编译原理教程(第二版)胡元义课后答案第四章
编译原理_chapter4

Fa | (E)
描述IF语句的二义文法
<stmt>→ if <expr> then <stmt>
| if <expr> then <stmt> else <stmt>
| other
(4.7)
根据if语句中else与then配对情况将其分为配对 的语句和不配对的语句两类。
上述if语句的文法没有对这两个不同的概念加 以区分,只是简单地将它们都定义为<stmt>, 从而导致该文法是二义性的。
if e1 then if e2 then s1 else s2的语法树
二义性(ambiquity)的定义
对于文法G,如果L(G)中存在一个具有两 棵或两棵以上分析树的句子,则称G是二 义性的。也可以等价地说:如果L(G)中
存在一个具有两个或两个以上最左(或最
右)推导的句子,则G是二义性文法。 如果一个文法G是二义性的,假设
2021/4/25
计算机学院 辛明影
E E→a a
E
E→a a
一棵树!
9
关于语法树的几点结论
短语:一棵子树的 所有叶子自左至右 排列起来形成一个 相对于子树根的短 语。教材p50
短语:
a, a,a,
a+a, a+a*a
2021/4/25
E E* E E +E
a
aa
10
关于语法树的几点结论
直接短语:仅有父子两 代的一棵子树,它的 所有叶子自左至右排列 起来所形成的符号串。
对于一般情况而言,若某一文法G的产生 式具有如下形式:
A→A α1| A α2 |…| A αm| β1| β2|…| βn
编译原理课后答案-第二版

从子树和短语之间的关系可知:
E+T*F是句型E+T*F相对于E的短语;
T*F是句型E+T*F相对于T的短语,也是简单短语和句柄。
13、(1)最左推导:S => ABS =>aBS=>aSBBS=>aBBS=>abBS=>abbS=>abbAa=>abbaa
A—>1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9
B—>AB | 0B |ε
C—>0 | 2 | ห้องสมุดไป่ตู้ | 6 | 8
考虑包括“0”的情况:
G[S]:S—>AB | C
B—>AB | C
A—>0 | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9
C—>0 | 2 | 4 | 6 | 8
Π0:{A,B},{C}
对终态组进行审查,判断A和B是等价的,故这是最后的划分
重新命名,以A、C代替{A,B}、{C}得DFA
a
b
–+A
A
C
C
A
(2)这是DFA,直接最小化
初始分划得:终态组{0},非终态组{1,2,3,4,5}
Π0:{0},{1,2,3,4,5}
对{1,2,3,4,5}进行审查:
∵{4}输入a后 到达{0},{1,2,3,5}输入a后 到达{1,3,5},故得到新分划{0,1,3,5},{4}
C—>2 | 4 | 6 | 8
6、设<表达式>为E,<项>为T,<因子>为F,注:推导过程不能省略,以下均为最左推导
编译原理课后答案-第二版
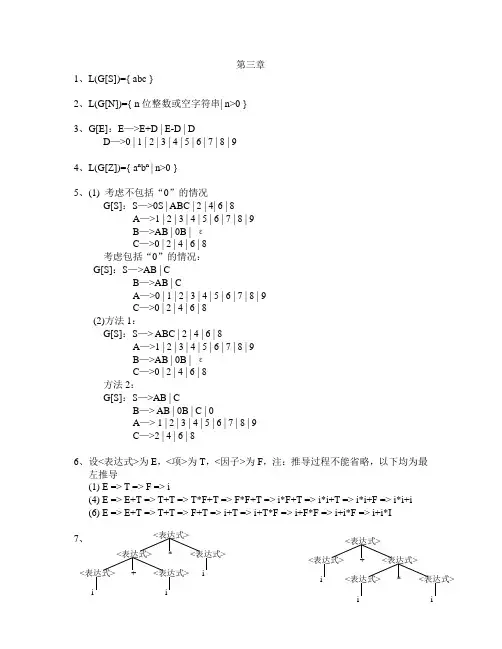
第三章1、L(G[S])={ abc }2、L(G[N])={ n位整数或空字符串| n>0 }3、G[E]:E—>E+D | E-D | DD—>0 | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 94、L(G[Z])={ a n b n | n>0 }5、(1) 考虑不包括“0”的情况G[S]:S—>0S | ABC | 2 | 4| 6 | 8A—>1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9B—>AB | 0B | εC—>0 | 2 | 4 | 6 | 8考虑包括“0”的情况:G[S]:S—>AB | CB—>AB | CA—>0 | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9C—>0 | 2 | 4 | 6 | 8(2)方法1:G[S]:S—> ABC | 2 | 4 | 6 | 8A—>1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9B—>AB | 0B | εC—>0 | 2 | 4 | 6 | 8方法2:G[S]:S—>AB | CB—> AB | 0B | C | 0A—> 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9C—>2 | 4 | 6 | 86、设<表达式>为E,<项>为T,<因子>为F,注:推导过程不能省略,以下均为最左推导(1) E => T => F => i(4) E => E+T => T+T => T*F+T => F*F+T => i*F+T => i*i+T => i*i+F => i*i+i(6) E => E+T => T+T => F+T => i+T => i+T*F => i+F*F => i+i*F => i+i*I7、<表达式><表达式>*<表达式><表达式>+<表达式>i i i<表达式><表达式>+<表达式>i <表达式>*<表达式>i i8、是有二义性的,因为句子abc 有两棵语法树(或称有两个最左推导或有两个最右推导)最左推导1:S => Ac => abc 最左推导2:S => aB => abc 9、(1)(2) 该文法描述了变量a 和运算符+、*组成的逆波兰表达式10、(1) 该文法描述了各种成对圆括号的语法结构(2) 是有二义性的,因为该文法的句子()()存在两种不同的最左推导: 最左推导1:S => S(S)S => (S)S => ()S => ()S(S)S => ()(S)S => ()()S => ()()最左推导2:S => S(S)S => S(S)S(S)S => (S)S(S)S=> ()S(S)S => ()(S)S => ()()S => ()()11、(1) 因为从文法的开始符E 出发可推导出E+T*F ,推导过程如下:E => E+T =>E+T*F ,所以E+T*F 是句型。
清华大学编译原理第二版课后习答案

《编译原理》课后习题答案第一章第 4 题对下列错误信息,请指出可能是编译的哪个阶段(词法分析、语法分析、语义分析、代码生成)报告的。
(1) else 没有匹配的if(2)数组下标越界(3)使用的函数没有定义(4)在数中出现非数字字符答案:(1)语法分析(2)语义分析(3)语法分析(4)词法分析《编译原理》课后习题答案第三章第1 题文法G=({A,B,S},{a,b,c},P,S)其中P 为:S→Ac|aBA→abB→bc写出L(G[S])的全部元素。
答案:L(G[S])={abc}第2 题文法G[N]为:N→D|NDD→0|1|2|3|4|5|6|7|8|9G[N]的语言是什么?答案:G[N]的语言是V+。
V={0,1,2,3,4,5,6,7,8,9}N=>ND=>NDD.... =>NDDDD...D=>D......D或者:允许0 开头的非负整数?第3题为只包含数字、加号和减号的表达式,例如9-2+5,3-1,7等构造一个文法。
答案:G[S]:S->S+D|S-D|DD->0|1|2|3|4|5|6|7|8|9第4 题已知文法G[Z]:Z→aZb|ab写出L(G[Z])的全部元素。
答案:Z=>aZb=>aaZbb=>aaa..Z...bbb=> aaa..ab...bbbL(G[Z])={anbn|n>=1}第5 题写一文法,使其语言是偶正整数的集合。
要求:(1) 允许0 打头;(2)不允许0 打头。
答案:(1)允许0 开头的偶正整数集合的文法E→NT|DT→NT|DN→D|1|3|5|7|9D→0|2|4|6|8(2)不允许0 开头的偶正整数集合的文法E→NT|DT→FT|GN→D|1|3|5|7|9D→2|4|6|8F→N|0G→D|0第6 题已知文法G:<表达式>::=<项>|<表达式>+<项><项>::=<因子>|<项>*<因子><因子>::=(<表达式>)|i试给出下述表达式的推导及语法树。
编译原理(第二版)清华大学---答案详解

第1章引论第1题解释下列术语:(1)编译程序(2)源程序(3)目标程序(4)编译程序的前端(5)后端(6)遍答案:(1) 编译程序:如果源语言为高级语言,目标语言为某台计算机上的汇编语言或机器语言,则此翻译程序称为编译程序。
(2) 源程序:源语言编写的程序称为源程序。
(3) 目标程序:目标语言书写的程序称为目标程序。
(4) 编译程序的前端:它由这样一些阶段组成:这些阶段的工作主要依赖于源语言而与目标机无关。
通常前端包括词法分析、语法分析、语义分析和中间代码生成这些阶段,某些优化工作也可在前端做,也包括与前端每个阶段相关的出错处理工作和符号表管理等工作。
(5) 后端:指那些依赖于目标机而一般不依赖源语言,只与中间代码有关的那些阶段,即目标代码生成,以及相关出错处理和符号表操作。
(6) 遍:是对源程序或其等价的中间语言程序从头到尾扫视并完成规定任务的过程。
第2题一个典型的编译程序通常由哪些部分组成?各部分的主要功能是什么?并画出编译程序的总体结构图。
答案:一个典型的编译程序通常包含8个组成部分,它们是词法分析程序、语法分析程序、语义分析程序、中间代码生成程序、中间代码优化程序、目标代码生成程序、表格管理程序和错误处理程序。
其各部分的主要功能简述如下。
词法分析程序:输人源程序,拼单词、检查单词和分析单词,输出单词的机内表达形式。
语法分析程序:检查源程序中存在的形式语法错误,输出错误处理信息。
语义分析程序:进行语义检查和分析语义信息,并把分析的结果保存到各类语义信息表中。
中间代码生成程序:按照语义规则,将语法分析程序分析出的语法单位转换成一定形式的中间语言代码,如三元式或四元式。
中间代码优化程序:为了产生高质量的目标代码,对中间代码进行等价变换处理。
目标代码生成程序:将优化后的中间代码程序转换成目标代码程序。
表格管理程序:负责建立、填写和查找等一系列表格工作。
表格的作用是记录源程序的各类信息和编译各阶段的进展情况,编译的每个阶段所需信息多数都从表格中读取,产生的中间结果都记录在相应的表格中。
新编语言学教程第2版第4章答案

新编语⾔学教程第2版第4章答案《新编简明英语语⾔学教程》第⼆版第4章练习题参考答案Chapter 4 Syntax1. What is syntax?Syntax is a branch of linguistics that studies how words are combined to form sentences and the rules that govern the formation of sentences.2. What is phrase structure rule?The grammatical mechanism that regulates the arrangement of elements (i.e. specifiers, heads, and complements) that make up a phrase is called a phrase structure rule.The phrase structural rule for NP, VP, AP, and PP can be written as follows: NP →(Det) N (PP) ...VP →(Qual) V (NP) ...AP →(Deg) A (PP) ...PP →(Deg) P (NP) ...We can formulate a single general phrasal structural rule in which X stands for the head N, V, A or P.3. What is category? How to determine a word's category?Category refers to a group of linguistic items which fulfill the same or similar functions in a particular language such as a sentence, a noun phrase or a verb.To determine a word's category, three criteria are usually employed, namely meaning, inflection and distribution.若详细回答,则要加上:Word categories often bear some relationship with its meaning. The meanings associated with nouns and verbs can be elaborated in various ways. The property or attribute of the entities denoted by nouns can be elaborated by adjectives. For example, when we say that pretty lady, we are attributing the property ‘pretty’ to the lady designated by the noun. Similarly, the properties and attributes of the actions, sensations and states designated by verbs can typically be denoted by adverbs. For example, in Jenny left quietly the adverb quietly indicates the manner of Jenny's leaving.The second criterion to determine a word's category is inflection. Words of different categories take different inflections. Such nouns as boy and desk take the plural affix -s. Verbs such as work and help take past tense affix -ed and progressive affix -ing. And adjectives like quiet and clever take comparative affix -er and superlative affix -est. Although inflection is very helpful in determining a word's category, it does not always suffice. Some words do not take inflections. For example, nouns like moisture, fog, do not usually take plural suffix -s and adjectives like frequent, intelligent do not take comparative and superlative affixes -er and -est.The last and more reliable criterion of determining a word's category is its distribution. That is what type of elements can co-occur with a certain word. For example, nouns can typically appear with a determiner like the girl and a card, verbs with an auxiliary such as should stay and will go, and adjectives with a degree word such as very cool and too bright.A word's distributional facts together with information about its meaning and inflectional capabilities help identify its syntactic category.4. What is coordinate structure and what properties does it have?The structure formed by joining two or more elements of the same type with the help of a conjunction is called coordinate structures.It has (或写Conjunction exhibits) four important properties:1) There is no limit on the number of coordinated categories that can appear prior to theconjunction.2) A category at any level (a head or an entire XP) can be coordinated.3) Coordinated categories must be of the same type.4) The category type of the coordinate phrase is identical to the category type of the elements being conjoined.5. What elements does a phrase contain and what role does each element play?A phrase usually contains the following elements: head, specifier and complement. Sometimes it also contains another kind of element termed modifier.The role each element can play:Head:Head is the word around which a phrase is formed.Specifier:Specifier has both special semantic and syntactic roles. Semantically, it helps to make more precise the meaning of the head. Syntactically, it typically marks a phrase boundary.Complement:Complements are themselves phrases and provide information about entities and locations whose existence is implied by the meaning of the head.Modifier:Modifiers specify optionally expressible properties of the heads.6. What is deep structure and what is surface structure?There are two levels of syntactic structure. The first, formed by the XP rule in accordance with the head's subcategorization properties, is called deep structure(or D-structure). The second, corresponding to the final syntactic form of the sentence which results from appropriate transformations, is called surface structure (or S-structure).第7—13⼩题⼤部分要求画树形图,这⾥省略。
编译原理第四章 参考答案
1.1考虑下面文法G1S->a|^|(T)T->T,S|S消去G1的左递归。
然后对每个非终结符,写出不带回溯的递归子程序。
答::(1)消除左递归:S->a|^|(T)T-> ST’T’->,S T’|ε(2)first(S)={ a , ^ , ( } first(T)= { a , ^ , ( } first(T’)={ , ε}First(a)={a},First(^)={^},First( (T) )={ ( }S的所有候选的首符集不相交First(,ST’)={,} ,First(ε)={ε},T’的所有候选的首符集不相交Follow(T’)=Follow(T)={ )}first(T’)∩Follow(T’)={}所以改造后的文法为LL(1)文法。
不带回溯的递归子程序如下:S( ){if (lookahead=’a’) advance;Else if(lookahead=’^’) advance;Else if(lookahead=’(’){advance;T();if(lookahead=’)’) advance;else error();}Else error();}T( ){S( );T’( ):}T’->,S T’|εT’( ){if (lookahead=’,’){advance;T’();}Else if(lookahead=Follow(T’)) advance;Else error;}有文法G(S):S→S+aF|aF|+aFF→*aF|*a(1)改写文法为等价文法G[S’],消除文法的左递归和回溯(2)构造G[S’]相应的FIRST和FOLLOW集合;(3)构造G[S’]的预测分析表,以此说明它是否为LL(1)文法。
(4)如果是LL(1)文法,请给出句子a*a+a*a*a的预测分析过程该文法为LL(1)文法,因为它的预测分析表中无冲突项。
编译原理第四章作业答案
非终结符
FIRSTVT
LASTVT
E
+ * ↑( i
+ * ↑) i
T
* ↑( i
* ↑) i
F
↑( i
↑)i
P
(i
)i
2).关系 1.由#E#,知 # = # ;由(E)知 ( = ) 2.求 < 关系 考察对象:文法中终结符号在前,非终结符号在后的相邻符号对 由#E # < FIRSTVT(E) 由+T + < FIRSTVT(T) 由*F * < FIRSTVT(F) 由↑F ↑< FIRSTVT(F) 由(E ( < FIRSTVT(E)
T→F
F→-P
F→P
P→(E)
P→i
(1) 构造 G 的算符优先矩阵;
(2) 指出 G 不是算符优先文法,即指出具有多重定义的优先矩阵元素;
(3)将 G 改写为算符优先文法。
解:
(1)求每个非终结符号的 FIRSTVT 集和 LASTVT 集
S→E
E→E-T|T
T→T*F|F
F→-P|P
P→(E)|i
Z 11 Z 12 Z 13
(S
A
B ) = (φ (S ) + () [S ] + [])Z 21
Z 22
Z
23
Z 31 Z 32 Z 33
Z 11 Z 12 Z 13 ε φ φ A B φ Z 11 Z 12 Z 13
Z 21
Z 22
Z
23
=
φ
ε
φ
+
ε
φ
φ
Z
21
Z 22
编译原理第4章习题解答
第4章习题解答:1,2,3,4 解答略!5. 解答:(1)× (2)√ (3)× (4)√ (5)√ (6)√(7)×(8)×6. 解答:(1)A:④ B:③ C:③ D:④ E:②(2)A:④ B:④ C:③ D:③ E:②7.解答:(1) 消除给定文法中的左递归,并提取公因子:bexpr→bterm {or bterm }bterm→bfactor {and bfactor}bfactor→not bfactor | (bexpr) | true |false(2) 用类C语言写出其递归分析程序:void bexpr();{bterm();WHILE(lookahead =='or') { match ('or');bterm();}}void bterm();{bfactor();WHILE(lookahead =='and'){ match ('and');bfactor();}} void bfactor();{if (llokahead=='not') then {match ('not');bfactor();}else if(lookahead=='(') then {match (‘(');bexpr();match(')');}else if(lookahead =='true')then match ('true) else if (lookahead=='false')then match ('false');else error;}8. 解答:消除所给文法的左递归,得G':S →(L)|aL → SL'L'→ ,SL' |实现预测分析器的不含递归调用的一种有效方法是使用一张分析表和一个栈进行联合控制,下面构造预测分析表:根据文法G'有:First(S) = { ( , a ) Follow(S) = { ) , , , #}First(L) = { ( , a ) Follow(L) = { ) }First(L') = { ,} Follow(L') = { ) }按以上结果,构造预测分析表M如下:文法G'是LL(1)的,因为它的LL(1)分析表不含多重定义入口。
《编译原理》(清华大学出版社第二版)课后习题答案
PL/0编译程序所产生的目标代码是一种假想栈式计算机的汇编语言,请说明该汇编语言中下列指令各自的功能和所完成的操作。
(1)INT 0 A
(2)OPR 0 0
(3)CAL L A
答案:
PL/0编译程序所产生的目标代码中有3条非常重要的特殊指令,这3条指令在code中的位置和功能以及所完成的操作说明如下:
或者:允许0开头的非负整数?
第3题
为只包含数字、加号和减号的表达式,例如9-2+5,3-1,7等构造一个文法。
答案:
G[S]:
S->S+D|S-D|D
D->0|1|2|3|4|5|6|7|8|9
第4题
已知文法G[Z]:
Z→aZb|ab
写出L(G[Z])的全部元素。
答案:
Z=>aZb=>aaZbb=>aaa..Z...bbb=> aaa..ab...bbb
N→D|1|3|5|7|9
D→2|4|6|8
F→N|0
G→D|0
第6题
已知文法G:
<表达式>::=<项>|<表达式>+<项>
<项>::=<因子>|<项>*<因子>
<因子>::=(<表达式>)|i
试给出下述表达式的推导及语法树。
(5)i+(i+i)
(6)i+i*i
答案:
(5) <表达式>
=><表达式>+<项>
n n
L(G[Z])={a b |n>=1}
第5题写一文法,使其语言是偶正整数的集合。要求:
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
101 (= ,1 ,_ , i )
102 (j≤,i ,20,104 ) 103 ( j ,_ ,_ ,114 ) 104 ( * ,4 ,i ,T1 ) 105 ( - ,A ,4 ,T2 )
106 (=[ ],T2 ,T1 ,T3 )
第四章 语义分析和中间代码生成 107 ( * ,4 ,i ,T4 ) 108 ( - ,B ,4 ,T5 )
不发生转移(即顺序执行下一个四元式),从而产生效
率较高的四元式代码。
第四章 语义分析和中间代码生成 【解答】 程序如下: 按要求改造描述布尔表达式的语义子
(1) E→i {E.tc=null;E.fc=nxq;emit(jez,entry(i),__ ,0);} (2) E→i(1) rop i(2) {E.tc=null;E.fc=nxq;emit(jnrop,entry(i(1)),entry (i(2));) /* nrop表示关系运算符与rop相反*/
(3) E→(E(1))
{E.tc=E(1).tc; E.fc=E(1).fc;}
(4) E→┐E(1) {E.fc=nxq;emit(j,__ ,__ ,0);Backpatch(E(1).fc,nx q);}
第四章 语义分析和中间代码生成 (5) EA→E(1) ∧ (6) E→EAE(2) {EA.fc=E(1).fc;}
第四章 语义分析和中间代码生成 在生成中间代码时,条件“i>0”为假的转移地址 无法确定,而要等到处理“else”时方可确定,这时就
存在一个地址返填问题。此外,按语义要求,当处理
完(i>0)后的语句(即“i>0”为真时执行的语句)时,则 应转出当前的if语句,也即此时应加入一条无条件跳
转指令,并且这个转移地址也需要待处理完else之后
和E3 分别对应A<C∧B<D、A≥1和A≤D,并且关系运 算符优先级高): 100 (j<,A,C,102) 101 (j,_,_,113) /*E1为F*/
102 (j<,B,D,104)
103 (j,_,_,113) 104 (j=,A,1,106)
/*E1为T*/
/*E1为F*/ /*E2为T*/
E的代码 真 S( 1 )的 代 码 假
图4-1 习题4.6的语句结构图
第四章 语义分析和中间代码生成 【解答】 本题的语义解释图已经给出了翻译后 的中间代码结构。在语法制导翻译过程中,当扫描到 while时,应记住E的代码地址;当扫描到do时,应对E 的“真出口”进行回填,使之转到S(1)代码的入口处; 当扫描到S(1)时,除了应将E的入口地址传给S(1).chain 之外,还要形成一个转向E入口处的无条件转移的四元 式,并且将E.fc继续传下去。因此,应把S→while E do S(1) 改写为如下的三个产生式: W→while A→W E do S→A S(1)
第四章 语义分析和中间代码生成 4.7 改写布尔表达式的语义子程序,使得i(1) rop
i(2)不按通常方式翻译为下面的相继两个四元式: (jrop, i(1), i(2), 0) (j ,__ ,__ , 0 ) 而是翻译成如下的一个四元式: (jnrop, i(1), i(2), 0) 使得当i(1) rop i(2) 为假时发生转移,而为真时并
{T.type=real;}
4.5 写出翻译过程调用语句的语义子程序。在所 生成的四元式序列中,要求在转子指令之前的参数四 元式par按反序出现(与实现参数的顺序相反)。此时, 在翻译过程调用语句时,是否需要语义变量(队 列)queue?
第四章 语义分析和中间代码生成 【解答】 为使过程调用语句的语义子程序产生 的参数四元式par按反序方式出现,过程调用语句的文 法为 S→call i(arglist) arglist→E
B→0|1
【解答】 计算S.val的文法G′[S]及语义动作如下: 产生式 S→L1·2 L L2.val/2L2.length} 语义动作 {S.val:=L1.val +
G′[S]:S′→S {print(S.val)}
第四章 语义分析和中间代码生成 S→L L→L1B L→B { S.val:=L.val } {L.val:=L1.val*2 + B.val {L.val:=B.val L.length:=2} B→1 B→0 {B.val:=1} {B.val:=0}
109 (=[ ],T5 ,T4 ,T6 )
110 ( * ,T3 ,T6 ,T7 ) 111 ( +,prod,T7,prod) 112 ( +, i, 1, i ) 113 (j,_ ,_ ,102 )
第四章 语义分析和中间代码生成 【解答】 此题只需要对说明语句进行语义分析
而不需要产生代码,但要求把每个标识符的类型填入
符号表中。对D、L、T,为其设置综合属性type,而过
程enter(name,type)用来把名字name填入到符号表中, 并且给出此名字的类型type。翻译方案如下:
D→id L
arglist→arglist(1),E
按照该文法,语法制导翻译程序不需要语义变量 队列queue,但需要一个语义变量栈STACK,用来实现 按反序记录每个实在参数的地址。翻译过程调用语句 的产生式及语义子程序如下:
第四章 语义分析和中间代码生成 (1) arglist→E { 建立一个 arglist.STACK栈,它仅包含一项E.place} (2) arglist→arglist(1) ,E 入 arglist(1). STACK 栈 STACK=arglist(1).STACK} (3) S→call i (arglist) arglist.STACK≠null do begin 将arglist.STACK栈顶项弹出并送入p单元之中; emit (par,_ ,_ ,p); end; { 将E.place压 , arglist. {while
第四章 语义分析和中间代码生成 105 (j,_,_,108) 106 (+, C, 1, C) /*E2为F*/ /*C:=C+1*/
107 (j,_,_,112)
108 (j≤,A,D,110) 109 (j,_,_,112) 110 (+, A, 2, A) 111 (j,_,_,108)
d. 节省存储空间,不便于优化处理
第四章 语义分析和中间代码生成 (3) 表达式(┐A∨B)∧(C∨D)的逆波兰表示为 a. ┐AB∨∧CD∨ c. AB∨┐CD∨∧ (4) 有一语法制导翻译如下所示: S→bAb {print″1″} 。
b. A┐B∨CD∨∧ d. A┐B∨∧CD∨
A→(B
第四章 语义分析和中间代码生成
第四章 语义分析和中间代码生成
4.1 完成下列选择题: (1) 四元式之间的联系是通过 a. 指示器 b. 临时变量 实现的。
c. 符号表
d. 程序变量
。
(2) 间接三元式表示法的优点为 a. 采用间接码表,便于优化处理 b. 节省存储空间,不便于表的修改 c. 便于优化处理,节省存储空间
/*跳过else后的语句*/
/*E3为T*/ /*E3为F*/ /*A:=A+2*/ /*转回内层while语句开始处*/
112 (j,_,_,100)
113
/*转回外层while语句开始处*/
第四章 语义分析和中间代码生成 4.9 已知源程序如下: prod=0; i=1; while (i≤20) {
第四章 语义分析和中间代码生成 用语法制导翻译(SDTS)生成中间代码的要点如下: (1) 按语法成分的实际处理顺序生成,即按语义
要求生成中间代码。
(2) 注意地址返填问题。 (3) 不要遗漏必要的处理,如无条件跳转等。 例如下面的程序段: if (i>0) a=i+e-b*d; else a=0;
的 对于赋值语句a=i+e-b*d,其处理顺序(也即生成中间
代码顺序)是先生成i+e的代码,再生成b*d的中间代码,
最后才产生“-”运算的中间代码,这种顺序不能颠倒。
第四章 语义分析和中间代码生成 4.3 令S.val为文法G[S]生成的二进制数的值,例如 对输入串101.101,则S.val=5.625。按照语法制导翻译方 法的思想,给出计算S.val的相应的语义规则,G(S)如下: G[S]: S→L.L|L L→LB|B
第四章 语义分析和中间代码生成 每个产生式对应的语义子程序如下: W→while { W.quad=nxq;} A→W E do { Backpatch(E.tc,nxq);
A.chain=E.fc;
A.quad=W.quad;} S→A S(1) { Backpatch(S(1).chain,A.quad); emit(j,_,_,A.quad); S.chain=A.chain;}
emit (call,_ ,_ , entry (i));}
第四章 语义分析和中间代码生成 4.6 设某语言的while语句的语法形式为 S→ while E do S(1)
其语义解释如图4-1所示。
(1) 写出适合语法制导翻译的产生式; (2) 写出每个产生式对应的语义动作。
第四章 语义分析和中间代码生成
{E.tc=E(2).tc;E.fc=merg(EA.fc,E(2).fc);}
(7) E0→E(1)∨ {E0.tc=nxq;emit(j,__ ,__ ,0);Backpatch(E(1).fc,n xq);} (8) E→E0E(2) {E.fc=E(2).fc;Backpatch(E0.tc,nxq);}
L.length:=L1.length +1}
第四章 语义分析和中间代码生成 4.4 下面的文法生成变量的类型说明: D→id L