python_数据类型
练习题-Python基本数据类型
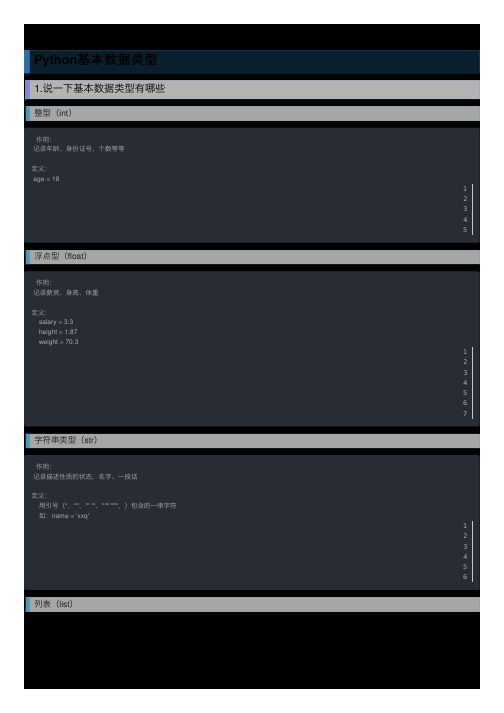
练习题-Python基本数据类型Python基本数据类型1.说⼀下基本数据类型有哪些整型(int)作⽤:记录年龄、⾝份证号、个数等等定义:age = 1812345浮点型(float)作⽤:记录薪资、⾝⾼、体重定义:salary = 3.3height = 1.87weight = 70.31234567字符串类型(str)作⽤:记录描述性质的状态,名字、⼀段话定义:⽤引号('',"",''' ''',""" """,)包含的⼀串字符如:name = 'xxq'123456列表(list)按位置记录多个值(同⼀个⼈的多个爱好、同⼀个班级的所有学校姓名、同⼀个⼈12个⽉的薪资)并且可以按照索引取指定位置的值定义:在[]内⽤逗号分隔开多个任意类型的值,⼀个值称之为⼀个元素如:list1 = [1,2,3,4,'5','六']注意点:索引对应值,索引从0开始,0代表第⼀个12345678910字典(dic)作⽤:⽤来存多个值,每个值都有唯⼀⼀个key与其对应,key对值有描述性功能定义:在{}内⽤逗号分开各多个 key:value如:info={"name":'xxq',"age":18, "gender":'male'}123456布尔类型(bool)作⽤:⽤来记录真假这两种状态定义:is_ok = Trueis_ok = False其他使⽤:通常⽤来当作判断的条件,我们将在if判断中⽤到它1234567元组类型(tuple)按照索引/位置存放多个值,只⽤于读,不⽤于改定义:t = (1,1.3,'aaa')注意点:1.单独⼀个括号,代表包含的意思x = (10)2.如果元组中只有⼀个元素,必须加逗号x = (10,)3.元组不能改,指的是不能改⾥⾯的内存地址t = (1,[11,22])print(t,id(t[0]),id(t[1]))t[1][0] = 33 # 元组内的列表的元素还是可以改的print(t,id(t[0]),id(t[1]))(1, [11, 22]) 2038884272 59297864(1, [33, 22]) 2038884272 5929786412345678910111213141516171819集合类型(set)作⽤:关系运算、去重定义:在 {} 内通逗号隔开多个元素,多个元素满⾜以下条件:1.集合内的元素必须为不可变类型2.集合内的元素⽆序3.集合内的元素没有重复12345678 2.说⼀下交互什么是交互?交互就是⼈和计算机互动,⼈输⼊信息,计算机获取后,输出信息给⼈,循环往复的这个过程,就是交互。
Python基本数据类型(元组)

Python基本数据类型(元组)Python基本数据类型(元组)⼀、概述元组(Tuple)是⼀种与列表类似的序列类型。
元组的基本⽤法与列表⼗分类似。
只不过元组⼀旦创建,就不能改变,因此,元组可以看成是⼀种不可变的列表。
⼆、元组格式Python⽤⼀对括号“()”⽣成元组,中间的元素⽤逗号“,”隔开。
尽量在最后元素后⾯加上⼀个额外的逗号“,”加以区分括号与元组,特别是只含单元素的元组:tu = (11,22,"alex",[(33,44)],)三、元组与列表的相互转换列表和元组可以使⽤tuple()函数和list()函数相互转换:li = [3,6,1,5,4,6]print(tuple(li)) #结果为:(3, 6, 1, 5, 4, 6)tu = (11,22,"alex",[(33,44)],)print(list(tu)) #结果为:[11, 22, 'alex', [(33, 44)]]四、索引和切⽚对于元组来说,只能通过索引和切⽚来取值,不能进⾏修改操作。
tu = (11,22,"alex",[(33,44)],)print(tu[3][0][1]) #结果为:44print(tu[1:-1]) #结果为:(22, 'alex')五、元组的⽅法由于元组是不可变的,所有它只⽀持.count()⽅法和.index()⽅法,⽤法与列表⼀致:.count()⽅法是计算元组的指定元素出现的次数。
tu = (11,22,"alex",[(33,44)],22,)print(tu.count(22)) #结果为:2.index()⽅法是获取指定元素第⼀次出现的索引位置。
tu = (11,22,"alex",[(33,44)],22,)print(tu.index(22)) #结果为:1元组所有⽅法归纳:1 lass tuple(object):2"""3 tuple() -> empty tuple4 tuple(iterable) -> tuple initialized from iterable's items56 If the argument is a tuple, the return value is the same object.7"""8def count(self, value): # real signature unknown; restored from __doc__9""" T.count(value) -> integer -- return number of occurrences of value """10return 01112def index(self, value, start=None, stop=None): # real signature unknown; restored from __doc__13"""14 T.index(value, [start, [stop]]) -> integer -- return first index of value.15 Raises ValueError if the value is not present.16"""17return 01819def__add__(self, y): # real signature unknown; restored from __doc__20""" x.__add__(y) <==> x+y """21pass2223def__contains__(self, y): # real signature unknown; restored from __doc__24""" x.__contains__(y) <==> y in x """25pass2627def__eq__(self, y): # real signature unknown; restored from __doc__28""" x.__eq__(y) <==> x==y """29pass3031def__getattribute__(self, name): # real signature unknown; restored from __doc__ 32""" x.__getattribute__('name') <==> """33pass3435def__getitem__(self, y): # real signature unknown; restored from __doc__36""" x.__getitem__(y) <==> x[y] """37pass3839def__getnewargs__(self, *args, **kwargs): # real signature unknown40pass4142def__getslice__(self, i, j): # real signature unknown; restored from __doc__43"""44 x.__getslice__(i, j) <==> x[i:j]4546 Use of negative indices is not supported.47"""48pass4950def__ge__(self, y): # real signature unknown; restored from __doc__51""" x.__ge__(y) <==> x>=y """52pass5354def__gt__(self, y): # real signature unknown; restored from __doc__55""" x.__gt__(y) <==> x>y """56pass5758def__hash__(self): # real signature unknown; restored from __doc__59""" x.__hash__() <==> hash(x) """60pass6162def__init__(self, seq=()): # known special case of tuple.__init__63"""64 tuple() -> empty tuple65 tuple(iterable) -> tuple initialized from iterable's items6667 If the argument is a tuple, the return value is the same object.68 # (copied from class doc)69"""70pass7172def__iter__(self): # real signature unknown; restored from __doc__73""" x.__iter__() <==> iter(x) """74pass7576def__len__(self): # real signature unknown; restored from __doc__77""" x.__len__() <==> len(x) """78pass7980def__le__(self, y): # real signature unknown; restored from __doc__81""" x.__le__(y) <==> x<=y """82pass8384def__lt__(self, y): # real signature unknown; restored from __doc__85""" x.__lt__(y) <==> x<y """86pass8788def__mul__(self, n): # real signature unknown; restored from __doc__89""" x.__mul__(n) <==> x*n """90pass9192 @staticmethod # known case of __new__93def__new__(S, *more): # real signature unknown; restored from __doc__94""" T.__new__(S, ...) -> a new object with type S, a subtype of T """95pass9697def__ne__(self, y): # real signature unknown; restored from __doc__98""" x.__ne__(y) <==> x!=y """99pass100101def__repr__(self): # real signature unknown; restored from __doc__ 102""" x.__repr__() <==> repr(x) """103pass104105def__rmul__(self, n): # real signature unknown; restored from __doc__ 106""" x.__rmul__(n) <==> n*x """107pass108109def__sizeof__(self): # real signature unknown; restored from __doc__ 110""" T.__sizeof__() -- size of T in memory, in bytes """111pass 112113 tuple tuple。
Python基础-数据类型总结归纳.

Python基础-数据类型总结归纳.1.1、python3 数据类型:类型含义⽰例int整型1float浮点型 1.0bool布尔值True或Falsecomplex复数a+bjstring字符串‘abc123’list列表[a,b,c]tuple元组(a,b,c)set集合{a,b,c}dictionary字典{a:b,c:d}1.2、备注说明类型说明complex复数的虚数部分不能省略string(字符串)字符串不能包括有 ‘\’ ,否则输出的不是原来的字符串list(列表)和tuple(元组)list可以修改元素,tuple不能,但是tuple可以包括list等多种数据类型,占⽤资源多于listset(集合)没有排列的顺序(没有索引,不能通过索引取值)及不会有重复的元素dictionary(字典)⼀个键对应多个值(值可以是列表、字典、集合等),⼀个值也可对应多个键。
但是不能有相同的键、列表作为值可以重复、字典和集合作为值不能重复。
不可变数据(3 个):Number(数字)、String(字符串)、Tuple(元组);可变数据(3 个):List(列表)、Dictionary(字典)、Set(集合)。
可变数据类型:value值改变,id值不变;不可变数据类型:value值改变,id值也随之改变。
(元组不可修改,所以元组是不可变类型)变量以及类型<1>变量的定义在程序中,有时我们需要对2个数据进⾏求和,那么该怎样做呢?⼤家类⽐⼀下现实⽣活中,⽐如去超市买东西,往往咱们需要⼀个菜篮⼦,⽤来进⾏存储物品,等到所有的物品都购买完成后,在收银台进⾏结账即可如果在程序中,需要把2个数据,或者多个数据进⾏求和的话,那么就需要把这些数据先存储起来,然后把它们累加起来即可在Python中,存储⼀个数据,需要⼀个叫做变量的东西,如下⽰例:1. num1 = 100 #num1就是⼀个变量,就是⼀个模具2. num2 = 87 #num2也是⼀个变量3. result = num1 + num2 #把num1和num2这两个"模具"中的数据进⾏累加,然后放到 result变量中说明:所谓变量,可以理解为模具(内存空间),如果需要存储多个数据,最简单的⽅式是有多个变量,当然了也可以使⽤⼀个列表程序就是⽤来处理数据的,⽽变量就是⽤来存储数据的变量定义的规则:变量名只能是字母、数字或下划线的任意组合变量名的第⼀个字符不能是数字以下关键字不能声明为变量名['and', 'as', 'assert', 'break', 'class', 'continue', 'def', 'del', 'elif', 'else', 'except', 'exec', 'finally', 'for', 'from', 'global', 'if', 'import', 'in', 'is', 'lambda', 'not', 'or', 'pass', 'print', 'raise', 'return', 'try', 'while', 'with', 'yield']想⼀想:我们应该让变量占⽤多⼤的空间,保存什么样的数据?<2>变量的类型Python采⽤动态类型系统。
列举出python中常用的组合数据类型

一、列表(List)在Python中,列表是一种有序的集合,可以容纳多个数据项,其中的数据项可以是不同类型的。
列表是可变的,可以随时添加、删除或修改其中的元素。
列表使用方括号[] 来表示,元素之间使用逗号分隔。
例如:```pythonmy_list = [1, 2, 3, "a", "b", "c"]```二、元组(Tuple)元组和列表类似,也是一种有序的集合,不同之处在于元组是不可变的,一旦创建后就不能进行修改。
元组使用圆括号 () 表示,元素之间同样使用逗号分隔。
例如:```pythonmy_tuple = (1, 2, 3, "a", "b", "c")```三、集合(Set)集合是一种无序的集合,其中的元素互不相同,可以用于去除重复元素或进行集合运算。
集合使用大括号 {} 或 set() 函数来创建。
例如:```pythonmy_set = {1, 2, 3, 4, 5}```四、字典(Dictionary)字典是一种键值对的数据结构,可以用于存储和查找具有键值关系的数据。
字典使用大括号 {} 表示,其中的键值对使用冒号 : 分隔,不同的键值对之间使用逗号分隔。
例如:```pythonmy_dict = {"name": "John", "age": 25, "city": "New York"}```五、序列(Sequence)序列是一种有序的集合,包括字符串、列表、元组等。
序列可以进行索引、切片、拼接等操作。
六、其他数据类型除了上述常用的组合数据类型外,Python中还有一些其他的数据类型,如字节对象(bytes)、字节数组(bytearray)、range对象等,它们在特定的场景下也具有重要的作用。
python基础知识--高考信息技术一轮二轮复习数据结构基础知识(浙教版2019)

Python 程序设计语言基础知识一、Python 的基本数据类型二、(1)算术运算符:**、*、/、//、%、+、-。
(2)关系运算符:<、<=、>、>=、==、!=、in 。
“==”表示判断,“=”表示赋值。
(3)逻辑运算符:not 、and 、or 。
(5)x +=1:将变量x 的值加1,与“x =x +1”等价,类似还有“-=”、“*=”、“/=”、“%=” (6)取某三位数n 各个位的方法:个位:n % 10 十位: n // 10 % 10 或n %100 // 10 百位: n //100 三、字符串字符串是用单引号(')、双引号(″)或三引号(''')括起来的一个字符序列,起始和末尾的引号必须要一致。
1.字符串的特点(1)字符串是不可变对象。
即一旦创建了一个字符串,那么这个字符串的内容是不可改变的。
(2)通过索引来访问字符串中的字符。
索引表示字符在字符串的位置,第一个元素的索引号是0,第二个元素的索引号是1,以此类推。
2.字符串的切片操作通过字符串的切片操作可以获得字符串的一个子串。
格式为:字符串名[start :end :step]step 默认为1,表示返回下标从start 到end -1的字符构成的一个子串。
四、列表列表是由0个或多个元素组成的序列,其中的元素可以是数字、字符串等混合类型的数据,甚至是其他的列表。
1.列表的特点(1)列表用[]表示,元素间用逗号分隔,不同类型的元素可以存储在同一列表中。
(2)列表的大小是可变的,可以根据需要增加或缩小。
(3)列表是可变对象。
一个列表被创建后,可以直接修改列表中的元素值。
2.列表的访问列表中的元素是通过索引来定位的,第一个元素的索引号是0。
列表中的元素可以通过索引进行访问。
3.列表的切片操作列表的切片形式为list[i :j :k],i 为起始位置索引(包含),默认为0,j 为终止位置索引(不含),默认至序列尾;k 为切片间隔,默认为1。
2.Python基本数据类型

字符串类型
字符串的处理方法
字符串类型
字符串的处理方法
字符串类型
字符串的处理方法
字符串类型
字符串类型的格式化
格式化是对字符串进行格式表达的方式
字符串format()方法的基本使用格式是: <模板字符串>.format(<逗号分隔的参数>)
字符串类型
字符串类型的格式化
- 如果希望在字符串中既包括单引号又包括双引号呢?
''' 这里既有单引号(')又有双引号 (") '''
字符串类型
字符串类型的表示
Python中字符串索引从0开始,一个长度为L的字符串最后一个 字符的位置是L-1 Python同时允许使用负数 从字符串右边末尾向左边进行 反向索引,最右侧索引值是-1
数字类型
math库概述
首先使用保留字import引用该库 • 第一种:import math 对math库中函数采用math.<b>()形式使用
• 第二种,from math import <函数名> 对math库中函数可以直接采用<函数名>()形式使用
数字类型
math库概述
首先使用保留字import引用该库 • 第一种:import math 对math库中函数采用math.<b>()形式使用
- 十六进制,以0x或0X开头:0x9a, -0X89
数字类型
浮点数类型
- 与数学中实数的概念一致,带有小数点及小数的数字
- 浮点数取值范围和小数精度都存在限制,但常规计算可忽略 - 取值范围数量级约-10 308 至10 308 ,精度数量级10 -16
【Python】(六)Python数据类型-列表和元组,九浅一深,用得到
【Python】(六)Python数据类型-列表和元组,九浅⼀深,⽤得到您好,我是码农飞哥,感谢您阅读本⽂,欢迎⼀键三连哦。
本⽂分⼗个章节介绍数据类型中的列表(list)和元组(tuple),从使⽤说到底层实现,包您满意⼲货满满,建议收藏,需要⽤到时常看看。
⼩伙伴们如有问题及需要,欢迎踊跃留⾔哦~ ~ ~。
⼀浅: 列表(list)的介绍列表作为Python序列类型中的⼀种,其也是⽤于存储多个元素的⼀块内存空间,这些元素按照⼀定的顺序排列。
其数据结构是:[element1, element2, element3, ..., elementn]element1~elementn表⽰列表中的元素,元素的数据格式没有限制,只要是Python⽀持的数据格式都可以往⾥⾯⽅。
同时因为列表⽀持⾃动扩容,所以它可变序列,即可以动态的修改列表,即可以修改,新增,删除列表元素。
看个爽图吧!⼆浅:列表的操作⾸先介绍的是对列表的操作:包括列表的创建,列表的删除等!其中创建⼀个列表的⽅式有两种:第⼀种⽅式:通过[]包裹列表中的元素,每个元素之间通过逗号,分割。
元素类型不限并且同⼀列表中的每个元素的类型可以不相同,但是不建议这样做,因为如果每个元素的数据类型都不同的话则⾮常不⽅便对列表进⾏遍历解析。
所以建议⼀个列表只存同⼀种类型的元素。
list=[element1, element2, element3, ..., elementn]例如:test_list = ['测试', 2, ['码农飞哥', '⼩伟'], (12, 23)]PS: 空列表的定义是list=[] 第⼆种⽅式:通过list(iterable)函数来创建列表,list函数是Python内置的函数。
该函数传⼊的参数必须是可迭代的序列,⽐如字符串,列表,元组等等,如果iterable传⼊为空,则会创建⼀个空的列表。
Python基础总结
Python基础一、Python中数据类型在Python中,能够直接处理的数据类型有以下几种:一、整数Python可以处理任意大小的整数,当然包括负整数,在Python程序中,整数的表示方法和数学上的写法一模一样,例如:1,100,—8080,0,等等.计算机由于使用二进制,所以,有时候用十六进制表示整数比较方便,十六进制用0x前缀和0—9,a—f表示,例如:0xff00,0xa5b4c3d2,等等。
二、浮点数浮点数也就是小数,之所以称为浮点数,是因为按照科学记数法表示时,一个浮点数的小数点位置是可变的,比如,1。
23x10^9和12。
3x10^8是相等的。
浮点数可以用数学写法,如1。
23,3。
14,—9.01,等等。
但是对于很大或很小的浮点数,就必须用科学计数法表示,把10用e替代,1。
23x10^9就是1.23e9,或者12。
3e8,0.000012可以写成1。
2e—5,等等。
整数和浮点数在计算机内部存储的方式是不同的,整数运算永远是精确的(除法难道也是精确的?是的!),而浮点数运算则可能会有四舍五入的误差.三、字符串字符串是以’'或”"括起来的任意文本,比如’abc’,"xyz”等等。
请注意,’’或””本身只是一种表示方式,不是字符串的一部分,因此,字符串'abc’只有a,b,c这3个字符.四、布尔值布尔值和布尔代数的表示完全一致,一个布尔值只有True、False两种值,要么是True,要么是False,在Python中,可以直接用True、False表示布尔值(请注意大小写),也可以通过布尔运算计算出来.布尔值可以用and、or和not运算。
and运算是与运算,只有所有都为True,and运算结果才是True。
or运算是或运算,只要其中有一个为True,or 运算结果就是True。
not运算是非运算,它是一个单目运算符,把True 变成False,False 变成True.五、空值空值是Python里一个特殊的值,用None表示.None不能理解为0,因为0是有意义的,而None是一个特殊的空值。
云开发技术应用Python-03-1-数据类型课件
3.1.6 容器类型简介
列表和元组(list & tuple)
类似于C语言中的数组,不过它们支持不同类型的元素,可以是数字、字符串、 其它列表、字典或集合。它们的表面区别在于,列表用方括号来声明和表达,而元 组使用圆括号;它们的内在区别在于,列表是可变对象,元组是不可变对象。
>>> a=[1,2,3] >>> b=(1,2,3) >>> type(a) <class 'list'> >>> type(b) <class 'tuple'>
>>> a=66.6 >>> type(a) <class 'float'> >>> b=int(a) >>> type(b) <class 'int'> >>> b 66 >>> c=float(b) >>> type(c) <class 'float'> >>> c 66.0 >>>
要注意的是:在源代码文件中,直接输入对象不会显示任何结果,你必须通过 其它方法,例如使用print函数。
3.1.6
容器类型简介
容器类型是由基本数据类型组成的复合数据类型,是Python内置的数据结
构,在本课程的现阶段,只对容器类型做最简单的介绍。要了解更多,请参考后
续课程。
字符串
序列
列表
容器数据类型
字典(映射)
集合
Python程序设计_Python语言数据类型、运算符和表达式
"What's your name?"
"What\'s" + "your name? "
12
变量
• 仅仅使用字面意义上的常量很快就会不能 满足我们的需求——我们需要一种既可以
储存信息又可以对它们进行操作(改变它
的内容)的方法。这是为什么要引入 变量
。
• 变量的值可以变化,即可以使用变量存储
缩进
• 如何缩进 不要混合使用制表符和空格来缩进,因为这在跨
越不同的平台的时候,无法正常工作。强烈建议 在每个缩进层次使用 单个制表符 或 两个或四个 空格 。
选择这三种缩进风格之一。更加重要的是,选择
一种风格,然后一贯地使用它,即 只 使用这一种
风格。
• Python迫使程序员写成统一、整齐并且具有可读
s = '''This is a multi-line string. This is the second line.''' print s
18
逻辑行与物理行
• 物理行是在编写程序时所 看见 的。逻辑行 是Python 看见 的单个语句。Python假定每 个 物 理行 对应一个 逻辑行
• Python希望每行都只使用一个语句,这样 使得代码更加易读
– 标识符名称的其他部分可以由字母(大写或小写)、下 划线(‘ _ ’)或数字(0-9)组成。
– 标识符名称是对大小写敏感的。例如,myname和 myName不是一个标识符。注意前者中的小写n和后者中 的大写N。
– 有效 标识符名称的例子有i、__my_name、name_23和
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
python 数据类型
python具有非常丰富的数据类型,
包括字符串,列表,元组,字典集合等,每种数据类型的特点都大一样,好好利用他们
可以让你的python编程变的非常轻松,要好好利用就应该充分了解他们的特点,下面对他们的特点进行一些总结。
python字符串:
字符串在python中是一个单个字符的字符串的序列,可以对字符串进行切片连接等相关操作。
下面是关于python字符串的一些文章:
python 字符串替换
python字符串连接
python列表:
列表是一个任意数据类型组成的有序集合,有点像其它语言的数组,如果用过其它语言的朋友相信对它不会陌生,列表的操作非常
丰富,可以用dir来查看他自带的方法。
下面是关于python列表的一些文章:
python列表
python列表操作方法
python元组:
python元组和列表一样都是有序序列,所不同的是元组是不可变的类型,经常用在系统配置文件里,作为系统的配置信息,比较安全和稳定,不容易轻易被改变。
下面是python元组的一些文章:
python 元组
python字典:
字典是python对象中唯一的映射的类型,和数学的映射的关系差不多,其它的语言也有大概的数据类型,自带的方法也很多
下面是python字典的一些文章:
python 字典:
python 字典添加
python集合:
python集合在其它的语言好像比较少见,做一些中间处理还是非常好的
下面是python集合的一些文章:
python 集合
下面是一些朋友总结的。
共同点:
1、它们都是py的核心类型,是py语言自身的一部分。
核心类型与非核心类型
多数核心类型可通过特定语法来生成其对象,比如"spam"就是创建字符串类型的对象的表达式;
非核心类型需要内置函数来创建,比如文件类型需要调用内置函数open()来创建。
类也可以理解成自定义的非核心类型。
2、边界检查都不允许越界索引
3、索引方法都使用[]
s = 'spam'
print s[0]
s = ['s', 'p', 'a', 'm']
print s[0]
s = {'name':'bob', 'age':'12'}
print s['name']
s = ('s', 'p', 'a', 'm')
print s[0]
4大部分都支持迭代的协议
不同点:
1、有序性
字符串、列表、元组是序列,元组可以理解成不可变的列表
字典是映射
序列才有有序性,字典没有可靠的左右顺序
2、可变性
字符串、元组(还有数字)具有不可变性,即赋值后对应存储空间的内容不可变,除非这个对象被销毁。
列表、字典具有可变性
s = 'spam'
s = 'z' + s[1:]
第一行的s的指向的内存空间(比如地址0x000123)存储了字符串'spam'
第二行的s“变”成了'zpam',但它只是重新指向了一个存储着'zpam'字符串的内存地址,原来0x000123出开始的内存空间可能还是一个'spam',直到系统来清理它。
3、序列操作
序列(字符串、列表、元祖)支持,映射(字典)不支持
注意:序列操作生成的类型不变。
col = 'spam'
print col[1:]
#结果是pam
col = ['s', 'p', 'a', 'm']
print col[1:]
#结果是['p', 'a', 'm']
col = ('s', 'p', 'a', 'm')
print col[1:]
#结果是('p', 'a', 'm')
4、列表解析表达式
表达式中支持序列(字符串、列表、元祖),貌似也支持映射(字典)。
注意:和序列操作不同的是,
列表解析表达式生成的只能是一个列表;
double = [c * 2 for c in 'spam']
print double
结果为['ss', 'pp', 'aa', 'mm']
L1 = [1, 2, 3]
L2 = [4, 5, 6]
L3 = [(a + b) for (a,b) in zip(L1, L2)]
print L3
#结果为[5, 7, 9]
tup = (1, 2, 3)
double = [c * 2 for c in tup]
print double
#结果为[2, 4, 6]
a = {'a':'zw','b':'ww'}
b = [i * 2 for i in a.items()]
print b
#结果为[('a','zw','a','zw'),('b','ww','b','ww')]
下面一段代码似乎是列表解析表达式对字典的支持,对字典进行的迭
代应该是对其keys的迭代,字典的items()、keys()、values()方法都是返回的列表,所以,这里的for i in a最好写成for i in a.keys(),效果等同。
总之,可以不追究列表解析表达式到底支不支持字典,本质上,列表解析表达式就是个对列表使用了循环结构,并生成新的列表的方法。
先这样理解
a = {'a':'zw','b':'ww'}
b = [i * 2 for i in a]
print b
#结果为['aa', 'bb']
复制代码
5、嵌套
除了字符串,列表、元组、字典可以相互多层次嵌套
#第一段
b = [1, 2, 3]
tup = (4, 5, b)
print tup[2]
#结果是[1, 2, 3]
b[0] = 'x'
print tup[2]
#结果是['x', 2, 3]
#第二段
b = '123'
tup = (4, 5, b)
print tup[2]
#结果是'123'
b = 'xxx'
print tup[2]
#结果仍然是'123'
有上面两段可以看出,嵌套与可变性是不冲突的。
tup = (4, 5, b)中所记忆、录入的b是个变量指针,或者叫内存地址,是个数字。
第一段,b指向一个列表,列表具有可变性,所以b[0] = 'x'的操作后,所以对元祖的索引能体现出变化;
第二段,b指向一个字符串,字符串具有不可变性,所以b = 'xxx'的操作后,b这个指针本身就改变了,重指向另一段内存空间,而tup 元组中记忆的内存地址(那个曾经的b)所指空间并没有变,还是字符串'123'。
所以,不管是第一段还是第二段,元组tup始终保持不可变性,要变化也是其元素作为指针所指向内存的变化。
总结:python数据类型最重要的就是理解好可变性和不可变性,相信理解好了可以减少很多错误和少走一些弯路!
想要了解更多python教程,可以上
老王python: 。