SPSS统计分析分析案例
spss案例分析
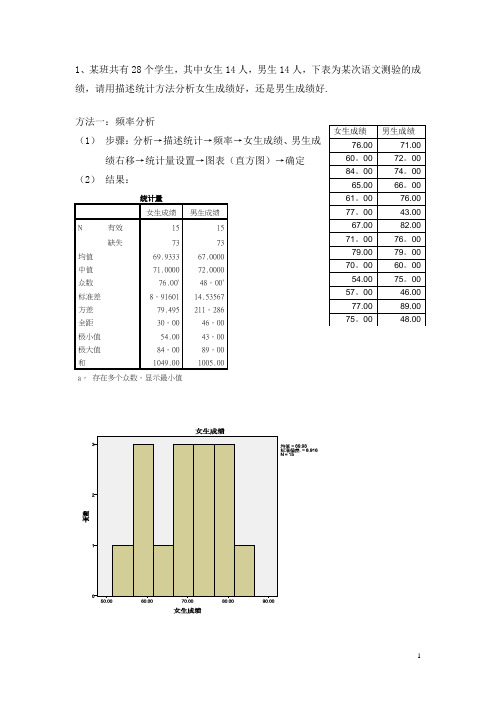
1、某班共有28个学生,其中女生14人,男生14人,下表为某次语文测验的成绩,请用描述统计方法分析女生成绩好,还是男生成绩好. 方法一:频率分析(1) 步骤:分析→描述统计→频率→女生成绩、男生成绩右移→统计量设置→图表(直方图)→确定 (2) 结果:统计量女生成绩男生成绩N有效 1515 缺失73 73 均值 69.9333 67.0000 中值 71.0000 72.0000 众数 76.00a48。
00a标准差 8。
91601 14.53567 方差 79.495 211。
286 全距 30。
00 46。
00 极小值 54.00 43。
00 极大值 84。
00 89。
00 和1049.001005.00a 。
存在多个众数。
显示最小值(3)分析:由统计量表中的均值、标准差及直方图可知,女生成绩比男生成绩好。
方法二:描述统计(1)步骤:分析→描述统计→描述→女生成绩、男生成绩右移→选项设置→确定(2)结果:描述统计量N 极小值极大值均值标准差方差女生成绩15 54。
00 84。
00 69.9333 8.91601 79。
495 男生成绩15 43.00 89.00 67.0000 14.53567 211.286 有效的 N (列表状态)15(3)分析:由描述统计量表中的均值、标准差、方差可知,女生成绩比男生成绩好。
2、某公司经理宣称他的雇员英语水平很高,现从雇员中随机随出11人参加考试,得分如下:80、81、72、60、78、65、56、79、77、87、76,请问该经理的宣称是否可信?(1)方法:单样本T检验H 0:u=u,该经理的宣称可信H 1:u≠u,该经理的宣称不可信(2)步骤:①输入数据:(80,81,…76)②分析→比较均值→单样本T检验→VAR00001右移→检验值(75)→确定(3)结果:单个样本统计量N 均值标准差均值的标准误VAR00001 11 73.73 9。
551 2.880(4)分析:由单个样本检验表中数据知t=0。
spss案例分析报告(精选)

spss案例分析报告(精选)本文通过分析一份 SPSS 数据,展示 SPSS 在统计分析中的应用。
数据概述本数据为一家咖啡馆的销售数据,共有 200 条记录,包括 7 个变量:日期、时间、收银员、商品名、销售价格、数量和总价。
SPSS 分析1. 描述性统计使用 SPSS 的描述性统计功能,可以获取数据的基本信息,如均值、标准偏差、最大值、最小值等。
其中,销售价格的均值为 44.71 元,标准偏差为 13.29 元,最小值为 23 元,最大值为 78 元。
数量的均值为 1.62 个,标准偏差为 0.51 个,最小值为 1 个,最大值为3 个。
总价的均值为 73.25 元,标准偏差为 21.89 元,最小值为 23 元,最大值为 156 元。
2. 单样本 t 检验假设一杯咖啡的平均售价为 50 元,我们可以使用单样本 t 检验对这个假设进行检验。
首先,我们需要用 SPSS 的数据透视表功能,计算出每杯咖啡的平均售价。
然后,使用单样本 t 检验功能,输入样本均值、假设的总体均值(50 元)、样本标准差、样本大小以及置信度水平。
在这个数据集中,单样本 t 检验得出的 t 值为 -2.36,P 值为 0.019,显著性水平为 0.05,因此我们可以拒绝原假设,认为该咖啡馆的咖啡售价不是 50 元。
4. 相关分析假设我们想要了解商品数量和销售额之间的关系,我们可以使用 SPSS 的相关分析功能来进行分析。
首先,我们需要使用数据透视表功能,计算出每个订单的总价和数量。
然后,使用相关分析功能,输入这两个变量的值,得出相关系数和显著性水平。
在这个数据集中,商品数量和销售额之间的相关系数为 0.749,P 值为 0,显著性水平非常显著。
因此,我们可以认为商品数量和销售额之间存在极强的正相关关系。
结论本文通过 SPSS 对一份咖啡馆销售数据进行分析,展示了 SPSS 在统计分析中的应用。
通过描述性统计、单样本 t 检验、双样本 t 检验和相关分析等功能,我们可以获得数据的基本信息,检验假设,分析变量之间的关系,从而帮助企业更好地决策和管理。
SPSS数据分析案例-信度效度-调节效应-中介效应

样本的基本计数统计:年龄、艺考科目、准备时间、年级、性别、是否独生、是否寄宿、家庭类型对于变量年龄,年龄为16的频数是72(占17.2%),年龄为17的频数是224(占53.5%),年龄为18的频数是123(占29.4%);对于变量艺考科目,艺考科目为体育的频数是57(占13.6%),艺考科目为美术的频数是208(占49.6%),艺考科目为舞蹈的频数是86(占20.5%),艺考科目为音乐的频数是68(占16.2%);对于变量准备时间,准备时间为高二的频数是362(占86.4%),准备时间为高三的频数是57(占13.6%);对于变量年级,年级为高二的频数是75(占17.9%),年级为高三的频数是344(占82.1%);对于变量性别,性别为男的频数是153(占36.5%),性别为女的频数是266(占63.5%);对于变量是否独生,是否独生为是的频数是303(占72.3%),是否独生为否的频数是116(占27.7%);对于变量是否寄宿,是否寄宿为是的频数是275(占65.6%),是否寄宿为否的频数是144(占34.4%);对于变量家庭类型,家庭类型为双亲家庭的频数是301(占71.8%),家庭类型为组合家庭的频数是118(占28.2%)。
变量年龄、艺考科目、准备时间、年级、性别、是否独生、是否寄宿、家庭类型的计数统计频数百分比年龄16 72 17.217 224 53.518 123 29.4艺考科目体育57 13.6美术208 49.6舞蹈86 20.5音乐68 16.2 准备时间高二362 86.4高三57 13.6 年级高二75 17.9高三344 82.1 性别男153 36.5女266 63.5 是否独生是303 72.3否116 27.7 是否寄宿是275 65.6否144 34.4 家庭类型双亲家庭301 71.8变量年龄、艺考科目、准备时间、年级、性别、是否独生、是否寄宿、家庭类型的计数统计频数百分比组合家庭118 28.2变量反向编码因为变量q11_2、q11_5、q11_6、q11_12、q11_11、q11_14、q11_16、q11_17、q11_18、q11_20是反向计分的,为了和其他题目保持相同的计分方式,并且能够与其他题目合成,我们需要对这些题目进行反向计分,也就是把分数进行转换使得高分变成低分,低分变成高分。
spss案例统计分析大学生收支分析

spss案例统计分析大学生收支分析标题:SPSS案例统计分析——大学生收支分析随着社会经济的发展和科技的进步,大学生作为未来社会的中坚力量,他们的收支情况日益受到社会各界的。
本文通过SPSS软件对大学生的收支情况进行案例统计分析,以揭示他们的经济生活状况。
一、数据来源与处理本文选取了某高校500名大学生作为研究对象,通过问卷调查的方式收集他们的收支数据。
数据包括每个学生的基本信息(如性别、年级、专业等)、月收入、月支出以及主要支出项目等。
在数据处理阶段,我们利用SPSS软件对数据进行清洗、整理和分类,以确保数据的质量和可用性。
二、大学生收支情况的描述性统计分析通过SPSS软件的描述性统计分析功能,我们可以得到大学生月收入和月支出的平均值、中位数、标准差等统计指标。
结果显示,大学生的月收入平均值为1500元,月支出平均值为1200元,收支差额平均为300元。
男生的月支出略高于女生,高年级学生的月支出略高于低年级学生。
三、大学生收支情况的交叉统计分析为了进一步探究大学生收支情况的影响因素,我们采用交叉统计分析方法,将学生的收支情况与他们的性别、年级、专业等因素进行关联分析。
结果显示,不同性别、年级和专业的大学生在收支情况上存在一定差异。
例如,女生的月支出普遍较低,而男生的月支出普遍较高;高年级学生的月支出普遍较高,低年级学生的月支出普遍较低;人文社科类专业的月支出普遍较低,理工科类专业的月支出普遍较高。
四、大学生主要支出项目的频数分析为了了解大学生主要支出项目的分布情况,我们采用频数分析方法,对收集到的数据进行统计。
结果显示,大学生的主要支出项目包括生活必需品(如食品、衣物等)、学习用品(如书本、文具等)、娱乐社交(如电影、聚餐等)以及交通费用等。
其中,生活必需品和学习用品的支出占据较大比例。
五、结论与建议通过以上统计分析,我们可以得出以下目前大学生收支状况整体稳定,但存在一定差异。
男生、高年级和理工科类专业的学生月支出相对较高,而女生、低年级和人文社科类专业的学生月支出相对较低。
大学生spss数据分析案例

大学生spss数据分析案例大学生SPSS数据分析案例。
在大学教育中,数据分析是一个非常重要的环节,尤其是对于社会科学和商业管理专业的学生来说。
SPSS(Statistical Package for the Social Sciences)是一个专业的统计分析软件,广泛应用于学术研究和商业决策中。
本文将以一个大学生SPSS数据分析案例为例,介绍如何使用SPSS进行数据分析。
案例背景:某大学社会科学专业的学生对大学生活满意度进行了调查,并收集了相关数据,包括学生的性别、年级、专业、宿舍类型、课程质量、宿舍环境、社交活动等方面的信息。
现在需要对这些数据进行分析,以了解不同因素对大学生活满意度的影响。
数据准备:首先,需要将调查所得的数据录入SPSS软件中,确保数据的准确性和完整性。
在录入数据时,要注意将不同的变量分别录入不同的列中,以便后续的分析和处理。
数据分析:1. 描述统计分析。
首先,可以对各个变量进行描述统计分析,包括计算均值、标准差、频数分布等。
通过描述统计分析,可以直观地了解各个变量的分布情况,为后续的分析提供基础。
2. 相关性分析。
接下来,可以进行各个变量之间的相关性分析,通过相关系数的计算来了解不同变量之间的关联程度。
例如,可以分析学生的性别、年级、专业与大学生活满意度之间的相关性,以及宿舍类型、课程质量、社交活动等因素对大学生活满意度的影响程度。
3. 方差分析。
针对分类变量,可以进行方差分析,比较不同组别之间的均值差异是否显著。
例如,可以分析不同年级、不同专业的学生对大学生活满意度的差异情况,以及不同宿舍类型对大学生活满意度的影响是否显著。
4. 回归分析。
最后,可以利用回归分析来探讨不同因素对大学生活满意度的影响程度。
通过建立回归模型,可以了解各个自变量对因变量的影响情况,以及它们之间的关系强度和方向。
结论与建议:通过以上的数据分析,可以得出不同因素对大学生活满意度的影响程度,为学校和相关部门提供决策建议。
用SPSS进行相关分析的典型案例

数据预处理
缺失值处理
对于缺失值,可以采用删除缺失样本、均值插补、多重插补等方法进行处理。在本案例中,由于缺失值较少,采用删 除缺失样本的方法进行处理。
异常值处理
对于异常值,可以采用箱线图、散点图等方法进行识别和处理。在本案例中,通过箱线图发现存在少数极端异常值, 采用删除异常样本的方法进行处理。
数据标准化
06
典型案例三:经济学领域 应用
案例背景介绍
研究目的
探讨某国经济增长与失业率之间的关系 。
VS
数据来源
采用某国统计局发布的年度经济数据,包 括GDP增长率、失业率等指标。
SPSS操作步骤详解
1. 数据导入与整理 将原始数据导入SPSS软件。 对数据进行清洗和整理,确保数据质量和准确性。
SPSS操作步骤详解
显著性检验
观察相关系数旁边的显著性水平 (p值),判断相关关系是否具有 统计显著性。通常情况下,p值小 于0.05被认为具有统计显著性。
结果讨论
结合相关系数和显著性检验结果 ,讨论社会经济地位与心理健康 之间的关系。例如,可以探讨不 同教育水平或职业对心理健康的 影响,以及这种关系在不同人群 中的差异。
关注SPSS输出的显著性检验结果。如 果P值小于设定的显著性水平(如 0.05),则认为药物剂量与症状改善 程度之间的相关性是显著的,即两变 量之间存在统计学意义的关联。
结合专业背景和实际情境,对结果进 行解释和讨论。例如,如果药物剂量 与症状改善程度呈正相关且相关性显 著,可以认为增加药物剂量有助于改 善患者症状。同时,需要注意结果的 局限性和可能的影响因素,以便为医 学实践提供有价值的参考信息。
提出政策建议或未来研究方向,以促进经济增长和降 低失业率。
统计学课SPSS数据分析实战案例
统计学课SPSS数据分析实战案例SPSS(统计分析系统)是一款常用的统计软件,被广泛应用于社会科学、商业、医学等领域的数据分析工作中。
通过这个案例,我们将运用SPSS软件进行数据分析,以展示统计学课的实战应用。
案例背景假设你是一位市场研究员,你的公司正在调查消费者对某产品的满意度。
你已经收集了一份随机抽样的数据集,包含了消费者的满意度评分以及他们的一些个人信息。
你的任务是对这些数据进行分析,以了解消费者满意度与个人信息之间是否存在关联。
数据集说明数据集包括了500个消费者的信息,具体变量如下:1. 变量1:满意度评分(连续变量,取值范围从1到10);2. 变量2:性别(分类变量,取值为男性和女性);3. 变量3:年龄(连续变量);4. 变量4:收入水平(分类变量,取值为低、中、高三个层次);5. 变量5:购买次数(连续变量,表示过去一年内购买该产品的次数)。
数据分析步骤以下是对这份数据集进行分析的步骤:1. 数据清洗和准备首先,我们需要检查数据集中是否存在缺失值或异常值,并进行数据清洗。
在SPSS中,我们可以使用数据查看和数据清洗的功能来完成这一步骤。
确保数据集中的每一列都没有缺失值,并且所有的异常值已经得到恰当的处理。
2. 描述性统计分析接下来,我们可以使用SPSS的描述性统计分析功能,对数据集进行描述性统计分析。
我们可以计算满意度评分、年龄和购买次数的平均值、标准差、最小值、最大值,并生成频数分布表和柱状图。
3. 相关性分析为了确定满意度评分与其他个人信息变量之间的关联性,我们可以使用SPSS的相关性分析功能。
通过计算满意度评分与性别、年龄、收入水平和购买次数之间的相关系数,我们可以评估它们之间的相关性。
4. 单因素方差分析我们可以使用SPSS进行单因素方差分析,以了解不同收入水平的消费者在满意度评分上是否存在显著差异。
通过观察方差分析表和显著性水平,我们可以得出初步结论。
5. 多元线性回归分析最后,我们可以使用SPSS的多元线性回归分析功能来建立一个回归模型,以预测满意度评分。
spss数据分析报告案例
SPSS数据分析报告案例1. 研究背景本研究旨在调查大学生是否存在晚睡现象,并探究晚睡与健康问题之间的关系。
通过采集大学生的睡眠时间、就寝时间以及健康状况等数据,利用SPSS软件进行数据分析,进一步了解大学生的睡眠状况与健康问题的关联。
2. 数据概况本研究共收集了200名大学生的数据,其中包括性别、年级、每晚睡眠时间、平均就寝时间、是否存在健康问题等变量。
下面是对数据的描述统计分析结果:•性别分布:男性占50%,女性占50%。
•年级分布:大一占25%,大二占30%,大三占25%,大四占20%。
•每晚睡眠时间:平均睡眠时间为7.8小时,标准差为1.2小时。
最小值为5小时,最大值为10小时。
•平均就寝时间:平均就寝时间为23:30,标准差为0.5小时。
最早就寝时间为22:00,最晚就寝时间为01:00。
•健康问题:共有45%的大学生存在健康问题。
3. 数据分析结果3.1 性别与睡眠时间的关系首先,我们探究性别与睡眠时间之间的关系。
利用独立样本T检验,得出以下的结果:•假设检验:男性和女性的睡眠时间是否存在显著差异?•结果:独立样本T检验显示,男性平均睡眠时间为7.6小时,女性平均睡眠时间为8.0小时。
T值为-2.14,P值为0.034,意味着男性和女性的睡眠时间存在显著差异。
3.2 年级与睡眠时间的关系我们进一步探究年级与睡眠时间的关系。
使用单因素方差分析(ANOVA),得出以下结果:•假设检验:各年级的睡眠时间是否存在显著差异?•结果:单因素方差分析显示,大一、大二、大三和大四的平均睡眠时间分别为7.7小时、7.9小时、8.1小时和7.6小时。
F值为2.75,P值为0.043,说明各年级之间的睡眠时间存在显著差异。
3.3 睡眠时间与健康问题的关系最后,我们分析睡眠时间与健康问题之间的关系。
利用相关分析,得出以下结果:•假设检验:睡眠时间与健康问题之间是否存在相关性?•结果:相关分析结果显示,睡眠时间和健康问题之间存在显著负相关(r = -0.25,P值 = 0.001),即睡眠时间越少,存在健康问题的可能性越大。
spss数据分析案例
spss数据分析案例SPSS数据分析案例。
在实际的数据分析工作中,SPSS(Statistical Product and Service Solutions)是一个非常常用的统计分析软件。
它提供了强大的数据处理和分析功能,可以帮助研究人员快速、准确地进行数据处理和分析。
本文将通过一个实际的案例,介绍如何使用SPSS进行数据分析,并展示分析结果。
案例背景:某公司想要了解员工满意度与工作绩效之间的关系,为了达到这个目的,他们进行了一项调查,收集了员工的满意度评分和绩效评分数据。
现在,他们希望通过这些数据,利用SPSS进行分析,找出员工满意度和工作绩效之间的关系。
数据收集:首先,我们收集了100名员工的满意度评分和绩效评分数据。
满意度评分采用了1-5的五级评分制,绩效评分采用了1-100的百分制评分。
数据导入:将收集到的数据导入SPSS软件中,创建一个新的数据集,并将员工的满意度评分和绩效评分数据分别录入到不同的变量中。
数据描述统计分析:首先,我们对数据进行描述性统计分析,包括计算满意度评分和绩效评分的均值、标准差、最大值、最小值等。
这些统计量可以帮助我们更好地了解数据的分布情况。
相关性分析:接下来,我们使用SPSS进行相关性分析,探索员工满意度评分和绩效评分之间的相关关系。
通过相关性分析,我们可以计算出两个变量之间的相关系数,进而判断它们之间是否存在显著的相关性。
回归分析:在确定了员工满意度评分和绩效评分之间存在相关性的基础上,我们可以进一步进行回归分析,建立员工满意度评分对绩效评分的预测模型。
通过回归分析,我们可以得到员工满意度评分对绩效评分的影响程度,以及其他可能影响绩效评分的因素。
结论:通过SPSS数据分析,我们发现员工满意度评分与绩效评分之间存在显著的正相关关系,即员工满意度评分越高,其绩效评分也越高。
这为公司提高员工绩效提供了重要的参考依据,可以通过提升员工满意度来提高整体绩效水平。
总结:在本案例中,我们利用SPSS软件进行了员工满意度和绩效之间的数据分析。
spss数据分析简单案例
spss数据分析简单案例SPSS数据分析简单案例。
在社会科学研究中,SPSS(统计分析软件包)被广泛应用于数据分析。
本文将通过一个简单的案例来介绍如何使用SPSS进行数据分析。
首先,我们收集了一份关于学生学习成绩的数据,包括学生的性别、年龄、每周学习时间和期末考试成绩。
我们的研究问题是探讨性别、年龄和每周学习时间对学习成绩的影响。
我们首先打开SPSS软件,导入我们收集的数据。
然后,我们可以使用SPSS 的数据编辑功能对数据进行清洗和整理,确保数据的准确性和完整性。
接下来,我们可以使用SPSS的描述性统计功能对数据进行分析。
我们可以计算每个变量的均值、标准差、最大值和最小值,从而对数据的分布和特征有一个直观的了解。
然后,我们可以使用SPSS的相关分析功能来探讨不同变量之间的相关性。
我们可以计算不同变量之间的皮尔逊相关系数,从而了解它们之间的线性关系。
在接下来的分析中,我们可以使用SPSS的回归分析功能来探讨性别、年龄和每周学习时间对学习成绩的影响。
我们可以建立一个多元线性回归模型,从而探讨不同变量对学习成绩的预测作用。
最后,我们可以使用SPSS的图表功能来进行数据可视化分析。
我们可以绘制散点图、柱状图和折线图,从而直观地展示不同变量之间的关系和趋势。
通过以上步骤,我们可以利用SPSS对学生学习成绩的数据进行全面的分析,从而回答我们的研究问题。
在实际研究中,我们还可以进一步探讨其他统计分析方法,如方差分析、卡方检验等,以深入挖掘数据的内在规律。
总之,SPSS作为一款功能强大的统计分析软件,为社会科学研究提供了重要的数据分析工具。
通过本文的简单案例,希望读者能够对SPSS的数据分析功能有一个初步的了解,并能够在实际研究中灵活运用,从而为研究工作提供有力的支持。
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
SPSS统计分析案例一、我国城镇居民现状近年来,我国宏观经济形势发生了重大变化,经济发展速度加快,居民收入稳定增加,在国家连续出台住房、教育、医疗等各项改革措施和实施“刺激消费、扩大内需、拉动经济增长”经济政策的影响下,全国居民的消费支出也强劲增长,消费结构发生了显著变化,消费结构不合理现象得到了一定程度的改善。
本文通过相关数据分析总结出了我国城镇居民消费呈现富裕型、娱乐教育文化服务类消费攀升的趋势特点。
二、我国居民消费结构的横向分析第一,食品消费支出比重随收入增加呈现出明显的下降趋势,这与恩格尔定律的表述一致。
但最低收入户与最高收入恩格尔系数相差太过悬殊,城镇最低收入户刚刚解决了温饱问题,而最高收入户的生活水平按照恩格尔系数的评价标准早已达到了富裕型,甚至接近最富裕型。
第二,衣着消费支出比重随收入增加缓慢上升,到高收入户又有所下降,但各收入组支出比重相差不大。
衣着支出比重没有更多的递增且最高收入户的支出比重有所下降,这些都符合恩格尔定律关于衣着消费的引申。
随着收入的增加,衣着支出比重呈现先上升后下降的走势。
事实上,在当前的价格水平和服装业的发展水平下,城镇居民的穿着是有一定限度的,而且居民对衣着的需求也不是无限膨胀的,即使收入水平继续提高,也不需要将更大的比例用于购买服饰用品了。
第三,家庭设备用品及服务、交通通讯、娱乐教育文化服务和杂项商品与服务的支出比重呈逐组上升趋势,说明居民的生活水平随收入的增加而不断提高和改善。
第四,医疗保健支出比重随收入水平提高呈现一种两端高、中间低的走势。
这是因为医疗保健支出作为生活必须支出,不论居民生活水平高低,都要将一定比例的收入用于维持自身健康,而且由于医疗制度改革,加重了个人负担的同时,也减小了旧制度可能造成的不同行业、不同体制下居民医疗保健支出的差别,因而不同收入等级的居民在医疗保健支出比重上差别不大。
第五,居住支出比重基本上呈先上升后下降的趋势,这与我国居民消费能级不断提升,住宅商品正在越来越成为城镇居民关注的热点是相吻合的,同时与恩格尔定律的引申也是一致的。
可以看出,城镇居民的消费状况虽然受价格水平、消费习惯、消费环境、消费心理预期等诸多因素的影响,但归根结底仍取决于居民的收入水平,要提高城镇居民的消费支出,必须增加居民收入。
因此,采取切实有效的措施增加城镇居民的可支配收入,不仅可以提高全国城镇居民的总体消费水平,促进消费结构向着更加健康、合理的方向发展,而且在启动内需,促进我国的经济发展方面有着重大的现实意义。
三、我国居民消费结构的纵向分析进入21世纪以来,随着经济体制改革的深入,国民经济的迅速发展,我国城乡居民的消费水平显著提高,居民的各项支出显著增加。
随着消费水平的提高,我国城乡居民消费从注重量的满足到追求质的提高,从以衣食消费为主的生存型到追求生活质量的享受型、发展型,消费质量和消费结构都发生了明显的变化。
城镇居民在食品、衣着、家庭设备用品三项支出在消费支出中的比重呈现明显的下降趋势,其中食品类支出比重降幅最大;衣着类有所下降;家庭设备用品类下降幅度不是很大。
与此同时,医疗保健、交通通讯、文化娱乐教育服务、居住及杂项商品支出在消费支出中的比例均有上升,富裕阶段的消费特征开始显现。
四、我国城镇居民消费结构及趋势的统计分析下图是出自《中国统计年鉴—2009》这一资料性年刊,它系统收录了全国和各省、自治区、直辖市2008年经济、社会各方面的统计数据,以及近三十年和其他重要历史年份的全国主要统计数据。
此年鉴正文内容分为24个篇章,本文选取其中的第九篇章-人民生活,用以探究我国城镇居民消费结构及其趋势。
表1 《中国统计年鉴—2009》统计表9-5 城镇居民家庭基本情况#可支配收入1510.16 4282.95 6279.98 13785.81 15780.76平均每人消费性支出(元) 1278.89 3537.57 4998.00 9997.47 11242.85 食品693.77 1771.99 1971.32 3628.03 4259.81衣着170.90 479.20 500.46 1042.00 1165.91居住60.86 283.76 565.29 982.28 1145.41 家庭设备用品及服务108.45 263.36 374.49 601.80 691.83 医疗保健25.67 110.11 318.07 699.09 786.20交通通信40.51 183.22 426.95 1357.41 1417.12 教育文化娱乐服务112.26 331.01 669.58 1329.16 1358.26 杂项商品与服务66.57 114.92 171.83 357.70 418.31平均每人消费性支出构成(人均消费性支出=100)食品54.25 50.09 39.44 36.29 37.89衣着13.36 13.55 10.01 10.42 10.37居住 6.98 8.02 11.31 9.83 10.19 家庭设备用品及服务10.14 7.44 7.49 6.02 6.15 医疗保健 2.01 3.11 6.36 6.99 6.99交通通信 1.20 5.18 8.54 13.58 12.60 教育文化娱乐服务11.12 9.36 13.40 13.29 12.08 杂项商品与服务0.94 3.25 3.44 3.58 3.72注:1.本表至9-17表为城镇住户抽样调查资料。
2.从2002年起,城镇住户调查对象由原来的非农业人口改为城市市区和县城关镇住户,本篇章相关资料均按新口径计算,历史数据作了相应调整。
五、SPSS统计分析图一给出了基本的描述性统计图,图中显示各个变量的全部观测量的Mean(均值)、Std. Deviation(标准差)和观测值总数N。
图2给出了相关系数矩阵表,其中显示3个自变量两两间的Pearson相关系数,以及关于相关关系等于零的假设的单尾显著性检验概率。
图1 描述性统计表图2 相关系数矩阵从表中看到因变量家庭设备用品及服务与自变量食品、衣着之间相关关系数依次为0.869、0.684,反映家庭设备用品及服务与食品、衣着之间存在显著的相关关系。
说明食品与衣着对于家庭设备用品及服务条件的好转有显著的作用。
自变量居住于因变量家庭设备用品及服务之间的相关系数为-0.894,它于其他几个自变量之间的相关系数也都为负,说明它们之间的线性关系不显著。
此外,食品与衣着之间的相关系数为0.950,这也说明它们之间存在较为显著的相关关系。
按照常识,它们之间的线性相关关系也是符合事实的。
图3给出了进入模型和被剔除的变量的信息,从表中我们可以看出,所有3个自变量都进入模型,说明我们的解释变量都是显著并且是有解释力的。
图3 变量进入/剔除信息表图4给出了模型整体拟合效果的概述,模型的拟合优度系数为0.982,反映了因变量于自变量之间具有高度显著的线性关系。
表里还显示了R平方以及经调整的R值估计标准误差,另外表中还给出了杜宾-瓦特森检验值DW=2.632,杜宾-瓦特森检验统计量DW是一个用于检验一阶变量自回归形式的序列相关问题的统计量,DW在数值2到4之间的附近说明模型变量无序列相关。
图4 模型概述表图4给出了方差分析表,我们可以看到模型的设定检验F统计量的值为9.229,显著性水平的P值为0.236。
图5 方差分析表图6给出了回归系数表和变量显著性检验的T值,我们发现,变量居住的T值太小,没有达到显著性水平,因此我们要将这个变量剔除,从这里我们也可以看出,模型虽然通过了设定检验,但很有可能不能通过变量的显著性检验。
图6 回归系数表图7给出了残差分析表,表中显示了预测值、残差、标准化预测值、标准化残差的最小值、最大值、均值、标准差及样本容量等,根据概率的3西格玛原则,标准化残差的绝对值最大为1.618,小于3,说明样本数据中没有奇异值。
图7 残差统计表图8给出了模型的直方图,由于我们在模型中始终假设残差服从正态分布,因此我们可以从这张图中直观地看出回归后的实际残差是否符合我们的假设,从回归残差的直方图于附于图上的正态分布曲线相比较,可以认为残差的分布不是明显地服从正态分布。
尽管这样也不能盲目的否定残差服从正态分布的假设,因为我们用了进行分析的样本太小,样本容量仅为5。
图8 残差分布直方图从上面图4的分析结果看,我们的模型需要剔除居住这个变量,用本次实验中的方法和步骤重新令家庭设备用品及服务对食品和衣着回归,得到的主要结果如图9、图10和图11所示,跟上面的分析类似,从中可以看出,剔除居住这个变量后,模型拟合优度为0.964,比原来有所降低;而方差分析的F检验为27.071,新模型与原来的模型相比,各个系数都通过了显著性T检验,因此更加合理,从而我们可以得出结论:剔除居住这个变量后的模型更加合理,因此在做预测过程中要使用剔除不显著变量后的模型。
图9 模型概述图10 方差分析表图11 回归系数表六、我国居民消费变化的趋势特点(1)食品消费质量提高,衣着消费支出比重下降。
食品消费水平由过去简单的吃饱吃好,转变为品种更加丰富,营养更加全面。
一方面由于食品供应的日益充足。
另一方面由于在外饮食的增加,粮食消费比重减小,购买量大幅度下降。
衣着是两项基本生存资料之一,衣着消费向时装化、名牌化、个性化发展的倾向更加明显,成衣化倾向成为主流。
从衣着和食品消费比重的下降可以看出城镇居民满足基本生活的支出并没有随着收入水平的提高而提高,这表明我国城镇居民满足吃、穿为主的生存型消费需求阶段已经结束,逐步向以发展型和享受型消费的阶段过渡。
(2) 居民收入迅速增长,消费水平大幅度提高,消费结构呈现明显的富裕型特征消费是收入的函数,收入的增加是消费水平提高和消费结构变化的前提。
随着我国经济的发展,我国居民的收入水平不断提高,特别是21世纪以来,我国居民的收入水平迅速提高。
伴随着收入水平的提高,城乡居民各项支出全面增加,消费性支出大幅度增长。
今后5—10年以至更长时间,我国经济保持一个较高的增长速度是完全可能的,城乡居民的消费水平将大幅度提高。
(3)消费能级不断提高,消费内容日益丰富,住房与轿车消费同时升温,可望提前成为消费热点在消费水平提高和消费结构改善的同时,城乡居民的消费能级不断提高。
(4)以教育为龙头的娱乐教育文化服务类消费继续攀升随着人们对知识认知程度的提高和自我完善意识的增强,对教育的投入仍会保持增长。
目前从子女教育在人们储蓄目的位居前列的情况看,对教育及教育产品的投入仍是今后一个时期的消费热点。
大力发展教育事业,特别是高等教育、成人教育、职业教育应是政府长期坚持和倡导的提高城镇居民收入水平,缩小收入差距,应做到:1.进一步强化收入分配的宏观调控力度采取切实措施努力提高低收入群体的收入水平。