常用数据库的说明
常用中文数据库

66
检索结果及处理
导出题录
勾选所需题录文献
检索式
全文下载
67
导出题录
[1] 谢国珍.基于可持续发展的企业财务战略制定与实施[J]. 会计之友,2006,(19): 83-85. [2] 林燕华.基于可持续发展的企业财务战略研究[J]. 改革与战略,2013,29(5):44-47. [3] 沈瑜.浅析我国企业财务会计管理及可持续发展[J]. 68 决策与信息 (下旬刊),2013,(8):232-233.
示例 [1]王娜,郭学平,栾贻宏,石艳丽.微生物来源的透明质 酸酶[J].食品与药品,2007,(09):40-44. [2]张艳丽,高华,刘小红. 微生物合成的聚谷氨酸及其 应用[J].生物技术通报,2008,(04):58-62.
37
检索结果处理——全文下载
点击篇名
38
检索结果处理—全文下载
1
第二章
常用中文数据库
1.中国知网学术期刊数据库
2.中文科技期刊数据库(维普数据)检索系统
3.万方数字化期刊信息检索系统 4.读秀学术搜索与超星电子图书信息检索 5.方正Apabi电子图书信息检索 6.书生之家电子图书信息检索
2 7.其它中文数据库
第一节中国知网学术期刊数据库
一、CNKI简介 二、中国知网学术期刊数据库简介 三、中国知网学术期刊数据库检索方法
81
数据库规范化的说明书

数据库规范化的说明书一、引言数据库规范化是设计和组织数据库的一种方法,旨在减少冗余数据,提高数据存储效率,确保数据的一致性和完整性。
本说明书将详细介绍数据库规范化的原则、规范化级别以及规范化的具体步骤。
二、规范化原则数据库规范化的设计需要遵循以下原则:1. 第一范式(1NF):确保每个属性都是原子性的,不可再分。
2. 第二范式(2NF):确保非主键属性完全依赖于候选键。
3. 第三范式(3NF):确保非主键属性之间没有传递依赖关系。
3. 其他范式:根据实际情况,可以进一步规范化到更高的范式级别。
三、规范化级别常用的数据库规范化级别包括:1. 第一范式(1NF):确保属性是原子性的。
2. 第二范式(2NF):确保非主键属性完全依赖于候选键。
3. 第三范式(3NF):确保非主键属性之间没有传递依赖关系。
4. Boyce-Codd范式(BCNF):确保每个属性都依赖于候选键,而不是依赖于其他非主键属性。
5. 第四范式(4NF):确保有多个候选键时,非主键属性之间没有多值依赖关系。
6. 第五范式(5NF):确保数据库中不存在关于同一实体的冗余数据。
四、规范化步骤为了使数据库设计符合规范化要求,可以按照以下步骤进行规范化:1. 确定函数依赖:分析数据集合,确定各个属性之间的依赖关系。
2. 识别候选键:找出可以唯一标识实体的属性或属性组合,即候选键。
3. 应用第一范式(1NF):确保每个属性都是原子性的,不可再分。
4. 应用第二范式(2NF):将非主键属性与候选键建立关系,确保非主键属性完全依赖于候选键。
5. 应用第三范式(3NF):消除传递依赖关系,确保非主键属性之间没有依赖关系。
6. 根据实际情况,进一步应用其他范式。
五、总结数据库规范化是一种重要的数据库设计方法,通过规范化可以提高数据存储效率、保证数据一致性和完整性。
本说明书介绍了数据库规范化的原则、规范化级别以及规范化的步骤,希望能够对数据库规范化的实践和应用提供指导。
数据库数据模型的说明书

数据库数据模型的说明书本文介绍了数据库数据模型的相关概念、设计原则和实践方法,旨在帮助读者全面理解和运用数据库数据模型。
1. 数据库数据模型的定义数据库数据模型是对数据库中数据的组织和表示方式进行抽象和规范的方法。
它定义了数据的结构、组织方式以及与数据相关的操作和约束规则。
2. 数据库数据模型的类型常见的数据库数据模型包括层次模型、网络模型、关系模型和面向对象模型。
其中,关系模型是应用最广泛的数据库数据模型,它基于集合论和关系代数理论,采用表的形式组织数据。
3. 关系模型的设计原则在设计关系模型时,需要遵循一些原则,以保证数据的一致性、完整性和有效性。
这些原则包括实体完整性、参照完整性、域完整性、关系完整性等。
4. 关系模型的组成要素关系模型由实体、属性和关系组成。
实体表示数据库中的对象或概念,属性表示实体的特征或描述,关系表示实体之间的联系。
5. 数据库的范式关系模型的设计还涉及到范式的概念。
范式是一组规范化原则,用于评估和改善数据库的结构设计。
常见的范式有第一范式(1NF)、第二范式(2NF)、第三范式(3NF)等。
6. 数据库设计过程数据库的设计过程包括需求分析、概念设计、逻辑设计和物理设计等阶段。
在需求分析阶段,需要明确数据的需求和约束;在概念设计阶段,需要建立概念模型;在逻辑设计阶段,需要转换为关系模型;在物理设计阶段,需要考虑数据库的存储和性能优化。
7. 数据库设计工具为了辅助数据库设计过程,可以使用一些数据库设计工具,如ER 图工具、数据库建模工具等。
这些工具提供了可视化的设计界面和自动生成代码的功能,提高了设计效率和准确性。
8. 数据库数据模型的优化在数据库运行过程中,为了提高性能和响应速度,常需要对数据库数据模型进行优化。
优化手段包括垂直分割和水平分割、索引的设计和优化、查询的优化等。
9. 数据库数据模型的未来发展随着大数据、云计算和人工智能等技术的快速发展,数据库数据模型也在不断演化和创新。
数据库表的说明书

数据库表的说明书概述本文档旨在提供有关数据库表的详细信息和说明。
它将介绍数据库表的结构、字段和关系,以帮助用户更好地理解和使用数据库。
以下是数据库表的详细说明。
表名称:[表名称]表说明:[表说明]表结构字段名数据类型约束条件说明-------------------------------------------------------------[字段1] [数据类型] [约束条件] [字段1说明][字段2] [数据类型] [约束条件] [字段2说明]...[字段n] [数据类型] [约束条件] [字段n说明]字段说明:- 字段名:指数据库表中的字段名称。
- 数据类型:指字段的数据类型,如字符串、整数、日期等。
- 约束条件:指字段的约束条件,如唯一性、非空等。
- 说明:对字段进行详细说明。
关系本数据库表与其他表之间存在以下关系:关系类型相关表名关系说明-------------------------------------------------------------[关系1] [相关表1] [关系1说明][关系2] [相关表2] [关系2说明]...[关系n] [相关表n] [关系n说明]关系说明:- 关系类型:指关系的类型,如一对一、一对多、多对多等。
- 相关表名:指与本表存在关系的其他表的名称。
- 关系说明:对关系进行详细说明。
使用示例以下是一个使用本数据库表的示例:INSERT INTO [表名称] ([字段1], [字段2], ..., [字段n]) VALUES ([值1], [值2], ..., [值n]);说明:- 表名称:指要插入数据的表的名称。
- 字段1、字段2、...、字段n:指要插入数据的字段名称。
- 值1、值2、...、值n:指要插入的值。
注意事项在使用本数据库表时,请注意以下事项:1. 确保按照字段的约束条件输入有效的数据。
2. 遵守本数据库表与其他表之间的关系。
高斯数据库和mysql的语法-概述说明以及解释

高斯数据库和mysql的语法-概述说明以及解释1.引言1.1 概述概述:高斯数据库和MySQL是两种常见的关系型数据库管理系统(RDBMS),它们在语法和功能上有所不同。
本文将探讨高斯数据库和MySQL的语法特点和使用方法。
高斯数据库是由高斯软件公司开发的一款关系型数据库管理系统,它具有高效、稳定和可扩展的特点。
高斯数据库支持标准SQL语法,并提供了一些高级功能,如数据分区和并行查询,以提高数据库的性能和可用性。
高斯数据库被广泛应用于大型企业和互联网企业,用于存储和管理大量的结构化数据。
而MySQL是一款开源的关系型数据库管理系统,它具有广泛的应用领域和强大的社区支持。
MySQL使用标准的SQL语法,提供了丰富的功能和灵活的配置选项,可以根据不同的需求进行定制。
MySQL广泛应用于Web应用程序、企业级应用和小型数据库环境。
本文将分别介绍高斯数据库和MySQL的语法特点和使用方法。
在高斯数据库的语法部分,我们将详细讨论数据库的创建和删除、表的创建和删除以及数据的插入、查询和更新。
在MySQL的语法部分,我们也将对这些方面进行详细说明,以便读者更好地理解和应用。
通过对比高斯数据库和MySQL的语法特点和使用方法,读者可以更好地了解它们之间的区别和适用场景。
此外,本文还将总结结论,为读者提供一些选取适合自身需求的数据库管理系统的参考。
下一节,我们将介绍文章的结构和目的,以帮助读者更好地理解本文的内容和价值。
文章结构部分的内容如下:1.2 文章结构本文主要介绍了高斯数据库和MySQL的语法,并对比了它们在数据库创建和删除、表的创建和删除以及数据的插入、查询和更新等方面的差异。
文章分为引言、正文和结论三个部分。
引言部分概述了本文的主题,并对高斯数据库和MySQL进行了简要的介绍。
在引言中,我们也明确了本文的目的,即通过对比两者的语法,帮助读者更好地理解和应用这两种数据库。
正文部分是本文的重点,分为高斯数据库的语法和MySQL的语法两个小节。
蛋白质数据库使用说明

引言:蛋白质数据是生物信息学领域中非常重要的资源之一,它提供了大量关于蛋白质序列、结构、功能以及相互作用等方面的信息。
本文旨在介绍如何使用蛋白质数据库,帮助用户更好地利用这一资源进行研究。
概述:蛋白质数据库是一个集成了许多蛋白质信息的在线资源,用户可以通过搜索、浏览、等方式获取所需的信息。
其中,常用的蛋白质数据库包括NCBI、UniProt、PDB等。
这些数据库提供了丰富的蛋白质数据,并且不断更新以满足用户需求。
正文内容:1.数据库搜索功能1.1.关键词搜索1.1.1.输入蛋白质名称1.1.2.输入序列片段1.1.3.输入关键词1.2.高级搜索选项1.2.1.提供更精确的搜索结果1.2.2.支持过滤和排序功能1.2.3.可以根据相关字段进行搜索2.数据库浏览功能2.1.蛋白质分类2.1.1.按物种分类2.1.2.按功能分类2.1.3.按家族分类2.2.数据表格浏览2.2.1.查看蛋白质基本信息2.2.2.查看蛋白质序列2.2.3.查看蛋白质结构2.3.数据图谱浏览2.3.1.查看蛋白质相互作用网络2.3.2.查看蛋白质结构域分布2.3.3.查看蛋白质功能注释3.数据库功能3.1.蛋白质序列数据3.1.1.全部序列3.1.2.特定物种的序列3.2.蛋白质结构数据3.2.1.已解析的蛋白质结构3.2.2.蛋白质结构预测结果3.3.蛋白质相互作用数据3.3.1.已验证的相互作用数据3.3.2.预测的相互作用数据4.数据库工具与资源4.1.序列比对工具4.1.1.BLAST4.1.2.PSIBLAST4.2.结构预测工具4.2.1.SWISSMODEL4.2.2.Phyre24.3.功能注释资源4.3.1.GeneOntology4.3.2.InterPro4.4.数据库交互接口4.4.1.提供API接口4.4.2.支持数据提交与5.数据库更新与维护5.1.数据更新频率5.2.数据质量保证5.3.用户反馈与支持5.4.数据库版本与历史记录总结:蛋白质数据库为研究人员提供了丰富的蛋白质信息资源,通过搜索、浏览、等功能,用户可以轻松地获取需要的数据。
数据库说明
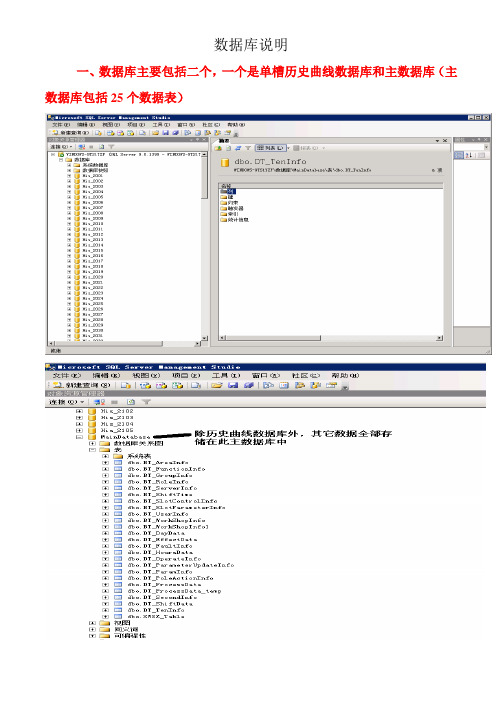
数据库说明一、数据库主要包括二个,一个是单槽历史曲线数据库和主数据库(主数据库包括25个数据表)二、单槽历史曲线数据库历史曲线字段:[SlotID] 槽号[RecordID] 记录号[Data] 日期[Electric] 电流[Volt] 电压[Resistance] 电阻[FilterRes] 滤波电阻[SmoothRes] 平滑电阻[Vibration] 针振[Swing] 摆动[Slope] 斜率[Accsloper] 累斜[RaleBlankInterval] 实际下料间隔[PoleUpDown] 阳极升降[Effection] 效应[OutAL] 出铝[Changepole]换极[SideProcess] 边加工[LiftBasar] 抬母线[PuremanOperation] 纯手动[BankState] 下料状态[PoleUpTime] 阳升时间[PoleDownTime] 阳降时间[PoleUpResistivity] 阳升阻率[PoledownResistivity] 阳降阻率[VoltupperLimit] 电压上限[VoltlowerLimit] 电压下限[BasbankInterval] 基准下料间隔[OutAlDistance] 出铝距今[ChangePoleDistance] 换极距今[SideProcessDistance] 加工距今历史曲线每10分钟存一次(数据是从下位机送上来的)三、主数据库:包括25个数据存储表和35个存储过程(1)BT_AreaInfo表包括:(AreaID)工区号, (AreaName)工区名,(WorkshopID)车间编号。
和数据表BT_SlotControlInfo(表7)中的相应字段相匹配。
(2)BT_FunctionInfo表:用于分配各级权限的功能包括:[FunctionID] 功能号[DebugParameter] 调试参数[SystemParameter] 系统参数[ProductionParameter] 生产参数[UserParameter] 常用参数[SetVolt] 设定电压[BankInterval] 下料间隔[FsaltVol] 氟盐[ThicknessControl] 浓度控制[TimeBank] 定时[StopBank] 停料[BankControl] 下料控制[EffectwaitInterval] 效应间隔[AutoRC] 自动RC[CancelautoRC] 取消自动RC[EffectContinueTime] 效应等待时间[UpSensitive] 上敏感区[DownSensitive] 下敏感区[SlotStatus] 槽状态[SlotDate] 槽日期[EffectBank] 闪烁效应[MiMa] 密码[DataInput] 数据导出值为0表示无权限修改或查看该参数 1为有权限功能号必须唯一(3)BT_GroupInfo: 此表暂时不用(4)BT_RoleInfo:角色表角色表包括:RoleID(编号)RoleName(角色名)暂时不用WorkShopID(车间编号)WorkAreaID(工区编号)FunctionID(功能号)角色表示的是所建角色对哪个车间,哪个工区有什么样的权限它要与BT_FunctionInfo和BT_UserInfo 一起使用来给用户分配权限(5)BT_ServerInfo表: 本服务器信息和动态信息数据库配置表存储本服务器和动态信息服务器程序所运行的服务器的IP地址及端口号(6)BT_ShiftTime表:班报配置表包括:ShiftID(班报索引)ShiftName(班名称)BeginTime(开始时间)TimeNum(班时间长)DateMark(是否跨天)(7)BT_SlotControlInfo表:槽控机通讯配置表BT_SlotControlInfo表为槽控机配置信息表:[SlotID] 槽号[CommID] 通讯号[WorkshopID] 车间号[AreaID] 工区号[GroupID] 分组号[SlotStatus] 槽状态[SlotAge] 槽龄[SlotstartDate] 启动日期[NetboxID] 转换器编号[PortID] 端口号[NetboxIP] 槽控机对应的IP地址[Remark] 备注(8)BT_SlotParameterInfo表:存槽控机调试参数所有地址,为二进制数据(9)BT_UserInfo表:用户表:[UserID] 用户登陆名[UserName] 用户姓名[Password] 用户密码[RoleID] 角色,用户与角色的关系:用户表示一个具体的人,角色表示一类人,这类人有着相同的权限用户只是这类人中的一个。
中外文常用数据库及网络资源介绍

Apabi电子教学参考书
CALIS中国高校教学参考书
由CALIS成员馆51家高校图书馆参建,提供电子书6万多册
CADAL
数字资源1225645册,其中学位论文192425册,民国图书/期 刊269094册,古籍187993册,现代图书444951册,英文图书 126729册,其它4426册
Apabi电子教学参考书 Apabi是五个英文单词Author(作者)Publisher (出版社)、Artery(渠道)、Buyer(购买者)、 Internet(互联网)的首字母缩写。 Apabi系统最大的特色在于收录的电子图书均可 以是经采访人员针对各校学科建设以及读者需求, 从与北大方正公司合作的400多家出版社出版的图 书中精心挑选而来,因此它的学科专业性、系统 性更为突出;同时,也是对 各馆纸本书的有效补 充。
中文数据库—文摘索引
全国报刊索引 社科版 自科版 中文社会科学引文索引CSSCI
1857年~ 期刊8500多种,报纸200余种 2000年~
中文人文科学、社会科学学术期刊400余种,海外 出版的期刊近20种。1998年~
中国科学引文数据库(CSCD)
四部丛刊
文渊阁四库全书
中国基本古籍库中文电子期刊—全数据库中国知网—中国期刊全文数据库
重庆维普—中文科技期刊数据库
万方—中国数字化期刊群
. . 人大复印资料 . . . . . . . . .
中国知网 中国知网为同方知网(北京)技术有限公司所 有,中国学术期刊(光盘版)电子杂志社出版, 是世界上最大的连续动态更新的中国学术文献数 据库。该库深度集成整合了学术期刊、博硕士学 位论文、会议论文、报纸、年鉴、专利、国内外 标准、科技成果等中文资源以及 Springer 等外文 资源。数据每日更新。
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
常用数据库1. IBM 的DB2作为关系数据库领域的开拓者和领航人,IBM在1977年完成了System R系统的原型,1980年开始提供集成的数据库服务器—— System/38,随后是SQL/DSforVSE和VM,其初始版本与SystemR研究原型紧密相关。
DB2 forMVSV1 在1983年推出。
该版本的目标是提供这一新方案所承诺的简单性,数据不相关性和用户生产率。
1988年DB2 for MVS 提供了强大的在线事务处理(OLTP)支持,1989 年和1993 年分不以远程工作单元和分布式工作单元实现了分布式数据库支持。
最近推出的DB2 Universal Database 6.1则是通用数据库的典范,是第一个具备网上功能的多媒体关系数据库治理系统,支持包括Linux在内的一系列平台。
2. OracleOracle 前身叫SDL,由Larry Ellison 和另两个编程人员在1977创办,他们开发了自己的拳头产品,在市场上大量销售,1979 年,Oracle公司引入了第一个商用SQL 关系数据库治理系统。
Oracle公司是最早开发关系数据库的厂商之一,其产品支持最广泛的操作系统平台。
目前Oracle关系数据库产品的市场占有率名列前茅。
3. InformixInformix在1980年成立,目的是为Unix等开放操作系统提供专业的关系型数据库产品。
公司的名称Informix便是取自Information 和Unix的结合。
Informix第一个真正支持SQL语言的关系数据库产品是Informix SE(StandardEng ine)。
InformixSE是在当时的微机Unix环境下要紧的数据库产品。
它也是第一个被移植到Linux上的商业数据库产品。
4. SybaseSybase公司成立于1984年,公司名称“Sybase”取自“s ystem”和“database” 相结合的含义。
Sybase公司的创始人之一Bob Epstein 是Ingres 大学版(与System/R同时期的关系数据库模型产品)的要紧设计人员。
公司的第一个关系数据库产品是1987年5月推出的Sybase SQLServer1.0。
S ybase首先提出Client/Server 数据库体系结构的思想,并领先在Sybase SQLServer 中实现。
5. SQL Server1987 年,微软和IBM合作开发完成OS/2,IBM 在其销售的OS/2 ExtendedEdition 系统中绑定了OS/2Database M anager,而微软产品线中尚缺少数据库产品。
为此,微软将目光投向Sybase,同Sybase 签订了合作协议,使用Sybase 的技术开发基于OS/2平台的关系型数据库。
1989年,微软公布了SQL Server 1.0 版。
6. PostgreSQLPostgreSQL 是一种特性特不齐全的自由软件的对象——关系性数据库治理系统(ORDBMS),它的专门多特性是当今许多商业数据库的前身。
PostgreSQL最早开始于BSD的In gres项目。
PostgreSQL 的特性覆盖了SQL-2/SQL-92和SQL-3。
首先,它包括了能够讲是目前世界上最丰富的数据类型的支持;其次,目前PostgreSQL 是唯一支持事务、子查询、多版本并行操纵系统、数据完整性检查等特性的唯一的一种自由软件的数据库治理系统.7.mySQLmySQL是一个小型关系型数据库治理系统,开发者为瑞典MySQL AB公司。
在2008年1月16号被Sun公司收购。
目前MySQL被广泛地应用在Internet上的中小型网站中。
由于其体积小、速度快、总体拥有成本低,尤其是开放源码这一特点,许多中小型网站为了降低网站总体拥有成本而选择了MySQL作为网站数据库。
MySQL的官方网站的网址是:数据库的种类2008年12月03日星期三 20:53数据库的种类大型数据库有:Oracle、Sybase、DB2、SQL server小型数据库有:Access、MySQL、BD2等。
2007年4月29日消息,国外媒体报道,据权威调研机构IDC 初步数据显示,尽管微软SQL Server进展迅猛,但甲骨文依旧称霸全球数据库市场。
IDC数据显示,2006年全球数据库市场规模达到了165亿美元。
其中,甲骨文的销售额为73亿美元,占到了44.4%,排名首位。
IBM位居第二,其DB2数据库的销售额为35亿美元,同比增长11.9%。
略低于甲骨文的14.7%,以及业内14.3%的平均水平。
微软排名第三,营收额达到了31亿美元,涨幅高达25%,市场份额为18.6%。
此外,Sybase和NCR Teradata分不列居第四和第五位---------------------------------------------------------------------------------------------------------------------一、开放性1. SQL Server只能在windows上运行,没有丝毫的开放性,操作系统的系统的稳定对数据库是十分重要的。
Windows9X系列产品是偏重于桌面应用,NT server只适合中小型企业。
而且windows平台的可靠性,安全性和伸缩性是特不有限的。
它不象unix 那样久经考验,尤其是在处理大数据库。
2. Oracle能在所有主流平台上运行(包括 windows)。
完全支持所有的工业标准。
采纳完全开放策略。
能够使客户选择最适合的解决方案。
对开发商全力支持。
3. Sybase ASE能在所有主流平台上运行(包括 windows)。
但由于早期Sybase与OS集成度不高,因此VERSION11.9.2以下版本需要较多OS和DB级补丁。
在多平台的混合环境中,会有一定问题。
4. DB2能在所有主流平台上运行(包括windows)。
最适于海量数据。
DB2在企业级的应用最为广泛,在全球的500家最大的企业中,几乎85%以上用DB2数据库服务器,而国内到97年约占5%。
二、可伸缩性,并行性1. SQL server并行实施和共存模型并不成熟,专门难处理日益增多的用户数和数据卷,伸缩性有限。
2. Oracle并行服务器通过使一组结点共享同一簇中的工作来扩展windownt的能力,提供高可用性和高伸缩性的簇的解决方案。
假如windowsNT不能满足需要,用户能够把数据库移到UNIX中。
Oracle的并行服务器对各种UNIX平台的集群机制都有着相当高的集成度。
3. Sybase ASE尽管有DB SWITCH来支持其并行服务器,但DB SWITCH在技术层面还未成熟,且只支持版本12.5以上的ASE SERVER。
DB SWITCH技术需要一台服务器充当SWITCH,从而在硬件上带来一些苦恼。
4. DB2具有专门好的并行性。
DB2把数据库治理扩充到了并行的、多节点的环境。
数据库分区是数据库的一部分,包含自己的数据、索引、配置文件、和事务日志。
数据库分区有时被称为节点安全性。
三、安全认证1. SQL server没有获得任何安全证书。
2. Oracle Server获得最高认证级不的ISO标准认证。
3. Sybase ASE获得最高认证级不的ISO标准认证。
4. DB2获得最高认证级不的ISO标准认证。
四、性能1. SQL Server多用户时性能不佳2. Oracle性能最高,保持开放平台下的TPC-D和TPC-C的世界记录。
3. Sybase ASE性能接近于SQL Server,但在UNIX平台下的并发性要优与 SQL Server。
4. DB2性能较高适用于数据仓库和在线事物处理。
五、客户端支持及应用模式1. SQL ServerC/S结构,只支持windows客户,能够用ADO、DAO、OLEDB、ODBC连接。
2. Oracle多层次网络计算,支持多种工业标准,能够用ODBC、JDBC、OCI等网络客户连接。
3. Sybase ASEC/S结构,能够用ODBC、Jconnect、Ct-library等网络客户连接。
4. DB2跨平台,多层结构,支持ODBC、JDBC等客户。
六、操作简便1. SQL Server操作简单,但只有图形界面。
2. Oracle较复杂,同时提供GUI和命令行,在windowsNT和unix下操作相同。
3. Sybase ASE较复杂,同时提供GUI和命令行。
但GUI较差,常常无法及时状态,建议使用命令行。
4. DB2操作简单,同时提供GUI和命令行,在windowsNT和unix下操作相同。
七、使用风险1. SQL server完全重写的代码,经历了长期的测试,不断延迟,许多功能需要时刻来证明。
并不十分兼容。
2. Oracle长时刻的开发经验,完全向下兼容。
得到广泛的应用。
完全没有风险。
3. Sybase ASE向下兼容, 然而ct-library 程序不益移植。
4. DB2在巨型企业得到广泛的应用,向下兼容性好。
风险小。
-----------------------------------------------------------------------------------------------------------------------最"容易"的数据库系统-Microsoft SQL Server假如你打算做一个DBA,建议你选择那些现在比较流行的数据库系统。
这意味着你将有更多的就业机会、交流和培训机会,而且,流行自有流行的理由,你能够因此省心专门多。
因此,就业竞争压力也比较大。
一般的入门者选择Microsoft SQL Server,这是特不适合中小型企业的数据库系统,熟悉Access 的读者专门容易就能初步使用Microsoft SQL Server,成为一个DBBS。
J Microsoft SQL Server 7.0的报价,5用户版1399美金,增加用户时,127美金每用户。
最"难"的数据库-无冕之王Oracle假如你有机会接触到Oracle,那但是个好机会。
Oracle是目前最看好的数据库厂商,由于其强大的功能和可配置、可治理能力,Oracle DBA的薪资一般比其他数据库治理员的薪资要高。
而且,Oracle在大中型企业的关键应用也更加普遍了。
Oracle能够运行在Windows NT、Sun Solaris、Linux等平台下。
专门多情况下要求你不仅仅熟悉NT,还要你熟悉Unix;而且Oracle不太友善的界面和成箱的Oracle产品资料可能也是一个障碍。