第三章查找与排序技术
查找排序
解:① 先设定3个辅助标志: low,high,mid, 显然有:mid= (low+high)/2 ② 运算步骤:
(1) low =1,high =11 ,故mid =6 ,待查范围是 [1,11]; (2) 若 S[mid] < key,说明 key[ mid+1,high] , 则令:low =mid+1;重算 mid= (low+high)/2;. (3) 若 S[mid] > key,说明key[low ,mid-1], 则令:high =mid–1;重算 mid ; (4)若 S[ mid ] = key,说明查找成功,元素序号=mid; 结束条件: (1)查找成功 : S[mid] = key (2)查找不成功 : high<low (意即区间长度小于0)
while(low<=high)
{ mid=(low+high)/2; if(ST[mid].key= = key) return (mid); /*查找成功*/
else if( key< ST[mid].key) high=mid-1; /*在前半区间继续查找*/ else } return (0); /*查找不成功*/
4 5 6 7
0
1
2
90
10
(c)
20
40
K=90
80
30
60
Hale Waihona Puke 25(return i=0 )
6
讨论:怎样衡量查找效率?
——用平均查找长度(ASL)衡量。
如何计算ASL?
教案数据的排序和筛选

数据的排序和筛选教学目标:1. 理解排序和筛选数据的概念及重要性。
2. 学会使用常用排序和筛选方法对数据进行处理。
3. 能够应用排序和筛选技术解决实际问题。
教学内容:第一章:数据的排序1.1 排序的概念1.2 排序的依据1.3 排序的方法1.4 排序的应用第二章:数据的筛选2.1 筛选的概念2.2 筛选的方法2.3 筛选的依据2.4 筛选的应用第三章:排序和筛选的结合3.1 排序与筛选的关系3.2 排序和筛选的结合方法3.3 结合排序和筛选解决问题的实例3.4 练习:结合排序和筛选处理数据第四章:排序和筛选在实际应用中的重要性4.1 排序和筛选在数据分析中的作用4.2 排序和筛选在决策支持中的应用4.3 排序和筛选在信息检索中的重要性4.4 实际案例分享:排序和筛选在商业决策中的应用第五章:排序和筛选技术的拓展5.1 高级排序方法介绍5.2 高级筛选方法介绍5.3 排序和筛选算法的优化5.4 拓展练习:运用高级排序和筛选技术解决复杂问题教学方法:1. 讲授:讲解排序和筛选的概念、方法和应用。
2. 案例分析:分析实际案例,让学生了解排序和筛选在实际应用中的重要性。
3. 练习:引导学生运用排序和筛选方法解决实际问题。
4. 小组讨论:分组讨论排序和筛选技术的拓展应用。
教学评估:1. 课堂问答:检查学生对排序和筛选概念的理解。
2. 练习题:评估学生运用排序和筛选方法解决问题的能力。
3. 小组报告:评价学生在小组讨论中的表现及对拓展排序和筛选技术的理解。
教学资源:1. 教材:数据排序和筛选相关教材。
2. 案例:提供实际案例,用于分析排序和筛选的应用。
3. 练习题:设计具有代表性的练习题,帮助学生巩固所学知识。
4. 计算机软件:用于演示排序和筛选操作。
第六章:排序和筛选工具的使用6.1 常见排序和筛选工具概述6.2 排序工具的使用方法6.3 筛选工具的使用方法6.4 实践练习:使用排序和筛选工具处理数据第七章:数据可视化与排序筛选7.1 数据可视化的基本概念7.2 排序与筛选在数据可视化中的作用7.3 数据可视化工具的排序筛选功能7.4 案例分析:数据可视化中的排序和筛选应用第八章:排序和筛选的算法原理8.1 排序算法的原理与实现8.2 筛选算法的原理与实现8.3 排序和筛选算法的性能分析8.4 练习:实现简单的排序和筛选算法第九章:大数据排序和筛选9.1 大数据排序和筛选的挑战9.2 大数据排序和筛选的策略9.3 大数据排序和筛选的算法优化9.4 案例分享:大数据环境下的排序和筛选应用第十章:排序和筛选的应用案例分析10.1 营销数据中的排序和筛选应用10.2 金融数据中的排序和筛选应用10.3 社交媒体数据中的排序和筛选应用教学评估:1. 练习题:设计具有代表性的练习题,帮助学生巩固所学知识。
第三章数据处理技术

4、简单的统计函数 AVERAGE 、SUM, MAX, MIN, COUNT、
COUNTA 5、日期和时间函数
TODAY、NOW、YEAR
逻辑函数
AND(logical_test1,logical_test2,...)
一个以上为FALSE时,返回FALSE;全部为TRUE,返回TRUE
字符或数字的输入:输入初值,拖动填充柄(相当 于复制)。
等差(比)数列的输入: –方法一:输入初值及第二值,然后,选中两个值 所在的区域,再拖动填充柄。
–方法二:只输入初值,右拖填充柄,再选择相应 的项,再填入步长。
字符数字混合体:填充时文字不变,最右边的数字 递增。
已定义的序列:输入初值,拖动填充柄。
④数据图表化。数据以图表的形式显示除了能带来良 好的视觉效果之外,还可以帮助制作者和阅读者分析 数据,查看数据的差异、趋势、预测发展趋势等。
2. Excel软件工作环境布局
Excel 工作界面包含有快速访问工具栏、选项卡、 功能区、编辑区、状态栏等,同时它还具有用于工作 簿文档编辑的名称框和编辑栏。
列 号:用字母表示(A~Z、AA~ZZ、AAA ~XFD 共214列)
行 号:用数字按顺序表示(1~1048376 共220行)
3)单元格 单元格:工作表行与列的交叉位置,存储数据的基 本单元。 单元格存储内容可以是:字符串、数字、公式。 单元地址:由单元格所处位置的列号和行号组合而 成,如(A1,B10) 当前单元格:名称框中显示的单元格,也称为“活 动单元格”。
插入函数、定义名称和公式等、进行公式审核、 公式 计算
获取外部数据、连接数据源、排序和筛选、数据 数据 工具、分级显示、数据分析。
如何在Excel中进行数据筛选与排序

如何在Excel中进行数据筛选与排序第一章:Excel中的数据筛选在Excel中进行数据筛选是一种非常常见和必要的操作。
通过数据筛选,我们可以从大量数据中迅速找到我们需要的特定数据。
下面将介绍几种在Excel中进行数据筛选的方法。
1.条件筛选:Excel中的条件筛选功能可以根据用户指定的条件,筛选出符合条件的数据。
首先,在数据区域选中需要筛选的范围,然后点击数据菜单栏中的"筛选"按钮。
接着,在需要筛选的列上单击下拉箭头,在弹出的筛选选项中选择或输入筛选条件,Excel会自动筛选出符合条件的数据。
2.高级筛选:高级筛选功能更加灵活和强大。
首先,在数据区域上方插入一行或一列,用于输入筛选条件。
在新插入的行或列中,输入筛选条件,并将光标定位到数据区域,点击数据菜单栏中的"高级"按钮。
在弹出的对话框中,选择数据区域,并确认筛选条件。
Excel会根据选定的条件筛选数据,并将筛选结果复制到新的位置。
3.文本筛选:Excel中的文本筛选功能可以根据文本内容进行筛选。
比如,在数据区域中的某一列包含有相同的文本或者关键字,我们可以通过点击该列的下拉箭头,选择"筛选",再从弹出的筛选选项中选择需要筛选的文本或者关键字,Excel会自动筛选出包含指定内容的所有数据。
第二章:Excel中的数据排序除了数据筛选,数据排序也是Excel中常用的功能之一。
通过数据排序,我们可以将数据按照特定的顺序进行排列,便于数据的查找和分析。
下面将介绍几种在Excel中进行数据排序的方法。
1.简单排序:Excel中的简单排序功能可以将数据按照指定的列进行升序或降序排列。
首先,在数据区域选中需要排序的范围,点击数据菜单栏中的"排序"按钮。
在弹出的排序对话框中,选择需要排序的列和排序方式(升序或降序),点击"确定"按钮即可完成排序。
2.高级排序:高级排序功能更加灵活和定制化。
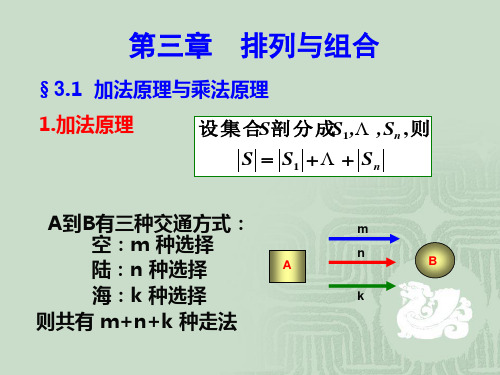
3、组合数学第三章排列组合(1)
P(5,3)
(2)同(1),若不限制每天考试的次数,问有多 少种排法?
53
例3.8 排列26个字母,使得在a 和 b之间正好有7个 字母,问有多少种排法?
例3 用26个字母排列,是元音 a,e,i,o,u 组不相继 出现,有多少种排法?
(1)排列所有辅音:P(21,21)=21! (2)在辅音前后的22个空档中排元音:
n2 +... + nk .
2若r=n,则N= n! ; n1 !n2 !...nk !
3若r < n且对一切i,i =1, 2,..., k,有ni ? r,则N=kr ; 4若r < n,且存在着某个ni < r,则对N没有一般的求解公式。
§3.5 多重集的组合
多重集S中r个元素进行无序选择,构成一个多重 集的r-组合。 篮子里有2个苹果,1个桔子,3个香蕉,篮子里 的水果构成“多重集”。
解1 (1)任意坐: n=9! (2)不相邻:A先就坐,B不相邻:7 其余8人排序:8! m=7*8! (3) P=m/n=7*8!/9!=7/9
例6 10个人为圆桌任意就坐,求指定的两个人 A与B不相邻的概率。
解2 (1)任意坐: n=9! (2)A,B相邻:A先就坐,B左右相邻:2 其余8人排序:8! k=2*8! (3)不相邻:m=9!-2*8! (4) 两人不相邻的概率 P=m/n=(9!-2*8!)/9!=1-2/9=7/9
证明
(1) 从{ 1,2,…,n }中选出2-组合有
C
2 n
(2) 另一种选法:
最大数为k的2-组合共有k-1个,k=1,2,…,n
有加法原理,共有 0+1+2+…+(n-1) 个2-组合
第三章查询

3.3 创建交叉表查询 :
例3.8 在“教学管理设计”数据库中,创建“各系各职称教师人数统计交叉表 查询”。以“教师”表为数据源,行标题为“系别”字段,列标题为“职称” 值为教师人数。
3.4 创建参数查询:
例3.9 在“教学管理设计”数据库中,创建“输入起止工作时间教师参数查 询”。以“教师”表为数据源,通过输入起止工作时间,查询在该时间段内参 加工作的教师。结果显示“教师”表全部字段,提示分别为:“请输入起始时 间”、“请输入终止时间:”。
2、创建总计查询:
例3.5 在“教学管理设计”数据库中,创建“各系教师人数统计”。以“教师” 表为数据源,统计每个系各有多少名教师,结果显示“系别”和“教师人数” 字段。 例3.6 如果学生表中的“学生编号”的前面4位数字表示学生所在的班级号。 统计每个班级的总人数以及学生的平均年龄,结果显示“班级”、“学生人数” 和“平均年龄”字段。 例3.7 以“学生”、“课程”、“选课成绩”表为数据源,创建总计查询。查 询结果要求显示:“学生编号”、“学生姓名”、“合格门数”、“总获学分” 及“所差学分”字段。
3.6.4数据查询
例3.20 以所创建的“学生”为例,设计如下SELECT查询。 (1)从学生表中筛选出所有学生记录,结果显示所有的字段,按“系别”升序、 “年龄”降序排序。 (2)从学生表中筛选出年龄在20到23岁的所有学生记录,结果显示“姓名”、 “年纪”字段,将“年纪”字段重命名为“年龄”。 (3)从学生表中筛选出信息、数学、计算机系的学生记录,结果显示“姓名”、 “性别”、“系别”字段。 (4)从学生表中筛选姓“刘”的学生记录,结果显示“姓名”、“学号”、 “性别”字段。 (5)统计学生表中男、女学生各有多少名,结果显示“性别”、“人数”字段。 (6)从学生、课程、选课成绩表中查询不及格的成绩信息,结果显示“学生编 号”、“姓名”、“课程名称”、“学分”和“成绩”字段。
6第六讲 第三章(盲目、启发搜索)
二、有序搜索
用估价函数 f 来排列OPEN表上的节点。
应用某个算法选择OPEN表上具有最小f 值的节点作为
二、宽度优先搜索
例3.2 八数码问题 操作规定: 允许空格四周上、下、左、右的数码 块移入空格中,不许斜方向移动,不许返回先辈 结点。
1 2 3 8 5 7 4 6
1
4
1 3 8 2 5 7 4 6
2
1 2 3 8 4 5 7 6
3
1 2 3 8 5 7 4 6
5
1 2 3 8 5 7 4 6
深度优先搜索的特点
OPEN表为堆栈,操作是后进先出(LIFO) 深度优先又称纵向搜索。 一般不容易保证找到最优解(如下图所示) 防止搜索过程沿着无益的路径扩展下去,往往 给出一个节点扩展的最大深度——深度界限。
2、有界深度优先搜索
引入搜索深度限制值d,使深度优先搜索具有完备性 。 (1)深度界限的选择很重要 d若太小,则达不到解的深度,得不到解;若太大,既 浪费了计算机的存储空间与时间,降低了搜索效率。由于 解的路径长度事先难以预料,要恰当地给出d的值是比较 困难的。 (2)即使能求出解,它也不一定是最优解。 例3.3:设定搜索深度限制d=5的八数码问题。
4. 搜索过程框图
S0放入OPEN表 是 OPEN表空? 否 将OPEN表中第一个节点(n) 移至CLOSE表 否 n是目标节点? 扩展节点n,把n的后继节点放入 OPEN表末端,提供指向 节点n的指针 修改指针方针,重排OPEN表
失败
是
成功
一、图搜索策略(Graph Search) 5.图搜索方法分析:
3.2 启发式搜索
盲目搜索的不足:效率低,耗费空间与时间。 启发式搜索:利用问题本身特性信息(启发信息) 指导搜索过程。是有序搜索。 一、启发式搜索策略 启发式信息主要用途:
数据结构查找与排序
第二部分 排序
• 各种排序算法的特性
– 时间性能(最好、最坏、平均情况) – 空间复杂度 – 稳定性
• 常见排序算法
– 堆排序-堆的定义,创建堆,堆排序(厦大3次,南航2次,南大3次) – 快速排序 – 基数排序 – 插入排序 – 希尔排序 – 冒泡排序 – 简单选择排序 – 归并排序
一、基于选择的排序
• 快速排序算法关键字的比较和交换也是跳跃式进行的,所以快速排序 算法也是一种不稳定的排序方法。
• 由于进行了递归调用,需要一定数量的栈O(log2n)作为辅助空间
例如
1、快速排序算法在 数据元素按关键字有序的 情况下最不利于发挥其长处。
2、设关键字序列为:49,38,66,80,70,15,22,欲对该序列进行从小到大排序。 采用待排序列的第一个关键字作为枢轴,写出快速排序法的一趟和二趟排序之 后的状态
49
49
38
66
38
10
90
75
10
20
90
75
66
20
10
38
20
90
75
66
49
2.序列是堆的是( C )。 A.{75, 65, 30, 15, 25, 45, 20, 10} B.{75, 65, 45, 10, 30, 25, 20, 15} C.{75, 45, 65, 30, 15, 25, 20, 10} D.{75, 45, 65, 10, 25, 30, 20, 15}
➢ 依靠“筛选”的过程
➢ 在线性时间复杂度下创建堆。具体分两步进行: 第一步,将N个元素按输入顺序存入二叉树中,这一步只要求满 足完全二叉树的结构特性,而不管其有序性。
第二步,按照完全二叉树的层次遍历的反序,找到第一个非叶子结点, 从该结点开始“筛选”,调整各结点元素,然后按照反序,依次做筛选,直到做 完根结点元素,此时即构成一个堆。
文件与文件夹的管理教案
文件与文件夹的管理教案第一章:文件与文件夹的基本概念1.1 文件的概念介绍文件的概念和作用解释文件的类型和特点强调文件在计算机中的重要性1.2 文件夹的概念介绍文件夹的概念和作用解释文件夹的作用和组织方式强调文件夹在管理文件中的重要性第二章:文件与文件夹的创建与管理2.1 创建文件介绍创建文件的方法和步骤解释不同类型的文件创建方式强调创建文件时需要注意的要素2.2 创建文件夹介绍创建文件夹的方法和步骤解释不同类型的文件夹创建方式强调创建文件夹时需要注意的要素2.3 管理文件和文件夹介绍管理文件和文件夹的方法和步骤解释文件和文件夹的复制、移动、重命名等操作强调管理文件和文件夹时需要注意的要素第三章:文件与文件夹的查找与排序3.1 查找文件和文件夹介绍查找文件和文件夹的方法和步骤解释不同类型的文件和文件夹查找方式强调查找文件和文件夹时需要注意的要素3.2 排序文件和文件夹介绍排序文件和文件夹的方法和步骤解释不同类型的文件和文件夹排序方式强调排序文件和文件夹时需要注意的要素第四章:文件与文件夹的共享与权限管理4.1 文件和文件夹的共享介绍文件和文件夹共享的概念和作用解释不同类型的文件和文件夹共享方式强调文件和文件夹共享时需要注意的要素4.2 文件和文件夹的权限管理介绍文件和文件夹权限管理的概念和作用解释不同类型的文件和文件夹权限管理方式强调文件和文件夹权限管理时需要注意的要素第五章:文件与文件夹的备份与恢复5.1 文件和文件夹的备份介绍文件和文件夹备份的概念和作用解释不同类型的文件和文件夹备份方式强调文件和文件夹备份时需要注意的要素5.2 文件和文件夹的恢复介绍文件和文件夹恢复的概念和作用解释不同类型的文件和文件夹恢复方式强调文件和文件夹恢复时需要注意的要素第六章:使用文件管理器6.1 认识文件管理器介绍文件管理器的作用和界面解释如何在不同操作系统中打开文件管理器强调文件管理器在管理文件和文件夹中的重要性6.2 使用文件管理器浏览文件和文件夹介绍如何在文件管理器中浏览文件和文件夹解释不同浏览方式的特点和适用场景强调浏览文件和文件夹时需要注意的要素6.3 使用文件管理器进行文件操作介绍如何在文件管理器中进行文件和文件夹的操作解释不同操作的方法和步骤强调进行文件操作时需要注意的要素第七章:使用搜索功能7.1 认识搜索功能介绍搜索功能的作用和界面解释如何在不同操作系统中使用搜索功能强调搜索功能在快速查找文件和文件夹中的重要性7.2 使用搜索功能查找文件和文件夹介绍如何使用搜索功能查找文件和文件夹解释不同搜索方式的特点和适用场景强调使用搜索功能查找文件和文件夹时需要注意的要素7.3 高级搜索技巧介绍高级搜索技巧的使用解释不同高级搜索技巧的含义和作用强调高级搜索技巧在提高搜索效率中的重要性第八章:文件与文件夹的安全管理8.1 文件和文件夹的安全性介绍文件和文件夹安全性的概念和重要性解释不同类型的文件和文件夹安全性问题强调保护文件和文件夹安全的重要性8.2 使用密码保护文件和文件夹介绍如何使用密码保护文件和文件夹解释不同密码保护方法的特点和适用场景强调使用密码保护文件和文件夹时需要注意的要素8.3 使用加密工具保护文件和文件夹介绍如何使用加密工具保护文件和文件夹解释不同加密工具的特点和适用场景强调使用加密工具保护文件和文件夹时需要注意的要素第九章:文件与文件夹的压缩与解压缩9.1 文件和文件夹的压缩介绍文件和文件夹压缩的概念和作用解释不同类型的文件和文件夹压缩方法强调文件和文件夹压缩时需要注意的要素9.2 使用压缩工具压缩文件和文件夹介绍如何使用压缩工具压缩文件和文件夹解释不同压缩工具的特点和适用场景强调使用压缩工具压缩文件和文件夹时需要注意的要素9.3 文件和文件夹的解压缩介绍文件和文件夹解压缩的概念和作用解释不同类型的文件和文件夹解压缩方法强调文件和文件夹解压缩时需要注意的要素第十章:文件与文件夹的导入与导出10.1 文件和文件夹的导入介绍文件和文件夹导入的概念和作用解释不同类型的文件和文件夹导入方法强调文件和文件夹导入时需要注意的要素10.2 使用导入导出工具导入文件和文件夹介绍如何使用导入导出工具导入文件和文件夹解释不同导入导出工具的特点和适用场景强调使用导入导出工具导入文件和文件夹时需要注意的要素10.3 文件和文件夹的导出介绍文件和文件夹导出的概念和作用解释不同类型的文件和文件夹导出方法强调文件和文件夹导出时需要注意的要素重点和难点解析文件与文件夹的基本概念:理解文件和文件夹的定义及其在计算机存储中的作用是学习的基础。
计算机二级考试选择题必背知识点(公共基础+计算机基础)
计算机二级考试选择题必背知识点公共基础第一章数据结构与算法§1.1 算法1.算法的定义:是指解题方案的准确而完整的描述。
(算法不等于程序,程序的设计不可能优于算法的设计)2.算法的基本特征:可行性、确定性、有穷性、足够的情报。
3.算法的基本要素:4.算法的时间和空间复杂度:算法的时间复杂度和算法的空间复杂度相互独立。
§1.2 数据结构的基本概念1.数据:需要处理的数据元素的集合,一般来说,这些数据元素,具有某个共同的特征。
(1)数据元素是数据的基本单位,即数据集合中的个体。
(2)有时一个数据元素可有若干数据项组成。
数据项是数据的最小单位。
2.结构:是集合中各个数据元素之间存在的某种关系(或联系)。
3.数据结构:是指相互有关联的数据元素的集合。
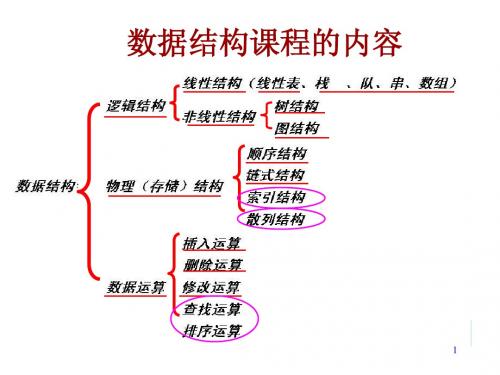
4.数据结构的分类:(1)逻辑结构:线性结构(线性表、栈、队列);非线性结构(树、图)。
(2)存储结构:顺序存储;链式存储。
(3)运算:插入、删除、查找、排序。
5.逻辑结构:反应数据元素间的逻辑关系(即前后件关系)的数据结构。
(1)线性结构(线性表):(举例:春→夏→秋→冬)a.有且只有一个根节点,它无前件;b.每一个节点最多有一个前件,也最多有一个后件。
(2)非线性结构:a.不满足以上两个条件的数据结构就称为非线性结构;b.非线性结构主要是指树形结构和网状结构。
6.存储结构:又称为数据的物理结构,是数据的逻辑结构在计算机存储空间中的存放方式(1)顺序存储结构:主要用于线性的数据结构,它把逻辑上相邻的数据元素存储在物理上相邻的存储单元里。
(2)链式存储结构:每一个结点至少包含一个指针域,用指针的指向来体现数据元素之间在逻辑上的联系。
§1.3 线性表及其顺序存储结构1.线性表:线性表是n(n≥0)个数据元素构成的有限序列,表中除第一个元素外的每一个元素,有且只有一个前件,除最后一个元素外,有且只有一个后件。
举例:英文字母表、地理学中的四向、表格2.线性表的顺序存储结构:通常线性表可以采用顺序存储和链式存储,但一般使用顺序存储结构。
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
理解各种查找与排序算法的基本思想,并根据问 题要求选用合适的数据结构,写出具体算法。
3.1 基本查找技术
3.1.1 查找的基本概念
查找,也称为检索。是数据处理中最基本的操作之一.在我 们日常生活中,随处可见查找的实例。如查找某人的地址、电 话号码;查某单位45岁以上职工等,都属于查找范畴。本书 中,我们规定查找是按关键字进行的。
i
jk
经过一次比较后情形(因V(k)=68>x , 故 j=k-1=4,k=(i+j)/2=2
[ 8 17 25 44 ] 68 77 98 100 115 125
ik
j
经过二次比较后情形 (因V(k)=17,查找成功
查找x=120的示意图
[ 8 17 25 44 68 77 98 100 115 125 ]
关键字(key):数据元素(或记录)中某个数据项的值, 用它可以标识(或识别)一个数据元素。
例如,描述一个考生的信息,可以包含:考号、姓名、性 别、年龄、家庭住址、电话号码、成绩等关键字。但有些关键 字不能唯一标识一个数据元素,而有的关键字可以唯一标识一 个数据元素。如考生信息中,姓名不能唯一标识一个数据元素 (因有同名同姓的人),而考号可以唯一标识一个数据元素(每 个考生考号是唯一的,不能相同)。我们将能唯一标识一个数 据元素的关键字称为主关键字,而其它关键字称为辅助关键字 或从关键字。
i 初始情况(i=1 , j=10 , k=(i+j)/2=5)
j
8 17 25 44 68 [ 77 98 100 115 125 ]
ki
j
经过一次比较后情形(因V(k)=68<x , 故 i=k+1=6,k=(i+j)/2=8
8 17 25 44 68 77 98 100 [ 115 125 ]
3.1.3 有序表的对分查找
如果线性表中元素是按其值递增或递减排列,则在进行 查找时可不必逐个比较,而可采用跳跃式查找,称对分查找 (折半查找或二分查找)。
1、对分查找的基本思想
设有序线性表的长度为n,被查元素为x。首先将待查元 素x与线性表的中间项进行,分三种情况 ① 相等,则查找成功; ② 若x小于中间项,则在线性表的前半部分以相同的方法继
kij 经过二次比较后情形 (因V(k)=100<x, 故 i=k+1=9,k=(i+j)/2=9
8 17 25 44 68 77 98 100 115 [ 125 ]
k ij 经过三次比较后情形 (因V(k)=115<x, 故 i=k+1=10,k=(i+j)/2=10
经过三8次比17较后25情形44(因68V(k7)7=1195<8x, 1故00i=k1+1=59,[ 1k2=5(i+]j)/2=9
3.1.2 顺序查找
基本思想:从表的一端开始,顺序扫描线性表,依次将扫描 到的结点关键字和待找的值K相比较,若相等,则查找成功, 若整个表扫描完毕,仍末找到关键字等于K的元素,则查找 失败。
从上述算法设计思想可看出,当查找的结点很多时,顺 序查找效率低,而且算法执行时间与被查元素位置有关。如 在第一个,查找一次成功;如在最后一个或不存在,则必须 搜索完整个表。但这种算法比较简单,对数据结构也无特殊 要求,既适用于顺序结构,也适用于链式结构。
算法3.2 在头指针为Head的线性表中查找元素x在表中位置
PROCEDURE LSERCH(V, Next , Head, x, k) k=Head; while ( k≠0) AND ( V(k) ≠x) DO k=Next(k) ; IF k=0 THEN k=-1 RETURN;
顺序查找法的时间复杂度为 O(n) 空间复杂度为 O(1)
第三章 查找与排序技术
3.1 基本查找技术 3.2 哈希(Hash)表技术 3.3 基本的排序技术 3.4 二叉排序树及其查找
本章主要介绍:
常用的查找(顺序查找、有序表的对分查找、分 块查找、二叉排序树的构造及查找)与排序(冒泡排 序、快速排序、插入排序、希尔排序、选择排序、堆 排序)算法,阐明这些算法的基本思想,讨论当采用 不同的数据结构时,算法的实现及效率。
例如,假设给定有序表中关键字为: {8,17,25,44,68,77,98,100,115,125},将查找x=17和x=120。
查找x=17的示意图
[ 8 17 25 44 68 77 98 100 115 125 ]
iห้องสมุดไป่ตู้
j
初始情况(i=1 , j=10 , k=(i+j)/2=5)
[ 8 17 25 44 ] 68 77 98 100 115 125
续查找; ③ 若x大于中间项,则在线性表的后半部分以相同的方法继
续查找; 这个过程一直进行到查找成功或子表长度为0(查找失
败)为止。
i
x=y 时找到
x<y 时找这一半
y
x>y 时找这一半
j
从上述查找思想可知,每进行一次关键字比较,区间数 目增加一倍,故称为对(二)分(区间一分为二),而区间长 度缩小一半,故也称为折半(查找的范围缩小一半)。即每 次可减少一半的工作量,因而查找效率较高。但它仅适用于 有序表,且只限于顺序存储结构。而对无序表或链式存储结 构无能为力(因链式存储结构地址不连续,不能确定中间项y 的地址)。
有了主关键字及关键字后,我们可以给查找下一个完整的 定义。
查找:根据给定的值,在一个表中查找出其关键字等于给定值 的数据元素,若表中有这样的元素,则称查找成功;若表中 不存在这样的记录,则称查找失败。
因为查找是对已存入计算机中的数据所进行的操作,所 以采用何种查找方法,首先取决于使用哪种数据结构来表示 “表”,即表中结点是按何种方式组织的。为了提高查找速 度,我们经常使用某些特殊的数据结构来组织表。因此在研 究各种查找算法时,我们首先必须弄清这些算法所要求的数 据结构,特别是存储结构。
算法3.1 在顺序存储的长度为n的线性表中查找元素x在表中位置
PROCEDURE SERCH(V, n, x, k)
k=1;
while ( k≤n) AND ( V(k) ≠x) DO
k=k+1;
IF k=n+1 THEN k=-1
>0 表示找到 V(k)=x
RETURN;
返回值k
=-1 表示未找到k>n且V(k) ≠x