遗传算法函数ga用法
遗传算法GA-最短路问题

function SelCh=Select(Chrom,FitnV,GGAP) NIND=size(Chrom,1); NSel=max(floor(NIND*GGAP+.5),2); ChrIx=Sus(FitnV,NSel); SelCh=Chrom(ChrIx,:);
%%--------------------遗传参数-------------------------------
NIND=100;
%种群大小
MAXGEN=200; %最大遗传代数
Pc=0.9;
%交叉概率
Pm=0.05;
%变异概率
GGAP=0.9;
%代沟
%% 初始化种群
Chrom=InitPop(NIND,N);
Distanse.m %% 计算两两城市之间的距离 %输入 a 各城市的位置坐标 %输出 D 两两城市之间的距离 function D=Distanse(a) row=size(a,1); D=zeros(row,row); for i=1:row
for j=i+1:row D(i,j)=((a(i,1)-a(j,1))^2+(a(i,2)-a(j,2))^2)^0.5; D(j,i)=D(i,j);
end end
InitPop.m
%% 初始化种群
%输入:
% NIND:种群大小
% N: 个体染色体长度(这里为城市的个数)
%输出:
%初始种群
function Chrom=InitPop(NIND,N)
Chrom=zeros(NIND,N);%用于存储种群
遗传算法步骤

遗传算法(Genetic Algorithm,GA)是一种基于自然进化理论的算法,是一种可以对不同问题寻找最优解的智能算法,它可以用于优化因变
量组成的多为目标函数,使得其能够模拟自然群体中最优种群的复制
替代的演化过程。
GA的基本步骤如下:
1.初始化种群:随机选择或采用已有解法创建一个代表优化问题的群体,这一群体中包含多个个体,并对每一体对应一个可衡量适应度的值。
2.计算适应度:根据建模函数以及求解问题,计算每一体的适应度值,作为群体的适应度表示,该适应度值指示了当前群体的优劣,越高的
适应度表示越优秀的群体。
3.选择操作:通过自然选择决定种群接下来的演化趋势,选取进化最佳的个体,裁去低适应度的个体,做出自然选择的决定。
4.交叉操作:将于原始群体中优秀的体通过交叉进行基因交换,优化基因序列,达到更加精细化优化的进化效果。
5.变异操作:在交叉操作过后,某些个体的基因顺序经过一定的随机变异,添加新的基因组合,增强搜索空间的拓展能力。
6.重复上述步骤:将上述步骤重复进行,让群体在遗传进化过程中迭代优化,不断找寻最优解,最终终止整个搜索过程,达到满足目标。
以上就是GA的基本步骤,它不仅能够用于求解多种问题,而且运算
效率高,不需要事先设定初始值,使得对比其它算法更加方便和灵活。
但是,由于其随机性原因,在某些情况下可能得出的解不一定是最优解,使其在实际应用中并不尽如人意。
变异概率自适应调整的遗传算法GA程序
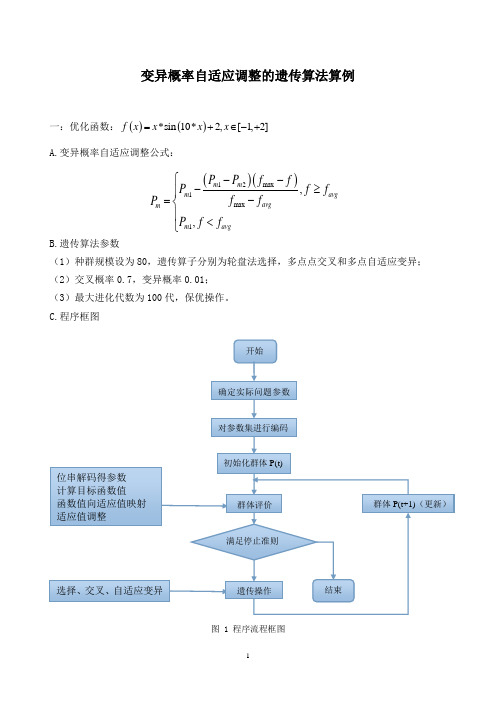
变异概率自适应调整的遗传算法算例一:优化函数:()()*sin 10*2,[1,2]f x x x x =+∈-+A.变异概率自适应调整公式:B.遗传算法参数 (1)种群规模设为80,遗传算子分别为轮盘法选择,多点点交叉和多点自适应变异;(2)交叉概率0.7,变异概率0.01;(3)最大进化代数为100代,保优操作。
C.程序框图图 1 程序流程框图()()12max 1max 1,,m m m avg avg m m avg P P f f P f f f f P P f f --⎧-≥⎪-=⎨⎪<⎩ 开始 确定实际问题参数对参数集进行编码 初始化群体P(t) 群体P(t+1)(更新) 位串解码得参数 计算目标函数值 函数值向适应值映射 适应值调整 选择、交叉、自适应变异群体评价 遗传操作 满足停止准则 结束二:程序及运行结果(1)%变异概率自适应调整的GA程序%优化函数为f=x*sin(10*x)+2,其中,-1=<x<=2%编码长度为12位%种群规模设为80,遗传算子分别为轮盘法选择,多点点交叉和多点自适应变异。
%交叉概率0.7,变异概率0.01%最大进化代数为100代,保优操作。
%**********************%主函数*****************************************function main()global chrom lchrom oldpop newpop varible fitness popsize sumfitness %定义全局变量global pcross pmutation temp bestfit maxfit gen bestgenglobal maxgen po pp mp nplchrom=12; %染色体长度popsize=80; %种群大小pcross=0.7; %交叉概率pmutation=0.01; %变异概率maxgen=100; %最大代数po=0.1; %淘汰概率pp=0.1; %保护概率mp=floor(pp*popsize); %保护的个数np=floor(po*popsize); %淘汰的个数initpop; % 初始化种群for gen=1:maxgenobjfun; %计算适应度值pp_po; %执行保优操作select; %选择操作selfmutation; %自变异操作crossover; %交叉操作endbestbestfit % 最佳个体适应度值输出bestgen % 最佳个体所在代数输出figuregen=1:maxgen;plot(gen,maxfit(1,gen)); % 进化曲线hold on;plot(bestgen,bestfit);xlabel('Generation');ylabel('Fitness');%********************** 产生初始种群 ************************************ function initpop()global lchrom oldpop popsize chromfor i=1:popsizechrom=rand(1,lchrom); % lchrom=12 染色体长度for j=1:lchromif chrom(1,j)<0.5chrom(1,j)=0;elsechrom(1,j)=1;endendoldpop(i,1:lchrom)=chrom;end%************************%计算适应度值************************************ function objfun()global lchrom oldpop fitness popsize chrom maxfit gen varible avgfiness savgfitness % a=0;b=3;a=0;b=10;for i=1:popsizechrom=oldpop(i,:);c=decimal(chrom);varible(1,i)=a+c*(b-a)/(2.^lchrom-1); %对应变量值fitness(1,i)=varible(1,i)*sin(10*varible(1,i))+2;avgfitness=sum(fitness)/popsize;lsort; % 个体排序maxfit(1,gen)=max(fitness); %求本代中的最大适应度值maxfit%************************二进制转十进制********************************** function c=decimal(chrom)global lchrom popsizec=0;for j=1:lchromc=c+chrom(1,j)*2.^(lchrom-j);end%************************* 个体从小到大排序 ************************ function lsort()global popsize fitness oldpopfor i=1:popsizej=i+1;while j<=popsizeif fitness(1,i)>fitness(1,j)tf=fitness(1,i); % 适应度值tc=oldpop(i,:); % 基因代码fitness(1,i)=fitness(1,j); % 适应度值互换oldpop(i,:)=oldpop(j,:); % 基因代码互换fitnescs(1,j)=tf;oldpop(j,:)=tc;endj=j+1;endend%*************************保优操作*****************************function pp_po()global popsize oldpop npi=np+1; % np=floor(po*popsize); %淘汰的个数npwhile i<=popsize %将(np+1)~popsize的个体放在toldpop中,共(popsize-np)个 toldpop(j,:)=oldpop(i,:);j=j+1;i=i+1;endfor i=1:(popsize-np) %从小到大顺序排列,将前面np个淘汰oldpop(i,:)=toldpop(i,:); % 适应度是否也要互换?end%*************************转轮法选择操作********************************** function select()global fitness popsize sumfitness oldpop temp mp npsumfitness=0; %个体适应度之和for i=1:(popsize-np-mp) % 仅计算(popsize-np-mp)个个体的选择概率sumfitness=sumfitness+fitness(1,i);endfor i=1:(popsize-mp-np) % 仅计算(popsize-np-mp)个个体的选择概率p(1,i)=fitness(1,i)/sumfitness; % 个体染色体的选择概率endq=cumsum(p); % 个体染色体的累积概率(内部函数),共(popsize-np-mp)个b=sort(rand(1,(popsize-mp))); % 产生(popsize-mp)个随机数,并按升序排列。
遗传算法教程GA2

遗传算法教程GA2遗传算法教程GA2遗传算法(Genetic Algorithm,GA)是一种模拟自然进化过程的优化算法。
它模拟了自然界中的遗传和进化过程,通过适应度函数评价个体的优劣,通过选择、交叉和变异等操作,不断迭代最优解。
遗传算法的基本过程包括初始化种群、计算适应度、选择、交叉、变异和更新种群。
下面将详细介绍这些步骤。
首先是初始化种群。
种群是指问题的解空间中的一个个体集合,每个个体代表问题的一个可能解。
种群的初始化可以随机生成,也可以根据问题的特点进行设计。
通常情况下,种群的大小越大,空间越广,但计算量也会增加。
接下来是计算适应度。
适应度函数是用来评价个体优劣的指标,它根据问题的具体要求进行设计。
适应度函数应该能够对个体的解进行量化评价,并且能够反映个体与最优解之间的差距。
适应度越高,个体越好。
然后是选择操作。
选择是根据个体的适应度来决定哪些个体被选择作为下一代的父代。
选择操作通常采用轮盘赌算法或排名选择算法。
轮盘赌算法根据个体适应度的比例来决定个体被选中的概率,适应度越高的个体被选中的概率越大。
排名选择算法则根据个体适应度的等级来决定个体被选中的概率。
接下来是交叉操作。
交叉是指将两个父代个体的染色体进行配对,通过染色体上的其中一种操作(如交换、重组等),生成两个子代个体。
交叉操作可以增加种群的多样性,避免陷入局部最优解。
然后是变异操作。
变异是指对个体的染色体进行随机的变换,从而产生新的个体。
变异操作能够引入种群的新解,并且有助于跳出当前空间的局部最优解。
最后是更新种群。
通过选择、交叉和变异操作生成的新个体替代原来的个体,形成下一代的种群。
这样不断进行迭代,直到满足终止条件为止,终止条件可以是达到最大迭代次数、找到满意解或达到收敛条件等。
遗传算法在实际应用中有广泛的应用。
例如,在旅行商问题中,遗传算法可以用来寻找最短路径;在机器学习中,遗传算法可以用来优化神经网络的权重和偏差;在工程设计中,遗传算法可以用来优化系统的参数等。
matlab中ga函数用法

MATLAB中的GA函数是遗传算法函数,它是一种基于生物进化原理的优化算法,用于求解一些难以用传统方法解决的优化问题。
GA 函数的使用方法如下:1. 确定问题的目标函数和约束条件。
目标函数是您希望优化的函数,而约束条件是您对问题的限制。
2. 确定问题的参数,包括变量个数、变量范围、迭代次数等。
3. 调用GA函数,并传递目标函数和约束条件作为参数。
例如:```matlabDWA 定义目标函数和约束条件fitnessFunction = @myFitnessFunction;constraintFunction = @myConstraintFunction;variableRange = [0,1];variableNum = 2;maxIterations = 100;DWA 调用GA函数[solution, fitness] = ga(fitnessFunction, variableNum, [], [], [], [], ...variableRange(1), variableRange(2), constraintFunction, maxIterations);```在上面的示例中,myFitnessFunction是您定义的目标函数,myConstraintFunction是您定义的约束条件,variableRange是变量的范围,variableNum是变量的个数,maxIterations是迭代次数。
ga函数将返回最优解和最优解的适应度值。
4. 使用返回的解进行后续分析或应用。
需要注意的是,GA函数需要您自己定义目标函数和约束条件。
目标函数应该是一个接受变量向量作为输入,并返回一个标量值的函数。
约束条件也应该是一个接受变量向量作为输入,并返回一个标量值的函数,表示约束是否被满足。
基本遗传算法(GA)的算法原理、步骤、及Matlab实现

算法原理遗传算法可以用来求函数的极值。
(1)用二进制编码来离散自变量,码长根据离散精度来确定。
码长为log 2[max−min 精度+1](2)交叉方法采用单点交叉(3)变异是根据变异概率反转子代某个位的值(4)选择策略采用轮盘赌策略,令PP i =∑p i i j=1,其中PP i 为累计概率,p i 为个体的选择概率,公式为: p i =fitness(x i )∑fitness(x i)NP i=1,其中fitness(x i )为个体的适应度,共轮转NP 次,每次轮转时,产生随机数r ,当PP i−1≤r <PP i 时选择个体i 。
算法步骤基本遗传算法的基本步骤是:1. 随机产生种群,2. 用轮盘赌策略确定个体的适应度,判断是否符合优化准则,若符合,输出最佳个体及其最优解,结束,否则,进行下一步3. 依据适应度选择再生个体,适应度高的个体被选中的概率高,适应度低的个体被淘汰4. 按照一定的交叉概率和交叉方法,生成新的个体5. 按照一定的变异概率和变异方法,生成新的个体6. 由交叉和变异产生新一代种群,返回步骤2算法的实现%基本遗传算法,一维无约束优化function [ xv,fv ] = mGA( fitness,a,b,NP,NG,Pc,Pm,eps )% 待优化的目标函数:fitness% 自变量下界:a% 自变量上界:b% 种群个体数:NP% 最大进化代数:NG% 杂交常数:Pc% 变异常数:Pm% 自变量离散精度:eps% 目标函数取最大值是的自变量值:xv% 目标函数的最小值:fvL=ceil(log2((b-a)/eps+1)); %码长x=zeros(NP,L);for i=1:NPx(i,:)=Initial(L);fx(i)=fitness(Dec(a,b,x(i,:),L));endfor k=1:NGsumfx=sun(fx);Px=fx/sumfx;PPx=0;PPx(1)=Px(1);for i=2:NP %根据轮盘赌确定父亲PPx(i)=PPx(i-1)+PPx(i);endfor i=1:NPsita=rand();for n=1:NPif sita <= PPx(n)SelFather = n;break;endendSelmother=floor(rand()*(NP-1))+1; %随机选择母亲posCut=floor(rand()*(L-2))+1; %随机确定交叉点r1=rand();if r1<=Pcnx(i,1:posCut)=x(SelFather,1:posCut);nx(I,(posCut+1):L)=x(Selmother,(posCut+1):L);r2=rand();if r2<=Pm %变异posMut=round(rand()*(L-1)+1);nx(i,posMut)=~nx(i,posMut);endelsenx(i,:)=x(SelFather,:);endendx=nx;for i=1:NPfx(i)=fitness(Dec(a,b,x(i,:),L);endendfv=-inf;for i=1:NPfitx=fitness(Dec(a,b,x(i,:),L));if fitx > fvfv=fitx;xv=Dec(a,b,x(i,:),L);endendendfunction result=Initial(length) %初始化函数for i=1:lengthr=round();result(i)=round(r);endendfunction y=Dec(a,b,x,L) %二进制转十进制base=2.^((L-1):-1:0);y=dot(base,x);y=a+y*(b-1)/(2^L-1)'end。
R语言GA遗传算法

GA包遗传算法最大化使用遗传算法的适应度函数。
默认求最大值。
用法:ga(type = c("binary", "real-valued", "permutation"), fitness, ..., min, max, nBits, population = gaControl(type)population,<br/>selection=gaControl(type)selection, crossover = gaControl(type)crossover,<br/> mutation=gaControl(type)mutation, popSize = 50, pcrossover = 0.8, pmutation = 0.1, elitism = base::max(1, round(popSize*0.05)), maxiter = 100, run = maxiter, maxfitness = Inf, names = NULL, suggestions = NULL, keepBest = FALSE, parallel = FALSE, monitor = gaMonitor, seed = NULL)参数说明•type: 解得编码类型–binary :二进制编码–real-valued:实数浮点编码–permutation:问题涉及到重新排序的列表,字符串编码。
可求解TSP 问题•fitness:适应度函数•min:解得下界(多元变量为一个向量)•max:解得上界(多元变量为一个向量)•nBits:一个种群用二进制编码的长度是多少(长度越大代表精度越高) •population:初始种群•selection:选择•crossover: 交叉•crossover:变异•popsize:种群大小•pcrossover: 交叉概率(默认0.8)•pmutation:变异概率(默认0.1)•elitism: 代沟(默认情况下,前5%个体将在每个迭代中保留)•maxiter:最大迭代次数(默认100)•maxfitness:适应度函数的上界,GA搜索后中断•keepBest:是否保留每一代的最优解•parallel:是否采用并行运算•monitor:绘图用的,监控遗传算法的运行状况•seed:一个整数值包含随机数发生器的状态。
R语言GA遗传算法【精品毕业设计】(完整版)
GA包遗传算法最大化使用遗传算法的适应度函数。
默认求最大值。
用法:ga(type = c("binary", "real-valued", "permutation"), fitness, ..., min, max, nBits, population = gaControl(type)population,<br/>selection=gaControl(type)selection, crossover = gaControl(type)crossover,<br/> mutation=gaControl(type)mutation, popSize = 50, pcrossover = 0.8, pmutation = 0.1, elitism = base::max(1, round(popSize*0.05)), maxiter = 100, run = maxiter, maxfitness = Inf, names = NULL, suggestions = NULL, keepBest = FALSE, parallel = FALSE, monitor = gaMonitor, seed = NULL)参数说明•type: 解得编码类型–binary :二进制编码–real-valued:实数浮点编码–permutation:问题涉及到重新排序的列表,字符串编码。
可求解TSP 问题•fitness:适应度函数•min:解得下界(多元变量为一个向量)•max:解得上界(多元变量为一个向量)•nBits:一个种群用二进制编码的长度是多少(长度越大代表精度越高) •population:初始种群•selection:选择•crossover: 交叉•crossover:变异•popsize:种群大小•pcrossover: 交叉概率(默认0.8)•pmutation:变异概率(默认0.1)•elitism: 代沟(默认情况下,前5%个体将在每个迭代中保留)•maxiter:最大迭代次数(默认100)•maxfitness:适应度函数的上界,GA搜索后中断•keepBest:是否保留每一代的最优解•parallel:是否采用并行运算•monitor:绘图用的,监控遗传算法的运行状况•seed:一个整数值包含随机数发生器的状态。
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
matlab 遗传算法工具箱函数ga
matlab 遗传算法工具箱函数及实例讲解
核心函数:
(1)function [pop]=initializega(num,bounds,eevalFN,eevalOps,options)--
初始种群的生成函数
【输出参数】
pop--生成的初始种群
【输入参数】
num--种群中的个体数目
bounds--代表变量的上下界的矩阵
eevalFN--适应度函数
eevalOps--传递给适应度函数的参数
options-- 选择编码形式( 浮点编码或是二进制编码)[precisionF_or_B],如
precision--变量进行二进制编码时指定的精度
F_or_B--为1 时选择浮点编码,否则为二进制编码,由precision指定精度)
(2)function[x,endPop,bPop,traceInfo]=ga(bounds,evalFN,evalOps,startPop,opts,... termFN,termOps,selectFN,selectOps,xOverFNs,xOverOps,mutFNs,mutOps)--遗传算法函数【输出参数】
x--求得的最优解
endPop--最终得到的种群
bPop--最优种群的一个搜索轨迹
【输入参数】
bounds--代表变量上下界的矩阵
evalFN--适应度函数
evalOps--传递给适应度函数的参数
startPop-初始种群
opts[epsilon prob_ops display]--opts(1:2)等同于initializega 的
options 参数,第三个参数控制是否输出,一般为0。
如[1e-6 1 0]
termFN--终止函数的名称,如['maxGenTerm']
termOps--传递个终止函数的参数,如[100]
selectFN--选择函数的名称,如['normGeomSelect']
selectOps--传递个选择函数的参数,如[0.08]
xOverFNs-- 交叉函数名称表,以空格分开,如['arithXover heuristicXoversimpleXover'] xOverOps--传递给交叉函数的参数表,如[2 0;2 3;2 0]
mutFNs-- 变异函数表,如['boundaryMutation multiNonUnifMutation nonUnifMutation unifMutation']
mutOps--传递给交叉函数的参数表,如[4 0 0;6 100 3;4 100 3;4 0 0]
注意】matlab 工具箱函数必须放在工作目录下运算借过为:x =同的初始群体)一定可以得到近似最优解。
第一个M文件为:
clear, clc
close all
prepare=[17 17 17 17 17 17 17 15 15 15 17 17 17 17 17 17 17 17 17 17 17 12 14 16 17 18 21 17 17 17 17 17 17 15 15 15 15 17 17 17;
-1 -1 -1 -1 -1 -1 -1 -0.6 -0.6 -0.6 -0.6 -0.2 -0.2 -0.2 -0.2 -0.2 0.2 0.2 0.2 0.2 0.2 0.6 0.6 0.6 0.6 0.6 0.6 1 1 1 1 1 1 1 1 1 1 1 1 1;
2 4 4 4 4 6 8 7 7 7 7 2 5 7 8 11
3 6 9 12 15 0 0 0 0 0 0
4 7 7 7 7 9 10 10 10 10 13 17 21;
24 24 14 34 44 24 24 24 24 24 24 24 24 24 24 24 24 24 24 24 24 24 24 24 24 24 24 24 24 24 24 24 24 14 24 34 44 24 24 24;
5 5 5 5 5 5 5 10 30 60 5 5 5 5 5 5 5 5 5 5 5 5 5 5 5 5 5 5 5 10 30 60 5 5 5 5 5 5 5 5];
flux=[890 686 649 721 789 648 400 721 621 10 290 524 721 834 842 1021 411 380 288 192 134 1450 950 750 523 375 130 767 623 577 659 15 690 705 943 986 1021 660 500 473];
%数据预处理。