Fisher线性判别分析实验(模式识别与人工智能原理实验1)
机器学习实验1-Fisher线性分类器设计

一、实验意义及目的掌握Fisher分类原理,能够利用Matlab编程实现Fisher线性分类器设计,熟悉基于Matlab算法处理函数,并能够利用算法解决简单问题。
二、算法原理Fisher准则基本原理:找到一个最合适的投影周,使两类样本在该轴上投影之间的距离尽可能远,而每一类样本的投影尽可能紧凑,从而使分类效果为最佳。
内容:(1)尝试编写matlab程序,用Fisher线性判别方法对三维数据求最优方向w的通用函数(2)对下面表1-1样本数据中的类别w1和w2计算最优方向w(3)画出最优方向w 的直线,并标记出投影后的点在直线上的位置(4)选择决策边界,实现新样本xx1=(-0.7,0.58,0.089),xx2=(0.047,-0.4,1.04)的分类三、实验内容(1)尝试编写matlab程序,用Fisher线性判别方法对三维数据求最优方向w的通用函数程序清单:clcclear all%10*3样本数据w1=[-0.4,0.58,0.089;-0.31,0.27,-0.04;-0.38,0.055,-0.035;-0.15,0.53,0.011;-0.35,.47,0.034;0.17,0.69,0.1;-0.011,0.55,-0.18;-0.27,0.61,0.12;-0.065,0.49,0.0012;-0.12,0.054,-0.063];w2=[0.83,1.6,-0.014;1.1,1.6,0.48;-0.44,-0.41,0.32;0.047,-0.45,1.4;0.28,0.35,3.1;-0.39,-0.48,0.11;0.34,-0.079,0.14;-0.3,-0.22,2.2;1.1,1.2,-0.46;0.18,-0.11,-0.49];W1=w1';%转置下方便后面求s1W2=w2';m1=mean(w1);%对w1每一列取平均值结果为1*3矩阵m2=mean(w2);%对w1每一列取平均值结果为1*3矩阵S1=zeros(3);%有三个特征所以大小为3S2=zeros(3);for i=1:10%1到样本数量ns1=(W1(:,i)-m1)*(W1(:,i)-m1)';s2=(W2(:,i)-m2)*(W2(:,i)-m2)';S1=S1+s1;S2=S2+s2;endsw=S1+S2;w_new=transpose(inv(sw)*(m1'-m2'));%这里m1m2是行要转置下3*3 X 3*1 =3*1 这里提前转置了下跟老师ppt解法公式其实一样%绘制拟合结果数据画图用y1=w_new*W1y2=w_new*W2;m1_new=w_new*m1';%求各样本均值也就是上面y1的均值m2_new=w_new*m2';w0=(m1_new+m2_new)/2%取阈值%分类判断x=[-0.7 0.0470.58 -0.40.089 1.04 ];m=0; n=0;result1=[]; result2=[];for i=1:2%对待观测数据进行投影计算y(i)=w_new*x(:,i);if y(i)>w0m=m+1;result1(:,m)=x(:,i);elsen=n+1;result2(:,n)=x(:,i);endend%结果显示display('属于第一类的点')result1display('属于第二类的点')result2figure(1)scatter3(w1(1,:),w1(2,:),w1(3,:),'+r'),hold onscatter3(w2(1,:),w2(2,:),w2(3,:),'sg'),hold onscatter3(result1(1,:),result1(2,:),result1(3,:),'k'),hold onscatter3(result2(1,:),result2(2,:),result2(3,:),'bd')title('样本点及实验点的空间分布图')legend('样本点w1','样本点w2','属于第一类的实验点','属于第二类的实验点')figure(2)title('样本拟合结果')scatter3(y1*w_new(1),y1*w_new(2),y1*w_new(3),'b'),hold onscatter3(y2*w_new(1),y2*w_new(2),y2*w_new(3),'sr')(2)对下面表1-1样本数据中的类别w1和w2计算最优方向w(3)画出最优方向w 的直线,并标记出投影后的点在直线上的位置最优方向w 的直线投影后的位置(4)选择决策边界,实现新样本xx1=(-0.7,0.58,0.089),xx2=(0.047,-0.4,1.04)的分类决策边界取法:分类结果:四、实验感想通过这次实验,我学会了fisher线性判别相关的分类方法,对数据分类有了初步的认识,尽管在过程中有不少中间量不会算,通过查阅网络知识以及模式识别专业课ppt等课件帮助,我最终完成了实验,为今后继续深入学习打下良好基础。
模式识别上机实验报告

实验一、二维随机数的产生1、实验目的(1) 学习采用Matlab 程序产生正态分布的二维随机数 (2) 掌握估计类均值向量和协方差矩阵的方法(3) 掌握类间离散度矩阵、类内离散度矩阵的计算方法(4) 熟悉matlab 中运用mvnrnd 函数产生二维随机数等matlab 语言2、实验原理多元正态分布概率密度函数:11()()2/21/21()(2)||T X X d p X eμμπ---∑-=∑其中:μ是d 维均值向量:Td E X μμμμ=={}[,,...,]12Σ是d ×d 维协方差矩阵:TE X X μμ∑=--[()()](1)估计类均值向量和协方差矩阵的估计 各类均值向量1ii X im X N ω∈=∑ 各类协方差矩阵1()()iTi iiX iX X N ωμμ∈∑=--∑(2)类间离散度矩阵、类内离散度矩阵的计算类内离散度矩阵:()()iTi iiX S X m X m ω∈=--∑, i=1,2总的类内离散度矩阵:12W S S S =+类间离散度矩阵:1212()()Tb S m m m m =--3、实验内容及要求产生两类均值向量、协方差矩阵如下的样本数据,每类样本各50个。
1[2,2]μ=--,11001⎡⎤∑=⎢⎥⎣⎦,2[2,2]μ=,21004⎡⎤∑=⎢⎥⎣⎦ (1)画出样本的分布图;(2) 编写程序,估计类均值向量和协方差矩阵;(3) 编写程序,计算类间离散度矩阵、类内离散度矩阵; (4)每类样本数增加到500个,重复(1)-(3)4、实验结果(1)、样本的分布图(2)、类均值向量、类协方差矩阵根据matlab 程序得出的类均值向量为:N=50 : m1=[-1.7160 -2.0374] m2=[2.1485 1.7678] N=500: m1=[-2.0379 -2.0352] m2=[2.0428 2.1270] 根据matlab 程序得出的类协方差矩阵为:N=50: ]0628.11354.01354.06428.1[1=∑ ∑--2]5687.40624.00624.08800.0[N=500:∑--1]0344.10162.00162.09187.0[∑2]9038.30211.00211.09939.0[(3)、类间离散度矩阵、类内离散度矩阵根据matlab 程序得出的类间离散度矩阵为:N=50: ]4828.147068.147068.149343.14[=bS N=500: ]3233.179843.169843.166519.16[b =S根据matlab 程序得出的类内离散度矩阵为:N=50:]0703.533088.73088.71052.78[1=S ]7397.2253966.13966.18975.42[2--=S ]8100.2789123.59123.50026.121[=W SN=500: ]5964.5167490.87490.86203.458[1--=S ]8.19438420.78420.70178.496[2=S ]4.24609071.09071.06381.954[--=W S5、结论由mvnrnd 函数产生的结果是一个N*D 的一个矩阵,在本实验中D 是2,N 是50和500.根据实验数据可以看出,当样本容量变多的时候,两个变量的总体误差变小,观测变量各个取值之间的差异程度减小。
模式识别FISHER线性判别实验

模式识别FISHER线性判别实验
人工知能领域中的模式识别是计算机实现人类识别物体的能力的一种
技术。
它的主要目的是根据给定模式的样本及其特征,自动识别出新的样
本的特征并做出判断。
其中最著名的技术之一就是FISHER线性判别法。
FISHER线性判别法基于正态分布理论,通过计算样本的统计特征来
分类,它是一种基于参数的最优分类算法。
算法的基本思想是通过计算两
个类别的最大类间差异度,以及最小类内差异度,来有效地分类样本。
具
体而言,FISHER线性判别法即求出一个线性超平面,使这个超平面把样
本区分开来,使样本离类中心向量之间的距离最大,同时使类中心向量之
间的距离最小。
FISHER线性判别法的具体实现过程如下:
1.准备好建立模型所需要的所有数据:训练样本集,其样本特征与对
应的类标号。
2.确定每个类的类中心向量c_1,c_2,…,c_m,其中m为类的数目。
3.根据类中心向量求出类间离散度矩阵S_b和类内离散度矩阵S_w。
4.将S_b与S_w相除,得到S_b/S_w,从而求出矩阵的最大特征值
λ_1及最小特征值λ_n。
5.将最大特征值λ_1进行特征值分解,求出其特征向量w,求出判
定函数:
f(x)=w·x+w_0。
6.根据判定函数,将样本进行分类。
《模式识别》线性分类器设计实验报告
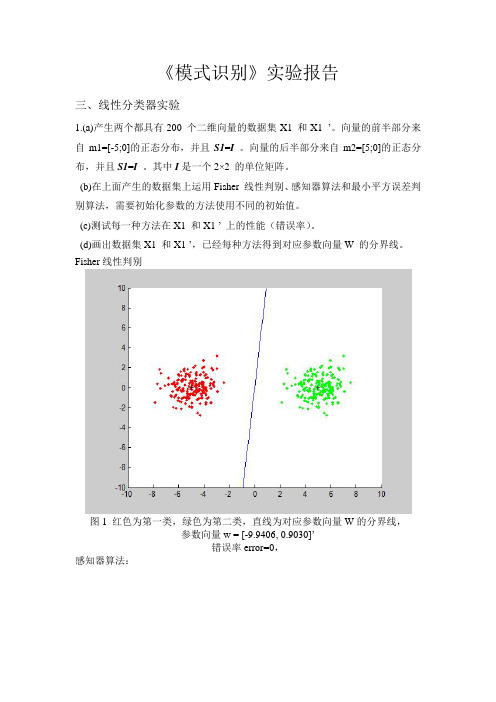
《模式识别》实验报告三、线性分类器实验1.(a)产生两个都具有200 个二维向量的数据集X1 和X1 ’。
向量的前半部分来自m1=[-5;0]的正态分布,并且S1=I 。
向量的后半部分来自m2=[5;0]的正态分布,并且S1=I。
其中I是一个2×2 的单位矩阵。
(b)在上面产生的数据集上运用Fisher 线性判别、感知器算法和最小平方误差判别算法,需要初始化参数的方法使用不同的初始值。
(c)测试每一种方法在X1 和X1 ’ 上的性能(错误率)。
(d)画出数据集X1 和X1 ’,已经每种方法得到对应参数向量W 的分界线。
Fisher线性判别图1 红色为第一类,绿色为第二类,直线为对应参数向量W的分界线,参数向量w = [-9.9406, 0.9030]’错误率error=0,感知器算法:图2 红色为第一类,绿色为第二类,直线为对应参数向量W的分界线,参数的初始值为[0.1;0.1];迭代次数iter=2参数向量w = [-4.8925, 0.0920]’错误率error=0图3 红色为第一类,绿色为第二类,直线为对应参数向量W的分界线,参数的初始值为[1; 1];迭代次数iter=2参数向量w = [-3.9925, 0.9920]’错误率error=0图4 红色为第一类,绿色为第二类,直线为对应参数向量W的分界线,参数的初始值为[10; 10];迭代次数iter=122参数向量w = [-5.6569, 7.8096]’错误率error=0图5 红色为第一类,绿色为第二类,直线为对应参数向量W的分界线,参数的初始值为[50; 50];迭代次数iter=600参数向量w = [-27.0945, 37.4194]’错误率error=0图6 红色为第一类,绿色为第二类,直线为对应参数向量W的分界线,参数的初始值为[50; 100];迭代次数iter=1190参数向量w = [-54.0048, 74.5875]’错误率error=0最小平方误差判别算法:图7 红色为第一类,绿色为第二类,直线为对应参数向量W的分界线,参数的初始值为[0.1; 0.1];参数向量w = [-0.1908, -0.0001]’错误率error=0图8 红色为第一类,绿色为第二类,直线为对应参数向量W的分界线,参数的初始值为[0.5; 0.5];参数向量w = [-0.1924, 0.1492]’错误率error=0图9 红色为第一类,绿色为第二类,直线为对应参数向量W的分界线,参数的初始值为[1; 0.5];参数向量w = [-0.1914, 0.0564]’错误率error=0图10 红色为第一类,绿色为第二类,直线为对应参数向量W的分界线,参数的初始值为[1; 1];参数向量w = [-0.1943, 0.3359]’错误率error= 0.00502.重复1.中的实验内容,数据集为X2 和X2 ’。
Fisher线性判别原理(实例论证解析)

Fisher 线性判别原理原始数据:111212122212p p n n np n px x x x x x X x x x ⨯⎡⎤⎢⎥⎢⎥=⎢⎥⎢⎥⎢⎥⎣⎦ 寻找关于X 的线性组合,使得Y Xa =,其中121p p a a a a ⨯⎡⎤⎢⎥⎢⎥=⎢⎥⎢⎥⎢⎥⎣⎦为p 维列向量。
使得111212111212222211221p p p p n n p np n n a x a x a x y a x a x a x y Y Xa a x a x a x y ⨯+++⎡⎤⎡⎤⎢⎥⎢⎥+++⎢⎥⎢⎥==⎢⎥⎢⎥⎢⎥⎢⎥+++⎢⎥⎣⎦⎣⎦对于Y 中的每个分量来说,离差平方和为:22211()nniii i y y yny ==-=-∑∑令11111n n n H I n⨯⨯'=-,则有:[][][][]121212121212100101011(111)0011111111111111n n n n n n y y Y HY y y y n y n n n y y y y y n nn y nn n y y y y y y y y y ⎡⎤⎡⎤⎡⎤⎢⎥⎢⎥⎢⎥⎢⎥⎢⎥⎢⎥'=-⎢⎥⎢⎥⎢⎥⎢⎥⎢⎥⎢⎥⎣⎦⎣⎦⎣⎦⎡⎤---⎢⎥⎡⎤⎢⎥⎢⎥⎢⎥---⎢⎥⎢⎥=⎢⎥⎢⎥⎢⎥⎢⎥⎣⎦⎢⎥---⎢⎥⎣⎦⎡⎤⎢⎥⎢⎥=---⎢⎥⎢⎣⎦22211()n nii i i y ny y y ==⎥=-=-∑∑而21()()nii y y Y HY Xa HXa a X HXa a Ta ='''''-====∑若n 个原始数据X 来自J 个不同的组,每个组有j n 个数据,12++J n n n n +=。
将X ,Y 重新标记为:111(1)(1)(1)11121(1)(1)(1)21222(1)(1)(1)12()()()11121()()()21222()()()12J J J pp n n n p J J J p J J J p J J J n n n p n p x x x x x x x x x X x x x x x x x x x ⨯⎡⎤⎢⎥⎢⎥⎢⎥⎢⎥⎢⎥⎢⎥=⎢⎥⎢⎥⎢⎥⎢⎥⎢⎥⎢⎥⎢⎥⎣⎦1(1)1(1)2(1)()1()2()J n J J J n y y y Y y y y ⎡⎤⎢⎥⎢⎥⎢⎥⎢⎥⎢⎥⎢⎥=⎢⎥⎢⎥⎢⎥⎢⎥⎢⎥⎢⎥⎢⎥⎣⎦,Y Xa = 其中(j)表示其属于第j 组的数据。
模式识别Fisher线性判别实验

模式识别Fisher线性判别实验实验三 Fisher线性判别实验姓名:徐维坚学号:2220103484 日期:2012/7/7 一、实验目的:1)加深对Fisher线性判别的基本思想的认识和理解。
2)编写实现Fisher线性判别准则函数的程序。
二、实验原理:1.基本原理:一般情况下,我们总可以找到某个方向,使得这个方向的直线上,样本的投影能分开的最好,而Fisher法所要解决的基本问题就是找到这条最好的、最易于分类的投影线。
X先从d维空间到一维空间的一维数学变换方法。
假设有一集合包含N个d维样本,其中个属于类的样本记为子集,个属于类的样本记为。
x,x,...,x,N,XNX212N11122若对的分量做线性组合可得标量 xN T, n,1,2,...,Ny,wxinn这样便得到N个一维样本组成的集合,并可分为两个子集和。
的绝对值是无关ywYYn12紧要的,它仅使乘上一个比例因子,重要的是选择的方向,从而转化为寻找最好的投ywn*w影方向,是样本分开。
2.基本方法:先定义几个基本参量:m(1)各类样本均值向量 i1m,x,i,1,2 ,iNx,XiSS(2)样本类内离散度矩阵和总类内离散度矩阵 i,TS,(x,m)(x,m),i,1,2 i,iix,XiS,S,S ,12S(3)样本类间离散度矩阵 bTS,(m,m)(m,m) 1212b(m,m)我们希望投影后,在低维空间里个样本尽可能的分开些,即希望两类均值越大越12Authord: Vivid Xu;好,同时希望各类样本内部尽量密集,即越小越好。
因此,我们定义Fisher 准则函数为 Si2,(mm)12 ,J(w)F,SS12但不显含,因此必须设法将变成的显函数。
wwJ(w)J(w)FF由式子111TTTm,y,wx,w(x),wm ,,,iiNNN,,,yYxXxXiiiiii2TT2TTT (m,m),(wm,wm),w(m,m)(m,m)w,wSw12121212bTTTTT22S,(y,m),(wx,wm),w(x,m)(x,m)w,wSw ,,iiiiii,,yYyYii从而得到TwSwbJw, (),FTwSw,*w采用Lagrange乘子法求解它的极大值TT L(w,,),wSw,,(wSw,c),b**对其求偏导,得,即 Sw,,Sw,0b,** Sw,,Swb,从而我们很容易得到*,1*,1T* ,w,S(Sw),S(m,m)R,其中R,(m,m)w,,b1212R*1,w,S(m,m) ,12,R/,忽略比例因子,得*1, w,S(m,m),12这就是我们Fisher准则函数J(w)取极大值时的解。
模式识别实验指导书

类别1234样本x 1x 2x 1x 2x 1x 2x 1x 210.1 1.17.1 4.2-3.0-2.9-2.0-8.42 6.87.1-1.4-4.30.58.7-8.90.23-3.5-4.1 4.50.0 2.9 2.1-4.2-7.74 2.0 2.7 6.3 1.6-0.1 5.2-8.5-3.25 4.1 2.8 4.2 1.9-4.0 2.2-6.7-4.06 3.1 5.0 1.4-3.2-1.3 3.7-0.5-9.27-0.8-1.3 2.4-4.0-3.4 6.2-5.3-6.780.9 1.2 2.5-6.1-4.1 3.4-8.7-6.49 5.0 6.48.4 3.7-5.1 1.6-7.1-9.710 3.9 4.0 4.1-2.2 1.9 5.1-8.0-6.3实验一 感知器准则算法实验一、实验目的:贝叶斯分类方法是基于后验概率的大小进行分类的方法,有时需要进行概率密度函数的估计,而概率密度函数的估计通常需要大量样本才能进行,随着特征空间维数的增加,这种估计所需要的样本数急剧增加,使计算量大增。
在实际问题中,人们可以不去估计概率密度,而直接通过与样本和类别标号有关的判别函数来直接将未知样本进行分类。
这种思路就是判别函数法,最简单的判别函数是线性判别函数。
采用判别函数法的关键在于利用样本找到判别函数的系数,模式识别课程中的感知器算法是一种求解判别函数系数的有效方法。
本实验的目的是通过编制程序,实现感知器准则算法,并实现线性可分样本的分类。
二、实验内容:实验所用样本数据如表2-1给出(其中每个样本空间(数据)为两维,x 1表示第一维的值、x 2表示第二维的值),编制程序实现1、 2类2、 3类的分类。
分析分类器算法的性能。
2-1 感知器算法实验数据具体要求1、复习感知器算法;2、写出实现批处理感知器算法的程序1)从a=0开始,将你的程序应用在和的训练数据上。
记下收敛的步数。
Fisher线性判别分析实验(模式识别与人工智能原理实验1)

F i s h e r线性判别分析实验(模式识别与人工智能原理实验1)-CAL-FENGHAI-(2020YEAR-YICAI)_JINGBIAN实验1 Fisher 线性判别分析实验一、摘要Fisher 线性判别分析的基本思想:通过寻找一个投影方向(线性变换,线性组合),将高维问题降低到一维问题来解决,并且要求变换后的一维数据具有如下性质:同类样本尽可能聚集在一起,不同类的样本尽可能地远。
Fisher 线性判别分析,就是通过给定的训练数据,确定投影方向W 和阈值y0,即确定线性判别函数,然后根据这个线性判别函数,对测试数据进行测试,得到测试数据的类别。
二、算法的基本原理及流程图 1 基本原理(1)W 的确定各类样本均值向量mi样本类内离散度矩阵i S 和总类内离散度矩阵w S12w S S S =+样本类间离散度矩阵b S在投影后的一维空间中,各类样本均值T i i m '= W m 。
样本类内离散度和总类内离散度 T T i i w w S ' = W S W S ' = W S W 。
样本类间离散度T b b S ' = W S W 。
Fisher 准则函数满足两个性质:·投影后,各类样本内部尽可能密集,即总类内离散度越小越好。
·投影后,各类样本尽可能离得远,即样本类间离散度越大越好。
根据这个性质确定准则函数,根据使准则函数取得最大值,可求出W :-1w 12W = S (m - m ) 。
(2)阈值的确定实验中采取的方法:012y = (m ' + m ') / 2。
(3)Fisher 线性判别的决策规则T x S (x m)(x m ), 1,2ii ii X i ∈=--=∑T1212S (m m )(m m )b =--对于某一个未知类别的样本向量x,如果y=W T·x>y0,则x∈w1;否则x∈w2。
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
实验1 Fisher 线性判别分析实验
一、摘要
Fisher 线性判别分析的基本思想:通过寻找一个投影方向(线性变换,线性组合),将高维问题降低到一维问题来解决,并且要求变换后的一维数据具有如下性质:同类样本尽可能聚集在一起,不同类的样本尽可能地远。
Fisher 线性判别分析,就是通过给定的训练数据,确定投影方向W 和阈值y0,即确定线性判别函数,然后根据这个线性判别函数,对测试数据进行测试,得到测试数据的类别。
二、算法的基本原理及流程图 1 基本原理
(1)W 的确定
各类样本均值向量mi
样本类内离散度矩阵i
S 和总类内离散度矩阵
w S
[
12w S S S =+
样本类间离散度矩阵b S
在投影后的一维空间中,各类样本均值T i i m '= W m 。
样本类内离散度和总类内离散度
T T i i w w S ' = W S W S ' = W S W 。
样本类间离散度T b b S ' = W S W 。
Fisher 准则函数满足两个性质:
·投影后,各类样本内部尽可能密集,即总类内离散度越小越好。
·投影后,各类样本尽可能离得远,即样本类间离散度越大越好。
根据这个性质确定准则函数,根据使准则函数取得最大值,可求出W :
-1w 12W = S (m - m ) 。
(2)阈值的确定
实验中采取的方法:012y = (m ' + m ') / 2。
\
T x S (x m
)(x m ), 1,2
i
i i
i X i ∈=
--=∑T
1212S (m m )(m m )b =--
(3)Fisher线性判别的决策规则
对于某一个未知类别的样本向量x,如果y=W T·x>y0,则x∈w1;否则x∈w2。
2 流程图
方差标准化(归一化处理)
一个样本集中,某一个特征的均值与方差为:
归一化:
三、实验要求
寻找数据进行实验,并分析实验中遇到的问题和结论,写出实验报告。