spss卡方检验与相关分析报告
医学统计学之卡方检验SPSS操作

医学统计学之卡方检验SPSS操作卡方检验(Chi-Square Test)是一种常用的统计方法,用于比较两个或多个分类变量的分布是否存在差异。
该方法主要用于处理分类数据,例如比较男女性别和吸烟与否对癌症发生的关系。
在SPSS(Statistical Package for the Social Sciences)软件中,进行卡方检验的操作主要分为数据准备、假设设定和计算步骤。
第一步:数据准备首先,需要在SPSS中导入数据。
假设我们需要在一个样本中比较男女性别和吸烟与否的关系,我们可以将性别和吸烟状况作为两个分类变量,分别用“Male”和“Female”表示性别,“Smoker”和“Non-smoker”表示吸烟状况。
将这些数据输入到SPSS中的一个数据表中。
第二步:假设设定接下来,需要设置假设。
在卡方检验中,我们通常有一个原假设和一个备择假设:-原假设(H0):两个或多个分类变量之间没有显著差异。
-备择假设(H1):两个或多个分类变量之间存在显著差异。
在本例中,原假设可以是“性别和吸烟状况之间没有显著差异”,备择假设可以是“性别和吸烟状况之间存在显著差异”。
第三步:计算步骤进行卡方检验的计算步骤如下:1.打开SPSS软件并导入数据。
2. 选择“分析(Analyse)”菜单,然后选择“非参数检验(Nonparametric Tests)”子菜单,最后选择“卡方(Chi-Square)”选项。
3.在弹出的对话框中选择两个分类变量(性别和吸烟状况),并将它们添加到变量列表中。
4.点击“确定(OK)”按钮,开始进行卡方检验的计算。
5.SPSS将计算卡方统计量的值和相关的P值。
如果P值小于指定的显著性水平(通常为0.05),则可以拒绝原假设,接受备择假设。
这样,就完成了卡方检验的SPSS操作。
需要注意的是,卡方检验是一种只能说明变量之间是否存在关系的方法,不能用于确定因果关系。
此外,在进行卡方检验之前,需要确保样本符合一些假设,例如每个单元格的期望频数应该大于5、如果不满足这些假设,可以考虑使用其他适用的统计方法。
spss实验报告,心得体会

spss实验报告,心得体会篇一:SPSS实验报告SPSS应用——实验报告班级:统计0801班学号:1304080116 姓名: 宋磊指导老师:胡朝明2010.9.8一、实验目的:1、熟悉SPSS操作系统,掌握数据管理界面的简单的操作;2、熟悉SPSS结果窗口的常用操作方法,掌握输出结果在文字处理软件中的使用方法。
掌握常用统计图(线图、条图、饼图、散点、直方图等)的绘制方法;3、熟悉描述性统计图的绘制方法;4、熟悉描述性统计图的一般编辑方法。
掌握相关分析的操作,对显著性水平的基本简单判断。
二、实验要求:1、数据的录入,保存,读取,转化,增加,删除;数据集的合并,拆分,排序。
2、了解描述性统计的作用,并1掌握其SPSS的实现(频数,均值,标准差,中位数,众数,极差)。
3、应用SPSS生成表格和图形,并对表格和图形进行简单的编辑和分析。
4、应用SPSS做一些探索性分析(如方差分析,相关分析)。
三、实验内容:1、使用SPSS进行数据的录入,并保存: 职工基本情况数据:操作步骤如下:打开SPSS软件,然后在数据编辑窗口(Data View)中录入数据,此时变量名默认为var00001,var00002,…,var00007,然后在Variable View窗口中将变量名称更改即可。
具体结果如下图所示:输入后的数据为:将上述的数据进行保存:单击保存即可。
2、读取上述保存文件:选择菜单File--Open—Data;选择数据文件的类型,并输入文件名进行读取,出现如下窗口:选定职工基本情况.sav文件单击打开即可读取数据。
3、对上述数据新增一个变量工龄,其操作步骤为将当前数据单元确定在某变量上,选择菜单Data—Insert Variable,SPSS自动在当前数据单元所在列的前一列插入一2个空列,该列的变量名默认为var00016,数据类型为标准数值型,变量值均是系统缺失值,然后将数据填入修改。
结果如下图所示:篇二:SPSS相关分析实验报告本科教学实验报告(实验)课程名称:数据分析技术系列实验实验报告学生姓名:一、实验室名称:二、实验项目名称:相关分析三、实验原理相关关系是不完全确定的随机关系。
SPSS 卡方检验
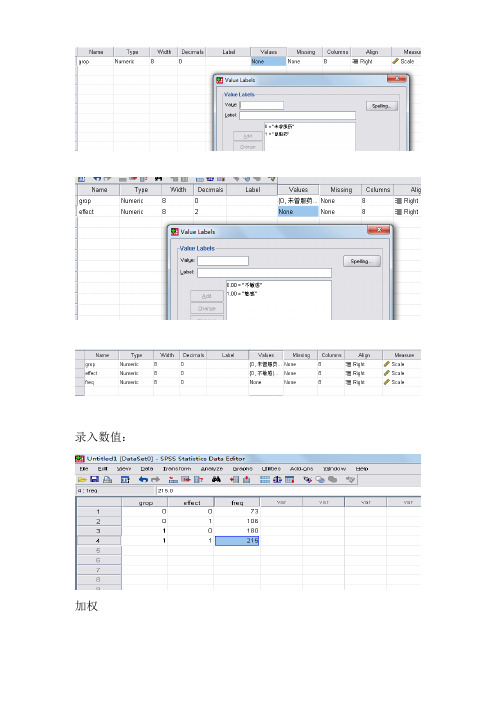
卡方检验1.四格表的卡方检验例1.某药品检验所随机抽取了574名成年人,研究某抗生素的耐药性。
其中179人未曾使用该抗生素,其耐药率为40.78%;而在395例曾用过该药的人群中,耐药率为45.57%,结果见表1,试兑现人和上人群的耐药率是否一样?表1 某抗生素的人群耐药性情况用药史不敏感敏感合计曾服该药180(174.10)215(220.90)395未服该药73(78.90)106(100.10)179合计253 321 574建立变量名:录入数值:加权统计分析指定横标目和纵标目,注意不要选反了,选反了会有什么后果?择分析方法:卡方检验Chi-square结果:实际频数理论频数表一:总例数为574,没有数值遗漏表二:可观察实际频数,理论频数,各组实际频数占各行各列及总数的百分比。
此例题总例数n=574≥40,且所有理论频数T≥5用基本公式或四个表专用公式计算卡方值,结果参照表三第一行。
P=0.285≥0.05还不能认为两组耐药率不同。
表三:(1)总例数n=574≥40,且所有理论频数T≥5用基本公式或四格表专用公式计算卡方值,结果参照表第一行。
(2)如果n≥40但有1<T<5用校正公式计算卡方值或用Fisher确切概率法直接计算概率,结果分别参照第二行和第四行。
(3)n<40或T<1时用Fisher确切概率法直接计算概率,结果参照第四行。
2.配对四格表的卡方检验例5.有28份咽喉涂片标本,把每份标本一分为二,分别接种在甲、乙两种白喉杆菌培养基上,观察白喉杆菌生长的情况,其结果如表5,问两种培养基的阳性检出率是否相等?表5 两种白喉杆菌培养基培养结果比较甲培养基乙培养基+ - 合计+ 11 1 12- 9 7 16合计20 8 28 建立变量名:录入数值:统计分析:结果:3.R*C表(行或列超过两个)的卡方检验(1)多个样本率的比较例6.某医院用三种方案治疗急性无黄疸型病毒性肝炎结果如下,问三种疗法的有效率是否一致?表6三种方案治疗肝炎疗效的结果比较组别有效无效合计有效率(%)西药组51 49 100 51.00中药组35 45 80 43.75中西结合59 15 74 79.73145 109 254 57.09建立变量名:录入数值:统计分析:结果分析:理论均数均大于5,卡方值为22.808。
卡方检验及SPSS分析

Data Weight Cases
• ③ x2检验:从菜单选择 分析 描述统计 交叉表
Analyze Descriptive Statistics Crosstabs • 结合数据(例3.sav)演示操作过程。
实际频数 理论频数
Fisher确切概率
第二节
2
配对资料的 检验 x2 test of paired fourfold data
某新药治疗原发性高血压的疗效
分组
有效
无效
合计
有效率()
试验组
20(a)
8(b)
28
71.43
对照组
2(c)
6(d)
8
25.00
合计
22
14
36
61.11
*例3. x2检验----Fisher确切概率法
(一)适用条件
① T<1或 n<40 ② P≈
(二)基本思想(超几何分布)
在四格表周边合计不变的条件下,直接计算表内四个数据的各
以认为两种剂量注射的结果不同。
SPSS操作过程
• ①建立数据文件:例4.sav 数据格式:包括4行3列的频数格式,三个变量分别为行变量、列变量和频数变 量。
• ②说明频数变量:数据 加权个案
Data Weight Cases
• ③ x2检验:从菜单选择 分析 描述统计 交叉表
Analyze Descriptive Statistics Crosstabs • 统计量Statistics: √ McNemar
mcnemarkappa?选中进行配对卡方检验??p005p005按按005005水准拒绝水准拒绝h0h0接受接受h1h1可以认为两种剂量的毒性有差异可以认为两种剂量的毒性有差异??甲剂量组的死亡率较高因为甲剂量组的死亡率较高因为bc?48?配对四格表mcnemar检验?kappa系数在pearson卡方检验中对行变量和列变量的相关性作检验其中行变量和列变量是一个事物的两个不同属性
SPSS学习系列24. 卡方检验

24. 卡方检验卡方检验,是针对无序分类变量的一种非参数检验,其理论依据是:实际观察频数f 0与理论频数f e (又称期望频数)之差的平方再除以理论频数所得的统计量,近似服从2χ分布,即)(n f f f ee 2202~)(χχ∑-= 卡方检验的一般是用来检验无序分类变量的实际观察频数和理论频数分布之间是否存在显著差异,二者差异越小,2χ值越小。
卡方检验要求:(1)分类相互排斥,互不包容; (2)观察值相互独立;(3) 样本容量不宜太小,理论频数≥5,否则需要进行校正(合并单元格、增加样本数、去除样本法、使用校正公式校正卡方值)。
卡方校正公式为:∑--=ee f f f 202)5.0(χ卡方检验的原假设H 0: 2χ= 0; 备择假设H 1: 2χ≠0; 卡方检验的用途:(1)检验某连续变量的数据是否服从某种分布(拟合优度检验); (2)检验某分类变量各类的出现概率是否等于指定概率; (3)检验两个分类变量是否相互独立(关联性检验); (4)检验控制某几个分类因素之后,其余两个分类变量是否相互独立;(5)检验两种方法的结果是否一致,例如两种方法对同一批人进行诊断,其结果是否一致。
(一)检验单样本某水平概率是否等于某指定概率一、单样本案例例如,检验彩票中奖号码的分布是否服从均匀分布(概率=某常值);检验某产品市场份额是否比以前更大;检验某疾病的发病率是否比以前降低。
有数据文件:检验“性别”的男女比例是否相同(各占1/2)。
1. 【分析】——【非参数检验】——【单样本】,打开“单样本非参数检验”窗口,【目标】界面勾选“自动比较观察数据和假设数据”2.【字段】界面,勾选“使用定制字段分配”,将变量“性别”选入【检验字段】框;注意:变量“性别”的度量标准必须改为“名义”类型。
3. 【设置】界面,选择“自定义检验”,勾选“比较观察可能性和假设可能性(卡方检验)”;4. 点【选项】,打开“卡方检验选项”子窗口,本例要检验男女概率都=0.5,勾选“所有类别概率相等”;注:若有类别概率不等,需要勾选“自定义期望概率”,在其表中设置各类别水平及相应概率。
spss卡方检验与相关分析

【Options钮】
Zero-order correlations 给出包括协变量在 内所有变量的相关方阵。
说明,上年发表的论文数对当年的立项课题数的线性影 响非常弱。前面的是属于虚假相关。
上机作业五
1、以实验3中保存的“数据8.sav”为例,完 成以下任务: 求出性别与工资等级的列联表,要求按性别 输出百分比,求出相关系数,并进行卡方检 验,理解所得结果。 2、对居民储蓄数据中的多选项进行列联表 分析。(要求先定义多选项变量集,用分类 法做频数分析,再选择一个变量,做列联表 分析) 3、试以spss自带的某一个数据文件为例 (建议使用1991U.S.General Social Survey数据)进行分析,了解变量是否相 关,发掘数据中变量间的规律性。
发生变化。
比较边缘百分比和条件百分比的差别。
卡方测量用来考察两变量是否独立(无关)。
Pij Pi. P. j
二、相关分析(Correlate)
(一)简介
相关分析用于描述两个变量间联系的密切 程度,其特点是变量不分主次,被置于同 等的地位。检验的原假设为相关系数为0。 可选择是单尾检验还是双尾检验。
定序
列联 cross-tabulate 积差相关 spearman correlation
积差相关 spearman correlation 积矩相关 pearson correlation 积矩相关 pearson correlation 回归 regression
定距
相关分析之二——关系强度
权威主义和地位欲的相关系数为0.667,这表明权 威主义越高的人地位欲也越高。权威主义与地位欲不 相关的假设检验值为0.003,否定假设,即权威主义与 地位欲是相关的。结果类似于Spearman分析。
SPSS分析报告(二)
SPSS实验分析报告二一、婆媳关系*住房条件检验(一)、提出原假设H0原假设: 婆媳关系的好坏程度与住房条件有关系(二)、两独立样本t检验结果及分析表(一)觀察值處理摘要觀察值有效遺漏總計N百分比N百分比N百分比婆媳关系* 住房条件600100.0%00.0%600100.0%由表(一)可知, 本次调查获得的有效样本为600份, 没有遗漏的个案。
表(二)婆媳关系*住房条件交叉列表住房条件總計差一般好婆媳关系紧张計數577860195預期計數48.868.378.0195.0婆媳关系內的%29.2%40.0%30.8%100.0%住房条件內的%38.0%37.1%25.0%32.5%佔總計的百分比9.5%13.0%10.0%32.5%殘差8.39.8-18.0一般計數458763195預期計數48.868.378.0195.0婆媳关系內的%23.1%44.6%32.3%100.0%住房条件內的%30.0%41.4%26.3%32.5%佔總計的百分比7.5%14.5%10.5%32.5%殘差-3.818.8-15.0好計數4845117210預期計數52.573.584.0210.0婆媳关系內的%22.9%21.4%55.7%100.0%住房条件內的%32.0%21.4%48.8%35.0%佔總計的百分比8.0%7.5%19.5%35.0%殘差-4.5-28.533.0總計計數150210240600預期計數150.0210.0240.0600.0婆媳关系內的%25.0%35.0%40.0%100.0%住房条件內的%100.0%100.0%100.0%100.0%佔總計的百分比25.0%35.0%40.0%100.0%由表(二)可知, 一共调查了600人, 其中婆媳关系紧张的组有195人, 占总人数的32.5%;婆媳关系一般的组有195人, 占总人数的32.5%;婆媳关系好的组有210人, 占总人数的35.0%;数据分布均匀。
卡方检验及SPSS分析82026
-[Display clustered bar charts 复选框]: 显示复式条 图
-[Suppress table复选框]: 不在输出结果中给出行×列
表。
16
.
Crosstabs过程祥解
❖ 界面说明
❖精确(Exact)子对话框: 针对2×2以上的行×列表 设计计算确切概率的方法。
❖统计量(Statistics)子对话框: 用于定义所需计算 的统计量
还是降序排列。
19
.
SPSS结果输出
group* effect 交叉制表
group 实验组 计数
期望的计数
对照组 计数
期望的计数
合计
计数
期望的计数
effect
有效
无效
99
5
90.5
13.5
75
21
83.5
12.5
174
26
174.0
26.0
合计 104
104.0 96
96.0 200
200.0
20
❖ 结合例7-1数据(chis01.sav)演示操作过程。
13
.
分类数据录入格式
频数格式: 用数据 加权个案(Weight Cases)过程 以指明反映频数的变量。
枚举格式:
14
.
交叉表(Crosstabs)过程
❖ Crosstabs过程用于对分类资料和有序分类资料进行 统计描述和统计推断。
❖该过程可以产生2维至n 维列联表, 并计算相应的百 分数指标。
28
.
检验步骤:
H 0 : B C H , 1 : B C , 0 .05
b c 12 2 14 40,用校正公式
SPSS卡方检验
• 结果3:OR的均一性检验,用两种方法比较 性别之间OR是否存在差异(p=0.001)。 说明男性高于女性
• 结果4:又称协变量分析,将性别当做协变 量,即剔除性别这个影响后吸烟与肺癌的 关系。结果显示在剔除性别影响后,吸烟 和肺癌仍然显著相关,即吸烟史导致肺癌 的危险因素。
• 结果5:又称公共OR值估计,合并OR值为2.812,95%置 信区间不包括1,且与1相比差异有显著性(p=0.000) • 注意:经OR值均一性检验各层OR值有显著差异时,不宜 计算公共OR值
关于OR值
• Odds Ratio:相对危险度(也称比值比、优 势比) • 指病例组中暴露人数与非暴露人数的比值 除以对照组中暴露人数与非暴露人数的比 值。 • 涵义:暴露者的疾病危险度为非暴露者的 多少倍。OR>1说明疾病的危险度因暴露而 增加,暴露与疾病为“正”关联。OR<1说 明疾病的危险度因暴露而减少,“负”关 联
• 1.相关性:计算Pearson和 Spearsmen相关系数,用以 说明行变量和列变量的相关 程度。 • 2相依系数:又称列联系数。 也是用来说明相关性。 • 3.Gamma :测量两个等级变 量之间关联度的统计量 • 4.Kappa:Kappa系数,见 下文
• • • •
观察值:观察频数 期望值:期望频数 行百分比:给出行变量百分比 列百分比:给出列变量百分比
(4)结果解释:
Pearson 卡方:非校正卡方检验 连续校正:仅适用于四格表
Fisher 的精确检验:Fisher确切概率检验,也仅 适用于四格表资料 似然比:似然比卡方检验,适用
R C表资料
线性和线性组合:线性相关性检验,两变量均为 等级变量,且从小到大排列时方有意义,其他 情况忽略
SPSS卡方检验的详细解读
SPSS卡方检验的详细解读一、基本概念:卡方检验(一)定义卡方检验主要用于研究定类与定类数据之间的差异关系。
一般使用卡方检验进行分析的目的是比较差异性。
例如研究人员想知道两组学生对于手机品牌的偏好差异情况。
(二)卡方值卡方值表示观察值与理论值之间的偏离程度。
卡方值的大小与样本量(自由度)有关。
一般来说,卡方值越大越好,但并不准确。
比如5000和5010的差异为10;40和50的差异为10,明显后者差异更大。
最终查看卡方值对应的p 值更准确。
二、卡方检验分类(一)方法分类SPSSAU系统中,卡方检验分为【通用方法】中的交叉卡方,以及【医学/研究】模块中的卡方检验、配对卡方、卡方拟合优度、分层卡方五类。
(二)方法对比(1)交叉卡方适用于大部分场景之中,满足大部分用户需求,使用频率高,仅使用Pearson卡方,不支持加权数据。
交叉卡方仅输出一个交叉卡方分析结果如下图:可以看到卡方值为16.667,p =0.000<0.01,所以不同地区的饮食习惯情况呈现出显著性差异。
(2)卡方检验适用于实验医学研究方向,专业性更强,使用频率高。
从上表可知,利用卡方检验(交叉分析)去研究减肥方式对于胆固醇水平共1项的差异关系【独立性】,不同减肥方式样本对于胆固醇水平共1项呈现出显著性(p <0.05)。
总结可知:不同减肥方式样本对于胆固醇水平全部均呈现出显著性差异。
①Pearson卡方、yates校正卡方、Fisher卡方三类卡方,具体选择标准如下图上表格为卡方检验的中间过程值,由于本案例数据为3*2格式,且1 <=E<5 格子的比例大于20%(此处为33.33%),因而最终选择使用yates校正卡方值。
【特别备注: Pearson卡方和yates校正卡方完全相同是正常现象,多数情况下二者完全相等】②加权数据数据格式如下③效应量指标(研究差异幅度情况,效应量值越大说明差异幅度越大,通常情况下效应量小、中、大的区分临界点分别是 0.20,0.50 和 0.80)卡方检验时,通常有5个指标均可表示效应量大小,区别在于使用场合不一样,选择标准如下图:上表格为效应量指标,由于本案例数据为3*2格式,所以使用Cramer V 研究差异幅度情况。
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
发生变化。
比较边缘百分比和条件百分比的差别。
卡方测量用来考察两变量是否独立(无关)。
Pij Pi. P. j
二、相关分析(Correlate)
(一)简介
相关分析用于描述两个变量间联系的密切 程度,其特点是变量不分主次,被置于同 等的地位。检验的原假设为相关系数为0。 可选择是单尾检验还是双尾检验。
性别与四级英语考试通过率的相关统计
1 通过考试 1 男性 2 女性 总计 40% 40% 40% 2 未通过考试 60% 60% 60%
表述:统计结果显示,当性别取值不同时,通过率变量 的取值并未发生变化,因此性别与考试通过率无关。 自变量的不同取值在因变量上无差异,两变量无关。 自变量的不同取值在因变量上有差异,两变量有关。
第五章
相关分析与检验
相关分析之一——有关与无关
寻找变量间的关系是科学研究的首要目
的。变量间的关系最简单的划分即:有关 与无关。
在统计学上,我们通常这样判断变量之
间是否有关:如果一个变量的取值发生 变化,另外一个变量的取值也相应发生 变化,则这两个变量有关。如果一个变 量的变化不引起另一个变量的变化则二 者无关。
可以画散点图先进行判断。
Graphs-legacy-scatter
定序
列联 cross-tabulate 积差相关 spearman correlation
积差相关 spearman correlation 积矩相关 pearson correlation 积矩相关 pearson correlation 回归 regression
定距
相关分析之二——关系强度
计算某个统计量时,在这一对变量 中排除有缺省值的观测值。 对于任何分析,有缺省值的观测值 都会被排除。
一般,如果r的绝对值大于0.8,则认为两变 量之间具有较强的线性相关关系;如果r小 于0.3,则认为两变量之间具有较弱的线性 相关关系。 当然,相关关系的程度与样本的容量大小 也有很大的关系。
例1:为研究高等院校人文社会科学研究中 立项课题数会受哪些因素影响,收集1999 年31个省市自治区部分高校有关社科方面 的数据,研究立项课题数(当年)与投入 的具有高级职称的人年数(上年)、发表 论文数(上年)之间是否具有较强的线性 关系。
定距 Eta 系数
定距
Spearman Spearman 相 相关系数 关系数 同 序 - 异 序 对析之三——关系性质
直线相关与曲线相关 正相关与负相关 完全相关与完全不相关
一、列联相关(第四章已讲)
(一)列联分析的基本原理 自变量发生变化,因变量取值是否也
自变量
1 男性 2 女性 总计
每月工资平均 数 752.40 601.97 680.95
N 452 409 861
因变量
统计结果显示,当性别取值不同时,收入变量 的取值发生了变化,因此性别与月收入有关。
变量关系的统计类型
定类 定类 列联 cross-tabulate 定序 列联 cross-tabulate 定距 方差分析 (分组平均数) compare means
(三)Bivariate相关分析
在进行相关分析时,散点图是重要的工具, 分析前应先做散点图,以初步确定两个变 量间是否存在相关趋势,该趋势是否为直 线趋势,以及数据中是否存在异常点。否 则可能得出错误结论。 Bivariate相关分析的步骤:输入数据后,依 次单击Analyze—Correlate—Bivariate, 打开Bivariate Correlations对话框
在Analyze的下拉菜单Correlate命令项中 有三个相关分析功能子命令Bivariate过程 (二变量相关分析)、Partial过程(偏相关分 析)、 Distances过程(距离分析)。
(二)相关分析类型
Bivariate过程用于进行两个或多个变量间的 相关分析,如为多个变量,给出两两相关的 分析结果。 Partial过程,当进行相关分析的两个变量的 取值都受到其他变量的影响时,就可以利用 偏相关分析对其他变量进行控制,输出控制 其他变量影响后的相关系数。 Distances过程用于对同一变量各观察单位间 的数值或各个不同变量间进行相似性或不相 似性分析,一般不单独使用,而作为因子分 析等的预分析。
变量关系强度的含义:指两个变量相关程度 的高低。统计学中是以准实验的思想来分 析变量相关的。通常从以下的角度分析: A)两变量是否相互独立。 B)两变量是否有共变趋势。 C)一变量的变化多大程度上能由另一变量 的变化来解释。
变量关系强度测量的主要指标
定类 定类 定序
卡方类测量 Lamda 等
定序
卡方类测量 Lamda 等
Bivariate Correlations 对话框
Pearson复选框 选择进行积差相关分析, 即最常用的相关分析,其计算连续变量或 等间隔测度变量间的相关系数。计算该相 关系数时,不仅要求两相关变量均为正态 变量,而且样本数(N)一般不应少于30。
Kendall‘s tau-b复选框 计算Kendall’s等级相 关系数,其计算定序变量间的线性相关关系。 (有打结现象时) Spearman复选框 计算Spearman相关系数。 也是计算等级相关系数(定序与定序)。最 常用的非参数相关分析(秩相关),适用于 连续等级资料。 (无打结现象) 以上三种相关分析可以选择其中之一,也可 以同时多选。如果参与分析的变量是连续变 量,选择Kendall's tau-b或Spearman相关, 则系统自动对连续变量的值先求秩,再计算 其秩分数间的相关系数。
Flag significant correlations 用于确定是否在结果中用星号标记有统计 学意义的相关系数,一般选中。此时 P<0.05的系数值旁会标记一个*,P<0.01的 则标记两个**。
Options 对话框
对每一个变量 输出均值、标准 差和无缺省值的 观测数。 对每一个变量 输出交叉距阵和 协方差距阵。