spss课后作业答案
《统计分析与SPSS的应用》课后练习答案

《统计分析与SPSS的应用》课后练习答案在学习《统计分析与 SPSS 的应用》这门课程后,通过课后练习能够帮助我们更好地掌握所学知识,并将其应用到实际的数据分析中。
以下是针对部分课后练习的答案及解析。
一、选择题1、在 SPSS 中,用于描述数据集中变量分布特征的统计量是()A 均值B 标准差C 中位数D 众数答案:ABCD解析:均值、标准差、中位数和众数都是描述数据分布特征的常用统计量。
均值反映了数据的集中趋势;标准差反映了数据的离散程度;中位数是将数据排序后位于中间位置的数值;众数则是数据集中出现次数最多的数值。
2、进行独立样本 t 检验时,需要满足的前提条件是()A 样本来自正态分布总体B 两样本方差相等C 两样本相互独立D 以上都是答案:D解析:独立样本 t 检验要求样本来自正态分布总体、两样本方差相等以及两样本相互独立。
只有在这些条件满足的情况下,t 检验的结果才是可靠的。
3、以下哪种方法适用于多组数据的比较()A 单因素方差分析B 配对样本 t 检验C 相关分析D 回归分析答案:A解析:单因素方差分析用于比较三个或三个以上组别的数据是否存在显著差异。
配对样本 t 检验适用于配对数据的比较;相关分析用于研究变量之间的线性关系;回归分析用于建立变量之间的预测模型。
二、简答题1、请简述 SPSS 中数据录入的基本步骤。
答:SPSS 中数据录入的基本步骤如下:(1)打开 SPSS 软件,选择“新建数据文件”。
(2)在变量视图中定义变量的名称、类型、宽度、小数位数等属性。
(3)切换到数据视图,按照定义好的变量逐行录入数据。
(4)录入完成后,保存数据文件。
2、解释相关分析和回归分析的区别。
答:相关分析主要用于研究两个或多个变量之间的线性关系程度和方向,但它并不确定变量之间的因果关系。
相关分析的结果通常用相关系数来表示,如皮尔逊相关系数。
回归分析则不仅可以确定变量之间的关系,还可以建立数学模型来预测因变量的值。
统计学spss课后题答案

实操训练答案目录第一章 (1)第二章 (2)第三章 (3)第四章 (4)第五章 (7)第六章 (10)第七章 (17)第八章 (21)第九章 (26)第十章 (31)第一章(一)思考题略(二)练习题1.(1)定类变量(2)定类变量(3)定序变量(4)数值型变量(5)数值型变量2. A3. B4. A B C D5. D A6. A B(三)操作题略1第二章(一)思考题略(二)练习题1. BD AC2. C3. D4. D5. A(三)操作题1. 见SPSS文件2.1.sav。
2. 略。
3. 略。
4. 略。
第三章1. 2011年人均国内生产总值(agdp2011),排在前五位的是天津、上海、北京、江苏、浙江;排在后五位的是广西、西藏、甘肃、云南、贵州。
. 2011年国内生产总值(gdp2011),在东部各省市里,排在第1位的是广东,排在最后1位的分别是海南;在中部各省市里,排在第1位的是河南,排在最后1位的分别是吉林;在西部各省市里,排在第1位的是四川,排在最后1位的分别是西藏。
2. 见SPSS文件3.2.sav。
3. 见SPSS文件3.3.sav。
4. A老师提供的管理学成绩见SPSS文件3.4-1.sav,B老师提供的经济学成绩见SPSS文件3.4-2.sav,合并后的文件见SPSS文件3.4.sav。
5. 见SPSS文件3.5.sav。
6. 见SPSS文件3.6.sav。
7. 见SPSS文件3.7.sav。
8. 见SPSS文件3.8.sav。
9. 两门课程都在80分以上的共4人,见SPSS文件3.5.sav。
10. 管理学成绩在80-89,经济学成绩在90分以上的只有1人,见SPSS文件3.6.sav。
第四章1. 由于变量品牌(brand)是定类变量,所以分别用众数和异众比来描述其集中趋势和离散趋势。
由分析结果可知,众数是B,异众比是(800-279)/800=65.1%。
统计量品牌N 有效800缺失0众数 2品牌频率百分比有效百分比累积百分比有效 A 164 20.5 20.5 20.5B 279 34.9 34.9 55.4C 110 13.8 13.8 69.1D 55 6.9 6.9 76.0E 192 24.0 24.0 100.0合计800 100.0 100.02.由于变量《统计学》这门课程难吗(v2.4)是定序变量,所以用众数,中位数,四分位数来描述其集中趋势,用四分位差来描述其离散趋势。
第4章 SPSS基本统计分析(课后练习参考)

第4章 SPSS基本统计分析(课后练习参考)1、利用习题二第6题数据,采用SPSS数据筛选功能将数据分成两份文件。
其中,第一份数据文件存储常住地是“沿海或中心繁华城市”且本次存款金额在1000至5000之间的调查数据;第二份数据文件是按照简单随机抽样所选取的70%的样本数据。
第一份文件:选取数据数据——选择个案——如果条件满足——存款>=1000&存款<5000&常住地=沿海或中心繁华城市。
第二份文件:选取数据数据——选择个案——随机个案样本——输入70。
2、利用习题二第6题数据,将其按常住地(升序)、收入水平(升序)、存款金额(降序)进行多重排序。
排序数据——排序个案——把常住地、收入水平、存款金额作为排序依据分别设置排列顺序。
3、利用习题二第4题的完整数据,对每个学生计算得优课程数和得良课程数,并按得优课程数的降序排序。
计算转换——对个案内的值计数输入目标变量及目标标签,把所有课程选取到数字变量,定义值——设分数的区间,之后再排序。
4、利用习题二第4题的完整数据,计算每个学生课程的平均分以及标准差。
同时,计算男生和女生各科成绩的平均分。
方法一:利用描述性统计,数据——转置学号放在名称变量,全部课程放在变量框中,确定后,完成转置。
分析——描述统计——描述,将所有学生变量全选到变量框中,点击选项——勾选均值、标准差。
先拆分数据——拆分文件按性别拆分,分析——描述统计——描述,全部课程放在变量框中,选项——均值。
方法二:利用变量计算,转换——计算变量分别输入目标变量名称及标签——均值用函数mean完成平均分的计算,标准差用函数SD完成标准差的计算。
数据——分类汇总——性别作为分组变量、全部课程作为变量摘要、(创建只包含汇总变量的新数据集并命名)——确定5、利用习题二第6题数据,大致浏览存款金额的数据分布状况,并选择恰当的组限和组距进行组距分组。
根据存款金额排序,观察其最大值与最小值,算出组数和组距。
SPSS课后作业答案

SPSS课后作业答案⼀、描述性统计分析:FrequenciesStatistics 2222220Valid MissingNPackage designPriceBrand nameFrequency TablePackage design940.940.940.9627.327.368.2731.831.8100.0 22100.0100.0A*B*C*TotalValidFrequencyPercentValid PercentCum ulativ e PercentPrice836.436.436.4627.327.363.6836.436.4100.0 22100.0100.0$1.19 $1.39$1.59TotalValidFrequencyPercentValid PercentCum ulative PercentBrand name731.831.831.8731.831.863.6836.436.4100.0 22100.0100.0K2R Glory Bissell TotalValidFrequencyPercentValid PercentCum ulative PercentFrequenciesStatistics2222001.3636 1.27271.0000 1.00001.00 1.00.49237.45584.242.2081.00 1.001.00 1.002.00 2.00Valid MissingNMean Median ModeStd. Deviation Variance Range Minim um MaximumGood Housek ee ping sealMoney-back guaranteeMeansCase P rocessing Summary22100.0%0.0%22100.0%Preference * Brand nam eN PercentN PercentNPercentIncludedExcluded Total CasesReportPreference 9.00007 6.7577113.00007 5.0990212.250087.3436111.4545226.44188Brand name K2R Glory Bissell TotalMean NStd. Deviation结果解释:(1)statistics 表显⽰了变量package design,price 和 brand name 都有22个有效观测值。
数据分析课后答案spss

1习题1.3統計資料全国居民 N有效 22 遺漏0 平均數 1117.00 中位數 727.50 標準偏差 1015.717 變異數 1031680.286偏斜度 1.025 偏斜度標準誤 .491 峰度 -.457 峰度標準誤 .953 百分位數25 304.25 50 727.50 751893.50(1).由表可知,全国居民的均值、方差、标准差、偏度、峰度分别为1117.00、1031680.286、1015.717、1.025、-0.457。
变异系数有公式计算得90.9325。
(2)中位数为727.50,上四分位数304.35,下四分位数为1893.50。
四分位极差由公式得到1579.15三均值由公式得到913.1857。
(3)直方图(%)*100cv _x s=131Q Q R -=31412141Q M Q M ++=∧(4)茎叶图全国居民Stem-and-Leaf Plot Frequency Stem & Leaf9.00 0 . 1222233445.00 0 . 567882.00 1 . 031.00 1 . 71.00 2 . 33.00 2 . 6891.00 3 . 1Stem width: 1000Each leaf: 1 case(s)(5)由箱图可以看出并不异常点。
統計資料农村居民N有效22遺漏0平均數747.86中位數530.50標準偏差632.198變異數399673.838偏斜度 1.013偏斜度標準誤.491峰度-.451峰度標準誤.953百分位數25239.7550530.50751197.00(1).由图可知农村居民的平均数、方差、标准差、偏度、峰度分别为747.86、399673.838、632.198、1.013、-0.451。
由公式可以算得变异系数为84.5342。
(2)中位数530.50,上四分位数239.75,下四分位数1197.00。
《统计分析与SPSS的应用》课后练习答案
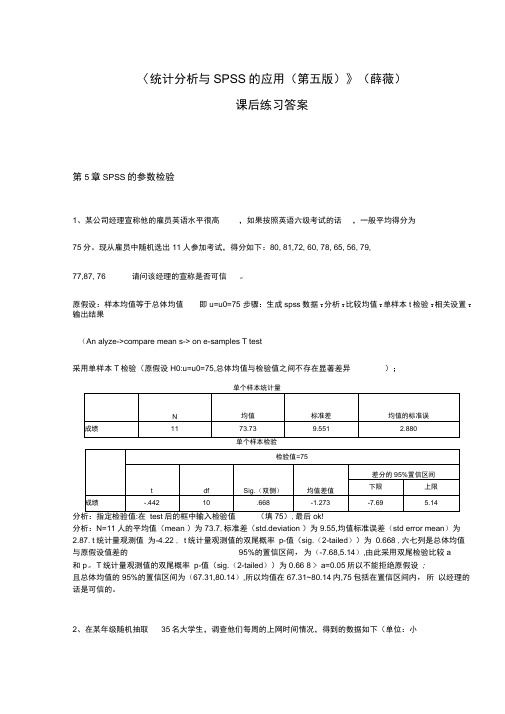
〈统计分析与SPSS的应用(第五版)》(薛薇)课后练习答案第5章SPSS的参数检验1、某公司经理宣称他的雇员英语水平很高,如果按照英语六级考试的话,一般平均得分为75分。
现从雇员中随机选出11人参加考试,得分如下:80, 81,72, 60, 78, 65, 56, 79,77,87, 76 请问该经理的宣称是否可信。
原假设:样本均值等于总体均值即u=u0=75 步骤:生成spss数据T分析T比较均值T单样本t检验T相关设置T 输出结果(An alyze->compare mean s-> on e-samples T test采用单样本T检验(原假设H0:u=u0=75,总体均值与检验值之间不存在显著差异);分析:N=11人的平均值(mean )为73.7,标准差(std.deviation )为9.55,均值标准误差(std error mean)为2.87. t统计量观测值为-4.22 , t统计量观测值的双尾概率p-值(sig.(2-tailed))为0.668 ,六七列是总体均值与原假设值差的95%的置信区间,为(-7.68,5.14),由此采用双尾检验比较a和p。
T统计量观测值的双尾概率p-值(sig.(2-tailed))为0.66 8 > a=0.05所以不能拒绝原假设;且总体均值的95%的置信区间为(67.31,80.14),所以均值在67.31~80.14内,75包括在置信区间内,所以经理的话是可信的。
2、在某年级随机抽取35名大学生,调查他们每周的上网时间情况,得到的数据如下(单位:小(1) 请利用SPSS 对上表数据进行描述统计,并绘制相关的图形。
(2)基于上表数据,请利用SPSS 给出大学生每周上网时间平均值的 9 5%的置信区间。
(1)分析描述统计描述、频率 (2)分析 比较均值 单样本T 检验每周上网时间的样本平均值为 27.5 ,标准差为10.7,总体均值95%的置信区间为23.8-31.2.3、经济学家认为决策者是对事实做出反应 ,不是对提出事实的方式做出反应 。
spss课后作业答案

SPSS课后作业第一章1-1、spss的运行方式有几种?分别是什么?答:SPSS的运行方式有三种,分别是批处理方式、完全窗口菜单运行方式、程序运行方式。
1-2、SPSS中“DataView”所对应的表格与一般的电子处理软件有什么区别?答:与一般电子表格处理软件相比,SPSS的“Data View”窗口还有以下一些特性:(1)一个列对应一个变量,即每一列代表一个变量(Variable)或一个被观测量的特征;(2)行是观测,即每一行代表一个个体、一个观测、一个样品,在SPSS中称为事件(Case);(3)单元包含值,即每个单元包括一个观测中的单个变量值;(4)数据文件是一张长方形的二维表。
第二章2-1、在SPSS中可以使用那些方法输入数据?答:SPSS中输入数据一般有以下三种方式:(1)通过手工录入数据;(2)可以将其他电子表格软件中的数据整列(行)的复制,然后粘贴到SPSS中;(3)通过读入其他格式文件数据的方式输入数据。
2-2、对于缺失值,如何利用SPSS进行科学替代?答:选择“Transform”菜单的Replace Missing Values命令,弹出Replace Missing Values 对话框。
先在变量名列中选择1个或多个存在缺失值的变量,使之添加到“New Variable(s)”框中,这时系统自动产生用于替代缺失值的新变量。
最后选择合适的替代方式即可。
2-3、在计算数据的加权平均数时,如何对变量进行加权?答:选择“Data”菜单中的Weight Cases命令,出现如图2-22所示的Weight Cases对话框。
其中, Do not weight cases项表示不做加权,这可用于取消加权;Weight cases by 项表示选择1个变量做加权。
2-4、如何对变量进行自动赋值?答:变量的自动赋值可以将字符型、数字型数值转变成连续的整数,并将结果保存在一个新的变量中。
具体操作的过程如下:选择“Transform”菜单中的Automatic Recode命令,在出现的对话框中,从左边的变量列表中选择需要自动赋值的变量,将它添加到Variable -> New Name框中,然后在下面New Name右边的文本框中输入新的变量名称,单击New Name 按钮,将新的变量名添加到上面的框中。
spss课后作业——方差分析(答案)

spss课后作业——方差分析(答案)1. 不同岗位的平均工资问题,用方差分析的方法分析一线工人、科以上干部、一般干部三类职工的当前平均工资有无显著差异。
(见岗位工资.sav)要求:1.进行方差齐次性检验。
2.输出描述统计量表。
3.输出方差分析表(要求对组间平方和进行线性分解)。
4.进行均值的多重比较,方差相等时,用LSD方法;方差不等时,用Tamhane’s T2方法。
5.进行均值多项式比较。
均值系数coefficients的选择为(-1,1,-1)答:表1 描述统计量表此表说明略。
Oneway表2表2是方差齐次性检验结果。
该检验的F统计量的值为10.512,对应的概率p值=0<0.05,说明三组数据不具有方差齐性表3 方差分析结果表3是方差分析的主要结果。
从中可以看出,组间离差平方和为42070380885,组内离差平方和为52166613580.8,总的离差平方和为94236994465.8。
第一个P值P=0,小于显著水平0.05,故认为三类职工的当前平均工资存在显著差异。
对组间平方和进行线性分解,其中可以被线性解释的部分为437435223.343,不能被线性解释的部分为41632945661.7,第三个概率P值0.082来看,0.082>0.05,故不能认为当前平均工资受职工类别的线性影响是显著的。
表4 多项式比较系数表4显示输入的所要比较的各值均值的系数。
该系数表明将要检验的是mean2-(mean1+mean3)的值和0有无显著差异。
表5 多项式比较检验表5是多项式比较检验的结果。
在(-1,1,-1)的系数下,由于本题是各总体方差不等的情况,故应该看第二行的分析结果。
概率P值为0.001,小于显著水平0.05,故拒绝零假设,即认为科以上干部的当前平均工资(mean2)与其余两类职工的当前平均工资的和(mean1+mean3)有显著差异。
科以上干部的当前平均工资比其余两类职工的当前平均工资的和还要高。
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
SPSS课后作业第一章1-1、spss的运行方式有几种?分别是什么?答:SPSS的运行方式有三种,分别是批处理方式、完全窗口菜单运行方式、程序运行方式。
1-2、SPSS中“DataView”所对应的表格与一般的电子处理软件有什么区别?答:与一般电子表格处理软件相比,SPSS的“Data View”窗口还有以下一些特性:(1)一个列对应一个变量,即每一列代表一个变量(Variable)或一个被观测量的特征;(2)行是观测,即每一行代表一个个体、一个观测、一个样品,在SPSS中称为事件(Case);(3)单元包含值,即每个单元包括一个观测中的单个变量值;(4)数据文件是一张长方形的二维表。
第二章2-1、在SPSS中可以使用那些方法输入数据?答:SPSS中输入数据一般有以下三种方式:(1)通过手工录入数据;(2)可以将其他电子表格软件中的数据整列(行)的复制,然后粘贴到SPSS中;(3)通过读入其他格式文件数据的方式输入数据。
2-2、对于缺失值,如何利用SPSS进行科学替代?答:选择“Transform”菜单的Replace Missing Values命令,弹出Replace Missing Values 对话框。
先在变量名列中选择1个或多个存在缺失值的变量,使之添加到“New Variable(s)”框中,这时系统自动产生用于替代缺失值的新变量。
最后选择合适的替代方式即可。
2-3、在计算数据的加权平均数时,如何对变量进行加权?答:选择“Data”菜单中的Weight Cases命令,出现如图2-22所示的Weight Cases对话框。
其中, Do not weight cases项表示不做加权,这可用于取消加权;Weight cases by 项表示选择1个变量做加权。
2-4、如何对变量进行自动赋值?答:变量的自动赋值可以将字符型、数字型数值转变成连续的整数,并将结果保存在一个新的变量中。
具体操作的过程如下:选择“Transform”菜单中的Automatic Recode命令,在出现的对话框中,从左边的变量列表中选择需要自动赋值的变量,将它添加到Variable -> New Name框中,然后在下面New Name右边的文本框中输入新的变量名称,单击New Name 按钮,将新的变量名添加到上面的框中。
从Recode Starting from框中有两个选项中选择一个,然后单击OK按钮,即可完成自动赋值运算。
3-1、一组数据的分布特征可以从哪几个方面进行测度?答:一组数据的分布特征可以从平均数、中位数、众数、方差、百分位、频数、峰度、偏度等方面描述。
3-2、简述众数、中位数和均值的特点及应用场合。
答:均值是总体各单位某一数量标志的平均数。
平均数可应用于任何场合,比如在简单时序预测中可用一定观察期内预测目标的时间序列的均值作为下一期的预测值。
中位数是指将数据按大小顺序排列起来,形成一个数列,居于数列中间位置的那个数据。
中位数的作用与算术平均数相近,也是作为所研究数据的代表值。
在一个等差数列或一个正态分布数列中,中位数就等于算术平均数。
在数列中出现了极端变量值的情况下,用中位数作为代表值要比用算术平均数更好,因为中位数不受极端变量值的影响。
众数是指一组数据中出现次数最多的那个数据。
它主要用于定类(品质标志)数据的集中趋势,当然也适用于作为定序(品质标志)数据以及定距和定比(数量标志)数据集中趋势的测度值。
3-3、(1)由题,用spss导出结果:Statistics日销售额N Valid 30Missing 0Mean 277.40Median 277.00Percentiles 25 256.0050 277.0075 301.00可知,该百货公司日销售额的均值为277.40万元,中位数为277万元,四分位数为256万元。
(2)由题,用spss导出结果:Statistics日销售额N Valid 30Missing 028.246Std.Deviation可知,日销售额的标准差为28.246万元。
3-4、(1)答:应采用方差、标准差来比较成年组和幼儿组的身高差异。
(2)由题,用spss导出结果:Statistics成人组身高幼儿组身高N Valid 10 10Missing 0 04.158 2.404Std.DeviationVariance 17.289 5.778可知,成人组方差及标准差都大于幼儿组,故成人组的身高差异较大。
4-1、如何检验某个单一样本某变量的总体均值和指定值之间是否存在显著差异?答:通过单一样本T检验可以检验某个单一样本某变量的总体均值与指定值之间是否存在显著差异。
4-2、如何对两个独立样本进行均值差异检验?答:对两个独立样本进行均值差异检验需要通过两步来完成:第一,利用F检验判断两总体的方差是否相同;第二,根据第一步的结果,决定T统计量和自由度计算公式,进而对T 检验的结论作出判断。
4-3、对两配对样本进行T检验的前提要求是什么?答:两配对样本T检验的前提要求是:两个样本应是配对的且样本来自的两个总体应服从正态分布。
4-4、(1)由题,用spss导出结果:Statistics用药前用药后N Valid 6 6Missing 0 0Mean 124.67 118.67Variance 175.467 331.867可知,治疗前这六名病人的均值为124.67,方差为175.467,用药后的均值为118.67,方差为331.867,可见治疗后均值降低,而方差变大。
(2)用配对样本T检验方法进行检验,导出数据:可知,伴随概率为0.337,大于显著性水平0.05,因而接受原假设,即治疗前后没有显著的变化。
4-5、用两独立样本T检验进行检验,导出数据:数学Equal variances assumed 3.006 13.2942.990 13.310Equal variances notassumed可知,甲乙两个班级学生的数学成绩方差无显著性差异,而这两个班级的学生数学成绩均值之间有差异,甲班成绩要高于乙班同学的数学成绩。
5-1、如何检验两个及两个以上样本均数之间是否存在显著差异?答:方差分析可以用来检验两个及两个以上样本均数之间是否存在显著差异。
5-2、进行多因素方差分析时为什么要将观察变量总的离差平方和分解为3个部分?答:因为多因素方差分析不仅需要分析多个控制变量独立作用对观察变量的影响,还要分析多个控制变量交互作用对观察变量的影响,及其他随机变量对结果的影响。
因此,它需要将观察变量总的离差平方和分解为3个部分。
5-3、什么是协方差分析?什么情况适于使用协方差分析?答:协方差分析是将那些很难控制的因素作为协变量,在排除协变量影响的条件下,分析控制变量对观察变量的影响,从而更加准确地对控制因素进行评价。
当有一些很难控制的随机变量时,可以使用协方差分析将这些随机变量作为协变量。
5-4、用单因素方差检验进行检验,导出结果:Test of Homogeneity of Variances肺活量LeveneStatistic df1 df2 Sig..408 2 26 .669ANOVA肺活量Sum of Squares df Mean Square Between Groups (Combined) 10.919 2 5.460 Linear Term Unweighted 10.804 1 10.804Weighted 10.804 1 10.804Deviation .115 1 .115Within Groups 1.462 26 .056Total 12.381 28ANOVA肺活量F Sig.Between Groups (Combined) 97.103 .000Linear Term Unweighted 192.160 .000Weighted 192.160 .000Deviation 2.045 .165 Post Hoc TestsHomogeneous Subsets肺活量组别Subset for alpha = 0.05 N 1 2 3Student-Newman-Keuls a,,b病10 1.6900可疑9 2.2889非10 3.1600Sig. 1.000 1.000 1.000 Means for groups in homogeneous subsets are displayed.a. Uses Harmonic Mean Sample Size = 9.643.b. The group sizes are unequal. The harmonic mean of the group sizes is used. Type I error levels are not guaranteed.Means Plots由上可知,患者,可疑患者和非患者三个组的总体方差是相等的,也就具备了进行方差检验的条件,从单因素方差检验结果看,这三个组之间存在着显著差异。
5-5、主体间效应的检验因变量:治疗后的血压源III 型平方和df 均方 F Sig.校正模型603.203a 3 201.068 .831 .499截距2461.484 1 2461.484 10.174 .007治疗前的血压150.425 1 150.425 .622 .444组别551.519 2 275.759 1.140 .348误差3387.075 14 241.934总计314725.000 18校正的总计3990.278 17a. R 方 = .151(调整 R 方 = -.031)F值和相伴概率分别为1.140和0.348。
这说明不同的治疗方法没有对血压造成显著影响。
协变量作用部分:这里治疗前的血压的离差平方和150.425,均方为150.425。
F值和相伴概率分别为0.622和0.444,表明协变量没有对观察结果造成显著影响。
成对样本检验成对差分t df Sig. (双侧)均值标准差均值的标准误差分的 95% 置信区间下限上限对 1 治疗前的血压 - 治疗后的血压39.44424.064 5.672 27.478 51.411 6.95417 .0000.05,说明治疗前后血压值有了明显变化,治疗后的血压比治疗前的低。
综上:这三个组别的接受治疗的患者在接受治疗之前各组之间没有显着性差异,在接受治疗之后,三个组别之间仍然没有显着性差异。
但是通过配对样本的T检验得知,用这三种治疗方法进行治疗的患者在治疗前后血压都有有显着性差异,也即是说三种治疗方法都是有效的,并且彼此之间差别不显着。
6-1、什么是相关分析?常用的方法有哪些?答:衡量事物之间,或称变量之间线性相关程度的强弱并用适当的统计指标表示出来,这个过程就是相关分析。