全网最新尚学堂hadoop大数据视频教程
《Hadoop大数据技术》课程理论教学大纲

《Hadoop大数据技术》课程教学大纲一、课程基本情况课程代码:1041139083课程名称(中/英文):Hadoop大数据技术/Hadoop Big Data Technology课程类别:专业必修课学分:3.5总学时:56理论学时:32实验/实践学时:24适用专业:数据科学与大数据技术适用对象:本科先修课程:JA V A程序设计、Linux基础教学环境:课堂、多媒体、实验机房二、课程简介《Hadoop大数据技术》课程是数据科学与大数据技术专业的专业必修课程。
《Hadoop大数据技术》主要学习当前广泛使用的大数据Hadoop平台及其主要组件的作用及使用。
通过学习Hadoop 平台框架,学会手动搭建Hadoop环境,掌握Hadoop平台上存储及计算的原理、结构、工作流程,掌握基础的MapReduce编程,掌握Hadoop生态圈常用组件的作用、结构、配置和工作流程,并具备大数据的动手及问题分析能力,使用掌握的知识应用到实际的项目实践中。
课程由理论及实践两部分组成,课程理论部分的内容以介绍Hadoop平台主要组件的作用、结构、工作流程为主,对Hadoop 平台组件的作用及其工作原理有比较深入的了解;课程同时为各组件设计有若干实验,使学生在学习理论知识的同时,提高实践动手能力,做到在Hadoop的大数据平台上进行大数据项目开发。
三、课程教学目标2.课程教学目标及其与毕业要求指标点、主要教学内容的对应关系四、教学内容(一)初识Hadoop大数据技术1.主要内容:掌握大数据的基本概念、大数据简史、大数据的类型和特征、大数据对于企业带来的挑战。
了解对于大数据问题,传统方法、Google的解决方案、Hadoop框架下的解决方案,重点了解Google的三篇论文。
掌握Hadoop核心构成、Hadoop生态系统的主要组件、Hadoop发行版本的差异及如何选择;了解Hadoop典型应用场景;了解本课程内容涉及到的Java语言基础;了解本课程实验涉及到的Linux基础。
《Hadoop大数据处理实战》教学课件 第六章(Hadoop大数据处理实战)

此外,由于Map任务的输入数据要求是键值对的形式,所以需要对输入分 片进行格式化,即将输入分片处理成<key1,value1>形式的数据,然后再传递给 Map任务。
MapReduce的Shuffle过程
MapReduce的工作流程
1.Map端的Shuffle过程
(1)map()函数的输出并不会立即写入磁盘,MapReduce会为每个Map任务分配一个环形内存缓冲区(buffer in memory),用于存储map()函数的输出。
(2)在将环形内存缓冲区中的数据写入磁盘之前,需要对数据进行分区、排序和合并(可选)操作。 ① 分区操作的主要目的是将数据均匀地分配给Reduce任务,以实现MapReduce的负载均衡,从而避免单个
MapReduce具有良好的可扩展性,这意味着当集群计算资源不足时,可以通过动态增加节点的方式 实现弹性计算。
3 (3)高容错性。
如果集群中的某计算节点出现故障,使得作业执行失败,MapReduce可自动将作业分配到可用 的计算节点上重新执行。
MapReduce概述
MapReduce也存在以下局限性:
01
MapReduce概述
MapReduce概述
MapReduce是Hadoop系统中最重要的计算引擎,它不仅直 接支持交互式应用、基于程序的应用,还是Hive等组件的基础。
MapReduce概述 6.1.1 分布式并行计算
1.分布式计算
使用Hadoop进行大数据处理的基本流程

使用Hadoop进行大数据处理的基本流程使用Hadoop进行大数据处理的基本流程:一、准备工作1. 安装Hadoop:根据操作系统的不同,选择对应版本的Hadoop,并按照官方文档进行安装。
2. 配置Hadoop集群:配置主节点和从节点,设置主节点的IP地址和端口号,将从节点加入到集群中。
3. 配置Hadoop环境变量:将Hadoop的bin目录添加到系统的环境变量中,方便在任何位置使用Hadoop命令。
二、数据准备1. 数据上传:将待处理的大数据文件上传到Hadoop集群的分布式文件系统(HDFS)中,可以使用Hadoop提供的命令行工具或者Hadoop客户端进行上传。
2. 数据分割:如果大数据文件过大,可以考虑对数据进行分割,使每个数据块的大小适合Hadoop的处理能力。
三、MapReduce编程1. Map阶段:a. 编写Map函数:根据具体需求,编写Map函数来处理输入数据文件,并输出键值对(key-value)。
b. 配置Map任务:设置Map的输入格式、Map类、Map输出的键值对类型等。
2. Reduce阶段:a. 编写Reduce函数:根据具体需求,编写Reduce函数来对Map输出的键值对进行处理,并输出结果。
b. 配置Reduce任务:设置Reduce的输入格式、Reduce类、Reduce输出的键值对类型等。
四、作业提交和执行1. 配置作业:a. 创建作业:使用Hadoop提供的工具或API,创建一个新的作业。
b. 设置输入和输出路径:指定作业的输入数据路径和输出数据路径。
2. 提交作业:将作业提交到Hadoop集群中进行执行。
3. 监控作业:通过Hadoop提供的命令行工具或者Web界面来监控作业的运行状态和进度。
五、结果获取1. 下载结果:当作业运行完成后,可以通过Hadoop的命令行工具或者Hadoop 客户端从HDFS中下载结果文件。
2. 结果整理:针对输出结果,可以进行进一步的处理和分析,以满足具体的需求。
《Hadoop大数据技术》课程实验教学大纲
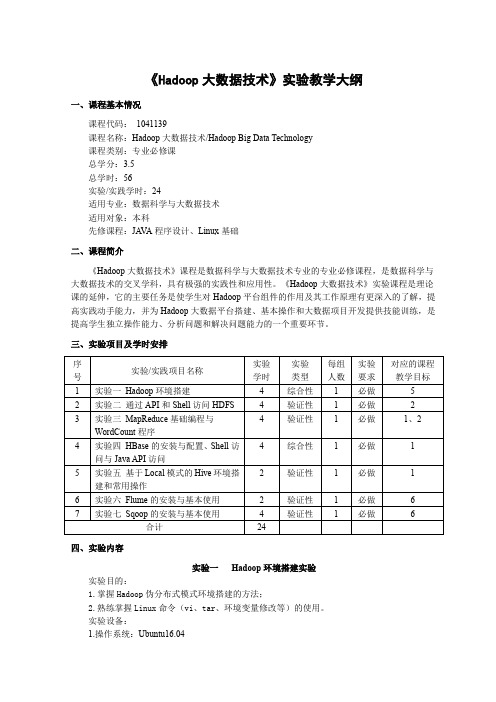
《Hadoop大数据技术》实验教学大纲一、课程基本情况课程代码:1041139课程名称:Hadoop大数据技术/Hadoop Big Data Technology课程类别:专业必修课总学分:3.5总学时:56实验/实践学时:24适用专业:数据科学与大数据技术适用对象:本科先修课程:JA V A程序设计、Linux基础二、课程简介《Hadoop大数据技术》课程是数据科学与大数据技术专业的专业必修课程,是数据科学与大数据技术的交叉学科,具有极强的实践性和应用性。
《Hadoop大数据技术》实验课程是理论课的延伸,它的主要任务是使学生对Hadoop平台组件的作用及其工作原理有更深入的了解,提高实践动手能力,并为Hadoop大数据平台搭建、基本操作和大数据项目开发提供技能训练,是提高学生独立操作能力、分析问题和解决问题能力的一个重要环节。
三、实验项目及学时安排四、实验内容实验一Hadoop环境搭建实验实验目的:1.掌握Hadoop伪分布式模式环境搭建的方法;2.熟练掌握Linux命令(vi、tar、环境变量修改等)的使用。
实验设备:1.操作系统:Ubuntu16.042.Hadoop版本:2.7.3或以上版本实验主要内容及步骤:1.实验内容在Ubuntu系统下进行Hadoop伪分布式模式环境搭建。
2.实验步骤(1)根据内容要求完成Hadoop伪分布式模式环境搭建的逻辑设计。
(2)根据设计要求,完成实验准备工作:关闭防火墙、安装JDK、配置SSH免密登录、Hadoop 安装包获取与解压。
(3)根据实验要求,修改Hadoop配置文件,格式化NAMENODE。
(4)启动/停止Hadoop,完成实验测试,验证设计的合理性。
(5)撰写实验报告,整理实验数据,记录完备的实验过程和实验结果。
实验二(1)Shell命令访问HDFS实验实验目的:1.理解HDFS在Hadoop体系结构中的角色;2.熟练使用常用的Shell命令访问HDFS。
《Hadoop大数据技术与应用》教学大纲

《Hadoop大数据技术与应用》课程教学大纲
【课程名称】HadoOP大数据技术与应用
【课程类型】专业必修课
【授课对象】大数据技术与应用、云计算技术与应用专业、人工智能技术专业高职,二年级学生【学时学分】周学时4,64学时,6学分
【课程概况】
《Hadoop大数据技术与应用》课程是大数据技术与应用、云计算技术与应用专业必修课,是计算机基础理论与应用实践相结合的课程,也是大数据专业的高核心课程,它担负着系统、全面地理解大数据,提高大数据应用技能的重任。
本课程的先修课为《大数据技术概论》、《编程基础》、《1inux操作系统》、《数据库设计与实现》等课程,要求学生掌握HadOOP生态系统的框架组件,操作方法。
[课程目标]
通过本课程的学习,让学生接触并了解HadOOP生态系统各组件的原理和使用方法,使学生具有Had。
P相关技术,具备大数据开发的基本技能,并具有较强的分析问题和解决问题的能力,为将来从事大数据相关领域的工作打下坚实的基础。
【课程内容及学时分布】
【使用教材及教学参考书】
使用教材:《Hadoop生态系统及开发》,邓永生、刘铭皓等主编,西安电子
科技大学出版社,2023年
大纲执笔人:
大纲审定人:
年月日。
《Hadoop大数据开发实战》教学教案(全)

《Hadoop大数据开发实战》教学教案(第一部分)一、教学目标1. 理解Hadoop的基本概念和架构2. 掌握Hadoop的安装和配置3. 掌握Hadoop的核心组件及其作用4. 能够搭建简单的Hadoop集群并进行基本的操作二、教学内容1. Hadoop简介1.1 Hadoop的定义1.2 Hadoop的发展历程1.3 Hadoop的应用场景2. Hadoop架构2.1 Hadoop的组成部分2.2 Hadoop的分布式文件系统HDFS2.3 Hadoop的计算框架MapReduce3. Hadoop的安装和配置3.1 Hadoop的版本选择3.2 Hadoop的安装步骤3.3 Hadoop的配置文件解读4. Hadoop的核心组件4.1 NameNode和DataNode4.2 JobTracker和TaskTracker4.3 HDFS和MapReduce的运行原理三、教学方法1. 讲授法:讲解Hadoop的基本概念、架构和组件2. 实践法:引导学生动手实践,安装和配置Hadoop,了解其运行原理3. 讨论法:鼓励学生提问、发表观点,共同探讨Hadoop的应用场景和优缺点四、教学准备1. 教师准备:熟悉Hadoop的安装和配置,了解其运行原理2. 学生准备:具备一定的Linux操作基础,了解Java编程五、教学评价1. 课堂参与度:学生提问、回答问题的积极性2. 实践操作:学生动手实践的能力,如能够独立完成Hadoop的安装和配置3. 课后作业:学生完成课后练习的情况,如编写简单的MapReduce程序4. 综合评价:结合学生的课堂表现、实践操作和课后作业,综合评价学生的学习效果《Hadoop大数据开发实战》教学教案(第二部分)六、教学目标1. 掌握Hadoop生态系统中的常用组件2. 理解Hadoop数据存储和处理的高级特性3. 学会使用Hadoop进行大数据处理和分析4. 能够运用Hadoop解决实际的大数据问题七、教学内容1. Hadoop生态系统组件7.1 YARN的概念和架构7.2 HBase的概念和架构7.3 Hive的概念和架构7.4 Sqoop的概念和架构7.5 Flink的概念和架构(可选)2. Hadoop高级特性8.1 HDFS的高可用性8.2 HDFS的存储策略8.3 MapReduce的高级特性8.4 YARN的资源管理3. 大数据处理和分析9.1 Hadoop在数据处理中的应用案例9.2 Hadoop在数据分析中的应用案例9.3 Hadoop在机器学习中的应用案例4. Hadoop解决实际问题10.1 Hadoop在日志分析中的应用10.2 Hadoop在网络爬虫中的应用10.3 Hadoop在图像处理中的应用八、教学方法1. 讲授法:讲解Hadoop生态系统组件的原理和应用2. 实践法:引导学生动手实践,使用Hadoop进行数据处理和分析3. 案例教学法:分析实际应用案例,让学生了解Hadoop在不同领域的应用九、教学准备1. 教师准备:熟悉Hadoop生态系统组件的原理和应用,具备实际操作经验2. 学生准备:掌握Hadoop的基本操作,了解Hadoop的核心组件十、教学评价1. 课堂参与度:学生提问、回答问题的积极性2. 实践操作:学生动手实践的能力,如能够独立完成数据处理和分析任务3. 案例分析:学生分析实际应用案例的能力,如能够理解Hadoop在不同领域的应用4. 课后作业:学生完成课后练习的情况,如编写复杂的MapReduce程序或使用Hadoop生态系统组件进行数据处理5. 综合评价:结合学生的课堂表现、实践操作、案例分析和课后作业,综合评价学生的学习效果重点和难点解析一、Hadoop的基本概念和架构二、Hadoop的安装和配置三、Hadoop的核心组件四、Hadoop生态系统组件五、Hadoop数据存储和处理的高级特性六、大数据处理和分析七、Hadoop解决实际问题本教案涵盖了Hadoop的基本概念、安装配置、核心组件、生态系统组件、数据存储和处理的高级特性,以及大数据处理和分析的实际应用。
最全大数据Hadoop基础教程下载

最全大数据Hadoop基础教程下载
在这个大数据时代,网络充斥了我们生活的每一个角落,所以我们更应该紧跟时代的步伐,了解大数据,了解Hadoop是什么?有哪些基础课程?下面由千锋教育为您带来详细地讲解:
Hadoop是什么?
Hadoop是一个由Apache基金会所开发的分布式系统基础架构。
用户可以在不了解分布式底层细节的情况下,开发分布式程序。
充分利用集群的威力进行高速运算和存储。
Hadoop实现了一个分布式文件系统(Hadoop Distributed File System),简称HDFS。
HDFS有高容错性的特点,并且设计用来部署在低廉的硬件上;而且它提供高吞吐量来访问应用程序的数据,适合那些有着超大数据集的应用程序。
HDFS放宽了POSIX的要求,可以以流的形式访问文件系统中的数据。
而Hadoop的框架最核心的设计就是:HDFS和MapReduce。
HDFS为海量的数据提供了存储,则MapReduce为海量的数据提供了计算。
千锋教育的Hadoop基础课程有哪些?
(1)Hadoop起源与安装
(2)MapReduce快速入门
(3)Hadoop分布式文件系统
(4)Hadoop文件I/O详解
(5)MapReduce工作原理
(6)MapReduce编程开发
(7)Hive数据仓库工具
(8)开源数据库HBase
(9)Sqoop与Oozie
千锋教育为您准备的课程福利大餐,做好准备迎接了吗?这里有精心编制的课程,有引领时代的精英教师,坐等为每一位学员量身定做,欢迎来访!。
Hadoop平台搭建与应用(第2版)(微课版)项目1 认识大数据

Hadoop平台搭建与应用教案靠、高性能、分布式和面向列的动态模式数据库。
⑤ ZooKeeper(分布式协作服务):其用于解决分布式环境下的数据管理问题,主要是统一命名、同步状态、管理集群、同步配置等。
⑥ Sqoop(数据同步工具):Sqoop是SQL-to-Hadoop的缩写,主要用于在传统数据库和Hadoop之间传输数据。
⑦ Pig(基于Hadoop的数据流系统):Pig的设计动机是提供一种基于MapReduce 的Ad-Hoc(计算在query时发生)数据分析工具。
⑧ Flume(日志收集工具):Flume是Cloudera开源的日志收集系统,具有分布式、高可靠、高容错、易于定制和扩展的特点。
⑨ Oozie(作业流调度系统):Oozie是一个基于工作流引擎的服务器,可以运行Hadoop的MapReduce和Pig任务。
⑩ Spark(大数据处理通用引擎):Spark提供了分布式的内存抽象,其最大的特点就是快,是Hadoop MapReduce处理速度的100倍。
YARN(另一种资源协调者):YARN是一种新的Hadoop资源管理器,它是一个通用资源管理系统,可为上层应用提供统一的资源管理和调度,它的引入为集群在利用率、资源统一管理和数据共享等方面带来了巨大好处。
Kafka(高吞吐量的分布式发布订阅消息系统):Kafka可以处理消费者规模的网站中的所有动作流数据。
任务1.1 认知大数据,完成系统环境搭建(1)安装CentOS系统(确保CentOS系统版本在7及以上,以便配合后续Docker 安装)。
①在VMware中设置CentOS 7镜像,进入后选择第一项安装CentOS 7,如图1-8所示。
②在新打开页面中设置时间(DATE&TIME),分配磁盘(INSTALLATION DESTINATION)和网络设置(NETWORK&HOST NAME)等,如图1-9所示。
③单击“INSTALLATION DESTINATION”链接,在打开的界面中选择“I will configure partitioning”选项,然后单击“Done”按钮,跳转到分配磁盘页面即可进行磁盘分配,如图1-10所示。
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
Hadoop是一个能够对大量数据进行分布式处理的软件框架。
Hadoop 以一种可靠、高效、可伸缩的方式进行数据处理。
Hadoop 是可靠的,因为它假设计算元素和存储会失败,因此它维护多个工作数据副本,确保能够针对失败的节点重新分布处理。
Hadoop 是高效的,因为它以并行的方式工作,通过并行处理加快处理速度。
Hadoop 还是可伸缩的,能够处理 PB 级数据。
此外,Hadoop 依赖于社区服务,因此它的成本比较低,任何人都可以使用。
Hadoop是一个能够让用户轻松架构和使用的分布式计算平台。
用户可以轻松地在Hadoop上开发和运行处理海量数据的应用程序。
它主要有以下几个优点:
1、高可靠性。
Hadoop按位存储和处理数据的能力值得人们信赖。
2、高扩展性。
Hadoop是在可用的计算机集簇间分配数据并完成计算任务的,这些集簇可以方
便地扩展到数以千计的节点中。
3、高效性。
Hadoop能够在节点之间动态地移动数据,并保证各个节点的动态平衡,因此处理
速度非常快。
4、高容错性。
Hadoop能够自动保存数据的多个副本,并且能够自动将失败的任务重新分配。
5、低成本。
与一体机、商用数据仓库以及QlikView、Yonghong Z-Suite等数据集市相比,
hadoop是开源的,项目的软件成本因此会大大降低。
6、Hadoop带有用Java语言编写的框架,因此运行在 Linux 生产平台上是非常理想的。
7、Hadoop 上的应用程序也可以使用其他语言编写,比如 C++。
hadoop大数据处理的意义
Hadoop得以在大数据处理应用中广泛应用得益于其自身在数据提取、变形和加载(ETL)方面上的天然优势。
Hadoop的分布式架构,将大数据处理引擎尽可能的靠近存储,对例如像ETL这样的批处理操作相对合适,因为类似这样操作的批处理结果可以直接走向存储。
Hadoop的MapReduce功能实现了将单个任务打碎,并将碎片任务(Map)发送到多个节点上,之后再以单个数据集的形式加载(Reduce)到数据仓库里。
课程目录:
01_尚学堂_肖斌_hadoop_hdfs1分布式文件系统01 02_尚学堂_肖斌_hadoop_hdfs1分布式文件系统02 03_尚学堂_肖斌_hadoop_hdfs1分布式文件系统03 04_尚学堂_肖斌_hadoop_hdfs1分布式文件系统04 05_尚学堂_肖斌_hadoop_hdfs1分布式文件系统05 06_尚学堂_肖斌_hadoop_hdfs1分布式文件系统06 07_尚学堂_肖斌_hadoop_hdfs1分布式文件系统07 08_尚学堂_肖斌_hadoop_hdfs1分布式文件系统08_io 09_尚学堂_肖斌_hadoop_hdfs1分布式文件系统09_io 10_尚学堂_肖斌_hadoop_hdfs1分布式文件系统10 11_尚学堂_肖斌_hadoop_hdfs1分布式文件系统11 12_尚学堂_肖斌_hadoop_hdfs1分布式文件系统12 13_尚学堂_肖斌_hadoop_hdfs1分布式文件系统13
14_尚学堂_肖斌_mr分布式计算框架_理论1 15_尚学堂_肖斌_mr分布式计算框架_理论2 16_尚学堂_肖斌_mr分布式计算框架_理论3 17_尚学堂_肖斌_mr分布式计算框架_理论4 18_尚学堂_肖斌_mr分布式计算框架_理论5 19_尚学堂_肖斌_mr分布式计算框架_理论6 20_尚学堂_肖斌_mr分布式计算框架_install01 21_尚学堂_肖斌_mr分布式计算框架_install02 22_尚学堂_肖斌_mr分布式计算框架_wc01
23_尚学堂_肖斌_mr分布式计算框架_wc02
24_尚学堂_肖斌_mr分布式计算框架_wc03
25_尚学堂_肖斌_mr分布式计算框架_wc04
26_尚学堂_肖斌_mr_qq推荐好友01
27_尚学堂_肖斌_mr_qq推荐好友02
28_尚学堂_肖斌_mr_精准广告推送01
29_尚学堂_肖斌_mr_精准广告推送02
30_尚学堂_肖斌_mr_精准广告推送03
31_尚学堂_肖斌_mr_精准广告推送04
32_尚学堂_肖斌_hadoop2.x_介绍01
33_尚学堂_肖斌_hadoop2.x_介绍02
34_尚学堂_肖斌_hadoop2.x_ha介绍01
35_尚学堂_肖斌_hadoop2.x_ha介绍02
36_尚学堂_肖斌_hadoop2.x_ha介绍03
37_尚学堂_肖斌_hadoop2.x_ha介绍04
38_尚学堂_肖斌_hadoop_hadoop2.5.2的安装部署01
39_尚学堂_肖斌_hadoop_hadoop2.5.2的安装部署02
40_尚学堂_肖斌_hadoop_hadoop2.5.2的安装部署03
41_尚学堂_肖斌_hadoop_hadoop2.5.2的安装部署04
42_尚学堂_肖斌_hadoop_hadoop2.5.2的安装部署05
43_尚学堂_肖斌_hadoop_hadoop2.5.2的安装部署06
44_尚学堂_肖斌_hadoop2.x_温度排序,分区,分组,自定义封装类01 45_尚学堂_肖斌_hadoop2.x_温度排序,分区,分组,自定义封装类02 46_尚学堂_肖斌_hadoop2.x_温度排序,分区,分组,自定义封装类03 47_尚学堂_肖斌_hadoop2.x_温度排序,分区,分组,自定义封装类04 48_尚学堂_肖斌_hadoop2.x_温度排序,分区,分组,自定义封装类05 49_尚学堂_肖斌_hadoop2.x_温度排序,分区,分组,自定义封装类06 50_尚学堂_肖斌_hadoop2.x_广告推送用户轨迹01
51_尚学堂_肖斌_hadoop2.x_广告推送用户轨迹02
52_尚学堂_肖斌_hadoop2.x_广告推送用户轨迹03
53_尚学堂_肖斌_hadoop2.x_广告推送用户轨迹04
54_尚学堂_肖斌_hadoop2.x_广告推送用户轨迹05
55_尚学堂_肖斌_hadoop2.x_广告推送用户轨迹06
56_尚学堂_肖斌_hive_介绍和安装01
57_尚学堂_肖斌_hive_介绍和安装02
58_尚学堂_肖斌_hive_介绍和安装03
59_尚学堂_肖斌_hive_介绍和安装04
60_尚学堂_肖斌_hive_ddl数据定义语言01
61_尚学堂_肖斌_hive_ddl数据定义语言02
62_尚学堂_肖斌_hive_ddl数据定义语言03
63_尚学堂_肖斌_hive_ddl数据定义语言04
64_尚学堂_肖斌_hive_dml数据操作语言_select01 65_尚学堂_肖斌_hive_dml数据操作语言_select02 66_尚学堂_肖斌_hive_dml数据操作语言_select03 67_尚学堂_肖斌_hive_dml数据操作语言_select04 68_尚学堂_肖斌_hive_server2服务器01
69_尚学堂_肖斌_hive_server2服务器02
70_尚学堂_肖斌_hive_server2服务器03
71_尚学堂_肖斌_hive_server2服务器04
72_尚学堂_肖斌_hadoop_轨迹分析01
73_尚学堂_肖斌_hadoop_轨迹分析02
74_尚学堂_肖斌_hadoop_轨迹分析03
75_尚学堂_肖斌_hadoop_轨迹分析04
76尚学堂_肖斌_mr分布式计算框架_理论01
77尚学堂_肖斌_mr分布式计算框架_理论02
【最新hadoop学习资源请到尚学堂】【专业JA V A培训机构,真正零首付入学】。