《数据结构与算法 Python精品课程》第二章:算法分析
数据结构与算法python语言实现

数据结构与算法python语言实现数据结构,顾名思义,是一种组织数据的方式。
在计算机科学中,数据结构是对计算机中数据的组织、存储和访问的描述,从而使得数据能够更加高效的被利用。
算法则是指一定的计算步骤,用来解决特定类型问题的方法。
结构和算法之间的关系紧密相连,一个好的数据结构可以给出高效的算法实现,而一个好的算法可以在一定的时间内解决大规模问题。
本篇文章主要介绍数据结构与算法在Python语言中的实现。
1. 线性表线性表是一种线性结构,它是多个数据元素按照特定的顺序排列而成,如数组。
Python中列表(list)是一种内置的线性数据结构,支持常见的插入、删除、查找等操作,同时还提供了丰富的方法和函数。
2. 栈栈是一种先进后出(FILO)的结构,只能在表尾进行插入和删除操作。
Python可以用列表(list)模拟栈,列表提供了append()方法作为入栈操作,pop()为出栈操作。
3. 队列队列是一种先进先出(FIFO)的结构,只能在表头和表尾进行插入和删除操作。
在Python中,可以使用collections模块中的deque类实现队列,或者使用列表(list)的pop(0)和append()方法,不过使用deque性能更优。
4. 树树是一种非线性结构,由根节点和若干子树组成。
Python中可以用字典(dictionary)来实现一个树,其中字典的键表示节点,值表示该节点的子节点。
常用的树结构包括二叉树、平衡树等。
5. 图图是一种非线性结构,由若干个节点和它们之间的边组成。
Python中可以使用字典(dictionary)和内置的set类分别表示图的节点和边,或者使用第三方库networkx实现复杂的图算法。
以上仅是数据结构和算法在Python中的简单介绍和实现,还有许多高级数据结构和算法,如哈希表、堆等,可以通过深入学习和实践进一步掌握。
数据结构与算法分析实验报告

数据结构与算法分析实验报告一、实验目的本次实验旨在通过实际操作和分析,深入理解数据结构和算法的基本概念、原理和应用,提高解决实际问题的能力,培养逻辑思维和编程技巧。
二、实验环境本次实验使用的编程语言为 Python,使用的开发工具为 PyCharm。
操作系统为 Windows 10。
三、实验内容(一)线性表的实现与操作1、顺序表的实现使用数组实现顺序表,包括插入、删除、查找等基本操作。
通过实验,理解了顺序表在内存中的存储方式以及其操作的时间复杂度。
2、链表的实现实现了单向链表和双向链表,对链表的节点插入、删除和遍历进行了实践。
体会到链表在动态内存管理和灵活操作方面的优势。
(二)栈和队列的应用1、栈的实现与应用用数组和链表分别实现栈,并通过表达式求值的例子,展示了栈在计算中的作用。
2、队列的实现与应用实现了顺序队列和循环队列,通过模拟银行排队的场景,理解了队列的先进先出特性。
(三)树和二叉树1、二叉树的遍历实现了先序、中序和后序遍历算法,并对不同遍历方式的结果进行了分析和比较。
2、二叉搜索树的操作构建了二叉搜索树,实现了插入、删除和查找操作,了解了其在数据快速查找和排序中的应用。
(四)图的表示与遍历1、邻接矩阵和邻接表表示图分别用邻接矩阵和邻接表来表示图,并比较了它们在存储空间和操作效率上的差异。
2、图的深度优先遍历和广度优先遍历实现了两种遍历算法,并通过对实际图结构的遍历,理解了它们的应用场景和特点。
(五)排序算法的性能比较1、常见排序算法的实现实现了冒泡排序、插入排序、选择排序、快速排序和归并排序等常见的排序算法。
2、算法性能分析通过对不同规模的数据进行排序实验,比较了各种排序算法的时间复杂度和空间复杂度。
四、实验过程及结果(一)线性表1、顺序表在顺序表的插入操作中,如果在表头插入元素,需要将后面的元素依次向后移动一位,时间复杂度为 O(n)。
删除操作同理,在表头删除元素时,时间复杂度也为 O(n)。
少儿python课程大纲

少儿python课程大纲Python是一种简单易学的编程语言,被广泛应用于各个领域。
为了满足儿童对编程学习的需求,少儿Python课程应运而生。
本文将为大家介绍少儿Python课程的大纲,旨在帮助家长和教育者了解课程内容及其教学方法。
一、课程概述少儿Python课程旨在培养孩子的逻辑思维能力和计算思维技能。
通过学习Python编程,孩子们能够开发创造力,提升问题解决能力,培养团队协作和沟通能力。
课程内容包括Python基础语法、数据结构、算法设计、图形化编程等。
二、课程目标1. 培养孩子的逻辑思维能力,引导学生按照程序设计思维解决问题;2. 培养孩子的计算思维能力,提升他们的抽象思维和创新能力;3. 培养孩子的团队协作能力,鼓励他们在项目中合作与分享;4. 培养孩子的自学能力,帮助他们构建有效的学习方法与习惯。
三、课程内容1. Python基础a. Python环境配置:安装Python解释器,操作系统选择与配置;b. 变量和数据类型:数字、字符串、列表、字典等;c. 条件语句与循环结构:if语句、for循环、while循环等;d. 函数与模块:自定义函数的创建和使用,常用Python模块的应用。
2. 数据结构与算法a. 栈和队列:数据结构的理解与应用,基本操作的实现;b. 链表与树:数据结构的实现与应用,节点插入和删除;c. 排序与查找算法:常见排序算法(如冒泡排序、快速排序)、二分查找等;d. 递归与回溯:理解递归的概念,应用于问题求解过程。
3. 图形化编程a. Turtle库:使用Python的Turtle库绘制简单图形;b. Pygame库:利用Pygame库创建动画和简单的游戏。
四、教学方法1. 理论讲解:通过课堂讲解,向学生介绍Python的基本概念和知识点;2. 编程实践:通过编写小程序,锻炼学生的实际操作能力;3. 项目实践:组织学生动手完成一些小型项目,培养他们的团队协作和问题解决能力;4. 实例分析:通过分析实际案例,引导学生理解编程应用的实际意义。
数据结构课程教学大纲
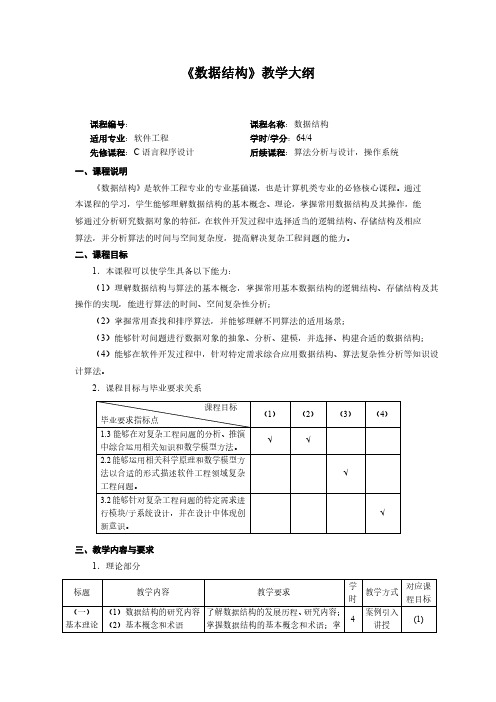
《数据结构》教学大纲课程编号:课程名称:数据结构适用专业:软件工程学时/学分:64/4先修课程:C语言程序设计后续课程:算法分析与设计,操作系统一、课程说明《数据结构》是软件工程专业的专业基础课,也是计算机类专业的必修核心课程。
通过本课程的学习,学生能够理解数据结构的基本概念、理论,掌握常用数据结构及其操作,能够通过分析研究数据对象的特征,在软件开发过程中选择适当的逻辑结构、存储结构及相应算法,并分析算法的时间与空间复杂度,提高解决复杂工程问题的能力。
二、课程目标1.本课程可以使学生具备以下能力:(1)理解数据结构与算法的基本概念,掌握常用基本数据结构的逻辑结构、存储结构及其操作的实现,能进行算法的时间、空间复杂性分析;(2)掌握常用查找和排序算法,并能够理解不同算法的适用场景;(3)能够针对问题进行数据对象的抽象、分析、建模,并选择、构建合适的数据结构;(4)能够在软件开发过程中,针对特定需求综合应用数据结构、算法复杂性分析等知识设计算法。
2.课程目标与毕业要求关系三、教学内容与要求1.理论部分2.实验部分四、课程目标考核评价方式及标准1.成绩评定方法及课程目标达成考核评价方式(1)成绩评定方法成绩评定依据期末考试成绩、平时成绩(实验、作业、测试、课堂互动、自主学习等)进行核定。
期末考试成绩占总评成绩的60%,平时成绩占总评成绩的40%。
(2)课程目标达成考核评价方式2.课程目标与考核内容3.考核标准(1)课程考试考核与评价标准(2)实验考核标准(3)作业考核标准五、参考书目[1]李春葆. 数据结构C语言版(第2版)[M]. 北京: 清华大学出版社. 2017.[2]严蔚敏, 吴伟民. 数据结构C语言版[M]. 北京: 清华大学出版社. 2012.[3]Weiss M.Allen. 数据结构与算法分析:C语言描述(原书第2版). 北京: 机械工业出版社. 2017.[4]陈越. 数据结构(第2版)[M]. 北京: 高等教育出版社. 2016.[5](美)Bruno R.Preiss著; 胡广斌等译. 数据结构与算法: 面向对象的C++设计模式[M].北京: 电子工业出版社. 2003.[6](美)Thomas H.Cormen, Charles E.Leiserson, Ronald L.Rivest, et al.著; 王刚, 邹恒明, 殷建平等译. 算法导论(原书第3版)[M]. 北京: 机械工业出版社. 2013.[7]殷人昆. 数据结构: 用面向对象方法与C++语言描述(第2版)[M]. 北京: 清华大学出版社. 2016.课程负责人:专业负责人:教学院长:。
数据结构与算法python版 pdf裘宗燕

在Python中实现数据结构和算法需要先了解数据结构和算法的基本概念。
以下是一些Python中常见的数据结构和算法的示例:1.数组(Array):在Python中,可以使用列表(list)来实现数组。
例如,以下是一个包含整数的数组:python复制代码arr = [1, 2, 3, 4, 5]2.链表(Linked List):链表是一种线性数据结构,其中每个元素包含数据和指向下一个元素的指针。
在Python中,可以使用类来实现链表。
例如,以下是一个简单的单向链表:python复制代码class Node:def__init__(self, data):self.data = dataself.next = Noneclass LinkedList:def__init__(self):self.head = None3.栈(Stack):栈是一种后进先出(LIFO)的数据结构。
在Python中,可以使用列表来实现栈。
例如,以下是一个简单的栈:python复制代码stack = []stack.append(1)stack.append(2)stack.append(3)print(stack.pop()) # 输出:3print(stack) # 输出:[1, 2]4.队列(Queue):队列是一种先进先出(FIFO)的数据结构。
在Python中,可以使用列表来实现队列。
例如,以下是一个简单的队列:python复制代码queue = []queue.append(1)queue.append(2)queue.append(3)print(queue.pop(0)) # 输出:1print(queue) # 输出:[2, 3]5.二叉树(Binary Tree):二叉树是一种树形数据结构,其中每个节点最多有两个子节点。
在Python中,可以使用类来实现二叉树。
例如,以下是一个简单的二叉树:python复制代码class Node:def__init__(self, data):self.data = dataself.left = Noneself.right = None。
计算机专业英语教案

计算机专业英语教案第一章:计算机科学简介1.1 教学目标了解计算机科学的基本概念和发展历程。
掌握计算机科学领域的关键技术。
能够阅读和理解计算机科学相关的英文文献。
1.2 教学内容计算机科学的定义和发展历程。
计算机科学领域的关键技术,如算法、数据结构、编程语言、软件工程、等。
计算机科学领域的著名人物和他们的贡献。
1.3 教学方法采用讲授法介绍计算机科学的基本概念和发展历程。
通过案例分析法讲解计算机科学领域的关键技术。
引导学生阅读和理解计算机科学相关的英文文献。
1.4 教学资源教材:《计算机科学概论》辅助材料:相关领域的英文文献、案例分析等。
1.5 教学评价课堂参与度:提问、讨论等。
课程报告:分析一个计算机科学领域的关键技术。
第二章:编程语言基础2.1 教学目标了解编程语言的基本概念和分类。
掌握常见编程语言的基本语法和特性。
能够阅读和理解编程语言相关的英文文献。
2.2 教学内容编程语言的定义和分类。
常见编程语言的基本语法和特性,如Python、Java、C++等。
编程语言的发展趋势和新技术。
2.3 教学方法采用讲授法介绍编程语言的基本概念和分类。
通过编程实践法讲解常见编程语言的基本语法和特性。
引导学生阅读和理解编程语言相关的英文文献。
2.4 教学资源教材:《编程语言基础》辅助材料:相关领域的英文文献、编程实践案例等。
2.5 教学评价课堂参与度:提问、讨论等。
编程实践:编写简单的程序,展示对编程语言的理解。
第三章:数据结构与算法3.1 教学目标了解数据结构的基本概念和常见类型。
掌握常见算法的原理和实现。
能够阅读和理解数据结构与算法相关的英文文献。
3.2 教学内容数据结构的基本概念和常见类型,如数组、链表、栈、队列、树、图等。
常见算法的原理和实现,如排序算法、查找算法、动态规划等。
算法分析的基本概念和方法。
3.3 教学方法采用讲授法介绍数据结构的基本概念和常见类型。
通过算法实现和分析讲解常见算法的原理和实现。
《图解Python数据结构与算法课件》

图:定义、图的表示方法、遍 历算法
详解图的定义和不同的表示方法,如邻接矩阵和邻接表,并探讨图的遍历算 法和常见的应用场景。
排序算法:冒泡排序、选择排 序、插入排序、快速排序、归 并排序
介绍常见的排序算法,包括冒泡排序、选择排序、插入排序、快速排序和归 并排序。比较它们的优缺点和适用场景。
搜索算法:深度优先搜索、广度优先搜索、 A*算法
栈与队列:定义、应用场景、 实现
介绍栈和队列的概念及其在计算中的应用。探索它们的实现方式和特定场景 中的应用。
链表:定义、单链表、双向链 表、循环链表
深入了解链表的不同类型:单链表、双向链表和循环链表,以及它们在数据 结构中的用途和实现方法。
树:定义、二叉树、遍历算法、 应用场景
探索树的定义和不同类型,特别是二叉树,并研究树的遍历算法和在实际应 用中的应用场景。
Python数据类型回顾
回顾Python中的基本数据类型,包括数字与算法中的应用。
列表:基本操作、排序、查找
探索列表的基本操作,如添加、删除和修改元素,以及各种排序和查找算法的实现与应用。
字符串:基本操作、匹配算法
了解字符串的基本操作,例如拼接和切片,以及常见的字符串匹配算法,如 暴力匹配和KMP算法。
《图解Python数据结构与 算法课件》
本课件旨在图解Python数据结构与算法,帮助读者深入理解并掌握重要概念。 包括数据结构、算法的基本概念,Python数据类型,以及列表、字符串等的 操作和排序查找算法。
什么是数据结构和算法?
探索数据结构与算法的定义,它们在计算中的重要作用,以及为什么它们对 于Python编程至关重要。
总结与展望
总结所学内容并展望未来,鼓励读者持续探索和应用数据结构与算法的知识。
斗地主人机对战课程设计

斗地主人机对战课程设计一、课程目标知识目标:1. 让学生掌握斗地主游戏的基本规则,了解牌型、出牌顺序和胜负条件。
2. 使学生理解人工智能在斗地主游戏中的应用,了解机器学习中的决策树、强化学习等基本概念。
3. 帮助学生掌握计算机编程中与斗地主相关的算法和数据结构。
技能目标:1. 培养学生运用所学知识进行斗地主游戏策略分析的能力。
2. 提高学生运用编程语言实现斗地主游戏的简单AI的能力。
3. 培养学生团队协作、沟通表达的能力。
情感态度价值观目标:1. 培养学生对人工智能的兴趣,激发他们探索未知、挑战自我的热情。
2. 培养学生在游戏中遵守规则、公平竞争的意识,树立正确的竞技观念。
3. 引导学生学会在团队合作中相互尊重、互相学习,培养良好的团队精神。
课程性质分析:本课程以斗地主人机对战为主题,结合计算机编程和人工智能知识,旨在提高学生的编程能力和人工智能素养。
学生特点分析:学生处于高年级阶段,已具备一定的计算机编程基础和逻辑思维能力,对人工智能有一定了解,对斗地主游戏有较高的兴趣。
教学要求:1. 注重理论与实践相结合,让学生在动手实践中掌握知识。
2. 鼓励学生积极参与讨论,培养他们的思维能力和创新能力。
3. 关注学生的个体差异,因材施教,提高教学质量。
二、教学内容1. 斗地主游戏规则及策略分析:包括牌型、出牌顺序、记分规则、胜负条件等,结合实例进行讲解。
2. 人工智能基本概念:介绍决策树、强化学习等基本原理,以及它们在斗地主游戏中的应用。
3. 编程语言及算法:选用Python语言,讲解列表、字典等数据结构,以及递归、迭代等算法在斗地主AI实现中的应用。
4. 斗地主人机对战系统设计:包括游戏界面设计、牌型识别、出牌策略、胜负判定等模块的编写。
5. 人工智能斗地主AI实战:分组进行项目实践,每组设计并实现一个简单的斗地主AI,进行对战演练。
教学内容安排和进度:第一周:斗地主游戏规则及策略分析,人工智能基本概念。
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
2.1.⽬标·了解为何算法分析的重要性·能够⽤⼤“O ”表⽰法来描述算法执⾏时间·了解在Python 列表和字典类型中通⽤操作⽤⼤“O ”表⽰法表⽰的执⾏时间·了解Python 数据类型的具体实现对算法分析的影响·了解如何对简单的Python 程序进⾏执⾏时间检测2.2.什么是算法分析计算机初学者经常将⾃⼰的程序与他⼈的⽐较。
你也可能注意到了电脑程序常常看起来很相似,尤其是那些简单的程序。
⼀个有趣的问题出现了,当两个看起来不同的程序解决相同的问题时,⼀个程序会优于另⼀个吗?为了回答这个问题,我们需要记住的是,程序和它所代表的基本算法有着重要差别。
在第⼀章中我们说到,算法是问题解决的通⽤的分步的指令的聚合。
这是⼀种能解决任何问题实例的⽅法,⽐如给定⼀个特定的输⼊,算法能产⽣期望的结果。
从另⼀⽅⾯看,⼀个程序是⽤某种编程语⾔编码后的算法。
同⼀算法通过不同的程序员采⽤不同的编程语⾔能产⽣很多程序。
为进⼀步探究这种差异,请阅读接下来展⽰的函数。
这个函数解决了⼀个我们熟知的问题,计算前n 个整数的和。
其中的算法使⽤了⼀个初始值为0的累加变量的概念。
解决⽅案是遍历这n 个整数,逐个累加到累加变量。
代码2.1前n 个正整数求和(active1)现在看下⾯的foo函数。
可能第⼀眼看上去⽐较奇怪,但是进⼀步观察你会发现,这个函数所实现的功能与之前代码2.1中的函数基本相同。
看不太懂的原因是糟糕的编码。
我们没有使⽤好的变量命名来增加可读性,并且在累加过程中使⽤了多余的赋值语句。
回到前⾯我们提出的问题:是否⼀个程序会优于另⼀个?答案取决于你⾃⼰的标准。
如果你关⼼可读性,那么sum_of_n函数肯定⽐foo函数更好。
实际上,在你的编程⼊门课程上你可能见过很多这样的例⼦,因为这些课程的⽬标之⼀就是帮助你编写更具可读性的程代码2.2 另⼀种前n个正整数求和(ac ve2)def foo(tom):fred=0for bill in range(1,tom+1):barney = billfred = fred + barneyreturn fredprint (foo(10))序。
然⽽,在这门课程中,我们主要感兴趣的是算法本⾝的特性。
(我们当然希望你可以继续努⼒写出更具可读性的代码。
)算法分析主要就是从计算资源的消耗的⾓度来评判和⽐较算法。
我们想要分析两种算法并且指出哪种更好,主要考虑的是哪⼀种可以更⾼效地利⽤计算资源。
或者占⽤更少的资源。
从这个⾓度,上述两个函数实际上是基本相同的,它们都采⽤了⼀样的算法来解决累加求和问题。
从这点上看,思考我们通过计算资源这个概念真正想表达的是什么是⾮常重要的。
有两种⽅法来看待它。
⼀种是考虑算法解决问题过程中需要的存储空间或内存。
问题解决⽅案所需的存储空间通常是由问题本⾝情况影响的,然⽽,算法常常有本⾝特定的空间需求,在这种情况下,我们需要很⼩⼼地解释这种变化。
作为空间需求的⼀个可替代物,我们可以⽤算法执⾏所需时间来分析和⽐较算法。
这种⽅法有时被称为算法的“执⾏时间”或“运⾏时间”。
我们可以检测sum_of_n函数的运⾏时间的⼀种⽅法是做基准分析。
这意味着我们将监测程序运⾏出结果所需要的时间。
在Python中,我们可以考虑我们使⽤的系统通过标定开始时间和结束时间来作为标准衡量⼀个函数。
在 me模块有⼀个叫 me的函数,它能返回在某些任意起点以秒为单位的系统当前时间。
通过在开始和结束时两次调⽤这个函数,然后计算两次时间之差,我们就可以得到精确到秒(⼤多数情况为分数)的运⾏时间。
这个编码展⽰了在原始sum_of_n函数的求和前后插⼊时间调⽤的情况。
这个函数返回⼀个元组,包括累加和及计算所需时间(以秒为单位)。
如果我们连续运⾏这个函数5次,每次都完成1到10,000的累加,我们得到的结果如下:>>>for i in range(5):Print(“Sum is %d required %10.7f seconds”% sum_of_n_2(10000))Sum is 50005000 required 0.0018950 secondsSum is 50005000 required 0.0018620 secondsSum is 50005000 required 0.0019171 secondsSum is 50005000 required 0.0019162 secondsSum is 50005000 required 0.0019360 seconds>>>我们发现这个时间是相当⼀致的,执⾏这段代码平均需要0.0019秒。
那么如果我们累加到100,000会怎么样呢?⼜是这样,每次运⾏所需时间虽然更长,但⾮常⼀致,平均约为之前的10倍,进⼀步累加到1,000,000我们得到:在这种情况下,平均时间再次约为之前的10倍。
现在考虑接下来的编码,它展⽰了⼀种解决求和问题的不同的⽅法。
这个函数,sum_of_n_3,利⽤⼀个封闭⽅程去完成⽆迭代的累加到n 的计算。
代码2.3 ⽆迭代求和 >>>for i in range(5):Print(“Sum is %d required %10.7f seconds”% sum_of_n_2(100000))Sum is 5000050000 required 0.0199420 secondsSum is 5000050000 required 0.0180972 secondsSum is 5000050000 required 0.0194821 secondsSum is 5000050000 required 0.0178988 secondsSum is 5000050000 required 0.0188949 seconds>>> >>>for i in range(5):Print(“Sum is %d required %10.7f seconds”% sum_of_n_2(1000000)) Sum is 500000500000 required 0.1948988 secondsSum is 500000500000 required 0.1850290 secondsSum is 500000500000 required 0.1809771 secondsSum is 500000500000 required 0.1729250 seconds Sum is 500000500000 required 0.1646299 seconds>>>def sum_of_n_3(n):return (n * (n +1)) / 2print (sum_of_n_3(10))如果我们对sum_of_n_3做同样的基准检测,n赋5个不同的值(10000,100000,1000000,10000,000和100000000),我们得到的结果如下:Sum is 50005000 required 0.00000095 secondsSum is 5000050000 required 0.00000191 secondsSum is 500000500000 required 0.00000095 secondsSum is 50000005000000 required 0.00000095 secondsSum is 5000000050000000 required 0.00000119 seconds对于输出我们需要关注两个关键点。
第⼀,这种算法的运⾏时间⽐之前任何例⼦都短很多。
第⼆,不管n取值多少运⾏时间都⾮常⼀致。
看上去sum_of_n_3的运⾏时间⼏乎不受需要累计的数⽬的影响。
但是这个基准测试真正告诉了我们什么?直观上,我们可以看到迭代算法似乎做了更多的⼯作,因为⼀些程序步骤被重复执⾏,这可能就是它需要更长时间的原因。
此外,迭代算法所需要的运⾏时间似乎会随着n值的增⼤⽽增⼤。
然⽽,还有⼀个问题。
如果我们在不同的计算机上运⾏相同的函数,或者使⽤不同的编程语⾔,我们可能会得到不同的结果。
如果计算机⽐较⽼旧,运⾏sum_of_n_3可能还需要更长的时间。
我们需要更好的⽅法来衡量算法运⾏的时间。
基准测试技术可以计算世界运⾏时间,然⽽它并没有真的为我们提供⼀个有⽤的度量指标。
因为这个指标依赖于特定的机器、程序、运⾏时段、编译器和编程语⾔。
相反,我们需要⼀个不依赖程序或者使⽤的机器的指标。
这种度量指标将有助于判断算法优劣,并且可以⽤来⽐较算法的具体实现。
2.2.1. ⼤“O”表⽰法当我们试图⽤执⾏时间作为独⽴于具体程序或计算机的度量指标去描述⼀个算法的效率时,确定这个算法所需要的操作数或步骤数显得尤为重要。
如果把每⼀⼩步看作⼀个基本计量单位,那么⼀个算法的执⾏时间就可以表达为它解决⼀个问题所需的步骤数。
制定⼀个合适的基本计量单位是⼀个很复杂的问题,并且还要依赖于算法具体是怎样执⾏的。
当我们⽐较上述⼏个求和算法时,统计执⾏求和的赋值语句的次数可能是⼀个好的基本计量单位。
在sum_of_n函数中,赋值语句的数量是1(the_sum=0)加上n(我们执⾏the_sum=the_sum+i 的次数)。
我们可以⽤⼀个叫T的函数来表⽰赋值语句数量,如上例中T(n) = 1 + n。
变量n⼀般指“问题的规模”,可以理解为当要解决⼀个规模为n,对应n+1步操作步数的问题,所需要的时间为T(n)。
在前⼀节给出的求和函数中,⽤求和的项数来代表问题的规模是合理的。
可以认为求前100000项整数的问题规模⼤于求前1000项整数。
因此,求解⼤规模问题所需时间显然⽐求解⼩规模要多⼀些。
那么我们的⽬标就是寻找程序的运⾏时间如何随着问题规模变化。
计算机科学家对这种算法分析技术进⾏了更为深远的思考。
有限的操作次数对于T(n)函数的影响,并不如某些占据主要地位的操作部分重要。
换⾔之,当问题规模越来越⼤时,T(n)函数中的⼀部分⼏乎掩盖了其他部分对于函数的影响。
最终,这种起主导作⽤的部分⽤来对函数进⾏⽐较。
数量级函数⽤来描述当规模n增加时,T(n)函数中增长最快的部分。
这种数量级函数⼀般被称为⼤“O”表⽰法,记作O(f(n))。
它提供了计算过程中实际步数的近似值。
函数f(n)是原始函数T(n)中主导部分的简化表⽰。
在上⾯的例⼦中,T(n) = 1 + n。
当n增⼤时,常数1对于最后的结果来说越来越不重要。
如果我们需要T(n)的近似值,我们可以忽略常数1,直接认为T(n)的运⾏时间就是O(n)。