关于快速高效的模式匹配算法的剖析与改进
数据匹配方法检讨书

数据匹配方法检讨书近年来,随着信息技术的迅猛发展,数据的重要性日益凸显。
数据匹配作为数据管理的重要环节,对于提高数据质量、实现精准分析具有重要意义。
然而,当前数据匹配方法存在着一些问题,需要进行深入的检讨和改进。
本文将就数据匹配方法的现状进行探讨,并提出相应的改进建议。
首先,传统的数据匹配方法在处理大规模数据时存在效率低下的问题。
传统方法通常采用基于规则的匹配算法,需要事先定义一系列的匹配规则,然后逐条进行匹配。
这种方法在数据量庞大的情况下,计算复杂度较高,往往无法满足实时匹配的需求。
因此,我们需要探索一种更高效的数据匹配方法,能够在保证匹配准确性的同时,提高匹配效率。
其次,数据匹配方法在处理非结构化数据时存在一定的局限性。
传统的数据匹配方法主要针对结构化数据进行匹配,对于非结构化数据的处理能力较弱。
然而,随着大数据时代的到来,非结构化数据的重要性日益凸显。
因此,我们需要开发一种能够有效处理非结构化数据的匹配方法,以满足实际应用的需求。
此外,数据匹配方法在处理不完整数据时存在一定的困难。
在实际应用中,由于各种原因,数据往往存在着不完整的情况,如缺失值、错误值等。
传统的数据匹配方法对于不完整数据的处理能力较弱,往往需要依赖人工干预来进行补充和修正。
因此,我们需要研究一种能够自动处理不完整数据的匹配方法,以提高匹配的准确性和效率。
此外,数据匹配方法在处理数据质量问题时存在一定的局限性。
数据质量是数据匹配的关键因素之一,而传统的数据匹配方法对于数据质量的处理能力较弱。
传统方法通常只关注数据的完整性和正确性,而忽视了其他重要的数据质量指标,如一致性、唯一性等。
因此,我们需要研究一种能够综合考虑数据质量的匹配方法,以提高匹配结果的准确性和可信度。
综上所述,当前的数据匹配方法存在着一些问题,需要进行深入的检讨和改进。
我们需要探索一种更高效、更灵活、更准确的数据匹配方法,以满足实际应用的需求。
在此基础上,我们还需要研究一种能够处理非结构化数据、不完整数据和数据质量问题的匹配方法,以提高匹配结果的准确性和可信度。
关于快速高效的模式匹配算法的剖析与改进

1 个字符全部 匹配 , 而实现 已经获知子模式P P……P一 且最常 的 , 1 首子 串与尾子 串同等 , : , 即 PP ……P .P K = P , …P , 么 +… 那
一
在下一次的匹配过程中, 就可以将模式串向右移动, 表示Nnx[ , et ] x
代表 当模 式串 中的第X 个字符和主 串中的相应 字符出现“ 失配 ” 现 象, 那么模 式中就 需要 重新 与主串中的字符位置进行 比较 , 预处 在 理时就 可以完成nx [] e t 的计 算工作。 x 为 了能完整体现完全匹配 的各种情况, 以上各首子串必须保证 为最长 。 因此 , 对于任何 一个子模式来说 ( ,, PP ……P. 中1 K .其 , ≤x n , 自匹配” )“ 中的首子串都 是唯一的 , 仅能与模 式的 自身结构相关 。 通过应用K 算法 , 取一 次将模式 向右移动若 干位置的方式 , MP 采 确 保匹配过程 中不需要任何 回溯 。 相对较好 的情况下 , 在 使用KMP 算 法的时 间复杂度 是0 m+n)n x[] ( ,e t 的计算时 间复杂度是0 m) x ( 。 23B 算 法 . M B M算法是单模 式匹配算法 的其 中一种 , 属于精确 的字符 串匹 配算法 , 采取从右 向左 的比较方 式, 应用 了“ 坏字符” 好后缀” 与“ 两 种启 发原则 。 M算法 与KMP算法 具有一定 区别 , B 主要是对模 式串 的扫描方式相反 , 由从左 向右改为从右 向左。 即 采用B M算法采用这 种 扫描 方式 的优 势在 于 : 如果在正 文中出现了个别模式没有 的字 符, 那么 可以将此模式迅速掠过 正文。 应用B M算法 , 关键 在于如何提高 正文的匹配速度 , 尤其是字 符在该模式 中的具体位置 。 假设模 式为W[,]同时定义函数X 函 1n, , 数X明确 了正文 中可 能产生字符 的模 式位置 : x>( , , , , 1 2 3 4 …… n, ) 且X∈。 函数X 的定义如 下 : 于每一个X∈ 对 来说 , 假设在执行正文 的位 置j “ 起 返前” 段以及模式从左 向右 的匹配检查 过程中 , 一 无论在 哪 位置 , 如果存在不 匹配现象 , 就开始 执行从Wn , 的从右向左 Nt +X
匹配改进方案

匹配改进方案在现代化的社会中,信息非常发达,但是其中的信息匹配却是一个大问题。
很多时候用户需要查询的信息较为复杂或者模糊,这就需要我们运用一些算法或技巧来提高信息匹配的效率和准确性。
在这篇文章中,我们将会提供一些匹配改进方案,谈谈如何利用这些方案提高信息匹配的效率。
一、文本匹配算法在信息检索领域,文本匹配是一种非常常用的技术。
其主要用途在于对文档库中的文章和用户查询之间进行匹配,然后返回最相关的结果。
现在常用的文本匹配算法有BM算法、KMP算法和AC算法等,这里我们主要介绍BM算法。
BM算法全称为Boyer-Moore算法,是一种实用而高效的文本匹配算法。
它在比较时,使用了字符上的信息,从而减少了比较次数,进而大大提高了匹配效率。
BM算法的核心思想是,先预处理要匹配的字符串,将其中的每个字符都放入散列表中,并记录下其最右边的出现位置。
在待匹配字符串中,从后往前匹配,一旦发现某个字符不匹配,就可以根据其最右边的出现位置,直接将模式串右移多个位数。
这样可以快速地进行匹配,提高匹配效率。
二、模糊匹配算法当查询的字符串模糊或存在一定的容错率时,我们可以利用模糊匹配算法来提高匹配准确度。
现在常用的模糊匹配算法有:莱文斯坦距离算法、Damerau-Levenshtein距离算法和Jaro-Winkler距离算法等。
这里我们主要介绍Jaro-Winkler距离算法。
Jaro-Winkler距离算法是一种字符串相似度算法,可以用来比较两个字符串间的相似程度。
其核心思想是,根据两个字符串之间的相同字符数量,计算出字符串间的相似度。
Jaro-Winkler距离算法首先根据字符串中相同字符数量和不同字符数量,计算出Jaro距离。
然后,根据两个字符串开头位置相同的字符数量,计算出Winkler修正系数。
最终,将Jaro距离与Winkler修正系数相乘,得到最终的Jaro-Winkler距离。
三、深度学习模型深度学习模型在近年来在信息检索领域也得到了广泛的应用。
快速高效多模式匹配算法的研究与实现

快速高效多模式匹配算法的研究与实现模式匹配算法是计算机科学领域的一个经典的研究方向,被广泛地应用在信息检索、入侵检测系统、病毒检测、信息过滤以及生物计算等众多领域中。
多模式匹配算法通过遍历一次文本串找到模式集中所有模式出现的位置。
近年来,多模式匹配已经成为模式匹配的研究热点。
WM算法是多模式匹配算法中效果最好的算法之一。
它的性能很大程度上依赖于预处理阶段构建的三张表,PREFIX表、SHIFT表和HASH表。
WM算法构建的这三张表存在明显缺陷,有很大的改进空间。
本文对WM算法进行了改进,主要工作如下:1、通过改进PREFIX表、SHIFT表和HASH表,设计了一个自适应哈希的WM算法:AHWM算法,提高了WM算法的时间性能。
其基本改进策略为:1)、将PREFIX表存储的模式串B位前缀的哈希值改进为lsp位前缀的哈希值,更大程度地过滤掉了不匹配的模式串;2)、建立了两个跳转表SHIFT1表和SHIFT2表,SHIFT1表和WM算法中的SHIFT表功能一样,用于记录在一次匹配之前字符块对应的跳转距离。
SHIFT2表用于记录一次匹配结束后滑动窗口可以跳转的最大安全距离,可使算法跳过很多没有必要比较的字符,加快了模式匹配过程;3)、将HASH表表项数据结构由链表转换为自适应哈希子结构HASH_STRUCT。
HASH_STRUCT可以根据当前哈希表槽中模式串的个数,动态地选择一种合适的数据结构来存储模式串。
当模式集规模很大的时候,与链表相比,HASH_STRUCT在保证尽量少占用内存的情况下,减少了在HASH表中查找模式消耗的时间。
2、对AHWM 算法进行了改进,提出了一种高效并行的多模式匹配算法EPPM算法。
虽然AHWM算法有着很好的时间性能,但是当模式集最短模式串长度比较小时,算法的性能变差。
EPPM算法克服了这个缺陷,它按照模式串长度将原来的模式集划分为四个模式子集SET1、SET2、SET3和SET4。
匹配改进方案

匹配改进方案引言在实际开发中,匹配场景是十分常见的。
例如,公司面试时可能需要对应聘者的简历进行关键词匹配来筛选合适的人选,电商平台需要对用户的搜索请求进行相关度匹配来返回合适的商品等等。
传统的字符串匹配算法诸如KMP、BM、正则表达式等虽然实现简单,但是在应对大规模的匹配场景时十分低效。
本文将介绍一些常用的匹配改进方案,旨在提升匹配效率。
精确匹配在需要精确匹配的场景中,基于哈希的精确匹配算法是一种非常可行的方案。
其基本思路是:将目标字符串和模式串均哈希为一个固定的整数,比较这两个整数是否相等,从而得到是否匹配的结果。
哈希值相等并不代表两个字符串必须完全相等,因此哈希值相等时还需要进一步进行字符串比较验证。
在实现哈希算法时,我们可以采用一些优化策略。
这里介绍两种常见的优化方式:1. 多项式哈希算法对于给定字符串S,其哈希值计算公式如下所示:hash(S) = S[0] * p^(n-1) + S[1] * p^(n-2) + ... + S[n-2] * p^1 + S[n-1] * p^0其中n为字符串长度,p为选定的一个质数。
多项式哈希算法具有以下特点:•速度快,通常比基于Trie等数据结构的算法更快。
•哈希冲突率低,在每个质数范围内随机选取质数时,哈希冲突的概率非常小。
•可逆性高,可以快速进行撤销操作。
2. Rabin-Karp算法Rabin-Karp算法是一种基于哈希的字符串匹配算法。
其基本思路是:计算出模式串的哈希值,然后依次计算目标字符串每个长度为模式串长度的子串的哈希值,比较它们与模式串哈希值是否相等。
为了进一步减小哈希冲突的概率,可以使用一个滑动窗口来遍历目标字符串,保证每个子串的长度均为模式串长度。
模糊匹配在实际场景中,需求更多地是针对文本的模糊匹配。
现在我们介绍几种常用的模糊匹配方案。
1. BM算法BM算法是一种字符串匹配算法,它的思想是每次通过比较模式串和目标串的尾部来跳过大量的匹配内容,从而提高匹配效率。
匹配改进方案

匹配改进方案随着互联网的发展和应用场景的丰富,人们的匹配需求越来越多,如网上相亲、招聘等。
而针对这些应用场景,如何提高匹配的准确度和效率,成为了一个重要的挑战。
本文将针对目前存在的匹配问题,提出一种可行的匹配改进方案。
现状和问题传统的匹配方式是使用关键词匹配,比如网上招聘中,招聘方用了一些关键词来说明岗位要求,并期望求职者简历中的信息与关键词匹配,从而筛选出符合要求的求职者。
然而,这种方式存在以下问题:•匹配准确度低:关键词匹配的方式具有歧义性,比如“UI设计师”和“用户体验设计师”在词义上非常接近,但从岗位要求的角度而言,两者在所需技能和职责方面存在很大的差异。
•难以处理同义词和近义词:在关键词匹配中,同义词和近义词很难被识别和精准匹配,例如“水管工”和“管道维修工”。
•难以处理上下文语境的影响:同一个关键词在不同的语境下可能有不同的含义和匹配度。
比如在招聘中,“水电工”可能指“管道技工”,而在闲置转让的网站中,“水电工”可能指擅长安装、维修水电设备的工人。
改进方案针对上述问题,我们提出一种基于自然语言处理的匹配方案,该方案的基本流程如下:1.对关键信息进行分词:求职者的简历和招聘方的岗位要求会分别进行分词,将描述、要求、技能等信息的文本,拆分为一个个单独的词。
2.通过词向量建立语义相似性:对于每个词语,我们可以利用预训练的词向量来计算其和其他词语之间的相似度。
词向量可以有效地解决同义词和近义词的问题,比如“水管工”和“管道维修工”在预训练的词向量中有很高的相似度。
3.建立整句语义相似度:对于简历和岗位要求中的每个句子,我们可以利用句子向量来计算其和其他句子的相似度。
这可以解决关键词匹配方法难以处理上下文语境的问题。
4.根据得分进行筛选:根据每个简历和岗位要求之间的相似性分数,我们可以进行初步筛选。
匹配得分高的求职者和岗位要求,可以进入下一步面试环节。
实现和优化我们可以采用开源的自然语言处理工具,如NLTK和spaCy,来实现上述算法。
搜索引擎的关键词匹配算法分析与优化建议

搜索引擎的关键词匹配算法分析与优化建议随着互联网的快速发展和普及,搜索引擎已经成为人们获取信息的主要途径之一。
而搜索引擎的核心功能则是通过关键词匹配算法,将用户输入的关键词与网页内容进行匹配,从而提供相应的搜索结果。
因此,关键词匹配算法的准确性和效率对于搜索引擎的用户体验至关重要。
本文将对搜索引擎的关键词匹配算法进行分析,并就如何优化关键词匹配算法提出建议。
一、关键词匹配算法的工作原理当前,搜索引擎中主要使用的关键词匹配算法有基于向量空间模型(VSM)的TF-IDF算法和基于语义相似度的Word2Vec算法。
这两种算法都是根据关键词在网页内容中出现的频率和位置等信息来计算关键词与网页的匹配度。
TF-IDF算法通过计算关键词在网页内容中的词频(TF)和逆文档频率(IDF)来计算关键词的权重,从而衡量关键词与网页的匹配程度。
这种算法简单高效,但没有考虑到词语之间的语义关系,容易受到关键词出现位置的影响。
Word2Vec算法则是通过训练神经网络模型,将文本内容映射到高维向量空间,并通过计算词向量之间的相似度来衡量关键词与网页的匹配度。
这种算法考虑了词语之间的语义关系,但计算复杂度较高。
二、关键词匹配算法存在的问题尽管目前使用的关键词匹配算法已经取得了一定的效果,但仍然存在一些问题:1. 歧义问题:有些关键词可能存在多种含义,特别是在特定领域或行业中,容易产生歧义。
比如,关键词“苹果”既可以指代水果,也可以指代科技公司。
2. 多词搜索问题:用户输入的搜索关键词可能是由多个词语组成的短语,而现有的关键词匹配算法通常只考虑单个关键词与网页的匹配度,对于多词搜索的支持不够充分。
3. 搜索结果偏差问题:由于关键词匹配算法的复杂性和数据量的限制,搜索引擎往往会偏向于权威网站或用户反馈较多的网页,导致搜索结果的偏差。
三、关键词匹配算法的优化建议为了改进搜索引擎的关键词匹配算法,提高用户搜索结果的准确性和相关性,可以采取以下优化措施:1. 语义分析与关键词扩展:在搜索引擎中引入自然语言处理技术,对关键词进行语义分析,识别关键词的上下文含义,从而减少歧义问题的发生。
模式匹配算法的分析与研究
模式匹配算法的分析与研究作者:余飞来源:《电脑知识与技术》2018年第10期摘要:模式匹配算法是计算机领域的一个重要研究方向,是防火墙系统、安全扫描系统、入侵检测系统等核心技术之一。
该文分析了四种经典算法,研究了算法原理,展示了模式匹配算法发展过程,研究表明模式匹配算法具有较高的用途和实用价值。
关键词:模式匹配算法;算法原理;核心技术中图分类号:TP311 文献标识码:A 文章编号:1009-3044(2018)10-0251-02Abstract: Pattern matching algorithm is an important research field in computer field. It is one of the core technologies of firewall system, security scanning system, intrusion detection system and so on. In this paper, four classical algorithms are analyzed, the algorithm principle is studied, and the development process of pattern matching algorithm is shown. The research shows that pattern matching algorithm has high practical and practical value.Key words: Pattern matching algorithm; algorithm principle; core technologies模式匹配算法是网络安全系统的核心技术之一。
现在比较流行的网络安全系统包括病毒防护系统,防火墙系统,安全扫描系统,入侵检测系统等等。
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
关于快速高效的模式匹配算法的剖析与改进
摘要:模式匹配算法是现代化网络入侵检测中的关键环节,本文主要介绍了几种常用的模式匹配算法,并在此基础上,提出一种更快捷、更高效的改进方法,以提高模式匹配的效率与质量,确保网络安全。
关键词:模式匹配入侵检测改进
随着我国计算机与网络技术的飞速发展,网络应用已涉及到人们生产、生活的各个领域,其重要性日益凸显。
随之而来的网络攻击问题也备受关注,给网络安全性带来挑战。
传统的网络防御模式,主要采取身份认证、防火墙、数据加密等技术,但是与当前网络发展不适应。
在此背景下,入侵检测技术营运而生,并建立在模式匹配基础上,确保检测的快捷性、准确性,应用越来越广泛。
1、模式匹配原理概述
模式匹配是入侵检测领域的重要概念,源自入侵信号的层次性。
结合网络入侵检测的底层审计事件,从中提取更高层次的内容。
通过高层事件形成的入侵信号,遵循一定的结构关系,将入侵信号的抽象层次进行具体划分。
入侵领域大师kumar将这种入侵信号划分为四大层次,并将每一个层次与匹配模式相对应。
以下将分别对四大层次进行分析:
(1)存在。
只要存在审计事项,就可以证明入侵行为的发生,并深层次挖掘入侵企图。
存在主要对应的匹配模式就是“存在模式”。
可以说,存在模式就是在固定的时间内,检查系统中的特定状态,
同时判断系统状态。
(2)序列。
一些入侵的发生,是遵循一定的顺序,而组成的各种行为。
具体表现在一组事件的秩序上。
序列对应的是“序列模式”,在应用序列模式检测入侵时,主要关注间隔的时间与持续的时间。
(3)规则。
规则表示的是一种可以扩展的表达方式,主要通过and 逻辑表达来连接一系列的描述事件规则。
一般适用于这种模式的攻击信号由相关活动组成,这些活动之间往往不存在事件的顺序关系。
(4)其他。
其他模式是不包含前面几种方法的攻击,在具体应用过程中,难以与其他入侵信号进行模式匹配,大多为部分实现方式。
2、几种常用的模式匹配算法
2.1 ac算法
ac算法(aho-corasick)是一种可以同时搜索若干个模式的匹配算法,最早时期在图书馆书目查询系统中应用,效果良好。
通过使用ac算法,实现了利用有限状态自动机结构对所有字符串的接收过程。
自动机具有结构性特征,且每一个前缀都利用唯一状态显示,甚至可同时应用于多个模式的前缀中。
如果文本中的某一个字符不属于模式中预期的下一个字符范围内,或者可能出现错误链接的指向状态等,那么最长模式的前缀同时也可作为当前状态相对应的后缀。
ac算法的复杂性在于o(n),预处理阶段的复杂性则在于o(m)。
在采取ac算法的有限状态自动机中,应该在每一个字符的模式串中分别建立节点,提高该算法的使用效率与质量。
目前,应用有限
自动计算法是一种较为典型与常用的方法,如果模式集比较大,可能引发空间膨胀问题。
在使用ac算法时,搜索输入串过程中没有跳跃,直接根据顺序输入,因此在规则较少的情况下,ac算法的搜索性能并不理想。
2.2 kmp算法
kmps算法与简单的算法有所不同,如果某一次的匹配失败,那么模式串不一定是向右移动一格,即使向右移动,也未必从模式的起点位置开始匹配。
kmp的具体计算方法为:
当某次试匹配成功之后,如果tx≠px,那么即使在模式之前j-1个字符全部匹配,而实现已经获知子模式p1p2……px-1,且最常的首子串与尾子串同等,即:p1p2……pk-1=px-k+1pjxk+2……pj-k,那么在下一次的匹配过程中,就可以将模式串向右移动,表示为next[x],代表当模式串中的第x个字符和主串中的相应字符出现“失配”现象,那么模式中就需要重新与主串中的字符位置进行比较,在预处理时就可以完成next[x]的计算工作。
为了能完整体现完全匹配的各种情况,以上各首子串必须保证为最长。
因此,对于任何一个子模式来说(p1p2……px,其中1≤x
≤n),“自匹配”中的首子串都是唯一的,仅能与模式的自身结构相关。
通过应用kmp算法,采取一次将模式向右移动若干位置的方式,确保匹配过程中不需要任何回溯。
在相对较好的情况下,使用kmp算法的时间复杂度是0(m+n),next[x]的计算时间复杂度是0(m)。
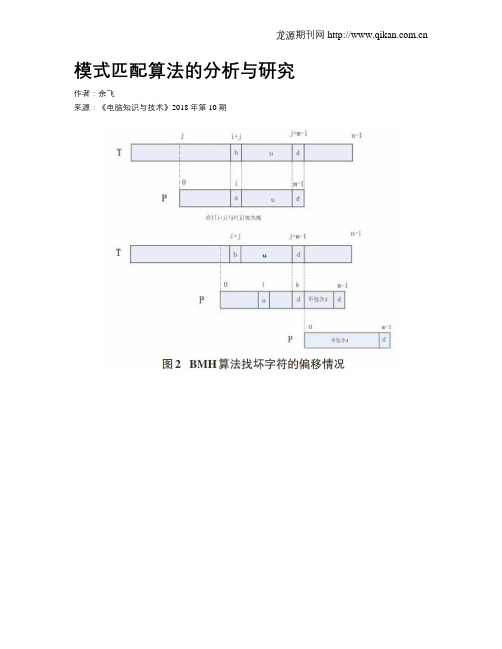
2.3 bm算法
bm算法是单模式匹配算法的其中一种,属于精确的字符串匹配算法,采取从右向左的比较方式,应用了“坏字符”与“好后缀”两种启发原则。
bm算法与kmp算法具有一定区别,主要是对模式串的扫描方式相反,即由从左向右改为从右向左。
采用bm算法采用这种扫描方式的优势在于:如果在正文中出现了个别模式没有的字符,那么可以将此模式迅速掠过正文。
应用bm算法,关键在于如何提高正文的匹配速度,尤其是字符在该模式中的具体位置。
假设模式为w[1,n],同时定义函数x,函数x明确了正文中可能产生字符的模式位置:x>(1,2,3,4,……n),且x∈。
函数x的定义如下:对于每一个x∈来说,假设在执行正文的位置j起“返前”一段以及模式从左向右的匹配检查过程中,无论在哪一位置,如果存在不匹配现象,就开始执行从wn和tj+x的从右向左的匹配检查。
这种检查的效果相当于将模式向右侧滑动一段距离。
很明显,tj不会在模式中出现或者仅在模式的末端存在,向右侧滑动的最大距离为n。
3、一种新的模式匹配算法
随着计算机与网络的不断应用与拓展,网络流量迅速增加,各种匹配原则与匹配效率逐渐落后,无法满足现代化高速网络的发展需要。
尤其随着各种检测规则的不断提出,各种数据包匹配的次数也有所改变,因此很难完全满足性能。
针对这一情况,在各种基本算
法的基础上,充分利用“本次匹配不成功”原则,在匹配失败的情况下,尽量跳过多个字符,实现迅速匹配目标。
实际上,本文介绍的快速高效的全新模式匹配算法qs,是bm的简化算法形式,具体描述如下:当p[1,2......n]和t[i,i+1, (i)
+n-1]对齐的情况下,就可以实现匹配。
如果匹配失败,就分析t[i +n]个字符,以此判断右移p[1,2……n]的距离。
由于某一次匹配失败之后,模式会至少向右侧移动一格位置,那么一般情况下,t[i +n]字符就会在下一次匹配中出现。
因此,匹配失败后,就可以综合考虑t[i+n]而非t[i,i+1,……i+n-1]中的某个字符,这样模式最大右移的距离是n+1,在bm算法中则是n。
以下将对两种改进方法分别进行论述:
(1)经过改进的算法,如果文本和模式的某次匹配失败,那么对于t[i,i+1,……i+n-1]左边的字符t[i-1]就可以采取坏字符移动的方式,而t[i,i+1,……i+n-1]则采取好前缀移动。
在文本中,应该取指针移动距离最大的一个,即minlength+1(minlength)是模式集合中的最短模式长度。
针对文本中的所有字符(w)来说,可将坏字符的移动函数定义为:
如果w出现在p中,那么执行公式(1),否则执行公式(2)。
(2)在传统的匹配算法中,当匹配失败之后,就会分别计算坏字符启发函数或者好前缀启发函数,然后取其中最大值,作为移动量。
但是每次计算的时间比较长,因此需要改进坏字符优先策略。
如果利用坏字符启发可以实现n或者n+1的量,就不需要再计算前缀
启发函数,最大限度地缩短模式匹配算法时间。
经过改进的算法,预处理时间复杂度是0(││+│p│),此处││代表字符集的大小,│p│则是模式集中所有的模式长度综合。
这种算法的最佳情况为:
在每次模式树的第一个字符和文本比较不匹配,而且存在偏移量的最大值minlength+1,改进算法的最佳性能,那么比较的次数为:在每次进行模式树中的最长模式,最后一个字符和文本比较时匹配失败,那么最小偏移量是1,改进之后的算法也具备最差性能,这种情况下的比较次数为:minlength+[n-2
(minlength-1)]maxlength,时间复杂度是0(n maxlength)。
在平均情况下,时间复杂度和字符出现概率相关,可以通过概率模型计算。
由上可见,随着各种网络应用的不断完善,网络入侵检测计算日益发展,逐渐无法适应网络环境的要求,必须加快改进与优化策略,将改进的算法应用于入侵检测系统中,提高检测效率,确保网络安全运行。
参考文献
[1] 陈围.采用集合切分编码的大容量模式匹配算法[j].计算机应用研究,2011(6).
[2] 王烁.字符串模式匹配的硬件加速研究[j].中国科学技术大学:通信与信息系统.2008.
[3] 孙伟.基于模式匹配和协议分析的入侵检测技术研究[j].湖
南大学:计算机应用技术,2006.
[4] 鲁宏伟,魏凯,孔华锋.一种改进的kmp高效模式匹配算法[j].华中科技大学学报,2006(10).
[5] 张航,王宏志,李建中,高宏.基于2-hop优化的子图模式匹配算法[j].黑龙江大学自然科学学报,2010
(1).
[6] 陶世群,富丽贞.一种高效非归并的xml小枝模式匹配算法[j].软件学报,2009(4).
[7] 郑海涛.基于网络信息内容的dns检测系统的设计与实现[j].北京交通大学:通信与信息系统,2009.
[8] 谷晓刚,江荣安,赵铭伟.snort的高效规则匹配算法[j].计
算机工程,2006(18).。