ for(k=0;k<(int)STRLEN((char*)m_Base64_Table);k++) { if(cTemp[j]==m_Base64_Table[k]) asc[j]=k; } //} } if('='==cTemp[2] && '='==cTemp[3]) { octetDecode[n++] = (byte)(int)(asc[0] << 2 | asc[1] << 2 >> 6); } else if('='==cTemp[3]) { octetDecode[n++] = (byte)(int)(asc[0] << 2 | asc[1] << 2 >> 6); octetDecode[n++] = (byte)(int)(asc[1] << 4 | asc[2] << 2 >> 4); } else { octetDecode[n++] = (byte)(int)(asc[0] << 2 | asc[1] << 2 >> 6); octetDecode[n++] = (byte)(int)(asc[1] << 4 | asc[2] << 2 >> 4); octetDecode[n++] = (byte)(int)(asc[2] << 6 | asc[3] << 2 >> 2); }//cTemp[0] = GetBase64Value((char)strSource[i]); //cTemp[1] = GetBase64Value((char)strSource[i+1]); //cTemp[2] = GetBase64Value((char)strSource[i+2]); //cTemp[3] = GetBase64Value((char)strSource[i+3]);//Length+=4; //if(Length==76) //{ // i+=2; // Length=0; //}//octetDecode[n++] = (cTemp[0] << 2) | (cTemp[1] >> 4); //octetDecode[n++] = (cTemp[1] << 4) | (cTemp[2] >> 2); //octetDecode[n++] = (cTemp[2] << 6) | (cTemp[3]);} *psize = n; return octetDecode; }。
base64 解码 原理

base64 解码原理
Base64是一种编码方式,它将二进制数据转换为可打印字符
的ASCII格式。
其原理如下:
1. 将待编码的数据划分为连续的24位(即3个字节)的分组。
2. 将每个24位的分组划分为4个6位的子分组。
3. 根据Base64编码表,将每个6位的子分组转换为对应的可
打印字符。
4. 如果最后的输入数据长度不足3个字节,会进行填充操作。
一般使用'='字符进行填充。
这样,在Base64编码中,一个3字节的二进制数据通过编码
后会变成4个字符,并且编码后的数据长度总是为4的倍数。
当需要对Base64编码进行解码时,可以按照以下步骤进行:
1. 将待解码的数据划分为连续的4个字符的分组。
2. 根据Base64解码表,将每个字符的编码值转换为对应的6
位二进制数据。
3. 将每个6位的子分组合并为一个24位的分组。
4. 将每个24位的分组划分为3个8位的子分组,并转换为对
应的字节数据。
5. 如果解码后的数据长度大于待解码的数据长度,则剔除填充的字节。
通过以上步骤,就可以将Base64编码的数据解码回原始的二
进制数据。
需要注意的是,Base64编码只是一种编码方式,它并不对数
据进行加密或压缩。
它主要用于在文本协议中传输二进制数据,或者在文本环境中嵌入二进制数据。
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
Base64编解码
一、编码原理
Base64是一种基于64个可打印字符来表示二进制数据的表示方法。
由于2的6次方等于64,所以每6个比特为一个单元,对应某个可打印字符。
三个字节有24个比特,对应于4个Base64单元,即3个字节需要用4个可打印字符来表示。
编码后的数据比原来的数据略长,是原来的4/3倍。
它可用来作为电子邮件的传输编码。
在Base64中的可打印字符包括字母A-Z、a-z、数字0-9 ,这样共有62个字符,此外两个可打印符号在不同的系统中而不同(Base64de 编码表如下所示)。
Base64常用于在通常处理文本数据的场合,表示、传输、存储一些二进制数据。
包括MIME的email,email via MIME, 在XML中存储复杂数据.
Base64编码表
二、编码流程
步骤1:将要编码的所有字符都转化成对应的ASCII码。
步骤2:将所有的ASCII码转换成对应的8位长的二进制数。
步骤3:将所得的二进制数从高位到低位开始分成6位一组,最后一组不足六的则补充0
步骤4:将每组二进制数转换成十进制数,然后对照base64的编码表查找得到相应的编码。
注意:1、要求被编码字符是8bit的,所以须在ASCII编码范围内,\u0000-\u00ff,中文就不行。
2、如果被编码的字符串中字符的个数为3的倍数,按照上面的步骤即可得到正确的base64编码。
但是如果不是3的倍数则要分情况讨论。
如果是3的倍数余1,则要在编好的码字后面加上两个“=”,如果是3的倍数余2,这要在编好的码字后面加上一个“=”。
(例如w的base64编码为dw==,w1的base64编码为dzE=)
下面我们来对具体的字符串进行编码举例,以便更好的理解编码流程:
编码「Man」
在此例中,Base64算法将三个字符编码为4个字符
特殊情况
A的编码为QQ= =
BC的编码为QkM=
三、核心算法程序
算法的基本原理如下:由于每次转换都需要6个bit,而这6个bit可能都来自一个字节,也可以来自前后相临的两个字节。
定义两个变量:prevByteBitCount和nextByteBitCount,这两个变量分别表述从前一个和后一个节字取得的bit数。
如果prevByteBitCount为0,表示6个bit全部来自下一个字节的高6位。
如果nextByteBitCount = 0,表示6个bit全部来自前一个字节的低6位。
最后通过适当的移位获得所需要的6个bit,再在上面的base64编码表中查找相应的字符。
算法的实现代码如下:
public static String encoder(byte[] bytes)
{
StringBuilder result = new StringBuilder();
String base64 = "ABCDEFGHIJKLMNOPQRSTUVWXYZabcdefghijklmnopqrstuvwxyz0123456789+/"; // prevByteBitCount表示从前一个字节取得的bit数,nextByteBitCount表示从后一个字节取得的bit数
int prevByteBitCount = 0, nextByteBitCount = 6;
// i表示当前的数组索引,n表示已经处理的位数
int i = 0, n = 0;
// byteCount表示总的位数
int byteCount = 8 * bytes.length;
byte b = 0;
while (true)
{
// 处理从前后两个字节取得位数的情况
if (prevByteBitCount > 0 && nextByteBitCount > 0)
{
// 将前一个字节的低位向左移nextByteBitCount个bit,并使下一个字节的高位(nextByteBitCount指定的位数)右移到字节的最低位,
// 然后将两个位移结果进行逻辑或,也就是将从前一个字节和后一个字节取得的相应的bit合并为一个字节的低位
b = (byte) (((0xff & bytes[i]) << nextByteBitCount) | ((0xff & bytes[i + 1]) >> (8 - nextByteBitCount)));
// 将逻辑或后的结果的最高两个bit置成0
b = (byte) (b & 0x3f);
prevByteBitCount = 8 - nextByteBitCount;
nextByteBitCount = 6 - prevByteBitCount;
}
// 处理从后一个字节取得高6位的情况
else if (prevByteBitCount == 0)
{
// 后一个字节的高6位右移动低6位
b = (byte) ((0xff & bytes[i]) >> (8 - nextByteBitCount));
// 处理后面的位时,就是从前一个字节取2个bit,从后一个字字取4个bit prevByteBitCount = 2;
nextByteBitCount = 4;
}
// 处理从前一个字节取得低6位的情况
else if (nextByteBitCount == 0)
{
// 将前一个字节的最高两个bit置成0
b = (byte) (0x3f & bytes[i]);
// 处理后面的位时,从后一个字节取6个bit
prevByteBitCount = 0;
nextByteBitCount = 6;
}
result.append(base64.charAt(b));
n += 6;
i = n / 8;
int remainBitCount = byteCount - n;
if (remainBitCount < 6)
{
// 将剩余的bit补0后,仍然需要在base64编码表中查找相应的字符,并添加到结果字符串的最后
if (remainBitCount > 0)
{
b = bytes[bytes.length - 1];
b = (byte) (0x3f & (b << (6 - remainBitCount)));
result.append(base64.charAt(b));
}
break;
}
}
// 如果总bit数除3的余数为1,加一个“=”,为2,加两个“=”
n = byteCount % 3;
for (i = 0; i < n; i++)
result.append("=");
return result.toString();
}
对于程序的理解:这个程序应该只是总程序的一部分,它主要实现了对二进
制代码分成以6位长为一组的分组,考虑了位数不足的情况,个人觉得这个是程序中的难点,所以就把它放进来了。
在这个程序中直接调用了查找base64编码表这个函数。
四、解码
Base64的解码原理很简单,其实就是编码的逆过程。
步骤1:将所给的字符在base64编码表中查到相应的数值
步骤2:将数值均转化成6位的二进制数
步骤3:将二进制数从高位到低位的顺序,以8为长度分组。
(若所给的base64码结尾没有“=”的情况,即字符数正好是4的倍数。
如果有“=”,这不是8的倍数,此时需要将最后的两位或者四位省去。
这就可能导致不同的符号可以解码出相同的编码,如下面所示的例子。
)
步骤4:将每组的二进制数转换成对应的ASCII代码。
这样就可以得到解码后的字符。
举例说明:
解码er==
Base64编码表中对应的值为30 43
每个化成对应6为二进制位011110 101011
以8位长为一组,多余省去,这可得01111010
则其ASCII码数值为7Ah,对应字符为Z
eq==解码所得结果也为Z。
注意:如果在步骤三中所得的数在ASCII码表中找不到对应数,则会出现解码
错误。
例如erYT解码得到就是Z!!(这是我在网上的base64解码器中实验得
到的结果)
五、感悟
我们觉得Base64的编码、解码原理很简单,但是它的应用范围挺广的,而且它的源代码对于我们来说也不简单(有的部分知道怎么回事,但是不知道怎么用程序来实现)。
在这次找编解码的过程中,我们受益良多。
一开始找的都是那些很大的音频、视频编解码,像ACC、OGG、H.264等等,基本上都看不懂,只能知道它是干什么的。
后来又找到了曼彻斯特编码、AMI编解码,结果有人已经做了,所以最后我们选了Base64编解码。
所以这次作业让我们了解了好多以前完全没有接触过的代码,收获颇丰。