相关分析步骤
最快五步用SPSS软件进行相关性分析

采用SPSS进行相关性分析的具体步骤
-
涉及到相关性分析,一般情况下就会用到 SPSS软件,那么怎样采用SPSS软件进行相 关性分析呢?下面我来具体说明一下相关 的步骤: 这一共分为五步
-
பைடு நூலகம்
第一步:打开SPSS软件,在数据视图中输入变量的数值。 比如我想探究饱和吸附量与阳离子交换量和阴离子交换量 的关系,就将数据粘贴上去。
-
第五步:下图呈现的就是相关性的结果,“双变量”就是 两个变量之间的相关性如何,数值是负值就是没有相关性, 正值就相关,然后自己截图或者做一个结果统计表就行。
-
-
第二步:数据视图只能输入数据,要想更改变量的名称就 得在变量视图中就行名称更改。所以在变量视图中输入变 量的名称。
-
第三步:更改后名称后,接下来就到了关键的部分,点击最上方菜 单栏中的“分析”这一栏,在“分析”中的“相关”栏中找到 “双变量”这一栏就行点击。 第四步:在出来的双变量相关中把框内所有的变量点击向右的按钮 过去另一个框,其余的按钮都不要变,再点击确定按钮就行。
如何进行相关性分析

如何进行相关性分析相关性分析是统计学中常用的分析方法之一,用于衡量两个或多个变量之间的关联程度。
通过相关性分析可以得出变量之间的相关性强弱及正负关系,为后续的数据分析和模型建立提供支持。
以下是进行相关性分析的步骤和注意事项。
1.确定变量类型在进行相关性分析之前,需要先明确变量的类型。
常见的变量类型包括定量变量(如身高、体重、销售额等)和分类变量(如性别、地区、婚姻状况等)。
不同类型的变量使用不同的相关系数进行分析。
2.寻找数据3.数据清洗与变换对收集到的数据进行清洗和变换处理,以确保数据的准确性和一致性。
包括去除缺失值、异常值、重复值以及数据格式化处理等。
此外,如有需要可以进行数据标准化或变量转换,以便进行更准确的相关性分析。
4.选择合适的相关系数根据变量的类型,选择合适的相关系数进行分析。
常见的相关系数包括Pearson相关系数、Spearman等级相关系数和判定系数等。
Pearson相关系数适用于定量变量之间的线性关系,Spearman相关系数适用于定序变量或非线性关系。
通过计算相关系数可以得到相关性分析的结果。
5.相关性检验对于得到的相关系数,需要进行相关性检验来判断其统计显著性。
常见的检验方法包括t检验和卡方检验等。
显著性水平的选择一般为0.05,即p值小于0.05认为相关系数具有统计显著性。
6.解读相关性结果根据计算得到的相关系数和显著性水平,进行结果的解读。
相关系数的取值范围在-1到1之间,接近1表示正相关性强,接近-1表示负相关性强,接近0表示无相关性。
同时,要注意相关性不代表因果关系,只能表明两个变量之间的联合变化程度。
7.注意事项在进行相关性分析时,需要注意以下几点:-数据的选择和准备要充分,确保数据的可信度和准确性。
-数据的类型和变换要符合相关系数的要求,确保相关性分析结果的可靠性。
-相关性只能表明两个变量之间的联合变化程度,并不能说明因果关系。
-相关系数是基于样本数据计算得到的,需要注意结果的一般性和推广性。
第七讲 相关分析与回归分析
DW检验。(零假设:总体的自相关系数ρ与0无显著差异。)
当随机扰动项存在序列相关时,进行Durbin-Watson检验:
2 ( e e ) i i 1 i 2 2 e i i 2 n n
DW
0<DW<dL:随机扰动项存在一阶正序列相关; 4-dL<DW<4:随机扰动项存在一阶负序列相关;
调整的可决系数: R 2 1 SSE /(n k 1) (多元线性回归方 SST /(n 1) 程) ① 解释变量增多时,SSE减少,R2增加;
② 有重要“贡献”的解释变量出现。
2)回归方程整体显著性检验
包含回归方程的显著性检验和回归系数的显著性检验两个部 分。 回归方程的显著性检验:检验线性关系是否显著
,
服从自由度为n-2的t分布。
定序变量的相关分析-Spearman
ui和vi分别表示变量 x和 y的秩变量,用di=ui-vi表示第i个样 n 本对应于两变量的秩之差。 2 Spearman秩相关公式:
rs 1 6 d i
i 1 2
n( n 1)
两变量正相关,秩变化有同步性,r趋向于1;
一般步骤: 1. 确定回归方程中的解释变量和被解释变量 2. 确定回归模型 3. 建立回归方程 4. 对回归方程进行各种检验 5. 利用回归方程进行预测
线性回归
数学模型: yi 0 1 xi1 2 xi 2 k xik i 使用最小二乘法对模型中的回归系数进行估计,得到样本 ^ ^ ^ ^ 回归函数:yi 0 1 xi1 2 xi 2 k xik ei
SPSS相关分析实例操作步骤-SPSS做相关分析

SPSS相关分析实例操作步骤-SPSS做相关分析SPSS(Statistical Product and Service Solutions)是目前在工业、商业、学术研究等领域中广泛应用的统计学软件包之一。
Correlation是SPSS的一个功能模块,可以用于分析两个或多个变量之间的关系。
下面是SPSS进行相关分析的具体步骤:1. 打开SPSS软件,选择“变量视图”(Variable View),输入相关的变量名,包括数字型变量和分类变量。
2. 进入“数据视图”(Data View),输入数据,并保存数据集。
3. 打开菜单栏中的“分析”(Analyze),选择“相关”(Correlate),再选择“双变量”(Bivariate)。
4. 在双变量窗口中,选择包含需要分析的变量的变量名,并将其移至右侧窗口中的变量框(Variables)。
5. 如果需要控制其他变量的影响,可以选择“控制变量”(Options)。
6. 点击“确定”(OK)按钮后,SPSS将输出结果,并将其显示在输出窗口中。
相关系数(Correlation Coefficient)介于-1和1之间,可以用来衡量两个变量之间的线性关系的强度。
7. 如果需要对结果进行图形化展示,可以选择“图”(Plots),并选择适当的图形类型。
需要注意的是,进行相关分析时需要确保变量之间存在线性关系。
如果变量之间存在非线性关系,建议使用其他统计方法进行分析。
同时,SPSS进行相关分析的结果只能描述变量之间的关系,不能用于说明因果关系。
以上是SPSS做相关分析的具体步骤,希望能对大家进行SPSS 数据分析有所帮助。
SPSS相关性分析 Pearson相关与偏相关分析的实现 步骤
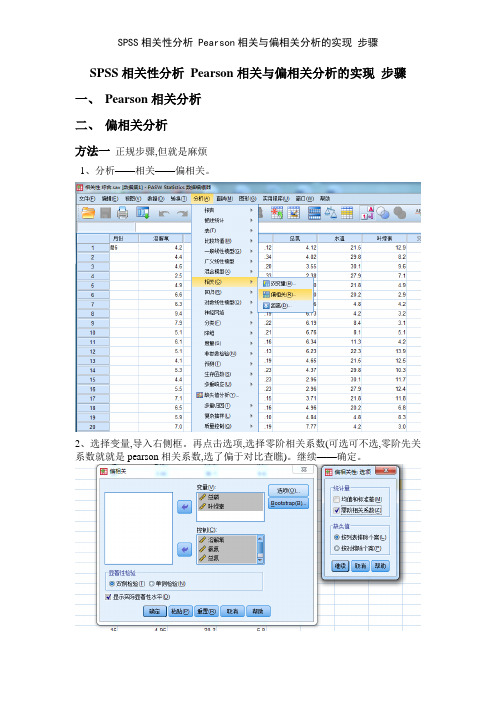
SPSS相关性分析Pearson相关与偏相关分析的实现步骤
一、Pearson相关分析
二、偏相关分析
方法一正规步骤,但就是麻烦
1、分析——相关——偏相关。
2、选择变量,导入右侧框。
再点击选项,选择零阶相关系数(可选可不选,零阶先关系数就就是pearson相关系数,选了偏于对比查瞧)。
继续——确定。
3、结果分析:总磷Pearson相关不显著,但偏相关显著。
Pearson相关系数,显著性P值为0、416>0、05,相关性不显著。
偏相关,显著性P值为0、001<o、o1,极显著相关。
(显著性瞧sig、P值,
P<0、05,“*”显著;
P<0、01,“**”极显著)
方法二:简便方法,快捷迅速,不用挨个分析偏相关,可以一下子出来。
1、分析——回归——线性。
2、“溶解氧、氨氮、总磷、总氮、水温”与“叶绿素”的偏相关分析。
如图,先选择变量,再选择“统计量”。
“统计量”一定要选择“部分相关与偏相关性”。
其她的可以不选。
继续—确定。
3、结果分析,分别瞧Sig、显著性,与偏相关系数。
以总磷为例,与之前单独做“偏相关”分析结果就是一样的。
其她变量与叶绿素的偏相关关系也可以在上表瞧出来。
简单相关分析的步骤

简单相关分析的步骤
简单相关分析是一种基本的统计分析方法,用于探究数据变量之间的关系。
它可以帮助我们理解自变量(也可以称为解释变量)与因变量(也可以称为被解释变量)之间的统计关系。
下面介绍的是简单相关分析的步骤:
第一步:选择数据。
在执行简单相关分析之前,你将需要选择来自同一数据集中的相关数据。
这些数据可以是分类变量(例如性别、国家/地区类型),也可以是因变量(例如年龄、收入)。
但前提是这些变量的值范围是全体可能值的子集,比如年龄是0-100之间的整数。
第二步:确定变量。
在选择数据之后,你需要建立一组被解释变量和一组解释变量,以及可以用来检验它们之间有没有关系的统计量(比如拟合度)。
第三步:计算统计量。
这一步将根据你选择的变量计算出包括平均值、方差、协方差和相关系数在内的一系列统计量。
第四步:解释数据。
计算统计量后,你可以根据统计量的值来解释结果,看看自变量与因变量之间有哪些关系。
如果解释变量的平均值高于因变量的平均值,或相关系数高于0,则可以得出结论,解释变量与因变量存在相关性;反之,如果解释变量的平均值低于因变量的平均值,或相关系数低于0,则意味着解释变量与因变量之间不存在相关性。
简单相关分析是一种统计技术,可以帮助我们了解连续变量和分类变量之间的关系,从而做出合理的数据分析结果。
为了分析解释变量与因变量之间的关系,我们必须按照前面介绍的步骤来进行,这样才能得到有价值的结果。
通过使用简单相关分析,可以更好地理解数据变量之间的关系,进而作出更明智的决策,帮助我们有效地控制与提高业绩。
相关分析和回归分析SPSS实现
相关分析和回归分析SPSS实现SPSS(统计包统计分析软件)是一种广泛使用的数据分析工具,在相关分析和回归分析方面具有强大的功能。
本文将介绍如何使用SPSS进行相关分析和回归分析。
相关分析(Correlation Analysis)用于探索两个或多个变量之间的关系。
在SPSS中,可以通过如下步骤进行相关分析:1.打开SPSS软件并导入数据集。
2.选择“分析”菜单,然后选择“相关”子菜单。
3.在“相关”对话框中,选择将要分析的变量,然后单击“箭头”将其添加到“变量”框中。
4.选择相关系数的计算方法(如皮尔逊相关系数、斯皮尔曼等级相关系数)。
5.单击“确定”按钮,SPSS将计算相关系数并将结果显示在输出窗口中。
回归分析(Regression Analysis)用于建立一个预测模型,来预测因变量在自变量影响下的变化。
在SPSS中,可以通过如下步骤进行回归分析:1.打开SPSS软件并导入数据集。
2.选择“分析”菜单,然后选择“回归”子菜单。
3.在“回归”对话框中,选择要分析的因变量和自变量,然后单击“箭头”将其添加到“因变量”和“自变量”框中。
4.选择回归模型的方法(如线性回归、多项式回归等)。
5.单击“统计”按钮,选择要计算的统计量(如参数估计、拟合优度等)。
6.单击“确定”按钮,SPSS将计算回归模型并将结果显示在输出窗口中。
在分析结果中,相关分析会显示相关系数的数值和统计显著性水平,以评估变量之间的关系强度和统计显著性。
回归分析会显示回归系数的数值和显著性水平,以评估自变量对因变量的影响。
值得注意的是,相关分析和回归分析在使用前需要考虑数据的要求和前提条件。
例如,相关分析要求变量间的关系是线性的,回归分析要求自变量与因变量之间存在一定的关联关系。
总结起来,SPSS提供了强大的功能和工具,便于进行相关分析和回归分析。
通过上述步骤,用户可以轻松地完成数据分析和结果呈现。
然而,分析结果的解释和应用需要结合具体的研究背景和目的进行综合考虑。
相关矩阵求典型相关
相关矩阵求典型相关
典型相关分析是一种用来研究两组变量之间的相关性的方法。
它基于矩阵的特征值和特征向量来计算典型相关系数。
以下是求解典型相关分析的步骤:
1. 收集数据:首先,需要收集两组变量的数据。
假设我们有两组变量X和Y,每组变量有n个样本,每个样本有m个观测值。
2. 构建协方差矩阵:对于变量X和Y,分别计算它们的协方差矩阵Cx和Cy。
协方差矩阵描述了变量之间的线性关系。
3. 计算广义特征值问题:将协方差矩阵Cx和Cy合并为一个大的矩阵,形成一个广义特征值问题。
解这个特征值问题可以得到一组特征值和对应的特征向量。
4. 选择主要特征值:根据特征值的大小,选择最大的k个特征值,其中k是希望保留的典型相关变量的数量。
5. 计算典型相关系数:根据选定的k个特征向量,计算典型相关系数,它衡量了X和Y之间的典型相关性。
典型相关分析可以用于多组变量之间的相关性分析,例如用于计算两个不同的指标集合之间的相关性。
通过分析典型相关系数,可以理解两组变量之间的关系,从而更好地理解数据中的模式和结构。
如何进行相关性分析
如何进行相关性分析相关性分析是一种统计分析方法,用于评估两个或多个变量之间的关联程度。
它可以帮助我们了解变量之间的关系,揭示出可能存在的因果关系或共同变化趋势。
在各个领域,相关性分析被广泛应用于数据分析、市场研究、经济学、社会科学等方面。
本文将介绍如何进行相关性分析,以便读者在实践中能够准确评估变量之间的关系。
一、相关性分析的基本概念在开始相关性分析之前,我们需要了解一些基本概念。
1. 变量:相关性分析涉及的对象称为变量,可以是数值型变量或分类变量。
数值型变量是指可量化的数据,如年龄、收入等;分类变量是指具有不同类别的数据,如性别、职业等。
2. 相关系数:相关性分析的结果通常用相关系数来表示。
相关系数可以衡量两个变量之间的关联程度,其值介于-1和1之间。
如果相关系数接近1,则表示两个变量正相关;如果相关系数接近-1,则表示两个变量负相关;如果相关系数接近0,则表示两个变量之间没有线性关系。
3. 样本容量:在进行相关性分析时,需要考虑样本容量。
样本容量越大,相关性分析的结果越可靠。
通常情况下,样本容量应当大于30。
二、相关性分析的步骤下面将介绍进行相关性分析的具体步骤。
1. 收集数据:首先,我们需要收集所需的数据。
数据可以从各种来源获取,如调查问卷、实验观测或公开的数据集。
2. 数据清洗:在进行相关性分析之前,需要对数据进行清洗处理。
这包括剔除缺失数据、异常值或不符合正态分布的数据。
3. 绘制散点图:绘制散点图是进行相关性分析的首要步骤。
通过绘制两个变量之间的散点图,可以直观地观察它们之间的关系。
4. 计算相关系数:根据散点图的结果,我们可以计算相关系数以衡量两个变量之间的关联程度。
常用的相关系数包括皮尔逊相关系数、斯皮尔曼等级相关系数和判定系数等。
5. 判断相关性:根据计算所得的相关系数,我们可以判断两个变量之间的相关性。
一般来说,相关系数越接近1或-1,表示两个变量之间的关联程度越高;相关系数越接近0,表示两个变量之间的关联程度越低。
如何进行有效的相关性分析
如何进行有效的相关性分析相关性分析是一种常用的统计方法,用于探索变量之间的关系。
它帮助我们理解不同变量之间的相关程度,以及它们之间的因果关系。
在本文中,我们将介绍如何进行有效的相关性分析,以及一些常见的工具和技术。
一、相关性分析的基本概念在开始进行相关性分析之前,我们首先需要了解一些基本概念。
1. 相关系数:相关系数是衡量两个变量之间关系强度的统计量。
常见的相关系数有皮尔逊相关系数、斯皮尔曼相关系数和切比雪夫距离等。
选择适当的相关系数取决于变量类型和数据特点。
2. 正相关与负相关:当两个变量的值朝相同方向变化时,它们之间存在正相关关系;当两个变量的值朝相反方向变化时,它们之间存在负相关关系。
3. 相关矩阵:相关矩阵是一个矩阵,用于展示多个变量之间的相关性。
矩阵中的每个元素代表两个变量之间的相关系数。
二、相关性分析的步骤进行有效的相关性分析,需要按照以下步骤进行:1. 收集数据:首先,需要收集相关的数据。
确保数据质量好,准确性高,并且涵盖了所有要分析的变量。
2. 数据预处理:在进行相关性分析之前,需要对数据进行预处理。
这包括数据清洗、缺失值处理、异常值处理等。
通过预处理,确保数据的准确性和完整性。
3. 确定相关系数:根据变量类型和数据特点,选择合适的相关系数。
常用的皮尔逊相关系数适用于连续变量之间的线性关系;斯皮尔曼相关系数适用于有序变量或非线性关系;切比雪夫距离适用于分类变量之间的关系。
4. 计算相关系数:使用选定的相关系数公式,计算各个变量之间的相关系数。
可以使用统计软件或编程语言来实现计算。
5. 相关性可视化:相关性可视化有助于更好地理解变量之间的关系。
常用的可视化方法包括散点图、热力图和线性回归图。
选择适当的可视化方法,将相关系数结果呈现出来。
6. 分析结果解读:根据相关系数的数值和可视化结果,进行结果解读。
判断变量之间的相关性强度、方向以及是否存在显著性差异。
注意结果解读时需谨慎,应结合具体情境和领域知识进行分析。
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
相关分析步骤
相关分析
双变量相关分析检验是否符合正态分布(K-S检验)
偏相关分析不需检验
距离分析不需检验
X/Y 度量(S)序号(O)名义(N)度量(S)Pearson相关系数Spearman等级相关系数/
序号(O)Spearman等级相关系数Spearman等级相关系数
Kendall ح系数
/
名义(N)/ 卡方值Pearson卡方值(Chi-Square)
Pearson相关系数K-S检验是否必须符合正态分布
Spearman等级相关系数不需检验
Kendall ح系数不需检验
一双变量相关分析(Pearson、Spearma、Kendall )
1 判断使用哪种相关系数,例检验是否满足使用Pearson相关系数的前提要求
2计算样本的相关系数r
按变量类型选择对应的相关系数种类,名义,度量,有序。
一般认为,当相关系数的绝对值大于0.8时,两变量具有较强的线性关系(Linear Relationship);而相关系数的绝对值小于0.3时,两变量间的线性关系较弱。
3 对两个样本来自的总体是否存在显著的线性关系进行判断
显著性检验来证明相关系数的大小是否显著。
1检验是否满足使用Pearson相关系数的前提要求
(1)【分析】——【非参数检验】——【单样本K-S检验】
(2)结果分析
单样本Kolmogorov-Smirnov 检验
年均衣着消费个人年收入家庭年收入
N 50 51 51
正态参数a,,b均值 1.44 1.33 2.25
标准差.733 .816 1.197
最极端差别绝对值.406 .462 .192
正.406 .462 .192
负-.274 -.342 -.147 Kolmogorov-Smirnov Z 2.870 3.302 1.372
渐近显著性(双侧) .000 .000 .046
a. 检验分布为正态分布。
. 根据数据计算得到。
H0:样本服从总体的正态分布。
0.046<0.05,拒绝原假设。
单样本检验的结果显示变量不服从正态分布,可以用Pearson相关系数检验变量之间的线性相关程度。
2 双变量相关分析
(1)【分析】→【相关】→【双变量】
(2)结果分析
相关性
年均衣着消费个人年收入家庭年收入年均衣着消费Pearson 相关性 1 .074 .199 显著性(双侧).612 .166
N 50 50 50 个人年收入Pearson 相关性.074 1 .419**显著性(双侧).612 .002
N 50 50 50 家庭年收入Pearson 相关性.199 .419** 1 显著性(双侧).166 .002
N 50 50 50 **. 在.01 水平(双侧)上显著相关。
附有“* *”的相关系数表明在0.01的水平上相关显著。
P值大于显著性水平0.01,则接受原假设,两者相关。
二偏相关分析
1先对各变量进行两两相关分析,计算变量之间的皮尔逊积差相关系数.
2进行偏相关分析,计算在控制其他变量的影响时,两个变量之间的相关程度。
1 【分析】→【相关】→【偏相关】
被试的两个变量选入右侧的变量框中,第三方变量选入右侧的控制变量框中。
2 结果分析
相关性
控制变量打折消费比年龄个人年收入-无-a打折消费比相关性 1.000 -.067 .084
显著性(双侧). .640 .558
df 0 49 49 年龄相关性-.067 1.000 .204
显著性(双侧).640 . .151
df 49 0 49 个人年收入相关性.084 .204 1.000
显著性(双侧).558 .151 .
df 49 49 0 个人年收入打折消费比相关性 1.000 -.086
显著性(双侧). .551
df 0 48
年龄相关性-.086 1.000
显著性(双侧).551 .
df 48 0
a. 单元格包含零阶(Pearson) 相关。
H0:两者不相关。
上表中的上半部分输出的是变量两两之间的简单相关系数,打折消费比与年龄之间相关系数为-0.067;
表下半部分是偏相关分析的输出结果,第一行为偏相关系数,第二行为相伴概率;第三行为统计检验的自由度。
剔除个人年收入的影响,打折消费比与年龄之间相关系数为-0.086.所以,在显著性水平下,打折消费比与年龄之间相关性不高。
三距离分析
1 “分析”→“相关”→“距离”
距离分析根据距离测度含义的差异,可以分为两种:相似性测度(Sinilarities)和不相似性测度(Dissimilarities)。
变量间距离是进行不相似性度量,个案间距离是进行相似性度量。
2 结果分析
不相似性测度以距离表示,距离的特征值越小越相似,距离越大差别越大;
相似性测度以相似系数表示,相似系数的特征值越大越相似,值越小差别越大。