编译原理实验二LL(1)语法分析实验报告
编译原理语法分析实验报告

编译原理语法分析实验报告第一篇:编译原理语法分析实验报告实验2:语法分析1.实验题目和要求题目:语法分析程序的设计与实现。
实验内容:编写语法分析程序,实现对算术表达式的语法分析。
要求所分析算术表达式由如下的文法产生。
E→E+T|E-T|TT→T*F|T/F|F F→id|(E)|num实验要求:在对输入表达式进行分析的过程中,输出所采用的产生式。
方法1:编写递归调用程序实现自顶向下的分析。
方法2:编写LL(1)语法分析程序,要求如下。
(1)编程实现算法4.2,为给定文法自动构造预测分析表。
(2)编程实现算法4.1,构造LL(1)预测分析程序。
方法3:编写语法分析程序实现自底向上的分析,要求如下。
(1)构造识别所有活前缀的DFA。
(2)构造LR分析表。
(3)编程实现算法4.3,构造LR分析程序。
方法4:利用YACC自动生成语法分析程序,调用LEX自动生成的词法分析程序。
实现(采用方法1)1.1.步骤:1)对文法消除左递归E→TE'E'→+TE'|-TE'|εT→FT'T'→*FT'|/FT'|εF→id|(E)|num2)画出状态转换图化简得:3)源程序在程序中I表示id N表示num1.2.例子:a)例子1 输入:I+(N*N)输出:b)例子2 输入:I-NN 输出:第二篇:编译原理实验报告编译原理实验报告报告完成日期 2018.5.30一.组内分工与贡献介绍二.系统功能概述;我们使用了自动生成系统来完成我们的实验内容。
我们设计的系统在完成了实验基本要求的前提下,进行了一部分的扩展。
增加了声明变量类型、类型赋值判定和声明的变量被引用时作用域的判断。
从而使得我们的实验结果呈现的更加清晰和易懂。
三.分系统报告;一、词法分析子系统词法的正规式:标识符(|)* 十进制整数0 |(1|2|3|4|5|6|7|8|9)(0|1|2|3|4|5|6|7|8|9)* 八进制整数0(1|2|3|4|5|6|7)(0|1|2|3|4|5|6|7)* 十六进制整数0x(0|1|2|3|4|5|6|7|8|9|a|b|c|d|e|f)(0|1|2|3|4|5|6|7|8|9|a|b|c|d|e|f)* 运算符和分隔符 +| * | / | > | < | = |(|)| <=|>=|==;对于标识符和关键字: A5—〉 B5C5 B5—〉a | b |⋯⋯| y | z C5—〉(a | b |⋯⋯| y | z |0|1|2|3|4|5|6|7|8|9)C5|ε综上正规文法为: S—〉I1|I2|I3|A4|A5 I1—〉0|A1 A1—〉B1C1|ε C1—〉E1D1|ε D1—〉E1C1|εE1—〉0|1|2|3|4|5|6|7|8|9 B1—〉1|2|3|4|5|6|7|8|9 I2—〉0A2 A2—〉0|B2 B2—〉C2D2 D2—〉F2E2|ε E2—〉F2D2|εC2—〉1|2|3|4|5|6|7 F2—〉0|1|2|3|4|5|6|7 I3—〉0xA3 A3—〉B3C3 B3—〉0|1|2|3|4|5|6|7|8|9|a|b|c|d|e|f C3—〉(0|1|2|3|4|5|6|7|8|9|a|b|c|d|e|f)|C3|εA4—〉+ |-| * | / | > | < | = |(|)| <=|>=|==; A5—〉 B5C5 B5—〉a | b |⋯⋯| y | z C5—〉(a | b |⋯⋯| y | z |0|1|2|3|4|5|6|7|8|9)C5|ε状态图流程图:词法分析程序的主要数据结构与算法考虑到报告的整洁性和整体观感,此处我们仅展示主要的程序代码和算法,具体的全部代码将在整体的压缩包中一并呈现另外我们考虑到后续实验中,如果在bison语法树生成的时候推不出目标的产生式时,我们设计了报错提示,在这个词的位置出现错误提示,将记录切割出来的词在code.txt中保存,并记录他们的位置。
编译原理实验报告材料LL(1)分析报告法84481

课程编译原理实验名称实验二 LL(1)分析法实验目的1.掌握LL(1)分析法的基本原理;2.掌握LL(1)分析表的构造方法;3.掌握LL(1)驱动程序的构造方法。
一.实验内容及要求根据某一文法编制调试LL(1)分析程序,以便对任意输入的符号串进行分析。
本次实验的目的主要是加深对预测分析LL(1)分析法的理解。
对下列文法,用LL(1)分析法对任意输入的符号串进行分析:(1)E->TG(2)G->+TG(3)G->ε(4)T->FS(5)S->*FS(6)S->ε(7)F->(E)(8)F->i程序输入一以#结束的符号串(包括+*()i#),如:i+i*i#。
输出过程如下:步骤分析栈剩余输入串所用产生式1 E i+i*i# E->TG... ... ... ...二.实验过程及结果代码如下:#include<iostream>#include "edge.h"using namespace std;edge::edge(){cin>>left>>right;rlen=right.length();if(NODE.find(left)>NODE.length())NODE+=left;}string edge::getlf(){return left;}string edge::getrg(){return right;}string edge::getfirst(){return first;}string edge::getfollow(){return follow;}string edge::getselect(){return select;}string edge::getro(){string str;str+=right[0];return str;}int edge::getrlen(){return right.length();}void edge::newfirst(string w){int i;for(i=0;i<w.length();i++)if(first.find(w[i])>first.length())first+=w[i];}void edge::newfollow(string w){int i;for(i=0;i<w.length();i++)if(follow.find(w[i])>follow.length()&&w[i]!='@')follow+=w[i];}void edge::newselect(string w){int i;for(i=0;i<w.length();i++)if(select.find(w[i])>select.length()&&w[i]!='@') select+=w[i];}void edge::delfirst(){int i=first.find('@');first.erase(i,1);}int SUM;string NODE,ENODE;//计算firstvoid first(edge ni,edge *n,int x){int i,j;for(j=0;j<SUM;j++){if(ni.getlf()==n[j].getlf()){if(NODE.find(n[j].getro())<NODE.length()){for(i=0;i<SUM;i++)if(n[i].getlf()==n[j].getro())first(n[i],n,x);}elsen[x].newfirst(n[j].getro());}}}//计算followvoid follow(edge ni,edge *n,int x){int i,j,k,s;string str;for(i=0;i<ni.getrlen();i++){s=NODE.find(ni.getrg()[i]);if(s<NODE.length()&&s>-1) //是非终结符if(i<ni.getrlen()-1) //不在最右for(j=0;j<SUM;j++)if(n[j].getlf().find(ni.getrg()[i])==0){if(NODE.find(ni.getrg()[i+1])<NODE.length()){for(k=0;k<SUM;k++)if(n[k].getlf().find(ni.getrg()[i+1])==0){n[j].newfollow(n[k].getfirst());if(n[k].getfirst().find("@")<n[k].getfirst().length())n[j].newfollow(ni.getfollow());}}else{str.erase();str+=ni.getrg()[i+1];n[j].newfollow(str);}}}}//计算selectvoid select(edge &ni,edge *n){int i,j;if(ENODE.find(ni.getro())<ENODE.length()){ni.newselect(ni.getro());if(ni.getro()=="@")ni.newselect(ni.getfollow());}elsefor(i=0;i<ni.getrlen();i++){for(j=0;j<SUM;j++)if(ni.getrg()[i]==n[j].getlf()[0]){ni.newselect(n[j].getfirst());if(n[j].getfirst().find('@')>n[j].getfirst().length())return;}}}//输出集合void out(string p){int i;if(p.length()==0)return;cout<<"{";for(i=0;i<p.length()-1;i++){cout<<p[i]<<",";}cout<<p[i]<<"}";}//连续输出符号void outfu(int a,string c){int i;for(i=0;i<a;i++)cout<<c;}//输出预测分析表void outgraph(edge *n,string (*yc)[50]){int i,j,k;bool flag;for(i=0;i<ENODE.length();i++){if(ENODE[i]!='@'){outfu(10," ");cout<<ENODE[i];}}outfu(10," ");cout<<"#"<<endl;int x;for(i=0;i<NODE.length();i++){outfu(4," ");cout<<NODE[i];outfu(5," ");for(k=0;k<ENODE.length();k++){flag=1;for(j=0;j<SUM;j++){if(NODE[i]==n[j].getlf()[0]){x=n[j].getselect().find(ENODE[k]);if(x<n[j].getselect().length()&&x>-1){cout<<"->"<<n[j].getrg();yc[i][k]=n[j].getrg();outfu(9-n[j].getrlen()," ");flag=0;}x=n[j].getselect().find('#');if(k==ENODE.length()-1&&x<n[j].getselect().length()&&x>-1){cout<<"->"<<n[j].getrg();yc[i][j]=n[j].getrg();}}}if(flag&&ENODE[k]!='@')outfu(11," ");}cout<<endl;}}//分析符号串int pipei(string &chuan,string &fenxi,string (*yc)[50],int &b) {char ch,a;int x,i,j,k;b++;cout<<endl<<" "<<b;if(b>9)outfu(8," ");elseoutfu(9," ");cout<<fenxi;outfu(26-chuan.length()-fenxi.length()," "); cout<<chuan;outfu(10," ");a=chuan[0];ch=fenxi[fenxi.length()-1];x=ENODE.find(ch);if(x<ENODE.length()&&x>-1){if(ch==a){fenxi.erase(fenxi.length()-1,1);chuan.erase(0,1);cout<<"'"<<a<<"'匹配";if(pipei(chuan,fenxi,yc,b))return 1;elsereturn 0;}elsereturn 0;}else{if(ch=='#'){if(ch==a){cout<<"分析成功"<<endl;return 1;}elsereturn 0;}elseif(ch=='@'){fenxi.erase(fenxi.length()-1,1);if(pipei(chuan,fenxi,yc,b))return 1;elsereturn 0;}else{i=NODE.find(ch);if(a=='#'){x=ENODE.find('@');if(x<ENODE.length()&&x>-1)j=ENODE.length()-1;elsej=ENODE.length();}elsej=ENODE.find(a);if(yc[i][j].length()){cout<<NODE[i]<<"->"<<yc[i][j];fenxi.erase(fenxi.length()-1,1);for(k=yc[i][j].length()-1;k>-1;k--)if(yc[i][j][k]!='@')fenxi+=yc[i][j][k];if(pipei(chuan,fenxi,yc,b))return 1;elsereturn 0;}elsereturn 0;}}}void main(){edge *n;string str,(*yc)[50];int i,j,k;bool flag=0;cout<<"请输入上下文无关文法的总规则数:"<<endl;cin>>SUM;cout<<"请输入具体规则(格式:左部右部,@为空):"<<endl;n=new edge[SUM];for(i=0;i<SUM;i++)for(j=0;j<n[i].getrlen();j++){str=n[i].getrg();if(NODE.find(str[j])>NODE.length()&&ENODE.find(str[j])>ENODE.length()) ENODE+=str[j];}//计算first集合for(i=0;i<SUM;i++){first(n[i],n,i);}//outfu(10,"~*~");cout<<endl;for(i=0;i<SUM;i++)if(n[i].getfirst().find("@")<n[i].getfirst().length()){if(NODE.find(n[i].getro())<NODE.length()){for(k=1;k<n[i].getrlen();k++){if(NODE.find(n[i].getrg()[k])<NODE.length()){for(j=0;j<SUM;j++){if(n[i].getrg()[k]==n[j].getlf()[0]){n[i].newfirst(n[j].getfirst());break;}}if(n[j].getfirst().find("@")>n[j].getfirst().length()){n[i].delfirst();break;}}}}}//计算follow集合for(k=0;k<SUM;k++){for(i=0;i<SUM;i++){if(n[i].getlf()==n[0].getlf())n[i].newfollow("#");follow(n[i],n,i);}for(i=0;i<SUM;i++){for(j=0;j<SUM;j++)if(n[j].getrg().find(n[i].getlf())==n[j].getrlen()-1)n[i].newfollow(n[j].getfollow());}}//计算select集合for(i=0;i<SUM;i++){select(n[i],n);}for(i=0;i<NODE.length();i++){str.erase();for(j=0;j<SUM;j++)if(n[j].getlf()[0]==NODE[i]){if(!str.length())str=n[j].getselect();else{for(k=0;k<n[j].getselect().length();k++)if(str.find(n[j].getselect()[k])<str.length()){flag=1;break;}}}}//输出cout<<endl<<"非终结符";outfu(SUM," ");cout<<"First";outfu(SUM," ");cout<<"Follow"<<endl;outfu(5+SUM,"-*-");cout<<endl;for(i=0;i<NODE.length();i++){for(j=0;j<SUM;j++)if(NODE[i]==n[j].getlf()[0]){outfu(3," ");cout<<NODE[i];outfu(SUM+4," ");out(n[j].getfirst());outfu(SUM+4-2*n[j].getfirst().length()," ");out(n[j].getfollow());cout<<endl;break;}}outfu(5+SUM,"-*-");cout<<endl<<"判定结论: ";if(flag){cout<<"该文法不是LL(1)文法!"<<endl;return;}else{cout<<"该文法是LL(1)文法!"<<endl;}//输出预测分析表cout<<endl<<"预测分析表如下:"<<endl;yc=new string[NODE.length()][50];outgraph(n,yc);string chuan,fenxi,fchuan;cout<<endl<<"请输入符号串:";cin>>chuan;fchuan=chuan;fenxi="#";fenxi+=NODE[0];i=0;cout<<endl<<"预测分析过程如下:"<<endl;cout<<"步骤";outfu(7," ");cout<<"分析栈";outfu(10," ");cout<<"剩余输入串";outfu(8," ");cout<<"推导所用产生式或匹配";if(pipei(chuan,fenxi,yc,i))cout<<endl<<"输入串"<<fchuan<<"是该文法的句子!"<<endl;elsecout<<endl<<"输入串"<<fchuan<<"不是该文法的句子!"<<endl;}截屏如下:三.实验中的问题及心得这次实验让我更加熟悉了LL(1)的工作流程以及LL(1)分析表的构造方法。
编译原理实验报告《ll(1)语法分析器构造》

规则右部首符号是终结
符
.
.
{ first[r].append(1,a); break;// 添加并结束
}
if(U.find(P[i][j])!=string::npos)// 规则右部首符号是非终结符 ,形如 X:: =Y1Y2...Yk
{
s=U.find(P[i][ j]);
//cout<<P[i][ j]<<":\n";
arfa=beta=""; for( j=0;j<100&&P[j][0]!=' ';j++) {
if(P[ j][0]==U[i]) {
if(P[ j][4]==U[i])// 产生式 j 有左递归 {
flagg=1;
.
.
for(temp=5;P[j][temp]!=' ';temp++) arfa.append(1,P[
{
int i,j,r,s,tmp;
string* first=new string[n];
char a;
int step=100;// 最大推导步数
while(step--){
// cout<<"step"<<100-step<<endl;
for(i=0;i<k;i++)
{
//cout<<P[i]<<endl;
j][temp]);
if(P[ j+1][4]==U[i]) arfa.append("|");//
编译原理实验报告LL(1)分析法

编译原理实验报告LL(1)分析法课程编译原理实验名称实验二 LL(1)分析法实验目的1.掌握LL(1)分析法的基本原理;2.掌握LL(1)分析表的构造方法;3.掌握LL(1)驱动程序的构造方法。
一.实验内容及要求根据某一文法编制调试LL(1)分析程序,以便对任意输入的符号串进行分析。
本次实验的目的主要是加深对预测分析LL(1)分析法的理解。
对下列文法,用LL(1)分析法对任意输入的符号串进行分析:(1)E->TG(2)G->+TG(3)G->ε(4)T->FS(5)S->*FS(6)S->ε(7)F->(E)(8)F->i程序输入一以#结束的符号串(包括+*()i#),如:i+i*i#。
输出过程如下:步骤分析栈剩余输入串所用产生式1 E i+i*i# E->TG... ... ... ...二.实验过程及结果代码如下:#include#include "edge.h"using namespace std;edge::edge(){cin>>left>>right;rlen=right.length();if(NODE.find(left)>NODE.length()) NODE+=left;}string edge::getlf(){return left;}string edge::getrg(){return right;}string edge::getfirst(){return first;}string edge::getfollow(){return follow;}string edge::getselect(){return select;}string edge::getro(){string str;str+=right[0];return str;}int edge::getrlen(){return right.length();}void edge::newfirst(string w){int i;for(i=0;iif(first.find(w[i])>first.length())first+=w[i];}void edge::newfollow(string w){int i;for(i=0;iif(follow.find(w[i])>follow.length()&&w[i]!='@')follow+=w[i];}void edge::newselect(string w){int i;for(i=0;iif(select.find(w[i])>select.length()&&w[i]!='@') select+=w[i];}void edge::delfirst(){int i=first.find('@');first.erase(i,1);}int SUM;string NODE,ENODE;//计算firstvoid first(edge ni,edge *n,int x){int i,j;for(j=0;j{if(ni.getlf()==n[j].getlf()){if(NODE.find(n[j].getro()){for(i=0;iif(n[i].getlf()==n[j].getro())first(n[i],n,x);}elsen[x].newfirst(n[j].getro());}}}//计算followvoid follow(edge ni,edge *n,int x){int i,j,k,s;string str;for(i=0;i{s=NODE.find(ni.getrg()[i]);if(s-1) //是非终结符if(ifor(j=0;jif(n[j].getlf().find(ni.getrg()[i])==0) {if(NODE.find(ni.getrg()[i+1]){for(k=0;kif(n[k].getlf().find(ni.getrg()[i+1])==0) {n[j].newfollow(n[k].getfirst());if(n[k].getfirst().find("@")n[j].newfollow(ni.getfollow());}}else{str.erase();str+=ni.getrg()[i+1];n[j].newfollow(str);}}}}//计算selectvoid select(edge &ni,edge *n){int i,j;if(ENODE.find(ni.getro()){ni.newselect(ni.getro());if(ni.getro()=="@")ni.newselect(ni.getfollow());}elsefor(i=0;i{for(j=0;jif(ni.getrg()[i]==n[j].getlf()[0]){ni.newselect(n[j].getfirst());if(n[j].getfirst().find('@')>n[j].getfirst().length()) return;}}}//输出集合void out(string p){int i;if(p.length()==0)return;coutfor(i=0;i{cout}cout}//连续输出符号void outfu(int a,string c){int i;for(i=0;icout}//输出预测分析表void outgraph(edge *n,string (*yc)[50]) {int i,j,k;bool flag;for(i=0;i{if(ENODE[i]!='@'){outfu(10," ");cout}}outfu(10," ");coutint x;for(i=0;i{outfu(4," ");coutoutfu(5," ");for(k=0;k{flag=1;for(j=0;j{if(NODE[i]==n[j].getlf()[0]){x=n[j].getselect().find(ENODE[k]); if(x-1){cout"yc[i][k]=n[j].getrg();outfu(9-n[j].getrlen()," ");flag=0;}x=n[j].getselect().find('#');if(k==ENODE.length()-1&&x-1) {cout"yc[i][j]=n[j].getrg();}}}if(flag&&ENODE[k]!='@')outfu(11," ");}cout}}//分析符号串int pipei(string &chuan,string &fenxi,string (*yc)[50],int &b){char ch,a;int x,i,j,k; b++; cout9) outfu(8," "); else outfu(9," "); cout-1) { if(ch==a) { fenxi.erase(fenxi.length()-1,1); chuan.erase(0,1); coutfenxi.erase(fenxi.length()-1,1); if(pipei(chuan,fenxi,yc,b)) return 1;elsereturn 0;}else{i=NODE.find(ch);if(a=='#'){x=ENODE.find('@');if(x-1) j=ENODE.length()-1; elsej=ENODE.length();}elsej=ENODE.find(a);if(yc[i][j].length()){cout"-1;k--) if(yc[i][j][k]!='@')fenxi+=yc[i][j][k];if(pipei(chuan,fenxi,yc,b)) return 1; elsereturn 0;}elsereturn 0;}}}void main(){edge *n;string str,(*yc)[50];int i,j,k;bool flag=0;cin>>SUM; coutNODE.length()&&ENODE.find(str[j])>ENODE.length())ENODE+=str[j]; } //计算first集合 for(i=0;in[j].getfirst().length()){ n[i].delfirst(); break; } } } } }for(k=0;koutfu(SUM," "); cout>chuan; fchuan=chuan; fenxi="#"; fenxi+=NODE[0]; i=0; coutoutfu(7," ");coutoutfu(10," ");coutoutfu(8," ");coutif(pipei(chuan,fenxi,yc,i))coutelsecout}截屏如下:三.实验中的问题及心得这次实验让我更加熟悉了LL(1)的工作流程以及LL(1)分析表的构造方法。
编译原理实验二语法分析器LL(1)实现

编译原理程序设计实验报告——表达式语法分析器的设计班级:计算机1306班:涛学号:20133967 实验目标:用LL(1)分析法设计实现表达式语法分析器实验容:⑴概要设计:通过对实验一的此法分析器的程序稍加改造,使其能够输出正确的表达式的token序列。
然后利用LL(1)分析法实现语法分析。
⑵数据结构:int op=0; //当前判断进度char ch; //当前字符char nowword[10]=""; //当前单词char operate[4]={'+','-','*','/'}; //运算符char bound[2]={'(',')'}; //界符struct Token{int code;char ch[10];}; //Token定义struct Token tokenlist[50]; //Token数组struct Token tokentemp; //临时Token变量struct Stack //分析栈定义{char *base;char *top;int stacksize;};⑶分析表及流程图逆序压栈int IsLetter(char ch) //判断ch是否为字母int IsDigit(char ch) //判断ch是否为数字int Iskey(char *string) //判断是否为关键字int Isbound(char ch) //判断是否为界符int Isboundnum(char ch) //给出界符所在token值int init(STack *s) //栈初始化int pop(STack *s,char *ch) //弹栈操作int push(STack *s,char ch) //压栈操作void LL1(); //分析函数源程序代码:(加入注释)#include<stdio.h>#include<string.h>#include<ctype.h>#include<windows.h>#include <stdlib.h>int op=0; //当前判断进度char ch; //当前字符char nowword[10]=""; //当前单词char operate[4]={'+','-','*','/'}; //运算符char bound[2]={'(',')'}; //界符struct Token{int code;char ch[10];}; //Token定义struct Token tokenlist[50]; //Token数组struct Token tokentemp; //临时Token变量struct Stack //分析栈定义{char *base;char *top;int stacksize;};typedef struct Stack STack;int init(STack *s) //栈初始化{(*s).base=(char*)malloc(100*sizeof(char)); if(!(*s).base)exit(0);(*s).top=(*s).base;(*s).stacksize=100;printf("初始化栈\n");return 0;}int pop(STack *s,char *ch) //弹栈操作{if((*s).top==(*s).base){printf("弹栈失败\n");return 0;(*s).top--;*ch=*((*s).top);printf("%c",*ch);return 1;}int push(STack *s,char ch) //压栈操作{if((*s).top-(*s).base>=(*s).stacksize){(*s).base=(char*)realloc((*s).base,((*s).stacksize+10)*sizeof(char)); if(!(*s).base)exit(0);(*s).top=(*s).base+(*s).stacksize;(*s).stacksize+=10;}*(*s).top=ch;*(*s).top++;return 1;}void LL1();int IsLetter(char ch) //判断ch是否为字母{int i;for(i=0;i<=45;i++)if ((ch>='a'&&ch<='z')||(ch>='A'&&ch<='Z'))return 1;return 0;}int IsDigit(char ch) //判断ch是否为数字{int i;for(i=0;i<=10;i++)if (ch>='0'&&ch<='9')return 1;return 0;}int Isbound(char ch) //判断是否为界符{int i;for(i=0;i<2;i++)if(ch==bound[i]){return i+1;}}return 0;}int Isoperate(char ch) //判断是否为运算符{int i;for(i=0;i<4;i++){if(ch==operate[i]){return i+3;}}return 0;}int main(){FILE *fp;int q=0,m=0;char sour[200]=" ";printf("请将源文件置于以下位置并按以下方式命名:F:\\2.txt\n");if((fp=fopen("F:\\2.txt","r"))==NULL){printf("文件未找到!\n");}else{while(!feof(fp)){if(isspace(ch=fgetc(fp)));else{sour[q]=ch;q++;}}}int p=0;printf("输入句子为:\n");for(p;p<=q;p++)printf("%c",sour[p]);}printf("\n");int state=0,nowlen=0;BOOLEAN OK=TRUE,ERR=FALSE;int i,flagpoint=0;for(i=0;i<q;i++){if(sour[i]=='#')tokenlist[m].code=='#';switch(state){case 0:ch=sour[i];if(Isbound(ch)){if(ERR){printf("无法识别\n");ERR=FALSE;OK=TRUE;}else if(!OK){printf("<10,%s>标识符\n",nowword); tokentemp.code=10;tokentemp.ch[10]=nowword[10];tokenlist[m]=tokentemp;m++;OK=TRUE;}state=4;}else if(IsDigit(ch)){if(OK){memset(nowword,0,strlen(nowword)); nowlen=0;nowword[nowlen]=ch;nowlen++;state=3;OK=FALSE;break;}else{nowword[nowlen]=ch;nowlen++;}}else if(IsLetter(ch)){if(OK){memset(nowword,0,strlen(nowword));nowlen=0;nowword[nowlen]=ch;nowlen++;OK=FALSE;}else{nowword[nowlen]=ch;nowlen++;}}else if(Isoperate(ch)){if(!OK){printf("<10,%s>标识符\n",nowword);tokentemp.code=10;tokentemp.ch[10]=nowword[10];tokenlist[m]=tokentemp;m++;OK=TRUE;}printf("<%d,%c>运算符\n",Isoperate(ch),ch); tokentemp.code=Isoperate(ch);tokentemp.ch[10]=ch;tokenlist[m]=tokentemp;m++;}break;case 3:if(IsLetter(ch)){printf("错误\n");nowword[nowlen]=ch;nowlen++;ERR=FALSE;state=0;break;}if(IsDigit(ch=sour[i])){nowword[nowlen]=ch;nowlen++;}else if(sour[i]=='.'&&flagpoint==0){flagpoint=1;nowword[nowlen]=ch;nowlen++;}else{printf("<20,%s>数字\n",nowword);i--;state=0;OK=TRUE;tokentemp.code=20;tokentemp.ch[10]=nowword[10];tokenlist[m]=tokentemp;m++;}break;case 4:i--;printf("<%d,%c>界符\n",Isbound(ch),ch); tokentemp.code=Isbound(ch);tokentemp.ch[10]=ch;tokenlist[m]=tokentemp;m++;state=0;OK=TRUE;break;}}printf("tokenlist值为%d\n",m);int t=0;tokenlist[m+1].code='r';m++;for(t;t<m;t++){printf("tokenlist%d值为%d\n",t,tokenlist[t].code);}LL1();printf("tokenlist值为%d\n",m);if(op+1==m)printf("OK!!!");elseprintf("WRONG!!!");return 0;}void LL1(){STack s;init(&s);push(&s,'#');push(&s,'E');char ch;int flag=1;do{pop(&s,&ch);printf("输出栈顶为%c\n",ch);printf("输出栈顶为%d\n",ch);printf("当前p值为%d\n",op);if((ch=='(')||(ch==')')||(ch=='+')||(ch=='-')||(ch=='*')||(ch=='/')||(ch==10)||(ch==20)) {if(tokenlist[op].code==1||tokenlist[op].code==20||tokenlist[op].code==10||tokenlist[op].cod e==2||tokenlist[op].code==3||tokenlist[op].code==4||tokenlist[op].code==5||tokenlist[op].co de==6)op++;else{printf("WRONG!!!");exit(0);}}else if(ch=='#'){if(tokenlist[op].code==0)flag=0;else{printf("WRONG!!!");exit(0);}}else if(ch=='E'){printf("进入E\n");if(tokenlist[op].code==10||tokenlist[op].code==20||tokenlist[op].code==1) {push(&s,'R');printf("将R压入栈\n");push(&s,'T');}}else if(ch=='R'){printf("进入R\n");if(tokenlist[op].code==3||tokenlist[op].code==4){push(&s,'R');push(&s,'T');printf("将T压入栈\n");push(&s,'+');}if(tokenlist[op].code==2||tokenlist[op].code==0){}}else if(ch=='T'){printf("进入T\n");if(tokenlist[op].code==10||tokenlist[op].code==20||tokenlist[op].code==1) {push(&s,'Y');push(&s,'F');}}else if(ch=='Y'){printf("进入Y\n");if(tokenlist[op].code==5||tokenlist[op].code==6){push(&s,'Y');push(&s,'F');push(&s,'*');}elseif(tokenlist[op].code==3||tokenlist[op].code==2||tokenlist[op].code==0||tokenlist[op].code= =4){}}else if(ch=='F'){printf("进入F\n");if(tokenlist[op].code==10||tokenlist[op].code==20){push(&s,10);}if(tokenlist[op].code==1){push(&s,')');push(&s,'E');push(&s,'(');}}else{printf("WRONG!!!!");exit(0);}}while(flag);}程序运行结果:(截屏)输入:((Aa+Bb)*(88.2/3))#注:如需运行请将文件放置F盘,并命名为:2.txt输出:思考问题回答:LL(1)分析法的主要问题就是要正确的将文法化为LL (1)文法。
编译原理词法分析,语法分析实验报告

编译原理实验报告一.LL(1)文法分析1.设计要求(1)对输入文法,它能判断是否为LL(1)文法,若是,则转(2);否则报错并终止;(2)输入已知文法,由程序自动生成它的LL(1)分析表;(3)对于给定的输入串,应能判断识别该串是否为给定文法的句型。
2.分析该程序可分为如下几步:(1)读入文法(2)判断正误(3)若无误,判断是否为LL(1)文法(4)若是,构造分析表;(5)由总控算法判断输入符号串是否为该文法的句型。
3.流程图开始读入文法有效?是是LL(1)文法?是判断句型报错结束4.源程序/*******************************************语法分析程序作者:xxx学号:xxx********************************************/#include<stdlib.h>#include<stdio.h>#include<string.h>/*******************************************/int count=0; /*分解的产生式的个数*/int number; /*所有终结符和非终结符的总数*/char start; /*开始符号*/char termin[50]; /*终结符号*/char non_ter[50]; /*非终结符号*/char v[50]; /*所有符号*/char left[50]; /*左部*/char right[50][50]; /*右部*/char first[50][50],follow[50][50]; /*各产生式右部的FIRST和左部的FOLLOW集合*/ char first1[50][50]; /*所有单个符号的FIRST集合*/char select[50][50]; /*各单个产生式的SELECT集合*/char f[50],F[50]; /*记录各符号的FIRST和FOLLOW是否已求过*/char empty[20]; /*记录可直接推出^的符号*/char TEMP[50]; /*求FOLLOW时存放某一符号串的FIRST集合*/int validity=1; /*表示输入文法是否有效*/int ll=1; /*表示输入文法是否为LL(1)文法*/int M[20][20]; /*分析表*/char choose; /*用户输入时使用*/char empt[20]; /*求_emp()时使用*/char fo[20]; /*求FOLLOW集合时使用*//*******************************************判断一个字符是否在指定字符串中********************************************/int in(char c,char *p){int i;if(strlen(p)==0)return(0);for(i=0;;i++){if(p[i]==c)return(1); /*若在,返回1*/if(i==strlen(p))return(0); /*若不在,返回0*/}}/*******************************************得到一个不是非终结符的符号********************************************/char c(){char c='A';while(in(c,non_ter)==1)c++;return(c);}/*******************************************分解含有左递归的产生式********************************************/void recur(char *point){ /*完整的产生式在point[]中*/int j,m=0,n=3,k;char temp[20],ch;ch=c(); /*得到一个非终结符*/k=strlen(non_ter);non_ter[k]=ch;non_ter[k+1]='\0';for(j=0;j<=strlen(point)-1;j++){if(point[n]==point[0]){ /*如果‘|’后的首符号和左部相同*/ for(j=n+1;j<=strlen(point)-1;j++){while(point[j]!='|'&&point[j]!='\0')temp[m++]=point[j++];left[count]=ch;memcpy(right[count],temp,m);right[count][m]=ch;right[count][m+1]='\0';m=0;count++;if(point[j]=='|'){n=j+1;break;}}}else{ /*如果‘|’后的首符号和左部不同*/ left[count]=ch;right[count][0]='^';right[count][1]='\0';count++;for(j=n;j<=strlen(point)-1;j++){if(point[j]!='|')temp[m++]=point[j];else{left[count]=point[0];memcpy(right[count],temp,m);right[count][m]=ch;right[count][m+1]='\0';printf(" count=%d ",count);m=0;count++;}}left[count]=point[0];memcpy(right[count],temp,m);right[count][m]=ch;right[count][m+1]='\0';count++;m=0;}}}/*******************************************分解不含有左递归的产生式********************************************/void non_re(char *point){int m=0,j;char temp[20];for(j=3;j<=strlen(point)-1;j++){if(point[j]!='|')temp[m++]=point[j];else{left[count]=point[0];memcpy(right[count],temp,m);right[count][m]='\0';m=0;count++;}}left[count]=point[0];memcpy(right[count],temp,m);right[count][m]='\0';count++;m=0;}/*******************************************读入一个文法********************************************/ char grammer(char *t,char *n,char *left,char right[50][50]) {char vn[50],vt[50];char s;char p[50][50];int i,j,k;printf("\n请输入文法的非终结符号串:");scanf("%s",vn);getchar();i=strlen(vn);memcpy(n,vn,i);n[i]='\0';printf("请输入文法的终结符号串:");scanf("%s",vt);getchar();i=strlen(vt);memcpy(t,vt,i);t[i]='\0';printf("请输入文法的开始符号:");scanf("%c",&s);getchar();printf("请输入文法产生式的条数:");scanf("%d",&i);getchar();for(j=1;j<=i;j++){printf("请输入文法的第%d条(共%d条)产生式:",j,i);scanf("%s",p[j-1]);getchar();}for(j=0;j<=i-1;j++)if(p[j][1]!='-'||p[j][2]!='>'){ printf("\ninput error!");validity=0;return('\0');} /*检测输入错误*/for(k=0;k<=i-1;k++){ /*分解输入的各产生式*/if(p[k][3]==p[k][0])recur(p[k]);elsenon_re(p[k]);}return(s);}/*******************************************将单个符号或符号串并入另一符号串********************************************/void merge(char *d,char *s,int type){ /*d是目标符号串,s是源串,type=1,源串中的‘^ ’一并并入目串;type=2,源串中的‘^ ’不并入目串*/int i,j;for(i=0;i<=strlen(s)-1;i++){if(type==2&&s[i]=='^');else{for(j=0;;j++){if(j<strlen(d)&&s[i]==d[j])break;if(j==strlen(d)){d[j]=s[i];d[j+1]='\0';}}}}}/*******************************************求所有能直接推出^的符号********************************************/void emp(char c){ /*即求所有由‘^ ’推出的符号*/ char temp[10];int i;for(i=0;i<=count-1;i++){if(right[i][0]==c&&strlen(right[i])==1){temp[0]=left[i];temp[1]='\0';merge(empty,temp,1);emp(left[i]);}}}/*******************************************求某一符号能否推出‘^ ’********************************************/int _emp(char c){ /*若能推出,返回1;否则,返回0*/ int i,j,k,result=1,mark=0;char temp[20];temp[0]=c;temp[1]='\0';merge(empt,temp,1);if(in(c,empty)==1)return(1);for(i=0;;i++){if(i==count)return(0);if(left[i]==c) /*找一个左部为c的产生式*/{j=strlen(right[i]); /*j为右部的长度*/if(j==1&&in(right[i][0],empty)==1)else if(j==1&&in(right[i][0],termin)==1)return(0);else{for(k=0;k<=j-1;k++)if(in(right[i][k],empt)==1)mark=1;if(mark==1)continue;else{for(k=0;k<=j-1;k++){result*=_emp(right[i][k]);temp[0]=right[i][k];temp[1]='\0';merge(empt,temp,1);}}}if(result==0&&i<count)continue;else if(result==1&&i<count)return(1);}}}/*******************************************判断读入的文法是否正确********************************************/int judge(){int i,j;for(i=0;i<=count-1;i++){if(in(left[i],non_ter)==0){ /*若左部不在非终结符中,报错*/ printf("\nerror1!");validity=0;return(0);}for(j=0;j<=strlen(right[i])-1;j++){if(in(right[i][j],non_ter)==0&&in(right[i][j],termin)==0&&right[i][j]!='^'){ /*若右部某一符号不在非终结符、终结符中且不为‘^ ’,报错*/ printf("\nerror2!");validity=0;return(0);}}}return(1);}/*******************************************求单个符号的FIRST********************************************/void first2(int i){ /*i为符号在所有输入符号中的序号*/char c,temp[20];int j,k,m;c=v[i];char ch='^';emp(ch);if(in(c,termin)==1) /*若为终结符*/{first1[i][0]=c;first1[i][1]='\0';}else if(in(c,non_ter)==1) /*若为非终结符*/{for(j=0;j<=count-1;j++){if(left[j]==c){if(in(right[j][0],termin)==1||right[j][0]=='^'){temp[0]=right[j][0];temp[1]='\0';merge(first1[i],temp,1);}else if(in(right[j][0],non_ter)==1){if(right[j][0]==c)continue;for(k=0;;k++)if(v[k]==right[j][0])break;if(f[k]=='0'){first2(k);f[k]='1';}merge(first1[i],first1[k],2);for(k=0;k<=strlen(right[j])-1;k++){empt[0]='\0';if(_emp(right[j][k])==1&&k<strlen(right[j])-1){for(m=0;;m++)if(v[m]==right[j][k+1])break;if(f[m]=='0'){first2(m);f[m]='1';}merge(first1[i],first1[m],2);}else if(_emp(right[j][k])==1&&k==strlen(right[j])-1){temp[0]='^';temp[1]='\0';merge(first1[i],temp,1);}elsebreak;}}}}}f[i]='1';}/*******************************************求各产生式右部的FIRST********************************************/void FIRST(int i,char *p){int length;int j,k,m;char temp[20];length=strlen(p);if(length==1) /*如果右部为单个符号*/ {if(p[0]=='^'){if(i>=0){first[i][0]='^';first[i][1]='\0';}else{TEMP[0]='^';TEMP[1]='\0';}}else{for(j=0;;j++)if(v[j]==p[0])break;if(i>=0){memcpy(first[i],first1[j],strlen(first1[j]));first[i][strlen(first1[j])]='\0';}else{memcpy(TEMP,first1[j],strlen(first1[j]));TEMP[strlen(first1[j])]='\0';}}}else /*如果右部为符号串*/{for(j=0;;j++)if(v[j]==p[0])break;if(i>=0)merge(first[i],first1[j],2);elsemerge(TEMP,first1[j],2);for(k=0;k<=length-1;k++){empt[0]='\0';if(_emp(p[k])==1&&k<length-1){for(m=0;;m++)if(v[m]==right[i][k+1])break;if(i>=0)merge(first[i],first1[m],2);elsemerge(TEMP,first1[m],2);}else if(_emp(p[k])==1&&k==length-1){temp[0]='^';temp[1]='\0';if(i>=0)merge(first[i],temp,1);elsemerge(TEMP,temp,1);}else if(_emp(p[k])==0)break;}}}/*******************************************求各产生式左部的FOLLOW********************************************/ void FOLLOW(int i){int j,k,m,n,result=1;char c,temp[20];c=non_ter[i]; /*c为待求的非终结符*/ temp[0]=c;temp[1]='\0';merge(fo,temp,1);if(c==start){ /*若为开始符号*/temp[0]='#';temp[1]='\0';merge(follow[i],temp,1);}for(j=0;j<=count-1;j++){if(in(c,right[j])==1) /*找一个右部含有c的产生式*/{for(k=0;;k++)if(right[j][k]==c)break; /*k为c在该产生式右部的序号*/for(m=0;;m++)if(v[m]==left[j])break; /*m为产生式左部非终结符在所有符号中的序号*/ if(k==strlen(right[j])-1){ /*如果c在产生式右部的最后*/if(in(v[m],fo)==1){merge(follow[i],follow[m],1);continue;}if(F[m]=='0'){FOLLOW(m);F[m]='1';}merge(follow[i],follow[m],1);}else{ /*如果c不在产生式右部的最后*/for(n=k+1;n<=strlen(right[j])-1;n++){empt[0]='\0';result*=_emp(right[j][n]);}if(result==1){ /*如果右部c后面的符号串能推出^*/if(in(v[m],fo)==1){ /*避免循环递归*/merge(follow[i],follow[m],1);continue;}if(F[m]=='0'){FOLLOW(m);F[m]='1';}merge(follow[i],follow[m],1);}for(n=k+1;n<=strlen(right[j])-1;n++)temp[n-k-1]=right[j][n];temp[strlen(right[j])-k-1]='\0';FIRST(-1,temp);merge(follow[i],TEMP,2);}}}F[i]='1';}/*******************************************判断读入文法是否为一个LL(1)文法********************************************/int ll1(){int i,j,length,result=1;char temp[50];for(j=0;j<=49;j++){ /*初始化*/first[j][0]='\0';follow[j][0]='\0';first1[j][0]='\0';select[j][0]='\0';TEMP[j]='\0';temp[j]='\0';f[j]='0';F[j]='0';}for(j=0;j<=strlen(v)-1;j++)first2(j); /*求单个符号的FIRST集合*/ printf("\nfirst1:");for(j=0;j<=strlen(v)-1;j++)printf("%c:%s ",v[j],first1[j]);printf("\nempty:%s",empty);printf("\n:::\n_emp:");for(j=0;j<=strlen(v)-1;j++)printf("%d ",_emp(v[j]));for(i=0;i<=count-1;i++)FIRST(i,right[i]); /*求FIRST*/printf("\n");for(j=0;j<=strlen(non_ter)-1;j++){ /*求FOLLOW*/if(fo[j]==0){fo[0]='\0';FOLLOW(j);}}printf("\nfirst:");for(i=0;i<=count-1;i++)printf("%s ",first[i]);printf("\nfollow:");for(i=0;i<=strlen(non_ter)-1;i++)printf("%s ",follow[i]);for(i=0;i<=count-1;i++){ /*求每一产生式的SELECT集合*/ memcpy(select[i],first[i],strlen(first[i]));select[i][strlen(first[i])]='\0';for(j=0;j<=strlen(right[i])-1;j++)result*=_emp(right[i][j]);if(strlen(right[i])==1&&right[i][0]=='^')result=1;if(result==1){for(j=0;;j++)if(v[j]==left[i])break;merge(select[i],follow[j],1);}}printf("\nselect:");for(i=0;i<=count-1;i++)printf("%s ",select[i]);memcpy(temp,select[0],strlen(select[0]));temp[strlen(select[0])]='\0';for(i=1;i<=count-1;i++){ /*判断输入文法是否为LL(1)文法*/ length=strlen(temp);if(left[i]==left[i-1]){merge(temp,select[i],1);if(strlen(temp)<length+strlen(select[i]))return(0);}else{temp[0]='\0';memcpy(temp,select[i],strlen(select[i]));temp[strlen(select[i])]='\0';}}return(1);}/*******************************************构造分析表M********************************************/void MM(){int i,j,k,m;for(i=0;i<=19;i++)for(j=0;j<=19;j++)M[i][j]=-1;i=strlen(termin);termin[i]='#'; /*将#加入终结符数组*/termin[i+1]='\0';for(i=0;i<=count-1;i++){for(m=0;;m++)if(non_ter[m]==left[i])break; /*m为产生式左部非终结符的序号*/for(j=0;j<=strlen(select[i])-1;j++){if(in(select[i][j],termin)==1){for(k=0;;k++)if(termin[k]==select[i][j])break; /*k为产生式右部终结符的序号*/ M[m][k]=i;}}}}/*******************************************总控算法********************************************/void syntax(){int i,j,k,m,n,p,q;char ch;char S[50],str[50];printf("请输入该文法的句型:");scanf("%s",str);getchar();i=strlen(str);str[i]='#';str[i+1]='\0';S[0]='#';S[1]=start;S[2]='\0';j=0;ch=str[j];while(1){if(in(S[strlen(S)-1],termin)==1){if(S[strlen(S)-1]!=ch){printf("\n该符号串不是文法的句型!");return;}else if(S[strlen(S)-1]=='#'){printf("\n该符号串是文法的句型.");return;}else{S[strlen(S)-1]='\0';j++;ch=str[j];}}else{for(i=0;;i++)if(non_ter[i]==S[strlen(S)-1])break;for(k=0;;k++){if(termin[k]==ch)break;if(k==strlen(termin)){printf("\n词法错误!");return;}}if(M[i][k]==-1){printf("\n语法错误!");return;}else{m=M[i][k];if(right[m][0]=='^')S[strlen(S)-1]='\0';else{p=strlen(S)-1;q=p;for(n=strlen(right[m])-1;n>=0;n--)S[p++]=right[m][n];S[q+strlen(right[m])]='\0';}}}printf("\nS:%s str:",S);for(p=j;p<=strlen(str)-1;p++)printf("%c",str[p]);printf(" ");}}/*******************************************一个用户调用函数********************************************/void menu(){syntax();printf("\n是否继续?(y or n):");scanf("%c",&choose);getchar();while(choose=='y'){menu();}}/*******************************************主函数********************************************/void main(){int i,j;start=grammer(termin,non_ter,left,right); /*读入一个文法*/ printf("count=%d",count);printf("\nstart:%c",start);strcpy(v,non_ter);strcat(v,termin);printf("\nv:%s",v);printf("\nnon_ter:%s",non_ter);printf("\ntermin:%s",termin);printf("\nright:");for(i=0;i<=count-1;i++)printf("%s ",right[i]);printf("\nleft:");for(i=0;i<=count-1;i++)printf("%c ",left[i]);if(validity==1)validity=judge();printf("\nvalidity=%d",validity);if(validity==1){printf("\n文法有效");ll=ll1();printf("\nll=%d",ll);if(ll==0)printf("\n该文法不是一个LL1文法!");else{MM();printf("\n");for(i=0;i<=19;i++)for(j=0;j<=19;j++)if(M[i][j]>=0)printf("M[%d][%d]=%d ",i,j,M[i][j]);printf("\n");menu();}}}5.执行结果(1)输入一个文法(2)输入一个符号串(3)再次输入一个符号串,然后退出程序二.词法分析一、问题描述识别简单语言的单词符号识别简单语言的基本字、标识符、无符号整数、运算符和界符。
编译原理语法分析实验报告
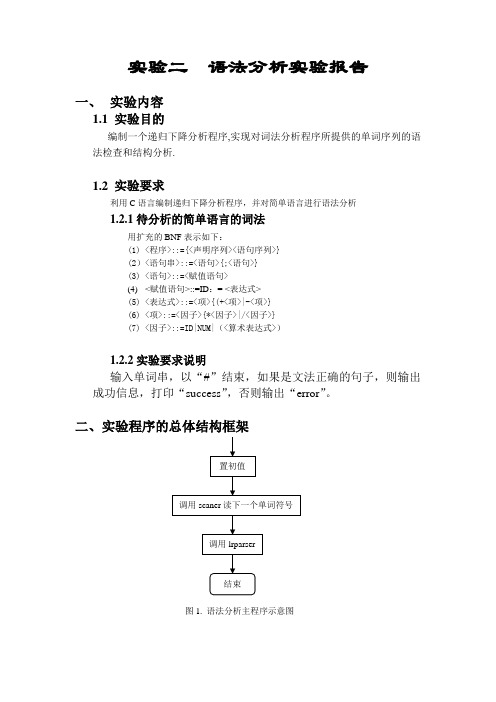
实验二语法分析实验报告一、实验内容1.1 实验目的编制一个递归下降分析程序,实现对词法分析程序所提供的单词序列的语法检查和结构分析.1.2 实验要求利用C语言编制递归下降分析程序,并对简单语言进行语法分析1.2.1待分析的简单语言的词法用扩充的BNF表示如下:(1) <程序>::={<声明序列><语句序列>}(2)<语句串>::=<语句>{;<语句>}(3) <语句>::=<赋值语句>(4) <赋值语句>::=ID:= <表达式>(5) <表达式>::=<项>{(+<项>|-<项>}(6) <项>::=<因子>{*<因子>|/<因子>}(7) <因子>::=ID|NUM|(<算术表达式>)1.2.2实验要求说明输入单词串,以“#”结束,如果是文法正确的句子,则输出成功信息,打印“success”,否则输出“error”。
二、实验程序的总体结构框架图1. 语法分析主程序示意图图2.递归下降分析程序示意图图5. expression表达式分析函数示意图图6.term分析函数示意图三、关键技术的实现方法Scanner函数定义已在实验一给出,本实验不再重复给出void Irparser(){kk=0;if(syn==1){scaner();yucu();if(syn==6){scaner();if(syn==0 && (kk==0)) cout<<"success!"<<endl;}else{if(kk!=1)cout<<"缺end!"<<endl;kk=1;}}else {cout<<"缺begin!"<<endl;kk=1;}return;}void yucu(){statement();while(syn==26){scaner();statement();}return;}void statement() {if(syn==10){scaner();if(syn==18){scaner();expression();}else{cout<<"赋值号错误"<<endl;kk=1;}}else{cout<<"语句错误"<<endl;kk=1;}return;}void expression(){term();while((syn==13)||(syn==14)){scaner();term();}return;}void term(){factor();while((syn==15)||(syn==16)){scaner();factor();}return;}void factor(){if((syn==10)||(syn==11))scaner();else if(syn==27){scaner();expression();if(syn==28)scaner();else{cout<<")错误"<<endl;kk=1;}}else{cout<<"表达式错误"<<endl;kk=1;}return;}void main(){p=0;cout<<"Please input string"<<endl;do{cin.get(ch);if(ch!=”\n”)prog[p++]=ch;}while(ch!='#');p=0;scaner();Irparser();}四、实验心得语法分析是编译过程的核心部分,它的主要功能是按照程序语言的语法规则,从由词法分析输出的源程序符号串中识别出各类语法成分,同时进行语法检查,为语义分析和代码生成做准备。
LL(1)语法分析实验报告

编译原理实验报告
(1)设计思路
输入文法规则、非终结符和终结符先求出first集合,然后根据first集合和文法规则再求出follow集合,最后求出LL(1)预测分析表,最后通过分析表识别字符串是否符合文法规则。
(2)流程图
(3)具体过程:
(a)first和follow集合的计算:
对G中每个文法符号X∈VT∪VN,构造FIRST(X)。
连续使用下述规则,直至每个FIRST集合不再增大:
a、若X∈ VT,则FIRST(X)={X};
b、若X∈ VN,且有产生式X→a…,则把a加入FIRST(X) ;若X→ε也是一条产生式,则把ε也加入
c、若X→Y…是一个产生式且Y∈ VN,则把FIRST(Y)中的所有非ε元素都加入FIRST(X)中;若X→Y1Y2…Yk是一个产生式,Y1,Y2,…,Yi-1都是非终结符,而且,对任意j(1≤j≤i-1),FIRST(Yj)都含有ε,则把FIRST(Yi)
(2)产生各个符合的FIRST集合及FOLLOW集合:
(3)构造M[A,a]
(4)输入字符串:i*(i+i)进行分析:
该字符串是文法的句型
(5)输入另一个字符串:i+i(i*i)进行分析:
该字符串不是文法的句型。
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
专题3_LL(1)语法分析设计原理与实现
李若森 13281132 计科1301
一、理论传授
语法分析的设计方法和实现原理;LL(1) 分析表的构造;LL(1)分析过程;LL(1)分析器的构造。
二、目标任务
实验项目
实现LL(1)分析中控制程序(表驱动程序);完成以下描述算术表达式的 LL(1)文法的LL(1)分析程序。
G[E]:
E→TE’
E’→ATE’|ε
T→FT’
T’→MFT’|ε
F→(E)|i
A→+|-
M→*|/
设计说明
终结符号i为用户定义的简单变量,即标识符的定义。
加减乘除即运算符。
设计要求
(1)输入串应是词法分析的输出二元式序列,即某算术表达式“专题 1”的输出结果,
输出为输入串是否为该文法定义的算术表达式的判断结果;
(2)LL(1)分析程序应能发现输入串出错;
(3)设计两个测试用例(尽可能完备,正确和出错),并给出测试结果。
任务分析
重点解决LL(1)表的构造和LL(1)分析器的实现。
三、实现过程
实现LL(1)分析器
a)将#号放在输入串S的尾部
b)S中字符顺序入栈
c)反复执行c),任何时候按栈顶Xm和输入ai依据分析表,执行下述三个动作之一。
构造LL(1)分析表
构造LL(1)分析表需要得到文法G[E]的FIRST集和FOLLOW集。
构造FIRST(α)
构造FOLLOW(A)
构造LL(1)分析表算法
根据上述算法可得G[E]的LL(1)分析表,如表3-1所示:
表3-1 LL(1)分析表
主要数据结构
pair<int, string>:
用pair<int, string>来存储单个二元组。
该对照表由专题1定义。
map<string, int>:
存储离散化后的终结符和非终结符。
vector<string>[][]:
存储LL(1)分析表
函数定义
init:
void init();
功能:
初始化LL(1)分析表,关键字及识别码对照表,离散化(非)终结符
传入参数:
(无)
传出参数:
(无)
返回值:
(无)
Parse:
bool Parse( const vector<PIS> &vec, int &ncol );
功能:
进行该行的语法分析
传入参数:
vec:该行二元式序列
传出参数:
emsg:出错信息
epos:出错标识符首字符所在位置
返回值:
是否成功解析。
是则返回true,否则返回false。
errMsg:
void errMsg( string filename, int rowNo, int colNo );功能:
向屏幕输出错误信息
传入参数:
filename:正在处理的文件的文件名称
rowNo:出错行
colNo:出错列
传出参数:
(无)
返回值:
(无)
四、程序测试
测试用例详见文件夹中test1.lexer和test2.lexer。
其中,
test1.lexer、test2.lexer为测试输入文件。
在命令行中运行parse [name]即可运行测试用例。
test1为正确文法二元序列,test2为非法文法输入二元序列。
五、心得体会
通过本次专题实验,我更加深入的理解了LL(1)语法分析器的构造以及其程序构造。
由于此种方法是以栈的形式进行语法分析处理,所以其代码量相对于递归下降语法分析少了许多,但也是因为用了栈作为语法处理的数据结构导致其报错信息只能提供错误位置,很难像递归下降那样精准的报出错误信息。
在像程序中输入LL(1)分析表时因为有些非终结符是多字符的,所以无法简单的按照单字节对非终结符进行处理。
因此我将每个非终结符和终结符用一个字符串表示,在分析表中每个格子都是一个字符串序列,因此免除了许多不必要的处理,使得编写更加容易。
目前该工程已上传至我的Github仓库中。
附录
[1]parse.cpp和parse.h为算符优先分析程序模块
[2]main.cpp为输入输出处理模块
[3]parse.exe为项目生成可执行文件
[4]makefile为项目编译文件
[5]ntable.txt为关键字及标识符对照表配置文件
[6]test1.lexer和test2.lexer为项目测试样例。