spss教程-常用的数据描述统计:频数分布表等--统计学
SPSS统计软件使用指导

SPSS统计软件使用指导SPSS(统计软件包社会科学)是一个功能强大的统计分析软件,被广泛应用于社会科学领域的数据处理和统计分析。
本文将为您提供SPSS的简单使用指导。
一、数据导入与数据处理1. 数据导入:打开SPSS软件后,选择“文件”菜单中的“导入数据”,选择合适的数据类型(如Excel、CSV等),然后按照指引找到要导入的数据文件,并点击“打开”按钮导入数据。
2.数据处理:导入数据后,您可以使用SPSS进行数据清洗、数据变换和数据整合等操作。
例如,可以使用数据筛选功能去除缺失值,使用重编码功能对变量进行重新分组等。
二、数据描述统计1.频数统计:选择“分析”菜单中的“描述统计”→“频数”,将要分析的变量移至“变量列表”中,点击“统计”按钮,并选择要统计的指标(如中位数、均值等),最后点击“确定”按钮即可进行频数统计分析。
2.描述性统计:选择“分析”菜单中的“描述统计”→“描述统计”,将要分析的变量移至“变量列表”中,点击“统计”按钮,并选择要统计的指标(如均值、标准差等),最后点击“确定”按钮即可进行描述统计分析。
三、数据分析与模型建立1.相关分析:选择“分析”菜单中的“相关”→“双变量”,将要分析的变量移至“变量列表”中,点击“OK”按钮即可进行相关性分析。
2.回归分析:选择“分析”菜单中的“回归”→“线性”,将因变量和自变量移至相应的“因变量”和“自变量”框中,可以选择“统计”按钮进行相应的统计分析。
3.方差分析:选择“分析”菜单中的“比较组”→“方差分析”,将要分析的变量移至“因子”列表中以及自变量列表中,点击“OK”按钮即可进行方差分析。
四、结果输出与图表绘制1.结果输出:分析完成后,可以通过点击“结果”菜单中的“查看输出”来查看统计结果。
可以选择复制、粘贴或导出统计结果到其他软件进行进一步分析或报告。
2.图表绘制:选择“图形”菜单,其中包含了众多图表类型,如饼图、柱状图、折线图等。
SPSS统计分析数据特征的描述统计分析

SPSS统计分析数据特征的描述统计分析SPSS(Statistical Package for the Social Sciences)是一种常用的统计分析软件,用于对数据进行描述统计分析。
描述统计分析旨在帮助研究人员对数据进行简单的整理、描述和总结,以便更好地理解数据的特征和趋势。
下面将说明几种常用的描述统计分析方法。
1.频数统计频数统计是指对数据中各个变量的不同取值进行计数。
通过统计每个取值出现的次数,可以了解数据的分布情况和变量的特点。
SPSS提供了多种方式来进行频数统计,包括直方图、饼图等。
通过这些图表,可以清晰地看到变量的取值分布。
2.中心趋势测量中心趋势测量是描述数据集合中心位置的统计方法,常用的测量指标包括平均数、中位数和众数。
平均数是所有数据的算术平均值,中位数是将数据按大小排列后处于中间位置的数值,众数是出现次数最多的数值。
SPSS提供了计算这些测量指标的功能,以便更好地了解数据的中心位置。
3.离散程度测量离散程度测量是描述数据变异程度的方法,常用的度量指标包括标准差、方差和极差。
标准差是数据与平均数之间的平均偏差,方差是标准差的平方,表示数据的离散程度,极差是最大值与最小值之间的差异。
通过这些指标,可以判断数据的离散程度,以及是否存在异常值等问题。
4.偏度和峰度测量偏度和峰度是描述数据分布形态的指标。
偏度测量的是数据分布的偏斜程度,正偏斜表示分布右侧的极端值较多,负偏斜表示分布左侧的极端值较多。
峰度测量的是数据分布的尖峰程度,正峰度表示尖峰较高且尾巴较短,负峰度表示尖峰较低且尾巴较长。
通过偏度和峰度的测量,可以判断数据的分布形态是否符合正态分布。
5.相关分析相关分析旨在研究两个或多个变量之间的关系。
相关系数是用来衡量变量之间线性相关程度的指标,取值范围从-1到+1、接近-1的相关系数表示负相关,接近+1的相关系数表示正相关,接近0的相关系数表示无相关。
通过相关分析,可以了解不同变量之间的关系,以及它们对研究问题的影响程度。
spss--描述性统计分析教程课件

17
主要内容
4.1 基本描述性统计量的定义及计算 4.2 频数分析 4.3 描述性分析 4.4 探索性分析 4.5 交叉列联表分析 4.6 多选项分析
spss--描述性统计分析教程
18
4.4 探索性分析
1.探索性分析目的和主要功能
与前面介绍的两种分析方法相比,探索性分析更加强大,它 是对数据的探索和考察,可以对变量进行更为深入详尽的统 计分析。在进行统计分析前,通常需要寻求和确定适合所研 究的问题的统计方法, SPSS提供的探索性分析是解决此类 问题的有效办法。
3.描述总体分布形态的统计量
偏度(Skewness)
峰度(Kurtosis)
spss--描述性统计分析教程
5
主要内容
4.1 基本描述性统计量的定义及计算 4.2 频数分析 4.3 描述性分析 4.4 探索性分析 4.5 交叉列联表分析 4.6 多选项分析
spss--描述性统计分析教程
6
4.2 频数分析
3.实例分析
➢结果分析
分别利用Kolmogorov-Smimov检验和Shapiro-Wilk检验两种方法来 确定变量是否服从正态分布。其中,Statistic表示检验统计量的值, df代表自由度,Sig.表示显著性水平。一般来说,Sig.>0.05则代表接 受零假设,即接受变量服从正态分布的假设。本例中,两个变量的
3.实例分析 ➢第1步 数据组织; 根据表4.1生成SPSS数据文件,建2个变量:“收入”、“教育”, 数 据文件的格式同表4.1类似。 ➢第2步 打开主对话框; 选择Analyze→ Descriptive Statistics → Frequencies,打开同图4-1 一样的频数分析主对话框。
spss 频数分析

SPSS SPSS主要介绍在主要介绍在SPSS SPSS中进行频数分析,交互分中进行频数分析,交互分析,相关分析,均值比较与检验,回归分析,相关分析,均值比较与检验,回归分析,方差分析,等。
析,方差分析,等。
一、频数分布表一、频数分布表在在SPSS SPSS中可以很容易地得出频数分布表,平均数,中可以很容易地得出频数分布表,平均数,标准差等。
标准差等。
频数分布:可以概略地看到资料的分布情况,可做频数分布:可以概略地看到资料的分布情况,可做初步整理之用,从中还可检查数据输入情况。
初步整理之用,从中还可检查数据输入情况。
Analyze Analyze ———— Descriptive Statistics Descriptive Statistics ———— Frequencies Frequencies 可选入多个变量。
可选入多个变量。
General Happiness 467 30.8 31.1 31.1 872 57.5 58.0 89.0 165 10.9 11.0 100.0 1504 99.1 100.0 13 .9 1517 100.0 Very Happy Pretty Happy Not Too Happy Total Valid NA Missing Total Frequency Percent Valid Percent Cumulative Percent Number of Children 419 27.6 27.8 27.8 255 16.8 16.9 44.7 375 24.7 24.9 69.5 215 14.2 14.2 83.8 127 8.4 8.4 92.2 54 3.6 3.6 95.8 24 1.6 1.6 97.3 23 1.5 1.5 98.9 17 1.1 1.1 100.0 1509 99.5 100.0 8 .5 1517 100.0 0 1 2 3 4 5 6 7 Eight or More Total V alid NA Missing Total F requency Percent V alidPercent Cumulative Percent Statistics: Statistics: Dispersion( Dispersion(离差栏)离差栏):: Std.Deviation Std.Deviation标准差标准差Variance Variance 方差方差Range Range全距全距Minimum Maximum Minimum Maximum S.E.mean S.E.mean均数的标准误均数的标准误Central Tendency ( Central Tendency (集中趋势栏)集中趋势栏)Mean Median Mode Sum Mean Median Mode Sum Skewness Skewness偏度(偏度(00,,1.5 1.5,,0.5 0.5,,--0.5 0.5))Kurtosis Kurtosis 峰度(峰度(00,正,负),正,负)例:例:09 09- -01 01 Statistics 1509 1510 8 7 1.90 12.88 .045 .077 2.00 12.00 0 12 1.765 2.984 3.114 8.904 1.034 -.168 .063 .063 1.060 .710 .126 .126 8 20 0 0 8 20 2869 19455 Valid Missing N Mean Std. Error of Mean Median Mode Std. Deviation Variance Skewness Std. Error of Skewness Kurtosis Std. Error of Kurtosis Range Minimum Maximum Sum Number of Children Highest Year of School Completed Number of Children 419 27.6 27.8 27.8 255 16.8 16.9 44.7 375 24.7 24.9 69.5 215 14.2 14.2 83.8 127 8.4 8.4 92.2 54 3.6 3.6 95.8 24 1.6 1.6 97.3 23 1.5 1.5 98.9 17 1.1 1.1 100.0 1509 99.5 100.0 8 .5 1517 100.0 0 1 2 3 4 5 6 7 Eight or More Total Valid NA Missing Total Frequency Percent Valid Percent Cumulative Percent 还可直接作出图形:还可直接作出图形:Charts: Charts: Bar charts: Bar charts:条形图条形图Pie Charts: Pie Charts:圆图、饼图圆图、饼图Histograms: Histograms:直方图。
SPSS统计分析教程-频数分布分析

统计分析往往是从了解数据的基本特征开始的。
描述数据分布特征的统计量可分为两类:一类表示数量的中心位置,另一类表示数量的变异程度(或称离散程度)。
两者相互补充,共同反映数据的全貌。
这些内容可以通过SPSS中的“Descriptive Statistics”菜单中的过程来完成。
1 频数分析 (Descriptive Statistics - Frequencies)频数分布分析主要通过频数分布表、条形图和直方图,以及集中趋势和离散趋势的各种统计量来描述数据的分布特征。
下面我们通过例子来学习单变量频数分析操作。
1) 输入分析数据在数据编辑器窗口打开“data1-2.sav”数据文件。
2)调用分析过程在主菜单栏单击“Analyze”,在出现的下拉菜单里移动鼠标至“Descriptive Statistics”项上,在出现的次菜单里单击“Frequencies”项,打开如图3-4所示的对话框。
图3-4 “Frequencies” 对话框3)设置分析变量从左则的源变量框里选择一个和多个变量进入“Variable(s):”框里。
在这里我们选“三化螟蚁螟 [虫口数]”变量进入“Variable(s):”框。
4)输出频数分布表Display frequency tables,选中显示。
5)设置输出的统计量单击“Statistics”按钮,打开图3-5所示的对话框,该对话框用于选择统计量:图3-5 “Statistics”对话框① 选择百分位显示“Percentiles Values”栏:Quartiles:四分位数,显示25%、50%和75%的百分位数。
Cut points for 10 equal groups:将数据平分为输入的10个等份。
Percentile(s)::用户自定义百分位数,输入值0—100之间。
选中此项后,可以利用“Add”、“Change”和“Remove”按钮设置多个百分位数。
② 选择变异程度的统计量“Dispersion”:(离散趋势)Std.deviation 标准差Minimum 最小值Variance 方差Maximum 最大值Range 极差S.E.mean 均值标准误③ 选择表示数据中心位置的统计量“Central Tendency”:(集中趋势)Mean 均值Median 中位数Mode 众数Sum 算术和④ 选择分布指标“Distribution”:Skewness 偏度Kurtosis 峰度6) 统计图形输出设置单击“Charts”按钮,将弹出如图3-6所示的对话框:图3-6 “Charts”对话框① Chart Type 图形选择栏:○ None:不输出图形;○ Bar charts:输出条形图;○ Pie charts:输出饼图;⊙ Histograms:输出柱状图。
统计分析与Spss应用第五章(描述性统计分析)

选入需要描述的 变量,可选入多个
确定是否将原始数 据的标准正态变换 结果存为新变量。
变量列表顺序 字母顺序 均数升序 均数降序。
Descriptive Statistics N 血清总胆固醇 Valid N (listwise) Minimum Maximum 101 2.70 7.22 101 Mean Std. Deviation 4.6995 .86162
5.1.1 对话框界面及 各部分选项说明 【Display frequency tables复选框】确定是 否在结果中输出频数 表。 【Statistics钮】单击 后弹出Statistics对话 框,用于定义需要计 算的其他描述统计量。
集中趋势指标
百分位数指标
计算百分数时选此项
离散趋势指标 分布指标
1
.002
.000
Hale Waihona Puke .006.002b
.000
.005
639 61.974 d 65.957 55.621 9.398
e
40 40
.014 .006
.016b .009b .011b .003
b
.008 .003 .004 .000
.025 .016 .018 .006 .001
b
1
.002
.000
.002
descriptive statistics菜单主要内容
(1)频数分布表分析(Frequencies):其特色就是产生 频数表,对分类数据和定量资料都适用。 (2)统计描述分析(Descriptive)进行一般性描述,适 用于服从正态分布的定量资料。 (3) Explore 过程:用于对数据分布状况不清楚时的 探索性分析,它会杂七杂八给出一大堆可能用到的 统计指标和统计图,让研究者参考。 (4)Crosstabs 过程则完成计数资料和等级资料的统计 描述和一般的统计检验我们常用的X2 检验也在其中 完成 (5)Ratio过程;用于对两个连续性变量计算相对比指 标,它可以计算出一系列非常专业的相对比描述指 标。
SPSS统计分析—描述性统计分析

Skewness
中位数 Median
方差
Variance
峰度
Kurtosis
众数
Mode
极小值
Minimum
和
Sum
极大值
Maximum
全距
Range
均值的标准 误差
S.E.mean
• 【Descriptive Statistics】子菜单
• ① Frequencies:产生变量值的频数分布表,并可计算常见 描述性统计量和绘制相对应的统计图。
• 执行【Analyze】/【Descriptive Statistics】/ 【Crosstabs】命令,弹出如图所示对话框
• 结果解读
1、列联表 2、卡方检验结果
3、条图
相对比描述——Ratio
• 在实际问题中,研究者有时除了希望了解变量自身的统计特 征,还希望得到两个变量相对比之间的统计描述。
适用范围:更适用于对分类变量以及不服从正态分布的连 续性变量进行描述。
• 学生身高频数表:已知有某地120名12岁男童身高数据,编 制其传统的简易频数表。
执行【Analyze】/【Descriptive Statistics】/ 【Frequencies】命令,弹出如下所示对话框
• 结果解读 1、频数表
每个格子中的理论频数T是在假定两组的发癌率相等(均等于两组 合计的发癌率)的情况下计算出来的,如第一行第一列的理论频数 为71*91/113=57.18,故卡方值越大,说明实际频数与理论频数的 差别越明显,两组发癌率不同的可能性越大。
2、卡方检验方法的适用条件
• 吸烟习惯与患病率的关系
调查339名50岁以上吸烟习惯与患慢性气管炎病的关系,如 上表所示。试问吸烟者与不吸烟者慢性气管炎患病率是否有 所不同。 ◆ 数据的预处理:WEIGHT CASE
spss教程-常用的数据描述统计:频数分布表等--统计学
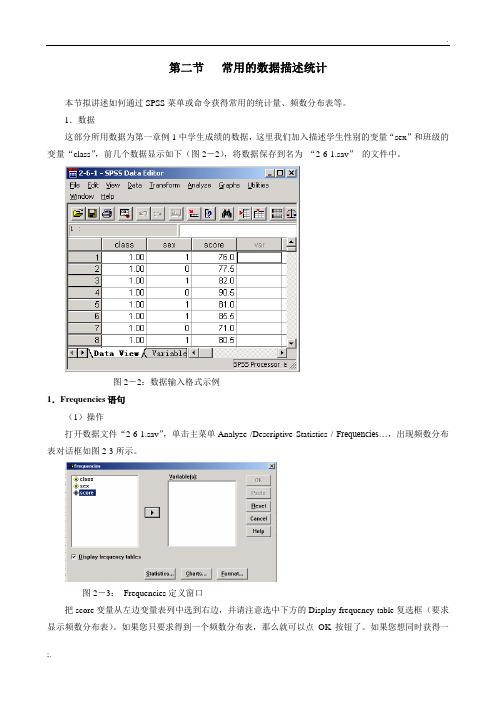
第二节常用的数据描述统计本节拟讲述如何通过SPSS菜单或命令获得常用的统计量、频数分布表等。
1.数据这部分所用数据为第一章例1中学生成绩的数据,这里我们加入描述学生性别的变量“sex”和班级的变量“class”,前几个数据显示如下(图2-2),将数据保存到名为“2-6-1.sav”的文件中。
图2-2:数据输入格式示例1.Frequencies语句(1)操作打开数据文件“2-6-1.sav”,单击主菜单Analyze /Descriptive Statistics / F requencies…,出现频数分布表对话框如图2-3所示。
图2-3:Frequencies定义窗口把score变量从左边变量表列中选到右边,并请注意选中下方的Display frequency table复选框(要求显示频数分布表)。
如果您只要求得到一个频数分布表,那么就可以点OK按钮了。
如果您想同时获得一些统计量,及统计图表,还需要进一步设置。
①Statistics选项单击Statistics按钮,打开对话框,请按图2-4自行设置。
有关说明如下:(ⅰ)在定义百分位值(percentile value)的矩形框中,选择想要输出的各种分位数,SPSS提供的选项有:●Quartiles四分位数,即显示25%、50%、75%的百分位数。
●Cut points equal 把数据平均分为几份。
如本例中要求平均分为3份。
●Percentile显示用户指定的百分位数,可重复多次操作。
本例中要求15%、50%、85%的百分位数。
(ⅱ) 在定义输出集中趋势(Central Tendency)的矩形框中,选择想要输出的集中统计量,常用的选项有:●Mean 算术平均数●Median 中数●Mode 众数●Sum 算术和(ⅲ)在定义输出离散统计量(Dispersion)的矩形框中,选择想要输出的离散统计量,常用的选项有:●Std. Deviation 标准差●Variance 方差●Range 全距●Minimum 最小值●Maximum 最大值●S.E. mean 平均数的标准误(ⅳ)描述数据分布(Distribution)的统计量●Skewness 偏度,非对称分布指数。
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
第二节常用的数据描述统计本节拟讲述如何通过SPSS菜单或命令获得常用的统计量、频数分布表等。
1.数据这部分所用数据为第一章例1中学生成绩的数据,这里我们加入描述学生性别的变量“sex”和班级的变量“class”,前几个数据显示如下(图2-2),将数据保存到名为“2-6-1.sav”的文件中。
图2-2:数据输入格式示例1.Frequencies语句(1)操作打开数据文件“2-6-1.sav”,单击主菜单Analyze /Descriptive Statistics / F requencies…,出现频数分布表对话框如图2-3所示。
图2-3: Frequencies定义窗口把score变量从左边变量表列中选到右边,并请注意选中下方的Display frequency table复选框(要求显示频数分布表)。
如果您只要求得到一个频数分布表,那么就可以点OK按钮了。
如果您想同时获得一些统计量,及统计图表,还需要进一步设置。
①Statistics选项单击Statistics按钮,打开对话框,请按图2-4自行设置。
有关说明如下:(ⅰ)在定义百分位值(percentile value)的矩形框中,选择想要输出的各种分位数,SPSS提供的选项有:●Quartiles四分位数,即显示25%、50%、75%的百分位数。
●把数据平均分为几份。
如本例中要求平均分为3份。
●Percentile显示用户指定的百分位数,可重复多次操作。
本例中要求15%、50%、85%的百分位数。
(ⅱ) 在定义输出集中趋势(Central Tendency)的矩形框中,选择想要输出的集中统计量,常用的选项有:●Mean 算术平均数●Median 中数●Mode 众数●Sum 算术和(ⅲ)在定义输出离散统计量(Dispersion)的矩形框中,选择想要输出的离散统计量,常用的选项有:●Std. Deviation 标准差●Variance 方差●Range 全距●Minimum 最小值●Maximum 最大值●S.E. mean 平均数的标准误(ⅳ)描述数据分布(Distribution)的统计量●Skewness 偏度,非对称分布指数。
●Kurtosis 峰度,CASE围绕中心点的扩展程度。
另外,频数过程(Frequence)除了能够提供上面常用的统计量外,还可以对分组数据计算百分位数和中数(Values are group midpoints),即对于已经分组的数据,并且数据中的原始数据表示的是组中数的数据计算百分位数的值和中位数。
图2-4:次数分布统计量定义窗口图2-5:次数分布图形定义窗口在本例中,我们选择输出:四分位点的值,平均分为3等分的分位点的值和15%,50%,85%的分位点的值;对于集中趋势的度量,选择输出算术平均数、中数、众数和总和,对于离散程度的度量选择输出标准差和方差。
②Charts选项为了获得统计图表,单击主对话框中的Charts铵钮,打开它的对话框,如图2-5所示。
用户可以在图形类型(Chart Type)选择框中定义输出的图形类型,频数(Frequence)过程可以提供的输出选项有:●None 不显示图表●Bar charts 条形图●Pie charts 圆形图●Histograms 直方图另外,对于图形中纵坐标值的表示,可以有两种方式:●Frequencies 纵座标为变量值的频数●Percentages 纵座标为变量值的百分比在本例中,由于学生成绩可以看成是连续性的数据,所以这里选择输出直方图,并拟合正态曲线。
点击Continue返回主对话框。
③Format选项单击Format…,打开Format对话框,如图2-6所示。
在该对话框,可以选择数据输出显示的顺序(Order by),Frequencies提供的选项有:●Ascending values 在输出频数分布表时按变量值升序排列●Descending values 在输出频数分布表时按变量值降序排列●Ascending counts 输出频数分布表时按变量值频数的升序排列●Descending counts 输出频数表时按变量值频数的降序排列图2-6:定义输出显示格式对话框在Format 中我们一律使用默认选项。
点击Continue 返回主对话框,在主对话框中点击OK,可以得到次数分布的输出结果。
(2)结果及解释①学生成绩变量的Frequences 输出描述统计结果:StatisticsSCORE 100079.68079.75080.07.02649.3717968.072.07575.00076.50079.75082.50084.00087.000Valid MissingNMean Median ModeStd. Deviation Variance Sum152533.333333335066.666666677585Percentiles输出说明:● N 后面的Valid 和Missing 分别用来描述有效值样本容量和缺失值的样本个数,在本例所用数据中,有100个有效数字,缺失值的个数为0。
● Mean 、Median 、Mode 和Sum 分别用来描述算术平均数、中数、众数和数据的总和,本例所用数据的算术平均数为79.680,中数为79.75,众数为80,数据总和为7968.0。
● Std. Deviation 和Variance 分别用来描述数据的标准差和方差,这里数据的标准差为7.026,方差为49.371。
● Percentiles 后给出不同的百分位数对应的值,如15后面的数字72.075表示,15%的分位点的值为72.075,即小于72.075分的人数占总人数的15%。
(表中有两个无穷循环小数,是我们自定义的三等分的百分位数)②学生成绩的频数分布表:SCOREFrequency Percent Valid Percent Cumulative Percent Valid62.01 1.0 1.0 1.065.01 1.0 1.0 2.066.01 1.0 1.0 3.067.01 1.0 1.0 4.068.01 1.0 1.0 5.068.51 1.0 1.0 6.069.01 1.0 1.07.070.01 1.0 1.08.070.51 1.0 1.09.071.03 3.0 3.012.071.51 1.0 1.013.072.02 2.0 2.015.072.51 1.0 1.016.073.02 2.0 2.018.073.52 2.0 2.020.074.02 2.0 2.022.074.52 2.0 2.024.075.03 3.0 3.027.075.52 2.0 2.029.076.03 3.0 3.032.076.52 2.0 2.034.077.02 2.0 2.036.077.52 2.0 2.038.078.03 3.0 3.041.078.52 2.0 2.043.079.04 4.0 4.047.079.53 3.0 3.050.080.05 5.0 5.055.080.53 3.0 3.058.081.03 3.0 3.061.081.52 2.0 2.063.082.03 3.0 3.066.082.52 2.0 2.068.083.04 4.0 4.072.083.52 2.0 2.074.084.03 3.0 3.077.084.51 1.0 1.078.085.01 1.0 1.079.085.51 1.0 1.080.086.03 3.0 3.083.086.51 1.0 1.084.087.02 2.0 2.086.087.51 1.0 1.087.088.01 1.0 1.088.088.51 1.0 1.089.089.02 2.0 2.091.089.51 1.0 1.092.090.01 1.0 1.093.090.51 1.0 1.094.091.01 1.0 1.095.092.51 1.0 1.096.093.01 1.0 1.097.094.01 1.0 1.098.096.01 1.0 1.099.098.01 1.0 1.0100.0Total100100.0100.0在输出的频数分布表中,第一列给出数据中出现的不同数值;第二列给出该数值对应的频数(Frequency);第三列给出对应数据在总数据中所占的百分比(Percent);第四列给出有效百分比(Valid percent)即去除缺失值后的百分比,由于在此例中不含有缺失值所以该列数据与第三列相同;最后一列给出累加百分比(Cumulative percent)。
如数据70,对应的频数为1,表示在这组数据中70出现了1次,所占比例和有效百分比都是1%,累计百分比8%表示小于等于70的人数占总人数的8%。
2.Descriptives仍以上面所用数据为例,简单说明另外一种常用的输出描述统计量的过程—Descriptive。
打开数据文件“2-6-1.sav”,(1)操作单击主菜单Analyze /Descriptive Statistics / Descriptives…,打开主对话框如图2-7所示:图2-7:Descriptives定义窗口将左边变量表列中的class、sex和scores变量选到右边的变量表列(Variable(s))中。
注意选中下方Save standardized values as variables复选框,即要求把该变量值的标准分存为一变量,并在数据窗口中显示(请注意在执行完操作后自行查看结果,新生成的变量名称分别为zclass、zsex和zscore)。
图2-8:Descriptives的options窗口①options选项单击options…按钮,打开描述统计过程的选择输出对话框(Descriptives:Options),设置如图2-8所示:请注意,这里所给出的一些统计量,与在Frequencies 中所给的相差无几。
所以,当我们需要用到这些描述统计量的时候,可以不受一种特殊方法的限制。
在此不再对这些统计量作过多说明,如有不解之处,请参阅Frequencies部分。
在图2-8的下方,提供了有关输出显示顺序(Display Order)的定义框:●Variable list 变量表列中变量的排列顺序为数据窗口中的顺序●Alphabetic 按字母顺序●Ascending means 按平均数的升序排列●Descending means 按平均数的降序排列定义完成后,点击Continue,返回主对话框,点击OK,可以得到的输出结果。