常用数据库的树形查询
oracle查询树行结构的方法

oracle查询树行结构的方法
如果需要查询Oracle数据库中的树形结构数据,可以使用CONNECT BY 子句和 START WITH 子句来查询。
CONNECT BY 子句通常用于查询树形结构数据,而 START WITH 子句用于指定查询的根节点。
以下是一个示例查询用于查询“部门”和“员工”的树形结构数据:
```sql
SELECT d.department_name, e.employee_name
FROM departments d
LEFT JOIN employees e ON e.department_id = d.department_id START WITH d.department_id = 1 -- 指定根节点
CONNECT BY PRIOR d.department_id = d.parent_department_id; -- 指定查询父节点
```
在这个查询中,我们使用 START WITH d.department_id = 1 指定了查询的根节点为部门ID为1的部门,使用CONNECT BY PRIOR d.department_id = d.parent_department_id 指定了查询父部门的ID,然后分别查询了部门名称和员工名称。
通过这样的查询方法,就可以查询出Oracle数据库中的树形结构数据。
1/ 1。
如何选择合适的数据库索引类型(二)

选择合适的数据库索引类型是数据库设计中的重要环节。
索引是一种数据结构,用于快速定位和访问数据库中的特定数据。
不同的索引类型适用于不同的场景和查询需求。
本文将从不同索引类型的特点、适用场景、优缺点等方面探讨如何选择合适的数据库索引类型。
一、B树索引B树索引是最常见的索引类型,它适用于范围查询和精确查询。
B树索引的特点是平衡的树形结构,可以在O(log n)的时间复杂度内进行查询操作。
在大多数常用的数据库中,如MySQL和Oracle,都使用B树索引作为默认的索引类型。
B树索引适合于在大数据量、多范围查询条件的场景下。
它可以高效地定位到相关数据的位置,从而提高查询的性能。
然而,B树索引的缺点是占用空间较大,当数据量增长时,索引的维护成本也较高。
二、哈希索引哈希索引是根据数据的哈希值进行索引的一种方式。
它适用于等值查询,即通过给定的键值快速定位到具体的数据。
哈希索引的特点是快速,可以在O(1)的时间复杂度内进行查询操作。
哈希索引适合于只有等值查询的场景,例如根据主键进行查询。
由于哈希索引是通过哈希函数计算得到的索引值,因此它不能支持范围查询。
此外,哈希索引对数据的插入和删除操作也不友好,因为数据的插入和删除可能需要重新计算哈希值。
三、全文索引全文索引是用于快速搜索文本内容的一种索引类型。
它适用于包含大量文本信息的表,如文章、博客等。
全文索引的特点是可以对文本进行分词,并根据分词结果进行索引和搜索。
全文索引适合于使用关键字进行搜索的场景,可以提供更精确和准确的搜索结果。
全文索引的缺点是占用更多的存储空间,而且索引的维护成本较高。
在使用全文索引时,还需要考虑分词的准确度和性能等问题。
四、空间索引空间索引是用于处理地理位置数据的一种索引类型。
它适用于包含地理位置信息的表,如地图应用、位置服务等。
空间索引的特点是可以对地理位置进行高效的索引和查询。
空间索引适合于需要根据地理位置进行查询和分析的场景。
通过空间索引,可以快速地找到附近的地点、计算距离和进行位置关系的计算。
园林植物数据库
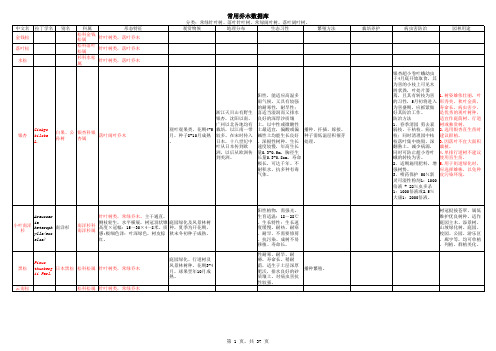
中文名 金钱松 落叶松 水松 拉丁学名 别名 科属 形态特征 松科金钱 针叶树类,落叶乔木 松属 松科落叶 针叶树类,落叶乔木 松属 杉科水松 针叶树类,落叶乔木 属 分类:常绿针叶树、落叶针叶树、常绿阔叶树、落叶阔叶树。 观赏物候 地理分布 生态习性 繁殖方法 栽培养护 病虫害防治 园林用途
第 4 页,共 37 页
常用乔木数据库
中文名 拉丁学名 别名 科属 形态特征 分类:常绿针叶树、落叶针叶树、常绿阔叶树、落叶阔叶树。 观赏物候 地理分布 生态习性 繁殖方法 栽培养护 病虫害防治 园林用途
树冠挺拔苍翠,属低 维护优良树种。适作 庭园主木、添景树、 山坡绿化树。庭园、 校园、公园、游乐区 、廊宇等,均可单植 、列植、群植美化。
黑松
Pinus thunberg 日本黑松 松科松属 针叶树类,常绿乔木 ii Parl.
松科松属 针叶树类,常绿乔木
庭园绿化、行道树及 风景林树种,花期3-4 月,球果翌年10月成 熟。
Cryptome 日本柳杉 ria 孔雀松 japonica
日本柳杉树形圆满丰 盈,高大雄伟,孤植? 、对植、行列种植与 丛植都很适宜。
柳杉
Cryptome 庭园绿化及风景林树 、孔雀松 杉科柳杉 针叶树类,常绿乔木。高达40m, ria 种,花期4月,球果 、木沙椤 属 树冠塔圆锥形。 fortunei 10-11月成熟。
播种
雪松
Cedrus deodara (Roxb.) Loud.
喜马拉雅 山雪松、 松科雪松 针叶树类,常绿乔木 香柏、喜 属 马拉雅杉
原产喜马拉雅山西 花期10-11月,球果次 部,现在长江流域 年9-10月成熟 各大城市中多有栽 培
生长速度:较快,阳 性树,喜光,稍耐阴 。喜温暖湿润气候, 有一定耐寒能力,大 苗可耐短期的-25℃低 温,耐旱性较强,年 雨量600-1200mm最好 。喜土层深厚、排水 良好的土壤,适生于 播种、扦插及嫁接繁 高燥、肥沃和土层深 殖。 厚的中性、微酸性土 壤及微碱性土壤、瘠 薄地和黏土地亦可适 应。忌积水,在低洼 地生长不良。根系 浅,侧根在土壤40-60 厘米处。性畏烟,含 二氧化硫气体会使嫩 叶迅速枯萎。
关系型数据库存储树形结构

关系型数据库存储树形结构树形结构是一种常见的数据结构,它由一个根节点和若干个子节点组成,每个节点可以有多个子节点,但只能有一个父节点。
在实际应用中,树形结构经常用于表达层级关系,如组织结构、分类体系等。
在关系型数据库中,如何存储和查询树形结构是一个常见的挑战。
传统的关系型数据库通常采用表格的形式来存储数据,每个表格由若干列和若干行组成。
然而,表格的结构并不适合直接存储树形结构。
为了解决这个问题,有几种常见的方法可以在关系型数据库中存储树形结构。
1. 嵌套集合模型(Nested Set Model)嵌套集合模型是一种常见的存储树形结构的方法。
它通过为每个节点分配一个左右值来表示节点在树中的位置。
通过使用左右值,可以快速查询某个节点的子节点、父节点以及兄弟节点。
然而,嵌套集合模型在插入、删除节点时需要更新大量的左右值,因此对于频繁变动的树形结构来说,性能可能不佳。
2. 路径枚举模型(Path Enumeration Model)路径枚举模型是另一种存储树形结构的方式。
它通过为每个节点存储一个路径来表示节点在树中的位置。
路径是一个由父节点的标识符组成的字符串,可以使用特定的分隔符来分隔各个节点。
通过路径,可以快速查询某个节点的子节点、父节点以及兄弟节点。
路径枚举模型在插入、删除节点时的性能较好,但在查询深层次节点时可能存在性能问题。
3. 闭包表模型(Closure Table Model)闭包表模型是一种更为灵活的存储树形结构的方法。
它通过使用一个闭包表来存储节点之间的关系。
闭包表是一个由祖先节点和后代节点组成的表,通过递归查询闭包表,可以获取任意节点的所有祖先节点和后代节点。
闭包表模型的优势在于查询灵活,但在插入、删除节点时需要更新闭包表,因此性能可能较差。
除了以上三种常见的存储树形结构的方法,还有其他一些变种模型,如材料化路径模型(Materialized Path Model)、嵌套集合模型的改进版(Modified Preorder Tree Traversal Model)等。
oracle 树形排序语句

oracle 树形排序语句树形排序是一种常用的排序方法,它可以将数据按照树的结构进行排列,使得数据之间的层次关系更加清晰。
在Oracle数据库中,我们可以使用CONNECT BY子句和START WITH子句来实现树形排序。
1. 使用CONNECT BY子句和START WITH子句实现树形排序的语句如下:```sqlSELECT *FROM table_nameSTART WITH parent_id IS NULLCONNECT BY PRIOR id = parent_id;```这段代码中,table_name是要进行排序的表名,parent_id是表示父节点的字段名,id是表示当前节点的字段名。
通过START WITH子句指定根节点,然后使用CONNECT BY子句指定节点之间的关系。
2. 如果要按照多个字段进行树形排序,可以在CONNECT BY子句中使用多个条件,并使用AND连接。
```sqlSELECT *FROM table_nameSTART WITH parent_id IS NULLCONNECT BY PRIOR id = parent_id AND PRIOR name = parent_name;```这段代码中,name是表示当前节点的字段名,parent_name是表示父节点的字段名。
通过多个条件进行排序,可以更加准确地表达节点之间的关系。
3. 使用LEVEL关键字可以获取当前节点在树中的层级。
```sqlSELECT id, name, LEVELFROM table_nameSTART WITH parent_id IS NULLCONNECT BY PRIOR id = parent_id;```这段代码中,LEVEL表示当前节点在树中的层级。
通过LEVEL关键字,可以对树中的节点进行分层,并在结果集中显示出来。
4. 使用CONNECT_BY_ROOT关键字可以获取根节点的值。
查询树状结构的数据显示形式

查询树状结构的数据显示形式全文共四篇示例,供读者参考第一篇示例:树状结构在数据显示和存储中经常被使用,它具有清晰的层次关系和易于理解的特点。
在实际应用中,我们经常需要查询树状结构的数据,以便找到所需的信息或进行统计分析。
本文将探讨查询树状结构数据的显示形式,以及如何有效地展示和处理这种数据。
树状结构通常是一种分层的数据结构,由根节点和若干子节点组成。
每个节点可以有多个子节点,但只能有一个父节点。
在实际应用中,树状结构常常用于表示组织结构、分类体系、文件目录等具有层级关系的数据。
在一个公司的组织结构中,总经理是根节点,部门经理是子节点,员工是子节点的子节点,依次类推。
1. 展开-折叠式显示:在展开-折叠式显示中,树状结构以层次化的方式展示出来,用户可以通过点击节点旁边的“+”或“-”符号来展开或折叠子节点。
这种显示形式适合于较大的树状结构,可以让用户快速定位到所需的节点。
2. 标签式显示:在标签式显示中,每个节点都被赋予一个标签或名称,用户可以通过输入标签或名称来查找特定节点。
这种显示形式适合于用户知道节点名称但不知道节点位置的情况。
3. 缩略图式显示:在缩略图式显示中,树状结构被以图形的方式展示出来,节点之间的层次关系可以通过不同的形状或颜色来表示。
这种显示形式适合于更直观地展示树状结构的关系。
在查询树状结构数据时,除了显示形式之外,还需要考虑如何高效地进行查询和分析。
以下是几点建议:1. 使用递归算法:由于树状结构的特点是递归性的,因此在查询和处理树状结构数据时,通常会用到递归算法。
递归算法可以简化代码逻辑,提高效率。
2. 添加索引优化性能:如果树状结构数据较大,可以考虑添加索引以提高查询性能。
通过为树状结构的某些字段建立索引,可以加快查询速度。
3. 避免循环依赖:在设计树状结构数据时,应避免出现循环依赖的情况,避免造成递归查询死循环的问题。
4. 使用缓存减少数据库查询:对于频繁查询的树状结构数据,可以考虑使用缓存技术,减少对数据库的访问次数,提高查询效率。
第四章 常用中文数据库(一)

分类浏 览路径
分类浏览结果
采用检索提问式检索复杂概念
用逻辑组配符号+连接检索词 ——表示检索结果为其左右两侧概念的并集。 用逻辑组配符号*连接检索词 ——表示检索结果为其左右两侧概念的交集。 用逻辑组配符号-连接检索词 ——表示检索结果为从前概念中去除后概念。
检中记录290条
对初级检索结果进行“二次检索”
核心期刊——是指发文质量高,专业信息含量大,被摘率、被引率和借阅率都比 较高,而被公认为代表着学科(或专业)当前水平和发展方向的期刊。
“二次检索”结果的题录显示
检索结果的摘要显示
全文下 载
全文 下载 相关检索
摘 要
检索结果的保存
打 印
存盘
文本选择工具(可 以选择需要摘录的 段落、章节予以保 存)
(1) 数据库基本情况
收录1989年至今约9000余种中国期刊(全文)。其 中核心期刊1747种,文献总量达1250万篇,年更新量大于 200万篇。 内容覆盖自然科学、社会科学各个领域。按照《中 国图书馆分类法》进行分类,所有文献被分为8个专辑: 社会科学、自然科学、工程技术、农业科学、医药卫生、 经济管理、教育科学和图书情报。 本数据库检索入口多、具有相关信息链接、支持全 文下载、文字转换能功能。数据每日更新。
传统检索界面
简单检索
输入检索词
查看检索结果
关 于 二 次 检 索
二次检索是在一次检索的检索结果中,根据检 索目标的需求,选择采用“与、或、非”进行再次 检索,以寻求更加准确的检索结果。 可以在检索中不止一次地应用“二次检索”功 能,但要注意及时对检索字段等的相应调整。
复合检索功能——检索举例
(1) 数据库基本情况 (2) 数据库检索 (3) 相关注意事项
树形结构数据库表Schema设计的两种方案

树形结构数据库表Schema设计的两种⽅案⽬录前⾔⼀、基本数据⼆、继承关系驱动的Schema设计三、基于左右值编码的Schema设计四、树形结构CRUD算法(1)获取某节点的⼦孙节点(2)获取某节点的族谱路径(3)为某节点添加⼦孙节点(4)删除某节点五、总结前⾔程序设计过程中,我们常常⽤树形结构来表征某些数据的关联关系,如企业上下级部门、栏⽬结构、商品分类等等,通常⽽⾔,这些树状结构需要借助于数据库完成持久化。
然⽽⽬前的各种基于关系的数据库,都是以⼆维表的形式记录存储数据信息,因此是不能直接将Tree存⼊DBMS,设计合适的Schema及其对应的CRUD算法是实现关系型数据库中存储树形结构的关键。
理想中树形结构应该具备如下特征:数据存储冗余度⼩、直观性强;检索遍历过程简单⾼效;节点增删改查CRUD操作⾼效。
⽆意中在⽹上搜索到⼀种很巧妙的设计,原⽂是英⽂,看过后感觉有点意思,于是便整理了⼀下。
本⽂将介绍两种树形结构的Schema设计⽅案:⼀种是直观⽽简单的设计思路,另⼀种是基于左右值编码的改进⽅案。
⼀、基本数据本⽂列举了⼀个⾷品族谱的例⼦进⾏讲解,通过类别、颜⾊和品种组织⾷品,树形结构图如下:⼆、继承关系驱动的Schema设计对树形结构最直观的分析莫过于节点之间的继承关系上,通过显⽰地描述某⼀节点的⽗节点,从⽽能够建⽴⼆维的关系表,则这种⽅案的Tree表结构通常设计为:{Node_id,Parent_id},上述数据可以描述为如下图所⽰:这种⽅案的优点很明显:设计和实现⾃然⽽然,⾮常直观和⽅便。
缺点当然也是⾮常的突出:由于直接地记录了节点之间的继承关系,因此对Tree的任何CRUD操作都将是低效的,这主要归根于频繁的“递归”操作,递归过程不断地访问数据库,每次数据库IO都会有时间开销。
当然,这种⽅案并⾮没有⽤武之地,在Tree规模相对较⼩的情况下,我们可以借助于缓存机制来做优化,将Tree的信息载⼊内存进⾏处理,避免直接对数据库IO操作的性能开销。
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
常用数据库的树形查询
在ORACLE、MSSQL、MYSQL中树结构表递归查询的实现方法
表recursion数据如下:
id name parentid
1 食品分类 -1
2 肉类 1
3 蔬菜类 1
4 产品分类 -1
5 保健品 4
6 医药 4
7 建筑 4
一ORACLE中实现方法:
Oracle中直接支持,使用语句select * from tablename start with connect by
prior id(子层的列)=parentid(属于顶层的列)
语句说明:
start with 指定层次开始的条件,即满足这个条件的行即可以作为层次树的最顶层
connect by prior指层之间的关联条件,即什么样的行是上层行的子行(自连接条件)
实例:
select * from recursionstart with connect by prior>查询结果:
id name parentid
1 食品分类 -1
2 肉类 1
3 蔬菜类 1
二MSSQL中的实现方法
在MSSQL中需要使用临时表和循环多次查询的方式实现.
创建函数:
create function GetRecursion(@id int)
returns @t table(
idint,
namevarchar(50),
parentidint
)
as
begin
insert @tselect * from recursion where> while @@rowcount>0
insert @t select a.* from recursion as a inner join @t as b
on a.parentid=b.id and a.id not in(select id from @t)
return
end
使用方法:
select * from GetRecursion(4)
查询结果:
id name parentid
4 产品分类 -1
5 保健品 4
6 医药 4
7 建筑 4
三MYSQL中的实现方法
查询语句:
select b.id,,b.parentid from recursion as a, recursion as bwhere
a.id=
b.parentid and (a.id=1 or a. parentid =1)
查询结果:
id name parentid
2 肉类 1
3 蔬菜类 1
四在ORACLE、MSSQL、MYSQL中可以使用下面的查询语句只返回树结构表的子结点数据select *
from tablename t
where not exists (select 'X'
from tablename t1, tablename t2
where t1.id = t2.parentid
and t1.id = t.id)
如:
select *
from recursion t
where not exists (select 'X'
from recursion t1, recursion t2
where t1.id = t2.parentid
and t1.id = t.id)
查询结果:
id name parentid
2 肉类 1
3 蔬菜类 1
5 保健品 4
6 医药 4
7 建筑 4
五在ORACLE、MSSQL、MYSQL中可以使用下面的查询语句只返回树结构表的根结点数据select *
from tablename t
where not exists (select 'X'
from tablename t1, tablename t2
where t1.id = t2.parentid
and t1.id = t. parentid)
如:
select *
from recursion t
where not exists (select 'X'
from recursion t1, recursion t2 where t1.id = t2.parentid
and t1.id = t. parentid)
查询结果:
id name parentid
1 食品分类 -1
4 产品分类 -1。