编译原理实验二语法分析器LL(1)实现
编译原理词法分析器-ll1-lr0-python实现代码

编译原理词法分析器-ll1-lr0-python实现代码计算机科学与通信工程学院编译原理实验报告题目: 1.词法分析器2. LL(1)分析器3. LR(0)分析器班级:姓名:学号:指导老师:2017年月目录一、实验题目 (1)二、实验目的和要求 (1)三、代码实现 (2)四、总结 (25)一、实验题目1.词法分析器分析一段程序代码,将代码中的单词符号分解出来,并对其进行检查,输出token表和error表2.LL(1)文法分析器分析给定文法。
求出文法的FIRST集,FOLLOW集,并构建分析表,对给定输入串进行分析。
3.LR(0)文法分析器分析给定文法。
用Ꜫ_CLOSURE方法构造文法的LR(0)项目集规范族,根据状态转换函数GO构造出文法的DFA,并转换为分析表,对给定输入串进行分析。
二、实验目的和要求1.学会词法分析器的实现思路。
2.学会求解FIRST集, FOLLOW集,构造LL(1)分析表。
3.学会Ꜫ_CLOSURE方法,状态转换函数GO, 构造LR(0)分析表。
三、代码实现1.词法分析器program.txt 中存放要分析的文法:E->TRR->+TR|-TR|~T->FGG->*FG|/FG|~F->(E)|i代码:KEYWORD_LIST = ['while', 'if', 'else', 'switch', 'case']SEPARATOR_LIST = [';', ':', ',', '(', ')', '[', ']', '{', '}']OPERATOR_LIST1 = ['+', '-', '*']OPERATOR_LIST2 = ['<=', '<', '==', '=', '>', '>=']CATEGORY_DICT = {# KEYWORD"while": {"while": ""},"if": {"if": ""},"else": {"else": ""},"switch": {"switch": ""},"case": {"case": ""},# OPERATOR"+": {"+": ""},"-": {"-": ""},"*": {"*": ""},"<=": {"relop": "LE"},"<": {"relop": "LT"},">=": {"relop": "GE"},">": {"relop": "GT"},"==": {"relop": "EQ"},"=": {"=": ""},# SEPARATOR";": {";": ""},":": {":": ""},",": {",": ""},"(": {"(": ""},")": {")": ""},"[": {"]": ""},"]": {"]": ""},"{": {"{": ""},"}": {"}": ""},}CONSTANTTABLE = []TOKENTABLE = []OPERATORTABLE = []KEYWORDTABLE = []SEPARATORTABLE = []UNDEFINEDTABLE = []# READ FILEdef read_file(path, method):temp_str = ""try:file = open(path, method)for line in file:line = line.replace('\n', " ") temp_str += linetemp_str = str(temp_str)except IOError as e:print(e)exit()finally:file.close()return temp_str.strip() + " "# GETBEdef getbe():global tokengetchar()token = ""return# GETCHARdef getchar():global characterglobal locationwhile all_string[location] == " ":location = location + 1character = all_string[location]return character# LINK TOKENdef concatenation():global tokenglobal charactertoken = token + character# IS NUMBERdef digit():if '0' <= character <= '9':return Truereturn False# IS ALPHABETdef letter():if 'A' <= character <= 'Z' or 'a' <= character <= 'z': return Truereturn False# IS IDENTIFIERdef reserve():if token in KEYWORD_LIST:return CATEGORY_DICT[token]else:return 0# RETRACTdef retract():global locationglobal character# location = location - 1character = ""return# MAIN FUNCTIONdef main():global tokenglobal characters = getchar()getbe()if 'a' <= s <= 'z' or 'A' <= s <= 'Z':while letter() or digit():concatenation()location = location + 1character = all_string[location]retract()c = reserve()if c == 0:TOKENTABLE.append(token)print("这是标识符:{'", token, "':'", TOKENTABLE.index(token), "'}") else:KEYWORDTABLE.append(token)print("这是保留字:", CATEGORY_DICT[token])elif '0' <= s <= '9':while digit():concatenation()location = location + 1character = all_string[location]retract()CONSTANTTABLE.append(token)print("这是常数:{'", token, "':'", CONSTANTTABLE.index(token), "'}") elif s in OPERATOR_LIST1:location = location + 1OPERATORTABLE.append(s)print("这是单操作符:", CATEGORY_DICT[s])elif s in OPERATOR_LIST2:location = location + 1character = all_string[location]if character == '=':OPERATORTABLE.append(s + character)print("这是双操作符:", CATEGORY_DICT[s + character])else:retract()location = location + 1OPERATORTABLE.append(s)print("这是单操作符:", CATEGORY_DICT[s])elif s in SEPARATOR_LIST:location = location + 1SEPARATORTABLE.append(s)print("这是分隔符:", CATEGORY_DICT[s])else:UNDEFINEDTABLE.append(s)print("error:undefined identity :'", s, "'")if __name__ == '__main__':character = ""token = ""all_string = read_file("program.txt", "r")location = 0while location + 1 < len(all_string):main()print('KEYWORDTABLE:', KEYWORDTABLE)print('TOKENTABLE:', TOKENTABLE)print('CONSTANTTABLE:', CONSTANTTABLE)print('OPERATORTABLE:', OPERATORTABLE)print('SEPARATORTABLE:', SEPARATORTABLE)运行结果:2.LL(1)分析器program.txt 中存放要分析的文法:E->TRR->+TR|-TR|~T->FGG->*FG|/FG|~F->(E)|i输入串:i+i*i代码:NonTermSet = set() # 非终结符集合TermSet = set() # 终结符集合First = {} # First集Follow = {} # Follow集GramaDict = {} # 处理过的产生式Code = [] # 读入的产生式AnalysisList = {} # 分析表StartSym = "" # 开始符号EndSym = '#' # 结束符号为“#“Epsilon = "~" # 由于没有epsilon符号用“~”代替# 构造First集def getFirst():global NonTermSet, TermSet, First, Follow, FirstAfor X in NonTermSet:First[X] = set() # 初始化非终结符First集为空for X in TermSet:First[X] = set(X) # 初始化终结符First集为自己Change = Truewhile Change: # 当First集没有更新则算法结束Change = Falsefor X in NonTermSet:for Y in GramaDict[X]:k = 0Continue = Truewhile Continue and k < len(Y):if not First[Y[k]] - set(Epsilon) <= First[X]: # 没有一样的就添加,并且改变标志if Epsilon not in First[Y[k]] and Y[k] in NonTermSet and k > 0: # Y1到Yi候选式都有~存在Continue = Falseelse:First[X] |= First[Y[k]] - set(Epsilon)Change = Trueif Epsilon not in First[Y[k]]:Continue = Falsek += 1if Continue: # X->~或者Y1到Yk均有~产生式First[X] |= set(Epsilon)# FirstA[Y] |= set(Epsilon)# 构造Follow集def getFollow():global NonTermSet, TermSet, First, Follow, StartSymfor A in NonTermSet:Follow[A] = set()Follow[StartSym].add(EndSym) # 将结束符号加入Follow[开始符号]中Change = Truewhile Change: # 当Follow集没有更新算法结束Change = Falsefor X in NonTermSet:for Y in GramaDict[X]:for i in range(len(Y)):if Y[i] in TermSet:continueFlag = Truefor j in range(i + 1, len(Y)): # continueif not First[Y[j]] - set(Epsilon) <= Follow[Y[i]]:Follow[Y[i]] |= First[Y[j]] - set(Epsilon) # 步骤2 FIRST(β)/~ 加入到FOLLOW(B)中。
编译原理实验报告材料LL(1)分析报告法84481

课程编译原理实验名称实验二 LL(1)分析法实验目的1.掌握LL(1)分析法的基本原理;2.掌握LL(1)分析表的构造方法;3.掌握LL(1)驱动程序的构造方法。
一.实验内容及要求根据某一文法编制调试LL(1)分析程序,以便对任意输入的符号串进行分析。
本次实验的目的主要是加深对预测分析LL(1)分析法的理解。
对下列文法,用LL(1)分析法对任意输入的符号串进行分析:(1)E->TG(2)G->+TG(3)G->ε(4)T->FS(5)S->*FS(6)S->ε(7)F->(E)(8)F->i程序输入一以#结束的符号串(包括+*()i#),如:i+i*i#。
输出过程如下:步骤分析栈剩余输入串所用产生式1 E i+i*i# E->TG... ... ... ...二.实验过程及结果代码如下:#include<iostream>#include "edge.h"using namespace std;edge::edge(){cin>>left>>right;rlen=right.length();if(NODE.find(left)>NODE.length())NODE+=left;}string edge::getlf(){return left;}string edge::getrg(){return right;}string edge::getfirst(){return first;}string edge::getfollow(){return follow;}string edge::getselect(){return select;}string edge::getro(){string str;str+=right[0];return str;}int edge::getrlen(){return right.length();}void edge::newfirst(string w){int i;for(i=0;i<w.length();i++)if(first.find(w[i])>first.length())first+=w[i];}void edge::newfollow(string w){int i;for(i=0;i<w.length();i++)if(follow.find(w[i])>follow.length()&&w[i]!='@')follow+=w[i];}void edge::newselect(string w){int i;for(i=0;i<w.length();i++)if(select.find(w[i])>select.length()&&w[i]!='@') select+=w[i];}void edge::delfirst(){int i=first.find('@');first.erase(i,1);}int SUM;string NODE,ENODE;//计算firstvoid first(edge ni,edge *n,int x){int i,j;for(j=0;j<SUM;j++){if(ni.getlf()==n[j].getlf()){if(NODE.find(n[j].getro())<NODE.length()){for(i=0;i<SUM;i++)if(n[i].getlf()==n[j].getro())first(n[i],n,x);}elsen[x].newfirst(n[j].getro());}}}//计算followvoid follow(edge ni,edge *n,int x){int i,j,k,s;string str;for(i=0;i<ni.getrlen();i++){s=NODE.find(ni.getrg()[i]);if(s<NODE.length()&&s>-1) //是非终结符if(i<ni.getrlen()-1) //不在最右for(j=0;j<SUM;j++)if(n[j].getlf().find(ni.getrg()[i])==0){if(NODE.find(ni.getrg()[i+1])<NODE.length()){for(k=0;k<SUM;k++)if(n[k].getlf().find(ni.getrg()[i+1])==0){n[j].newfollow(n[k].getfirst());if(n[k].getfirst().find("@")<n[k].getfirst().length())n[j].newfollow(ni.getfollow());}}else{str.erase();str+=ni.getrg()[i+1];n[j].newfollow(str);}}}}//计算selectvoid select(edge &ni,edge *n){int i,j;if(ENODE.find(ni.getro())<ENODE.length()){ni.newselect(ni.getro());if(ni.getro()=="@")ni.newselect(ni.getfollow());}elsefor(i=0;i<ni.getrlen();i++){for(j=0;j<SUM;j++)if(ni.getrg()[i]==n[j].getlf()[0]){ni.newselect(n[j].getfirst());if(n[j].getfirst().find('@')>n[j].getfirst().length())return;}}}//输出集合void out(string p){int i;if(p.length()==0)return;cout<<"{";for(i=0;i<p.length()-1;i++){cout<<p[i]<<",";}cout<<p[i]<<"}";}//连续输出符号void outfu(int a,string c){int i;for(i=0;i<a;i++)cout<<c;}//输出预测分析表void outgraph(edge *n,string (*yc)[50]){int i,j,k;bool flag;for(i=0;i<ENODE.length();i++){if(ENODE[i]!='@'){outfu(10," ");cout<<ENODE[i];}}outfu(10," ");cout<<"#"<<endl;int x;for(i=0;i<NODE.length();i++){outfu(4," ");cout<<NODE[i];outfu(5," ");for(k=0;k<ENODE.length();k++){flag=1;for(j=0;j<SUM;j++){if(NODE[i]==n[j].getlf()[0]){x=n[j].getselect().find(ENODE[k]);if(x<n[j].getselect().length()&&x>-1){cout<<"->"<<n[j].getrg();yc[i][k]=n[j].getrg();outfu(9-n[j].getrlen()," ");flag=0;}x=n[j].getselect().find('#');if(k==ENODE.length()-1&&x<n[j].getselect().length()&&x>-1){cout<<"->"<<n[j].getrg();yc[i][j]=n[j].getrg();}}}if(flag&&ENODE[k]!='@')outfu(11," ");}cout<<endl;}}//分析符号串int pipei(string &chuan,string &fenxi,string (*yc)[50],int &b) {char ch,a;int x,i,j,k;b++;cout<<endl<<" "<<b;if(b>9)outfu(8," ");elseoutfu(9," ");cout<<fenxi;outfu(26-chuan.length()-fenxi.length()," "); cout<<chuan;outfu(10," ");a=chuan[0];ch=fenxi[fenxi.length()-1];x=ENODE.find(ch);if(x<ENODE.length()&&x>-1){if(ch==a){fenxi.erase(fenxi.length()-1,1);chuan.erase(0,1);cout<<"'"<<a<<"'匹配";if(pipei(chuan,fenxi,yc,b))return 1;elsereturn 0;}elsereturn 0;}else{if(ch=='#'){if(ch==a){cout<<"分析成功"<<endl;return 1;}elsereturn 0;}elseif(ch=='@'){fenxi.erase(fenxi.length()-1,1);if(pipei(chuan,fenxi,yc,b))return 1;elsereturn 0;}else{i=NODE.find(ch);if(a=='#'){x=ENODE.find('@');if(x<ENODE.length()&&x>-1)j=ENODE.length()-1;elsej=ENODE.length();}elsej=ENODE.find(a);if(yc[i][j].length()){cout<<NODE[i]<<"->"<<yc[i][j];fenxi.erase(fenxi.length()-1,1);for(k=yc[i][j].length()-1;k>-1;k--)if(yc[i][j][k]!='@')fenxi+=yc[i][j][k];if(pipei(chuan,fenxi,yc,b))return 1;elsereturn 0;}elsereturn 0;}}}void main(){edge *n;string str,(*yc)[50];int i,j,k;bool flag=0;cout<<"请输入上下文无关文法的总规则数:"<<endl;cin>>SUM;cout<<"请输入具体规则(格式:左部右部,@为空):"<<endl;n=new edge[SUM];for(i=0;i<SUM;i++)for(j=0;j<n[i].getrlen();j++){str=n[i].getrg();if(NODE.find(str[j])>NODE.length()&&ENODE.find(str[j])>ENODE.length()) ENODE+=str[j];}//计算first集合for(i=0;i<SUM;i++){first(n[i],n,i);}//outfu(10,"~*~");cout<<endl;for(i=0;i<SUM;i++)if(n[i].getfirst().find("@")<n[i].getfirst().length()){if(NODE.find(n[i].getro())<NODE.length()){for(k=1;k<n[i].getrlen();k++){if(NODE.find(n[i].getrg()[k])<NODE.length()){for(j=0;j<SUM;j++){if(n[i].getrg()[k]==n[j].getlf()[0]){n[i].newfirst(n[j].getfirst());break;}}if(n[j].getfirst().find("@")>n[j].getfirst().length()){n[i].delfirst();break;}}}}}//计算follow集合for(k=0;k<SUM;k++){for(i=0;i<SUM;i++){if(n[i].getlf()==n[0].getlf())n[i].newfollow("#");follow(n[i],n,i);}for(i=0;i<SUM;i++){for(j=0;j<SUM;j++)if(n[j].getrg().find(n[i].getlf())==n[j].getrlen()-1)n[i].newfollow(n[j].getfollow());}}//计算select集合for(i=0;i<SUM;i++){select(n[i],n);}for(i=0;i<NODE.length();i++){str.erase();for(j=0;j<SUM;j++)if(n[j].getlf()[0]==NODE[i]){if(!str.length())str=n[j].getselect();else{for(k=0;k<n[j].getselect().length();k++)if(str.find(n[j].getselect()[k])<str.length()){flag=1;break;}}}}//输出cout<<endl<<"非终结符";outfu(SUM," ");cout<<"First";outfu(SUM," ");cout<<"Follow"<<endl;outfu(5+SUM,"-*-");cout<<endl;for(i=0;i<NODE.length();i++){for(j=0;j<SUM;j++)if(NODE[i]==n[j].getlf()[0]){outfu(3," ");cout<<NODE[i];outfu(SUM+4," ");out(n[j].getfirst());outfu(SUM+4-2*n[j].getfirst().length()," ");out(n[j].getfollow());cout<<endl;break;}}outfu(5+SUM,"-*-");cout<<endl<<"判定结论: ";if(flag){cout<<"该文法不是LL(1)文法!"<<endl;return;}else{cout<<"该文法是LL(1)文法!"<<endl;}//输出预测分析表cout<<endl<<"预测分析表如下:"<<endl;yc=new string[NODE.length()][50];outgraph(n,yc);string chuan,fenxi,fchuan;cout<<endl<<"请输入符号串:";cin>>chuan;fchuan=chuan;fenxi="#";fenxi+=NODE[0];i=0;cout<<endl<<"预测分析过程如下:"<<endl;cout<<"步骤";outfu(7," ");cout<<"分析栈";outfu(10," ");cout<<"剩余输入串";outfu(8," ");cout<<"推导所用产生式或匹配";if(pipei(chuan,fenxi,yc,i))cout<<endl<<"输入串"<<fchuan<<"是该文法的句子!"<<endl;elsecout<<endl<<"输入串"<<fchuan<<"不是该文法的句子!"<<endl;}截屏如下:三.实验中的问题及心得这次实验让我更加熟悉了LL(1)的工作流程以及LL(1)分析表的构造方法。
编译原理语法分析程序设计(LL(1)分析法)

编译原理语法分析程序设计(LL(1)分析法)1. 实验目的:掌握 LL(1)分析法的基本原理,掌握 LL(1)分析表的构造方法,掌握 LL(1)驱动程序的构造方法。
2.实验要求:实现 LR分析法(P147,例 4.6)或预测分析法(P121,例4.3)。
3.实验环境:一台配置为 1G 的 XP 操作系统的 PC机;Visual C++6.0.4.实验原理:编译程序的语法分析器以单词符号作为输入,分析单词符号串是否形成符合语法规则的语法单位,如表达式、赋值、循环等,最后看是否构成一个符合要求的程序,按该语言使用的语法规则分析检查每条语句是否有正确的逻辑结构,程序是最终的一个语法单位。
编译程序的语法规则可用上下文无关文法来刻画。
语法分析的方法分为两种:自上而下分析法和自下而上分析法。
自上而下就是从文法的开始符号出发,向下推导,推出句子。
而自下而上分析法采用的是移进归约法,基本思想是:用一个寄存符号的先进后出栈,把输入符号一个一个地移进栈里,当栈顶形成某个产生式的一个候选式时,即把栈顶的这一部分归约成该产生式的左邻符号。
自顶向下带递归语法分析:1、首先对所以的生成式消除左递归、提取公共左因子2、在源程序里建立一个字符串数组,将所有的生成式都存在这个数组中。
3、给每个非终结符写一个带递归的匹配函数,其中起始符的函数写在 main 函数里。
这些函数对生成式右边从左向右扫描,若是终结符直接进行匹配,匹配失败,则调用出错函数。
如果是非终结符则调用相应的非终结符函数。
4、对输入的符号串进行扫描,从起始符的生成式开始。
如果匹配成功某个非终结符生成式右边的首个终结符,则将这个生成式输出。
匹配过程中,应该出现的非终结符没有出现,则出错处理。
5.软件设计与编程:对应源程序代码:#include#include1#includeusing namespace std;struct Node1{char vn;char vt;char s[10];}MAP[20];//存储分析预测表每个位置对应的终结符,非终结符,产生式int k;//用 R 代表E”,W 代表T”,e 代表空char start=“E”;int len=8;charG[10][10]={“E->TR”,”R->+TR”,”R->e”,”T->FW”,”W->*FW”,”W ->e”,”F->(E)”,”F->i”};//存储文法中的产生式char VN[6]={“E”,”R”,”T”,”W”,”F”};//存储非终结符char VT[6]={“i”,”+”,”*”,”(“,”)”,”#”};//存储终结符charSELECT[10][10]={“(,i”,”+”,”),#”,”(,i”,”*”,”+,),#”,”(“,”i”};//存储文法中每个产生式对应的 SELECT 集charRight[10][8]={“->TR”,”->+TR”,”->e”,”->FW”,”->*FW”,”->e”,”->(E)”,”->i”};stack stak;bool compare(char *a,char *b){2int i,la=strlen(a),j,lb=strlen(b);for(i=0;i1;j--){stak.push(action[j]);}}}if(strcmp(output,”#”)!=0)return “ERROR”;}int main (){freopen(“in.txt”,”r”,stdin);char source[100];int i,j,flag,l,m;printf(“\n***为了方便编写程序,用 R 代表E”,W 代表T”,e 代表空*****\n\n”);printf(“该文法的产生式如下:\n”);for(i=0;i>source){ printf(“\n 分析结果:%s\n\n”,Analyse(source));}return 0;}6. 程序测试结果:3。
编译原理 语法分析(2)_ LL(1)分析法1
自底向上分析法
LR分析法的概念 LR分析法的概念 LR(0)项目族的构造 LR(0)项目族的构造 SLR分析法 SLR分析法 LALR分析法 LALR分析法
概述
功能:根据文法规则 文法规则, 源程序单词符号串 单词符号串中 功能:根据文法规则,从源程序单词符号串中
识别出语法成分,并进行语法检查。 识别出语法成分,并进行语法检查。
9
【例】文法G[E] 文法G[E] E→ E +T | T 消除左递归 T→ T * F | F F→(E)|i 请用自顶向下的方法分析是否字 分析表 符串i+i*i∈L(G[E])。 符串i+i*i∈L(G[E])。
E→TE’ E’→+TE’|ε T →FT’ T’→*FT’|ε F→(E)|i
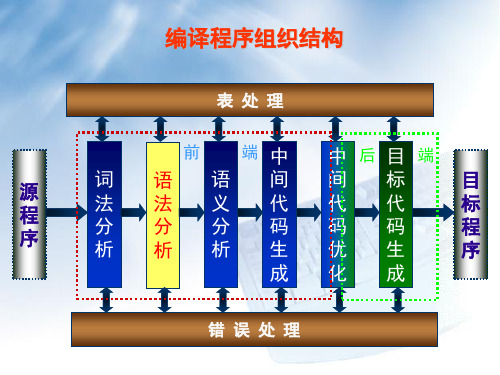
编译程序组织结构
表 处 理
前
端 中
源 程 序
词 法 分 析
语 法 分 析
语 义 分 析
间 代 码 生 成
中 后 目 端 间 标 代 代 码 码 优 生 化 成
目 标 程 序
错 误 处 理
第4章 语法分析
自顶向下分析法
递归子程序法(递归下降分析法) 递归子程序法(递归下降分析法) LL(1)分析法 LL(1)分析法
通常把按LL(1)方法完成语法分析任务的程序叫LL(1)分析程序或者LL(1)分析器。 通常把按LL(1)方法完成语法分析任务的程序叫LL(1)分析程序或者LL(1)分析器。 LL(1)方法完成语法分析任务的程序叫LL(1)分析程序或者LL(1)分析器
输入串
一、分析过程
#
此过程有三部分组成: 此过程有三部分组成: 分析表 总控程序) 执行程序 (总控程序) 分析栈) 符号栈 (分析栈)
编译原理实验二语法分析器LL(1)实现

编译原理程序设计实验报告——表达式语法分析器的设计班级:计算机1306班姓名:张涛学号:20133967实验目标:用LL(1)分析法设计实现表达式语法分析器实验内容:⑴概要设计:通过对实验一的此法分析器的程序稍加改造,使其能够输出正确的表达式的token序列。
然后利用LL(1)分析法实现语法分析。
⑵数据结构:int op=0; //当前判断进度char ch; //当前字符char nowword[10]=""; //当前单词char operate[4]={'+','-','*','/'}; //运算符char bound[2]={'(',')'}; //界符struct Token{int code;char ch[10];}; //Token定义struct Token tokenlist[50]; //Token数组struct Token tokentemp; //临时Token变量struct Stack //分析栈定义{char *base;char *top;int stacksize;};⑶分析表及流程图逆序压栈int IsLetter(char ch) //判断ch是否为字母int IsDigit(char ch) //判断ch是否为数字int Iskey(char *string) //判断是否为关键字int Isbound(char ch) //判断是否为界符int Isboundnum(char ch) //给出界符所在token值int init(STack *s) //栈初始化int pop(STack *s,char *ch) //弹栈操作int push(STack *s,char ch) //压栈操作void LL1(); //分析函数源程序代码:(加入注释)#include<stdio.h>#include<string.h>#include<ctype.h>#include<windows.h>#include <stdlib.h>int op=0; //当前判断进度char ch; //当前字符char nowword[10]=""; //当前单词char operate[4]={'+','-','*','/'}; //运算符char bound[2]={'(',')'}; //界符struct Token{int code;char ch[10];}; //Token定义struct Token tokenlist[50]; //Token数组struct Token tokentemp; //临时Token变量struct Stack //分析栈定义{char *base;char *top;int stacksize;};typedef struct Stack STack;int init(STack *s) //栈初始化{(*s).base=(char*)malloc(100*sizeof(char));if(!(*s).base)exit(0);(*s).top=(*s).base;(*s).stacksize=100;printf("初始化栈\n");return 0;}int pop(STack *s,char *ch) //弹栈操作{if((*s).top==(*s).base){printf("弹栈失败\n");return 0;(*s).top--;*ch=*((*s).top);printf("%c",*ch);return 1;}int push(STack *s,char ch) //压栈操作{if((*s).top-(*s).base>=(*s).stacksize){(*s).base=(char*)realloc((*s).base,((*s).stacksize+10)*sizeof(char));if(!(*s).base)exit(0);(*s).top=(*s).base+(*s).stacksize;(*s).stacksize+=10;}*(*s).top=ch;*(*s).top++;return 1;}void LL1();int IsLetter(char ch) //判断ch是否为字母{int i;for(i=0;i<=45;i++)if ((ch>='a'&&ch<='z')||(ch>='A'&&ch<='Z'))return 1;return 0;}int IsDigit(char ch) //判断ch是否为数字{int i;for(i=0;i<=10;i++)if (ch>='0'&&ch<='9')return 1;return 0;}int Isbound(char ch) //判断是否为界符{int i;for(i=0;i<2;i++)if(ch==bound[i]){return i+1;}}return 0;}int Isoperate(char ch) //判断是否为运算符{int i;for(i=0;i<4;i++){if(ch==operate[i]){return i+3;}}return 0;}int main(){FILE *fp;int q=0,m=0;char sour[200]=" ";printf("请将源文件置于以下位置并按以下方式命名:F:\\2.txt\n");if((fp=fopen("F:\\2.txt","r"))==NULL) {printf("文件未找到!\n");}else{while(!feof(fp)){if(isspace(ch=fgetc(fp)));else{sour[q]=ch;q++;}}}int p=0;printf("输入句子为:\n");for(p;p<=q;p++)printf("%c",sour[p]);}printf("\n");int state=0,nowlen=0;BOOLEAN OK=TRUE,ERR=FALSE;int i,flagpoint=0;for(i=0;i<q;i++){if(sour[i]=='#')tokenlist[m].code=='#';switch(state){case 0:ch=sour[i];if(Isbound(ch)){if(ERR){printf("无法识别\n");ERR=FALSE;OK=TRUE;}else if(!OK){printf("<10,%s>标识符\n",nowword);tokentemp.code=10;tokentemp.ch[10]=nowword[10];tokenlist[m]=tokentemp;m++;OK=TRUE;}state=4;}else if(IsDigit(ch)){if(OK){memset(nowword,0,strlen(nowword));nowlen=0;nowword[nowlen]=ch;nowlen++;state=3;OK=FALSE;break;}else{nowword[nowlen]=ch;nowlen++;}}else if(IsLetter(ch)){if(OK){memset(nowword,0,strlen(nowword));nowlen=0;nowword[nowlen]=ch;nowlen++;OK=FALSE;}else{nowword[nowlen]=ch;nowlen++;}}else if(Isoperate(ch)){if(!OK){printf("<10,%s>标识符\n",nowword);tokentemp.code=10;tokentemp.ch[10]=nowword[10];tokenlist[m]=tokentemp;m++;OK=TRUE;}printf("<%d,%c>运算符\n",Isoperate(ch),ch);tokentemp.code=Isoperate(ch);tokentemp.ch[10]=ch;tokenlist[m]=tokentemp;m++;}break;case 3:if(IsLetter(ch)){printf("错误\n");nowword[nowlen]=ch;nowlen++;ERR=FALSE;state=0;break;}if(IsDigit(ch=sour[i])){nowword[nowlen]=ch;nowlen++;}else if(sour[i]=='.'&&flagpoint==0){flagpoint=1;nowword[nowlen]=ch;nowlen++;}else{printf("<20,%s>数字\n",nowword);i--;state=0;OK=TRUE;tokentemp.code=20;tokentemp.ch[10]=nowword[10];tokenlist[m]=tokentemp;m++;}break;case 4:i--;printf("<%d,%c>界符\n",Isbound(ch),ch);tokentemp.code=Isbound(ch);tokentemp.ch[10]=ch;tokenlist[m]=tokentemp;m++;state=0;OK=TRUE;break;}}printf("tokenlist值为%d\n",m);int t=0;tokenlist[m+1].code='r';m++;for(t;t<m;t++){printf("tokenlist%d值为%d\n",t,tokenlist[t].code);}LL1();printf("tokenlist值为%d\n",m);if(op+1==m)printf("OK!!!");elseprintf("WRONG!!!");return 0;}void LL1(){STack s;init(&s);push(&s,'#');push(&s,'E');char ch;int flag=1;do{pop(&s,&ch);printf("输出栈顶为%c\n",ch);printf("输出栈顶为%d\n",ch);printf("当前p值为%d\n",op);if((ch=='(')||(ch==')')||(ch=='+')||(ch=='-')||(ch=='*')||(ch=='/')||(ch==10)||(ch==20)){if(tokenlist[op].code==1||tokenlist[op].code==20||tokenlist[op].code==10||tokenlist[op].code==2||tokenlist[op] .code==3||tokenlist[op].code==4||tokenlist[op].code==5||tokenlist[op].code==6)op++;else{printf("WRONG!!!");exit(0);}}else if(ch=='#'){if(tokenlist[op].code==0)flag=0;else{printf("WRONG!!!@@@@@@@@@");exit(0);}}else if(ch=='E'){printf("进入E\n");if(tokenlist[op].code==10||tokenlist[op].code==20||tokenlist[op].code==1) {push(&s,'R');printf("将R压入栈\n");push(&s,'T');}}else if(ch=='R'){printf("进入R\n");if(tokenlist[op].code==3||tokenlist[op].code==4){push(&s,'R');push(&s,'T');printf("将T压入栈\n");push(&s,'+');}if(tokenlist[op].code==2||tokenlist[op].code==0){}}else if(ch=='T'){printf("进入T\n");if(tokenlist[op].code==10||tokenlist[op].code==20||tokenlist[op].code==1) {push(&s,'Y');push(&s,'F');}}else if(ch=='Y'){printf("进入Y\n");if(tokenlist[op].code==5||tokenlist[op].code==6){push(&s,'Y');push(&s,'F');push(&s,'*');}elseif(tokenlist[op].code==3||tokenlist[op].code==2||tokenlist[op].code==0||tokenlist[op].code==4) {}}else if(ch=='F'){printf("进入F\n");if(tokenlist[op].code==10||tokenlist[op].code==20){push(&s,10);}if(tokenlist[op].code==1){push(&s,')');push(&s,'E');push(&s,'(');}}else{printf("WRONG!!!!");exit(0);}}while(flag);}程序运行结果:(截屏)输入:((Aa+Bb)*(88.2/3))#注:如需运行请将文件放置F盘,并命名为:2.txt输出:思考问题回答:LL(1)分析法的主要问题就是要正确的将文法化为LL (1)文法。
编译原理实验报告LL(1)分析法

编译原理实验报告LL(1)分析法课程编译原理实验名称实验二 LL(1)分析法实验目的1.掌握LL(1)分析法的基本原理;2.掌握LL(1)分析表的构造方法;3.掌握LL(1)驱动程序的构造方法。
一.实验内容及要求根据某一文法编制调试LL(1)分析程序,以便对任意输入的符号串进行分析。
本次实验的目的主要是加深对预测分析LL(1)分析法的理解。
对下列文法,用LL(1)分析法对任意输入的符号串进行分析:(1)E->TG(2)G->+TG(3)G->ε(4)T->FS(5)S->*FS(6)S->ε(7)F->(E)(8)F->i程序输入一以#结束的符号串(包括+*()i#),如:i+i*i#。
输出过程如下:步骤分析栈剩余输入串所用产生式1 E i+i*i# E->TG... ... ... ...二.实验过程及结果代码如下:#include#include "edge.h"using namespace std;edge::edge(){cin>>left>>right;rlen=right.length();if(NODE.find(left)>NODE.length()) NODE+=left;}string edge::getlf(){return left;}string edge::getrg(){return right;}string edge::getfirst(){return first;}string edge::getfollow(){return follow;}string edge::getselect(){return select;}string edge::getro(){string str;str+=right[0];return str;}int edge::getrlen(){return right.length();}void edge::newfirst(string w){int i;for(i=0;iif(first.find(w[i])>first.length())first+=w[i];}void edge::newfollow(string w){int i;for(i=0;iif(follow.find(w[i])>follow.length()&&w[i]!='@')follow+=w[i];}void edge::newselect(string w){int i;for(i=0;iif(select.find(w[i])>select.length()&&w[i]!='@') select+=w[i];}void edge::delfirst(){int i=first.find('@');first.erase(i,1);}int SUM;string NODE,ENODE;//计算firstvoid first(edge ni,edge *n,int x){int i,j;for(j=0;j{if(ni.getlf()==n[j].getlf()){if(NODE.find(n[j].getro()){for(i=0;iif(n[i].getlf()==n[j].getro())first(n[i],n,x);}elsen[x].newfirst(n[j].getro());}}}//计算followvoid follow(edge ni,edge *n,int x){int i,j,k,s;string str;for(i=0;i{s=NODE.find(ni.getrg()[i]);if(s-1) //是非终结符if(ifor(j=0;jif(n[j].getlf().find(ni.getrg()[i])==0) {if(NODE.find(ni.getrg()[i+1]){for(k=0;kif(n[k].getlf().find(ni.getrg()[i+1])==0) {n[j].newfollow(n[k].getfirst());if(n[k].getfirst().find("@")n[j].newfollow(ni.getfollow());}}else{str.erase();str+=ni.getrg()[i+1];n[j].newfollow(str);}}}}//计算selectvoid select(edge &ni,edge *n){int i,j;if(ENODE.find(ni.getro()){ni.newselect(ni.getro());if(ni.getro()=="@")ni.newselect(ni.getfollow());}elsefor(i=0;i{for(j=0;jif(ni.getrg()[i]==n[j].getlf()[0]){ni.newselect(n[j].getfirst());if(n[j].getfirst().find('@')>n[j].getfirst().length()) return;}}}//输出集合void out(string p){int i;if(p.length()==0)return;coutfor(i=0;i{cout}cout}//连续输出符号void outfu(int a,string c){int i;for(i=0;icout}//输出预测分析表void outgraph(edge *n,string (*yc)[50]) {int i,j,k;bool flag;for(i=0;i{if(ENODE[i]!='@'){outfu(10," ");cout}}outfu(10," ");coutint x;for(i=0;i{outfu(4," ");coutoutfu(5," ");for(k=0;k{flag=1;for(j=0;j{if(NODE[i]==n[j].getlf()[0]){x=n[j].getselect().find(ENODE[k]); if(x-1){cout"yc[i][k]=n[j].getrg();outfu(9-n[j].getrlen()," ");flag=0;}x=n[j].getselect().find('#');if(k==ENODE.length()-1&&x-1) {cout"yc[i][j]=n[j].getrg();}}}if(flag&&ENODE[k]!='@')outfu(11," ");}cout}}//分析符号串int pipei(string &chuan,string &fenxi,string (*yc)[50],int &b){char ch,a;int x,i,j,k; b++; cout9) outfu(8," "); else outfu(9," "); cout-1) { if(ch==a) { fenxi.erase(fenxi.length()-1,1); chuan.erase(0,1); coutfenxi.erase(fenxi.length()-1,1); if(pipei(chuan,fenxi,yc,b)) return 1;elsereturn 0;}else{i=NODE.find(ch);if(a=='#'){x=ENODE.find('@');if(x-1) j=ENODE.length()-1; elsej=ENODE.length();}elsej=ENODE.find(a);if(yc[i][j].length()){cout"-1;k--) if(yc[i][j][k]!='@')fenxi+=yc[i][j][k];if(pipei(chuan,fenxi,yc,b)) return 1; elsereturn 0;}elsereturn 0;}}}void main(){edge *n;string str,(*yc)[50];int i,j,k;bool flag=0;cin>>SUM; coutNODE.length()&&ENODE.find(str[j])>ENODE.length())ENODE+=str[j]; } //计算first集合 for(i=0;in[j].getfirst().length()){ n[i].delfirst(); break; } } } } }for(k=0;koutfu(SUM," "); cout>chuan; fchuan=chuan; fenxi="#"; fenxi+=NODE[0]; i=0; coutoutfu(7," ");coutoutfu(10," ");coutoutfu(8," ");coutif(pipei(chuan,fenxi,yc,i))coutelsecout}截屏如下:三.实验中的问题及心得这次实验让我更加熟悉了LL(1)的工作流程以及LL(1)分析表的构造方法。
编译原理实验二LL文法分析

实验2 LL(1)分析法一、实验目的通过完成预测分析法的语法分析程序,了解预测分析法和递归子程序法的区别和联系。
使学生了解语法分析的功能,掌握语法分析程序设计的原理和构造方法,训练学生掌握开发应用程序的基本方法。
有利于提高学生的专业素质,为培养适应社会多方面需要的能力。
二、实验要求1、编程时注意编程风格:空行的使用、注释的使用、缩进的使用等。
2、如果遇到错误的表达式,应输出错误提示信息。
3、对下列文法,用LL(1)分析法对任意输入的符号串进行分析:(1)E->TG(2)G->+TG|—TG(3)G->ε(4)T->FS(5)S->*FS|/FS(6)S->ε(7)F->(E)(8)F->i三、实验内容根据某一文法编制调试LL ( 1 )分析程序,以便对任意输入的符号串进行分析。
构造预测分析表,并利用分析表和一个栈来实现对上述程序设计语言的分析程序。
分析法的功能是利用LL(1)控制程序根据显示栈栈顶内容、向前看符号以及LL(1)分析表,对输入符号串自上而下的分析过程。
四、实验步骤1、根据流程图编写出各个模块的源程序代码上机调试。
2、编制好源程序后,设计若干用例对系统进行全面的上机测试,并通过所设计的LL(1)分析程序;直至能够得到完全满意的结果。
3、书写实验报告;实验报告正文的内容:写出LL(1)分析法的思想及写出符合LL(1)分析法的文法。
程序结构描述:函数调用格式、参数含义、返回值描述、函数功能;函数之间的调用关系图。
详细的算法描述(程序执行流程图)。
给出软件的测试方法和测试结果。
实验总结(设计的特点、不足、收获与体会)。
五、实验截图六、核心代码#include<iostream>#include<stdio.h>#include<stdlib.h>#include<string.h>#define MAX 20using namespace std;char A[MAX];char B[MAX];char v1[MAX] = { 'i','+','-','*','/','(',')','#'}; char v2[MAX] = {'E','G','T','S','F'};int j = 0, b = 0, top = 0;int l; //l是字符串长度class type{public:char origin;char array[7];int length;};type e, t, g,g0, g1, s, s0,s1, f, f1;type C[10][10];void print(){int a;for ( a = 0; a <= top + 1; a++)cout<<A[a];cout << "\t\t";}void print1(){int j;for (j = 0; j<b; j++)cout << " ";for (j = b; j <= l; j++)cout << B[j];cout << "\t\t\t";}int main(){int m, n, k = 0;int flag = 0,finish = 0;char ch, x;type cha;e.origin = 'E';strcpy(e.array, "TG");e.length = 2;t.origin = 'T';strcpy(t.array, "FS");t.length = 2;g.origin = 'G';strcpy(g.array, "+TG");g.length = 3;g0.origin = 'G';strcpy(g0.array, "-TG");g0.length = 3;g1.origin = 'G';g1.array[0] = '^';g1.length = 1;s.origin = 'S';strcpy(s.array, "*FS");s.length = 3;s0.origin = 'S';strcpy(s0.array, "/FS");s0.length = 3;s1.origin = 'S';s1.array[0] = '^';s1.length = 1;f.origin = 'F';strcpy(f.array, "(E)");f.length = 3;f1.origin = 'F';f1.array[0] = 'i';f1.length = 1;for (m = 0; m <= 4;m++)for (n = 0; n <= 7; n++)C[m][n].origin = 'N';/*C[0][0] = e; C[0][3] = e; C[1][2] = g0;C[1][1] = g; C[1][4] = g1; C[1][5] = g1;C[2][0] = t; C[2][3] = t;C[3][1] = s1; C[3][2] = s;C[3][4] = C[3][5] = s1;C[4][0] = f1; C[4][3] = f;*/C[0][0] = e; C[0][5] = e;C[1][1] = g; C[1][2] = g0;C[1][6] = g1; C[1][7] = g1;C[2][0] = t; C[2][5] = t;C[3][1] = s1; C[3][2] = s1;C[3][3] = s;C[3][4] = s0; C[3][6] = s1; C[3][7] = s1;C[4][0] = f1; C[4][5] = f;cout << "input,please~:";do{cin >> ch;if ((ch!='i') &&(ch!='+') &&(ch!='-') &&(ch!='*') &&(ch!='/') &&(ch!='(') &&(ch!=')') &&(ch!='#')){cout << "Error!\n";exit(1);}B[j] = ch;j++;} while (ch != '#');l = j; //l是字符串长度/* for(j=0;j<l;j++)cout<<B[j]<<endl;*/ch = B[0]; //当前分析字符A[top] = '#';A[++top] = 'E';/*'#','E'进栈*/cout << "步骤\t\t分析栈\t\t剩余字符\t\t所用字符\n"; do{x = A[top--];cout << k++;cout << "\t\t";for (j = 0; j<=7 ; j++)if (x == v1[j]){flag = 1;break;}if (flag==1){if (x == '#'){finish = 1;cout << "acc!\n";getchar();getchar();exit(1);}if (x == ch){print();print1();cout <<ch << "匹配\n";ch = B[++b];flag = 0;}else{cout<<"x:"<<x<<endl;cout<<"ch:"<<ch<<endl;print();print1();cout <<ch<< "出错\n" ;exit(1);}}else //非终结符{for (j = 0; j <= 4; j++)if (x == v2[j]){m = j;//行号break;}for (j = 0; j <= 7; j++)if (ch == v1[j]){n = j; //列号break;}cha = C[m][n];if (cha.origin != 'N'){print();print1();cout << cha.origin << "->";for (j = 0; j<cha.length; j++)cout << cha.array[j];cout << "\n";for (j = (cha.length - 1); j >= 0; j--)A[++top] = cha.array[j];if (A[top] == '^')/*为空则不进栈*/top--;}else{print();print1();cout<<"x:"<<x<<endl;cout<<"ch:"<<ch<<endl;cout<<"sign1"<<endl;cout << "Error!" << x;exit(1);}}} while (finish == 0);}。
编译原理实验二语法分析器LL(1)实现

编译原理程序设计实验报告——表达式语法分析器的设计班级:计算机1306班:涛学号:20133967 实验目标:用LL(1)分析法设计实现表达式语法分析器实验容:⑴概要设计:通过对实验一的此法分析器的程序稍加改造,使其能够输出正确的表达式的token序列。
然后利用LL(1)分析法实现语法分析。
⑵数据结构:int op=0; //当前判断进度char ch; //当前字符char nowword[10]=""; //当前单词char operate[4]={'+','-','*','/'}; //运算符char bound[2]={'(',')'}; //界符struct Token{int code;char ch[10];}; //Token定义struct Token tokenlist[50]; //Token数组struct Token tokentemp; //临时Token变量struct Stack //分析栈定义{char *base;char *top;int stacksize;};⑶分析表及流程图逆序压栈int IsLetter(char ch) //判断ch是否为字母int IsDigit(char ch) //判断ch是否为数字int Iskey(char *string) //判断是否为关键字int Isbound(char ch) //判断是否为界符int Isboundnum(char ch) //给出界符所在token值int init(STack *s) //栈初始化int pop(STack *s,char *ch) //弹栈操作int push(STack *s,char ch) //压栈操作void LL1(); //分析函数源程序代码:(加入注释)#include<stdio.h>#include<string.h>#include<ctype.h>#include<windows.h>#include <stdlib.h>int op=0; //当前判断进度char ch; //当前字符char nowword[10]=""; //当前单词char operate[4]={'+','-','*','/'}; //运算符char bound[2]={'(',')'}; //界符struct Token{int code;char ch[10];}; //Token定义struct Token tokenlist[50]; //Token数组struct Token tokentemp; //临时Token变量struct Stack //分析栈定义{char *base;char *top;int stacksize;};typedef struct Stack STack;int init(STack *s) //栈初始化{(*s).base=(char*)malloc(100*sizeof(char)); if(!(*s).base)exit(0);(*s).top=(*s).base;(*s).stacksize=100;printf("初始化栈\n");return 0;}int pop(STack *s,char *ch) //弹栈操作{if((*s).top==(*s).base){printf("弹栈失败\n");return 0;(*s).top--;*ch=*((*s).top);printf("%c",*ch);return 1;}int push(STack *s,char ch) //压栈操作{if((*s).top-(*s).base>=(*s).stacksize){(*s).base=(char*)realloc((*s).base,((*s).stacksize+10)*sizeof(char)); if(!(*s).base)exit(0);(*s).top=(*s).base+(*s).stacksize;(*s).stacksize+=10;}*(*s).top=ch;*(*s).top++;return 1;}void LL1();int IsLetter(char ch) //判断ch是否为字母{int i;for(i=0;i<=45;i++)if ((ch>='a'&&ch<='z')||(ch>='A'&&ch<='Z'))return 1;return 0;}int IsDigit(char ch) //判断ch是否为数字{int i;for(i=0;i<=10;i++)if (ch>='0'&&ch<='9')return 1;return 0;}int Isbound(char ch) //判断是否为界符{int i;for(i=0;i<2;i++)if(ch==bound[i]){return i+1;}}return 0;}int Isoperate(char ch) //判断是否为运算符{int i;for(i=0;i<4;i++){if(ch==operate[i]){return i+3;}}return 0;}int main(){FILE *fp;int q=0,m=0;char sour[200]=" ";printf("请将源文件置于以下位置并按以下方式命名:F:\\2.txt\n");if((fp=fopen("F:\\2.txt","r"))==NULL){printf("文件未找到!\n");}else{while(!feof(fp)){if(isspace(ch=fgetc(fp)));else{sour[q]=ch;q++;}}}int p=0;printf("输入句子为:\n");for(p;p<=q;p++)printf("%c",sour[p]);}printf("\n");int state=0,nowlen=0;BOOLEAN OK=TRUE,ERR=FALSE;int i,flagpoint=0;for(i=0;i<q;i++){if(sour[i]=='#')tokenlist[m].code=='#';switch(state){case 0:ch=sour[i];if(Isbound(ch)){if(ERR){printf("无法识别\n");ERR=FALSE;OK=TRUE;}else if(!OK){printf("<10,%s>标识符\n",nowword); tokentemp.code=10;tokentemp.ch[10]=nowword[10];tokenlist[m]=tokentemp;m++;OK=TRUE;}state=4;}else if(IsDigit(ch)){if(OK){memset(nowword,0,strlen(nowword)); nowlen=0;nowword[nowlen]=ch;nowlen++;state=3;OK=FALSE;break;}else{nowword[nowlen]=ch;nowlen++;}}else if(IsLetter(ch)){if(OK){memset(nowword,0,strlen(nowword));nowlen=0;nowword[nowlen]=ch;nowlen++;OK=FALSE;}else{nowword[nowlen]=ch;nowlen++;}}else if(Isoperate(ch)){if(!OK){printf("<10,%s>标识符\n",nowword);tokentemp.code=10;tokentemp.ch[10]=nowword[10];tokenlist[m]=tokentemp;m++;OK=TRUE;}printf("<%d,%c>运算符\n",Isoperate(ch),ch); tokentemp.code=Isoperate(ch);tokentemp.ch[10]=ch;tokenlist[m]=tokentemp;m++;}break;case 3:if(IsLetter(ch)){printf("错误\n");nowword[nowlen]=ch;nowlen++;ERR=FALSE;state=0;break;}if(IsDigit(ch=sour[i])){nowword[nowlen]=ch;nowlen++;}else if(sour[i]=='.'&&flagpoint==0){flagpoint=1;nowword[nowlen]=ch;nowlen++;}else{printf("<20,%s>数字\n",nowword);i--;state=0;OK=TRUE;tokentemp.code=20;tokentemp.ch[10]=nowword[10];tokenlist[m]=tokentemp;m++;}break;case 4:i--;printf("<%d,%c>界符\n",Isbound(ch),ch); tokentemp.code=Isbound(ch);tokentemp.ch[10]=ch;tokenlist[m]=tokentemp;m++;state=0;OK=TRUE;break;}}printf("tokenlist值为%d\n",m);int t=0;tokenlist[m+1].code='r';m++;for(t;t<m;t++){printf("tokenlist%d值为%d\n",t,tokenlist[t].code);}LL1();printf("tokenlist值为%d\n",m);if(op+1==m)printf("OK!!!");elseprintf("WRONG!!!");return 0;}void LL1(){STack s;init(&s);push(&s,'#');push(&s,'E');char ch;int flag=1;do{pop(&s,&ch);printf("输出栈顶为%c\n",ch);printf("输出栈顶为%d\n",ch);printf("当前p值为%d\n",op);if((ch=='(')||(ch==')')||(ch=='+')||(ch=='-')||(ch=='*')||(ch=='/')||(ch==10)||(ch==20)) {if(tokenlist[op].code==1||tokenlist[op].code==20||tokenlist[op].code==10||tokenlist[op].cod e==2||tokenlist[op].code==3||tokenlist[op].code==4||tokenlist[op].code==5||tokenlist[op].co de==6)op++;else{printf("WRONG!!!");exit(0);}}else if(ch=='#'){if(tokenlist[op].code==0)flag=0;else{printf("WRONG!!!");exit(0);}}else if(ch=='E'){printf("进入E\n");if(tokenlist[op].code==10||tokenlist[op].code==20||tokenlist[op].code==1) {push(&s,'R');printf("将R压入栈\n");push(&s,'T');}}else if(ch=='R'){printf("进入R\n");if(tokenlist[op].code==3||tokenlist[op].code==4){push(&s,'R');push(&s,'T');printf("将T压入栈\n");push(&s,'+');}if(tokenlist[op].code==2||tokenlist[op].code==0){}}else if(ch=='T'){printf("进入T\n");if(tokenlist[op].code==10||tokenlist[op].code==20||tokenlist[op].code==1) {push(&s,'Y');push(&s,'F');}}else if(ch=='Y'){printf("进入Y\n");if(tokenlist[op].code==5||tokenlist[op].code==6){push(&s,'Y');push(&s,'F');push(&s,'*');}elseif(tokenlist[op].code==3||tokenlist[op].code==2||tokenlist[op].code==0||tokenlist[op].code= =4){}}else if(ch=='F'){printf("进入F\n");if(tokenlist[op].code==10||tokenlist[op].code==20){push(&s,10);}if(tokenlist[op].code==1){push(&s,')');push(&s,'E');push(&s,'(');}}else{printf("WRONG!!!!");exit(0);}}while(flag);}程序运行结果:(截屏)输入:((Aa+Bb)*(88.2/3))#注:如需运行请将文件放置F盘,并命名为:2.txt输出:思考问题回答:LL(1)分析法的主要问题就是要正确的将文法化为LL (1)文法。
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
编译原理程序设计实验报告——表达式语法分析器的设计班级:计算机1306班姓名:张涛学号:20133967 实验目标:用LL(1)分析法设计实现表达式语法分析器实验内容:⑴概要设计:通过对实验一的此法分析器的程序稍加改造,使其能够输出正确的表达式的token序列。
然后利用LL(1)分析法实现语法分析。
⑵数据结构:int op=0; //当前判断进度char ch; //当前字符char nowword[10]=""; //当前单词char operate[4]={'+','-','*','/'}; //运算符char bound[2]={'(',')'}; //界符struct Token{int code;char ch[10];}; //Token定义struct Token tokenlist[50]; //Token数组struct Token tokentemp; //临时Token变量struct Stack //分析栈定义{char *base;char *top;int stacksize;};⑶分析表及流程图Begin PUSH(#),PUSH(E)POP(x)x ∈VT x ∈VNx=wend W=#ny NEXT(w)ynerr查LL (1)分析表空?n PUSH (i )err ny逆序压栈⑷关键函数:int IsLetter(char ch) //判断ch 是否为字母int IsDigit(char ch) //判断ch 是否为数字int Iskey(char *string) //判断是否为关键字int Isbound(char ch) //判断是否为界符int Isboundnum(char ch) //给出界符所在token 值int init(STack *s) //栈初始化int pop(STack *s,char *ch) //弹栈操作int push(STack *s,char ch) //压栈操作void LL1(); //分析函数源程序代码:(加入注释)#include<stdio.h>#include<string.h>#include<ctype.h>#include<windows.h>#include <stdlib.h>int op=0; //当前判断进度char ch; //当前字符char nowword[10]=""; //当前单词char operate[4]={'+','-','*','/'}; //运算符char bound[2]={'(',')'}; //界符struct Token{int code;char ch[10];}; //Token定义struct Token tokenlist[50]; //Token数组struct Token tokentemp; //临时Token变量struct Stack //分析栈定义{char *base;char *top;int stacksize;};typedef struct Stack STack;int init(STack *s) //栈初始化{(*s).base=(char*)malloc(100*sizeof(char));if(!(*s).base)exit(0);(*s).top=(*s).base;(*s).stacksize=100;printf("初始化栈\n");return 0;}int pop(STack *s,char *ch) //弹栈操作{if((*s).top==(*s).base){printf("弹栈失败\n");return 0;(*s).top--;*ch=*((*s).top);printf("%c",*ch);return 1;}int push(STack *s,char ch) //压栈操作{if((*s).top-(*s).base>=(*s).stacksize){(*s).base=(char*)realloc((*s).base,((*s).stacksize+10)*sizeof(char));if(!(*s).base)exit(0);(*s).top=(*s).base+(*s).stacksize;(*s).stacksize+=10;}*(*s).top=ch;*(*s).top++;return 1;}void LL1();int IsLetter(char ch) //判断ch是否为字母{int i;for(i=0;i<=45;i++)if ((ch>='a'&&ch<='z')||(ch>='A'&&ch<='Z'))return 1;return 0;}int IsDigit(char ch) //判断ch是否为数字{int i;for(i=0;i<=10;i++)if (ch>='0'&&ch<='9')return 1;return 0;}int Isbound(char ch) //判断是否为界符{int i;for(i=0;i<2;i++)if(ch==bound[i]){return i+1;}}return 0;}int Isoperate(char ch) //判断是否为运算符{int i;for(i=0;i<4;i++){if(ch==operate[i]){return i+3;}}return 0;}int main(){FILE *fp;int q=0,m=0;char sour[200]=" ";printf("请将源文件置于以下位置并按以下方式命名:F:\\2.txt\n");if((fp=fopen("F:\\2.txt","r"))==NULL) {printf("文件未找到!\n");}else{while(!feof(fp)){if(isspace(ch=fgetc(fp)));else{sour[q]=ch;q++;}}}int p=0;printf("输入句子为:\n");for(p;p<=q;p++)printf("%c",sour[p]);}printf("\n");int state=0,nowlen=0;BOOLEAN OK=TRUE,ERR=FALSE;int i,flagpoint=0;for(i=0;i<q;i++){if(sour[i]=='#')tokenlist[m].code=='#';switch(state){case 0:ch=sour[i];if(Isbound(ch)){if(ERR){printf("无法识别\n");ERR=FALSE;OK=TRUE;}else if(!OK){printf("<10,%s>标识符\n",nowword);tokentemp.code=10;tokentemp.ch[10]=nowword[10];tokenlist[m]=tokentemp;m++;OK=TRUE;}state=4;}else if(IsDigit(ch)){if(OK){memset(nowword,0,strlen(nowword));nowlen=0;nowword[nowlen]=ch;nowlen++;state=3;OK=FALSE;break;}else{nowword[nowlen]=ch;nowlen++;}}else if(IsLetter(ch)){if(OK){memset(nowword,0,strlen(nowword));nowlen=0;nowword[nowlen]=ch;nowlen++;OK=FALSE;}else{nowword[nowlen]=ch;nowlen++;}}else if(Isoperate(ch)){if(!OK){printf("<10,%s>标识符\n",nowword);tokentemp.code=10;tokentemp.ch[10]=nowword[10];tokenlist[m]=tokentemp;m++;OK=TRUE;}printf("<%d,%c>运算符\n",Isoperate(ch),ch);tokentemp.code=Isoperate(ch);tokentemp.ch[10]=ch;tokenlist[m]=tokentemp;m++;}break;case 3:if(IsLetter(ch)){printf("错误\n");nowword[nowlen]=ch;nowlen++;ERR=FALSE;state=0;break;}if(IsDigit(ch=sour[i])){nowword[nowlen]=ch;nowlen++;}else if(sour[i]=='.'&&flagpoint==0){flagpoint=1;nowword[nowlen]=ch;nowlen++;}else{printf("<20,%s>数字\n",nowword);i--;state=0;OK=TRUE;tokentemp.code=20;tokentemp.ch[10]=nowword[10];tokenlist[m]=tokentemp;m++;}break;case 4:i--;printf("<%d,%c>界符\n",Isbound(ch),ch);tokentemp.code=Isbound(ch);tokentemp.ch[10]=ch;tokenlist[m]=tokentemp;m++;state=0;OK=TRUE;break;}}printf("tokenlist值为%d\n",m);int t=0;tokenlist[m+1].code='r';m++;for(t;t<m;t++){printf("tokenlist%d值为%d\n",t,tokenlist[t].code);}LL1();printf("tokenlist值为%d\n",m);if(op+1==m)printf("OK!!!");elseprintf("WRONG!!!");return 0;}void LL1(){STack s;init(&s);push(&s,'#');push(&s,'E');char ch;int flag=1;do{pop(&s,&ch);printf("输出栈顶为%c\n",ch);printf("输出栈顶为%d\n",ch);printf("当前p值为%d\n",op);if((ch=='(')||(ch==')')||(ch=='+')||(ch=='-')||(ch=='*')||(ch=='/')||(ch==10)||(ch==20)){if(tokenlist[op].code==1||tokenlist[op].code==20||tokenlist[op].code==10||tokenlist[op].code==2||tokenlist[op] .code==3||tokenlist[op].code==4||tokenlist[op].code==5||tokenlist[op].code==6)op++;else{printf("WRONG!!!");exit(0);}}else if(ch=='#'){if(tokenlist[op].code==0)flag=0;else{printf("WRONG!!!@@@@@@@@@");exit(0);}}else if(ch=='E'){printf("进入E\n");if(tokenlist[op].code==10||tokenlist[op].code==20||tokenlist[op].code==1) {push(&s,'R');printf("将R压入栈\n");push(&s,'T');}}else if(ch=='R'){printf("进入R\n");if(tokenlist[op].code==3||tokenlist[op].code==4){push(&s,'R');push(&s,'T');printf("将T压入栈\n");push(&s,'+');}if(tokenlist[op].code==2||tokenlist[op].code==0){}}else if(ch=='T'){printf("进入T\n");if(tokenlist[op].code==10||tokenlist[op].code==20||tokenlist[op].code==1) {push(&s,'Y');push(&s,'F');}}else if(ch=='Y'){printf("进入Y\n");if(tokenlist[op].code==5||tokenlist[op].code==6){push(&s,'Y');push(&s,'F');push(&s,'*');}elseif(tokenlist[op].code==3||tokenlist[op].code==2||tokenlist[op].code==0||tokenlist[op].code==4) {}}else if(ch=='F'){printf("进入F\n");if(tokenlist[op].code==10||tokenlist[op].code==20){push(&s,10);}if(tokenlist[op].code==1){push(&s,')');push(&s,'E');push(&s,'(');}}else{printf("WRONG!!!!");exit(0);}}while(flag);}程序运行结果:(截屏)输入:((Aa+Bb)*(88.2/3))#注:如需运行请将文件放置F盘,并命名为:2.txt输出:思考问题回答:LL(1)分析法的主要问题就是要正确的将文法化为LL(1)文法。