大学课程《编译原理》考试试卷A卷及答案
编译原理期末考试试卷A卷

试卷答题时限:120 分钟考试形式:闭卷笔试一、单项选择题(请从4个备选答案中选择最适合的一项,每小题2分,共20注意:须将本题答案写在下面的表格中,写在其它地方无效1. 编译程序是对()A. 汇编程序的翻译B。
高级语言程序的解释执行C. 机器语言的执行D. 高级语言的翻译2。
词法分析器的输出结果是()A.单词的种别编码B.单词在符号表中的位置C.单词的种别编码和自身值D.单词自身值3.在规范规约中,用()来刻画可规约串.A.直接短语B.句柄C.最左素短语D.素短语4。
与正规式(a* |b)*(c |d)等价的正规式是()A.a*(c |d)|b(c |d) B.a*(c |d) * | b(c |d)*C.a*(c | d)| b*(c |d) D.(a | b) * c|(a |b)*d5. 若项目集I K含有A→α·,则在状态K时,仅当面临输入符号a∈FOLLOW(A)时,才采取A→α·动作的一定是()A.LALR文法B.LR(0) 文法C.LR(1)文法D.SLR(1)文法6。
四元式之间的联系是通过()实现的。
A. 指示器B。
临时变量C。
符号表D. 程序变量7.文法G:S → x Sx|y所识别的语言是()A.xyx B.(xyx)*C.x n yx n(n≥0)D.x*yx*8.有一语法制导翻译如下所示:S → b Ab {print “1”}A→(B {print “2”}A→a {print “3"}B→Aa) {print “4”}若输入序列为b(((aa)a)a)b,且采用自下而上的分析方法,则输出序列为()A.32224441 B. 34242421 C.12424243 D。
344422129.关于必经结点的二元关系,下列叙述不正确的是( )A.满足自反性B.满足传递性C.满足反对称型D.满足对称性10.错误的局部化是指()。
A.把错误理解成局部的错误B.对错误在局部范围内进行纠正C.当发现错误时,跳过错误所在的语法单位继续分析下去D.当发现错误时立即停止编译,待用户改正错误后再继续编译1分,共5分)1.文法G的一个句子对应于多个推导,则G是二义性的。
编译原理考试试卷+答案A卷
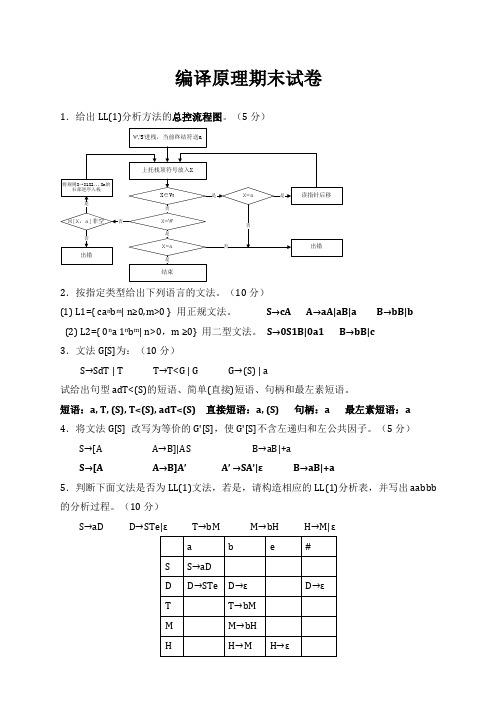
编译原理期末试卷1.给出LL(1)分析方法的总控流程图。
(5分)2.按指定类型给出下列语言的文法。
(10分)(1) L1={ ca n b m| n≥0,m>0 } 用正规文法。
S→cA A→aA|aB|a B→bB|b(2) L2={ 0n a 1n b m| n>0,m ≥0} 用二型文法。
S→0S1B|0a1 B→bB|c3.文法G[S]为:(10分)S→SdT | T T→T<G | G G→(S) | a试给出句型adT<(S)的短语、简单(直接)短语、句柄和最左素短语。
短语:a, T, (S), T<(S), adT<(S) 直接短语:a, (S) 句柄:a 最左素短语:a 4.将文法G[S] 改写为等价的G'[S],使G'[S]不含左递归和左公共因子。
(5分)S→[A A→B]|AS B→aB|+aS→[A A→B]A’A’→SA’|εB→aB|+a5.判断下面文法是否为LL(1)文法,若是,请构造相应的LL(1)分析表,并写出aabbb 的分析过程。
(10分)S→aD D→STe|ε T→bM M→bH H→M|ε6.简述编译程序概念及构成。
(10分)编译程序是现代计算机系统的基本组成部分.从功能上看,一个编译程序就是一个语言翻译程序,它把一种语言(称作源语言)书写的程序翻译成另一种语言(称作目标语言)的等价的程序.7.设G=(V N,V T,P,<S>)是上下文无关文法,产生式集合P中任意一个产生式应具有什么样的形式?若G是正则文法呢?(10分)2型(上下文无关):规则形式:A→βA ∈VN,β∈ (VT⋃VN)*3型(右线性):A→aB或A→a(右线性)A→Ba或A→a (左线性)a ∈VT⋃{ε}8.为文法G[E]:(10分)V → N | N[E] E → V | V+E N → i构造递归下降识别程序E( ){ V( ); if symbol = ‘+’E( ); }V( ){ N(); if symbol = ‘[’ { E(); if symbol != ‘]’error(); }N( ){ if symbol != ‘i ’ error(); }/* 这样的写法很简化,当文法提取左公因子后,需要计算相关非终结符的Follow 集,才能确定什么时候用空串规则推导。
编译原理试题及答案

编译原理试题及答案一、选择题1. 编译器的主要功能是什么?A. 程序设计B. 程序翻译C. 程序调试D. 数据处理答案:B2. 下列哪一项不是编译器的前端处理过程?A. 词法分析B. 语法分析C. 语义分析D. 代码生成答案:D3. 在编译原理中,词法分析器的主要作用是什么?A. 识别程序中的关键字和标识符B. 将源代码转换为中间代码C. 检查程序的语法结构D. 确定程序的运行环境答案:A4. 语法分析通常采用哪种方法?A. 自顶向下分析B. 自底向上分析C. 正则表达式匹配D. 直接解释执行答案:B5. 语义分析的主要任务是什么?A. 检查程序的语法结构B. 检查程序的类型安全C. 识别程序中的变量和常量D. 将源代码转换为机器代码答案:B二、简答题1. 简述编译器的工作原理。
答案:编译器的工作原理主要包括以下几个步骤:词法分析、语法分析、语义分析、中间代码生成、代码优化和目标代码生成。
词法分析器将源代码分解成一系列的词素;语法分析器根据语法规则检查词素序列是否合法;语义分析器检查程序的语义正确性;中间代码生成器将源代码转换为中间代码;代码优化器对中间代码进行优化;最后,目标代码生成器将优化后的中间代码转换为目标机器代码。
2. 什么是词法分析器,它在编译过程中的作用是什么?答案:词法分析器是编译器前端的一个组成部分,负责将源代码分解成一个个的词素(tokens),如关键字、标识符、常量、运算符等。
它在编译过程中的作用是为语法分析器提供输入,是编译过程的基础。
三、论述题1. 论述编译器中的代码优化技术及其重要性。
答案:代码优化是编译过程中的一个重要环节,它旨在提高程序的执行效率,减少资源消耗。
常见的代码优化技术包括:常量折叠、死代码消除、公共子表达式消除、循环不变代码外提、数组边界检查消除等。
代码优化的重要性在于,它可以显著提高程序的运行速度和性能,同时降低程序对内存和处理器资源的需求。
四、计算题1. 给定一个简单的四则运算表达式,请写出其对应的逆波兰表达式。
编译原理(A卷)答案

湖北第二师范学院2014-2015学年度第二学期《编译原理》课程考试答案(A卷) 院系:计算机学院专业班级:学生姓名:学号:考试方式:闭卷………………………………………………………………………………………………………………一、填空题(每空1分,共10分)1.词法分析程序是逐个识别(字符),形成单词级别的(字符)串,词法分析程序输出的数据是(2 )个,它们分别是(种别编码)和(自身值)。
2.语法分析程序是逐个识别(单词),形成语句级别的(单词)串。
3.一遍扫描的编译方法,是以语法分析程序为主,调用(词法分析)程序、语义分析程序,再由语义程序调用中间代码生成、中间代码优化等。
4.程序设计语言的发展带来了日渐多变的运行时存储管理方案,主要分为两大类,即(静态存储分配)方案和(动态存储分配)方案。
二、综合题(共90分)1.(5分)将下面文法改写成3型文法:G=({S,A,B},{a,b,c,d,e},P,S)其中:P={S→abcA|edB,A→beB,B→d}答案:改写后的3型文法是(5分)G=({S,A,B,C,D,E,F},{a,b,c,d,e},P,S)其中:P={S→aC|eF, C→bD,D→cA,A→bE,E→eB,F→dB,B→d}2.(5分)给出下面表达式的四元式形式:a*b+(c-d)/e答案:四元式形式(5分)(*,a,b,t1)(-,c,d,t2)(/,t2,e,t3)(+,t1,t3,t4)3.(30分)给定文法 G[E] :E → E+T | E-T | TT → T*F | T/F | FF → (E) | i该文法是 LL(1) 文法吗?为什么?不是的能否改造为LL(1)文法,如果能够改造,给出改造后的文法,并给出改造后文法是LL(1)文法的证明过程。
无论改造前还是改造后的文法,如果是LL(1)文法,则给出(i+i)*i的分析过程(要求给出详细过程,并给出LL(1)的分析表)答案:(1)该文法不是LL(1)文法,因为文法的产生式含有左递归(2分)(2)该文法可改造为LL(1)文法,即消除左递归,改造后的文法是(3分)E → TE’E’→ +TE’ | -TE’ | εT → FT’T’→ *FT’ | /FT’ |εF → (E) | i证明改造后的文法是LL(1)文法的过程A.求可达ε的非终结符(1分)可达的是E’,T’B.求每个非终结符的First集合(3分)First(E)={ (,i}First(E’)={+,-}First(T)={ (,i}First(T’)={*,/}First(F)={ (,i}C.求每个产生式右部字符串的First集合(3分)First(TE’)={ (,i}First(+TE’)={+}First(-TE’)={-}First(FT’)={ (,i}First(*FT’)={*}First(/FT’)={/}First((E))={ ( }First(i)={ i }First(ε)={ ε}D.求每个非终结符的Follow集合(3分)Follow(E)={$,)}Follow(E’)= Follow(E)={$,)}Follow(T)=First(E’) ∪ Follow(E)={$,+,-,)}Follow(T’)= Follow(T)={$,+,-,)}Follow(F)= First(T’) ∪ Follow(T)={$,+,-, *,/,)}E.求每个非终结符的Select集合(5分)Select(E → TE’)=First(TE’)={ (,i }Select(E’→ +TE’)=First(+TE’)={ + }Select(E’→ -TE’)=First(-TE’)={ - }Select(E’→ε)=First(ε)-{ ε} ∪ Follow(E’)={ $,) }Select(T → FT’)=First(FT’)={ (,i }Select(T’→ *FT’)=First(*FT’)={ * }Select(T’→ /FT’)=First(/FT’)={ / }Select(T’→ε)=First(ε)-{ ε} ∪ Follow(T’)={ $,+,-,) }Select(F → (E))=First((E))={ ( }Select(F → i)=First(TE’)={ i }F.求有多个产生式的非终结符Select集合的交集(2分)显然有Select(E’→ +TE’)∩Select(E’→ -TE’) ∩Select(E’→ε)=ΦSelect(T’→ *FT’) ∩Select(T’→ /FT’) ∩Select(T’→ε)= ΦSelect(F → (E))= ∩Select(F → i)= Φ所以改造后的文法是LL(1)文法4.(10分)对下面的NFA进行确定化答题:第1第25.(15分)给定文法 G[E] :E → E+T | E-T | TT → T*F | T/F | F该文法是算符优先文法吗?是,则构造该文法的算符优先关系矩阵,并给出(i+i)*i的分析过程(要求给出详细过程)答案:(1)该文法是算符优先文法(1分)(2)构造该文法的算符优先矩阵A.求各非终结符的FirstVT集合(3分)FirstVT(E)={+,-,*,/,(,i}FirstVT(T)={*,/,(,i}FirstVT(F)={(,i}B.求各非终结符的LasttVT集合(3分)LastVT(E)={ +,-,*,/,),i }LastVT(T)={ *,/,),i }LastVT(F)={ ),i }C.构造优先关系表(4分)6.(25分)给定文法 G[E] :T → T*F | FF → (E) | i该文法是LR(0)文法吗?是,则构造该文法的LR(0)分析表,并给出(i+i)*i的分析过程,不是的,是SLR(1)文法吗,是,则构造该文法的SLR(1)分析表,并给出(i+i)*i的分析过程。
编译原理试卷A参考答案

《编译原理》试卷A 参考答案注意事项:1. 请考生按要求在试卷装订线内填写姓名、学号和年级专业。
2. 请仔细阅读各种题目的回答要求,在规定的位置填写答案。
3. 不要在试卷上乱写乱画,不要在装订线内填写无关的内容。
4. 满分100分,考试时间为120分钟。
题号一二三四总分统分人得分一、单项选择题(每小题2分共20分)1.中间代码生成所依据的是语言的(C )。
A: 词法规则B: 语法规则C: 语义规则D: 产生式规则2.词法分析器的加工对象是(C )。
A: 中间代码B: 单词C: 源程序D: 元程序3.同正则表达式a*b*等价的文法是(C )。
A: G1: S aS|bS|εB: G2: S aSb|εC: G3: S aS|Sb|εD: G4: S abS|ε4.文法G[A]:A→b A→bH H H →BA B→Ab H →a 不是(B ):A: 2型文法B: 正规文法C: 0型文法D: 1型文法5.算符优先分析每次都是对(算符优先分析每次都是对( B B B )进行规约。
)进行规约。
A: A: 短语短语短语 B: B: B: 最左素短语最左素短语最左素短语 C: C: C: 素短语素短语素短语 D: D: D: 句柄句柄6.一个LR (1)文法合并同心集后,如果不是LALR(1)文法必定存在(B ):A: 移进-归约冲突B: 归约-归约冲突C: 识别句型D: 收集类型信息7.下列不属于类型检查范畴的描述是(C )。
A: 运算符的分量类型的相容性B: 形参和实参类型的相容性C :形参和实参的个数的一致性D: 赋值语句的左右部类型的相容性8.( B B )不是)不是DFA 的成分。
A:A:有穷字母表有穷字母表有穷字母表 B: B: B:初始状态集合初始状态集合C:C:终止状态集合终止状态集合终止状态集合 D: D: D:有限状态集合有限状态集合9.若B 为非终结符,则A α.B β为(为( B B B )项目。
编译原理考试题及答案

编译原理考试题及答案一、选择题(每题5分,共20分)1. 编译器的主要功能是什么?A. 代码优化B. 代码翻译C. 代码调试D. 代码运行答案:B2. 下列哪个选项不属于编译器的前端部分?A. 词法分析B. 语法分析C. 语义分析D. 代码生成答案:D3. 在编译原理中,文法的产生式通常表示为:A. A -> αB. A -> βC. A -> γD. A -> δ答案:A4. 下列哪个算法用于构建语法分析树?A. LL(1)分析B. LR(1)分析C. SLR(1)分析D. LALR(1)分析答案:A二、填空题(每空5分,共20分)1. 编译器的前端通常包括词法分析、语法分析和________。
答案:语义分析2. 编译器的后端主要负责________和目标代码生成。
答案:代码优化3. 编译器中的词法分析器通常使用________算法来识别单词。
答案:有限自动机4. 语法分析中,________分析是一种自顶向下的分析方法。
答案:递归下降三、简答题(每题10分,共30分)1. 简述编译器的作用。
答案:编译器的主要作用是将高级语言编写的源代码转换成计算机能够理解的低级语言或机器代码,以便执行。
2. 解释一下什么是语法制导翻译。
答案:语法制导翻译是一种翻译技术,它利用源语言的语法信息来指导翻译过程,使得翻译过程能够更好地理解源代码的语义。
3. 什么是词法分析器?答案:词法分析器是编译器前端的一部分,它的任务是将源代码文本分解成一系列的标记(tokens),这些标记是源代码的最小有意义的单位。
四、计算题(每题10分,共30分)1. 给定一个简单的文法G(E):E → E + T | TT → T * F | FF → (E) | id请计算文法的非终结符号E的FIRST集和FOLLOW集。
答案:E的FIRST集为{(, id},FOLLOW集为{), +, $}。
2. 假设编译器在进行语法分析时,遇到一个语法错误的代码片段,请简述编译器如何处理这种情况。
编译原理试卷(A)--2010
二、选择题(每题3分,共30分)1、作为编译程序的源语言不能是____________A、高级语言B、C语言C、低级语言D、Pascal语言2、正规式M1和M2等价是指__________。
A、M1和M2的状态数相等 B、M1和M2的有向边条数相等C、M1和M2所识别的语言集相等 D、M1和M2的状态数和有向边条数相等3、由文法的开始符号经0步或多步推导产生的文法符号序列是_________。
A、短语B、句柄C、句型D、句子4、设∑={0,1},则∑上所有以1开头,后跟若干个010的字的集合对应的正规式为________。
A.1(010)* B.1(010)+ C.(010)*1 D.(010)+15、文法G(S) :S xSx|y所识别的语言是________。
A.xyx B. (xyx)* C. x n yx n(n>=0) D.x*yx*6、一个________指明了在分析过程中的某时刻所能看到的产生式多大一部分。
A.活前缀B.前缀C.项目D.项目集7、LL(1)文法的条件是______。
A.对形如U->Xl|X2|…|Xn的规则,要求FIRST(Xi)∩FIRST(Xj)=Φ,(i≠j)B.对形如U->Xl|X2|…|Xn的规则,若Xi=>*ε,则要求FIRST(Xj)∩FOLLOW(U)=ΦC.a和bD.都不是8、已知文法G[E]E->TE'E'->+TE'|εT->FT'T'->*FT'|εF一(E)|idFOLLOW(F)=______A.{*,+}B. {#,)} C.{+,#,)} D.{*,+,#,)}9、语法制导的翻译程序能同时进行__________和语义分析。
A、词法分析B、语法分析C、优化D、目标代码生成10、在LR 分析法中,分析栈中存放的状态是识别规范句型_____的DFA 状态。
《编译原理》试卷参考答案(2020A)

2019―2020第二学期《编译原理》期末考试试卷(A)使用专业、班级学号姓名题数一二三四五六七总分得分一、选择填空〖每空1分,共计20分〗1.编译程序将源程序加工成目标程序是 C 之间的转换。
A.词法B.语法C.语义D.规则2.开发一个编译程序应掌握 D 。
A.源语言B.目标语言C.编译技术D.以上三项都是3.词法分析器的输出结果是 B 。
A.单词自身B.单词的机内符C.单词的词义信息D.单词的词法信息4.称有限自动机A1和A2等价是指 D 。
A.A1和A2都是定义在一个字母表Σ上的有限自动机B.A1和A2状态数和有向边数相等C.A1和A2状态数或有向边数相等D.A1和A2所能识别的字符串集合相同5.同正则表达式(a | b)+等价的正则表达式是 B 。
A.(a | b) * B.(a | b) (a | b) *C.(a b)* (a b) D.(a | b)| (a | b)*6.前后文无关文法G:S→[ S ] | [ ]所产生的语言是 D 。
A.[ m ] n (m,n>0)B.[ m ] n (m,n>1)C.[ m ] m(m≥0)D.[ n ] n(n≥1)7.由文法的开始符出发通过若干步(包括0步)推导产生的文法符号序列是 B 。
A.语言B.句型C.句子D.句柄8.最左简单子树的叶结点,自左至右排列组成句型的 C 。
A.短语B.简单短语C.句柄D.素短语9.简单优先分析法每次都是对 D 进行归约。
A.短语B.简单短语C.素短语D.句柄考试形式开卷()、闭卷(√),在选项上打(√)开课教研室命题教师试卷专用纸使用学期总张数教研室主任审核签字江 南 大 学 考二、文法和语言类型题〖1小题10分,2小题5分,共计15分〗1.设有文法G[S]:E → E+T | E-T | TT → T*F | T/F | F F → x | y | z | (E)(1) 给出对于句子x+y*x-z 的最右推导过程E => E-T=> E -F=> E -z=> E+T -z=> E+ T*F -z =>> E+T*x -z=> E+F*x -z=> E+y*x -z => T+y*x -z=> F+y*x -z=> x+y*x -z(2) 试构造句型(E+T)-(T+F)的语法树(3) 基于上述语法树给出该句型的短语、简单短语和句柄。
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
《编译原理》考试试卷A
适用专业:考试日期:闭卷
所需时间:120分钟总分:100分
一、填空题:(每空1分,共10分)
1.解释系统与编译系统的区别在于和。
2.在编译过程中始终伴随着管理和出错处理过程。
3.语法分析的方法为和两大类。
4.LL(1)文法中不能有和。
5.词法分析器中单词的描述工具是 ,单词的识别工具。
6.算符优先语法分析,在符号栈栈顶出现时,进行规约处理。
二、单选题(每小题2分,共10分)
1.词法分析器的加工对象是()
A.中间代码
B.单词
C.源程序
D.元程序
2.同正则表达式a*b*等价的文法是()
A. G1:S→aS|bS|ε
B. G2: S→aSb|ε
C. G3:S→aS|Sb|ε
D. G4: S→abS|ε
3.文法G[A]:A→bH H→BA B→Ab H→a 不是()
A. 2型文法
B. 3型文法
C. 0型文法
D.1型文法
4.算符优先分析每次都是对()进行规约。
A.短语
B.最左素短语
C.素短语
D.句柄
5.( )不是DFA的成分。
A.有穷字母表
B. 初始状态集合
C.终止状态集合
D.有限状态集合
三、问答题(第1,5小题每题15分,其余每小题10分,共80分)
1. (15分)解释下列术语:
(1)编译程序
(2)句柄
(3)上下文无关文法
2.编译程序主要有哪些构成成分?(10分)
3.给出描述语言L={a n b2n c m|n,m≥0}的cfg。
(10分)
4.(10分)将下图中的DFA M最小化。
5. (15分)判断文法G[S]:
S→aH
H→aMd|d
M→Ab|ε
A→aM|e
是否为LL(1)文法?给出判断过程。
6. (10分)改写文法G[E]:
E → E+T|T
T →T*F|F
F →(E)| a
为无左递归文法。
7. (10分)已知文法G[S]为:
S→V
V→T|ViT
T→F|T+F
F→)V*|(
请指出句型(+(i( 规范推到,并指出句型F+Fi( 中的短语、句柄和素短语。
《编译原理》考试试卷A参考答案
适用专业:考试日期:闭卷
所需时间:120分钟总分:100分
一、填空题:(每空1分,共10分)
1. 边翻译边执行和不生成目标代码。
2. 表格。
3. 自上而下和自底向上。
4. 左递归和回溯。
5. 正则式或正规文法, 有穷自动机。
6. 最左素短语。
二、单选题(每小题2分,共10分)
1-5:CCBBB
三、问答题(每小题10分,共80分)
1.
(1)编译程序
一个编译程序就是一个语言翻译程序,它把一种语言(称作源语言)书写的程序翻译成另一种语言(称作目标语言)的程序
(2)句柄
一个句型的最左直接短语称为该句型的句柄
(3)上下文无关文法
对任一产生式α→β,α为非终结符,β为终结符和非终结符组成的符号串。
2.
编译程序一般由词法分析程序,语法分析程序,语义分析程序,中间代码生成程序,目标代码生成程序,代码优化程序,符号表管理程序和错误处理程序等成分构成。
3.
G[S]:
S→AB
A→aAbb|ε
B→cB|ε
4.
初始划分:I1={1,2,3,4},I2={5,6,7}
因为
move(I1,a)={6,1,7,4}→move({1,2},a)={6,7} move({3,4},a)={1,4}
所以第二次划分:I1={1,2},I2={3,4},I3={5,6,7}
又因为
move({3,4},a)={1,4}→ move({3},a)={1}, move({4},a)={4}
所以,将{3,4}划分为集合:{3},{4}
move({5,6,7},a)={4,7}→move({5},a)={7}, move({6,7},a)={4} 所以将集合{5,6,7}划分为:{5},{6,7}
最终划分结果:I1={1,2},I2={3},I3={4},I4={5},I5={6,7}
产生式的Select集交集都为空集,所以该文法是LL(1)文法。
6. G[ E]: (1) E →TE’ (2) E’ →+TE’
(3) E’ →ε (4) T →FT’
(5) T’ →*FT’ (6) T’ →ε
(7) F → (E) (8) F →a
7.
S → V → ViT→ViF→Vi(→Ti(→T+Fi(→T+(i(→F+(i(→(+(i( 句型F+Fi(
短语:F,F+F,(,F+Fi( 句柄:F
素短语:F+F,(。