SPSS进行主成分分析
SPSS软件进行主成分分析的应用例子

SPSS软件进行主成分分析的应用例子主成分分析是一种常用的多变量数据降维方法,它可以将众多相关性较强的变量通过线性组合转化为较少数量的无关变量,方便进行后续的统计分析和可视化。
下面是一个应用SPSS软件进行主成分分析的例子。
假设我们有一份健康调查问卷数据,其中包括了以下一些变量:1.年龄2.身高3.体重4.血压5.血糖6.血脂7.心率8.运动频率9.饮食习惯10.吸烟习惯11.饮酒习惯我们希望通过主成分分析来探索这些变量之间的关系,并找出影响健康的主要因素。
首先,我们需要使用SPSS软件导入数据并进行数据预处理,包括缺失值处理、异常值处理等。
接下来,我们需要进行主成分分析。
在SPSS中,可以通过如下步骤实现:1.打开SPSS软件并导入数据文件。
2.选择"分析"菜单中的"降维",然后选择"主成分"。
3.在弹出的对话框中,选择要进行主成分分析的变量。
在我们的例子中,我们选择所有的量表变量。
4.选择主成分提取的方法。
常用的方法有主成分提取和因子分析,我们选择"主成分"。
5.在主成分提取对话框中,可以选择要保留的主成分数量。
可以使用不同的标准来确定保留的主成分数量,如特征值大于1、方差解释度大于85%等。
根据实际需求,我们选择保留主成分的累积方差解释度达到60%。
6.点击"确定"进行主成分分析。
在主成分分析完成后,SPSS会生成主成分的系数矩阵、特征根表和解释根表等结果。
接着,我们需要对主成分进行解释和命名。
可以通过查看主成分的系数矩阵和特征根表来判断主成分代表的变量或潜在构念。
在我们的例子中,主成分的系数较高且与身高、体重、血压等变量相关,可以将其命名为"体型健康"。
最后,我们可以进行主成分得分的计算和解释。
在SPSS中,可以通过如下步骤实现:1.在主成分分析的结果中,选择"得分"选项卡。
用SPSS进行详细的主成分分析步骤

用SPSS进行详细的主成分分析步骤主成分分析是一种常用的多元统计分析方法,用于降低数据的维度从而简化数据集。
SPSS(统计软件)提供了强大的主成分分析功能,以下是详细的主成分分析步骤。
步骤1:打开数据集首先,打开SPSS软件并加载需要进行主成分分析的数据集。
选择“文件”>“打开”>“数据”,浏览并选择要进行主成分分析的数据文件,然后点击“打开”。
步骤2:选择变量在SPSS中,主成分分析可以应用于数值型变量。
在“数据视图”中,选择需要进行主成分分析的变量。
你可以按住Ctrl键选择多个变量,或者按住Shift键选择连续的变量。
步骤3:进行主成分分析在SPSS的主菜单中,选择“分析”>“降维”>“因子”(或者“主成分”)。
这将打开主成分分析的对话框。
步骤4:选择成分数量在主成分分析对话框中,选择“主成分”选项卡。
在该选项卡,你需要指定要提取的主成分数量。
通常,一个好的经验是提取具有特征值大于1的主成分。
步骤5:选择成分提取方法在同一选项卡,你可以选择主成分的计算方法。
最常用的方法是“主成分”和“因子”,但在大部分情况下,“主成分”方法效果更好。
步骤6:选择旋转方法在主成分分析对话框的“旋转”选项卡中,你可以选择使用特定的旋转方法。
主成分的旋转可以帮助解释和可解释性。
最常用的旋转方法是“变量最大化”(Varimax)或“正交旋转”。
步骤7:输出选项在主成分分析对话框的“输出”选项卡中,你可以选择需要输出的结果。
例如,你可以选择输出成分系数矩阵、方差解释和旋转后的成分矩阵等。
步骤8:点击运行完成以上设置后,点击“确定”按钮来运行主成分分析。
SPSS将执行主成分分析,并在输出窗口中显示结果。
步骤9:解释结果通过分析输出结果,你可以解释每个主成分的方差解释比例、因子载荷和特征值等。
方差解释比例表示每个主成分对总方差的贡献程度。
因子载荷表示每个变量对每个主成分的贡献程度。
步骤10:绘制因子图在SPSS中,你还可以绘制因子图来可视化主成分分析的结果。
SPSS进行主成分分析(PCA)
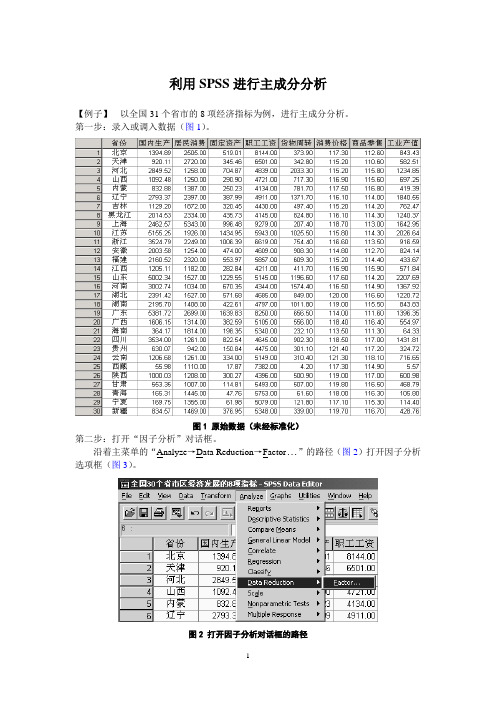
利用SPSS进行主成分分析【例子】以全国31个省市的8项经济指标为例,进行主成分分析。
第一步:录入或调入数据(图1)。
图1 原始数据(未经标准化)第二步:打开“因子分析”对话框。
沿着主菜单的“Analyze→Data Reduction→Factor ”的路径(图2)打开因子分析选项框(图3)。
图2 打开因子分析对话框的路径图3 因子分析选项框第三步:选项设置。
首先,在源变量框中选中需要进行分析的变量,点击右边的箭头符号,将需要的变量调入变量(Variables)栏中(图3)。
在本例中,全部8个变量都要用上,故全部调入(图4)。
因无特殊需要,故不必理会“Value ”栏。
下面逐项设置。
图4 将变量移到变量栏以后⒈设置Descriptives选项。
单击Descriptives按钮(图4),弹出Descriptives对话框(图5)。
图5 描述选项框在Statistics 栏中选中Univariate descriptives 复选项,则输出结果中将会给出原始数据的抽样均值、方差和样本数目(这一栏结果可供检验参考);选中Initial solution 复选项,则会给出主成分载荷的公因子方差(这一栏数据分析时有用)。
在Correlation Matrix 栏中,选中Coefficients 复选项,则会给出原始变量的相关系数矩阵(分析时可参考);选中Determinant 复选项,则会给出相关系数矩阵的行列式,如果希望在Excel 中对某些计算过程进行了解,可选此项,否则用途不大。
其它复选项一般不用,但在特殊情况下可以用到(本例不选)。
设置完成以后,单击Continue 按钮完成设置(图5)。
⒉ 设置Extraction 选项。
打开Extraction 对话框(图6)。
因子提取方法主要有7种,在Method 栏中可以看到,系统默认的提取方法是主成分(∏ρινχιπαλ χομπονεντσ),因此对此栏不作变动,就是认可了主成分分析方法。
如何正确应用SPSS软件做主成分分析

如何正确应用SPSS软件做主成分分析如何正确应用SPSS软件做主成分分析一、概述主成分分析(Principal Component Analysis, PCA)是一种常用的多变量分析方法,通过将原始变量进行线性组合,得到少数几个新的主成分,用于降低原始变量的维度,并揭示变量之间的结构关系。
SPSS软件是目前主流的数据分析工具之一,本文旨在介绍如何正确应用SPSS软件进行主成分分析。
二、数据准备进行主成分分析前,首先需要将数据导入SPSS软件。
数据应以矩阵形式呈现,每一行代表一个观测对象,每一列代表一个变量。
确保数据清洗完整,并检查是否有缺失值。
若有缺失值,可以选择删除含有缺失值的观测对象,或者使用插补方法填充缺失值。
在数据导入完成后,可以根据需求选择进行标准化操作,以消除不同变量间的量纲差异。
三、主成分分析步骤1. 启动SPSS软件并打开数据文件。
2. 选择"分析"(Analyze)菜单中的"降维"(Dimension Reduction),然后选择"主成分"(Principal Components)。
3. 在"主成分"对话框中,将需要进行主成分分析的变量移动到"变量"框中的右侧。
4. 点击"图"按钮,弹出"主因子图"对话框。
可以选择生成散点图,查看主成分之间的关系。
5. 点击"提取"选项卡,查看提取出的主成分的方差解释比。
6. 可根据需要点击"选项"按钮进行参数设置,如旋转方法、因子得分计算等。
7. 点击"统计"按钮,可以查看每个主成分的特征值以及贡献度。
8. 点击"摘要"按钮,生成主成分分析结果的摘要信息。
四、结果解释与应用主成分分析结果可以通过以下几个方面进行解释与应用:1. 主成分贡献度:通过方差解释比可以判断每个主成分对原始变量的贡献程度。
如何用SPSS软件进行主成分分析

如何用SPSS软件进行主成分分析如何用SPSS软件进行主成分分析主成分分析(Principal Component Analysis,PCA)是一种常用的数据降维与探索性分析方法,可以将高维的数据转换为低维的数据。
在实践中,主成分分析常常用于提取主要特征,简化数据集并辅助数据分析。
SPSS软件是一款功能强大的统计分析软件,提供了简单易用的主成分分析工具,使得分析人员可以快速高效地应用主成分分析。
以下是使用SPSS软件进行主成分分析的步骤:步骤一:准备数据首先,我们需要准备一个数据集,可以是Excel或者CSV格式的数据文件。
确保数据集中的变量是数值型的,并且进行过必要的数据清洗和处理。
步骤二:导入数据打开SPSS软件,点击菜单栏的“文件(File)”选项,选择“导入(Import)”子选项。
在弹出的导入对话框中,选择要导入的数据文件,点击“打开(Open)”按钮。
SPSS会自动将导入的数据文件转换为SPSS支持的格式,并将数据显示在数据视图中。
步骤三:选择主成分分析工具在SPSS软件中,主成分分析工具位于“分析(Analyse)”菜单栏的“降维(Dimension Reduction)”子选项中。
点击“主成分(Principal Components)”选项,弹出主成分分析的对话框。
步骤四:选择变量在主成分分析对话框中,选择需要进行主成分分析的变量。
可以通过将变量从“变量(Variables)”框中拖拽到“主要成分(Primary Components)”框中来选择变量。
也可以点击“变量(Variables)”框中的变量名,然后点击“右移(>)”按钮来选择变量。
选择完变量后,点击“确定(OK)”按钮。
步骤五:设置参数在主成分分析对话框中,可以设置一些参数。
例如,可以指定主成分的个数、选择的旋转方法和法则等。
如果对参数不熟悉,可以保持默认设置。
点击“确定(OK)”按钮开始进行主成分分析。
步骤六:解读结果主成分分析结束后,会生成一份主成分分析报告,展示各个主成分的解释程度和变量的贡献度等信息。
SPSS进行主成分分析

SPSS进行主成分分析主成分分析(PCA)是一种数据降维技术,用于将大量变量转换为较少的、不相关的主成分。
通过这种转换,可以更好地理解和解释数据集中的变量之间的关系。
要在SPSS中进行主成分分析,首先需要准备一个包含多个变量的数据集。
在数据集中,所有变量都应该是数值型的,而且应该是连续型的。
然后,按照以下步骤进行主成分分析:1.打开SPSS软件,并导入准备好的数据集。
在导入数据集时,请确保选择适当的数据类型和测量级别。
3.在出现的对话框中,将所有需要进行主成分分析的变量移动到右侧的"变量"框中。
可以使用向右箭头按钮移动变量,或者直接双击变量。
4. 在"提取"选项卡中,可以选择不同的提取方法,比如特征值大于1、Kaiser准则等。
选择一个适当的提取方法,确定需要提取的主成分数量。
5. 在"选项"选项卡中,可以选择不同的旋转方法,如方差最大化方法(Varimax)、直角旋转方法(Quartimax)等。
选择一个适当的旋转方法,以获得更易解释的主成分。
6.点击"确定"按钮开始主成分分析。
分析结果将在输出窗口中显示。
主成分分析的结果包括每个主成分的特征向量、特征值、解释的方差比例和累计方差比例。
特征向量表示每个变量在主成分中的权重,特征值表示该主成分解释的方差量,解释的方差比例表示每个主成分解释的方差占总方差的比例,累计方差比例表示前n个主成分解释的方差占总方差的比例。
根据主成分分析的结果,可以进行进一步的解释和应用。
例如,可以选择解释度较高的前几个主成分,进行进一步的数据分析。
也可以使用主成分分析结果来构建新的变量,代替原始的变量进行后续的分析。
总结来说,SPSS是进行主成分分析的常用工具。
通过使用SPSS中的主成分分析功能,可以有效地降低数据维度,并提取主要的变量信息,从而更好地理解和解释数据集中的变量之间的关系。
主成分分析在SPSS中的实现和案例

主成分分析在SPSS中的实现和案例
主成分分析(PCA)是一种常用的数据降维方法,可以将多个相关变量转化为少数几个无关的主成分。
在SPSS中实现PCA的步骤如下:
1. 打开SPSS软件,并打开需要进行PCA分析的数据集。
2. 选择“分析”菜单下的“降维”选项,再选择“因子”。
3. 在弹出的窗口中,选择需要进行PCA分析的变量,添加至“因子”列表中。
4. 点击“提取”按钮,选择提取主成分的方式,可以选择保留的主成分个数或者保留的方差比例。
5. 点击“确定”按钮,返回因子分析结果窗口,可以查看提取的主成分特征根、方差贡献率以及旋转后的载荷矩阵等信息。
下面介绍一个PCA的案例:假设研究人员要对顾客满意度进行研究,数据集包括顾客的年龄、性别、消费金额、服务态度、产品质量等变量。
为了降低变量维度,可以进行PCA分析。
在SPSS 中进行该分析的步骤如上述操作。
结果表明,经过PCA分析,可以选择保留3个主成分,解释总方差达到了80%以上。
第一主成分代表消费水平,第二主成分代表服务品质,第三主成分代表年龄和性别。
这说明顾客的满意度受到这3个方面的影响较大。
总之,主成分分析在SPSS中的实现方法简单易行,可以有效地解决多变量相关性较强的问题,为研究提供更加深入的解释和认识。
spss进行主成分分析及得分分析

s p s s进行主成分分析及得分分析This manuscript was revised by the office on December 22, 2012spss进行主成分分析及得分分析1将数据录入spss1. 2数据标准化:打开数据后选择分析→描述统计→描述,对数据进行标准化,选中将标准化得分另存为变量:2.3进行主成分分析:选择分析→降维→因子分析,3.4设置描述性,抽取,得分和选项:4.5查看主成分分析和分析:相关矩阵表明,各项指标之间具有强相关性。
比如指标GDP总量与财政收入、固定资产投资总额、第二产业增加值、第三产业增加值、工业增加值的相关系数较大。
这说明他们之间指标信息之间存在重叠,适合采用主成分分析法。
(下表非完整呈现)5.6由 TotalVarianceExplained(主成分特征根和贡献率)可知,特征根λ1=9.092,特征根λ2=1.150前两个主成分的累计方差贡献率达93.107%,即涵盖了大部分信息。
这表明前两个主成分能够代表最初的11个指标来分析河南各个城市经济综合实力的发展水平,故提取前两个指标即可。
主成分,分别记作F1、F2。
6.7指标X1、X2、X3、X4、X5、X6、X7、X8、X9、X10在第一主成分上有较高载荷,相关性强。
第一主成分集中反映了总体的经济总量。
X11在第二主成分上有较高载荷,相关性强。
第二主成分反映了人均的经济量水平。
但是要注意:这个主成分载荷矩阵并不是主成分的特征向量,也就是说并不是主成分1和主成分2的系数,主成分系数的求法是:各自主成分载荷向量除以各自主成分特征值的算术平方根。
7.8成分得分系数矩阵(因子得分系数)列出了强两个特征根对应的特征向量,即各主要成分解析表达式中的标准化变量的系数向量。
故各主要成分解析表达式分别为:F1=0.32ZX11+0.33ZX12+0.31ZX13+0.31ZX14+0.32ZX15+0.32ZX16+0.32ZX17+0.32ZX 18+0.32ZX19+0.21ZX110+0.15ZX111F2=8.46ZX21+0.02ZX22-0.02ZX23-0.20ZX24-0.23Z25-0.04ZX26-0.15ZX27-0.02ZX28+0.10ZX29+0.47ZX210+0.78ZX2118.9主成分的得分是相应的因子得分乘以相应的方差的算术平方根。
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
实验七、利用SPSS进行主成分分析【例子】以全国31个省市的8项经济指标为例,进行主成分分析。
第一步:录入或调入数据(图1)。
图1 原始数据(未经标准化)第二步:打开“因子分析”对话框。
沿着主菜单的“Analyze→Data Reduction→Factor ”的路径(图2)打开因子分析选项框(图3)。
图2 打开因子分析对话框的路径图3 因子分析选项框第三步:选项设置。
首先,在源变量框中选中需要进行分析的变量,点击右边的箭头符号,将需要的变量调入变量(Variables)栏中(图3)。
在本例中,全部8个变量都要用上,故全部调入(图4)。
因无特殊需要,故不必理会“Value ”栏。
下面逐项设置。
图4将变量移到变量栏以后⒈设置Descriptives描述选项。
单击Descriptives按钮(图4),弹出Descriptives对话框(图5)。
图5 描述选项框在Stat is tic s 统计 栏中选中U niva riate d escript ives 复选项,则输出结果中将会给出原始数据的抽样均值、方差和样本数目(这一栏结果可供检验参考);选中Initial soluti on 复选项,则会给出主成分载荷的公因子方差(这一栏数据分析时有用)。
在C orrel ation M atri x栏中,选中Coe fficien ts 复选项,则会给出原始变量的相关系数矩阵(分析时可参考);选中Deter minant 复选项,则会给出相关系数矩阵的行列式,如果希望在E xc el中对某些计算过程进行了解,可选此项,否则用途不大。
其它复选项一般不用,但在特殊情况下可以用到(本例不选)。
设置完成以后,单击Cont inue 按钮完成设置(图5)。
⒉ 设置Extra ction 选项。
打开Ext raction 对话框(图6)。
因子提取方法主要有7种,在Method 栏中可以看到,系统默认的提取方法是主成分(Pr in ci pa l Compon en ts),因此对此栏不作变动,就是认可了主成分分析方法。
在Ana lyze 栏中,选中Correlatio n ma trix 复选项,则因子分析基于数据的相关系数矩阵进行分析;如果选中Covar iance matri x复选项,则因子分析基于数据的协方差矩阵进行分析。
对于主成分分析而言,由于数据标准化了,这两个结果没有分别,因此任选其一即可。
在D isplay 栏中,选中U nrotated factor s olu ti on(非旋转因子解)复选项,则在分析结果中给出未经旋转的因子提取结果。
对于主成分分析而言,这一项选择与否都一样;对于旋转因子分析,选择此项,可将旋转前后的结果同时给出,以便对比。
选中Scree P lo t(“山麓”图),则在分析结果中给出特征根按大小分布的折线图(形如山麓截面,故得名),以便我们直观地判定因子的提取数量是否准确。
在Extract 栏中,有两种方法可以决定提取主成分(因子)的数目。
一是根据特征根(Eig envalues )的数值,系统默认的是1=c λ。
我们知道,在主成分分析中,主成分得分的方差就是对应的特征根数值。
如果默认1=c λ,则所有方差大于等于1的主成分将被保留,其余舍弃。
如果觉得最后选取的主成分数量不足,可以将c λ值降低,例如取9.0=c λ;如果认为最后的提取的主成分数量偏多,则可以提高c λ值,例如取1.1=c λ。
主成分数目是否合适,要在进行一轮分析以后才能肯定。
因此,特征根数值的设定,要在反复试验以后才能决定。
一般而言,在初次分析时,最好降低特征根的临界值(如取λ),这样提取的主成分将会偏多,根据初次分析的结果,在第二轮分析过程中=8.0c可以调整特征根的大小。
第二种方法是直接指定主成分的数目即因子数目,这要选中Number offactors复选项。
主成分的数目选多少合适?开始我们并不十分清楚。
因此,首次不妨将数值设大一些,但不能超过变量数目。
本例有8个变量,因此,最大的主成分提取数目为8,不得超过此数。
在我们第一轮分析中,采用系统默认的方法提取主成分。
图6提取对话框需要注意的是:主成分计算是利用迭代(Iterations)方法,系统默认的迭代次数是25次。
但是,当数据量较大时,25次迭代是不够的,需要改为50次、100次乃至更多。
对于本例而言,变量较少,25次迭代足够,故无需改动。
设置完成以后,单击Continue按钮完成设置(图6)。
⒊设置Scores设置。
选中Saveas variables栏,则分析结果中给出标准化的主成分得分(在数据表的后面)。
至于方法复选项,对主成分分析而言,三种方法没有分别,采用系统默认的“回归”(Regression)法即可。
图7 因子得分对话框选中Di sp lay fac tor s core coeffici ent ma tri x,则在分析结果中给出因子得分系数矩阵及其相关矩阵。
设置完成以后,单击Continue 按钮完成设置(图7)。
⒋ 其它。
对于主成分分析而言,旋转项(Rota tio n)可以不必设置;对于数据没有缺失的情况下,Optio n项可以不必理会。
全部设置完成以后,点击OK 确定,S PS S很快给出计算结果(图8)。
图8 主成分分析的结果第四步,结果解读。
在因子分析结果(Outp ut )中,首先给出的Descri ptive Sta tisti cs,第一列Mean 对应的变量的算术平均值,计算公式为∑==ni ij j x n x 11第二列Std . Deviation 对应的是样本标准差,计算公式为2/112])(11[∑=--=ni j ij j x x n σ 第三列A nal ys is N 对应是样本数目。
这一组数据在分析过程中可作参考。
接下来是Co rr el at ion Ma tr ix(相关系数矩阵),一般而言,相关系数高的变量,大多会进入同一个主成分,但不尽然,除了相关系数外,决定变量在主成分中分布地位的因素还有数据的结构。
相关系数矩阵对主成分分析具有参考价值,毕竟主成分分析是从计算相关系数矩阵的特征根开始的。
相关系数阵下面的De te rmin ant =1.133E-0.4是相关矩阵的行列式值,根据关系式0)det(=-R I λ可知,d et(λI )=d et (R ),从而Dete rmin ant =1.133E-0.4=λ1*λ2*λ3*λ4*λ5*λ6*λ7*λ8。
这一点在后面将会得到验证。
在Communa lit ies 中,给出了因子载荷阵的初始主成分方差(Initial )和提取主成分方差(Ex tr actio n),后面将会看到它们的含义。
在To tal Vari ance Ex pl ain ed(全部解释方差) 表的Initial E igenvalues(初始特征根)中,给出了按顺序排列的主成分得分的方差(Tota l),在数值上等于相关系数矩阵的各个特征根λ,因此可以直接根据特征根计算每一个主成分的方差百分比(% of Varia nce)。
由于全部特征根的总和等于变量数目,即有m =∑λi =8,故第一个特征根的方差百分比为λ1/m=3.755/8=46.939,第二个特征根的百分比为λ2/m =2.197/8= 27.459,……,其余依此类推。
然后可以算出方差累计值(Cu mulati ve %)。
在Extr action Sums o f S quared Loa ding s,给出了从左边栏目中提取的三个主成分及有关参数,提取的原则是满足λ>1,这一点我们在图6所示的对话框中进行了限定。
E i g e n v a l u e图8 特征根数值衰减折线图(山麓图)主成分的数目可以根据相关系数矩阵的特征根来判定,如前所说,相关系数矩阵的特征根刚好等于主成分的方差,而方差是变量数据蕴涵信息的重要判据之一。
根据λ值决定主成分数目的准则有三:i 只取λ>1的特征根对应的主成分从Total Variance Explained表中可见,第一、第二和第三个主成分对应的λ值都大于1,这意味着这三个主成分得分的方差都大于1。
本例正是根据这条准则提取主成分的。
ii累计百分比达到80%~85%以上的λ值对应的主成分在Total Variance Explained表可以看出,前三个主成分对应的λ值累计百分比达到89.584%,这暗示只要选取三个主成分,信息量就够了。
iii根据特征根变化的突变点决定主成分的数量从特征根分布的折线图(ScreePlot)上可以看到,第4个λ值是一个明显的折点,这暗示选取的主成分数目应有p≤4(图8)。
那么,究竟是3个还是4个呢?根据前面两条准则,选3个大致合适(但小有问题)。
在Component Matrix(成分矩阵)中,给出了主成分载荷矩阵,每一列载荷值都显示了各个变量与有关主成分的相关系数。
以第一列为例,0.885实际上是国内生产总值(GDP)与第一个主成分的相关系数。
将标准化的GDP数据与第一主成分得分进行回归,决定系数R2=0.783(图9),容易算出R=0.885,这正是GDP在第一个主成分上的载荷。
下面将主成分载荷矩阵拷贝到Excel上面作进一步的处理:计算公因子方差和方差贡献。
首先求行平方和,例如,第一行的平方和为h12=0.88492+0.38362+0.12092=0.9449这是公因子方差。
然后求列平方和,例如,第一列的平方和为s12=0.88492+0.60672+…+0.82272=3.7551这便是方差贡献(图10)。
在Excel中有一个计算平方和的命令sumsq,可以方便地算出:至于行平方和,果我们将8个主成分全部提取,则主成分载荷的行平方和都等于1(图11),即有h i=1,s j=λj。
到此可以明白:在Communalities中,Initial对应的是初始公因子方差,实际上是全部主成分的公因子方差;Extraction对应的是提取的主成分的公因子方差,我们提取了3个主成分,故计算公因子方差时只考虑3个主成分。
y = 0.0012x - 2.2336R2 = 0.783-4-3-2-1123450100020003000400050006000第一主成分国内生产总值图9 国内生产总值(GDP)的与第一主成分的相关关系(标准化数据)图10 主成分方差与方差贡献Com ponent Matrix a.885.384.121-.203-6.87E-02 1.143E-02 2.420E-029.192E-02.607-.598.271.409-7.61E-02.157 5.525E-02 1.317E-02.912.161.212-.270-7.71E-028.271E-028.113E-02-7.36E-02.466-.722.368-.164.304-1.64E-02-7.62E-02 3.949E-03.486.738-.275.212.305 2.254E-02 6.855E-02-6.02E-03-.509.252.797.072 2.716E-02-.161.107 2.435E-03-.620.594.438-.027 3.531E-02.247-9.23E-02 1.634E-03.823.427.211.209-9.38E-02-.137-.157-2.30E-02国内生产居民消费固定资产职工工资货物周转消费价格商品零售工业产值12345678ComponentEx traction Method: Principal Com ponent Analysis.8 com ponents ex tracted.a.图11 全部主成分的公因子方差和方差贡献提取主成分的原则上要求公因子方差的各个数值尽可能接近,亦即要求它们的方差极小,当公因子方差完全相等时,它们的方差为0,这就达到完美状态。