_数据描述性分析解读
描述性统计分析
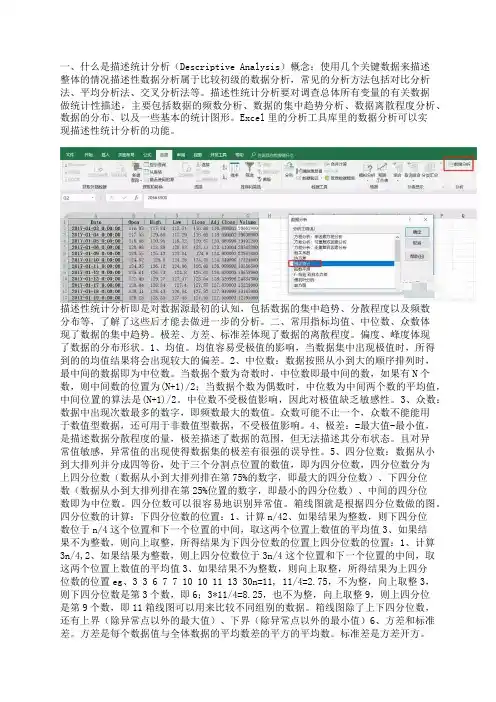
一、什么是描述统计分析(Descriptive Analysis)概念:使用几个关键数据来描述整体的情况描述性数据分析属于比较初级的数据分析,常见的分析方法包括对比分析法、平均分析法、交叉分析法等。
描述性统计分析要对调查总体所有变量的有关数据做统计性描述,主要包括数据的频数分析、数据的集中趋势分析、数据离散程度分析、数据的分布、以及一些基本的统计图形。
Excel里的分析工具库里的数据分析可以实现描述性统计分析的功能。
描述性统计分析即是对数据源最初的认知,包括数据的集中趋势、分散程度以及频数分布等,了解了这些后才能去做进一步的分析。
二、常用指标均值、中位数、众数体现了数据的集中趋势。
极差、方差、标准差体现了数据的离散程度。
偏度、峰度体现了数据的分布形状。
1、均值。
均值容易受极值的影响,当数据集中出现极值时,所得到的的均值结果将会出现较大的偏差。
2、中位数:数据按照从小到大的顺序排列时,最中间的数据即为中位数。
当数据个数为奇数时,中位数即最中间的数,如果有N个数,则中间数的位置为(N+1)/2;当数据个数为偶数时,中位数为中间两个数的平均值,中间位置的算法是(N+1)/2。
中位数不受极值影响,因此对极值缺乏敏感性。
3、众数:数据中出现次数最多的数字,即频数最大的数值。
众数可能不止一个,众数不能能用于数值型数据,还可用于非数值型数据,不受极值影响。
4、极差:=最大值-最小值,是描述数据分散程度的量,极差描述了数据的范围,但无法描述其分布状态。
且对异常值敏感,异常值的出现使得数据集的极差有很强的误导性。
5、四分位数:数据从小到大排列并分成四等份,处于三个分割点位置的数值,即为四分位数,四分位数分为上四分位数(数据从小到大排列排在第75%的数字,即最大的四分位数)、下四分位数(数据从小到大排列排在第25%位置的数字,即最小的四分位数)、中间的四分位数即为中位数。
四分位数可以很容易地识别异常值。
箱线图就是根据四分位数做的图。
数据分析实验报告(数据描述性分析)

数据分析实验报告(数据描述性分析)浙江理⼯⼤学实验报告实验项⽬名称数据描述性分析所属课程名称数据分析实验类型验证型实验实验⽇期班级学号姓名成绩【实验⽬的及要求】了解SPSS软件的安装、启动、退出以及运⾏管理⽅式;熟悉各主要操作模块,窗⼝及其功能,相关的系统参数设置等。
掌握SPSS软件的Analyze菜单中的Descriptive Statistics模块进⾏数据的描述性统计分析。
【实验原理】数据分析是指⽤适当的统计⽅法对收集来的⼤量第⼀⼿资料和第⼆⼿资料进⾏分析,以求最⼤化地开发数据资料的功能,发挥数据的作⽤;是为了提取有⽤信息和形成结论⽽对数据加以详细研究和概括总结的过程。
要对数据进⾏分析,当然要分析数据中包含的主要信息,即要分析数据的主要特征,也就是说,要研究数据的数字特征。
对于数据的数字特征,要分析数据的集中位置、分散程度。
数据的分布是正态的还是偏态等。
对于多元数据,还要分析多元数据的各个分量之间的相关性等。
【实验环境】CPU P4;RAM 512M。
Windows XP;SPSS 15.0等。
【实验⽅案设计】选取我国历年⼈⼝的出⽣率、死亡率和⾃然增长率,利⽤SPSS软件分别对出⽣率、死亡率和⾃然增长率进⾏数据的描述性统计分析:(1)计算各个变量的均值、⽅差、标准差、变异系数、偏度、峰度。
(2)计算中位数,下、上四分位数,四分位极差,三均值,并做五数总括及字母显⽰值;分析各个变量的主要数字特征。
(3)做出直⽅图,茎叶图,箱线图;分析各个变量的正态性。
(4)计算各个变量之间的协⽅差矩阵,Pearson相关矩阵、Spearman相关矩阵,分析各变量间的相关性。
【实验过程】(实验步骤、记录、数据、分析)(1)打开SPSS软件,输⼊我国历年⼈⼝的出⽣率、死亡率和⾃然增长率的数据后,点Analyze菜单按钮中的Descriptive Statistics 命令项中的 frequencies命令,跳出命令框后将左侧“出⽣率,死亡率,⾃然增长率”调到右边的variables栏中,再点击 statistics...钮,弹出frequencies Statistics 对话框。
统计学中的描述性统计分析方法

统计学中的描述性统计分析方法统计学是一门研究数据收集、整理、分析和解读的学科,它可以帮助我们更好地理解和解释数据。
描述性统计是统计学中的一个重要分支,旨在总结和揭示数据的基本特征。
在本文中,我们将介绍统计学中常用的描述性统计分析方法。
一、数据收集与整理描述性统计分析的第一步是数据收集,通过合适的调查问卷、实验或观察,我们可以获取所需的数据。
在数据收集完成后,我们需要对数据进行整理和准备,以便后续的分析。
二、测量指标在描述性统计中,我们常用各种测量指标来描绘数据的中心趋势、离散程度以及数据之间的关联性。
1. 中心趋势测量中心趋势测量用来反映数据集中的一个“典型值”。
(1)平均数(Mean):平均数是数据集中所有观测值的总和除以观测值的数量。
它可以用来衡量数据的总体情况。
(2)中位数(Median):中位数是将数据集按大小顺序排列后的中间值。
它可以忽略异常值的影响,更好地反映数据的中心位置。
(3)众数(Mode):众数是数据集中出现频率最高的值。
它在描述分类数据时特别有用。
2. 离散程度测量离散程度测量用来反映数据集的分散程度。
(1)标准差(Standard Deviation):标准差是数据集各个观测值与平均数之间的偏离度的平均值。
它反映了数据的总体分散程度。
(2)方差(Variance):方差是各个观测值与平均数之间偏离度的平方的平均值。
它是标准差的平方。
(3)极差(Range):极差是数据集中最大值与最小值之间的差值。
它可以用来衡量数据的全局范围。
三、数据可视化数据可视化是描述性统计分析中非常重要的一部分。
通过图表和图形的方式展示数据,可以使数据的特征更加直观地呈现出来。
1. 条形图(Bar Chart):条形图用于对比不同类别或组之间的数据差异。
2. 折线图(Line Chart):折线图可以展示变量随时间的变化趋势。
3. 饼图(Pie Chart):饼图适用于展示分类数据的比例关系。
4. 散点图(Scatterplot):散点图可以直观地显示两个变量之间的关系。
描述性统计分析报告

描述性统计分析报告引言:统计数据是现代社会中不可或缺的一部分,它为我们提供了了解各种现象和现实情况的重要工具。
在本篇文章中,我们将进行一项关于某地区居民收入的描述性统计分析,通过对数据的分析和解释,将展示出居民收入的整体状况以及在不同人口群体之间的差异。
数据来源和样本:本次统计分析所用的数据来自于某地区政府统计部门的年度统计报告,并且涵盖了该地区所有居民的收入情况。
样本总数为1000,通过随机抽样方式选取了不同年龄、教育水平、职业和家庭收入水平的居民。
总体数据分析:1. 平均收入:通过对数据进行计算,我们得出该地区居民的平均收入为12000元。
2. 中位数:进行中位数的计算后,我们发现该地区居民的中位数收入为10000元。
3. 众数:进行众数的计算后,我们发现该地区居民的众数收入为8000元。
居民收入差异分析:1. 年龄差异:我们将居民按照年龄分组,并计算每个年龄组的平均收入。
结果显示,年龄在25岁到34岁之间的居民平均收入最高,为15000元,而年龄在55岁以上的居民平均收入最低,为8000元。
2. 教育水平差异:根据居民的教育水平进行分组,并计算每个组的平均收入。
结果显示,高中及以下文凭的居民平均收入最低,为8000元,而拥有本科及以上学历的居民平均收入最高,为15000元。
3. 职业差异:我们将居民按照职业进行分组,并计算每个职业的平均收入。
结果显示,专业人士和经理人员的平均收入最高,为20000元,而服务和销售行业的居民平均收入最低,为8000元。
4. 家庭收入差异:我们将居民按照家庭收入水平进行分组,并计算每个组的平均收入。
结果显示,家庭收入水平较高的居民平均收入较高,为16000元,而家庭收入水平较低的居民平均收入较低,为10000元。
结论:通过对该地区居民收入数据的描述性统计分析,我们可以得出以下结论:该地区居民的平均收入为12000元,中位数为10000元,众数为8000元。
同时,在不同人口群体之间存在明显的收入差异,包括年龄、教育水平、职业和家庭收入水平等方面。
SPSS数据处理与分析教案-数据的描述性统计分析

(项目,任务)
项目二SPSS Statistics数据创建与数据预处理
任务4图表分析
教学目标:
1.掌握交叉表格的制作方法。
2.掌握柱形图和饼图的绘制方法。
教学重点、难点:
重点:能够绘制交叉表格、柱形图、饼图。
难点:理解数据的各种图形的特点。
教学内容及过程设计
时间分配
一、制作交叉表格
子任务1:“手机销售统计.sav”文件记录了某淘宝店铺某日手机的销售数据,通过交叉表格分析消费者的性别与手机品牌的关系。
2.箱图
子任务2:打开“满意度测评.sav”文件,绘制不同营业厅的满意度的箱图,并在图中标注个案。
【步骤1】~【步骤3】
二、数据的正态性检验
1.通过直方图进行正态性检验
子任务3:在“满意度测评.sav”文件中,绘制不同营业厅的满意度的直方图。
【步骤1】~【步骤3】
2.通过正态QQ图进行正态性验证
子任务4:在“满意度测评.sav”文件中,利用正态QQ图判断不同营业厅的满意度是否服从正态分布。
【步骤1】~【步骤3】
3.通过正态性验证指标进行正态性验证
子任务5:在“满意度测评.sav”文件中,判断不同营业厅的满意度是否服从正态分布。
【步骤1】~【步骤4】
任务实训
在“成绩.sav”文件中,判断不同性别的成绩是否服从正态分布。
(20分钟)
(20分钟)
(10分钟)
(10分钟)
(15分钟)
课后总结分析:
【步骤1】~【步骤8】
2.中位数
子任务3:某公司员工工资数据存放在“工资统计.sav”文件中,根据此数据文件计算平均值与中位数,并比较哪一个指标更能体现工资的集中趋势。
SPSS数据分析—描述性统计分析

SPSS数据分析—描述性统计分析描述性统计分析是一种针对数据本身的分析方法,通过使用统计学指标来描述数据的特征。
这种分析方法看似简单,但实际上却是许多高级分析的基础工作。
很多高级分析方法都对数据有一定的假设和适用条件,这些可以通过描述性统计分析来判断。
我们也会发现,许多分析方法的结果中都会穿插一些描述性分析的结果。
描述性统计主要关注数据的三个方面:集中趋势、离散趋势和数据分布情况。
描述集中趋势的指标包括均值、众数和中位数,其中均值包括截尾均值、几何均值和调和均值等。
描述离散趋势的指标包括频数、相对数、方差、标准差、标准误、全距、四分位间距、四分位数、百分位数和变异系数等。
需要注意的是,连续型变量和离散型变量的指标有所不同。
由于许多统计分析都有一个正态分布的假设,因此我们经常关注数据的分布特征。
常用峰度系数和偏度系数来描述数据偏离正态分布的程度。
也可以使用Bootstrap方法计算出结果与经典统计学方法计算出的结果进行对比,如果差异明显,则说明原数据呈偏态分布或存在极值。
SPSS用于描述性统计分析的过程大部分都在分析-描述统计菜单中,另有一个在比较均值-均值菜单。
虽然这几个过程用途不同,但基本上都可以输出常用的指标结果。
分析-描述统计-频率过程可以输出连续型变量集中趋势和离散趋势的主要指标,还可以输出判断分布的直方图、峰度值和偏度值。
此外,该过程最主要的作用是输出频数表。
分析-描述统计-描述过程输出的内容并不多,也没有统计图可以调用,唯一特别的是该过程可以对数据进行标准化变换,并保存为新变量。
分析-描述统计-探索过程是在原有数据进行描述性统计的基础上,更进一步的描述数据。
与前两种过程相比,它能提供更详细的结果。
分析-描述统计-比率过程主要用于对两个连续变量间的比率进行描述分析。
输出的结果比较简单,只是指标的汇总表格。
分析-描述统计-交叉表过程主要用于分类变量的描述性统计。
它可以完成频数分布和构成比的分析,也经常被用来做列联表的推断分析。
数据分析数据的描述性分析
数据分析是指通过收集、整理、加工和解释数据,从中发现有价值的信息和见解。
在进行数据分析时,我们通常会使用一系列描述性统计方法,以对数据进行描述性分析。
描述性分析是一种分析数据的方法,它主要关注数据的特征和趋势。
通过描述性统计指标,我们可以了解数据的基本特征、分布情况和偏差情况。
在描述性分析中,常用的统计指标包括均值、中位数、众数、标准差、方差等。
首先,均值是描述数据中心位置的指标。
它是一组数据的算术平均值,通过将所有观测值相加,再除以观测值的数量来计算。
均值可以帮助我们理解数据点的集中趋势,并判断数据是否呈现出正态分布。
其次,中位数是数据的中间位置的指标。
对于一个有序的数列,如果数列的个数为奇数,则中位数是位于中间位置的数值;如果数列的个数为偶数,则中位数是中间两个数的平均值。
中位数可以帮助我们了解数据的中间位置,并且不会受到极端值的影响。
众数是数据中出现频率最高的数值。
它可以帮助我们了解数据的主要趋势,并且通常用于描述离散型数据。
对于连续型数据,我们通常使用分组数据来计算众数。
标准差是描述数据离散程度的指标。
它表示数据围绕均值的分散程度,标准差越大,表示数据的波动性越高。
标准差可以帮助我们判断数据的稳定性和可靠性。
方差是数据离散程度的另一个指标。
它计算了数据与其均值之间的差异的平方的平均值。
方差越大,表示数据的分散程度越高。
方差可以帮助我们判断数据是否集中在均值附近。
描述性分析不仅可以从数值上描述数据,还可以使用图表来直观地展示数据的特征和趋势。
常用的图表包括柱状图、折线图、饼图等。
这些图表可以帮助我们更好地理解数据,发现其中的规律和关联。
除了以上常用的描述性统计指标和图表外,还可以使用其他方法进行数据的描述性分析。
例如,可以通过计算统计学的偏度和峰度指标来描述数据分布的形状;可以通过绘制箱线图来展示数据的离群值情况;还可以使用相关系数分析来研究变量之间的关系等。
总之,描述性分析是数据分析的重要步骤之一,它可以帮助我们了解数据的基本特征和趋势,为后续的数据解释和决策提供基础。
描述性统计分析结果举例解读
描述性统计分析结果举例解读描述性统计分析(DescriptiveStatistics)是统计学中最常用的研究方法之一,也是研究工作中最容易实施的研究方法。
描述性统计分析能够帮助研究者了解一个研究群体人口结构特征、行为特征以及结果特征等内容,以便更好地指导实践并采取有效的行动,以提升整个研究的质量。
本文通过描述性统计分析的例子,来进行解读,以期对描述性统计分析有更深入的认识。
一、定义描述性统计分析(Descriptive Statistics)指的是一种把一组数据的摘要用一种形式表示出来的统计方法,它可以帮助人们了解一组数据的状况。
描述性统计分析可以把一些复杂的数据转换成简单易懂的形式来表示,让我们可以快速掌握一组数据的特征和趋势,比如最大值、最小值、中位数、均值、众数、众数频数等。
二、描述性统计分析结果解读1、求出数据组的最大值、最小值、均值最大值、最小值可以反映数据组中数据点的范围,而均值反映了数据组中大部分数据点的分布情况。
如果我们发现均值大于最大值或小于最小值,则可以考虑数据组中存在异常值,从而对数据进行更详细地分析。
2、求出数据组的众数和众数频数众数(Mode)是指一组数据中出现次数最多的值,而众数频数(Mode Frequency)是指某个众数出现的次数。
出现次数最多的众数可以反映数据点的普遍情况,而众数频数可以反映出现次数最多的众数出现的程度。
3、求出数据组的中位数中位数(Median)是指一组数据中点两边的数据点刚好相等的数据点,其用于表示数据分布的中间状态,中位数的值代表的是这一组数据的中心值。
如果数据分布有较大的偏差,则中位数能够更好地表征数据的分布趋势。
三、结论描述性统计分析能够帮助我们有效的描述一组数据的特征。
它可以快速给出该组数据的最大值、最小值、均值、众数、众数频数和中位数等摘要信息。
这些信息能够帮助我们更好地分析和理解数据,从而有效地指导实践并采取有效的行动。
数据描述性统计分析
数据描述性统计分析数据是当今社会中不可或缺的重要资源,通过对数据进行描述性统计分析,可以帮助我们更好地理解数据的特征和规律,为决策提供有力支持。
本文将从数据描述性统计分析的概念、方法和应用等方面进行探讨。
一、概念数据描述性统计分析是指通过对数据的整理、总结、分析和展示,揭示数据的分布规律、集中趋势、离散程度等特征。
在数据分析领域中,描述性统计分析是最基础、最核心的环节,能够直观地帮助我们了解数据的基本情况,为后续的推断性统计分析提供依据。
二、方法1. 数据整理:首先需要对所收集的数据进行整理,包括数据的输入、分类、编码等操作,确保数据的准确性和完整性。
2. 数据总结:接着可以对数据进行总结,包括计算数据的频数、频率、均值、中位数、众数、标准差、方差等统计量,从而揭示数据的集中趋势和离散程度。
3. 数据展示:最后,可以通过图表等形式将数据进行展示,如直方图、饼图、折线图等,直观地展现数据的分布情况,有助于我们更好地理解数据。
三、应用数据描述性统计分析在各个领域都有着广泛的应用,下面以几个典型领域为例进行介绍:1. 商业领域:在市场调研、销售预测等方面,可以通过对数据的描述性统计分析,快速获取市场需求、产品销售情况等信息,为企业决策提供支持。
2. 医疗领域:在医学研究、疾病预防等方面,可以通过对患者的病例数据进行描述性统计分析,揭示疾病的发病率、治疗效果等信息,为医疗保健提供参考。
3. 教育领域:在学生考试成绩、学科发展等方面,可以通过对学生成绩数据进行描述性统计分析,了解学生学习情况、课程难易度等信息,为教学改进提供依据。
综上所述,数据描述性统计分析作为一种重要的数据分析手段,在各个领域都有着广泛的应用,能够帮助我们更好地理解数据、发现问题、做出决策,对推动社会发展和进步具有重要意义。
希望本文对读者有所启发,促进更多人深入了解和应用数据描述性统计分析。
描述性统计分析报告
描述性统计分析报告在统计学中,描述性统计分析是对数据进行整理、总结和展示的过程,通过描述性统计分析,我们可以更好地理解数据的特征和规律。
本报告将对某公司销售数据进行描述性统计分析,以便更好地了解销售情况并为未来的决策提供参考。
首先,我们将对销售数据的基本特征进行描述性统计分析。
销售数据包括销售额、销售数量、销售渠道等指标。
我们将计算这些指标的平均值、中位数、标准差等统计量,以便了解销售数据的集中趋势和离散程度。
通过描述性统计分析,我们可以得出销售额的平均值为XXXX万元,中位数为XXXX万元,标准差为XXXX万元,表明销售额的波动较大,需要进一步关注。
其次,我们将对销售数据的分布情况进行描述性统计分析。
销售数据的分布情况反映了销售情况的差异性和波动性。
我们将绘制销售额、销售数量的频数分布直方图和箱线图,以便观察销售数据的分布情况。
通过描述性统计分析,我们可以发现销售额呈现右偏分布,销售数量呈现正态分布,这表明销售额的波动较大,需要加强管理和控制。
最后,我们将对销售数据的相关性进行描述性统计分析。
销售数据之间的相关性反映了销售指标之间的关联程度。
我们将计算销售额与销售数量、销售额与销售渠道之间的相关系数,以便了解销售数据之间的关联情况。
通过描述性统计分析,我们可以得出销售额与销售数量之间的相关系数为XXXX,销售额与销售渠道之间的相关系数为XXXX,表明销售额与销售数量之间存在一定的正相关关系,需要进一步研究和分析。
综上所述,通过描述性统计分析,我们可以更好地了解销售数据的特征和规律,为未来的决策提供参考。
在未来的工作中,我们将加强对销售额的管理和控制,进一步研究销售数据之间的关联关系,以便提高销售业绩和效益。
通过本次描述性统计分析报告,我们对销售数据有了更深入的了解,为未来的决策提供了参考。
希望本报告能够对公司的发展和决策提供帮助。
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
SAS软件
在数据处理与统计分析领域,SAS系统已成为国 际上流行标准企业管理软件。美国《财富》杂志 评选的500家最大公司中的90%以上的企业都在 应用SAS软件。 在北美,SAS广泛地被用于所有的金融公司,医 药研发机构和政府调查和监管部门。特别是在加 拿大的金融中心-多伦多,每年更是需要大量熟练 掌握和运用SAS的科技人员。
2 方差、标准差与变异系数 方差是描述数据取值分散性的一个度量,
1 n 2 s ( x x ) i n 1 i 1
2
其量纲是数据量纲的平方。 标准差
1 n s s ( xi x) 2 n 1 i 1
2
均值、方差等数字特征
变异系数:刻画数据相对分散性的度量
s CV= 100 (%) x
SAS软件介绍-Colin
美国SAS软件研究所(SAS Institute Inc.)创建于1976年。 27年来,SAS软件研究所一直致力于为金融、医药研发、 保险、电信、制造、政府以及科研教育等部门,在SAS的 数据仓库, 统计分析、联机分析处理系统, 数据挖掘, Intranet和各种瘦客户端的核心产品和技术之上,为各种 企业提供客户关系管理、信贷风险分析和管理、企业综合 风险管理、数据仓库、协作式商务智能、企业均衡记分卡 (Balanced Score Card)、电子商务智能、供应关系管理、 财务分析和报告、人力资源管理和其它各种商务智能和决 策支持系统(DSS)的解决方案。
SAS系统的启动和退出
退出 1 选择关闭按钮; 2 执行菜单命令【File】→【Exit...】; 3 在命令框执行BYE或ENDSAS命令
n
数据描述性分析
数据分析研究的对象是数据,它们是n 个观测值:
x1 , x2 ,, xn ,
1
,
如果这 n 个观测值就是所要研究对象的全体,那么数据 分析的任务就是提取数据中包含的有用的信息。如果数 据是从总体中抽出的样本,就要分析推断样本中包含的 总体的信息。
SAS软件
SAS 是一个庞大的系统,它多个功能模块 组成,每个模块分别完成不同的功能。由于SAS 最初是为专业统计人员设计的(这一点和SPSS 已恰恰相反),因此使用上以编程为主,初学者 掌握较为困难。
SAS软件
SAS公司统计分析的强大优势和完美的数据挖掘产品,可以帮助用户: Customer Segmentation-识别最有利润的客户群,并揭示其中的 特征 Credit Risk Management-通过准确的信用评分提高客户的利润 率 Balanced Scorecard - 企业均衡计分管理 Fraud Detection-欺诈检测 Customer Retention-客户流失管理 Cross Selling-组合销售 以及其他需要预测和规则发现的应用等等 SAS的宗旨是为所有需要进行数据处理、数据分析的非计算机工作人 员提供一种易学易用、完整可靠的软件系统。SAS语言本身是一种非 过程语言(第四代语言),类似于C语言,且综合了各种高级语言的 功能和灵活的格式,将数据处理和统计分析融合于一体。
SAS系统的启动和退出
启动 1 双击桌面图标 2 执行开始菜单中程序菜单项
输出 窗口, F7
日志 窗口, F6
程序 编辑 窗口, F5
显示管理系统的基本窗口
在程序编辑窗口中,你可以 1 输入、编辑和提交程序语句 2 打开以前储存的程序 3 将程序存入文件
显示管理系统的基本窗口
在日志窗口中,你可以看到你提交的程序执行过 程中系统产生的一些信息 在输出窗口中,你可以浏览当前的SAS程序产生 的输出结果
SAS模块
SAS8.2的完整版本包含以下数十个模块。 BASE,GRAPH,ETS,FSP,AF,OR,IML,SHARE, QC,STAT,INSIGHT,ANALYST,ASSIST, CONNECT,CPE,LAB,EIS,WAREHOUSE,PC File Formats,GIS,SPECTRAVIEW, SHARE*NET, R/3,OnlineTutor: SAS Programming,MDDB Server, IT Service Vision Client, IntrNet Compute Services, Enterprise Reporter,MDDB Server common products, Enterprise Miner,AppDev Studio,Integration Technologies等 常用的模块有base,graph,stat,insight,assist, analyst模块等,分别执行基本数据处理、绘图、统计分 析、数据探索、可视化数据处理等功能。
均值、方差等数字特征
一元数据的数字特征主要是以下几种。设 n个观测值为
x1 , x2 ,, xn ,
其中n 称为样本容量。 , 1 均值:即是 x1 , x2 ,, xn的平均数:
1 n x xi n i 1
均值表示数据的集中位臵。(matlab mean函数)
均值、方差等数字特征
第一章 数据描述性分析
数据分析的基本内容
数据描述性分析 非参数方法 回归分析 主成分分析 判别分析 聚类分析 时间序列分析 Bayes统计分析
SAS软件介绍-Colin
随着信息技术的迅速发展-特别是数据仓库技术的 广泛应用,企业拥有的数据量急剧呈几何级数增 大,在这大量的数据信息中,隐藏着企业运作的 利弊得失,若能够对这种海量的数据与信息进行 快速有效地深入分析和处理,就能从中找出规律 和模式,获取企业决策所需知识,帮助企业进行 迅速有效的运筹决策。
n
校正平方和
(x CSS=
i 1
i
2 x )
未校平方和
2 x USS = i i 1 n
均值、方差等数字特征
3 偏度与峰度 偏度与峰度是刻画数据的偏态、尾重程度的度量。 它们与数据的矩有关。数据的矩分为原点矩与中心矩。
k阶原ቤተ መጻሕፍቲ ባይዱ矩
1 n k v k xi n i 1
uk 1 k ( x x ) i n i 1