PaxosRaft 分布式一致性算法原理剖析及其在实战中的应用
PaxosRaft分布式一致性算法原理剖析及其在实战中的应用

PaxosRaft分布式一致性算法原理剖析及其在实战中的应用一、Paxos算法原理剖析Paxos算法是由Leslie Lamport于1989年提出的,它解决了分布式系统中的一致性问题。
Paxos算法通过引入提议者(proposer)、接受者(acceptor)和学习者(learner)三种角色来实现一致性。
基本流程如下:1.提议者向接受者发送提案,接受者可以接受或拒绝提案。
2.如果大多数接受者接受了提案,那么提案被批准。
3.提议者将批准的提案发送给学习者,学习者学习到最新的提案。
二、Paxos算法的实战应用1. 分布式数据库:Paxos算法可以用来保证分布式数据库的一致性。
通过Paxos算法,可以确保多个节点之间在进行数据写入操作时达成一致,从而避免数据的冲突和不一致。
2. 分布式锁:Paxos算法可以用来实现分布式锁的一致性。
通过Paxos算法,可以保证在多个节点之间只有一个节点能够获得锁,从而保证数据的一致性和并发操作的正确性。
3. 分布式文件系统:Paxos算法可以用来实现分布式文件系统的一致性。
通过Paxos算法,可以确保多个节点之间在进行文件写入操作时达成一致,从而避免文件的冲突和不一致。
三、Raft算法原理剖析Raft算法是由Diego Ongaro和John Ousterhout于2024年提出的,它是一种相对于Paxos算法更易理解和实现的一致性算法。
Raft算法将一致性问题分解成了领导选举、日志复制和安全性三个子问题,并通过角色分离和日志复制的方式来解决这些问题。
Raft算法的基本角色包括领导者(leader)、跟随者(follower)和候选者(candidate)。
基本流程如下:1.初始状态下,所有节点都是跟随者。
2.当跟随者接收到来自候选者或领导者的请求时,它会根据一定的规则来更新自己的状态。
3.当跟随者的选举定时器超时时,它会成为候选者,并发起选举。
4.候选者向其他节点发送投票请求,其他节点根据一定的规则来决定是否投票给候选者。
分布式一致性算法

分布式一致性算法分布式一致性是指在分布式系统中,多个节点之间保持数据一致的性质。
在分布式系统中,由于节点之间的网络延迟、节点故障、并发操作等原因,可能导致数据的不一致性。
因此,为了保证数据的一致性,需要设计一些分布式一致性算法。
基于副本的一致性算法是通过复制数据副本到多个节点上,并通过协调副本之间的更新操作来实现一致性。
其中,最经典的算法是Paxos算法和Raft算法。
Paxos算法是一种经典的分布式一致性算法,它采用一个由多个节点组成的集群来保证数据的一致性。
Paxos算法通过选举一个Leader节点来协调所有节点的操作。
当一个节点想要更新数据时,必须先向Leader 节点发送Propose请求,Leader节点会将该请求广播给其他节点进行确认,确认通过后,Leader节点将该更新操作提交给所有节点执行,从而保持所有节点的数据一致性。
Raft算法是一种相对简单的分布式一致性算法,它也是通过复制数据副本和协调节点之间的操作来实现一致性。
Raft算法将集群分为Leader节点、Follower节点和Candidate节点。
Leader节点负责处理所有客户端的请求并向其他节点发送心跳消息。
如果Leader节点宕机,其他节点会通过选举产生新的Leader节点。
Raft算法通过Leader节点的选举机制,以及日志的复制和提交来保证数据的一致性。
基于事务的一致性算法是通过保证事务的ACID特性来实现分布式一致性。
ACID是指原子性、一致性、隔离性和持久性。
最经典的基于事务的一致性算法是两阶段提交(2PC)算法和三阶段提交(3PC)算法。
两阶段提交(2PC)算法是一种分布式事务协议,它分为准备阶段和提交阶段。
在准备阶段,协调者节点会询问所有参与者节点是否可以提交事务,并收集所有参与者节点的投票结果。
如果所有参与者节点都同意提交事务,则进入提交阶段,协调者节点向所有参与者节点发送提交请求,参与者节点接收到提交请求后执行事务提交操作。
常见的分布式算法

常见的分布式算法分布式算法是一种能够处理大规模分布式系统的算法。
随着云计算和大数据的不断发展,分布式算法也逐渐成为了计算机科学领域的热门研究方向。
本文将介绍几种常见的分布式算法。
1. Paxos算法Paxos算法是一种用于解决分布式一致性问题的经典算法。
它能够确保在一个分布式环境中,多个进程能够达成一致的决策,即使发生网络故障或进程崩溃等异常情况。
Paxos算法被广泛应用于分布式数据库、分布式文件系统等领域。
2. Raft算法Raft算法是一种新兴的分布式一致性算法,它与Paxos算法类似,但更易于理解和实现。
Raft算法的设计目标是使分布式系统的可理解性更高,从而降低系统实现和维护的难度。
因此,Raft算法在近年来得到了广泛的关注和应用。
3. MapReduce算法MapReduce算法是一种用于处理大规模数据的分布式算法。
它通过将大规模数据分解成多个小数据块,并将这些数据块分散到多个计算机节点上进行并行计算,从而实现高效的数据处理。
MapReduce算法被广泛应用于搜索引擎、数据仓库等领域。
4. Gossip算法Gossip算法是一种用于分布式信息传播的算法。
它通过模拟人类社交网络中的信息传播行为,实现分布式节点之间的信息传输和共享。
Gossip算法在分布式系统中具有很高的可扩展性和容错性,因此在云计算、分布式数据库等领域得到了广泛应用。
总之,分布式算法是一种非常重要的计算机科学研究方向,它能够提高分布式系统的可扩展性、可靠性和性能。
通过学习和应用以上几种常见的分布式算法,我们可以更好地理解和应用分布式系统,从而促进分布式计算的发展。
分布式一致性算法

分布式一致性算法在计算机系统中,分布式一致性是指在分布式系统的多个节点上保持数据或计算结果的一致性。
由于分布式系统中节点的不稳定性和网络的不可靠性,实现分布式一致性变得非常具有挑战性。
为了解决这个问题,人们提出了许多分布式一致性算法。
一致性算法是指通过协调各个节点之间的操作,使得分布式系统中的数据在逻辑上是一致的。
下面将介绍几个常见的分布式一致性算法。
1.基于主从复制的一致性算法:这种算法中有一个主节点和多个从节点。
主节点负责处理写操作,并将结果传播给从节点进行更新。
当有读操作时,客户端可以从主节点或者从节点读取数据。
这种算法的优点是简单直接,但是主节点的单点故障可能导致整个系统不可用。
2. 基于Paxos算法的一致性算法:Paxos算法是一种分布式一致性算法,主要用于解决一致性协议的问题。
它通过选择一个决策提案并将其传播给其他节点来实现一致性。
Paxos算法具有高效、可扩展和容错性强的特点,可以在分布式系统中实现一致性。
3. 基于Raft算法的一致性算法:Raft算法是一种相对较新的分布式一致性算法,与Paxos算法类似,它也可以用于解决一致性协议的问题。
Raft算法将分布式系统分为多个节点,其中有一个领导者节点和多个跟随者节点。
领导者节点负责接收来自客户端的操作,并将其进行复制和传播给其他节点。
如果领导者节点故障,其他节点将通过选举新的领导者节点来维持一致性。
4.基于链式复制的一致性算法:这种算法中,多个节点以链条形式连接起来,每个节点负责将接收到的操作复制给下一个节点。
当链中的节点都接收到相同的操作后,一致性就得以实现。
这种算法的优点是简单可靠,但是链中的节点过多可能导致延迟增加。
总结来说,分布式一致性算法在保持系统一致性的过程中会面临节点故障、网络故障和并发操作等问题。
不同的算法适用于不同的场景,需要根据具体的应用需求来选择合适的一致性算法。
为了提高系统的可靠性和性能,还可以通过增加冗余节点、优化网络通信和增加并发处理能力等手段来改善分布式一致性。
分布式一致性协议Raft原理与实例

分布式一致性协议Raft原理与实例Raft是一种用于分布式系统中实现一致性的协议,它是一种相对较新的协议,相比于传统的Paxos算法,Raft更加易于理解和实现。
本文将介绍Raft协议的原理和一个实例。
一、Raft协议的原理Raft协议将一致性问题分为三个关键的子问题:领导选举、日志复制和安全性。
下面分别介绍这三个子问题的解决方案。
1.领导选举:在Raft协议中,时间被划分为多个连续的任期。
每个任期都有一个唯一的领导者。
在每个任期开始时,所有节点都是候选者状态,它们向其他节点发送选举请求。
当一个候选者收到了大多数节点的选票时,它就成为了领导者。
候选者在选举超时时间内没有收到足够的选票时,会触发新一轮的选举。
2.日志复制:一旦选出了领导者,它就可以接收来自客户端的请求,并将这些请求作为日志条目追加到自己的日志中。
领导者将这些日志条目发送给其他节点,然后等待大多数节点确认收到。
一旦领导者收到大多数节点的确认,它就可以提交这些日志条目,并将结果返回给客户端。
3.安全性:Raft协议通过使用递增的索引号来标识日志条目,并通过比较两个日志条目的索引号和任期来判断它们的顺序。
当一个节点接收到一个包含更大索引号的日志条目时,它会将自己的日志截断到这个索引号,并且将这个日志条目追加到自己的日志中。
二、Raft协议的实例为了更好地理解Raft协议的工作原理,下面将介绍一个简单的Raft协议实例。
假设有一个由5个节点组成的Raft集群,它们分别是A、B、C、D和E。
开始时,所有节点都是候选者状态,并且它们的任期都是0。
节点A在任期0的选举中获得了大多数选票,成为了领导者。
客户端向领导者节点A发送一个写请求,这个请求包含一条日志条目。
领导者将这个日志条目追加到自己的日志中,并将这个日志条目发送给其他节点。
其他节点收到这个日志条目后,将其追加到自己的日志中,并返回确认给领导者。
当领导者收到大多数节点的确认后,它将这个日志条目提交,并将结果返回给客户端。
分布式一致性算法Paxos、Raft、Zab的区别与联系
分布式⼀致性算法Paxos、Raft、Zab的区别与联系什么是分布式系统?拿⼀个最简单的例⼦,就⽐如说我们的图书管理系统。
之前的系统包含了所有的功能,⽐如⽤户注册登录、管理员功能、图书借阅管理等。
这叫做集中式系统。
也就是⼀个⼈⼲了好⼏件事。
后来随着功能的增多,⽤户量也越来越⼤。
集中式系统维护太⿇烦,拓展性也不好。
于是就考虑着把这些功能分开。
通俗的理解就是原本需要⼀个⼈⼲的事,现在分给n个⼈⼲,各⾃⼲各⾃的,最终取得和⼀个⼈⼲的效果⼀样。
稍微正规⼀点的定义就是:⼀个业务分拆多个⼦业务,部署在不同的服务器上。
然后通过⼀定的通信协议,能够让这些⼦业务之间相互通信。
既然分给了n个⼈,那就涉及到这些⼈的沟通交流协作问题。
想要去解决这些问题,就需要先聊聊分布式系统中的CAP理论。
CAP原理CAP原理指的是⼀个分布式系统最多只能同时满⾜⼀致性(Consistency)、可⽤性(Availability)和分区容错性(Partition tolerance)这三项中的两项。
这张图不知道你之前看到过没,如果你看过书或者是视频,这张图应该被列举了好⼏遍了。
下⾯我不准备直接上来就对每⼀个特性进⾏概述。
我们先从案例出发逐步过渡。
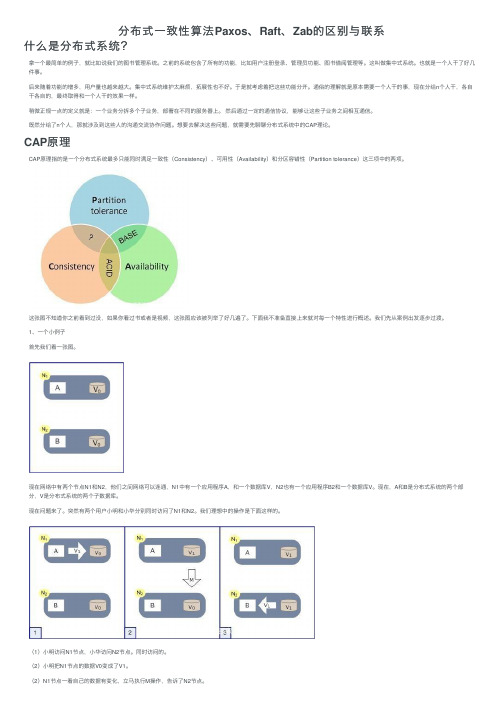
1、⼀个⼩例⼦⾸先我们看⼀张图。
现在⽹络中有两个节点N1和N2,他们之间⽹络可以连通,N1中有⼀个应⽤程序A,和⼀个数据库V,N2也有⼀个应⽤程序B2和⼀个数据库V。
现在,A和B是分布式系统的两个部分,V是分布式系统的两个⼦数据库。
现在问题来了。
突然有两个⽤户⼩明和⼩华分别同时访问了N1和N2。
我们理想中的操作是下⾯这样的。
(1)⼩明访问N1节点,⼩华访问N2节点。
同时访问的。
(2)⼩明把N1节点的数据V0变成了V1。
(2)N1节点⼀看⾃⼰的数据有变化,⽴马执⾏M操作,告诉了N2节点。
(4)⼩华读取到的就是最新的数据。
也是正确的数据。
上⾯这是⼀种最理想的情景。
它满⾜了CAP理论的三个特性。
现在我们看看如何来理解满⾜的这三个特性。
深入理解分布式系统中的一致性算法

深入理解分布式系统中的一致性算法一、引言分布式系统是由大量计算机节点组成的网络系统,这些节点之间通过网络互相连接,每个节点具有自己的计算能力和存储能力。
分布式系统是实现信息共享、资源共享和分布式计算的重要手段,是现代计算机系统的主要形态之一。
然而,由于分布式系统中存在诸多的不确定因素,如计算节点故障、网络拥塞、消息丢失等,导致分布式系统运行时存在数据不一致的风险。
因此,在分布式系统中,一致性算法是非常重要的,它可以确保分布式系统中各个节点之间的数据保持一致。
本文将深入剖析分布式系统中的一致性算法,帮助读者更好地理解和应用这些算法。
二、CAP定理在深入理解分布式系统中的一致性算法之前,我们需要了解一下分布式系统的CAP定理。
CAP定理是分布式系统领域的一个经典定理,由加州大学伯克利分校的Eric Brewer提出。
CAP定理指出,在一个分布式系统中,最多只能同时满足以下三个条件中的两个:1.一致性(Consistency):每个用户都能够从分布式系统中读取到最新的数据,即在多个节点之间数据一致。
2.可用性(Availability):每个用户访问分布式系统都能够得到正常的响应,即系统能够保证在有限时间内给出响应。
3.分区容错性(Partition Tolerance):系统即使发生网络分区,也能够继续对外提供服务。
在实际应用中,由于网络通信的不确定性以及硬件故障等原因,分布式系统中存在网络分区的可能性。
因此,为了保证分布式系统的稳定性,必须保证分区容错性。
当出现网络分区时,要么选择保证一致性,牺牲可用性;要么选择保证可用性,牺牲一致性。
三、一致性算法1. 2PC2PC(Transaction Processing Protocol)是一种常见的分布式一致性算法。
2PC算法分为投票阶段和提交阶段两个阶段。
在投票阶段,所有的参与者会向2PC的协调者发送投票消息,告诉协调者是否同意提交某个事务。
如果所有的参与者都同意提交这个事务,那么2PC的协调者就会向各个参与者发送提交消息,告诉它们可以提交这个事务。
区块链技术软件开发实践:分布式系统一致性共识原理FLP、Paxos拜占庭Raft算法

分布式系统一致性与共识的原理1一致性问题一致性问题是分布式领域最为基础也是最重要的问题。
如果分布式系统能实现“一致”,对外就可以呈现为一个完美的、可扩展的“虚拟节点”,相对物理节点具备更优越性能和稳定性。
这也是分布式系统希望能实现的最终目标。
1.1定义与重要性定义一致性(c o n s i s t e n c y),早期也叫a g r ee m e n t,是指对于分布式系统中的多个服务节点,给定一系列操作,在约定协议的保障下,试图使得它们对处理结果达成“某种程度”的认同。
理想情况下,如果各个服务节点严格遵循相同的处理协议,构成相同的处理状态机,给定相同的初始状态和输入序列,则可以保障在处理过程中的每个环节的结果都是相同的。
那么,为什么说一致性问题十分重要呢?举个现实生活中的例子,多个售票处同时出售某线路上的火车票,该线路上存在多个经停站,怎么才能保证在任意区间都不会出现超售(同一个座位卖给两个人)的情况呢?这个问题看起来似乎没那么难,现实生活中经常通过分段分站售票的机制。
然而,为了支持海量的用户和避免出现错误,存在很多设计和实现上的挑战。
特别在计算机的世界里,为了达到远超普通世界的高性能和高可扩展性需求,问题会变得更为复杂。
注意一致性并不代表结果正确与否,而是系统对外呈现的状态一致与否;例如,所有节点都达成失败状态也是一种一致。
1.2问题与挑战看似强大的计算机系统,实际上很多地方都比人类世界要脆弱得多。
特别是在分布式计算机集群系统中,如下几个方面很容易出现问题:·节点之间的网络通信是不可靠的,包括消息延迟、乱序和内容错误等;·节点的处理时间无法保障,结果可能出现错误,甚至节点自身可能发生宕机;·同步调用可以简化设计,但会严重降低分布式系统的可扩展性,甚至使其退化为单点系统。
仍以火车票售卖问题为例,愿意动脑筋的读者可能已经想到了一些不错的解决思路,例如:·要出售任意一张票前,先打电话给其他售票处,确认下当前这张票不冲突。
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
基础架构事业群-数据库技术-数据库内核何登成Paxos/Raft 分布式一致性算法原理剖析及其在实战中的应用目录ContentsConsensus ProblemBasic PaxosMulti-Paxos and Raft实战分析参考资料定义:The consensus problem requires agreement among a number of processes (or agents) for a single data value.✓理解Consensus 问题的关键✓绝对公平,相互独立:所有参与者均可提案,均可参与提案的决策✓针对某一件事达成完全一致:一件事,一个结论✓已经达成一致的结论,不可被推翻✓在整个决策的过程中,没有参与者说谎✓晚饭吃什么?炉鱼食堂同乐会炉鱼炉鱼炉鱼ConsensusAlgorithmConsensus Algorithm:Basic Paxos✓Basic Paxos✓一个或多个Servers可以发起提案(Proposers)✓系统必须针对所有提案中的某一个提案,达成一致✓何谓达成一致?系统中的多数派同时认可该提案✓最多只能针对一个确定的提案达成一致✓Liveness (只要系统中的多数派存活,并且可以相互通信)✓整个系统一定能够达成一致状态,选择一个确定的提案Basic Paxos:Components✓Proposers✓Active:提案发起者(value)✓处理用户发起的请求✓Acceptors✓Passive:参与决策,回应Proposers的提案✓存储accept的提案(value),存储决议处理的状态✓Learners✓Passive:不参与决策,从Proposers/Acceptors学习最新达成一致的提案(value)✓本文接下来的部分,一个Server同时具有Proposer和Acceptor两种角色,Learner角色逻辑简单,暂时不讨论Basic Paxos:Acceptors如何决策?✓Accept First✓Acceptor仅仅接受其收到的第一个value✓Accept Last✓Acceptor接受其收到的所有value,新的覆盖老的Accept First:Split Votes✓对于并发的proposals,同时accept多个value,违背原则:✓系统中的多数派同时认可该提案✓最多只能针对一个确定的提案达成一致Accept Last:Conflicting Choices✓对于并发的proposals,先后accept多个value,违背原则:✓最多只能针对一个确定的提案达成一致Accept Last:Conflicting Choices(2)✓对于并发的proposals,先后accept多个value,违背原则:✓最多只能针对一个确定的提案达成一致Basic Paxos:Acceptors如何决策?✓Accept First✓Acceptor仅仅接受其收到的第一个value✓Accept Last✓Acceptor接受其收到的所有value,新的覆盖老的✓Accept First,Accept Last都有问题。
那Basic Paxos如何解决这些问题?如何实现Consensus?Basic Paxos:一阶段至两阶段✓一阶段Accept✓Accept First,Accept Last都不行✓参考分布式事务,两阶段提交(2PC)?✓两阶段Accept✓第一阶段:Propose阶段。
Proposers向Acceptors发出Propose请求,Acceptors针对收到的Propose请求进行Promise承诺✓第二阶段:Accept阶段。
收到多数派Acceptors承诺的Proposer,向Acceptors发出Accept请求,Acceptors针对收到的Accept请求进行接收处理✓第三阶段(可优化):Commit阶段。
发出Accept请求的Proposer,在收到多数派Acceptors的接收之后,标志着本次Accept成功。
向所有Acceptors追加Commit消息Basic Paxos:Proposal ID✓Propose阶段✓Proposal ID:唯一标识所有的Propose。
包括:不同Proposers发出的Propose,同一Proposer发出的不同Propose。
✓Proposal Number(唯一性)Proposal IDRound Number Server Id✓Round Number:每个节点存储本节点曾经看到过的最大值:maxRound✓Server Id:系统中每个节点的唯一标识✓Propose:获取当前节点的maxRound,自增1,然后加上本节点的Server Id,作为本次的Proposal ID✓Proposal ID(特性)✓Proposal ID全局唯一递增,大小代表了优先级。
优先级的作用?✓Proposer 发送Propose✓Proposer 生成全局唯一且递增的Proposal ID,向集群的所有机器发送Propose,这里无需携带提案内容,只携带Proposal ID即可✓Acceptor 应答Propose✓Acceptor 收到Propose后,做出“两个承诺,一个应答”✓两个承诺✓第一,不再应答Proposal ID 小于等于(注意:这里是<= )当前请求的Propose✓第二,不再应答Proposal ID 小于(注意:这里是< )当前请求的Accept请求✓一个应答✓返回已经Accept 过的提案中Proposal ID 最大的那个提案的Value和acceptedProposal ID,没有则返回空值✓Proposer 发送Accept✓“提案生成规则”:Proposer 收集到多数派的Propose应答后,从应答中选择存在提案Value的并且同时也是Proposal ID最大的提案的Value,作为本次要发起Accept 的提案。
如果所有应答的提案Value均为空值,则可以自己随意决定提案Value。
然后携带上当前Proposal ID,向集群的所有机器发送Accept请求✓应答Accept✓Acceptor 收到Accpet请求后,检查不违背自己之前作出的“两个承诺”情况下,持久化当前Proposal ID 和提案Value。
最后Proposer 收集到多数派的Accept应答后,形成决议Basic Paxos:细节(算法版)Proposers1) Choose new proposal number n2)Broadcast Prepare(n) to all servers4)When responses received from majority:If any acceptedValues returned, replace value with acceptedValue for highest acceptedProposal5)Broadcast Accept(n, value) to all servers6)When responses received from majority:Any rejections (result > n)? goto(1)Otherwise, value is chosenAcceptors3)Respond to Prepare(n):If n >minProposal then minProposal= nReturn(acceptedProposal, acceptedValue) 6)Respond to Accept(n, value):If n ≥minProposal then acceptedProposal= minProposal= n acceptedValue= valueReturn(minProposal)Acceptors must record minProposal, acceptedProposal, and acceptedValue on stable storage✓P 3.1✓Proposal ID:round number(3), server id(1)✓P 3.1达成多数派,其Value(X)被Accept,然后P 4.5学习到Value(X),并AcceptP 3.1没有被多数派Accept(只有S3 Accept),但是被P 4.5学习到,P 4.5将自己的Value 由Y替换为X,Accept(X)✓P 3.1没有被多数派Accept(只有S1 Accept),同时也没有被P 4.5学习到。
由于P 4.5 Propose的所有应答,均未返回Value,则P 4.5可以Accept自己的Value(Y)✓后续P 3.1的Accept(X)会失败,已经Accept的S1,会被覆盖Basic Paxos:Livelock(活锁)✓回顾两个承诺之一✓不再应答Proposal ID 小于等于当前请求的Propose。
意味着:需要应答Proposal ID大于当前请求的Propose✓两个Proposers交替Propose成功,Accept失败,形成活锁(Livelock)Basic Paxos:阶段总结✓Now,what we learn?✓学会了Basic Paxos,能用Basic Paxos解决Consensus问题,确定一个提案,确定一个取值✓Now,what we can do?✓决定本届美国总统选谁(两个Proposers:民主党、共和党;两个Value:Hillary、Trump;但我们好像是Learner角色…)✓决定今晚吃什么?✓一主多从架构,主宕机,决定选哪个从当新主✓Now,what we can’t do?✓如果想确定连续多个提案,确定连续多个值,Basic Paxos搞不定了…Consensus :From Basic to Multi-Paxos✓相同顺序执行命令,所有Servers 状态一致add jmp mov shlLogConsensus ModuleState Machineadd jmp mov shlLogConsensus ModuleState Machineadd jmp mov shlLogConsensus ModuleState MachineServersClientsshl✓只要多数节点存活,Server 能提供正常服务✓Consensus Module :从Basic Paxos 的决策单个Value ,到连续决策多个Value 。