第11章主成分和因子分析
管理统计SPASS第11章主成分分析与因子分析资料

主成分的计算流程
步骤三:
按如下方法得到主成分 Yi :
Y1 b1T X ,Y2 b2T X ,,Yk bkT X
பைடு நூலகம்
式中,X ( X1, X 2 ,, X k )T 。
Yi (i 1,, k) 是相互正交的综合变量。将k个主成分放到一
起可得矩阵表达式: Y BT X
Y1 b11 b1k X1
简记为
Y AX
向量 Y 满足如下条件:
指标 Yi 之间不相关。
方差尽可能大,即对 n 个对象的分辨率尽可能强,信息损
失尽可能的少。
主成分分析小结:
(1)从相关的多个指标 X1, X 2 ,, X k 中,求出相互独立 的多个指标 Y1,Y2 ,,Yk 。
(2) Y (Y1,Y2 ,,Yk )T 的方差信息不损失,尽可能等同于 X ( X1, X 2 ,, X k )T 的方差。
Yk bk1 bkk X k
主成分的计算流程
主成分更为明晰的表达式:
Y1 b11X1 b21 X 2 bk1 X k Y2 b12 X1 b22 X 2 bk 2 X k
Yk bk1 X 1 bk 2 X 2 bkk X k
主成分的计算流程
结语:
X 与 Y 的转换关系为:
Y1 a11 a1k X 1
Yk ak1 akk X k
几何解释
在下图 X1 O X 2 的坐标中,散点大致为椭圆状。经过 线性变换可以得到新的坐标 Y1 O Y2 。Y1 在椭圆的长轴上, 反映出了散点在这个方向的最大方差。 Y2 在椭圆的短轴上,反 映出了散点在这个方向的方差。
X2
Y2
X1
Y1
主成分的计算流程
多元分析:主成分分析与因子分析

第十一章 多元分析:主成分分析与因子分析引言主成分分析和因子分析在多元分析框架内是数据结构分析技术,与第六章的多元回归、第七章的多变量协整一起是多变量分析中广泛使用的技术。
它们不同于多元回归。
回归的目标是识别外生变量与内生变量的关系,而在主成分分析和因子分析情形下,仅确定内生变量间的结构关系。
它们也不像协整,变量间不需要平稳性。
在金融、社会科学或其它领域,通常需要识别多变量结构的特征,其有两个特征是被子广泛关心的:1. 多变量结构中的波动性。
2. 变量间的相关或共线性。
在结构的整体变化中,通常是一些变量起产生主要的影响,而其它变量仅有次要的或不显著的影响。
困难的是要了解哪些变量能被确定在这个结构中和它在结构中应怎样度量。
例如,如果两个变量是完全相关的,则不需要第二个变量,它不会带来进一步的信息。
这类似多元回归的共线问题。
在一般情况下,包含哪个变量,剔除哪个变量并不是很清楚的,我们需要有能够程序化的有效方法来识别带有最可用信息的变量或变量组合。
主成分分析(PCA )是分析多变量结构波动时有用的技术。
因子分析(F A )在分析多变量结构变量的相关时很有用。
两者都依赖于方差/协方差矩阵,因为这个矩阵在一定范围内包含了变量间有用的全部信息。
因此在一定范围内,两者是重复的或相互补充的。
在这章,我们将方差/协方差矩阵记为C 。
尽管PCA 和F A 都利用方差/协方差矩阵,但它们不同于第四章和第九章中的均值—方差分析。
均值—方差分析度量了一组变量的总体变异性,而没有特别指明一部分变量对总变异性的贡献。
PCA 识别和排序了部分变量在总变异性中的贡献,每个部分变量称为“主成分”。
它识别了部分变量间组成的协方差的强度,每个主成分对总的变异性的贡献,并根据部分变量组的方差进行排序。
使用PCA ,数据内的总体变异性由特征值之和(它等于C矩阵主对角线上元素之和,也称为迹)度量,成分(变量的线性组合)的选择是依次序减少特征值,直到满足总变异性的一个足够大的比例。
因子分析、主成分分析

通过主成分分析,可以研究多个变量之间的相关性,揭示变量
之间的内在联系。
多元回归分析
03
在多元回归分析中,主成分分析可以用来消除变量间的多重共
线性,提高回归分析的准确性和稳定性。
金融数据分析
风险评估
在金融数据分析中,主成分分析可以用来评估投资组合的风险, 通过提取主要因子来反映市场的整体波动。
市场趋势分析
主成分分析案例:金融数据分析
总结词
主成分分析用于金融数据分析中,能够 降低数据维度并揭示主要经济趋势。
VS
详细描述
在金融领域,主成分分析被广泛应用于股 票、债券等资产组合的风险评估和优化。 通过对大量金融数据进行主成分分析,可 以提取出几个关键主成分,这些主成分代 表了市场的主要经济趋势。投资者可以利 用这些信息进行资产配置和风险管理。
特征提取
主成分分析能够提取出数据中的 主要特征,突出数据中的主要变 化方向,有助于揭示数据的内在 规律。
数据可视化
降低数据维度后,数据的可视化 变得更加容易,有助于直观地理 解和分析数据。
多元统计
多元数据描述
01
主成分分析可以用来描述多元数据的总体特征,提供对多元数
据分布的整体理解。
多元相关分析
02
目的
通过找出影响观测变量的潜在结构, 更好地理解数据的意义,简化复杂数 据的分析,并解决诸如多重共线性等 问题。
因子分析的原理
1 2 3
基于相关性
因子分析基于观测变量之间的相关性,通过找出 这些相关性背后的公因子来解释变量之间的依赖 关系。
降维
通过提取公因子,将多个观测变量的复杂关系简 化为少数几个潜在因子的线性组合,实现数据的 降维。
卫生统计学:主成分分析与因子分析

通常先对x作标准化处理,使其均值为 零,方差为1.这样就有
x i a i1 f1 a i2 f2 a im fm e i
假定〔1〕fi的均数为 i22 0,方差为1; 〔2〕ei的均数为0,方差为δi; 〔3〕 fi与ei相互独立.
那么称x为具有m个公共因子的因子模型
〔2〕δi称为特殊方差〔specific variance〕,是不能由公共因子解 释的局部
▪ 因子载荷〔负荷〕aij是随机变量xi与 公共因子fj的相关系数。
▪设
p
g
2 j
a
2 ij
i1
j 1, 2 ,..., m
▪ 称gj2为公共因子fj对x的“奉献〞, 是衡量公共因子fj重要性的一个指标。
根本思想:使公共因子的相对负荷 〔lij/hi2〕的方差之和最大,且保持 原公共因子的正交性和公共方差总和 不变。
可使每个因子上的具有最大载荷的变量 数最小,因此可以简化对因子的解释。
〔2〕斜交旋转〔oblique rotation〕
因子斜交旋转后,各因子负荷发生 了较大变化,出现了两极分化。各 因子间不再相互独立,而彼此相关。 各因子对各变量的奉献的总和也发 生了改变。
ai2j
g
2 j
i1
▪ 极大似然法〔maximum likelihood factor〕
▪ 假定原变量服从正态分布, 公共因子和特殊因子也服从正态分 布,构造因子负荷和特殊方差的似 然函数,求其极大,得 factor〕
▪ 设原变量的相关矩阵为 R=(rij),其逆矩阵为R-1=(rij)。 各变量特征方差的初始值取为逆 相关矩阵对角线元素的倒数, δi’=1/rii。那么共同度的初始值 为(hi’) 。
主成分分析和因子分析(朱艳科)

主成分分析和因子分析法一、主成分分析概论主成分分析的工作对象是样本点×定量变量类型的数据表。
它的工作目标,就是要对这种多变量的平面数据表进行最佳综合简化。
也就是说,要在力保数据信息丢失最少的原则下,对高维变量空间进行降维处理。
很显然,识辨系统在一个低维空间要比一个高维空间容易得多。
英国统计学家斯格特(M.Scott )在1961年对157个英国城镇发展水平进行调查时,原始测量的变量有57个。
而通过主成分分析发现,只需5个新的综合变量(它们是原变量的线性组合),就可以95%的精度表示原数据的变异情况,这样,对问题的研究一下子从57维降到5维。
可以想象,在5维空间中对系统进行任何分析,都比在57维中更加快捷、有效。
另一项十分著名的工作是美国的统计学家斯通(Stone)在1947年关于国民经济的研究。
他曾利用美国1929~1938年各年的数据,得到了17个反映国民收入与支出的变量要素,例如雇主补贴、消费资料和生产资料、纯公共支出、净增库存、股息、利息和外贸平衡等等。
在进行主成分分析后,竟以97.4%的精度,用三个新变量就取代了原17个变量。
根据经济学知识,斯通给这三个新变量要别命名为总收入1F 、总收入变化率2F 和经济发展或衰退的趋势3F (是时间t 的线性项)。
更有意思的是,这三个变量其实都是可以直接测量的。
二、主成分分析的基本思想与理论1、主成分分析的基本思想在对某一事物进行实证研究中,为了更全面、准确地反映出事物的特征及其发展规律,人们往往要考虑与其有关系的多个指标,这些指标在多元统计中也称为变量。
这样就产生了如下问题:一方面人们为了避免遗漏重要的信息而考虑尽可能多的指标,而另一方面随着考虑指标的增多增加了问题的复杂性,同时也由于各指标均是对同一事物的反映,不可避免地造成信息的大量重叠,这种信息有时甚至会抹杀事物的真正特征与内在规律。
基于上述问题,人们就希望在定量研究中涉及的变量较少,而得到的信息量又较多。
主成分分析和因子分析的区别
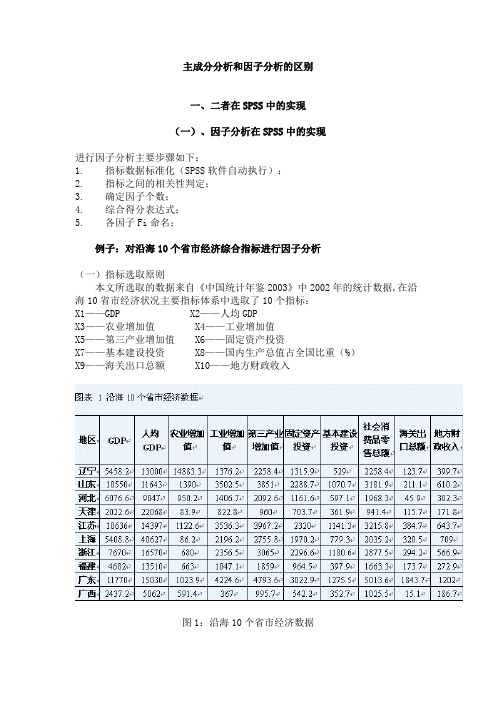
主成分分析和因子分析的区别一、二者在SPSS中的实现(一)、因子分析在SPSS中的实现进行因子分析主要步骤如下:1. 指标数据标准化(SPSS软件自动执行);2. 指标之间的相关性判定;3. 确定因子个数;4. 综合得分表达式;5. 各因子Fi命名;例子:对沿海10个省市经济综合指标进行因子分析(一)指标选取原则本文所选取的数据来自《中国统计年鉴2003》中2002年的统计数据,在沿海10省市经济状况主要指标体系中选取了10个指标:X1——GDP X2——人均GDPX3——农业增加值X4——工业增加值X5——第三产业增加值X6——固定资产投资X7——基本建设投资X8——国内生产总值占全国比重(%)X9——海关出口总额X10——地方财政收入图1:沿海10个省市经济数据(二)因子分析在SPSS中的具体操作步骤运用SPSS统计分析软件Factor过程[2]对沿海10个省市经济综合指标进行因子分析。
具体操作步骤如下:1. Analyzeà Data Reductionà Factor Analysis,弹出Factor Analysis对话框2. 把X1~X10选入Variables框3. Descriptives: Correlation Matrix框组中选中Coefficients等选项,然后点击Continue,返回Factor Analysis对话框4. 点击“OK”图2:Factor Analyze对话框与Descriptives子对话框SPSS在调用Factor Analyze过程进行分析时,SPSS会自动对原始数据进行标准化处理,所以在得到计算结果后指的变量都是指经过标准化处理后的变量,但SPSS不会直接给出标准化后的数据,如需要得到标准化数据,则需调用Descriptives过程进行计算。
我们可以通过Analyze-Descriptive Statistics- Descriptives对话框来实现:弹出Descriptives对话框后,把X1~X10选入Variables框,在Save standardized values as variables前的方框打上钩,点击“OK”,经标准化的数据会自动填入数据窗口中,并以Z开头命名。
主成分分析与因子分析法

主成分分析与因子分析法主成分分析是一种减少数据维度的统计学方法,通过将多变量数据投影到一个较低维度的空间中,实现数据的降维。
主成分分析的基本思想是将原始数据转换为一组新的变量,这些新的变量称为主成分,通过主成分的降序排列,能够使原始数据中较大方差的信息更好地保留下来。
1.数据标准化:根据数据的特点,将数据进行标准化处理,使得各个变量具有相同的尺度。
2.计算协方差矩阵:通过计算数据的协方差矩阵,了解各个变量之间的相关性。
3.求解特征向量和特征值:通过对协方差矩阵进行特征值分解,得到特征向量和特征值。
4.选择主成分:选取前k个特征向量对应的主成分,使得它们能够解释绝大部分的方差。
通常选择的标准是特征值大于1,或者解释方差的累积比例达到一定的阈值。
5.主成分系数:计算原始变量和主成分之间的线性关系,这个关系可以用主成分的特征向量作为系数矩阵进行表示。
1.降低维度:主成分分析能够将高维数据降维,提取出最能代表原始数据的主成分。
2.去除冗余信息:通过选择主成分,可以去除原始数据中的冗余信息,提取出最有用的信息。
3.可视化:降维后的数据可以更容易地可视化和解释。
二、因子分析法(Factor Analysis)因子分析法是一种用于确定多个观测变量之间的潜在结构的统计学方法。
它假设观测变量是由一组潜在因子决定的,通过观测变量和因子之间的相关性,可以推断出潜在因子之间的关系。
因子分析法的基本步骤如下:1.确定因子数:根据研究的目的和背景,确定潜在因子的个数。
2.求解因子载荷矩阵:通过最大似然估计或主因子方法,求解因子载荷矩阵,得到每个观测变量与潜在因子之间的相关关系。
3.提取因子:根据因子载荷矩阵,提取出与观测变量相关性最高的因子,将原始数据映射到潜在因子空间中。
4.旋转因子:通过旋转因子载荷矩阵,使得因子之间更易解释和解读,常用的旋转方法有正交旋转和斜交旋转。
5.因子得分:根据观测变量的信息和因子载荷矩阵,计算每个样本在每个因子上的得分。
第章主成分分析和因子分析习题答案

.707
X8
-.066
.575
.090
Extraction Method: Principal Component Analysis.
Rotation Method: Varimax with Kaiser Normalization.
a Rotation converged in 5 iterations.
28
61
65
81
98
94
95
29
79
95
83
89
89
79
30
81
90
79
73
85
80
31
85
77
75
52
73
59
32
68
85
70
84
89
86
33
85
91
95
63
76
66
34
91
85
100
70
65
76
35
74
74
84
61
80
69
36
88
100
85
49
71
66
37
63
82
66
89
78
80
38
87
84
100
55.043
43.677
中国石油
33.441
19.900
0.735
0.923
28.068
1.043
42.682
45.593
广聚能源
6.790
15.650
0.441
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
如果长轴变量代表了数据包含的大部分信息,就 用该变量代替原先的两个变量(舍去次要的一 维),降维就完成了。
椭圆的长短轴相差得越大,降维也越有道理。
-4
-2
0
2
4
-4
-2
0
2
实际上主成分分析可以说是因子分析的一 个特例。在引进主成分分析之前,先看下 面的例子。
成绩数据(student.txt)
100个学生的数学、物理、化学、语文、历史、英语 的成绩如下表(部分)。
SPSS数据形式
从本例可能提出的问题
目前的问题是,能否把这个数据的6个 变量用一两个综合变量来表示呢?
4
主轴和主成分
多维变量的情况和二维类似,也有高维的椭 球,只不过不那么直观罢了。
首先把高维椭球的主轴找出来,再用代表大 多数数据信息的最长的几个轴作为新变量; 这样,主成分分析就基本完成了。
正如二维椭圆有两个主轴,三维椭球有三个 主轴一样,有几个变量,就有几个主轴。
和二维情况类似,高维椭球的主轴也是互相 垂直的。
主成分几个有用的性质:
1、第i个主成分的方差等于对应的第i个特征值
Va(Yr)
i
i
2、标准化后各个变量Xi的方差之和等于所有特征值之和
p
p
ii i
i1
i1
3、第j个主成分Yj与第i个变量Xi的相关系数:
(Yj , Xi )
u j ji
ii
综上我们可以总结出主成分的求解步骤:
轴X1和X2旋转45°,那么点在新坐标系中的坐标(Y1,Y2)与
原坐标(X1,X2)有如下的关系:
Y1
22X1
2 2 X2
u1X
Y2
22X1
2 2 X2
u2 X
在新坐标系中(如图),可以发现,虽然散点图
的形状没有改变,但新的随机变量Y1和Y2已经不在 相关。而且大部分点沿Y1轴散开,在Y1轴方向的变 异较大(即Y1的方差较大),相对来说,在Y2轴方 向的变异较小(即Y2的方差较小)
由此有:(Σ -λI)u=0 可以求出Σ的特征值分别为:λ1=1.6 λ2=0.4
及其对应的特征向量分别为:
u1(u11,u21)(
2, 2
2) 2
u2
(u12,u22)(
2, 2) 22
显然,这两个特征向量是相互正交的单位向量,而且它
们与原来的坐标轴X1和X2的夹角都分别为45°。如果将坐标
需要高度概括
在如此多的变量之中,有很多是相 关的。人们希望能够找出它们的少 数“代表”来对它们度概括。
主成分分析
本章介绍两种把变量维数降低以便于描述、 理解和分析的方法:主成分分析 ( principal component analysis ) 和 因 子分析(factor analysis)。
第11章 主成分分析和因 子分析
汇报什么?
假定你是一个公司的财务经理,掌握 了公司的所有数据,这包括众多的变 量,如:固定资产、流动资金、借贷 的数额和期限、各种税费、工资支出、 原料消耗、产值、利润、折旧、职工 人数、分工和教育程度等等。
如果让你向上级或有关方面介绍公司 状况,你能够把这些指标和数字都原 封不动地摆出去吗?
事实上,随机变量Y1和Y2的方差分别为:
V(a Y 1)rE (Y 12)u1 u1(2 2
2)(1 2 0.6
0 1 .6) 2 2 2 1.61
2
V(a Y 2)r E (Y 2 2)u2 u2(2 2 2 2)0 (1 .60 1 .6 ) 2 2 2 0 .42
这些互相正交的新变量是原先变量的线性组
合,叫做主成分(principal component)。
主成分之选取
选择越少的主成分,降维就越好。什么是 标准呢?
那就是这些被选的主成分所代表的主轴的 长度之和占了主轴长度总和的大部分。
有些文献建议,所选的主轴总长度占所有 主轴长度之和的大约85%即可,其实,这 只是一个大体的说法;具体选几个,要看 实际情况而定。
下面通过一个例子在二维空间中讨论主成 分的求解:
假定某年级学生的语文成绩x1和数学成绩x2的
相关系数ρ=0.6。设x1和x2分别为标准化后的分
数,其散点图如图所示。
那么随机向量 X(X1,X2) 的方差-协差阵(相关系数矩阵)为: 1 21 1 1 22 201.6 01.6
这一两个综合变量包含有多少原来的 信息呢?
能否利用找到的综合变量来对学生排 序或据此进行其他分析呢?
空间的点
例中数据点是六维的;即每个观测值是6维空间 中的一个点。希望把6维空间用低维空间表示。
先假定只有二维,即只有两个变量,由横坐标和 纵坐标所代表;
每个观测值都有相应于这两个坐标轴的两个坐标 值;
如果这些数据形成一个椭圆形状的点阵(这在二 维正态的假定下是可能的)该椭圆有一个长轴和 一个短轴。在短轴方向上数据变化很少;
在极端的情况,短轴如退化成一点,长轴的方向 可以完全解释这些点的变化,由二维到一维的降 维就自然完成了。
-4
-2
0
2
4
-4
-2
0
2
4
椭圆的长短轴
当坐标轴和椭圆的长短轴平行,那么代表长轴的 变量就描述了数据的主要变化,而代表短轴的变 量就描述了数据的次要变化。
2
可以看出,最大变动方向是由特征向量所决定的,而特 征值则刻画了对应的方差。
在上面的例子中Y1和Y2就是原变量X1和X2的第一主成分和 第二主成分。实际上第一主成分Y1就基本上反映了X1和X2的 主要信息,因此可以选Y1为一个新的综合变量。当然如果再 选Y2也作为综合变量,那么Y1和Y2则反映了X1和X2的全部信 息。
对于有p个变量n个个案的数据 x11 x12 x1p
1、将原始数据标准化,得到矩阵:
X
x21
x22
x2 p
2、建立p个变量的相关系数阵R:
x n1
x n2