独立性检验分析
《列联表与独立性检验》教学分析

《列联表与独立性检验》教学分析一、本节知识结构框图二、重点、难点重点:22⨯列联表,独立性检验的思想和方法.难点:2χ统计量的导出和意义,独立性检验的思想和方法.三、教科书编写意图及教学建议统计最基本的思想是用样本推断总体,而估计和假设检验是两种基本而重要的推断方法.在前面的学习中,主要学习了统计估计的推断方法,例如,用样本数据的均值和方差分别估计总体的均值和方差;用样本相关系数估计两个数值变量的相关系数,从而推断这两个变量线性关系的密切程度;利用最小二乘思想估计一元线性回归模型中的参数等,本节结合具体实例,01,的分类变量的独立性,了解根据频率稳定到概率的原理及小概率原理,检验两个取值于{}独立性检验的思想方法,进一步提升学生的数据分析素养.本节内容对学生来说难度较大,涉及的基础知识有古典概型、条件概率、频率稳定到概率的原理及分类变量独立性的概念,涉及的统计思想方法主要是假设检验的思想方法.教科书结合丰富的实例,通过问题引导,采取了由易到难、逐步深入的处理方式,使学生了解独立性检验的基本思想.在本节教学中,应通过具体案例渗透独立性检验的基本思想和方法,使学生了解统计推断可能犯错误的特点,避免单纯地记忆独立性检验的基本步骤和机械地套用公式解决问题.应注重培养学生联系实际的意识,提高学生解决实际问题的能力.教科书注重信息技术与相关内容的有机融合,强调使用计算器、计算机等工具探索和解决问题.例如,在画等高堆积条形图时,借助信息技术作图,不但作出的图形准确美观,而且省时省力.面对复杂的计算,教学中应使用统计软件,解决计算量大的问题,使学生从烦琐的计算中解脱出来,把更多的精力放在对于独立性检验的基本思想的理解上.8.3.1分类变量与列联表教科书首先设置问题情境,对某中学全体学生分性别就体育锻炼的经常性进行普查,全校523名女生中有331人经常锻炼,601名男生中有473人经常锻炼,据此判断该中学学生不同性别在体育锻炼的经常性方面是否有差异.由于是普查数据,而且仅对这所学校进行判断,因此只需分别计算出女生经常参加体的比率和男生经常参加体育锻炼的比率,并比较这两个值是否相等.如果不相等,就认为不同性别在体育锻炼的经常性方面有差异,否则就认为没有差异.实际计算的结果显示经常参加体育锻炼的比率男生比女生高15.4个百分点.因此可判断该校的女生和男生在体育锻炼的经常性方面有差异,而且男生更经常锻炼.这个问题还可以从概率的角度进行解答.从女生和男生中各随机选取一名学生,分别计算两个群体中抽到经常参加体育锻炼学生的概率,并比较两个概率是否相等.如果不相等,就认为不同性别在体育锻炼的经常性方面有差异,否则就认为没有差异.若令0,1,X ⎧⎨⎩该生为女生,该生为男生,0,1,Y ⎧⎨⎩该生不经常锻炼,该生经常锻炼,则问题可以转化为比较条件概率|(10)P Y X ==和|(11)P Y X ==是否相等.如果数据是采用抽样调查得到的,怎样判断两个条件概率是否相等,从而推断两个分类变量是否存在关联性呢?接着教科书设置了例1,根据随机样本数据,推断两所学校学生数学成绩的优秀率是否有差异.根据频率稳定于概率的原理,直观上看,如果两校学生数学成绩优秀的频率差异较大,则可推断对应的两个条件概率不等,从而认为两校学生的数学成绩优秀率存在差异.基于所给的数据,计算得到甲校学生数学成绩优秀的频率为0.2326;乙校学生数学成绩优秀的频率为0.1556.因为两个频率存在明显差异,所以可以认为两校学生的数学成绩优秀率存在差异,并且甲校学生的数学成绩优秀率高于乙校.但是频率具有随机性,频率与概率之间存在误差,因此根据频率进行推断有可能犯错误.对此教科书设置了一个思考栏目,让学生思考上面推断的结论是否可能犯错误,进而深刻理解抽样数据的随机性特点,实际上也指出,例1给出的解答方法也是有缺陷的,为后面引出独立性检验方法作了铺垫.1.数值变量与分类变量数值变量的取值为实数,其大小和运算都具有实际含义.例如年龄、身高、体重、学习成绩等都是数值变量,张明的身高是180cm,李立的身高是175cm,说明张明比李立高5cm.常见数值变量的数字特征(如均值、方差、百分位数等)均有明确的含义.分类变量的取值表示个体所属类别,例如性别变量是分类变量,取男、女两个值;同样,数学考试等级是分类变量,取优、良、中等、及格、不及格五个值;等等.有时也可以把分类变量的不同取值用实数表示,但这些数值仅作为编号使用,通常没有大小关系和运算意义,例如,用0表示“男”,1表示“女”,性别变量这个分类变量的取值就变成0和1,但这里的0和1仅作为分类用,没有其他含义,比较0和1的大小没有意义,通常计算其均值和方差也没有意义.2.列联表列联表是由两个及两个以上分类变量进行交叉分类的频数分布表,教科书中仅涉及两个分类变量的列联表,并且每个变量只取两个值,这样的列联表称为2×2列联表.一般的独立性检验并不要求每个分类变量只取两个值.在教学中,不要求给出这些概念的严格定义,只需给出描述性的说明即可.3.例题及其教学例1给出了借助概率的观点研究“两校学生的数学成绩优秀率之间是否存在差异”的过程:(1)根据实际问题,引入样本空间,建立古典概型,并定义分类变量X和Y.(2)将样本数据整理成2×2列联表的形式.(3)计算并比较分类变量X和Y相应的频率.(4)用等高堆积条形图直观展示上述频率.(5)根据频率稳定于概率的原理,估计分类变量X和Y相应的条件概率,进而作出推断.在例1的教学中,要注意渗透用频率估计概率的思想.既要理解这种推断方法的合理性,又要认识到这种推断方法的缺陷.对于等高堆积条形图,可以借助统计软件绘制.对于例1,教科书中比较的是甲校学生中数学成绩不优秀和优秀的频率与乙校学生中数学成绩不优秀和优秀的频率,是从行的角度进行比较.同样地,也可以从列的角度进行比较:数学成绩不优秀的学生中甲校和乙校的频率分别为330.464871≈和380.53571≈2,数学成绩优秀的学生中甲校和乙校的频率分别为100.588217≈和70.411817≈,比较相应的频率,也能得出两校学生中数学成绩优秀率之间存在差异.4.例1后的“思考”例1事实上是根据两个频率的差异进行推断的,没有考虑随机性的影响.但事实上,即便两个样本来自同一个总体,也会因为随机性使得频率产生差异,因此需要用概率的方法进行推断.例1后安排的思考栏目,目的是让学生体会在样本推断总体的过程中,由于样本具有随机性,依据频率所作的推断可能会犯错误.8.3.2独立性检验假设检验是统计推断的一种基本形式,其基本思想是根据观察或试验的结果去检验一个假设(零假设)是否成立,即通过样本的某个指标对总体的某种属性进行推断,推断的结果是拒绝或接受零假设.独立性检验是假设检验的一个特例.独立性检验的基本原理是根据观测值与期望值的差异的大小作出推断,这种差异由2χ统计量进行刻画,其大小的标准根据推理有关联时犯错误的概率确定.独立性检验的依据是小概率原理,即小概率事件在一次试验中几乎不可能发生.在零假设成立的条件下,若一个不利于零假设的小概率事件在一次试验中发生了,则有理由拒绝零假设;若在一次试验中,此小概率事件没有发生,则没有充足的理由拒绝零假设,通常会接受零假设.教科书首先借助古典概型的观点对独立性检验问题进行分析,给出基于分类变量X 和Y 的零假设o H 的两种严格的数学表述.然后结合22⨯列联表,给出了在零假设o H 成立的前提下, 构造2χ统计量的全过程,通过推导过程让学生感悟其合理性.最后教科书总结了独立性检验的基本步骤,并与反证法进行了比较.1.独立性检验的基本步骤(1)提出零假设0:H X 和Y 相互独立对不同背景的实际问题,判断两种现象之间是否有关联或是否相互影响,需要给出严格的数学描述.当定义了两个只取两个值的分类变量X 和Y 后,由前面的分析可知,判断X 和Y 是否有关联只需判断(1|0)P Y X ==和(1|1)P Y X ==是否相等.根据条件概率的定义,可推出(1|0)(1|1)P Y X P Y X =====等价于事件{1}X =与{1}Y =相互独立,由后者又可推出{0}X =与{1},{1}Y X ==与{0},{0}Y X ==与{0}Y =都相互独立.如果这4组事件独立.则称分类变量X和Y 独立.因此,零假设可改述为0:H X 和Y 相互独立.(2)构造检验的统计量将样本数据整理成22⨯列联表的形式,4个积事件的观测频数分别为,,,a b c d .在X 和Y 独立的假设下,分别估计这4个积事件的期望频数,根据频率稳定到概率的原理,考虑所有对应频数的总的偏差并加以调整,构造2χ统计量.这种构造方法非常容易推广到取值超过两个的分类变量的独立性检验.根据2χ统计量的构造过程可知,2χ的值越小,零假设0H 成立的可能性越大;2χ的值越大,零假设0H 成立的可能性越小.为了方便查阅,这里给出2χ统计量的简化形式的推导过程.教科书中给出的该统计量最初的形式为22222()()()()()()()()()()()()()()()()a b a c a b b d c d a c c d b d a b c d n n n n a b a c a b b d c d a c c d b d n n n n χ++++++++⎡⎤⎡⎤⎡⎤⎡⎤----⎢⎥⎢⎥⎢⎥⎢⎥⎣⎦⎣⎦⎣⎦⎣⎦=+++++++++++. 由上式得22222[()()][()()][()()][()()]()()()()()()()()na a b a c nb a b b d nc c d a c nd c d b d n a b a c n a b b d n c d a c n c d b d χ-++-++-++-++=+++++++++++, 把n a b c d =+++代入上式各项分子,得22222()()()()()()()()()()()()ad bc bc ad bc ad ad bc n a b a c n a b b d n c d a c n c d b d χ----=+++++++++++, 对上式右边的分式进行通分,得22()[()()()()()()()()]()()()()ad bc c d b d c d a c a b b d a b a c n a b c d a c b d χ-+++++++++++=++++. 进一步化简得2222()()()()()()()()()()()ad bc a b c d n ad bc n a b c d a c b d a b c d a c b d χ-+++-==++++++++. 上式等号右边即为教科书中给出的2χ统计量的简化形式.(3)确定检验规则,得出推断结论由2χ统计量的构造过程可以看出,2χ统计量的分布与n 有关.在零假设0H 成立的条件下, 统计学家证明,当n →∞时,2χ的分布收敛到随机变量2(1)χ的分布,后者就是自由度为1的卡方分布.也就是说,当n →∞时,对任意的0x ,都有()()22(1)P x P x χχ→,根据卡方分布的性质,对于事先给定的小概率值α,都可以找到相应的正实数a x ,使得()2(1)a P x χα=.在n 充分大时,可以忽略2χ和2(1)χ分布之间的误差,因此认为()2a P x χα=成立.这里的值a x 即可作为与小概率值α对应的判断2χ大小标准的临界值.根据列联表计算2χ的值,当2a x χ时,拒绝零假设,由()2P x αχα=知,犯错误的概率不超过α.当2x αχ<时,不能拒绝零假设,意味着在小概率值α的检验规则下,根据样本数据,没有足够理由认为零假设不成立.我们在作统计推断时,如果不能拒绝零假设,不妨暂且接受它.但这并不代表零假设就是成立的,只是表明若要拒绝零假设,则需要积累更多的证据,作进一步验证.当小概率值0.01α=时,临界值 6.635x α=,当2 6.635χ时,我们推断0H 不成立,即认为X 和Y 不独立,该推断犯错误的概率不超过0.01;当2 6.635χ<时,我们没有充分证据推断0H 不成立,可以暂且认为X 和Y 独立,待有新的证据时再作进一步检验.下面我们提供一个应用独立性检验解决问题的案例,并给出完整的过程,供大家参考. 案例 为了研究一种新药对治疗某疾病是否有效,进行了临床试验.采用放回简单随机抽样的方法得到了如下数据:抽到服用新药的患者44名,其中34名痊愈,10名未痊愈;抽到服用没有任何疗效安慰剂的患者56名,其中32名痊愈,24名未痊愈.依据小概率值0.01α=的独立性检验,能否认为新药治疗该疾病有明显的效果?解:零假设为o H 新药治疗该疾病没有明显的效果.由样本数据可得列联表(表8-1).表8-1根据列联表中的数据, 经计算得到220.01100(34241032) 4.449 6.63544566634x χ⨯-⨯=≈<=⨯⨯⨯. 根据小概率值0.01α=的独立性检验,没有充分证据推断0H 不成立,因此可以认为0H 成立,即认为新药治疗该疾病没有明显的效果.药品对人类的健康至关重要,在没有充分证据表明新药对治疗疾病有效的情况下,必须慎重处理,可以等待时机成熟后,再作进一步试验.各类药品的使用在疾病治疗中具有十分重要的作用,一种新药在投放市场前需要检验其对疾病是否具有疗效.新药的推广使用涉及多方面的因素,成本往往很高,也伴随一定风险.因此,在对药品治疗疾病是否有效进行独立性检验时,一般会选取较小的小概率值α,以不轻易作出药品有效的结论.针对某些疾病,民间有些“食疗方法,这些方法往往简单易行、成本低廉,而且已流传多年,没有什么风险.在对这些“食疗”方法是否有疗效进行独立性检验时,通常不必像对药品的检验那样严苛,可以把小概率值α取得稍大一些.为了减少复杂的计算所花费的时间,同时对2χ分布有一个直观认识,建议使用GeoGebra 软件进行本案例的教学.利用该软件可以计算2χ的值.如图8-18,在“概率统计”视图下,在“统计”标签中选择卡方检验,只要输入观测频数,同时勾选预期次数,即可得到2χ的值为4.4494,即22222(3429.04)(1014.96)(3236.96)(2419.04) 4.449429.0414.9636.9619.04χ----=+++≈. 其中的p 值为0.0349,其含义是()2 4.44940.034P χ≈9.因为()2 6.6350.01P χ≈,所以0.01p >等价于2 6.635χ<.利用该软件还可以根据小概率值α求对应的临界值.如图8-19,在“分布”标签中选择卡方检验,输入自由度为1,概率值为0.1,即得到对应的临界值为2.7055.(4)分析X 和Y 之间的影响规律拒绝零假设,简单地认为X 和Y 有关联或相互影响,不一定是最终想要的结果.在很多时候还需要明确X 和Y 之间是什么样的关联或在多大程度上相互影响,这可以通过样本数据计算相应的频率,推断X 和Y 之间的影响规律.2.应用独立性检验解决实际问题时的注意事项(1)一般来说,样本量n a b c d =+++越大,2χ统计量的分布与2χ(1)分布的近似程度越高.因此,为了保证一定的精度,在实际应用中通常要求列联表中的四个数,,a b c 和d 都不小于5.(2)当零假设被接受时,也可能犯错误,至于犯这种错误的概率(不妨记为p )是多少,我们并不清楚.但是我们知道,当α增大时,p 会减小;反之,当α减小时,p 会增大.因此,在具体操作中,要根据实际问题,选择恰当的小概率值,不能一味地降低或提高α的取值.3.对犯错误概率的解释在零假设0H 成立的前提下,随着小概率值α的逐渐减小,2χ统计量对应的临界值0x 逐当增大,则事件2{}x αχ越来越不容易发生,零假设越来越不容易被拒绝;随着小概率值α的逐当增大,2χ统计量对应的临界值x α逐渐减小,则事件2{}x αχ越来越容易发生,零假设越来越容易被拒绝.例如,对于例3中的数据,经计算得2 4.881χ≈.(1)当小概率值α取0.005时,0.0057.879x =,此时20,0054.8817.879x χ≈<=,则没有充分理由拒绝零假设,因此可以接受0H ,即认为两种疗法的效果没有差异.(2)当小概率值α取0.05时,0.05 3.841χ=,此时20.054.881 3.841x χ≈>=,则拒绝零假设,即认为两种疗法的效果有差异,该推断犯错误的概率不超过0.05.(3)当小概率值α取0.1时,0.1 2.706χ=,此时20.14.881 2.706x χ≈>=,则拒绝零假设,即认为两种疗法的效果有差异,该推断犯错误的概率不超过0.1.对于(2)和(3),用的是与(1)同一组数据,但都得到了与(1)相反的结论,可见推断的结论与检验规则有关.另外,由于依据不同的检验规则,(2)和(3)两个推断犯错误的概率上界是不同的,而这种犯错误的概率只能通过多次试验才能表现出来.因此在具体的问题中,所使用的小概率值往往是由有经验的专家事先确定的.4.样本量对于2χ独立性检验结果的影响对于例1列联表8.3-2中的数据,依据0.1α=的独立性检验,得出的结论是两校学生数学成绩的优秀率没有明显差异.假设对于例1中的问题我们得到如表82-的数据.表8-2显然,基于这些数据计算出的频率与例1中的相同.然而在相同的检验标准下作2χ独立性检验,可以推出两校学生数学成绩的优秀率有明显差异,结论却发生了变化.通常情况下,样本量越大,提供的信息越充分,观测的结果通常会更准确.与例1中的数据相比,这里的每个数据都变为原来的10倍,即样本量变为原来的10倍,这种差异无法通过频率的计算表现出来,而2χ独立性检验可能会得出不同的结论,可见2χ统计量能够有效地提取样本所包含的有用信息.5.例题及其教学关于两校学生数学成绩的优秀率是否有差异,例2利用独立性检验的方法得到的结论与例1用频率估计概率的方法得到的结论截然相反,应注意结合例2后的“思考”,使学生体会独立性检验的必要性.例3是检验甲、乙两种疗法的疗效哪个更好.在例3的教学中,应通过复习列联表的制作,引导学生运用学过的知识解决问题,熟悉运用独立性检验的方法解决具体问题的步骤,教学的重点应该放在解释独立性检验的基本思想上,避免学生单纯地记忆处理问题的步骤和机械套用公式进行计算.需要注意的是,利用独立性检验得出的结论是有条件的,不能在使用时随意扩大范围.例如,例3中的样本数据来自于某儿童医院,根据样本数据得出的结论能很好地适用于该儿童医院.若将这个结论推广到其他群体,则可能会犯错误.例4主要研究吸烟与患肺癌的关系,属于直接运用独立性检验的方法解决实际问题的经典范例.在例4的教学中,应让学生亲自处理数据、解决问题,从中体会统计思维和确定性思维之间的差异,在理解独立性检验思想的过程中,培养学生数据处理的能力,提升学生的数学运算、数据分析等核心素养.6.对132页观察栏目的说明在教科书表8.3-5中,对调两种疗法或两种疗效的位置,不会影响2χ值的计算结果.事实上,对调两种疗法的位置,相当于对调a与,c b与d的位置,由2χ的表达式知,并不影响2χ值的计算结果.同样地,对调两种疗效的位置,相当于对调a与,b c与d的位置,也不影响2χ值的计算结果.7.对本节最后思考栏目的说明可以在与反证法思想的比较中帮助学生了解独立性检验的思想.表8-3给出了反证法与独立性检验两种方法的比较.表8-3从表8-3的对比中,可以看出独立性检验的思想和反证法类似,但需要注意的是:在全部逻辑推理正确的情况下,反证法不会犯错误,而独立性检验可能会犯错误,对于这种错误概率的估计是2 独立性检验的重要组成部分.11/ 11。
人教版高数选修2-3第7讲:独立性检验与回归分析(学生版)

独立性检验与回归分析__________________________________________________________________________________ __________________________________________________________________________________1.了解变量间的相关关系,能根据给出的线性回归方程系数建立线性回归方程.2.了解独立性检验(只要求2×2列联表)的基本思想、方法及其简单应用.3.了解回归分析的基本思想、方法及其简单应用.1.独立性检验(1)概念:用2χ统计量研究独立性问题的检验的方法称为独立性检验.(2)m×n列联表指有m行n列的列联表(3)必备公式2χ=2()()()()()n ad bca cb d a bc d-++++2.2χ统计量中的四个临界值经过对2χ统计量分布的研究,已经得到了四个经常用到的临界值:2.706、3.841、6.635、10.828.由2×2列联表计算出2χ,然后与相应的临界值进行比较,当2χ>2.706时,有______的把握说事件A与B有关.当2χ>3.841时,有______的把握说事件A与B有关.当2χ>6.635时,有______的把握说事件A与B有关.当2χ>10.828时,有______的把握说事件A与B有关.当2χ≤2.706时,认为事件A与B是无关的.3.回归分析(1)线性回归模型是指方程y a bxε=++,其中________称为确定性函数,____称为随机误差.(2)线性回归方程是指直线方程ˆˆˆya bx =+,其中回归截距ˆa 、回归系数ˆb 公式如下: ˆb=_______________________ˆa =_____________. (3)参数r 检验线性相关的程度,计算公式为r()()niix x yy --∑即ni ix ynx y-∑化简后r =x yxy x yS S -,其中y S 表示数据i y (i =1,2,…,n )的标准差,这个r 称为y 与x 的样本相关系数,简称相关系数,其中-1≤r ≤1.若r >0,则x 与y 是正相关,若r <0,则x 与y 是负相关,若r =0,则x 与y 不相关,r =1或r =-1时,x 与y 为完全线性相关.类型一.独立性检验例1:为考察高中生的性别与是否喜欢数学课程之间的关系,在某城市的某校高中生中随机抽取300名学生,得到如下列联表:判断性别与是否喜欢数学课程有关吗?用独立性检验方法判断父母吸烟对子女是否吸烟有影响.类型二.变量间的相关关系及线性回归方程例2:下列关系中,是带有随机性相关关系的是______. ①正方形的边长与面积之间的关系; ②水稻产量与施肥量之间的关系;③人的身高与年龄之间的关系;④降雪量与交通事故的发生率之间的关系.例3:某工业部门进行一项研究,分析该部门的产量与生产费用的关系,从这个工业部门内随机抽选了10个企业作样本,资料如下表:练习1:下列两个变量之间的关系哪个不是函数关系( ) (A)角度和它的余弦值 (B)正方形边长和面积(C)正n 边形的边数和顶点角度之和 (D)人的年龄和身高 类型三.相关检验与回归分析例3:某工业部门进行一项研究,分析该部门的产量与生产费用之间的关系.从这个工业部门内完成下列问题:(1)计算x 与y 的相关系数;(2)对这两个变量之间是否线性相关进行相关性检验;(3)设线性回归方程为ˆˆˆ,ybx a =+求系数ˆˆ,.a b试预测该运动员训练47次以及55次的成绩.1.在调查中学生近视情况中,某校男生150名中有80名近视,女生140名中有70名近视,在检验这些中学生眼睛近视是否与性别有关时用什么方法最有说服力( )A.期望与方差B.排列与组合C.独立性检验D.概率2.通过对2χ统计量的研究,得到了若干临界值,当2χ≤2.706时,我们认为事件A 与B ( ) A.有90%的把握认为A 与B 有关系 B.有95%的把握认为A 与B 有关系C.没有充分理由说明事件A 与B 有关系D.不能确定3.下列关于2χ的说法中正确的是( )A.2χ在任何相互独立问题中都可以用来检验有关还是无关 B.2χ的值越大,两个事件的相关性就越大C.2χ是用来判断两个分类变量是否有关系的随机变量,只对于两个分类变量适合D.2χ的观测值2χ的计算公式为2()()()()()n ad bc a b c d a c b d χ-=++++4.下列两个变量之间的关系是相关关系的是( ) A.角度和它的余弦值 B.正方形边长和面积 C.正n 边形的边数和顶点数 D.人的年龄和身高5.由一组样本数据1122(,),(,),,(,n x y x y x )n y 得到的回归方程为ˆˆˆ,ybx a =+下面说法不正确的是( )A.直线ˆˆˆybx a =+必经过点(,)x y B.直线ˆˆˆybx a =+至少经过点1122(,),(,),,(,)n n x y x y x y 中的一个点C.直线ˆˆˆybx a =+的斜率为1221()ni ii nii x y nxyxn x ==--∑∑D.直线ˆˆˆybx a =+和各点1122(,),(,),,(,)n n x y x y x y 的偏差平方和21ˆˆ[()]ni ii y bx a =-+∑是该坐标平面上所有直线与这些点的偏差平方和中最小的直线6.有甲、乙两个班级进行数学考试,按照大于等于85分为优秀,85分以下非优秀统计成绩,得到如下所示的列联表:已知在全部105人中随机抽取1人,成绩优秀的概率为27,则下列说法正确的是( )A .列联表中c 的值为30,b 的值为35B .列联表中c 的值为15,b 的值为50C .根据列联表中的数据,若按97.5%的可靠性要求,能认为“成绩与班级有关系”D .根据列联表中的数据,若按97.5%的可靠性要求,不能认为“成绩与班级有关系”7.为了判断高中三年级学生是否选修文科与性别的关系,现随机抽取50名学生,得到如下2×2列联表:已知P (K 2≥3.841)≈0.05根据表中数据,得到K 2=50×(13×20-10×7)223×27×20×30≈4.844.则认为选修文科与性别有关系出错的可能性为________.8.某数学老师身高176cm ,他爷爷、父亲和儿子的身高分别是173cm 、170cm 和182cm.因儿子的身高与父亲的身高有关,该老师用线性回归分析的方法预测他孙子的身高为________cm._________________________________________________________________________________ _________________________________________________________________________________基础巩固1.(2014重庆卷)已知变量x与y正相关,且由观测数据算得样本平均数x=3,y=3.5,则由该观测数据算得的线性回归方程可能是()A.y^=0.4x+2.3 B.y^=2x-2.4C.y^=-2x+9.5 D.y^=-0.3x+4.42.(2014湖北卷)根据如下样本数据:得到的回归方程为y=bx+a,则()A.a>0,b>0B.a>0,b<0C.a<0,b>0D.a<0,b<03.(2014江西卷)某人研究中学生的性别与成绩、视力、智商、阅读量这4个变量的关系,随机抽查52名中学生,得到统计数据如表1至表4,则与性别有关联的可能性最大的变量是()及格2032A.成绩B.视力C.智商D.阅读量4.下列两个变量之间的关系是相关关系的是()A.正方体的棱长和体积B.角的弧度数和它的正弦值C.单产为常数时,土地面积和总产量D.日照时间与水稻的亩产量5.(2015福建)为了解某社区居民的家庭年收入所年支出的关系,随机调查了该社区5户家庭,得到如下统计数据表:根据上表可得回归直线方程ˆˆˆybx a =+,其中ˆˆˆ0.76,b a y bx ==-,据此估计,该社区一户收入为15万元家庭年支出为( )A.11.4万元B.11.8万元C.12.0万元D.12.2万元6.“回归”一词是在研究子女的身高与父母的身高之间的遗传关系时,由高尔顿提出的.他的研究结果是子代的平均身高向中心回归.根据他的结论,在儿子的身高y 与父亲的身高x 的回归方程ˆˆˆya bx =+中,ˆb ( ) A.在(-1,0)内B.等于0C.在(0,1)内D.在[1,+∞)7.线性回归方程ˆˆˆya bx =+中,回归系数ˆb 的含义是________________. 8.在一项打鼾与患心脏病是否有关的调查中,共调查了1978人,经过计算2χ=28.63,根据这一数据分析,我们有理由认为打鼾与患心脏病是________的.(填“有关”、“无关”)能力提升1.下列说法:①将一组数据中的每一个数据都加上或减去同一个常数后,方差不变;②设有一个线性回归方程y ^=3-5x ,变量x 增加1个单位时,y 平均增加5个单位;③设具有相关关系的两个变量x ,y 的相关系数为r ,则|r |越接近于0,x 和y 之间的线性相关程度越强;④在一个2×2列联表中,由计算得K 2的值,则K 2的值越大,判断两个变量间有关联的把握就越大.其中错误的个数是( ) A.0B.1C.2D.32.已知x 与y 之间的几组数据如下表:假设根据上表数据所得线性回归直线方程y =b x +a ,若某同学根据上表中的前两组数据(1,0)和(2,2)求得的直线方程为y =b ′x +a ′,则以下结论正确的是( )A.b ^>b ′,a ^>a ′B.b ^>b ′,a ^<a ′ C.b ^<b ′,a ^>a ′D.b ^<b ′,a ^<a ′3.对相关系数r ,下列说法正确的是( ) A.||r 越大,相关程度越小B.||r 越小,相关程度越大C.||r 越大,相关程度越小,||r 越小,相关程度越大D.||r≤1且||r越接近1,相关程度越大,||r越接近0,相关程度越小4.若由资料知,y对x呈线性相关关系,试求:(1)线性回归方程;(2)估计设备的使用年限为10年时,维修费用约是多少?5.若由资料可知y对x呈线性相关关系,试求:(1)线性回归直线方程;(2)根据回归直线方程,估计使用年限为12年时,维修费用是多少?6.在某医院,因为患心脏病而住院的665名男性病人中,有214人秃顶;而另外772名不是因为思心脏病而住院的男性病人中有175人秃顶,利用独立性检验方法判断秃顶与患心脏病是否有关系?课程顾问签字: 教学主管签字:。
统计学中的独立性检验

统计学中的独立性检验统计学中的独立性检验(Test of Independence)是一种常用的统计方法,用于研究两个或多个分类变量之间是否存在相互独立的关系。
通过对随机抽样数据进行分析,可以判断不同变量之间是否有关联,并衡量关联的强度。
本文将介绍独立性检验的基本原理、常用的检验方法以及实际应用。
一、独立性检验的基本原理独立性检验的基本原理是基于统计学中的卡方检验(Chi-Square Test)。
卡方检验是一种非参数检验方法,用于比较观察值频数与期望频数之间的差异。
在独立性检验中,我们首先建立一个原假设,即所研究的两个或多个变量之间不存在关联,然后通过计算卡方统计量来判断观察值与期望值之间的差异是否显著。
二、常用的独立性检验方法1. 皮尔逊卡方检验(Pearson's Chi-Square Test):这是最常见的独立性检验方法,适用于有两个以上分类变量的情况。
它基于观察频数和期望频数之间的差异,计算出一个卡方统计量,并根据卡方分布表给出显著性水平。
2. Fisher精确检验(Fisher's Exact Test):当样本量较小或者某些期望频数很小的情况下,皮尔逊卡方检验可能存在一定的偏差。
在这种情况下,可以使用Fisher精确检验来代替皮尔逊卡方检验,得到更准确的结果。
3. McNemar检验:适用于配对数据比较的独立性检验,例如一个样本在两个时间点上的观察结果。
三、独立性检验的实际应用独立性检验在各个领域都有广泛的应用,以下是几个常见的实际应用场景:1. 医学研究:独立性检验可以用于研究某种药物治疗方法是否具有显著的疗效,或者判断不同年龄组和性别之间是否存在患病率的差异。
2. 教育领域:独立性检验可用于研究学生成绩与家庭背景、教育水平之间是否存在关联。
3. 市场调研:在市场调研中,可以通过独立性检验来分析不同年龄、性别、收入水平等因素对消费者购买习惯的影响。
4. 社会科学研究:独立性检验可以帮助社会科学研究人员探索个体特征与社会行为之间的关系,例如政治倾向与不同年龄群体之间的关联性等。
配合度检验独立性检验与同质性检验

配合度检验、独立性检验与同质性检验1. 引言在统计学中,配合度检验、独立性检验和同质性检验是常用的方法之一,用于检验随机变量之间的关系。
它们在不同的场景中用来评估数据之间的相关性、独立性以及异质性。
本文将分别介绍这三种检验方法的定义、假设前提和具体应用。
2. 配合度检验2.1 定义配合度检验 (Goodness-of-Fit Test) 是一种用于确定观测数据是否与理论分布相符的统计检验方法。
它通过比较观测数据与给定理论分布的离差来评估两者之间的差异。
2.2 假设前提配合度检验的假设前提包括以下两点: 1. 观测数据来自于特定的总体或总体分布; 2. 预期的理论分布已知。
2.3 应用场景配合度检验在许多实际应用中被广泛采用,例如: - 检验观测数据是否符合正态分布、泊松分布等特定的理论分布; - 检验样本数据是否符合某一理论模型,如线性回归模型、逻辑回归模型等。
2.4 示例以下是一个应用配合度检验的简单示例:假设我们有一组观测数据,表示了一批产品的重量。
根据厂家提供的数据,产品的重量应该符合正态分布。
我们可以使用配合度检验来评估观测数据是否与正态分布相符。
首先,我们计算观测数据的均值和标准差,作为理论分布的参数。
然后,我们根据观测数据的样本量和理论分布的参数,计算出在理论分布下每个重量区间的期望频数。
最后,我们使用配合度检验统计量(如卡方检验)来比较观测频数与理论分布的期望频数之间的差异。
如果差异较小,则我们可以得出结论:观测数据符合正态分布。
3. 独立性检验3.1 定义独立性检验 (Test of Independence) 用于检验两个随机变量之间是否存在相互独立的关系。
它可以帮助我们确定两个变量是否在某种程度上相互影响。
3.2 假设前提独立性检验的假设前提包括以下两点: 1. 观测数据来自于一个大的总体或总体分布; 2. 两个变量之间不存在相互依赖的关系。
3.3 应用场景独立性检验在数据分析中具有广泛的应用场景,例如: - 检验两个变量之间是否存在相关性,如商品价格与销量之间的关系; - 检验两个分类变量之间是否相互独立,如男性与女性对某一产品的偏好。
正态分布回归分析独立性检验

正态分布回归分析独立性检验
在进行回归分析时,通常会假设误差项服从正态分布,是一个独立同分布的随机变量。
这个假设在很多情况下是合理的,特别是当样本容量较大时,中心极限定理保证了误差项的正态分布。
为了验证误差项是否满足正态分布的假设,我们可以利用正态分布的统计方法进行检验。
下面介绍两种常用的检验方法:基于直方图和基于正态概率图。
1.基于直方图的检验方法
基于直方图的检验方法通过绘制误差项的直方图,观察其分布形态是否接近正态分布。
具体步骤如下:
1)将残差(误差项)按照大小排序。
2)将排序后的残差分为k个区间,计算每个区间中的残差频数。
3)绘制直方图,观察残差分布是否近似于正态分布。
若直方图呈现钟型曲线,说明残差近似满足正态分布假设,否则不能满足正态分布假设。
2.基于正态概率图的检验方法
基于正态概率图的检验方法通过绘制误差项的正态概率图,观察其是否呈现近似直线的趋势。
1)将残差按照大小排序。
2)计算每个残差在正态分布下对应的累积概率。
3)绘制散点图,横坐标为残差的标准正态分位数,纵坐标为残差对应的累积概率。
4)观察散点图是否近似于一条直线。
若散点图近似直线,则说明残差近似满足正态分布假设,否则不能满足正态分布假设。
正态分布回归分析独立性检验的目的是验证回归模型中误差项是否满足正态分布的假设,如果不满足,则可能需要对模型进行修正,或者使用非参数回归模型等更适合的方法。
因此,对于从事回归分析的教师来说,熟练掌握正态分布回归分析独立性检验方法是非常重要的。
解读“独立性检验问题”

解读“独立性检验问题”独立性检验研究的问题是两个分类变量之间是否有关系。
为此,需要先根据采集样本的数据画出两个分类变量的列联表(通常表中数据a ,b ,c ,d 都不小于5),利用列联表可以进行粗略估计,直观地得到结论。
与表格相比,三维柱形图和二维条形图更能直观地反映相关数据的总体状况,不过不仅作图麻烦,而且三维柱形图和二维条形图所表示的关系也只是一种粗略的估计,不能精确地给出所得结论的可靠程度,因而不常用;一般用公式求得2K 的值,与临界值的大小作比较来判断分类变量X 与Y 是否有关。
具体步骤:1.采集样本数据.2.假设两个分类变量X 和Y 没有关系;给定一个显著水平,查表给出临界值;3.计算()()()()()22n ad bc K a b c d a c b d -=++++;4.若2K 大于临界值,则认为X 与Y 有关系,否则没有充分理由说明这个结论不成立。
如:当2K >3.841时,有95%的把握说事件A 与B 有关;当2K >6.635时,有99%的把握说事件A 与B 有关;当2K ≤3.841时,认为事件A 与B 是无关的.下面我们通过几个典型例题对独立性检验问题进行剖析,使同学们进一步掌握这类问题的研究方法.例1 为了研究色盲与性别的关系,调查了1000个人,调查结果如下表所示:分析:该例可归结为二元总体的独立性检验问题。
解析:由已知条件可得下表:根据公式得()22100044263851427.13995644480520K ⨯⨯-⨯=≈⨯⨯⨯。
因为27.13910.828>,所以有99.9%的把握认为色盲与性别是有关的。
评注:根据假设检验的思想,比较计算出2K 与临界值的大小,判断两个分类变量是否有关。
例2 为考察性别与是否喜欢饮酒之间的关系,在某地区随机抽取290人,得到如下列联表:分析:本题是独立性检验的题目。
解析:由列联表数据得:()222901012012445 5.30 5.024122178225228K ⨯-⨯=≈>⨯⨯⨯,故我们有97.5%的把握认为“性别与喜欢饮酒有关。
【高考数学总复习】:回归性分析与独立性检验(知识点讲解+真题演练+详细解答)
量,例如某同学的数学成绩与化学成绩。
2.线性回归分析 (1) 散点图:将样本中的各对数据在直角坐标系中描点而得到的图形叫做散点图,它直观地 描述了两个变量之间是否有相关关系,是判断两个变量相关性的重要依据。 (2) 回归直线:散点图中点的整体分布在一条直线左右,则称这两个变量之间具有线性相关
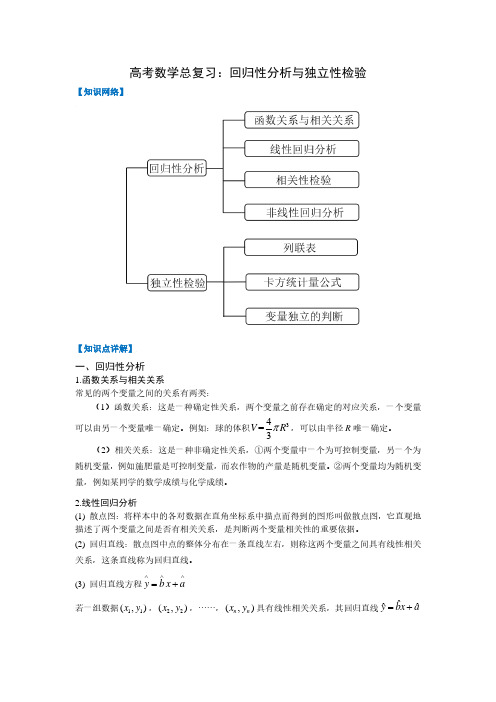
(a b)(c d)(a c)(b d )
通过对统计量 K2 的研究,一般情况下认为:
①当 K 2 ≤3.841 时,认为变量 X 与 Y 是无关的。
②当 K 2 >3.841 时,有 95%的把握说变量 X 与 Y 有关;
④ 当 K 2 >6.635 时,有 99%的把握说变量 X 与 Y 有关;
定在多大程度上可以认为“两个分类变量有关系”的方法称为两个分类变量的独立性检验。
2.分类变量的理解: 分类变量是说明事物类别的一个名称,其取值是分类数据。如“性别”就是一个分类变 量,其变量值为“男”或“女”;“行业”也是一个分类变量,其变量值可以为“零售 业”,说明 X 与 Y 无关的把握越小
6. 右表是对与喜欢足球与否的统计列联表依据表中的数据,得到( )
A. K 2 9.564 B. K 2 3.564 C. K 2 2.706 D. K 2 3.841
7. 对两个分类变量 A、B 的下列说法中正确的个数为( ). ①A 与 B 无关,即 A 与 B 互不影响;②A 与 B 关系越密切,则 K2 的值就越大;③K2
x yw
46.6 563 6.8
8
(xi x )2
i 1
独立性检验原理

独立性检验原理
一、独立性检验原理
独立性检验是一种统计学方法,用来检验两个变量之间是否具有某种特定的关联。
这种检验通常被称为卡方检验,也称为假设检验,可用于衡量总体比例的差异。
独立性检验的原理是基于卡方检验的假设。
卡方检验是一种假定检验,由卡方分布检验构成,它主要对两个及以上的分类字段进行检验,以确定两个或多个字段是否存在某种统计关联。
此外,在独立性检验中,被检验的时间变量不能过剩或不足。
检验的内容取决于所检验的变量是多变量还是单变量。
如果是多变量检验,可以分析多个变量之间的时间关系;而如果是单变量检验,则只能测量单变量之间的关系。
独立性检验也是针对总体比例的,因此它可以用于衡量独立变量和因变量间的关系。
例如,独立性检验可用于测量某种健康行为的总体比例,以及分析事件发生的不同国家或地区之间是否具有某种统计关联性。
另外,独立性检验也可用于分析多项结果之间具有相互影响的概率,以及分析某种疾病的发病率。
例如,它可以用于确定一个人决定一种某种疾病发病的概率是否与另一个人的不同因素(例如性别)有关。
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
推出矛盾,意味着结 推出有利于H1成立的小概率事件 发生,意味着 H1成立的可能性 论A成立 很大 没有找到矛盾,不能对 推出有利于H1 成立的小概率事 H A下任何结论,即反 件不发生,接受原假设 证不成功
0
例 1. 在 500 人身上试验某种血清预防感冒作用,把他们 P(χ≥x0) 0.50 0.40 0.25 0.15 0.10 0.05 0.025 0.010 0.005 0.001 一年中的感冒记录与另外 500 名未用血清的人的感冒记 x0 0.455 0.708 1.323 2.072 2.706 3.841 5.024 6.635 7.879 10.828 录作比较,结果如表所示。问:该种血清能否起到预防 感冒的作用? 未感冒 感冒 合计
99.9%把握认 为A与B有关
99%把握认 6.635 为A与B有关 90%把握认 10%把握认为 2 2.706 为A与B有关 A与B无关 没有充分的依据显示A与B有关, 2 2.706 但也不能显示A与B无关
2
解:H0: 吸烟和患肺癌之间没有关系
患肺癌 不患肺癌 吸烟 15 患肺 不患 39 总计 癌 肺癌 21 不吸烟 25
P(x2≥k) k 0.50 0.40 0.25 0.15 0.10 0.05 0.025 0.010 0.005 0.001
0.455 0.708 1.323 2.072 2.706 3.841 5.024 6.635 7.879 10.828
10.828
2
0.1%把握认 为A与B无关 1%把握认为 A与B无关
3、计算
a bc d a 2 c b d
nad bc a bc d a c b d
2
4、把 的值与临界值进行比较,确定X,Y有关系 的程度或无关系
作业: 数学同步导学P64-65
用A表示:吸烟,用B表示:患肺癌
P(A)=0.54 P(B)=0.6
P(AB)=0.39 P(AB)=0.39
P(A)P(B) =0.324
从上面数据和事件的独立性显然是可 以断定吸烟和患肺癌有关
我们能够有多大的把握认 为“吸烟与患肺癌有关”?
独立性检验
第一步:假设 H0:吸烟与患肺癌没有关系 第二步:列出2× 2列联表
练习1:为了探究患气管炎是否与吸烟有关, 调查了409名50岁以上的人,现已将得到的数 2 =12.34 ,则下列说法 据进行计算得 中正确的是( D ) A.50岁以上的人,患慢性气管炎与吸烟无关
B.在100个50岁以上的患慢性气管炎的人中, 一定有95人有吸烟习惯 C.在100个50岁以上的患慢性气管炎的人中, 一定有995人有吸烟习惯 D.我们有99%的把握认为50岁以上的人患慢 性气管炎与吸烟习惯有关
现在的 =7.31的观测值大于6.635,出现 这样的观测值的概率不超过0.01。
2
故有99%的把握认为H0不成立,即有99%的把 握认为“患肺癌与吸烟有关系”。
反证法原理与独立性(假设)检验原理 反证法
要证明结论A 在A不成立的前提下 进行推理
假设检验
1 A与B有关系) 要证明假设 H(
假设H ( 0 A与B没有关系)成 H 立的条件下进行推理
吸烟 不吸 烟2 总计
总计 54 46 100
总计
39
15
60
54
40
通过公式计算
100(39 25 15 21) 7.31 60 40 54 46
2
21 60
25 40
46
100
已知在 H 0成立的情况下,
P(
2
6.635) 0.01
2 即在 H 0 成立的情况下, 大于6.635概率非常小, 近似为0.01
分类变量Y1 分类变量Y2 总计
分类变量X1 a c a+c
分类变量X2 b d b+d
总计 a+b c+d a+b+c+d
第三步:引入一个随机变量:卡方统计量
nad bc (n=a+b+c+d) a bc d a c b d
2 2
第四 122
无效 40 31 71
2
合计 98 95 193
解:设H0:药的效果与给药方式没有关系。
19358 31 64 40 2 1.3896 122 71 98 95 因当H0成立时,χ2≥1.3896的概率大于15%,故不能否定假设 H0,即不能作出药的效果与给药方式有关的结论。
练习 3 :为研究学生数学课堂上听课效率是否与吃早餐 有关,现在随机对20位水平相当的同学某天的课堂小测 进行调查,结果如下: 成绩<=80 成绩>80 合计
没吃早餐 有吃早餐 合计 4 3 7 1 12 13 5 15 20
试问有多大把握认为听课效率与吃早餐有关?
P(2 ≥x0) 0.50 0.40 0.25 0.15 x0 0.10 0.05 0.025 0.010 0.005 0.001
21 60
54
不 45.65% 在不吸烟中患肺癌的比例是 吸 21 25 46 烟 在吸烟中患肺癌的比例是 72.22% 总 60 40 100 计
事件A与事件B相互独立 P(AB)= P(A)P(B)
吸烟 不吸烟 总计
患肺癌 39 21 60 不患肺癌 15 25 40 总计 54 46 100
列联表独立性分析案例
对于性别变量,其取值为男和女两种.
对于血型变量,其取值可分为 O型、A型、B型、AB型等.
这种变量的不同“值”表 示个体所属的不同类别,像 这类变量称为分类变量.
生活中的分类变量
是否吸烟,宗教信仰,国籍„
两个分类变量之间是否有关系? 吸烟 患肺癌
周恩来不抽烟不喝酒,活到 78岁;毛泽东只抽烟不喝酒, 活到83岁;邓小平又抽烟又 喝酒,活到98岁——孩子规 劝父母戒烟戒酒,竟得到如 此回答。
练习 2:为研究不同的给药方式(口服与注射)和药的 P(χ≥x 0.10 0.05 0.025 0.010 0.005 0.001 0) 0.50 0.40 0.25 0.15 效果(有效与无效)是否有关,进行了相应的抽样调 x0 0.455 0.708 1.323 2.072 2.706 3.841 5.024 6.635 7.879 10.828 查,调查的结果列在表中,根据所选择的193个病人 的数据,能否作出药的效果和给药方式有关的结论?
0.455 0.708 1.323 2.072 2.706 3.841 5.024 6.635 7.879 10.828
课堂小节:
一.分类变量的定义
二.2×2列联表
三.利用独立性检验来考虑两个分类变量是否相关
2
1、假设两个分类变量X,Y独立
K
2
2、列n2 × 2列联表 ad bc
2
问题1:吸烟与患肺癌有关系吗?
问题2:你有多大程度把握吸烟与患肺癌有关系?
为了调查吸烟是否对患肺癌有影响?某医疗研究 所随机地调查了100人,得到如下结果 2×2列联表
未患 患肺 患肺癌 肺 总计 癌 39 吸烟 癌
不吸烟 吸 39 烟 总计
不患肺癌 15 25 40
总计 54 46 100
15
使用血清 未使用血清
合计
258 216
474
242 284
526
2
500 500
1000
解:设H0:感冒与是否使用该血清没有关系。
1000258 284 242 216 2 7.075 474 526 500 500 因当H0成立时,χ2≥6.635的概率约为0.01,故有99%的把握认 为该血清能起到预防感冒的作用。