Mplus结构方程模型步骤入门
完整版Mplus结构方程模型步骤入门

1数据格式转换因为Mplus只能打开ASCII格式的文件(.dat和.txt文件),所以常规的SPSS数据库的数据不能被读取,所以数据分析之前先要将sav格式另存为dat格式。
另存为选项里有两类dat格式,一般可选用“以制表符分隔”,当数据量较大时,可选“固定ASCII格式”。
这两类并没有明显特异的使用条件。
2打开mplus程序,建立新文件,即点击"new”。
当然,新打开Mplus程序也会默认这个TITLE: example3.2然后表明我们引用的数据库来自于哪里,也就是刚刚那个DAT文件。
命令为:DATA: FILE IS C:\Users\dell\Desktop\MPLUS结构方程模型教程数据库.dat;这里面需要注意的是:DATA: FILE IS (或者DATA: FILE=是固定句式,是必要的。
之后“C:\Users\dell\Desktop\MPLUS结构方程模型教程数据库.dat”这是DAT文件的保存路径。
一般情况下,如果mplus语句文件和dat文件在同一个文件夹中,只需要DATA: FILE I黴据库.dat;但实际上很多情况下,两者即使在同一个文件中,也很可能读不出来,所以必要的话,可将该DAT文件的保存路径写全,这样肯定是没错的。
另外,一个命令结束后,必须必须加上“;”即英文格式下的分号(除外TITLE)°3.3写出数据库中所有的变量名称以及本次分析需要的变量名称。
这需要按照spss数据库中变量名称顺序来写。
VARIABLE: NAMES ARE a1 a2 a3 a4 a5 a6 a7 a8 a9 b1 b2 b3 b4 c1 c2 c3 c4;USEVARIABLES ARES ARE a1 a2 a3 a4 a5 a6 a7 a8 a9 b1 b2 b3 b4 c1 c2 c3 c4;当然这是最基本繁琐的写法,可以直接写为:VARIABLE: NAMES ARE a1-a9 b1-b4 c1-c4;USEVARIABLES ARES ARE a1-a9 b1-b4 c1-c4;不同变量间有空格。
mplus结构方程模型步骤入门)

1数据格式转换因为Mplus只能打开ASCII格式的文件(.dat和.txt文件),所以常规的SPSS数据库的数据不能被读取,所以数据分析之前先要将sav格式另存为dat格式。
另存为选项里有两类dat格式,一般可选用“以制表符分隔”,当数据量较大时,可选“固定ASCII格式”。
这两类并没有明显特异的使用条件。
选择某一种dat格式后,“将变量名写入表格”这一项不要勾选。
然后保存。
一般将该数据文件和mplus语句文件放在一个文件夹。
2 打开mplus程序,建立新文件,即点击“new”。
当然,新打开Mplus程序也会默认这个界面。
3 编辑命令。
这是Mplus分析数据最核心的步骤首先我们可以给该分析起个名字(该步骤可有可无),例如:TITLE: example然后表明我们引用的数据库来自于哪里,也就是刚刚那个DAT文件。
命令为:DATA: FILE IS C:\Users\dell\Desktop\MPLUS结构方程模型教程\数据库.dat;这里面需要注意的是: DATA: FILE IS (或者DATA: FILE=)是固定句式,是必要的。
之后“C:\Users\dell\Desktop\MPLUS结构方程模型教程\数据库.dat”这是DAT文件的保存路径。
一般情况下,如果mplus语句文件和dat文件在同一个文件夹中,只需要DATA: FILE IS数据库.dat; 但实际上很多情况下,两者即使在同一个文件中,也很可能读不出来,所以必要的话,可将该DAT文件的保存路径写全,这样肯定是没错的。
另外,一个命令结束后,必须必须加上“;”即英文格式下的分号(除外TITLE)。
写出数据库中所有的变量名称以及本次分析需要的变量名称。
这需要按照spss数据库中变量名称顺序来写。
VARIABLE: NAMES ARE a1 a2 a3 a4 a5 a6 a7 a8 a9 b1 b2 b3 b4 c1 c2 c3 c4;USEVARIABLES ARES ARE a1 a2 a3 a4 a5 a6 a7 a8 a9 b1 b2 b3 b4 c1 c2 c3 c4;当然这是最基本繁琐的写法,可以直接写为:VARIABLE: NAMES ARE a1-a9 b1-b4 c1-c4;USEVARIABLES ARES ARE a1-a9 b1-b4 c1-c4;不同变量间有空格。
mplus结构方程模型 基础命令

一、mplus结构方程模型简介mplus是一种常用的结构方程模型(Structural Equation Modeling, SEM)分析软件,它具有强大的功能和灵活的操作方式,被广泛应用于社会科学、心理学、教育学等领域的数据分析中。
在mplus中,基础命令是进行SEM分析的基础,熟练掌握基础命令对于进行SEM分析是至关重要的。
二、mplus基础命令的语法结构mplus基础命令的语法结构主要包括变量定义、模型设置和分析选项三个部分,在编写基础命令时需要按照特定的格式书写。
1. 变量定义变量定义部分通过使用VARIABLE命令来定义观测变量和潜在变量,语法格式如下:VARIABLE:变量1-变量n;定义观测变量和潜在变量的名称,并使用分号进行分隔。
2. 模型设置模型设置部分通过使用ANALYSIS命令来指定模型的参数设置和分析选项,语法格式如下:ANALYSIS:TYPE = basic;在模型设置部分可以指定各种参数和选项,以满足具体的分析需求。
3. 分析选项分析选项部分通过使用MODEL命令来指定SEM模型的结构和参数估计方法,语法格式如下:MODEL:f1 BY x1-x3;f2 BY x4-x6;在分析选项部分可以定义模型中的路径和参数,以及指定变量之间的关系。
三、mplus基础命令的使用方法在使用mplus进行SEM分析时,需要按照以下步骤进行基础命令的编写和运行。
1. 打开mplus软件并创建新的分析文件。
2. 编写基础命令,包括变量定义、模型设置和分析选项。
3. 保存基础命令文件,并使用.mplus后缀名进行命名。
4. 运行基础命令文件,查看分析结果并进行进一步的模型检验和修正。
四、mplus基础命令的案例分析以下是一个基础的mplus命令案例,用于进行双因子结构方程模型的分析:VARIABLE:y1-y5;f1 f2;ANALYSIS:TYPE = general;MODEL:f1 BY y1 y2 y3;f2 BY y4 y5;在这个案例中,通过使用VARIABLE命令定义了观测变量和潜在变量,使用ANALYSIS命令指定了分析类型,使用MODEL命令定义了双因子结构方程模型,并指定了观测变量和潜在因子之间的关系。
Mplus结构方程模型步骤(入门)
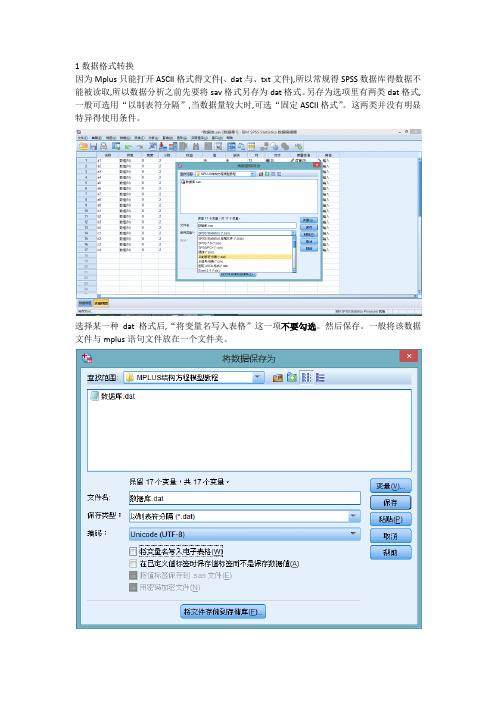
1数据格式转换因为Mplus只能打开ASCII格式得文件(、dat与、txt文件),所以常规得SPSS数据库得数据不能被读取,所以数据分析之前先要将sav格式另存为dat格式。
另存为选项里有两类dat格式,一般可选用“以制表符分隔”,当数据量较大时,可选“固定ASCII格式”。
这两类并没有明显特异得使用条件。
选择某一种dat格式后,“将变量名写入表格”这一项不要勾选。
然后保存。
一般将该数据文件与mplus语句文件放在一个文件夹。
2 打开mplus程序,建立新文件,即点击“new”。
当然,新打开Mplus程序也会默认这个界面。
3 编辑命令。
这就是Mplus分析数据最核心得步骤3、1 首先我们可以给该分析起个名字(该步骤可有可无),例如:TITLE: example3、2 然后表明我们引用得数据库来自于哪里,也就就是刚刚那个DAT文件。
命令为: DATA: C:\Users\dell\Desktop\MPLUS结构方程模型教程\数据库、dat;这里面需要注意得就是: DATA: (或者DATA: FILE=)就是固定句式,就是必要得。
之后“C:\Users\dell\Desktop\MPLUS结构方程模型教程\数据库、dat”这就是DAT文件得保存路径。
一般情况下,如果mplus语句文件与dat文件在同一个文件夹中,只需要DATA: 数据库、dat; 但实际上很多情况下,两者即使在同一个文件中,也很可能读不出来,所以必要得话,可将该DAT文件得保存路径写全,这样肯定就是没错得。
另外,一个命令结束后,必须必须加上“;”即英文格式下得分号(除外TITLE)。
3、3 写出数据库中所有得变量名称以及本次分析需要得变量名称。
这需要按照spss数据库中变量名称顺序来写。
VARIABLE: NAMES ARE a1 a2 a3 a4 a5 a6 a7 a8 a9 b1 b2 b3 b4 c1 c2 c3 c4;USEVARIABLES ARES ARE a1 a2 a3 a4 a5 a6 a7 a8 a9 b1 b2 b3 b4 c1 c2 c3 c4;当然这就是最基本繁琐得写法,可以直接写为:VARIABLE: NAMES ARE a1-a9 b1-b4 c1-c4;USEVARIABLES ARES ARE a1-a9 b1-b4 c1-c4;不同变量间有空格。
动态结构方程模型mplus

动态结构方程模型mplus动态结构方程模型(Mplus)是一种常用的统计分析方法,可用于在多个时间点上对数据进行分析。
它可以用于测量模型、结构模型、纵向数据分析和多水平数据分析等方面。
本文将介绍如何使用Mplus进行动态结构方程模型分析。
1. 准备数据在使用Mplus进行动态结构方程模型分析之前,首先需要准备好数据。
在数据准备阶段,需要确认数据是否包含多个时间点,并且每个时间点的变量名称是否相同。
此外,需要检查数据是否具有足够的可测性以进行结构方程建模。
2. 设计结构方程模型设计结构方程模型是动态结构方程模型分析的关键一步。
首先需要确定理论模型的内容,以及各个时间点上需要测量的变量。
然后需要建立一个初始模型,并进行逐步的改进。
改进模型的过程中,需要根据拟合程度指标,对模型进行适当的适应。
适应的目标是让拟合程度指标最优,以便获得最好的拟合表现。
3. 模型拟合在设计好结构方程模型后,需要通过Mplus进行拟合,以得到相应的参数估计值。
拟合过程中需要注意以下问题:(1)确定程序设置。
这包括确定要使用哪一种算法,如BGM、EM等,以及确定最大迭代次数和容许误差等。
(2)确定模型拟合检验的方法。
模型提供了多个拟合指标,如卡方拟合指标、SRMR、RMSEA和CFI指标等,需要了解它们各自的含义,并根据实际需求进行选择。
4. 解释结果当模型拟合成功后,需要对结果进行解释,以确定模型的质量。
需要评估拟合指标,以评估模型是否符合预期。
如果模型拟合不佳,需要进行模型改进,并重新进行拟合。
总结:动态结构方程模型是一种有效的统计方法,能够在多个时间点上对论题进行探究。
在进行动态结构方程模型分析之前,需要准备好数据、设计结构方程模型、进行模型拟合和结果解释。
同时,需要注意拟合程度指标的使用,并进行根据实际需求的选择。
(完整版)Mplus简介及实例应用

Mplus 6.1 使用示例Mplus结构方程模型步骤(入门)1数据格式转换因为Mplus只能打开ASCII格式的文件(.dat和.txt文件),所以常规的SPSS数据库的数据不能被读取,所以数据分析之前先要将sav格式另存为dat格式。
另存为选项里有两类dat格式,一般可选用“以制表符分隔”,当数据量较大时,可选“固定ASCII格式”。
这两类并没有明显特异的使用条件。
选择某种dat格式后,“将变量名写入表格”这一项不要勾选。
然后保存。
一般将该数据文件和mplus语句文件放在一个文件夹。
2 打开mplus程序,建立新文件,即点击“new”。
当然,新打开Mplus程序也会默认这个界面。
3 编辑命令。
这是Mplus分析数据最核心的步骤3.1 首先我们可以给该分析起个名字(该步骤可有可无),例如:TITLE: example3.2 然后表明我们引用的数据库来自于哪里,也就是刚刚那个DAT文件。
命令为:DATA: FILE IS C:\Users\dell\Desktop\MPLUS 结构方程模型教程\数据库.dat;这里面需要注意的是:DATA: FILE IS (或者DATA: FILE=)是固定句式,是必要的。
之后“C:\Users\dell\Desktop\MPLUS结构方程模型教程\数据库.dat”这是DAT文件的保存路径。
一般情况下,如果mplus语句文件和dat文件在同一个文件夹中,只需要DATA:FILE IS数据库.dat; 但实际上很多情况下,两者即使在同一个文件中,也很可能读不出来,所以必要的话,可将该DAT文件的保存路径写全,这样肯定是没错的。
另外,一个命令结束后,必须必须加上“;”即英文格式下的分号(除外TITLE)。
3.3 写出数据库中所有的变量名称以及本次分析需要的变量名称。
这需要按照spss数据库中变量名称顺序来写。
VARIABLE: NAMES ARE a1 a2 a3 a4 a5 a6 a7 a8 a9 b1 b2 b3 b4 c1 c2 c3 c4; USEVARIABLES ARES ARE a1 a2 a3 a4 a5 a6 a7 a8 a9 b1 b2 b3 b4 c1 c2 c3 c4;当然这是最基本繁琐写法,可直接写为:VARIABLE: NAMES ARE a1-a9 b1-b4 c1-c4; USEVARIABLES ARES ARE a1-a9 b1-b4 c1-c4;不同变量间有空格。
mplus mlr法

Mplus MLR法1. 简介Mplus是一种用于结构方程模型(SEM)分析的统计软件,提供了许多常用的分析方法和技术。
其中,MLR(Maximum Likelihood Robust)法是Mplus中的一种参数估计方法,用于处理具有缺失数据的结构方程模型。
2. MLR法的原理MLR法是一种基于最大似然估计的方法,用于估计结构方程模型的参数。
与传统的ML(Maximum Likelihood)法相比,MLR法考虑了数据的缺失情况,可以更准确地估计参数。
MLR法的核心思想是通过最大化似然函数来估计模型参数。
似然函数是描述观测数据出现的概率,而MLR法则通过优化似然函数,找到最能解释观测数据的模型参数。
在具体的实施过程中,MLR法引入了鲁棒标准误(Robust Standard Errors)的概念,用于处理数据的缺失和非正态分布情况。
通过计算鲁棒标准误,可以获得更准确的参数估计和统计推断。
3. MLR法的应用MLR法在结构方程模型分析中的应用非常广泛,特别适用于处理缺失数据和非正态分布的变量。
下面介绍一些常见的应用场景:3.1 缺失数据分析在实际研究中,数据缺失是一个常见的问题。
传统的ML方法无法处理缺失数据,而MLR法则可以通过引入鲁棒标准误来处理缺失数据,提供更准确的参数估计。
3.2 非正态分布数据分析在某些情况下,研究者收集到的数据可能不符合正态分布假设。
MLR法可以通过引入鲁棒标准误来处理非正态分布的数据,避免参数估计的偏差。
3.3 多组分析MLR法还可以用于多组分析,即将样本分为多个组别进行分析。
通过比较不同组别之间的模型拟合指标和参数估计,可以了解不同组别之间的差异和相似性。
4. MLR法的优缺点MLR法作为一种参数估计方法,具有以下优点:•考虑了数据的缺失情况,提供了更准确的参数估计;•考虑了数据的非正态分布情况,提供了更准确的统计推断;•可以用于处理多组数据,进行组间比较和分析。
然而,MLR法也存在一些局限性:•计算复杂度较高,需要较长的运行时间;•对于大规模数据集,可能存在计算和存储上的限制。
Mplus简介及实例应用

Mplus 6.1 使用示例文案大全 Mplus结构方程模型步骤(入门)1数据格式转换因为Mplus 只能打开ASCII 格式的文件(.dat 和.txt 文件),所以常规的SPSS 数据库的数据不能被读取,所以数据分析之前先要将sav 格式另存为dat 格式。
另存为选项里有两类dat 格式,一般可选用“以制表符分隔”,当数据量较大时,可选“固定ASCII 格式”。
这两类并没有明显特异的使用条件。
文案大全选择某种dat 格式后,“将变量名写入表格”这一项不要勾选。
然后保存。
一般将该数据文件和mplus 语句文件放在一个文件夹。
2 打开mplus程序,建立新文件,即点击“new”。
当然,新打开Mplus程序也会默认这个界面。
3 编辑命令。
这是Mplus分析数据最核心的步骤3.1 首先我们可以给该分析起个名字(该步骤可有可无),例如:TITLE: example3.2 然后表明我们引用的数据库来自于哪里,也就是刚刚那个DAT文件。
命令为:DATA: FILE IS C:\Users\dell\Desktop\MPLUS 结构方程模型教程\数据库.dat;这里面需要注意的是:DATA: FILE IS (或者DATA: FILE=)是固定句式,是必要的。
之后“C:\Users\dell\Desktop\MPLUS结构方程模型教程\数据库.dat”这是DAT文件的保存路径。
一般情况下,如果mplus语句文件和dat文件在同一个文件夹中,只需要DATA:文案大全FILE IS数据库.dat; 但实际上很多情况下,两者即使在同一个文件中,也很可能读不出来,所以必要的话,可将该DAT文件的保存路径写全,这样肯定是没错的。
另外,一个命令结束后,必须必须加上“;”即英文格式下的分号(除外TITLE)。
3.3 写出数据库中所有的变量名称以及本次分析需要的变量名称。
这需要按照spss数据库中变量名称顺序来写。
VARIABLE: NAMES ARE a1 a2 a3 a4 a5 a6 a7 a8 a9 b1 b2 b3 b4 c1 c2 c3 c4; USEVARIABLES ARES ARE a1 a2 a3 a4 a5 a6 a7 a8 a9 b1 b2 b3 b4 c1 c2 c3 c4;当然这是最基本繁琐写法,可直接写为:VARIABLE: NAMES ARE a1-a9 b1-b4 c1-c4; USEVARIABLES ARES ARE a1-a9 b1-b4 c1-c4;不同变量间有空格。
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
.
1数据格式转换
因为Mplus只能打开ASCII格式的文件(.dat和.txt文件),所以常规的SPSS数据库的数据不能被读取,所以数据分析之前先要将sav格式另存为dat格式。
另存为选项里有两类dat格式,一般可选用“以制表符分隔”,当数据量较大时,可选“固定ASCII格式”。
这两类并没有明显特异的使用条件。
然后保存。
一般将该数据不要勾选dat选择某一种格式后,“将变量名写入表格”这一项语句文件放在一个文件夹。
mplus文件和
.
.
2 打开mplus程序,建立新文件,即点击“new”。
当然,新打开Mplus程序也会默认这个界面。
Mplus分析数据最核心的步骤3 编辑命令。
这是首先我们可以给该分析起个名字(该步骤可有可无),例如:3.1
TITLE: example
文件。
命令为:DAT3.2 然后表明我们引用的数据库来自于哪里,也就是刚刚那个.dat;
数据库DATA: FILE IS C:\Users\dell\Desktop\MPLUS结构方程模型教程\)是固定句式,是必要的。
之后FILE=IS (或者DATA: 这里面需要注意的是:DATA: FILE
文件的保存路径。
DAT.dat”这是“C:\Users\dell\Desktop\MPLUS结构方程模型教程\数据库数据DATA: FILE ISdat文件在同一个文件夹中,只需要一般情况下,如果mplus语句文件和但实际上很多情况下,两者即使在同一个文件中,也很可能读不出来,所以必要的库.dat;
DAT文件的保存路径写全,这样肯定是没错的。
话,可将该)。
;”即英文格式下的分号(除外TITLE另外,一个命令结束后,必须必须加上“数据库中spss需要的变量名称。
这需要按照写出数据库中3.3 所有的变量名称以及本次分析来写。
变量名称顺序VARIABLE: NAMES ARE a1 a2 a3 a4 a5 a6 a7 a8 a9 b1 b2 b3 b4 c1 c2 c3 c4;
USEVARIABLES ARES ARE a1 a2 a3 a4 a5 a6 a7 a8 a9 b1 b2 b3 b4 c1 c2 c3 c4;
当然这是最基本繁琐的写法,可以直接写为:VARIABLE: NAMES ARE a1-a9 b1-b4 c1-c4; USEVARIABLES ARES ARE a1-a9 b1-b4 c1-c4;
不同变量间有空格。
否则需要哪些因为我们本次分析需要纳入该数据库所有变量,所以上下两行变量是一样的,里面纳入哪些变量。
USEVARIABLES变量,在分析方法3.4
,所以中针对连续型变量的结构方程模型的默认分析方法是最小二乘法即MPLUSML 因为ANALYSIS: 如果使用的方法是这个,那么分析方法语句可以不写,当然也可以写,即ESTIMATOR = ML;
ANALYSIS: 或者= ANALYSIS: 如果采用其他方法,需要写出来,例如ESTIMATOR MLR;ESTIMATOR = WLSMV;
.
.
另外ANALYSIS中还有TYPE语句,MODEL语句,INFORMATION语句,如果没有特殊要求,我们就按照Mplus的默认方式分析就可,故不用写出来。
如果分析采用其他方式,则需要写出来。
命令举例:ANALYSIS: ESTIMATOR = ML; TYPE = GENERAL;
MODEL=NOMEANSTRUCTURE; INFORMATION=EXPECTED;
3.5模型语句
比如我们预期的结构方程模型是这样的:
,y2合并得出三个潜变量,也就是我们研究的自变量首先我们要将各个观测变量使用“BY”y3. ,和因变量中介变量y1 语句为:MODEL: y1 BY a1-a9;
y2 BY b1-b4;
y3 BY c1-c4;
”来表示各潜变量之间的回归关系,即:ON然后使用“y3 ON y1 y2;
y1 ON y2;
前面的是结局变量,后面的是预测变量。
ON 所以模型语句合并起来就是:MODEL: y1 BY a1-a9; y2 BY b1-b4;
y3 BY c1-c4;
y3 ON y1 y2;
y1 ON y2;
的默认程序都会呈现。
我们需要的结构Mplus3.6 最后一步是输出语句,如果没有特殊要求,如果有特殊要求也可以写出来,例如:OUTPUT: SAMPSTAT TECH1 TECH4 STDYX MOD;
.
.
所以将所有语句写出来就是:
TITLE: example
DATA: FILE IS C:\Users\dell\Desktop\MPLUS结构方程模型教程\数据库.dat;
VARIABLE: NAMES ARE a1 a2 a3 a4 a5 a6 a7 a8 a9 b1 b2 b3 b4 c1 c2 c3 c4;
USEVARIABLES ARES ARE a1 a2 a3 a4 a5 a6 a7 a8 a9 b1 b2 b3 b4 c1 c2 c3 c4; MODEL: y1 BY a1-a9;
y2 BY b1-b4;
y3 BY c1-c4;
y3 ON y1 y2;
y1 ON y2;
如图
按钮然后点击RUN
它会提示你保存该语句
保存完成后,结果就出来了。
.
.
View diagram
Diagram,选择如果想看我们得到的结构方程图的话,点击菜单栏的
JAVA工具。
如果电脑没有的话,会提示你安装这需要
安装完,既可以观看图示。
.
.
.。