ENDF数据库介绍
数据库三大范式的理解

数据库三大范式的理解一、数据库三大范式数据库三大范式(Database Normalization)是由 Edgar F. Codd 博士提出的三个范式,用于保护数据的完整性和准确性,确保数据的有效管理。
这三个范式分别是:1NF(一级范式)、2NF(二级范式)和3NF(三级范式)。
1.1NF(一级范式)--字段内不可再分割1NF(一级范式)是最低级的形式,也是一个表最基本的要求,要求每一个属性或字段都是不可分割的原子值,也就是说,每一个字段里只能存储一个完整的数据项,且不可再分割。
1.2NF(二级范式)--具有唯一标识性的字段2NF(二级范式)要求表中的实体不能有重复项,也就是说,每条记录都必须具有唯一标识性的字段,这个字段可以用作主键(Primary Key),主键是由一个或多个字段组成的字段,是唯一性的。
1.3NF(三级范式)--非主属性完全依赖于主属性3NF(三级范式)要求每一个非主属性(Non-prime Attribute)都只和一个主属性(Prime Attribute)相关,也就是说,非主属性必须完全依赖于主属性,而不能有其他的依赖关系。
在3NF的要求下,一个表中的属性必须都是原子值,即一个表中只能存储完整的数据项。
二、数据库三大范式的优点1.避免数据冗余采用数据库三大范式的优点之一就是避免数据冗余,以节省磁盘存储空间,减少系统对数据的查询,更新操作,以及维护完整性所需的开销。
2.减少数据的插入、删除、更新错误使用数据库三大范式可以减少数据插入、删除、更新错误。
一个表中的字段必须是原子值,即一个表中只能存储完整的数据项,从而避免多个表之间互相依赖及冗余带来的信息不准确的问题。
3.增强数据的可靠性使用数据库三大范式可以明确定义表、字段,以及定义每个字段的类型。
这样可以提高数据的可靠性,保证数据的准确性和完整性。
4.简化和统一系统设计数据库三大范式将表的设计规范化,使表之间的设计具有一致性,从而简化和统一系统设计。
基本农田划定数据库标准2017版
第一部分 总体说明
为统一各业务管理部门永久基本农田数据,规范永久基本农田建库工作,推动永久基 本农田管理信息化建设,在考虑到永久基本农田数据库与第二次全国土地调查基本农田上图 成果、土地利用总体规划数据库基本农田数据相衔接,以及实现永久基本农田数据的日常管 理维护和年度更新功能需求基础上,遵循《基本农田划定技术规程》(TD/T1032-2011)(以 下简称《规程》)的基本要求,对《基本农田数据库标准》(TD/T1019-2009)(以下简称《标 准》)的部分内容进行了调整补充,于 2013 年 8 月,形成了《基本农田数据库标准》(调整试 行版)。2017 年 1 月,根据永久基本农田划定新要求,调整试版进行了再次调整完善,形 成《永久基本农田数据库标准》(2017 版)。
基本农田质检软件(V1.5)修改说明 (2017-01-18)
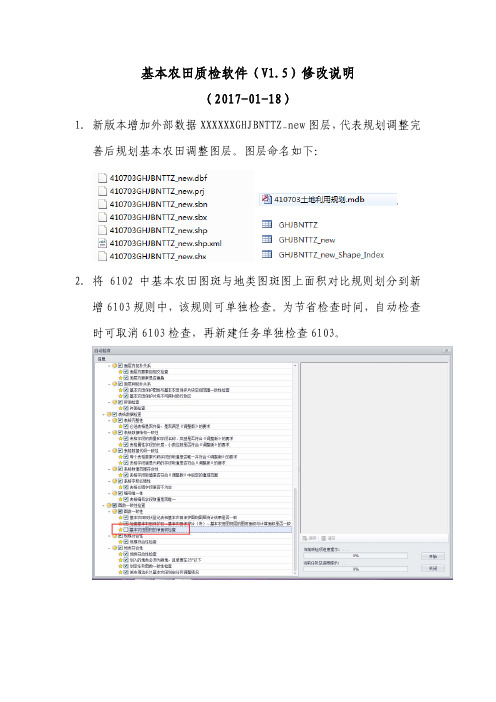
1. 新版本增加外部数据 XXXXXXGHJBNTTZ_new 图层,代表规划调整完 善后规划基本农田调整图层。图层命名如下:
2. 将 6102 中基本农田图斑与地类图斑图上面积对比规则划分到新 增 6103 规则中,该规则可单独检查。为节省检查时间,自动检查 时可取消 6103 检查,再新建任务单独检查 6103。
2 《2017 版》针对《调整试行版》调整内容
本 2017 版在试行过程中,发现部分内容不适应实际数据库建设需求,调整如下: (1) 基本农田保护片(块)扩展属性表对三个字段代码进行调整,包括:“组可调整人工
牧草地”字段代码调整为“ZKTZMCDMJ”;“组城镇村及工矿用地”字段代码调整为 “ZCZCGKYDMJ”;“组水域及水利设施用地” 字段代码调整为“ZSYJSLYDMJ”。 基本农田保护片(块)属性(保护责任)扩展表中,“组农户个数”字段长度由“2” 修改为“3”。 (2) 基本农田划入划出属性表中增加“标识码”字段,将“耕地面积”字段值域由“>0” 修改为“≥0”; (3) 基本农田保护区、基本农田保护片(块)属性结构表中,“耕地面积”字段值域由“>0” 修改为“≥0”;基本农田保护片(块)属性(保护责任)扩展表中,“组耕地面积” 字段值域由“>0”修改为“≥0”。基本农田现状登记表中,“耕地面积”字段值域由 “>0”修改为“≥0”。 (4)表 15“基本农田图斑属性(土地质量)扩展表结构(属性表名:JBNTBHTBZL)”中, 删除“利用等”字段,并将“有机质含量”、“土壤质地”、“耕作层厚度”、“标准耕作
数据库五大范式详解

第一范式(1NF)第一范式,强调属性的原子性约束,要求属性具有原子性,不可再分解。
举个例子,活动表(活动编码,活动名称,活动地址),假设这个场景中,活动地址可以细分为国家、省份、城市、市区、位置,那么就没有达到第一范式。
第二范式(2NF)第二范式,强调记录的唯一性约束,表必须有一个主键,并且没有包含在主键中的列必须完全依赖于主键,而不能只依赖于主键的一部分。
举个例子,版本表(版本编码,版本名称,产品编码,产品名称),其中主键是(版本编码,产品编码),这个场景中,数据库设计并不符合第二范式,因为产品名称只依赖于产品编码。
存在部分依赖。
所以,为了使其满足第二范式,可以改造成两个表:版本表(版本编码,产品编码)和产品表(产品编码,产品名称)。
第三范式(3NF)第三范式,强调属性冗余性的约束,即非主键列必须直接依赖于主键。
举个例子,订单表(订单编码,顾客编码,顾客名称),其中主键是(订单编码),这个场景中,顾客编码、顾客名称都完全依赖于主键,因此符合第二范式,但是顾客名称依赖于顾客编码,从而间接依赖于主键,所以不能满足第三范式。
为了使其满足第三范式,可以拆分两个表:订单表(订单编码,顾客编码)和顾客表(顾客编码,顾客名称),拆分后的数据库设计,就可以完全满足第三范式的要求了。
值得注意的是,第二范式的侧重点是非主键列是否完全依赖于主键,还是依赖于主键的一部分。
第三范式的侧重点是非主键列是直接依赖于主键,还是直接依赖于非主键列。
修正的第三范式(BCNF)修正的第三范式,是防止主键的某一列会依赖于主键的其他列。
举个例子,每个管理员只能管理一个仓库,那么如果设计库存表(仓库名,管理员名,商品名,数量),主键为(仓库名,管理员名,商品名),这是满足前面三个范式的,但是仓库名和管理员名之间存在依赖关系,因此删除某一个仓库,会导致管理员也被删除,因此设计不合理。
第四范式(4NF)当一个表中的非主属性相互独立时(3NF),这些非主属性不应该有多值。
数据库范式 通俗讲解

数据库范式通俗讲解
数据库范式是一种设计数据库表结构的方法,旨在消除数据冗余并提高数据存储的效率。
通俗来讲,数据库范式就是一种规范,它告诉我们如何把数据存储在数据库中,以便更好地组织和管理数据。
数据库范式通常分为不同的级别,即第一范式(1NF)、第二范式(2NF)、第三范式(3NF)等。
每个级别都有其特定的规则和要求,用于确保数据库表的结构合理且数据不会重复存储。
第一范式要求每个数据表中的每一列都是不可再分的原子值,不可再分的意思是不能再分解为更小的数据单元。
这样可以避免数据冗余和复杂的数据结构。
第二范式要求数据表中的非主键列完全依赖于主键,即非主键列必须完全依赖于主键,而不是部分依赖。
这样可以确保数据表中的数据结构更加清晰和简洁。
第三范式要求数据表中的每一列都与主键直接相关,而不是与其他非主键列相关。
这样可以进一步减少数据冗余,提高数据的一
致性和完整性。
总的来说,数据库范式的目标是通过合理的数据表设计,减少数据冗余,提高数据存储和检索的效率,确保数据的一致性和完整性。
然而,有时候过度范式化也可能导致查询性能下降,因此在实际应用中需要根据具体情况进行权衡和调整。
简述数据库设计3个范式的含义

数据库设计是指按照特定的规范和要求,对数据库的数据存储和管理进行规划和设计的过程。
数据库设计的三个范式是指数据库设计中的基本规范,其中第一范式(1NF)、第二范式(2NF)和第三范式(3NF)分别规定了数据库中的数据应该满足的标准和要求。
下面我们将简要介绍数据库设计的三个范式的含义。
一、第一范式(1NF)1. 第一范式是指数据库表中的所有字段都是不可再分的最小单元,即每个数据项都是不可再分的,不能再被分割为更小的数据项。
2. 数据库表中的每一列都是单一的值,不可再分。
3. 所有的字段都应该是原子性的,即不能再分。
4. 如果数据库表中的字段不满足第一范式的要求,就需要进行适当的调整和修改,使之满足第一范式的要求。
二、第二范式(2NF)1. 第二范式是指数据库表中的所有非主属性都完全依赖于全部主键。
2. 所谓主属性是指唯一标识一个记录的属性,而非主属性是指与主键相关的其他属性。
3. 如果一个表中的某些字段与主键没有直接关系,而是依赖于其他字段,则需要将这些字段拆分到另一个表中。
4. 通过将非主属性与主键分离,可以避免数据冗余和更新异常。
5. 第二范式要求数据库表中的数据项应该是唯一的,不可再分,且完全依赖于全部主键。
三、第三范式(3NF)1. 第三范式是指数据库表中的所有字段都不依赖于其他非主字段。
2. 也就是说,一个表中的字段之间应该相互独立,不应该存在字段之间的传递依赖关系。
3. 如果一个字段依赖于其他非主字段,则应该将其拆分到另一张表中,以避免数据冗余和更新异常。
4. 第三范式要求数据库表中的字段之间应该是独立的,不应该存在传递依赖关系。
数据库设计的三个范式分别规范了数据库表中数据的原子性、依赖性和独立性。
遵循这些范式可以有效地减少数据冗余和更新异常,提高数据库的数据完整性和稳定性。
在进行数据库设计时,设计人员应该严格遵循这些范式的要求,以确保数据库的高效性和可靠性。
众所周知,数据库设计的三个范式是设计和维护关系型数据库时非常重要的标准和指导原则。
数据库范式名词解释

数据库范式名词解释
数据库范式是数据库设计中的一种理论,它基于离散数学中的知识,主要为了解决数据存储和优化的问题。
其核心目标是为了减少数据冗余,提高数据的一致性和完整性。
范式包括六种,从低到高依次是:第一范式(1NF)、第二范式(2NF)、第三范式(3NF)、巴斯-科德范式(BCNF)、第四范式(4NF)和第五范式(5NF,又称完美范式)。
其中,满足最低要求的范式是第一范式(1NF)。
第一范式(1NF)要求在关系模型中,所有的域都应该是原子性的,即数据库表的每一列都是不可分割的原子数据项,而不能是集合、数组、记录等非原子数据项。
如果实体中的某个属性有多个值时,必须拆分为不同的属性。
在符合第一范式(1NF)的表中,每个域值只能是实体的一个属性或一个属性的一部分。
简而言之,第一范式就是无重复的域。
数据库范式的主要作用是解决关系数据库中数据冗余、更新异常、插入异常、删除异常问题。
通过应用数据库范式,可以避免数据冗余,减少数据库的存储空间,并降低维护数据完整性的成本。
数据库范式是关系数据库核心的技术之一,也是从事数据库开发人员必备知识。
数据库范式(1NF2NF3NFBCNF)详解

数据库的设计范式是数据库设计所需要满足的规范,满足这些规范的数据库是简洁的、结构明晰的,同时,不会发生插入(insert)、删除(delete)和更新(update)操作异常。
反之则是乱七八糟,不仅给数据库的编程人员制造麻烦,而且面目可憎,可能存储了大量不需要的冗余信息。
范式说明第一范式(1NF)无重复的列所谓第一范式(1NF)是指数据库表的每一列都是不可分割的基本数据项,同一列中不能有多个值,即实体中的某个属性不能有多个值或者不能有重复的属性。
如果出现重复的属性,就可能需要定义一个新的实体,新的实体由重复的属性构成,新实体与原实体之间为一对多关系。
在第一范式(1NF)中表的每一行只包含一个实例的信息。
简而言之,第一范式就是无重复的列。
说明:在任何一个关系数据库中,第一范式(1NF)是对关系模式的基本要求,不满足第一范式(1NF)的数据库就不是关系数据库。
例如,如下的数据库表是符合第一范式的:字段1 字段2 字段3 字段4而这样的数据库表是不符合第一范式的:字段1 字段2 字段3 字段4字段字段数据库表中的字段都是单一属性的,不可再分。
这个单一属性由基本类型构成,包括整型、实数、字符型、逻辑型、日期型等。
很显然,在当前的任何关系数据库管理系统(DBMS)中,傻瓜也不可能做出不符合第一范式的数据库,因为这些DBMS不允许你把数据库表的一列再分成二列或多列。
因此,你想在现有的DBMS中设计出不符合第一范式的数据库都是不可能的。
第二范式(2NF)属性完全依赖于主键[ 消除部分子函数依赖]如果关系模式R为第一范式,并且R中每一个非主属性完全函数依赖于R的某个候选键,则称为第二范式模式。
第二范式(2NF)是在第一范式(1NF)的基础上建立起来的,即满足第二范式(2NF)必须先满足第一范式(1NF)。
第二范式(2NF)要求数据库表中的每个实例或行必须可以被惟一地区分。
为实现区分通常需要为表加上一个列,以存储各个实例的惟一标识。
finalreport基因组数据格式介绍

finalreport基因组数据格式介绍摘要:一、引言二、基因组数据格式概述1.基因组数据的基本组成2.常见的基因组数据格式三、FASTA 格式1.FASTA 格式的特点2.FASTA 格式的应用场景四、GenBank 格式1.GenBank 格式的特点2.GenBank 格式的应用场景五、FASTQ 格式1.FASTQ 格式的特点2.FASTQ 格式的应用场景六、SAM 格式1.SAM 格式的特点2.SAM 格式的应用场景七、BED 格式1.BED 格式的特点2.BED 格式的应用场景八、结论正文:一、引言随着基因组学研究的发展,基因组数据在生物信息学领域中占据越来越重要的地位。
对于这些庞大的基因组数据,我们需要一种合适的格式进行存储和传输。
本文将对基因组数据格式进行介绍,并重点分析几种常见的格式。
二、基因组数据格式概述基因组数据通常包括序列数据和注释信息。
序列数据可以是DNA、RNA 或蛋白质序列,而注释信息包括基因注释、转录因子结合位点、调控元件等。
为了方便存储和传输这些数据,科学家们制定了许多基因组数据格式。
三、FASTA 格式FASTA 格式是一种常用于表示核酸或蛋白质序列的文本格式。
它以简单的文本形式存储序列数据,易于阅读和编辑。
FASTA 格式的主要特点包括:每行包含一个序列,序列之间以空行分隔;序列中的碱基或氨基酸用单个字符表示;对于核酸序列,碱基T 在文件中用字母"U"表示。
FASTA 格式适用于序列数据的初稿存储和传输。
四、GenBank 格式GenBank 格式是一种二进制格式,主要用于存储基因组序列和相关的注释信息。
GenBank 文件通常包含多个序列,每个序列都由独立的记录组成。
每个记录包括序列标识符、物种信息、序列长度、核酸类型、存放位置等信息。
GenBank 格式适用于基因组数据的长期存储和分布式共享。
五、FASTQ 格式FASTQ 格式是一种用于表示高通量测序数据的文本格式。
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
不同温度、不同核素都有单独的ACE格式数据文件
提供的核数据全面
能量框架1e-5eV~20MeV 各种核反应的微观截面(n,f ),(n,n),(n,p)… 弹性/非弹性散射中子的角分布 裂变中子产额和能谱 裂变产物的产额、微观截面和衰变常数 慢化材料热中子散射律数据
裂变nu数据位置
JXS(13)
JXS(3)
MT数组位置
JXS(14)
JXS(4)
Q值数组位置
JXS(15)
JXS(5)
反应类型数组位置
JXS(16)
JXS(6)
截面值指针表位置
JXS(17)
JXS(7)
截面值表位置
JXS(18)
JXS(8)
角分布数据指针表位置
JXS(19)
JXS(9)
角分布数据位置
7. 457970 92235 38623 42 39 33 0 0
8. 0 0 0 0 0 0 0 0 9. 1 193116 193439 193481 193523 193565
193607 315950 10. 315990 362436 362475 415953 454576
454609 454642 455894 11. 455927 455927 455960 457967 193700
XSDIR文件中的数据分为三个部分:
第一部分是该文件的存储路径
告知文件如果不在默认目录的话,该如何找到文件
第二部分是原子质量比
原子质量与中子质量之比
第三部分列出了所有存在的数据表
ZAID标识
在了解了索引文件XSDIR的结构以后,就可以定位所 需要的数据表了。比如,如果想查找铀235,在XSDIR 中找到:
457970 414253 0
12. 0 0 0 0 0 0 0 0
从第7行开始的两行是NXS数组的16个数,接下来 的四行是JXS数组的32个数,它们是从数据表正确 读取数据的关键。
NXS数组(第7-8行)
数组数据 长度
NXS(2)
ZA=1000×Z+A
NXS(3)
92235.60c|233.025000|endf601|0|1|1716788|289975|0|0|2.5300E-08
从它可以了解到该数据文件位于文件endf601中,起 始行位于第1716788行,对应的温度是2.5300E08MeV,数据表格式为1,等等。
4. ACE格式数据表结构
通过MCNP数据库的XSDIR索引文件,我们可以找到 每个核素对应温度下的数据表。每个数据表包括三个 数组:
中。
LSIG SIG LAND AND
含有除弹性散射外所有中子反应的截 面数据的位置指针。
含有除弹性散射外所有中子反应的截 面数据。
含有所有产生二次中子反应的角分布 数据的位置指针。
含有所有产生二次中子反应的角分布 数据。
NXS(4)不为0时存在。
NXS(4)不为0时存在。 NXS(4)不为0时存在。
MTR LQR
含有除了弹性散射外所 所有拥有除弹性散射外
有中子反应的ENDF/B MT 其它反应的核素(NXS(4)
数。
不为0)均存在。
含有除了弹性散射外所 有中子反应的Q值。
NXS(4)不为0时存在。
XSS数组-续
TYR
含有除弹性散射外所有中子反应类型 的信息,包括:二次中子数目以及二次中 子角分布是在实验室参照系中还是质心系
NXS数组含有特定的计数、标记 JXS数组含有各种数据位置指针 XSS数组依次存放对应核数据
同一个数据表中,NXS数组和JXS数组分别有16和32个 数据。而XSS数组的大小各核素各不相同。
对于每个数据表来说,其初始的12行数据都 是固定格式的,以endf601数据文件中铀235 数据表为例,前12行数据如下:
1. 92235.63c 233.025000 2.5335E-08 12/23/05 2. 2003(0) from ENDFB-6.8 njoy99 mat9228 3. 0 0. 0 0. 0 0. 0 0. 4. 0 0. 0 0. 0 0. 0 0. 5. 0 0. 0 0. 0 0. 0 0. 6. 0 0. 0 0. 0 0. 0 0.
能量框架的能量点数目
NXS(4) NXS(5)
除弹性散射外的反应数目 除弹性散射外有二级中子的反应 数目
NXS(6)
产生光子的反应数目
注:NXS数组其余10个数据暂时并没有使用,为将来可 能的扩展留下了余地
JXS数组(第9-12行)
数组 数据
具体含义
数组 数据
JXS(1)
能量表位置
JXS(12)
JXS(2)
JXS(20)
JXS(10)
能量分布数据指针表位置
JXS(21)
JXS(11)
能量分布数据表位置
JXS(22)
具体含义
光子产生数据表位 置
光子产生MT数组位 置
光子产生反应截面 数据指针表位置 光子产生反应截面
数据表位置 光子产生角分布数 据指针表位置 光子产生角分布数
据表位置 光子产生能量分布 数据指针表位置 光子产生能量分布
数据表位置
屈服倍数数据位置
总裂变截面数据位 置
表的最后一个字的
XSS数组
数据块名称
数据块内容
补充说明
ESZ
整个能量框架以及总截 面、总吸收截面、弹性截 面和平均热数数据。总存
在。
能量范围大多从1e11MeV到20MeV,数据点
为几百或几万个点不等
NU
J次XS裂只(包2有变)含不可二瞬为裂次时0变中的和核子核/或素平素总(均)的即数存每。在。量给给点出出此都一一数按些个据系系能对有数数量应两计然框的种算后架形每,值式个及;:能其21))
工物研3 黄世恩
1.ENDF数据库简介
ENDF(Evaluated Nuclear Data File) 包括ENDF/A、ENDF/B 包含反应堆物理和屏蔽设计所需的核数据 专门处理程序-NJOY 由美国国家核数据中心(NNDC)负责维护 ENDF/B-6.8
2.ENDF/B库数据存放格式
3. 数据表索引文件XSDIR
ENDF/B数据库中每个特定核素的数据表都是从XSDIR 目录文件开始的。每个核素都以一个ZAID来识别。 ZAID的通用格式是ZZZAAA.nnX,其中:
ZZZ是原子序数
AAA是原子量
nn是评价库的识别符,X代表数据的类型
比如92235.63C代表的是U235的连续能量中子与物质作 用数据,其数据来源是编号63对应的ENDFB-6.8库