第29章 路径分析——【SPSS精品教程 资源池】
“保姆级”操作教程 手把手教你SPSS分析数据实战这也太方便了吧

保姆级操作教程 | 手把手教你SPSS分析数据实战这也太方便了吧数据分析是现代社会研究中不可或缺的一部分。
而SPSS作为一款功能强大且易于使用的统计分析软件,受到了许多研究人员和学生的青睐。
本文将手把手教你如何使用SPSS进行数据分析,让你的研究工作更加高效和准确。
步骤1:导入数据首先,打开SPSS软件并点击菜单栏上的“文件”选项。
然后选择“打开”并浏览你存储数据集的位置。
选择相应的数据文件,并点击“打开”。
现在,你的数据集就已经成功导入。
步骤2:查看数据在导入数据后,你可以通过点击菜单栏上的“数据视图”选项来查看数据。
在数据视图中,你可以浏览和编辑数据。
如果你想查看数据的统计摘要信息,可以点击菜单栏上的“变量视图”选项。
步骤3:数据清理在进行数据分析之前,你需要对数据进行清理。
这包括处理缺失值、异常值和离群值等。
SPSS提供了一系列用于数据清理的功能,例如删除无效数据、替换缺失值等。
你可以使用菜单栏上的“转换”选项来执行这些操作。
步骤4:选择统计分析方法在进行数据清理后,接下来需要选择合适的统计分析方法。
SPSS提供了多种常用的统计分析方法,例如描述统计、相关分析、回归分析、t检验等。
你可以根据自己的研究目的和数据类型选择相应的方法。
步骤5:进行统计分析一旦你选择了合适的统计分析方法,你可以点击菜单栏上的“分析”选项,并选择相应的分析方法。
然后,你需要选择要分析的变量,并设置相应的参数。
点击“确定”后,SPSS将自动进行统计分析,并生成相应的结果。
步骤6:解读结果进行完统计分析后,你需要对分析结果进行解读。
SPSS会生成各种统计指标和图表,用于帮助你理解数据。
你可以查看参数估计值、置信区间、显著性水平等信息,并根据这些结果进行推断和判断。
步骤7:报告和呈现结果最后,你需要将分析结果进行报告和呈现。
SPSS提供了生成报告和图表的功能,你可以根据需要选择相应的样式和格式。
在报告中,你可以总结分析结果、提出结论,并展示相关的图表和图形。
第29章 路径分析

;是否是少数民族为“0”、“1”变量,“1”表示“Yes”, 是少数民族,“0”表示“No”非少数民族。用出生日期 的年份数来计算出新变量年龄代替出生日期进行分
析。
§ 1.以“salary”为因变量
§ 操作步骤如下:
§ (1)单击“分析”|“回归”|“线性”命令,弹出图2912所示。“因变量”框中放入本次需要比较的变量 “salary”,把“educ”、“salbegin”、 “minority”“jobcat”“gender1”“prevexp”和“jobtime” 放入“自变量”,方法选择“进入”。
§ 2.“旧值和新值”按钮
§ 单击“旧值和新值”按钮,弹出图29-5所示的“旧 值和新值”对话框,此对话框可用于对目标变量 进行具体变量的转换。在“旧值”的“值”栏里输入 需要转换的目标变量“m”,“新值”的“值”中输入新 的值“1”,单击“添加”按钮,再以同样方法添加“f” 和“0”,单击“确定”按钮,即生成一个新的变量 “gender1”,如图29-6所示。
§ 、prevexp(Previous Experience,以前的工作经验 )、minority(是否是少数民族)等10个变量。 gender为属性变量,用“f ”表示female女性,“m ”表 示male男性;educ使用受教育的年数衡量;jobcat 分为三类:“1”表示clerical(文员),“2”代表 custodial(保管人员),以“3”表示manager(管理 人员)。当前工资和初始工资以实际额为准。已经
§ 以“job time”为因变量,“age”为自变量,输出结 果,其结果解释同上,此处不一一叙述。
§ 完成路径图
§ 根据以上6次回归的结果,6次输出的标准系数 即是路径系数(直接效果),我们可以完成模 型1的路径图,如图29-34所示。
毕业论文SPSS路径分析怎么做?案例解析详解

路径分析1、作用路径分析,一种基于线性回归方法、用于分析错综复杂变量之间路径关系的一种模型。
2、输入输出描述输入:变量对应的路径关系,一般要求输入数据为定量数据。
输出:各变量作用的路径关系或是否成立。
3、案例示例案例:研究“幸福感”的影响因素,有四个变量可能对幸福感有影响,他们分别是:经济水平、受教育程度、身体健康、情感支持。
通过路径分析可以得到这四个变量如图所示路径关系作用于幸福感。
4、案例数据模型要求为变量对应的路径关系,一般要求输入数据为定量数据(案例数据中为幸福度、经济水平、情感支持水平、身体健康水平、受教育程度),路径关系可以参考案例里的路径,这是由调查或者询问专家获得的。
5、案例操作Step1:新建分析;Step2:上传数据;Step3:选择对应数据打开后进行预览,确认无误后点击开始分析;Step4:选择【路径分析】;Step5:查看对应的数据数据格式,【路径分析】要求按照初步假设出模型中各变量的相互关系,绘制成一张清晰的路径分析图;Step6:点击【开始分析】,完成全部操作。
6、输出结果分析输出结果 1:模型路径图图表说明:上表展示了带权路径图,主要包括模型的标准化系数,用于分析路径影响关系情况。
输出结果 2:模型回归系数表图表说明:基于配对项经济水平->情感支持水平,显著性 P 值为 0.000***,水平上呈现显著性,则拒绝原假设,因此此路径有效,其影响系数为 0.489。
基于配对项受教育程度->情感支持水平,显著性 P 值为 0.016**,水平上呈现显著性,则拒绝原假设,因此此路径有效,其影响系数为-0.132。
基于配对项情感支持水平->幸福度,显著性 P 值为 0.025**,水平上呈现显著性,则拒绝原假设,因此此路径有效,其影响系数为 0.233。
基于配对项身体健康水平->幸福度,显著性 P 值为 0.000***,水平上呈现显著性,则拒绝原假设,因此此路径有效,其影响系数为-0.354。
路径分析

▪ 6.“统计量”按钮
▪ 单击“统计量”按钮,弹出图29-13所示的“统 计量”对话框,选择“描述性”,单击“继续 ”完成选择,回到线性回归对话框单击“确定 ”按钮即可计算回归系数。
实例详解
▪ 例29.1:我们采用SPSS软件系统自带的数据文件 Employee data.sav(可在SPSS软件的子目录下找 到该数据)来进行路径分析。该数据收录了474个员 工的人事工资资料,序号为434的缺失出生日期,所 以有效为473个,在接下来的分析中,剔除该样品; 该数据包含有:id(编码)、gender(性别)、 bdate(Date of Birth,出生日期)、educ( Educational Level,受教育水平)、jobcat( Employment Category,职位类别)、salary( Current Salary,目前工资)、salbegin(Beginning Salary,初始工资)、jobtime(Months since Hire ,已工作时间)
▪ 如果多个路径系数同时不显著,则首先删除最不显著的路径 继续进行回归分析,根据下一步的结果再决定是否需要删除 其它原因变量。
▪ 进行调试的一般原则,实际进行调试时,还必须考虑模型的 理论基础。
▪ 作为研究焦点的因果联系必须要有足够的理论根据,即使其 统计不显著,仍然应当加以仔细考虑,并寻找其统计不显著 的原因:是否是多重共线性的影响,还是其它路径假设的不 合理而影响了该路径的显著性。
▪ 、prevexp(Previous Experience,以前的工作经验 )、minority(是否是少数民族)等10个变量。 gender为属性变量,用“f ”表示female女性,“m ”表示male男性;educ使用受教育的年数衡量; jobcat分为三类:“1”表示clerical(文员), “2”代表custodial(保管人员),以“3”表示 manager(管理人员)。当前工资和初始工资以实
路径分析、结构方程讲义

路径分析的优势在于:它可以容纳多环节的因果结构,通过路径图把这 些因果关系很清楚地表示出来,据此进行更深层次的分析,如比较各种 因素之间的相对重要程度,计算变量与变量之间的直接与间接影响
例:某种消费性电子产品(如手机)路径分析:
四个变量耐用性、操作的简单性、通话效果和价格两两相 关,决定感知价值,同时通过感知价值决定忠诚度。相对 于图10-1,它具有两层的因果关系。
耐用性、操作的简单 性、通话效果和价格 即为外生变量
感知价值和顾客忠诚 度为内生变量
其他变量对内生变量的影响:若A直接通过单向箭头对B具有因果 影响,称A 对B有直接作用(direct effect);若A 对B的作用是间 接地通过其他变量(C)起作用,称A 对B有间接作用(indirect effect),称C为中间变量(mediator variable)。
这里,第一项p45为D对E的直接作用,第二项p24p25是前面尚未涉及的 分解内容,对应路径图,既找不到间接作用的路径链条,也找不到涉及相 关的路径,这一部分的原因是相关系数所涉及的两个变量D、E有一个共 同的作用因子B。由于B的存在,是得B的变化引起D、E的同时变化,而 使D、E的样本数据表现出相关关系,这种相关关系称为伪相关。很多情 况下均存在伪相关,特别是在一些混杂因子的影响中。
二、相关系数的分解
• 分解相关系数在路径分析中带有一般性意义,并且是路径分析中很重要 的一部分。通过对原因变量和结果变量的相关系数的分解,我们可以很 清楚地看出造成相关关系的各种原因。
例: A,B,C为三个两两相关的外生变量,A,B和残差项e4共同决定D, B,C,D和残差项e5决定E,最后,D,E和残差项e6影响最终结果变量F,共 具有三层的因果关系。
第29章 路径分析——【SPSS精品教程】

• 3.年龄转换
• 由于年龄比出生日期更简洁直观,我们把出生日期转换成年龄进 行分析,因为统计资料的时间不清楚,用现在时间计算并不影响 结果,所以算当下时间的年龄。
• 单击“转换”|“日期和时间向导”命令,弹出图29-7所示的对 话框,选择“使用日期和时间进行计算”选项,单击“下一步” 按钮,弹出图29-8所示的对话框,日期和时间向导第一步对话框。
Байду номын сангаас块解读
• 1.变量转换 • 因为性别为属性变量,我们无法对字串变量进行回归分析,所以
需要用转换功能将性别m(男)和f(女)转换分别成虚拟数字变 量1和0。 • 单击“转换”|“重新编码为不同变量”命令,弹出变量转换对 话框,如图29-4所示。“输出变量”框中“名称”栏输入一个新 的变量“gender1”,“标签”是“性别”,然后单击“更改”。
• 路径模型的假设条件和限制
• (1)首先要求模型中各变量的函数关系为线性、可加;否则不 能采用回归方法估计路径系数。如果处理变量之间的交互作用, 把交互项看作一个单独的变量,此时它与其它变量的函数关系同 样满足线性、可加。
• (2)模型中各变量均为等间距测度。
• (3)各变量均为可观测变量,并且各变量的测量不能存在误差
• 、prevexp(Previous Experience,以前的工作经验)、minority(是否 是少数民族)等10个变量。gender为属性变量,用“f ”表示female女 性,“m ”表示male男性;educ使用受教育的年数衡量;jobcat分为三 类:“1”表示clerical(文员),“2”代表custodial(保管人员),以 “3”表示manager(管理人员)。当前工资和初始工资以实际额为准。
【IBM-SPSS课件】路径分析

▪ 3.年龄转换
▪ 由于年龄比出生日期更简洁直观,我们把出生 日期转换成年龄进行分析,因为统计资料的时 间不清楚,用现在时间计算并不影响结果,所 以算当下时间的年龄。
▪ 单击“转换”|“日期和时间向导”命令,弹出 图29-7所示的对话框,选择“使用日期和时间 进行计算”选项,单击“下一步”按钮,弹出 图29-8所示的对话框,日期和时间向导第一步 对话框。
▪ 、prevexp(Previous Experience,以前的工作经验 )、minority(是否是少数民族)等10个变量。 gender为属性变量,用“f ”表示female女性,“m ”表示male男性;educ使用受教育的年数衡量; jobcat分为三类:“1”表示clerical(文员), “2”代表custodial(保管人员),以“3”表示 manager(管理人员)。当前工资和初始工资以实
结构关系,在多元回归的基础上计算变量间的相关 系数,计算结果给出的线性回归方程的标准系数( Standardized Coefficients)也就是我们需要的路径 系数。路径系数分为直接路径系数(某一自变量对 因变量的直接作用)和间接路径系数(该自变量通 过其他自变量对因变量的间接作用)两种。在一个 构造合适的路径图中,任何两个变量间的相关系数就 是连结这两点之间的所有复合链上的路径系数的乘 积之和
IBM-SPSS
路径分析
▪ 前面的多元回归分析常用于对影响因素的分 析,但由于只考察变量之间的直接作用,而实际上 变量之间的相关关系往往是一个复杂的传递过程, 因此需要一种可以全面地考察变量间的相互作用, 包括直接作用和间接作用的方法,即本章所介绍的 路径分析(通径分析)。
▪ 路径分析通过构建路径图直观地显示变量间的
SPSS操作方法:判别分析08——【SPSS精品教程 资源池】
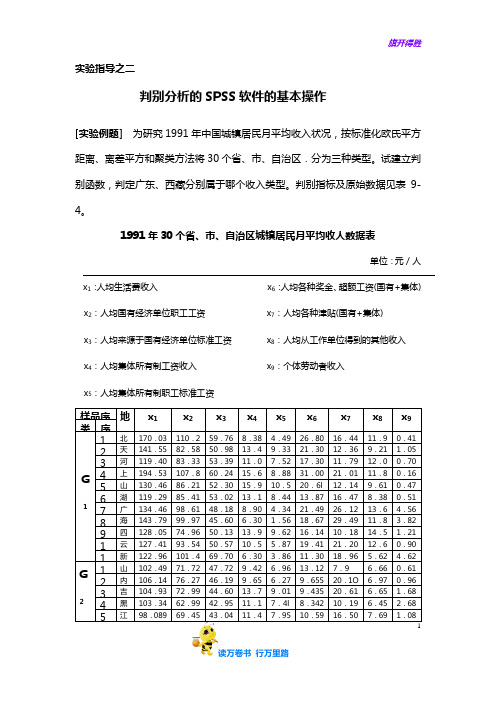
实验指导之二判别分析的SPSS软件的基本操作[实验例题]为研究1991年中国城镇居民月平均收入状况,按标准化欧氏平方距离、离差平方和聚类方法将30个省、市、自治区.分为三种类型。
试建立判别函数,判定广东、西藏分别属于哪个收入类型。
判别指标及原始数据见表9-4。
1991年30个省、市、自治区城镇居民月平均收人数据表单位:元/人x1:人均生活费收入x6:人均各种奖金、超额工资(国有+集体) x2:人均国有经济单位职工工资x7:人均各种津贴(国有+集体)x3:人均来源于国有经济单位标准工资x8:人均从工作单位得到的其他收入x4:人均集体所有制工资收入x9:个体劳动者收入x5:人均集体所有制职工标准工资贝叶斯判别的SPSS操作方法:1. 建立数据文件2.单击Analyze→Classify→Discriminant,打开Discriminant Analysis判别分析对话框如图1所示:图1 Discriminant Analysis判别分析对话框3.从对话框左侧的变量列表中选中进行判别分析的有关变量x1~x9进入1Independents 框,作为判别分析的基础数据变量。
从对话框左侧的变量列表中选分组变量Group进入Grouping Variable框,并点击Define Range...钮,在打开的Discriminant Analysis: Define Range对话框中,定义判别原始数据的类别数,由于原始数据分为3类,则在Minimum(最小值)处输入1,在Maximum(最大值)处输入3(见图2)。
选择后点击Continue按钮返回Discriminant Analysis 主对话框。
图2 Define Range对话框4、选择分析方法✧Enter independent together 所有变量全部参与判别分析(系统默认)。
本例选择此项。
✧Use stepwise method 采用逐步判别法自动筛选变量。
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
模块解读
• 1.变量转换 • 因为性别为属性变量,我们无法对字串变量进行回归分析,所以
需要用转换功能将性别m(男)和f(女)转换分别成虚拟数字变 量1和0。 • 单击“转换”|“重新编码为不同变量”命令,弹出变量转换对 话框,如图29-4所示。“输出变量”框中“名称”栏输入一个新 的变量“gender1”,“标签”是“性别”,然后单击“更改”。
• 6.“统计量”按钮
• 单击“统计量”按钮,弹出图29-13所示的“统计量”对话框, 选择“描述性”,单击“继续”完成选择,回到线性回归对话框 单击“确定”按钮即可计算回归系数。
实例详解
• 例29.1:我们采用SPSS软件系统自带的数据文件Employee data.sav(可 在SPSS软件的子目录下找到该数据)来进行路径分析。该数据收录了 474个员工的人事工资资料,序号为434的缺失出生日期,所以有效为 473个,在接下来的分析中,剔除该样品;该数据包含有:id(编码)、 gender(性别)、bdate(Date of Birth,出生日期)、educ (Educational Level,受教育水平)、jobcat(Employment Category,职 位类别)、salary(Current Salary,目前工资)、salbegin(Beginning Salary,初始工资)、jobtime(Months since Hire,已工作时间)
• 3.年龄转换
• 由于年龄比出生日期更简洁直观,我们把出生日期转换成年龄进 行分析,因为统计资料的时间不清楚,用现在时间计算并不影响 结果,所以算当下时间的年龄。
• 单击“转换”|“日期和时间向导”命令,弹出图29-7所示的对 话框,选择“使用日期和时间进行计算”选项,单击“下一步” 按钮,弹出图29-8所示的对话框,日期和时间向导第一步对话框。
回归的基础上计算变量间的相关系数,计算结果给出的线性回归方程 的标准系数(Standardized Coefficients)也就是我们需要的路径系数。 路径系数分为直接路径系数(某一自变量对因变量的直接作用)和间
接路径系数(该自变量通过其他自变量对因变量的间接作用)两种。 在一个构造合适的路径图中,任何两个变量间的相关系数就是连结这两 点之间的所有复合链上的路径系数的乘积之和
• 如果多个路径系数同时不显著,则首先删除最不显著的路径 继续进行回归分析,根据下一步的结果再决定是否需要删除 其它原因变量。
• 进行调试的一般原则,实际进行调试时,还必须考虑模型的 理论基础。
• 作为研究焦点的因果联系必须要有足够的理论根据,即使其 统计不显著,仍然应当加以仔细考虑,并寻找其统计不显著 的原因:是否是多重共线性的影响,还是其它路径假设的不 合理而影响了该路径的显著性。
• 4.计算当前年龄 • 在日期和时间向导第一步对话框中选择“计算两个日期之间的时
间数”,单击“下一步”弹出图29-9第二步对话框,把变量列表 中的“STIME”和“bdate”放入相应栏中,点开“单位”下拉取整”。
• 单击“下一步”按钮,弹出图29-10第三步对话框,在“结果变 量”栏里输入计算生成的新的变量名称“age”,“变量标签”
• 、prevexp(Previous Experience,以前的工作经验)、minority(是否 是少数民族)等10个变量。gender为属性变量,用“f ”表示female女 性,“m ”表示male男性;educ使用受教育的年数衡量;jobcat分为三 类:“1”表示clerical(文员),“2”代表custodial(保管人员),以 “3”表示manager(管理人员)。当前工资和初始工资以实际额为准。
已经工作的时间和以前的工作经验均以月为单位来衡量;是否是少数 民族为“0”、“1”变量,“1”表示“Yes”,是少数民族,“0”表 示“No”非少数民族。用出生日期的年份数来计算出新变量年龄代替 出生日期进行分析。
• (4)变量间的多重共线性程度不能太高,否则路径系数估计值 的误差将会很大。
• (5)需要有足够的样本量。Kline(1998)建议样本量的个数应 该是需要估计的参数个数的10倍(20倍更加理想)。
路径模型的调试,过程类似于多元回归过 程的调试
• 如果某一变量的路径系数(回归系数)统计性不显著,则考 虑是否将其对应的路径从模型中删去;
• 路径模型的假设条件和限制
• (1)首先要求模型中各变量的函数关系为线性、可加;否则不 能采用回归方法估计路径系数。如果处理变量之间的交互作用, 把交互项看作一个单独的变量,此时它与其它变量的函数关系同 样满足线性、可加。
• (2)模型中各变量均为等间距测度。
• (3)各变量均为可观测变量,并且各变量的测量不能存在误差
IBM-SPSS
第29章 路径分析
• 前面的多元回归分析常用于对影响因素的分析,但由于只考察变 量之间的直接作用,而实际上变量之间的相关关系往往是一个复杂 的传递过程,因此需要一种可以全面地考察变量间的相互作用,包 括直接作用和间接作用的方法,即本章所介绍的路径分析(通径分 析)。
• 路径分析通过构建路径图直观地显示变量间的结构关系,在多元
栏中输入“年龄”给新的变量加上标签,单击“完成”即可生成 一个新的变量,如图29-11所示。
• 5.计算路径系数 • 单击“分析”|“回归”|“线性”命令,弹出线性回归对话框,
如图29-12所示。“因变量”框中放入本次需要比较的变量 “salary”,把要比较的八个因素“educ”、“salbegin”、 “minority”“jobcat”“gender1”“prevexp”和“jobtime”放 入“自变量”框中,方法选择“进入”。
• 2.“旧值和新值”按钮
• 单击“旧值和新值”按钮,弹出图29-5所示的“旧值和新值”对 话框,此对话框可用于对目标变量进行具体变量的转换。在“旧 值”的“值”栏里输入需要转换的目标变量“m”,“新值”的 “值”中输入新的值“1”,单击“添加”按钮,再以同样方法 添加“f”和“0”,单击“确定”按钮,即生成一个新的变量 “gender1”,如图29-6所示。