通过Xpath定位元素
八爪鱼如何通过xpath实现自定义定位元素
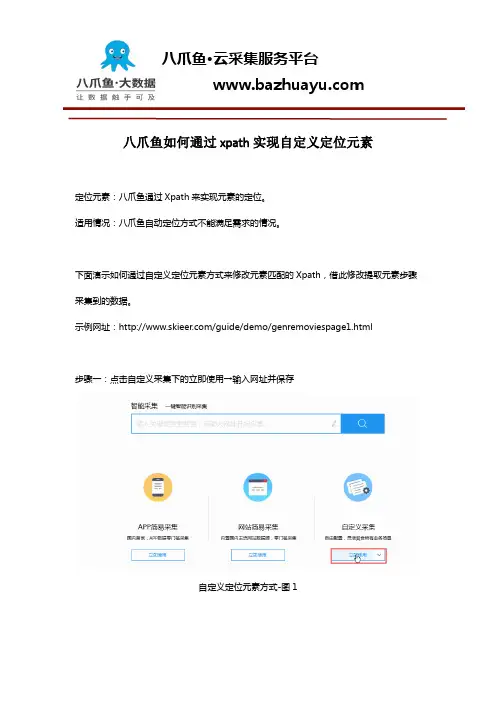
八爪鱼如何通过xpath实现自定义定位元素定位元素:八爪鱼通过Xpath来实现元素的定位。
适用情况:八爪鱼自动定位方式不能满足需求的情况。
下面演示如何通过自定义定位元素方式来修改元素匹配的Xpath,借此修改提取元素步骤采集到的数据。
示例网址:/guide/demo/genremoviespage1.html 步骤一:点击自定义采集下的立即使用→输入网址并保存自定义定位元素方式-图1自定义定位元素方式-图2步骤二:点击采集位置→循环采集元素→补充并修改提取元素步骤自定义定位元素方式-图3自定义定位元素方式-图4说明:循环采集元素会采集所有信息,我们在补充并修改提取元素步骤进行了删除第一个字段操作,同时添加了我们需要的正确字段。
步骤三:修改自定义定位元素方式选中要修改的字段→点击高级选项中自定义数据字段(如下图)→点击自定义定位元素方式进入自定义定位元素方式后,我们在下图红框处修改Xpath自定义定位元素方式-图6其中元素匹配的Xpath是指可以通过这个Xpath路径在网页中直接找到所需数据的路径;相对Xpath指相对于循环Xpath的路径,将循环中的Xpath接上相对Xpath路径就可以生成一条直接匹配元素的路径。
下面进行演示。
演示中使用了火狐浏览器的Firebug插件,详细使用情况请到Xpath使用教程中查看。
自定义定位元素方式-图7自定义定位元素方式-图8自定义定位元素方式-图9自定义定位元素方式-图10如图,示例中将循环中的Xpath和字段对应的相对Xpath接在一起,在浏览器中可以查找到所有的标题。
假如我们想通过Xpath 的修改采集其他的字段怎么采集呢?下面演示如何通过自定义定位元素方式修改标题字段的Xpath 使之采集的内容变成类型中的内容步骤1:找出类型所在的Xpath 是怎样的自定义定位元素方式-图11自定义定位元素方式-图12自定义定位元素方式-图13说明:我们知道循环中的内容为每个需要采集的内容所在的位置,我们将循环中的Xpath 复制进入浏览器也看到匹配到了所有电影的框。
八爪鱼xpath入门教程以及定位元素实例

xpath入门教程以及定位元素实例本文用来讲解xpath的入门基础,本教材是xpath入门2,建议大家从入门1教程开始学习Xpath的教程适合对八爪鱼已经有一些基础的用户来学习。
示例地址/tutorial?type=0&page=0&tag=%E8%BF%9B%E9%98%B6&version=otherXpath:是一种路径查询语言,简单的说就是利用一个路径表达式找到我们需要的数据位置。
Html:超文本标记语言,是用来描述网页的一种语言。
主要用于控制数据的显示和外观。
HTML文档也被称为网页。
Xpath专用于xml中沿着路径查找数据用的,但是八爪鱼采集器内部有一套针对Html的Xpath引擎,使得直接用Xpath就能精准的查找定位网页里面的数据。
xpath入门2-图1例如下图通过火狐的firebug、firepath查看网页源码。
查看方法参考“xpath入门1”教程xpath入门2-图2完整的HTML文件至少包括<HTML>标签、<HEAD>标签、<TITLE>标签和<BODY>标签,并且这些标签都是成对出现的,开头标签为<>,结束标签为</>,在这两个标签之间添加内容。
通过这些标签中的相关属性可以设置页面的背景色、背景图像等。
Html标签作为开始和结束的标记由尖括号包围的关键词,比如 <html>标签对中,第一个标签是开始标签,第二个标签是结束标签元素HTML的网页内容是由元素组成的,从开始标签到结束标签的所有代码。
元素的开始和结束都使用标签作为开始和结束的标记节点所有事物都是节点整个文档是一个文档节点每个 HTML 元素是元素节点HTML元素内的文本是文本节点每个 HTML 属性是属性节点注释是注释节点Html常见标签<a></a> 定义超链接,用于从一张页面链接到另一张页面<h1></h1> 文本标题标签,最大的标签。
python元素定位的八种方法_Selenium定位元素的8种方法介绍

python元素定位的八种方法_Selenium定位元素的8种方法介绍Selenium是一个自动化测试工具,常用于网页自动化测试和网页爬虫。
定位元素是Selenium的重要功能之一,通过定位元素,可以进行元素的查找、操作和验证。
Selenium提供了多种定位元素的方法,下面将介绍Selenium定位元素的8种方法。
1. 通过id定位:使用find_element_by_id(方法,通过元素的id 属性定位元素。
id是网页中元素的唯一标识符,因此通过id定位元素是最常用的定位方法之一2. 通过name定位:使用find_element_by_name(方法,通过元素的name属性定位元素。
name属性不是所有元素都有的,但是一些元素会有name属性,可以利用这个属性来定位元素。
3. 通过class定位:使用find_element_by_class_name(方法,通过元素的class属性定位元素。
class属性是元素的类名,一个元素可以有多个类名,使用空格分隔。
通过class属性可以定位多个相同类名的元素。
6. 通过partial link text定位:使用find_element_by_partial_link_text(方法,通过包含元素的链接文本定位元素。
与前一种方法相比,这种方法不要求链接文本完全匹配,只需要包含指定的链接文本即可。
7. 通过xpath定位:使用find_element_by_xpath(方法,通过元素的路径表达式定位元素。
Xpath是一种用于选择XML文档中节点的语言,通过Xpath可以定位任意元素。
8. 通过css selector定位:使用find_element_by_css_selector(方法,通过元素的CSS选择器定位元素。
CSS选择器是用来选择HTML元素的一种方法,使用CSS选择器可以更精确地定位元素。
xpath 教程的例子

xpath 教程的例子XPath 是一种用来在 XML 文档中定位节点的语言,它是 XML Path Language的缩写。
XPath 在 XML 文档中定位节点的方法类似于在 HTML 页面中使用 CSS选择器来定位元素。
在本教程中,我们将介绍 XPath 的基本语法以及一些实际的例子来演示如何在 XML 文档中使用 XPath 定位节点。
1. XPath 基本语法XPath 使用路径表达式来定位 XML 文档中的节点。
路径表达式可以使用节点名称、节点关系、属性等来定位节点。
以下是一些基本的 XPath 表达式:- 使用节点名称定位节点:`/bookstore/book` 表示选择 bookstore 元素下的所有book 元素。
- 使用路径定位节点:`//book` 表示选择文档中所有的 book 元素。
- 使用属性定位节点:`//book[@category='novel']` 表示选择 category 属性为'novel' 的所有 book 元素。
2. XPath 实例演示现在让我们来看几个使用 XPath 定位节点的实例。
- 示例 1:选择所有 book 元素`//book` 表示选择文档中所有的 book 元素。
如果 XML 文档中有多个 book 元素,那么这个表达式将匹配所有的 book 元素。
- 示例 2:选择特定属性的 book 元素`//book[@category='novel']` 表示选择 category 属性为 'novel' 的所有 book 元素。
这个表达式将筛选出 category 属性为 'novel' 的所有 book 元素。
- 示例 3:选择指定位置的 book 元素`/bookstore/book[1]` 表示选择 bookstore 元素下的第一个 book 元素。
xpath定位中详解id、starts-with、contains、text()和last。。。

xpath定位中详解id、starts-with、contains、text()和last。
1、XPATH使⽤⽅法使⽤XPATH有如下⼏种⽅法定位元素(相⽐CSS选择器,⽅法稍微多⼀点):a、通过绝对路径定位元素(不推荐!)WebElement ele = driver.findElement(By.xpath("html/body/div/form/input"));b、通过相对路径定位元素WebElement ele = driver.findElement(By.xpath("//input"));c、使⽤索引定位元素WebElement ele = driver.findElement(By.xpath("//input[4]"));d、使⽤XPATH及属性值定位元素WebElement ele = driver.findElement(By.xpath("//input[@id='fuck']"));//其他⽅法(看字⾯意思应该能理解吧)WebElement ele = driver.findElement(By.xpath("//input[@type='submit'][@name='fuck']"));WebElement ele = driver.findElement(By.xpath("//input[@type='submit' and @name='fuck']"));WebElement ele = driver.findElement(By.xpath("//input[@type='submit' or @name='fuck']"));e、使⽤XPATH及属性名称定位元素元素属性类型:@id 、@name、@type、@class、@tittle//查找所有input标签中含有type属性的元素WebElement ele = driver.findElement(By.xpath("//input[@type]"));f、部分属性值匹配WebElement ele = driver.findElement(By.xpath("//input[start-with(@id,'fuck')]"));//匹配id以fuck开头的元素,id='fuckyou'WebElement ele = driver.findElement(By.xpath("//input[ends-with(@id,'fuck')]"));//匹配id以fuck结尾的元素,id='youfuck'WebElement ele = driver.findElement(By.xpath("//input[contains(@id,'fuck')]"));//匹配id中含有fuck的元素,id='youfuckyou'g、使⽤任意值来匹配属性及元素WebElement ele = driver.findElement(By.xpath("//input[@*='fuck']"));//匹配所有input元素中含有属性的值为fuck的元素元素定位总结//注:本专题只介绍java版//By idWebElement ele = driver.findElement(By.id());//By NameWebElement ele = driver.findElement(By.id());//By classNameWebElement ele = driver.findElement(By.className());//By tabNameWebElement ele = driver.findElement(By.tagName());//By linkTextWebElement ele = driver.findElement(By.linkText());//By partialLinkTextWebElement ele = driver.findElement(By.partialLinkText());//通过部分⽂本定位连接//By cssSelectorWebElement ele = driver.findElement(By.cssSelector());//By XPATHWebElement ele = driver.findElement(By.xpath());=================================栗⼦=====================================1、id 获取id 的属性值2、starts-with 顾名思义,匹配⼀个属性开始位置的关键字 -- 模糊定位3、contains 匹配⼀个属性值中包含的字符串 -- 模糊定位4、text() 函数⽂本定位5、last() 函数位置定位eg<input id="su" class="bg s_btn btnhover" value="百度⼀下" type="submit"/>//*[@id='su'] 获取id 的属性为'su' 的值或//input[contains(@class,'bg s_btn')]<a class="lb" href="https:///v2/?login&tpl=mn&u=http%3A%2F%%2F" name="tj_login" onclick="return false;">登录</a>//a[starts-with(@name,'tj_lo')] 属性模糊定位//a[contains(@name,'tj_lo')] 属性模糊定位<a href="">百度搜索</a>//a[text()='百度搜索']或//a[contains(text(),"搜索")] --⽂本模糊定位<a id="setf" href="///cache/sethelp/help.html" onmousedown="returnns_c({'fm':'behs','tab':'favorites','pos':0})" target="_blank">把百度设为主页</a>//a[text()='把百度设为主页']/A/B/C[last()] 表⽰A元素→B元素→C元素的最后⼀个⼦元素,得到id值为e2的E元素。
xpath helper用法 -回复

xpath helper用法-回复使用XPath Helper是一种方便快捷的方式来定位网页上的特定元素。
XPath是一种查询语言,用于在XML文档中定位和选择节点。
XPath Helper是一款浏览器插件,为网页开发人员提供了一种简单直观的方式来测试和验证XPath表达式。
XPath Helper的用法非常简单,只需按照以下步骤进行操作:第一步:安装XPath Helper在您的浏览器上搜索并安装XPath Helper插件。
XPath Helper适用于Chrome和Firefox浏览器,您可以根据自己的浏览器选择相应的插件安装。
第二步:打开XPath Helper安装完成后,在浏览器工具栏上找到XPath Helper图标,点击它以打开XPath Helper。
一旦打开,XPath Helper将以一个弹出窗口的形式出现。
第三步:在XPath Helper中输入XPath表达式在XPath Helper弹出窗口中,您会看到两个主要输入框:XPath和XML。
XPath输入框用于输入您想要测试的XPath表达式,而XML输入框用于输入您要测试的XML文档。
第四步:测试XPath表达式在XPath输入框中输入您的XPath表达式,并在XML输入框中输入示例XML代码。
然后,点击“Evaluate XPath”按钮。
第五步:查看结果一旦您点击“Evaluate XPath”按钮,XPath Helper将会对您的XPath 表达式和XML文档进行分析,并将结果以可视化的方式显示在窗口的下方。
XPath Helper显示的结果包括所选择的节点的数量,以及每个节点的具体内容。
这使您能够轻松确定您的XPath表达式是否有效,并帮助您在调试代码时更快地找到错误。
另外,XPath Helper还提供了一些其他功能,如排序功能和基于CSS选择器生成XPath表达式的功能,以帮助您更好地理解和使用XPath语言。
Android自动化之元素定位xpath
Android⾃动化之元素定位xpath
1.通过xpath定位元素
2. 像图⽚1的元素路径为:
find_element_by_xpath("//android.support.v4.view.ViewPager/android.widget.Linearlayout/android.widget.LinearLayout[3]/android.widget.Button[1]")从外往⾥⼀层⼀层的剥,最终找到要的元素。
注意:xpath路径不能从最外层的整个页⾯开始,那样会报错。
要从包含该控件的最上层的class开始写。
什么是包含该空间的最上层元素呢?像这⾥是:android.support.v4.view.ViewPager
我们点击 android.support.v4.view.ViewPager 就发现实际就是整个键盘区域
元素的定位貌似和我们⽤uiautomatorviewer获取到的不⼀致。
android.widget.LinearLayout[3]/android.widget.Button[1] ⽽不是 android.widget.LinearLayout[2]/android.widget.Button[0]笔者认为要定位第三个android.widget.Linearlayout中的第⼀个button.
有⼀种说法xpath定位元素是从1开始⽽不是从0开始。
xpath 规则
xpath 规则XPath规则:如何使用XPath定位元素XPath是一种用于在XML文档中定位元素的语言。
它可以帮助开发人员快速准确地找到他们需要的元素,从而更加高效地处理XML文档。
在本文中,我们将介绍XPath规则,以及如何使用XPath定位元素。
XPath规则XPath规则由一系列路径表达式组成,用于定位XML文档中的元素。
以下是一些常用的XPath规则:1. 绝对路径:以斜杠“/”开头,表示从根节点开始查找元素。
例如,/bookstore/book表示查找根节点下的bookstore元素,再查找其中的book元素。
2. 相对路径:不以斜杠“/”开头,表示从当前节点开始查找元素。
例如,bookstore/book表示查找当前节点下的bookstore元素,再查找其中的book元素。
3. 轴:用于指定元素之间的关系。
例如,ancestor::book表示查找当前节点的所有祖先节点中的book元素。
4. 谓语:用于筛选元素。
例如,book[1]表示查找第一个book元素。
5. 通配符:用于匹配任意元素。
例如,bookstore/*表示查找bookstore元素下的所有子元素。
使用XPath定位元素在使用XPath定位元素时,我们需要先创建一个XPath对象,然后使用XPath对象的evaluate()方法来执行XPath规则。
以下是一个使用XPath定位元素的示例:```pythonimport xml.etree.ElementTree as ET# 创建XML文档对象tree = ET.parse('books.xml')root = tree.getroot()# 创建XPath对象xpath = ET.XPath('/bookstore/book[1]/title')# 执行XPath规则title = xpath(root)[0].text# 输出结果print(title)```在上面的示例中,我们首先使用ElementTree模块解析XML文档,然后创建了一个XPath对象,使用XPath规则定位第一个book元素下的title元素。
pythonseleniumxpath定位时使用变量
pythonseleniumxpath定位时使用变量在使用Python和Selenium进行XPath定位时,经常遇到需要使用变量来进行定位的情况。
变量可以是任何类型的数据,如字符串、整数等。
使用变量可以动态地定位元素,使代码更加灵活和复用。
以下是一些使用变量进行XPath定位的示例:1.使用字符串变量定位元素:```python#定义一个字符串变量username = "admin"# 使用变量构建XPath表达式# 使用XPath表达式进行定位element = driver.find_element_by_xpath(xpath)```在上面的例子中,我们使用字符串变量`username`构建XPath表达式来定位一个带有`name`属性为`admin`的`input`元素。
通过使用`f-string`或`.format(`等方式,我们可以将变量嵌入XPath表达式中。
2.使用整数变量定位一组元素:```python#定义一个整数变量index = 2# 使用变量构建XPath表达式# 使用XPath表达式进行定位elements = driver.find_elements_by_xpath(xpath)```在这个例子中,我们使用整数变量`index`构建XPath表达式来定位一组`div`元素中的第`index`个元素。
通过更改`index`的值,我们可以定位不同的元素。
3.使用多个变量组合定位元素:```python#定义多个变量username = "admin"password = "password123"# 使用变量构建XPath表达式# 使用XPath表达式进行定位element = driver.find_element_by_xpath(xpath)```在这个例子中,我们使用多个变量`username`和`password`来构建XPath表达式来定位一个`input`元素,该元素具有特定的`name`,`type`和`value`属性。
元素定位-XPATH定位方法总结
元素定位-XPATH定位⽅法总结1、Xpath定位⽅法探讨xpath是⽐较常⽤的⼀种定位元素的⽅式,因为它很⽅便,缺点是,消耗系统性能。
如果Xpath使⽤的⽐较好,⼏乎可以定位到任何页⾯元素,⽽且受页⾯变化影响较⼩。
1.1、什么是XPATH: XPath (XML Path Language) 是⼀门在 HTML⽂档中查找信息的语⾔,可⽤来在 HTML⽂档中对元素和属性进⾏遍历。
详细使⽤⽅法可见 W3School官⽅⽂档:1.2、XPATH节点选择⽅式1)Chrome插件⼯具:Xpath helper可以验证定位元素的位置准确性、可以查看某个元素的xpath路径,但路径通常较长不建议此⽅式2)Chrome浏览器:⿏标右键copy->Copy Xpath直接复制某个元素xpath路径(常⽤⽅式)3)⼿动编写xpath路径:⽅式⼆不能满⾜所有情况,需要⼿动微调路径借助⽅式⼀来验证1.3、XPATH节点定位⽅法与特点使⽤绝对路径定位元素 例如:driver.findElement(By.xpath("/html/body/div/form/input"))。
特点:这个路径是从⽹页起始标签开始⼀直到要定位的元素的路径,如果要定位的元素在页⾯最下⾯,则这个Xpath路径会⾮常长。
如果在要定位的元素与页⾯开始之间的元素有任何增减,元素定位就会失败。
使⽤相对路径定位元素 例如:driver. findElement(By.xpath ("//input") ) 返回查找到的第⼀个符合条件的元素。
特点:相对路径⼀般只会包含与被定位元素最近的⼏层元素有关,相对路径写的好的话,页⾯变动影响最⼩,⽽且定位准确。
使⽤索引定位元素,索引的初始值为1,注意与数组等区分开。
例如:driver. findElement(By.xpath ("//input[2]") )返回查找到的第⼆个符合条件的元素。
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
使用XPath进行元素定位
在Selenium中,定位HTML元素经常用到XPath表达式,下面将进行详细的介绍。
XPath是在XML文档中查找信息的一种语言,可用来在XML文档中对元素和属性进行导航。
XPath是W3C XSLT标准的主要元素,并且XQuery和Xpointer都构建于XPath表达之上。
因此,对XPath的理解是很多高级XML应用的基础。
XPath使用路径表达式来选取XML文档中的节点或者节点集。
这些路径表达式和常规的计算机文件系统中看到的表达式非常相似。
虽然XPath用于查找XML的节点,但由于HTML和XML结构类似,所以XPath也经常用于查找HTML文档中的节点。
为了使读者更好地了解XPath表达式是什么,这里直接用实例进行说明,列举一些最常用的XPath语法。
实例1-1
基本的XPath语法类似于在一个文件系统中定位文件,如果路径以斜线“/”开始,那么该路径就表示到一个元素的绝对路径,如表1-1至表1-3所示。
表1-1 以斜线开始的路径实例(一)
表1-2 以斜线开始的路径实例(二)
表1-3 以斜线开始的路径实例(三)
实例1-2
如果路径以双斜线//开始,则表示选择文档中所有满足双斜线“//”之后规则的元素(无论层级关系),如表1-4和表1-5所示。
表1-4 以双斜线开始的路径实例(一)
表1-5 以双斜线开始的路径实例(一)
星号* 表示选择所有由星号之前的路径所定位的元素,如表1-6至表1-8所示。
表1-6 以星号开始的路径实例(一)
表1-7 以星号开始的路径实例(二)
表1-8 以星号开始的路径实例(三)
方括号中的表达式可以进一步地限定元素,其中数字表示元素在选择集中的位置,而last()函数则表示选择集中的最后一个元素,如表1-9和表1-10所示。
表1-9 使用方括号限定元素实例(一)
表1-10 使用方括号限定元素实例(二)
实例1-5
可以通过前缀@ 来指定属性,如表1-11至表1-15所示。
表1-11 通过@指定属性实例(一)
表1-12 通过@指定属性实例(二)
表1-13 通过@指定属性实例(三)
表1-14 通过@指定属性实例(四)
表1-15 通过@指定属性实例(五)
实例1-6
属性的值可以用来作为选择的准则,如表1-16和表1-17所示。
表1-16 使用属性值作为选择准则(一)
表1-17 使用属性值作为选择准则(二)
实例1-7
可以使用分隔符| 将多个路径合并在一起,如表1-18至表1-20所示。
表1-18 使用分隔符“Ⅰ”合并多个路径实例(一)
表1-19 使用分隔符“Ⅰ”合并多个路径实例(二)
表1-20 使用分隔符“Ⅰ”合并多个路径实例(三)
相信大家看了这些实例后,应该能大致了解XPath的作用了。
更多关于XPath的信息可参见/xpath/index.asp。