基于主成分线性加权综合评价的信用评分方法及应用
主成分分析方法及其应用效果评估

主成分分析方法及其应用效果评估主成分分析(Principal Component Analysis,简称PCA)是一种常用的数据降维技术,被广泛应用于数据分析、模式识别和机器学习等领域。
本文将介绍主成分分析的基本原理、具体方法以及其在实际应用中的效果评估。
一、主成分分析的基本原理主成分分析是一种统计分析方法,旨在将具有相关性的多个变量转化为一组线性无关的新变量,称为主成分。
通过降维,主成分分析可以有效减少数据的维度,并保留原始数据中的大部分信息。
主成分分析的基本原理是通过找到数据中的最大方差方向来构建主成分。
具体步骤如下:1. 标准化数据:对原始数据进行标准化处理,使得每个变量具有相同的尺度。
2. 计算协方差矩阵:计算标准化后数据的协方差矩阵。
3. 计算特征值与特征向量:对协方差矩阵进行特征值分解,得到特征值和对应的特征向量。
4. 选择主成分:根据特征值的大小排序,选择前k个特征值对应的特征向量作为主成分。
5. 构建主成分:将选择的主成分按权重线性组合,得到原始数据的主成分。
二、主成分分析的具体方法主成分分析可以通过多种计算方法实现,其中最常用的是基于特征值分解的方法。
下面介绍主成分分析的具体计算步骤:1. 标准化数据:对原始数据进行标准化处理,使得每个变量具有均值为0、方差为1的特性。
2. 计算协方差矩阵:将标准化后的数据计算协方差矩阵。
3. 特征值分解:对协方差矩阵进行特征值分解,得到特征值和对应的特征向量。
4. 选择主成分:根据特征值的大小选择前k个特征向量作为主成分。
5. 构建主成分:将选择的主成分按权重线性组合,得到原始数据的主成分。
三、主成分分析在实际应用中的效果评估在应用主成分分析时,我们需要对其效果进行评估,以确保选择的主成分能够充分保留原始数据的信息。
常用的效果评估方法有以下几种:1. 解释方差比(Explained Variance Ratio):解释方差比可以衡量每个主成分对原始数据方差的贡献程度。
浅谈统计综合评价中主成分分析法的应用

③ 在主成分分析将原始变量变换
为成分的过程中 , 同时形成了反 映成分和指标包含信息量的权 数 , 以计算综合评价值 , 这比人为 地确定权数 , 工作量少些 , 也有助 于保证客观地反映样本间的现实 关系。 此外 , 随着电子计算机技术 的 发 展 , SAS、 SPSS等 商 品 化 统 计 分析软件的推广与应用 , 使得主 成分分析在各类综合评价实践中 的广泛应用成为现实。
GONGZUOYANJ IU
等功能于一身 , 是世界著名的统 计分析软件之一。 因此 , 我们可以 利用 SPSS中的主成分分析模块进 行评价。 具体做法是 : 将参评指标的 数据导入软件后 , 在分析模块上 选择主成分法进行分析。在矩阵 方差最大旋转” 它 旋转方面 , 取“ 。 是一种正交旋转方法。它使每个 因子上的具有最高载荷的变量数 最小 , 可以简化对因子的解释。 其 余的都可按系统默认值确定。最 后我们用第一主成分的特征向量 与原始指标值的线性加权的值得 出综合值 , 并根据其分值对企业 由高到低进行排序。 总之 , 综合评价的过程实际 上是理论与实践相结合的过程。 没有经济理论和统计专业知识的 而主 支持 , 是体现不出科学性的。 成分分析在综合评价中的应用可 避免许多人为因素 , 使评价结果 更为科学。 此外 , 由于计算机的普 及和计算软件的发展 , 使得进行 主成分分析已变成一件逐渐普遍 和十分容易的事情了。
通过数学计算可将p个原始指标的总方差分解为p个不相关的综合指标的方差之和方差达到最大贡献率最大第二个综合指标y的方差次大以此类推一般前面几个综合指标yp即可包含总方差中绝大部分也就是说主成分分析可以使原始指标的大部分方差集中于少数几个主成分综合指标上通过对这几个主成分的分析来实现对总体的综合评价
工作研究
基于主成分分析算法的信用评估模型研究

基于主成分分析算法的信用评估模型研究一、引言信用评估是金融领域中的重要问题,它可以帮助银行和其他金融机构评估借款人的信用风险,以决定是否向其发放贷款。
随着金融信息化技术的发展,越来越多的金融机构开始采用机器学习方法进行信用评估,以提高评估质量和效率。
本文将介绍一种基于主成分分析算法的信用评估模型,并探讨其优缺点和应用前景。
二、背景传统的信用评估方法往往依赖于贷款人提供的财务和背景资料,这种方法的主要问题在于可能存在欺诈行为和数据不全等情况。
另一方面,随着互联网金融的兴起,越来越多的贷款人开始使用网络平台进行借贷,这种方式更加强调快速和便利,传统的信用评估方法已无法满足这种需求。
为了解决这一问题,机器学习方法逐渐应用于信用评估领域。
对于金融机构来说,使用机器学习方法可以帮助它们更好地评估借款人的信用风险,并提高贷款的成功率。
同时,对于借款人来说,使用机器学习方法不仅可以提高成功借贷的概率,还可以在一定程度上降低借贷成本。
三、主成分分析算法主成分分析算法又称为PCA,是最常用的无监督降维算法之一。
它的基本思想是找到一个新的坐标系,使得数据能够在新的坐标系下得到最大的方差。
具体方法是将高维数据映射到低维空间中,从而达到减少数据冗余的目的。
在信用评估中,我们可以将PCA算法应用于借款人的行为数据和信用历史数据。
例如,如果一个借款人在信用卡账单上有很高的滞纳金和逾期次数,那么这个行为可能代表着他的还款能力不足。
而如果借款人的信用历史记录中有很多欠款和违约记录,那么这个历史记录可能代表着他的信用worthiness低。
由此可以看出,PCA算法可以帮助Goldman Sachs等金融机构更好地评估借款人的信用worthiness。
其基本思想是将行为数据和信用历史数据分别表示为不同的特征,并将它们映射到低维空间中。
之后,评估模型将根据映射后的数据进行信用worthiness评估,并决定是否向该借款人发放贷款。
四、优缺点PCA算法有以下优点和缺点:优点:1. 可以有效减少数据冗余,提高数据的处理效率;2. 可以将高维数据映射到低维空间中,方便进行数据可视化和分析;3. 不需要任何先验知识或人工干预。
基于主成分分析法对信贷风险的综合评估

21 年第3 总第17 01 期( 3 期)
基于主成分分析法对信贷风险的综合评估
张子 夜
( 河北 大学 经济学院, 河北 保定 0 10 ) 7 00
摘
要: 主成分分析法 简便 、 学, 科 运用该方 法对企业做 出的综合评 估 , 可以作为 商业银行 贷款决策 的重要依 据 , 对
再 以各主成分 的特征值 占所提取 主成分的 比 重为权重 , 对各主成分进行综合 , 获得其综合评价值
降低商业银行的贷款风险、 提高银行 信贷资产质量有积极作 用。
关 键 词: 信贷风险; 主成分分析 ; 决策模型
中图分类号 :8 21 F3 . 文献标识码 : A 文章编号 :0 6 34 (0 )3 0 4 — 2 10 — 5 4 2 1 0 — 0 3 0 1
主成分分析也称 主分量分析 , 它通过对原来相 关的各原始变量作数学变换 , 使之成为相互独立的 分量 , 根据每个分量的贡献率选择主分量 , 然后再对 主分量计算综合评价值 。 使用这种方法的优点在 于: 消除了评价指标间的相关影 响; 减少 了指标选择的
化处 理后 得 。
三 、 算样 本 相 关 矩 阵R, 特 征 值 与 计 求R
贡献率
借 助 =ssl.统计 软件 , 得样 本 的相关 矩 阵  ̄ ps30 : 求
、
指标体 系的建立
本文主要是采用公司财务绩效评价指标体现企 业 的信贷风险 , 主要指标有 : 销售净利率 ( 1 、 x )资产 报酬率 ( 2 、 x )主营业务利润率( 3 、 x )总资产周转率 (4 、 x )应收账款周转率 ( 5 = x )销售收入/0 ( [. 期初 5×
主成分分析在综合评价中的应用

主成分分析在综合评价中的应用作者:王丽芳来源:《经济研究导刊》2012年第19期摘要:应用主成分分析原理,以较小的综合变量取代原有的多维变量,并且能客观的确定权数,避免主观随意性。
把原指标综合成几个主成分,再以这几个主成分的贡献率为权数构成加权平均,构造出一个综合评价函数。
给出了多指标复杂系统的排序方法,它排除了各指标间的相关性和量纲的不一致性,使系统信息不重叠,得到的排序结果合理可信。
关键词:主成分分析;综合评价;排序中图分类号:F22 文献标志码:A 文章编号:1673-291X(2012)19-0219-05引言排序问题在我们日常生活中经常碰到,对单指标系统中的各样本点进行排序,可按指标值的大小排序就可以了,而对多指标系统中的各样本点要进行排序就不能按各指标值的大小这一简单原则进行了,一个常用方法是对各指标进行总和平均后,按平均值的大小进行排序。
但有时由于各指标间的量纲不一样,就不能进行加法运算了。
再者,即使各指标间的量纲一致,可以作加法运算,而各指标反映系统侧面不同,对系统的作用不一样,作加法运算时,存在一个权系数的处理问题,而权系数的取定没有一个统一的标准,这样就不能得到统一的排序结果,同时,在很多情况下各指标间有一定的相关性,甚至是严重相关,从而使得这些指标所提供的信息在一定的程度上有所重叠,求和时系统信息会重叠计算,也不能得到令人信服的排序结果,本文利用主成分分析原理,对多维空间实行降维处理,在系统变异信息损失最小的情况下,得到线性无关的几个主成分,利用主成分得分,对系统中各样本点进行综合评价,这样就排除了各指标间由于量纲不同和信息重叠所造成的影响,不用人为规定权系数,排除主观因素的干扰,使得计算结果更加科学、真实可靠。
一、主成分分析法原理[1]设系统中各指标向量的均值为,协方差阵为,考虑线性组合:y1=l′1X=l11x1+l21x2+…+lp1xpy2=l′2x=l12x1+l22x2+…+lp2xp………………………………y p=l′pX=l1px1+l2px2+…+lppxp(1)由随机向量变换的性质,显然有:var(yi)=l′i∑li (i=1,2,…,p)cov(yi,yj)=l′i∑lj (i,j=1,2,…,p)在式(1)中的y1,y2,…,yp分别称为X=(x1,…,xp)′的第一主成分,第二主成分,…,第P主成分,如果它们满足:(1)yi与yj(i≠j)不相关;(2)y1是X的一切线性组合中方差达到最大的;y2是与y1不相关的一切X的线性组合中方差达到最大的,…,yi是与y1,…,yi-1(i=1,2,…,p)都不相关的一切X的线性组合中方差达到最大的。
基于主成分分析的综合评价
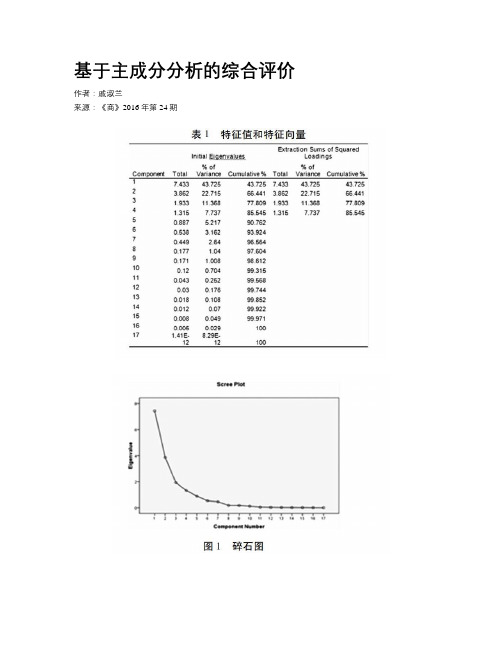
基于主成分分析的综合评价作者:戚淑兰来源:《商》2016年第24期摘要:研究综合评价研究问题关于社会、环境、经济等很多领域,是将事物的时效性,准确性,经济性以及满意性等方面进行评价的过程。
这要经过一定的途径将许多评价指标值合成一个综合性的评价指标值,从而进行综合评价。
主成分分析是一种重要的统计分析方法,它不仅可以想办法把原来很多具有一定相关关系的指标重新组合成一组新的且相互之间没有关系的指标,而且还能显示出比较客观的权重。
关键词:主成分分析;综合评价;环境污染;工业发展;spss.一、引言评价是一个综合咨询、计算和观测等方法的一个综合分析的过程。
但是这个过程需要评价者做出相应的指示。
综合评价就是将事物的准确性,时效性,经济性以及满意性等方面进行评价的过程。
但是评价者在评价这个过程中很容易主关干预,造成评价的结果偏离原来的结果。
多元统计分析是探讨多维变量总体,总体的每一个个体都可用p项指标来表示,虽然指标多能够描述详尽,显示细腻的一方面;但由于指标很多就较易造成分不清主次,对研究的对象很难做一个直接清楚的判断。
而主成分分析作为综合分析的一种统计方法,能够比较好的保证评价的结果是客观的。
主成分分析作为了一种比较科学的、客观的评价方法。
使综合评价的结果更加的科学,更加的实效。
二、研究背景人类的生产及生活过程与环境资源和生态环境有着很强的关系。
随着科学技术与经济的发展,人民生活水平的提高,工业的发达,废弃废料的排放造成很大程度的环境破坏和环境污染。
中国作为一个发展中国家,随着改革开放和经济的高速发展,环境污染也随之呈加剧之势。
经济发展与环境污染已经成为一个越来越重要的话题。
现在我们国家处于经济转型期,要把经济效益、环境保护以及产业结构相结合起来,形成经济新常态。
运用主成分分析综合评价的方法,寻找各省市经济发展、工业产值与环境污染状况之间的关系,而且对评价结论进行了解释。
三、主要思路经过探讨指标体系里面的结构关系就可以把许多个指标转换为相互之间没有关系的、含有初始指标的大部分内容的少数的几个综合性指标,运每个主成分的方差贡献率对那些指标加权得到综合评价得分。
基于主成分分析的综合评价模型

基于主成分分析的综合评价模型在数据分析领域中,主成分分析(Principal Component Analysis,简称PCA)是一种常用的降维技术,它能够将高维的数据转化为较低维的数据,并保留数据的主要信息。
基于主成分分析的综合评价模型则是在PCA的基础上,对多个评价指标进行综合评价的模型。
本文将介绍基于主成分分析的综合评价模型的原理和应用。
一、主成分分析(PCA)简介主成分分析是一种通过线性变换将原始数据转化为低维空间的技术。
它通过找到数据中的主要方向,将数据投影到新的坐标系中,使得投影后的数据具有更好的可解释性和区分性。
主成分分析的基本步骤包括特征值分解、选择主成分和投影计算。
二、综合评价模型的构建方法基于主成分分析的综合评价模型的构建方法包括数据准备、特征值分解、主成分选择和综合评价计算。
首先,需要收集和整理待评价的指标数据,并进行归一化处理,以消除不同指标之间的量纲差异。
然后,对归一化后的指标数据进行特征值分解,得到特征值和特征向量。
接下来,选择主成分,可以根据特征值的大小顺序,选择前几个特征值对应的特征向量作为主成分。
最后,利用选定的主成分对原始指标数据进行投影,得到综合评价结果。
三、基于主成分分析的综合评价模型的应用举例以某酒店为例,我们希望对其服务质量进行综合评价。
我们收集了以下几个指标作为评价依据:员工态度、服务速度、设施条件和价格水平。
首先,对这些指标进行归一化处理,然后进行特征值分解。
假设得到的特征值分别为λ1、λ2、λ3、λ4,对应的特征向量分别为v1、v2、v3、v4。
根据特征值的大小顺序,我们选择前两个特征值对应的特征向量作为主成分。
然后,我们利用选定的主成分对原始指标数据进行投影计算,得到综合评价结果。
假设原始指标数据为X1、X2、X3、X4,对应的投影结果为Y1、Y2。
最后,通过采用某种评分方法,将投影结果转化为能够描述酒店服务质量的综合评价得分。
四、基于主成分分析的综合评价模型的优势与不足基于主成分分析的综合评价模型具有以下优势:首先,可以将多个指标融合为一个综合指标,简化评价过程;其次,可以消除不同指标之间的量纲差异,减小指标权重确定的困难。
主成分分析主成分计算综合评分公式

主成分分析主成分计算综合评分公式主成分分析的基本原理是寻找一个新的坐标系,使得数据在新坐标系下的方差最大化。
这个新坐标系的基向量称为主成分,是原始数据向量的线性组合。
主成分分析的目标是找到一个转换矩阵,将原始数据映射到主成分空间,从而找到最能代表原始数据特征的主成分。
主成分的计算可以通过协方差矩阵的特征值分解来实现。
设原始数据矩阵为X,其中每一行为一个样本,每一列为一个特征。
首先,计算原始数据的均值向量μ,然后将每个特征减去其均值,得到零均值的数据矩阵X'。
接着,计算协方差矩阵C=1/(n-1)*X'*X'的转置,其中n为样本数量。
对协方差矩阵进行特征值分解,得到特征值λ和特征向量V。
按照特征值从大到小的顺序排列特征向量,选取前k个特征向量构成主成分,其中k为降维后的维度。
主成分得分的计算可以通过原始数据矩阵和主成分矩阵的乘积来实现。
设主成分矩阵为P=[v1,v2,...,vk],其中vi为第i个主成分的特征向量,原始数据矩阵为X,由n个样本组成。
则主成分得分矩阵为Y=X*P,其中Y的每一行对应一个样本在主成分空间的坐标。
综合评分公式是一种基于主成分分析结果计算样本综合得分的方法。
在主成分分析中,主成分可以看作是原始数据中的一种变化,反映了数据样本在不同方向上的变化程度。
综合评分可以通过将每个主成分乘以其贡献率得到,然后对结果求和,从而综合反映各主成分对样本的影响程度。
具体而言,设主成分向量为v=[v1,v2,...,vk],其贡献率为λ=[λ1,λ2,...,λk],样本数据矩阵为X,其中每一行为一个样本。
主成分得分矩阵为Y=X*P,综合评分向量为Z=Y*v。
综合评分Z可以表示为Z=z1*v1+z2*v2+...+zk*vk,其中zi为第i个主成分的得分,vi为第i 个主成分的向量。
这样,综合评分Z即为将各主成分的得分按照其贡献率加权求和得到的结果。
综合评分公式的计算可以通过以下步骤实现:1.计算主成分矩阵P和贡献率向量λ;2.计算主成分得分矩阵Y=X*P;3.计算综合评分矩阵Z=Y*v,其中v为主成分矩阵;4.对综合评分矩阵Z的每一行求和,即可得到样本的综合评分。
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
等造成的评价偏差。
根据主成分方法的特点, 当样本不同时会得到不同 的
主因 子和系数, 这样可 以将经济环 境相差 比较大 的地区,
作 为不同 的样 本来计 算, 得出 不同 的计 算得 分的 综合 函
数, 并由此设定与此相对应的信用等级标准和信用额度 标
准。基于相同的原因, 该方法也可以很方便地实现同一 地
第 22 卷第 8 期( 总第 128 期) 系 统 工 程 2004 年 8 月 Syst ems Engineering
文章编号: 1001-4098( 2004) 08- 0064-05
Vol. 22, No. 8 Aug. , 2004
基于主成分线性加权综合评价的信用评分方法及应用X
选取的原 始评价指标 包括年龄、收入等 14 个, 使用 SP SS 11. 0 作为计算工具[ 6] 。
( 1) 训练样本的计算结果 经过 数 据 预处 理 后 SP SS 给出 KMO 值 为 0. 787> 0. 5, Ba rtlett 球度检验为显著, 表示进行主成分分析是合 适的。取特征值大于 0. 8 作为截取因子的标准, 用正交极 大法转动 方差, 进 行因子分 析, 选取前 10 个主 成分, 此时 方差总解释量为 86. 74% 。 通过各因 子的权重系 数并按照 回归法 计算出 最后的
y = 0. 49X 1 + 7. 07X2 + 6. 79X3 + 8. 60X4 + 4. 39X5
+ 6. 16X6 + 0. 48X7 + 4. 73X 8 + 5. 50X9 + 6. 97X10
+ 8. 00X11 + 7. 48X12 + 8. 16X13 + 7. 93X14
F = a 1z1 + a2z 2 + … + aszs
( 1)
式中, z i 为第 i 个主成分, a i 为贡献率:
ai =
Ki
k
∑Km
m= 1
l
∑Km
atl =
m= 1 k
, i , l = 1, 2, …, k
∑Km
m= 1
( Ki 为从大到 小排列 的第 i 个特征 值, a tl 为主成 分 z 1 到 zl
方法的基 本思想和实 现步骤可 以通过 图 1 来 直观表
示。
3 实证结果
对本文第二部分所述的模型方法进行实证检验 , 使用 的样本情况如下:
总样本为 1350 个 实际信 用卡数 据记录, 训练 数据集 为 随机 抽取 的 1000 条记 录 ( 其中 755 个好 人, 245 个 坏 人) , 测试 数据集为 剩余的 350 条记录 ( 262 个 好人, 88 个 坏人) 。
i= 1
( 5) 划分信用等级
根据计算样本的综合得分以及好人坏人的分布 情况,
按照一定的标准和方法设定信用等级, 即给综合得分划分
类别。
( 6) 利用综合函数预测新样本的得分
新申请人 的数据经过 与样本相 同的预 处理并 标准化
后, 使用公式( 3) 计算综合得分, 根据步骤 5 划定的信用等
级, 决定是否给予其信用卡。
本组的数据用于构造预测模型, 而测试样本组的数据用 于
验证预测模型的有效程度。
( 2) 数据的预处理
为保证主成分方法使用的准确性, 将对原始数据进 行
预处 理, 主要 是保证数 据具有同一 的方向 性, 并 且使指 标
数据具有经济含义。按照该思想, 本文将样本数据先按 某
银行的现行标准分类, 然后使用某一具体类中的好人数 与
区综合评价函数的动态变化, 一旦银行认为一个地区的 人
口漂移比较大时, 就可以根据新的样本调整得分函数。
本方法具体的构造过程可以分为以 下几个步骤。
( 1) 研究样本的选取
选取一定数量的“好人”和“坏人”组成 的历史样本, 其
好人和坏人的定义由各银行自己给出。将总样 本随机分为
两组, 一组为训练样本组, 另外一组为测试样本组 。训练样
12 20 32 0. 625 0. 6
总数 7 55 2 45 1 00 0
第 8 期 李建平, 徐伟宣等: 基于主成分线性加 权综合评价的信用评分方法及应用
67
如果申请人的综合得分在 68 分以上即大于两倍标 准 果, 按公式( 3) 可以计算出指标系数, 并得到 综合得分函数
差的, 则作为第一类, 表示信用最高。在样 本中, 属于这 一 为 ( 为 方便 表 示 同 时与 得 分 对 应, 各 系数 均 扩 大 了 100
1 引言
随 着招商银行 “2003, 信用 卡元年”概 念的提 出后, 我 国信用卡市场出现了前所未有的激烈竞 争, 各商业银行 由 此展 开的宣传战、产品 战、价 格战、地域战 等随处 可见, 信 用卡规模急速扩大。出于战略方面的考虑, 现阶段各银 行 都将业务的重点放在了提高发卡量上, 由此不可避免的 带 来对于发卡标准的宽泛化。从发达国家的 经验来看, 随 着 信用卡规模的扩大, 信用卡风险的防范与化解将会成为 焦 点, 宽泛的发 卡标准将 带来更大的 风险, 特别是 在社会 信 用体系还没有效建立和发挥作用的情况 下。因此, 如何 有 效分 析客户的信 用卡风险 状况, 确 立合理 的发卡 标准, 不 仅是发卡机构的首要任务, 而且还是银行进行市场竞争 的 有力武器。
综合得分, 该样本 得分结果 显示了很 好的正态 分布特 性, 如图 2 所示: 均值为 0, 标准差 为 34. 18( 考虑实际状 况, 将 计算分值扩大了 100 倍) 。我们根据该特征 使用标准差分 类方法, 即按均值、一个标准差和两个标准差作为分 类点, 将样本分为 6 类, 每类的相关情况列于表 1。
坏人数的比值作为主成分计算的输入数 据。这 不但保证了
各指标数据具有同一的方向性, 且都有经济意义。例如, 对
于 年龄指 标, 将其分 为 18- 22, 23- 34, 35- 40, 41- 60,
60 以上 等 5 个具体类别, 样本中 18- 22 年 龄段中有好 人
60 个, 坏人 34 个, 则该项输入数据 定为 1. 765( 60/ 34) , 其
李建平1, 徐伟宣1, 石 勇2
( 1. 中国科学院 科技政策与管 理科学研究所, 北京 100080; 2. 中国科学院 研究生院, 北京 100039)
摘 要: 基于我国商业 银行现有的信用卡评 分标准和信用评分 方法, 提出 一种基于主成分线性 加权的综合评 价的信用评分方法。其优点在于能够实现指标项权重 的客观性、能方便地适应我国不同地区由于经济文化 的 差别而带来 的信用环境不同以 及一个地区由于人 口漂移快而带来的评 分变化。实证检验表明 模型训练结果 符合信用卡风险管理实际, 测试结果显示有较好的应用前景, 与现有银行评分标准对比的研究表明, 本文的 方 法具有明显优势。 关键词: 信用卡; 风险管理; 信用评分; 主成分分析 中图分类号: F 830 文献标识码: A
X 收稿日期: 2004-01-16 基金项目: 中国科学院院长基金资助项目( yjj z946) ; 中科院科技政策与管理科学研究所所长基金资助项目( 0343sz) 作者简介: 李建平( 1976-) , 男, 浙江建德人, 中国科学院科技政策与管理科学研究所助理研究员, 博士, 研究方向: 风险管理与数据
余类似处理。
( 3) 进行主成分计算
进行主成分计算时, 首先检验数据是否适合使用主 成
分分析方法 , 检验该方 法的工具主要是 KMO 和 Bar relett
球度 检验, 当 KMO 值 大于 0. 5 球度检 验为显 著时, 使 用
主成分方法是合适的。
( 4) 构建预测函数模型
设选择了 s 个主成分, 则可得估计样 本的评分函数为
65
评估 中所使用的 指标比较 少, 在现 有计算 机条件 下, 主 成
分使 用个数的多 少没有太 大的区别, 之所 以使用 该方法,
主要目的有:
¹ 获得客观权重系数。
主成分方法强调差异性原理, 获得的系数是完全基 于
数据本身, 这样得到的指标权重系数, 具有 客观性, 避免 太
多的人为干扰。
º 可 以很方便地 解决由于 宏观因素 不同及 人口漂 移
66
系 统 工 程 2004 年
图 1 本文方法的基本思想和实现步骤
图 2 样本综合得分分布情况 表 1 训练样本( 1000) 的分类结果
得分值
≥68
34 ~68
0
类 别 好人数 坏人数 Tot al 坏人比率
第1类 27 1 28
2 改进方法的基本思想和构造步骤
在综合评 价函数中, 指标 系数如 何得到是 关键因 素, 该系数至少必须满足以下条件, 才能 较好地具有前文所述 的适应性:
¹ 能够较好地随着样本变化而变化; º 客观性; » 能够保证评价结果的合理性。 针对这些条件, 我们使用主成分 方法来获得系数。主 成分方法( Pr incipal Component s Analysis ) 是由 Hotelling 于 1933 年 提出的, 是利用降 维的思 想将多 指标转 化为少 数几个综合指标的多元统计分析[ 5] 。该方法的特点主要体 现在降维 作用和根据 数据本身 差异性给出 指标间 的相对 重要性。本方法使用主成分方法计算指标系数的主要目的 不在于降 维以减少问 题的复杂 度, 因 为, 在 现有个 人信用
0. 0357
第2类 91 5 96
0. 0521
第3类 35 7 63 42 0 0. 15
第4类 21 0 10 7 31 7
0. 3375
第 5类 58 49 1 07