EM算法(讲解+程序)
分类 em算法

分类em算法摘要:1.引言2.EM 算法的基本原理3.EM 算法的分类应用4.结论正文:1.引言EM 算法,全称Expectation-Maximization 算法,是一种常见的概率模型优化算法。
该算法在统计学、机器学习等领域具有广泛的应用,特别是在分类问题上表现出色。
本文将重点介绍EM 算法在分类问题上的应用及其基本原理。
2.EM 算法的基本原理EM 算法是一种迭代优化算法,主要通过两个步骤进行:E 步(Expectation)和M 步(Maximization)。
在E 步中,根据观测数据计算样本的隐含变量的期望值;在M 步中,根据隐含变量的期望值最大化模型参数的似然函数。
这两个步骤交替进行,直至收敛。
EM 算法的基本原理可以概括为:对于一个包含隐含变量的概率模型,通过迭代优化模型参数,使得观测数据的似然函数最大化。
在这个过程中,EM 算法引入了Jensen 不等式,保证了算法的收敛性。
3.EM 算法的分类应用EM 算法在分类问题上的应用非常广泛,典型的例子包括高斯混合模型(GMM)和隐马尔可夫模型(HMM)。
(1)高斯混合模型(GMM)在传统的分类问题中,我们通常使用极大似然估计(MLE)来求解最佳分类模型。
然而,当数据分布复杂时,MLE 可能无法得到一个好的解。
此时,我们可以引入EM 算法,通过迭代优化模型参数,提高分类的准确性。
在GMM 中,EM 算法可以有效地处理数据的多峰分布,从而提高分类效果。
(2)隐马尔可夫模型(HMM)HMM 是一种基于序列数据的概率模型,广泛应用于语音识别、时间序列分析等领域。
在HMM 中,EM 算法被用于求解最优路径和状态转移概率。
通过EM 算法,我们可以有效地处理观测序列与隐状态之间的不确定性,从而提高分类效果。
4.结论EM 算法作为一种强大的概率模型优化算法,在分类问题上表现出色。
通过引入隐含变量和迭代优化,EM 算法可以有效地处理数据的复杂性和不确定性,提高分类的准确性。
EM算法-完整推导

EM算法-完整推导前篇已经对EM过程,举了扔硬币和⾼斯分布等案例来直观认识了, ⽬标是参数估计, 分为 E-step 和 M-step, 不断循环, 直到收敛则求出了近似的估计参数, 不多说了, 本篇不说栗⼦, 直接来推导⼀波.Jensen 不等式在满⾜:⼀个 concave 函数, 即形状为 "⋂" 的函数f(x)λj≥0∑jλj=1 类似于随机变量的分布的前提条件下, 则有不等式:f(∑jλj x j)≥∑jλj f(x j)恒成⽴, 则该不等式称为 Jensen 不等式. 是有些不太直观哦, (sum 是最后哦, 有时候会犯晕).为了更直观⼀点, 考虑λ只有两个值, 即:λ1=1−tλ2=1其中,0⩽"\bigcap" 函数 f(x) 中有⼀段区间 [a, b], 构造出该范围内的⼀个点x_t当, x_t = (1+t)a + tb则有:f((1-t)a +tb) \ge (1-t)f(a) + tf(b)这⾥跟之前写过的 convex 其实是⼀模⼀样的, 要是还不直观, 就⾃个画个草图就秒懂了.左边是函数的值, 右边连接两个端点a,b的函数值的直线, 因为是 "\bigcap 的", 故函数值必然在直线的上⽅.⽤数学归纳法, 当 M > 2:f(\sum \limits _{j=1}^M \lambda_j x_j) \ge \sum \limits _{j=1}^M \lambda_j f(x_j)EM算法推导假设给定⼀个包含 n 个独⽴的训练样本的数据集, D = \{ x_1, x_2, x_3...x_n) \}希望拟合⼀个概率模型p(x, z) , 其对数似然函数(log likelihood)为:为啥要 log, 乘法变加法, 不太想说了, ⾃⼰都重复吐⾎了似然, 不加log 前是: l(\theta) = \prod \limits _{i=1}^n p(x; \theta)的嘛, 样本的联合概率最⼤l(\theta) = \sum \limits _{i=1}^n log \ p(x; \theta)= \sum \limits _{i=1}^n log \ \sum \limits _{z} p(x, z; \theta)理解\sum \limits _{z} p(x, z; \theta)给定\theta的前提下, 关于 x, z 的联合概率跟之前扔硬币是⼀样的, 对于每个独⽴数据的产⽣, 其实还有⼀个隐含的因素 z (扔硬币中,到底这次试验是来⾃于硬币A 还是硬币B每个Z因素, 影响着 p(x,z) 的联合概率分布. 考虑所有的 z, 则是全概率了呀.对于p(x; \theta)直接通过 x 来观测\theta⽐较难 (扔硬币中, 没有上帝视⾓, 不知道扔结果是哪个硬币产⽣的)z^{(i)}是⼀个隐变量(latent), 如果能观测到z^{(i)}则参数预测会容易很多, EM算法就是来解决这个问题的EM 算法呢, 分为两个步骤:在 E 步中, 构建l(\theta)的下界函数 (给定\theta来找 z)在 M 步中, 最⼤化这个下界函数不太直观, 就回顾上篇扔硬币的栗⼦, 这⾥的 z 就是那个来⾃哪⾥A 还是 B 的概率(每次试验)设Q_i为关于 z 的概率分布, 即\sum \limits _{z} Q_i(z) = 1 (z 如是连续变量则\sum \rightarrow \int_z) ,则对于上⾯的对数似然函数:= \sum \limits _{i=1}^n log \ \sum \limits _{z} p(x_i, z_i; \theta) \ (1)对 p 的部分, 同时乘上和除以Q_i(z_i)不改变等式 , 这种技巧, 中学的 "配平⽅或数列裂项求和" ⼀样滴= \sum \limits _i log \sum \limits _{z_i} Q_i(z_i) \frac {p(x_i, z_i; \theta)}{Q_i(z_i) } \ (2)log 函数是 concave 的, 联想 jensen不等式f(\sum \limits _j \lambda_j x_j) \ge \sum \limits _j \lambda_j f(x_j)即 log 对于与 f(); \sum \limits _{z_i} Q_i(z_i) 对应于 \sum \limits _j \lambda_j ; 最后⼀项对x_j\ge \sum \limits_{i} \sum \limits_{z_i}Q_i(z_i) \ log \frac {p(x_i, z_i; \theta)}{Q_i(z_i) } \ (3)就类似与, 把⼀个, 函数⾥⾯的参数, 提取到函数外⾯来. 如还是不理解, 回看之前写的 convex 篇什么时候会取到等于?即当\frac {p(x_i, z_i; \theta)}{Q_i(z_i) } = c是个常数的时候, (2) 和 (3) 是相等的.即p(x_i, z_i; \theta) = c \ * Q_i(z_i)在\theta给定下, 关于 x, z 的联合概率分布与隐变量 z 的分布是⼀个线性关系因为\sum \limits_{z_i} Q_i(z_i) = 1, 如果将Q_i(z_i)认为是给定x_i 和 z_i的后验概率分布, 这样就得到了该似然函数的⼀个下界,根据全概率(后验) 与贝叶斯公式:Q_i(x_i) = \frac {p(x_i, z_i; \theta)}{\sum \limits _{z_i} p(x_i, z_i; \theta)}=\frac {p(x_i, z_i; \theta)}{p(x; \theta)}=p(z_i|x_i, \theta)相当于求给定\theta 和 x_i的情况下, 求 z_i 的条件概率, 果然, 深刻理解贝叶斯公式显得多么重要呀再回顾⼀波贝叶斯公式:设A1,A2,A3..构成完备事件组, 则对任意⼀事件B有:P(A_i|B) = \frac {P(A_i)P(B|A_i)}{\sum \limits _{i=1}^n P(A_i)P(B|A_i)}同上述, 只要当我们取Q_i(z_i)的值为给定\theta 和 x_i的后验概率分布的时候, 就能保证:\frac {p(x_i, z_i; \theta)}{Q_i(z_i) }的值是⼀个常数 (反过来推的), 既然是个常数, 也就**前⾯ (3) 的地⽅可以取等号啦, 即: **\sum \limits _{i=1}^n log \ \sum \limits _{z} p(x_i, z_i; \theta) = \sum \limits_{i} \sum \limits_{z_i}Q_i(z_i) \ log \frac {p(x_i, z_i; \theta)}{Q_i(z_i) }这样⼀来, 相当于在 E 步得到了似然函数的⼀个下界, 然后在 M 步, 求解(3) 最⼤值时候的参数\theta . 然后重复以上的 E, M 步骤:E-步: For each i:Q_i(z_i) = p(z_i | x_i; \theta)M-步, 更新\theta:\theta = arg \ max _\theta \sum \limits_{i} \sum \limits_{z_i}Q_i(z_i) \ log \frac {p(x_i, z_i; \theta)}{Q_i(z_i) }....循环直到收敛, 则估计出了参数\theta但, 万⼀不收敛呢?, so, 必须证明⼀波, EM算法是收敛的哦证明EM算法会收敛假设\theta^{(t)} 和 \theta^{(t+1)}为EM算法的连续两个步骤的参数值, 欲证l (\theta)收敛, 只需证:l(\theta^{(t)}) \leq l(\theta^{(t+1)})即可EM算法使得似然函数的值单调递增即可根据前⾯关于⽤ jensen不等式的取等条件, 推导出, 取得Q_i(z_i)^{(t)}的⽅式是:Q_i ^{(t)} (z_i) = p(z_i | x_i; \theta ^{(t)})此条件下, 使得jensen不等式取等即:l(\theta^{(t)}) = \sum \limits_{i} \sum \limits_{z_i}Q_i(z_i) \ log \frac {p(x_i, z_i; \theta ^t)}{Q_i(z_i) }⽽参数\theta^{(t+1)}的取值⽅式, 是使得上⾯的这个等式的值最⼤, 则必然l(\theta^{(t+1)}) \ge l(\theta^{(t)})展开⼀波:l(\theta^{(t+1)}) \ge \sum \limits_{i} \sum \limits_{z_i}Q_i^t(z_i) \ log \frac {p(x_i, z_i; \theta ^{(t+1)})}{Q_i^t(z_i) } \ (4)\ge \sum \limits_{i} \sum \limits_{z_i}Q_i^t(z_i) \ log \frac {p(x_i, z_i; \theta^t)}{Q_i^t(z_i) }\ (5)=l(\theta^{(t)}) \ (6)(4) 源于不等式的性质, 必然成⽴嘛(5) 就是取最⼤值的⼀个过程必然成⽴(6) 取相等的⽅式去是应⽤了 Jensen不等式即证明了l(\theta^{(t)}) \leq l(\theta^{(t+1)}) , 即EM算法是收敛的呀.⼩结⾸先是要理解,参数估计的是在⼲嘛, 需要回顾统计学的基础知识, 或理解上篇扔硬币的栗⼦核⼼, ⽤到了⼀个jensen 不等式, 需要回顾凸函数的⼀些性质来理解⼀波推导的⽅式呢, 依旧是极⼤似然估计, 带log (乘法边加法)推导核⼼技巧是全概率与贝叶斯公式, 真正理解太重要, 如LDA, 逻辑回归, 贝叶斯...这些算法都⽤到了.证明收敛, 其实只是⼀些, 推理的技巧, 还是挺有意思的.总体上, EM算法, 理解起来,我感觉不是很容易, 但, 也没有想象的那样难, 只要肯坚持, 正如爱因斯坦所说的那样嘛, 当然也为了⾃勉⽬前在经济和精神双重困境中的⾃⼰:耐⼼和恒⼼, 总会获得收获的Loading [MathJax]/jax/element/mml/optable/SuppMathOperators.js。
EM算法

i i z i z i
(i ) Q ( z Z i ) 1 Qi ( z ) 0
Q i 表示隐含变量Z的某种分布,Qi 满足的条件是
z P x i , z i ; C
EM算法
i i z(i )
EM算法
(i ) (i ) (i ) ln p ( x ; ) ln p ( x , z ; ) i i 种分布,Qi 满足的条件是
(i ) Q ( z Z i ) 1 Qi ( z ) 0
p ( x ( i ) , z ( i ) ; ) ln Qi ( z ) (i ) ( i ) Q ( z ) i z i
根据数学期望的相关定 理:E[ f ( X )] f ( xi ) p( xi )
p ( x , z ; ) p ( x ( i ) , z ( i ) ; ) (i ) Q ( z ) 是 ( z )的数学期望 i (i ) Qi Qi ( z ) z(i ) p ( x ( i ) , z ( i ) ; )
(i ) (i ) (i )
i
ln(E[
i
Qi ( z )
(i )
])
(3)
EM算法
根据Jensen不等式:
f ( x) ln x是凹函数 f ( EX ) E f ( x)
lnE[ X ] Eln X
p( x ( i ) , z ( i ) ; ) ln(E[ ]) (i ) Qi ( z ) i (3)
至与此 t 对应的L t 的值相等。
只有当此时的下界等于 当前的对数似然函数时, 我才能保证当我优化这 个下界的时候,才真正 优化了目标函数。
【机器学习】EM算法详细推导和讲解
【机器学习】EM算法详细推导和讲解 今天不太想学习,炒个冷饭,讲讲机器学习⼗⼤算法⾥有名的EM算法,⽂章⾥⾯有些个⼈理解,如有错漏,还请读者不吝赐教。
众所周知,极⼤似然估计是⼀种应⽤很⼴泛的参数估计⽅法。
例如我⼿头有⼀些东北⼈的⾝⾼的数据,⼜知道⾝⾼的概率模型是⾼斯分布,那么利⽤极⼤化似然函数的⽅法可以估计出⾼斯分布的两个参数,均值和⽅差。
这个⽅法基本上所有概率课本上都会讲,我这就不多说了,不清楚的请百度。
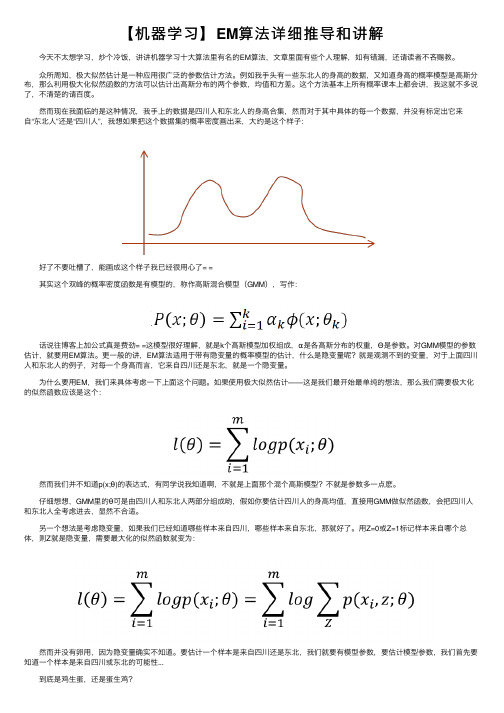
然⽽现在我⾯临的是这种情况,我⼿上的数据是四川⼈和东北⼈的⾝⾼合集,然⽽对于其中具体的每⼀个数据,并没有标定出它来⾃“东北⼈”还是“四川⼈”,我想如果把这个数据集的概率密度画出来,⼤约是这个样⼦: 好了不要吐槽了,能画成这个样⼦我已经很⽤⼼了= = 其实这个双峰的概率密度函数是有模型的,称作⾼斯混合模型(GMM),写作: 话说往博客上加公式真是费劲= =这模型很好理解,就是k个⾼斯模型加权组成,α是各⾼斯分布的权重,Θ是参数。
对GMM模型的参数估计,就要⽤EM算法。
更⼀般的讲,EM算法适⽤于带有隐变量的概率模型的估计,什么是隐变量呢?就是观测不到的变量,对于上⾯四川⼈和东北⼈的例⼦,对每⼀个⾝⾼⽽⾔,它来⾃四川还是东北,就是⼀个隐变量。
为什么要⽤EM,我们来具体考虑⼀下上⾯这个问题。
如果使⽤极⼤似然估计——这是我们最开始最单纯的想法,那么我们需要极⼤化的似然函数应该是这个: 然⽽我们并不知道p(x;θ)的表达式,有同学说我知道啊,不就是上⾯那个混个⾼斯模型?不就是参数多⼀点麽。
仔细想想,GMM⾥的θ可是由四川⼈和东北⼈两部分组成哟,假如你要估计四川⼈的⾝⾼均值,直接⽤GMM做似然函数,会把四川⼈和东北⼈全考虑进去,显然不合适。
另⼀个想法是考虑隐变量,如果我们已经知道哪些样本来⾃四川,哪些样本来⾃东北,那就好了。
⽤Z=0或Z=1标记样本来⾃哪个总体,则Z就是隐变量,需要最⼤化的似然函数就变为: 然⽽并没有卵⽤,因为隐变量确实不知道。
大数据经典算法EM算法 讲解

������ ������ = ������������������ ������ = ������������
������=������
������ ������������ ������ =
������=������
������������������(������������ |������)
dl( p ) n dp 1 p
n
[x i ln p (1 x i )ln(1 p )] n ln(1 p ) x i[ln p ln(1 p )] i i
1 1
n 1 1 n 1 x i( ) xi 0 p 1 p 1 p p(1 p ) i 1 i 1
ˆ xi x 4. 解似然方程得: p n i 1 5. 验证在 pˆ x 时,d l( p ) 0,这表明 pˆ x 可使似 dp 然函数达到最大
2 2
11
1
n
16:54:11
小结
极大似然估计,只是一种概率论在统计学的应 用,它是参数估计的方法之一。说的是已知某 个随机样本满足某种概率分布,但是其中具体 的参数不清楚,参数估计就是通过若干次试验, 观察其结果,利用结果推出参数的大概值。最 大似然估计是建立在这样的思想上:已知某个 参数能使这个样本出现的概率最大,我们当然 不会再去选择其他小概率的样本,所以干脆就 把这个参数作为估计的真实值。
16:54:09
EM算法——最大期望算法
——吴泽邦 吴林谦 万仔仁 余淼 陈志明 秦志勇
1
16:54:10
食堂的大师傅炒了一份菜,要等分成两份给两个人吃
——显然没有必要拿来天平一点一点的精确的去称分量, 最简单的办法是先随意的把菜分到两个碗中,然后观察是 否一样多,把比较多的那一份取出一点放到另一个碗中, 这个过程一直迭代地执行下去,直到大家看不出两个碗所 容纳的菜有什么分量上的不同为止 EM算法就是这样,假设我们估计知道A和B两个参数,在 开始状态下二者都是未知的,并且知道了A的信息就可以 得到B的信息,反过来知道了B也就得到了A。可以考虑首 先赋予A某种初值,以此得到B的估计值,然后从B的当前 值出发,重新估计A的取值,这个过程一直持续到收敛为 止。
机器学习 EM算法详细版

本节课内容:计算似然的极大值
牛顿法 EM算法
极大似然估计
似然函数:令 X 1 ,..., X n 为IID,其pdf为 f ( x; θ ) , 似然函数定义为
Ln (θ ) = ∏ f ( X i ; θ )
i =1 n
log似然函数:
ln (θ ) = log Ln (θ )
在给定观测数据的条件下,计算完整似然的期望(随 机变量为隐含变量)
涉及计算缺失数据的条件期望,需要利用参数的当前估计值
M —步:求极大值( Maximization )
求使得完整似然的期望最大的参数
又是一个极大值求解问题。通常可以解析求解,这时EM是一 个很方便的工具;否则,需借助一个可靠的最大化方法求解
i =1
n
k =1
EM—Maximization
t Q θ , θ 对E步计算得到的完整似然函数的期望 ( )求 极大值(Maximization),得到参数新的估计值, 即 t +1 t
θ
= arg max Q (θ , θ
θ
)
每次参数更新会增大似然(非完整似然)值 反复迭代后,会收敛到似然的局部极大值
涉及求和的log运算,计算困难
完整似然函数
若隐含变量的值 Y = (Y1 ,..., Yn ) 也已知,得到完整 数据的似然函数为:
n n i =1 i =1
log (L (θ | X , Y )) = log ∏ f ( X i , Yi | θ ) = ∑ log ( f ( X i , Yi | θ ))
EM算法(坐标上升算法)

EM算法(坐标上升算法)⼗⼤算法之⼀:EM算法。
能评得上⼗⼤之⼀,让⼈听起来觉得挺NB的。
什么是NB啊,我们⼀般说某个⼈很NB,是因为他能解决⼀些别⼈解决不了的问题。
神为什么是神,因为神能做很多⼈做不了的事。
那么EM算法能解决什么问题呢?或者说EM算法是因为什么⽽来到这个世界上,还吸引了那么多世⼈的⽬光。
我希望⾃⼰能通俗地把它理解或者说明⽩,但是,EM这个问题感觉真的不太好⽤通俗的语⾔去说明⽩,因为它很简单,⼜很复杂。
简单在于它的思想,简单在于其仅包含了两个步骤就能完成强⼤的功能,复杂在于它的数学推理涉及到⽐较繁杂的概率公式等。
如果只讲简单的,就丢失了EM算法的精髓,如果只讲数学推理,⼜过于枯燥和⽣涩,但另⼀⽅⾯,想把两者结合起来也不是件容易的事。
所以,我也没法期待我能把它讲得怎样。
希望各位不吝指导。
⼀、最⼤似然扯了太多,得⼊正题了。
假设我们遇到的是下⾯这样的问题:假设我们需要调查我们学校的男⽣和⼥⽣的⾝⾼分布。
你怎么做啊?你说那么多⼈不可能⼀个⼀个去问吧,肯定是抽样了。
假设你在校园⾥随便地活捉了100个男⽣和100个⼥⽣。
他们共200个⼈(也就是200个⾝⾼的样本数据,为了⽅便表⽰,下⾯,我说“⼈”的意思就是对应的⾝⾼)都在教室⾥⾯了。
那下⼀步怎么办啊?你开始喊:“男的左边,⼥的右边,其他的站中间!”。
然后你就先统计抽样得到的100个男⽣的⾝⾼。
假设他们的⾝⾼是服从⾼斯分布的。
但是这个分布的均值u和⽅差∂2我们不知道,这两个参数就是我们要估计的。
记作θ= [u, ∂]T。
⽤数学的语⾔来说就是:在学校那么多男⽣(⾝⾼)中,我们独⽴地按照概率密度p(x|θ)抽取100了个(⾝⾼),组成样本集X,我们想通过样本集X来估计出未知参数θ。
这⾥概率密度p(x|θ)我们知道了是⾼斯分布N(u,∂)的形式,其中的未知参数是θ=[u, ∂]T。
抽到的样本集是X={x1,x2,…,x N},其中x i表⽰抽到的第i个⼈的⾝⾼,这⾥N就是100,表⽰抽到的样本个数。
一文让你完全入门EM算法

一文让你完全入门EM算法重磅干货,第一时间送达EM(Expectation Maximum,期望最大化)是一种迭代算法,用于对含有隐变量概率参数模型的极大似然估计或极大后验估计。
模型参数的每一次迭代,含有隐变量概率参数模型的似然函数都会增加,当似然函数不再增加或增加的值小于设置的阈值时,迭代结束。
EM算法在机器学习和计算机视觉的数据聚类领域有广泛的应用,只要是涉及到后验概率的应用,我们都可以考虑用EM算法去解决问题。
EM算法更像是一种数值分析方法,正确理解了EM算法,会增强你机器学习的自学能力,也能让你对机器学习算法有新的认识,本文详细总结了EM算法原理。
目录1. 只含有观测变量的模型估计2. 含有观测变量和未观测变量的模型参数估计3. EM算法流程4. 抛硬币问题举例5. 高斯混合模型的参数估计6. 聚类蕴含的EM算法思想7. 小结1. 只含有观测变量的模型估计我们首先考虑比较简单的情况,即模型只含有观测变量不含有隐藏变量,如何估计模型的参数?我们用逻辑斯蒂回归模型(logistic regression model)来解释这一过程。
假设数据集有d维的特征向量X和相应的目标向量Y,其中,。
下图表示逻辑斯蒂回归模型:由之前的文章介绍,逻辑斯蒂回归模型的目标预测概率是S型函数计算得到,定义为:若,则目标预测变量为1;反之,目标预测变量为0。
其中w是待估计的模型参数向量。
机器学习模型的核心问题是如何通过观测变量来构建模型参数w,最大似然方法是使观测数据的概率最大化,下面介绍用最大似然方法(Maximum Likelihood Approach)求解模型参数w。
假设数据集,样本数据,模型参数。
观测数据的对数似然函数可写为:由对数性质可知,上式等价于:式(1)代入式(2),得:其中:由于(3)式是各个样本的和且模型参数间并无耦合,因此用类似梯度上升的迭代优化算法去求解模型参数w。
因为:由式(4)(5)(6)可得:因此,模型参数w的更新方程为:其中η是学习率。
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
EM算法实验报告一、算法简单介绍EM 算法是Dempster,Laind,Rubin于1977年提出的求参数极大似然估计的一种方法,它可以从非完整数据集中对参数进行MLE估计,是一种非常简单实用的学习算法。
这种方法可以广泛地应用于处理缺损数据、截尾数据以及带有噪声等所谓的不完全数据,可以具体来说,我们可以利用EM算法来填充样本中的缺失数据、发现隐藏变量的值、估计HMM中的参数、估计有限混合分布中的参数以及可以进行无监督聚类等等。
本文主要是着重介绍EM算法在混合密度分布中的应用,如何利用EM算法解决混合密度中参数的估计。
二、算法涉及的理论我们假设X是观测的数据,并且是由某些高斯分布所生成的,X是包含的信息不完整(不清楚每个数据属于哪个高斯分布)。
,此时,我们用k维二元随机变量Z(隐藏变量)来表示每一个高斯分布,将Z引入后,最终得到:,,然而Z的后验概率满足(利用条件概率计算):但是,Z nk为隐藏变量,实际问题中我们是不知道的,所以就用Z nk的期望值去估计它(利用全概率计算)。
然而我们最终是计算max:最后,我们可以得到(利用最大似然估计可以计算):三、算法的具体描述3.1 参数初始化对需要估计的参数进行初始赋值,包括均值、方差、混合系数以及。
3.2 E-Step计算利用上面公式计算后验概率,即期望。
3.3 M-step计算重新估计参数,包括均值、方差、混合系数并且估计此参数下的期望值。
3.4 收敛性判断将新的与旧的值进行比较,并与设置的阈值进行对比,判断迭代是否结束,若不符合条件,则返回到3.2,重新进行下面步骤,直到最后收敛才结束。
四、算法的流程图五、实验结果a_best=0.8022 0.1978mu_best=2.71483.93074.9882 3.0102 cov_best=(:,:,1) =5.4082 -0.0693-0.0693 0.2184(:,:,2) =0.0858 -0.0177-0.0177 0.0769f=-1.6323数据X的分布每次迭代期望值-50510利用EM估计的参量值与真实值比较(红色:真实值青绿色:估计值)六、参考文献1.M. Jordan. Pattern Recognition And Machine Learning2.Xiao Han. EM Algorithm七、附录close all;clear;clc;% 参考书籍Pattern.Recognition.and.Machine.Learning.pdf% % lwm@% 2009/10/15%%M=2; % number of GaussianN=200; % total number of data samplesth=0.000001; % convergent thresholdK=2; % demention of output signal% 待生成数据的参数a_real =[4/5;1/5];mu_real=[3 4;5 3];cov_real(:,:,1)=[5 0;0 0.2];cov_real(:,:,2)=[0.1 0;0 0.1];% generate the datax=[ mvnrnd( mu_real(:,1) , cov_real(:,:,1) , round(N*a_real(1)) )' , mvnrnd(mu_real(:,2),cov_real(:,:,2),N-round(N*a_real(1)))'];% for i=1:round(N*a_real(1))% while (~((x(1,i)>0)&&(x(2,i)>0)&&(x(1,i)<10)&&(x(2,i)<10)))% x(:,i)=mvnrnd(mu_real(:,1),cov_real(:,:,1),1)';% end% end%% for i=round(N*a_real(1))+1:N% while (~((x(1,i)>0)&&(x(2,i)>0)&&(x(1,i)<10)&&(x(2,i)<10)))% x(:,i)=mvnrnd(mu_real(:,1),cov_real(:,:,1),1)';% end% endfigure(1),plot(x(1,:),x(2,:),'.')%这里生成的数据全部符合标准%% %%%%%%%%%%%%%%%% 参数初始化a=[1/3,2/3];mu=[1 2;2 1];%均值初始化完毕cov(:,:,1)=[1 0;0 1];cov(:,:,2)=[1 0;0 1];%协方差初始化%% EM Algorothm% loopcount=0;figure(2),hold onwhile 1a_old = a;mu_old = mu;cov_old= cov;rznk_p=zeros(M,N);for cm=1:Mmu_cm=mu(:,cm);cov_cm=cov(:,:,cm);for cn=1:Np_cm=exp(-0.5*(x(:,cn)-mu_cm)'/cov_cm*(x(:,cn)-mu_cm));rznk_p(cm,cn)=p_cm;endrznk_p(cm,:)=rznk_p(cm,:)/sqrt(det(cov_cm));endrznk_p=rznk_p*(2*pi)^(-K/2);%E step%开始求rznkrznk=zeros(M,N);%r(Zpikn=zeros(1,M);%r(Zpikn_sum=0;for cn=1:Nfor cm=1:Mpikn(1,cm)=a(cm)*rznk_p(cm,cn);% pikn_sum=pikn_sum+pikn(1,cm);endfor cm=1:Mrznk(cm,cn)=pikn(1,cm)/sum(pikn);endend%求rank结束% M stepnk=zeros(1,M);for cm=1:Mfor cn=1:Nnk(1,cm)=nk(1,cm)+rznk(cm,cn);endenda=nk/N;rznk_sum_mu=zeros(M,1);% 求均值MUfor cm=1:Mrznk_sum_mu=0;%开始的时候就是错在这里,这里要置零。
for cn=1:Nrznk_sum_mu=rznk_sum_mu+rznk(cm,cn)*x(:,cn);endmu(:,cm)=rznk_sum_mu/nk(cm);end% 求协方差COVfor cm=1:Mrznk_sum_cov=zeros(K,M);for cn=1:Nrznk_sum_cov=rznk_sum_cov+rznk(cm,cn)*(x(:,cn)-mu(:,cm))*(x(:,cn)-mu(:,cm))';endcov(:,:,cm)=rznk_sum_cov/nk(cm);endt=max([norm(a_old(:)-a(:))/norm(a_old(:));norm(mu_old(:)-mu(:))/norm(mu_old(:));norm(cov_ol d(:)-cov(:))/norm(cov_old(:))]);temp_f=sum(log(sum(pikn)));plot(count,temp_f,'r+')count=count+1;if t<thbreak;endend %while 1hold offf=sum(log(sum(pikn)));a_best=a;mu_best=mu;cov_best=cov;f_best=f;% 输出结果disp('a_best=');disp(a_best);disp('mu_best=');disp(mu_best);disp('cov_best=');disp(cov_best);disp('f=');disp(f);figure(3),hold onplot(x(1,:),x(2,:),'.');plot(mu_real(1,:),mu_real(2,:),'*r');plot(mu_best(1,:),mu_best(2,:),'+c');hold offclear allclcx1(1)=0.2000;x2(1)=0.8000;y1(1)=2.0000;y2(1)=1.0000;z1(1)=0.0000;z2(1)=2;N=1000;for j=1:Nif rand(1)<0.4a(j)=random('Normal',0,1,1,1) elsea(j)=random('Normal',2,2,1,1) endendfor i=1:50W1=0;W2=0;W3=0;W4=0;for j=1:Np1=(normpdf(a(j),y1(i),z1(i)))*x1(i);p2=(normpdf(a(j),y2(i),z2(i)))*x2(i);w1(j)=p1/(p1+p2);w2(j)=p1/(p1+p2);W1=w1(j)+W1;W2=w2(j)+W2;W3=(w1(j)*a(j)+W3);W4=(w2(j)*a(j)+W4);endx1(i+1)=W1/N;x2(i+1)=W2/N;y1(i+1)=(W3/(N*x1(i+1)));y2(i+1)=(W4/(N*x2(i+1)));W5=0;W6=0;for j=1:NW5=(w1(j)*(a(j)-y1(i+1).^2)+W5);W6=(w2(j)*(a(j)-y2(i+1).^2)+W6); endz1(i+1)=sqrt(W5/(N*x1(i+1)));z2(i+1)=sqrt(W6/(N*x2(i+1)));end。