检验和消除异方差和自相关的报告
异方差、自相关检验及修正

异方差、自相关的检验与修正实验目的:通过对模型的检验掌握异方差性问题和自相关问题的检验方法及修正的原理,以及相关的Eviews 操作方法。
模型设定:εβββ+++=23121i i i X X YYi----人均消费支出X1--从事农业经营的纯收入X2--其他来源的纯收入 中国内地2006年各地区农村居民家庭人均纯收入与消费支出 单位:元 城市 y x1 x2 城市 y x1 x2 北京 5724.5 958.3 7317.2 湖北 2732.5 1934.6 1484.8 天津 3341.1 1738.9 4489 湖南 3013.3 1342.6 2047 河北 2495.3 1607.1 2194.7 广东 3886 1313.9 3765.9 山西 2253.3 1188.2 1992.7 广西 2413.9 1596.9 1173.6 内蒙古 2772 2560.8 781.1 海南 2232.2 2213.2 1042.3 辽宁 3066.9 2026.1 2064.3 重庆 2205.2 1234.1 1639.7 吉林 2700.7 2623.2 1017.9 四川 2395 1405 1597.4 黑龙江 2618.2 2622.9 929.5 贵州 1627.1 961.4 1023.2 上海 8006 532 8606.7 云南 2195.6 1570.3 680.2 江苏 4135.2 1497.9 4315.3 西藏 2002.2 1399.1 1035.9 浙江 6057.2 1403.1 5931.7 陕西 2181 1070.4 1189.8 安徽 2420.9 1472.8 1496.3 甘肃 1855.5 1167.9 966.2 福建 3591.4 1691.4 3143.4 青海 2179 1274.3 1084.1 江西 2676.6 1609.2 1850.3 宁夏 2247 1535.7 1224.4 山东 3143.8 1948.2 2420.1 新疆 2032.4 2267.4 469.9 河南 2229.3 1844.6 1416.4 数据来源:《中国农村住户调查年鉴(2007)》、《中国统计年鉴(2007)》参数估计:估计结果如下:2709030.01402097.01402.728X X Y ++=Λ(2.218) (2.438) (16.999) 922173.02=R D.W.=1.4289 F=165.8853 SE=395.2538实验步骤:一、检查模型是否存在异方差1.图形分析检验(1)散点相关图分析分别做出X1和Y 、X2和Y 的散点相关图,观察相关图可以看出,随着X1、X2的增加,Y 也增加,但离散程度逐步扩大,尤其表现在X1和Y .这说明变量之间可能存在递增的异方差性。
计量经济学实验报告

上海海关学院
实验报告
实验课程名称 __ 计量经济学_ _
指导教师姓名 __ 高军______
学生姓名__王圣___
学生专业班级__税收1401 __
填写日期__2017.6.10
四、模型设定
为分析建筑业企业利润总额(Y)和建筑业总产值(X)的关系,作如下散点图:
Y i=2.368138+0.034980X i (9.049371) (0.001754)
检验
F=;查表可得
绝原假设,此即表明模型存在异方差。
表.用权数w2的结果
(3) w3=1/x^0.5
经估计检验发现用权数w2的效果最好。
可以看出,运用加权最小二乘法消除了异方检验均显著,F检验也显著,即估计结果为
表示国内生产总值。
三、检验自相关
该回归方程可决系数较高,回归系数显著。
dL=1.316,dU=1.469, DW<dL,
,说明在
4.利用EViews软件作如图残差图
LM=TR²=27×0.517409=13.970043,其中p 值为0.0009,表明存在自相关。
自相关问题的处理
由最终模型可知,中国进口需求总额每增加1亿元,平均说来国内生产总值
20。
自相关和异方差处理顺序

自相关和异方差处理顺序引言自相关和异方差是时间序列分析中常见的两种问题,它们影响了模型的准确性和可靠性。
在进行时间序列建模时,需要处理这些问题,以确保模型的有效性。
本文将深入探讨自相关和异方差处理的顺序,并讨论不同处理顺序的影响。
什么是自相关和异方差自相关自相关是指时间序列中当前观测值与之前观测值之间的相关性。
它衡量的是时间序列中各个观测值之间的依赖关系。
自相关可以用自相关函数(ACF)图来表示,通过观察ACF图,可以判断时间序列是否存在自相关。
异方差异方差是指时间序列中方差不稳定的特征。
在时间序列中,方差可能随着时间的推移发生变化,这会导致模型的拟合不准确。
异方差可以用方差函数(VCF)图来表示,通过观察VCF图,可以判断时间序列是否存在异方差。
自相关和异方差处理的重要性自相关和异方差对时间序列建模的准确性和可靠性有重要影响,它们需要被处理以获得可靠的模型结果。
•自相关的存在会导致参数估计不准确,预测结果失真。
如果存在自相关,模型会无法捕捉到序列的真实动态,导致预测结果不准确。
•异方差使得模型的残差不符合正态分布,违背了建模的基本假设。
这会使得模型的显著性检验和置信区间估计不可靠,影响模型的有效性。
因此,为了获得可靠的模型结果,需要对自相关和异方差进行处理。
自相关和异方差处理顺序的影响自相关和异方差的处理顺序会对最终的模型结果产生影响。
不同的处理顺序可能导致不同的模型结构和参数估计。
先处理自相关后处理异方差如果先处理自相关再处理异方差,可能会导致如下影响:1.自相关处理可能会改变时间序列的动态特征。
当我们去除自相关时,可能会削弱序列中的一些重要信息,导致模型无法准确捕捉到序列的动态变化。
2.异方差处理可能会影响自相关的结构。
当我们对残差进行异方差处理时,可能会改变残差序列的结构,从而使得自相关的估计失真。
先处理异方差后处理自相关如果先处理异方差再处理自相关,可能会产生如下影响:1.异方差处理可能改变原始序列的动态特征。
多元线性回归实验报告
实验题目:多元线性回归、异方差、多重共线性实验目的:掌握多元线性回归的最小二乘法,熟练运用Eviews软件的多元线性回归、异方差、多重共线性的操作,并能够对结果进行相应的分析。
实验内容:习题3.2,分析1994-2011年中国的出口货物总额(Y)、工业增加值(X2)、人民币汇率(X3),之间的相关性和差异性,并修正。
实验步骤:1.建立出口货物总额计量经济模型:错误!未找到引用源。
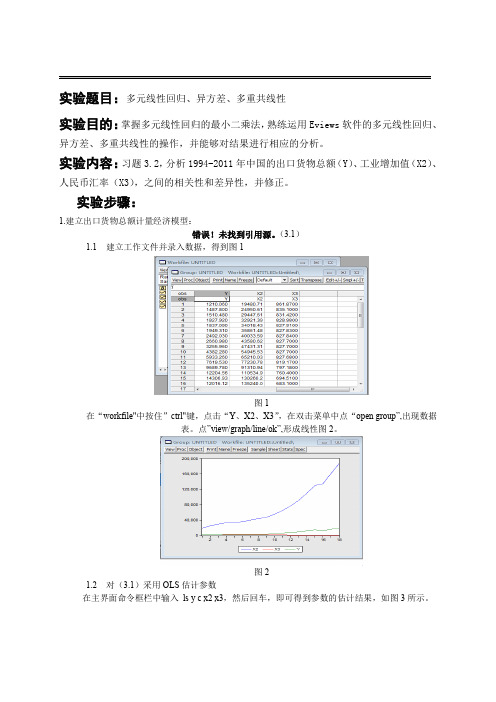
(3.1)1.1建立工作文件并录入数据,得到图1图1在“workfile"中按住”ctrl"键,点击“Y、X2、X3”,在双击菜单中点“open group”,出现数据表。
点”view/graph/line/ok”,形成线性图2。
图21.2对(3.1)采用OLS估计参数在主界面命令框栏中输入ls y c x2 x3,然后回车,即可得到参数的估计结果,如图3所示。
图 3根据图3中的数据,得到模型(3.1)的估计结果为(8638.216)(0.012799)(9.776181)t=(-2.110573) (10.58454) (1.928512)错误!未找到引用源。
错误!未找到引用源。
F=522.0976从上回归结果可以看出,拟合优度很高,整体效果的F检验通过。
但当错误!未找到引用源。
=0.05时,错误!未找到引用源。
=错误!未找到引用源。
2.131.有重要变量X3的t检验不显著,可能存在严重的多重共线性。
2.多重共线性模型的识别2.1计算解释变量x2、x3的简单相关系数矩阵。
点击Eviews主画面的顶部的Quick/Group Statistics/Correlatios弹出对话框在对话框中输入解释变量x2、x3,点击OK,即可得出相关系数矩阵(同图4)。
相关系数矩阵图4由图4相关系数矩阵可以看出,各解释变量相互之间的相关系数较高,证实解释变量之间存在多重共线性。
2.2多重共线性模型的修正将各变量进行对数变换,在对以下模型进行估计。
多重共线性和自相关的检验和解决

《计量经济学》课程实训项目报告项目名称多重共线性和自相关的检验及解决方法实训日期2012.11.23 实训人53 班级统计1005 学号1004100508 指导教师张维群应用软件SPSS 实训地点实验楼314实训目的1.多重共线性和自相关的检验及解决方法的软件操作能力训练2.验证多重共线性和自相关的检验及解决方法的理论,并加深理解。
实训内容1.根据自己在网上寻找到的感兴趣的数据,用膨胀因子法和相关系数法对其进行是否存在多重共线性的检验;运用图示法和D-W法对数据是否存在自相关进行检验。
2.若检验出有多重共线性,则用逐步回归法剔除对因变量影响不大的解释变量;若检验出存在自相关,则用广义差分法建立新的模型进行解决。
实训数据资料说明1.问题:我国GDP的增长率与第一产业增长率、第二产业增长率、第三产业增长率用最小二乘法回归时的模型是否存在多重共线性和自相关。
若存在,先解决多重共线性再解决自相关并重新估计。
2.指标有哪些?自变量有x1:第一产业增长率,x2:第二产业增长率,x3:第三产业增长率。
因变量是y:GDP的增长率。
3.数据来源什么地方?数据是从网上查找的,数据包括从1981—2010年我国的GDP增长率、第一产业增长率、第二产业增长率和第三产业增长率,为时间序列数据,样本量为30。
实训结果与简要分析首先对原始数据进行用普通最小二乘法进行大致的拟合,并选择Linear Regression-Statistics-Collinearity diagnostics,即用膨胀因子法对原模型进行多重共线性检验,结果如下:Model SummaryModel R R Square Adjusted R Square Std. Error of the Estimate1 .982a.965 .961 .55883表1A N OVA bModel Sum of Squares df Mean Square F Sig.1 Regression 224.079 3 74.693 239.176 .000aResidual 8.120 26 .312T otal 232.199 29表2Coefficients aModel1(Constant) 第一产业增长率第二产业增长率第三产业增长率Unstandardized Coeff icients B .690 .187 .456 .287Std. Error .400 .047 .030 .042 Standardized Coeff icients Beta .169 .742 .344t 1.727 3.971 15.045 6.837 Sig. .096 .001 .000 .000 Collinearity Statistics T olerance .740 .553 .531VIF 1.351 1.809 1.883表3由表1可知模型的可决系数R^=0.965>0.8,可见其拟合程度较好。
计量经济学报告

计量经济学报告在当今社会,计量经济学扮演着重要的角色。
它使用数学和统计方法来研究经济现象,并对经济政策制定者提供决策支持。
通过分析数据、建立模型以及进行推断,计量经济学能够帮助我们理解经济中的因果关系和发展趋势。
在这篇文章中,我们将探讨计量经济学的应用以及它对经济学研究的意义。
计量经济学的应用广泛。
它可以用于分析个体和家庭的消费行为,企业的生产效率,以及国家之间的贸易关系。
例如,通过使用计量经济学方法,经济学家可以测量某个因素对经济增长的影响,以及确定制定货币政策的最佳方式。
此外,计量经济学还可以用于评估政府政策的效果,如减贫计划和环境保护措施。
通过分析数据和建立模型,我们可以量化政策的效果并提出改进建议。
计量经济学的研究方法至关重要。
研究者使用大量的数据来验证他们的假设,并通过计量模型来预测未知的现象。
其中最常用的方法之一是回归分析。
回归分析可以用来研究两个或多个变量之间的关系,并量化这种关系的强度。
通过建立回归模型,我们可以识别出对一个变量的影响因素,并进一步探讨这种影响的原因。
为了确保分析结果的准确性和可靠性,计量经济学研究需要遵循一定的方法和原则。
首先,数据的选择和准备非常重要。
研究者需要确保所使用的数据具有代表性,并且要对数据进行清洗和整理,以便消除不准确或不完整的信息。
其次,模型的建立需要符合经济学的理论框架。
只有在理论的基础上,计量经济学模型才能更好地解释现实世界的经济现象。
此外,计量经济学还使用了一些假设和统计工具来处理数据中的问题,如异方差性和自相关性等。
计量经济学对经济学研究的意义不言而喻。
它不仅可以提供有关经济现象的深刻见解,还可以为经济政策制定者提供决策支持。
通过分析数据和建立模型,计量经济学使我们能够预测经济发展的趋势,并制定相应的政策来应对挑战。
此外,计量经济学还有助于改善政策的效果,并评估政府的干预措施。
通过使用计量经济学的方法,我们能够更好地理解经济学中的因果关系,并为实现可持续发展和社会福利做出贡献。
eviews异方差、自相关检验与解决办法

eviews异方差、自相关检验与解决办法一、异方差检验:1.相关图检验法LS Y C X 对模型进行参数估计GENR E=RESID 求出残差序列GENR E2=E^2 求出残差的平方序列SORT X 对解释变量X排序SCAT X E2 画出残差平方与解释变量X的相关图2.戈德菲尔德——匡特检验已知样本容量n=26,去掉中间6个样本点(即约n/4),形成两个样本容量均为10的子样本。
SORT X 将样本数据关于X排序SMPL 1 10 确定子样本1LS Y C X 求出子样本1的回归平方和RSS1SMPL 17 26 确定子样本2LS Y C X 求出子样本2的回归平方和RSS2计算F统计量并做出判断。
解决办法3.加权最小二乘法LS Y C X 最小二乘法估计,得到残差序列GRNR E1=ABS(RESID) 生成残差绝对值序列LS(W=1/E1) Y C X 以E1为权数进行加权最小二成估计二、自相关1.图示法检验LS Y C X 最小二乘法估计,得到残差序列GENR E=RESID 生成残差序列SCAT E(-1) E et—et-1的散点图PLOT E 还可绘制et的趋势图2.广义差分法LS Y C X AR(1) AR(2)首先,你要对广义差分法熟悉,不是了解,如果你是外行,我奉劝你还是用eviews来做就行了,其实我想老师要你用spss无非是想看你是否掌握广义差分,好了,废话不多说了。
接着,使用spss16来解决自相关。
第一步,输入变量,做线性回归,注意在Liner Regression 中的Statistics中勾上DW,在save中勾Standardized,查看结果,显然肯定是有自相关的(看dw值)。
第二步,做滞后一期的残差,直接COPY数据(别告诉我不会啊),然后将残差和滞后一期的残差做回归,记下它们之间的B指(就是斜率)。
第三步,再做滞后一期的X1和Y1,即自变量和因变量的滞后一期的值,也是直接COPY。
异方差、自相关检验
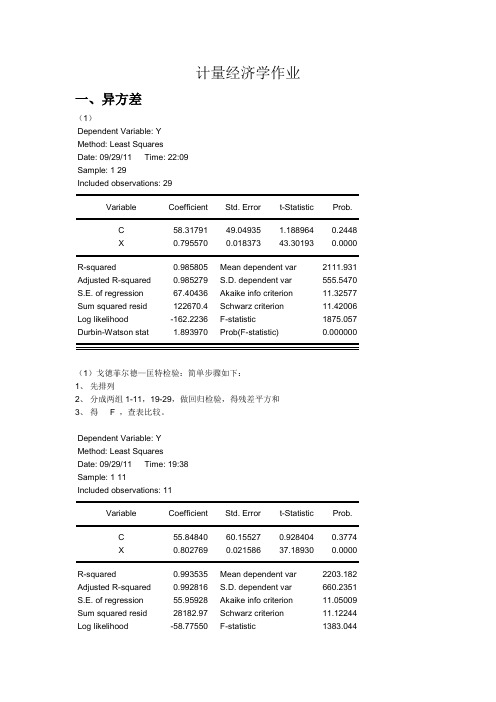
计量经济学作业一、异方差(1)Dependent Variable: YMethod: Least SquaresDate: 09/29/11 Time: 22:09Sample: 1 29Included observations: 29Variable Coefficient Std. Error t-Statistic Prob.C 58.31791 49.04935 1.188964 0.2448X 0.795570 0.018373 43.30193 0.0000R-squared 0.985805 Mean dependent var 2111.931 Adjusted R-squared 0.985279 S.D. dependent var 555.5470 S.E. of regression 67.40436 Akaike info criterion 11.32577 Sum squared resid 122670.4 Schwarz criterion 11.42006 Log likelihood -162.2236 F-statistic 1875.057 Durbin-Watson stat 1.893970 Prob(F-statistic) 0.000000(1)戈徳菲尔德—匡特检验:简单步骤如下:1、先排列2、分成两组1-11,19-29,做回归检验,得残差平方和3、得 F ,查表比较。
Dependent Variable: YMethod: Least SquaresDate: 09/29/11 Time: 19:38Sample: 1 11Included observations: 11Variable Coefficient Std. Error t-Statistic Prob.C 55.84840 60.15527 0.928404 0.3774X 0.802769 0.021586 37.18930 0.0000R-squared 0.993535 Mean dependent var 2203.182 Adjusted R-squared 0.992816 S.D. dependent var 660.2351 S.E. of regression 55.95928 Akaike info criterion 11.05009 Sum squared resid 28182.97 Schwarz criterion 11.12244 Log likelihood -58.77550 F-statistic 1383.044Durbin-Watson stat 1.657950 Prob(F-statistic) 0.000000第一组:Sum squared resid(残差平方和)=28182.97Dependent Variable: YMethod: Least SquaresDate: 09/29/11 Time: 19:39Sample: 19 29Included observations: 11Variable Coefficient Std. Error t-Statistic Prob.C 92.44615 96.01293 0.962851 0.3608X 0.782281 0.035369 22.11798 0.0000R-squared 0.981935 Mean dependent var 2141.455Adjusted R-squared 0.979928 S.D. dependent var 590.5276S.E. of regression 83.66352 Akaike info criterion 11.85445Sum squared resid 62996.26 Schwarz criterion 11.92679Log likelihood -63.19947 F-statistic 489.2051Durbin-Watson stat 1.770865 Prob(F-statistic) 0.000000第二组:Sum squared resid(残差平方和)=62996.26F=62996.26/28182.97=2.23526,给定显著性水平a=0.05查F分布临界值表可得临界值F0.05(11,11)=2.85,所以统计量F< F0.05(11,11),支出模型不存在异方差。
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
消除异方差和自相关的实验报告【实验内容】通过查询中国统计局的2012年中国统计年鉴及新浪财经数据网,获得1980年--2012年各项指标的数据,如下表所示:年份Y-出口贸易总额(亿美元)X-外商直接投资(亿美元)1980181.19 3.54 1981220.10 3.54 1982223.20 3.54 1983222.309.20 1984261.4014.20 1985273.5019.56 1986309.4022.44 1987394.4023.14 1988475.2031.94 1989525.4033.92 1990620.9134.87 1991719.1043.66 1992849.40110.08 1993917.44275.15 19941210.06337.67 19951487.80375.21 19961510.48417.26 19971827.92452.57 19981837.09454.63 19991949.31403.1920002492.03407.1520012660.98468.7820023255.96527.4320034382.28535.0520045933.26606.3020057619.53603.2520069689.36630.21200712177.76747.68200814306.93923.95200912016.12900.33201015779.301057.40201118986.001160.23201220489.301116.16【实验步骤——检验并消除异方差】一检查模型是否存在异方差性1、图形分析检验(1)散点相关图分析做出外商直接投资X与出口贸易总额Y的散点图(SCAT X Y)。
观察相关图可以看出,随着外商直接投资的增加,出口贸易总额的平均水平不断提高,但离散程度也逐步扩大。
这说明变量之间可能存在递增的异方差性。
(2)残差图分析建立一元线性回归;Y=β1+β2X +u,使resid中存放最后一次回归的残差。
Dependent Variable: YMethod: Least SquaresDate: 05/18/13 Time: 12:32Sample: 1980 2012Included observations: 33Variable CoefficientStd.Error t-Statistic Prob.C-1451.623598.2829-2.4263150.0213 X15.188931.13869713.338880.0000R-squared0.851622 Mean dependentvar4418.315Adjusted R-squared0.846835 S.D. dependentvar5949.497S.E. of Akaike inforegression2328.409criterion18.40245Sum squaredresid 1.68E+08 Schwarz criterion18.49315Log likelihood-301.6404 F-statistic177.9257Durbin-Watsonstat0.180035 Prob(F-statistic)0.000000因为残差存在负值,所以建立列函数(e=resid^2),获得e=resid^2的数列,建立e关于X的散点图,可以发现随着X增加,残差呈现明显的扩大趋势,表明存在递增的异方差。
2、White检验+β2X +u回归模型。
建立Y=β1在窗口菜单中选择Residual Tests: White Heteroskedasticity,检验结果如下:White Heteroskedasticity Test:F-statistic 3.333467 Probability0.049283Obs*R-squared6.000197 Probability0.049782取显著水平,由于Probability (Obs*R-squared)<0.05的显著水平,认为存在异方差性。
3、ARCH检验建立Y=β+β2X +u回归模型。
1在窗口菜单中选择Residual Tests: ARCH Test,阶数为2,检验结果如下:Lags to 2:ARCH Test:F-statistic19.16665 Probability0.000006Obs*R-squared17.91457 Probability0.000129取显著水平,由于Probability (Obs*R-squared)<0.05的显著水平,认为存在异方差性。
同理,分别作3阶,4阶的ARCH检验,取得同样的检验结果:Lags to 3:ARCH Test:F-statistic12.90773 Probability0.000023Obs*R-squared17.94868 Probability0.000451Lags to 4:ARCH Test:F-statistic8.862241 Probability0.000153Obs*R-squared17.29248 Probability0.0016964、Gleiser检验建立Y=β1+β2X +u回归模型。
生成新变量序列: GENR E1 = ABS(Resid)建立新残差序列E1对解释变量X的回归模型,回归结果如图所示。
Dependent Variable: E1Method: Least SquaresDate: 05/18/13 Time: 13:28Sample: 1980 2012Included observations: 33Variable CoefficientStd.Error t-Statistic Prob.C1666.263252.99656.5861090.0000 X0.9128950.4815221.8958530.0673R-squared0.103898 Mean dependentvar2019.061Adjusted R-squared0.074991 S.D. dependentvar1023.751S.E. ofregression984.6169 Akaike infocriterion16.68107Sum squaredresid30053586 Schwarzcriterion16.77177Log likelihood-273.2377 F-statistic 3.594258Durbin-Watsonstat0.724867 Prob(F-statistic)0.067335由上述回归结果可知,回归模型中解释变量的系数估计值显著不为0,通过10%显著性检验。
所以认为存在异方差性。
二克服异方差1、确定权数变量W1=1/X ,W2=1/X^2 , W3=1/SQR(X)其中RESID为最初回归模型LS Y C X的残差序列。
2、利用加权最小二乘法估计模型在Eviews命令窗口中键入命令LS= Y C X,在回归的权数变量栏里依次输入W1、W2、W3、W4,得到回归结果。
并对所估计的模型再分别进行White检验,观察异方差的调整情况。
W1:Dependent Variable: YMethod: Least SquaresDate: 05/18/13 Time: 13:52Sample: 1980 2012Included observations: 33Weighting series: W1Variable CoefficientStd.Error t-Statistic Prob.C-7316.965808.6150-9.0487620.0000 X23.181690.91253425.403650.0000Weighted StatisticsR-squared0.986405 Mean dependentvar9398.091Adjusted R-squared 0.985966 S.D. dependentvar16564.41S.E. ofregression1962.300 Akaike infocriterion18.06031Sum squaredresid 1.19E+08 Schwarz criterion18.15101 Log likelihood-295.9952 F-statistic645.3454 Durbin-Watsonstat0.949176 Prob(F-statistic)0.000000UnweightedStatisticsR-squared0.391213 Mean dependentvar4418.315Adjusted R-squared0.371575 S.D. dependentvar5949.497S.E. ofregression4716.361 Sum squaredresid 6.90E+08Durbin-Watsonstat0.062636W2:Dependent Variable: YMethod: Least Squares Date: 05/18/13 Time: 13:55 Sample: 1980 2012 Included observations: 33 Weighting series: W2Variable CoefficientStd.Error t-Statistic Prob.C187.892514.8476412.654700.0000 X 5.6939513.9978031.4242700.1644Weighted StatisticsR-squared0.990402 Meandependent var218.0007Adjusted R-squared0.990093 S.D. dependentvar598.0862S.E. ofregression59.53023 Akaike infocriterion11.06954Sum squaredresid109859.3 Schwarzcriterion11.16023Log likelihood-180.6474 F-statistic 2.028545Durbin-Watsonstat1.654586 Prob(F-statistic)0.164358UnweightedStatisticsR-squared0.398773 Meandependent var4418.315Adjusted R-squared0.379379 S.D. dependentvar5949.497S.E. ofregression4686.985 Sum squaredresid 6.81E+08Durbin-Watsonstat0.055673W3:Dependent Variable: YMethod: Least SquaresDate: 05/18/13 Time: 14:11Sample: 1980 2012Included observations: 33Weighting series: W3Variable Coefficient Std.Errort-Statistic Prob.C116.981796.512321.2120910.2346 X11.130040.98372711.314150.0000Weighted StatisticsR-squared0.595113 Meandependent var1387.549Adjusted R-squared0.582052 S.D. dependentvar1231.245S.E. ofregression795.9862 Akaike infocriterion16.25573Sum squaredresid19641413 Schwarzcriterion16.34643Log likelihood-266.2196 F-statistic128.0101 Durbin-Watsonstat0.126450 Prob(F-statistic)0.000000UnweightedStatisticsR-squared0.790807 Meandependent var4418.315Adjusted R-squared0.784059 S.D. dependentvar5949.497S.E. ofregression2764.697 Sum squaredresid 2.37E+08Durbin-Watsonstat0.128599经比较,以W1=1/W作为权数的模型消除异方差性效果最好,参数的t检验均显著,可决系数大幅提高(R2=0.986405),拟合程度较好,F检验也显著,并说明外商直接投资每增加1亿美元,平均说来将增加11.13004亿美元出口贸易总额,而不是原模型的15.18893亿美元出口贸易总额。