Openfire+Spark+Spark Web安装配置
openfire详细安装配置步骤

openfire详细安装配置步骤说明:红⾊字体可任意改动(但⼀旦改动,后⾯与此对应的名称也要⼀起改动),该⽂档下的步骤是在win7(32位,64位皆可)Eclipse环境下实现的,openfire⽤的是openfire_src_3_8_2版本;第⼀步:在D盘⾥新建⼀⽂件夹openfire_src,把openfire_src_3_8_2/openfire下的所有⽂件夹copy到openfire_src⾥;第⼆步:因为openfire源码中没有包含coherence.jar、coherence-work和tangosol.jar包,所以把这三个包copy到D://openfire_src/build/lib⾥;第三步:启动Eclipse,新建⼯程File-->New-->javaproject,填⼊项⽬名openfire,选中Createprojectfromexistingsource,然后单击Browse...选出在D盘⾥新建的Openfire_src;单击Finish。
第四步:双击openfire,会看到3处错误,第⼀处错误,是由于hazelcast下⾯包⾥的java代码与clustering下⾯包⾥的java代码重复引起的,直接对⽐包名跟java⽂件名即可,然后在clustering源码中删除与hazelcast想同的java代码;完成后hazelcast将没有错误;第五步:plugins中的错误的修正,直接打开plugins中的最后⼀个包,双击SipCommRouter.java找出出错的地⽅,把光标停留在出错部分,系统会⾃动提⽰错误原因,并提供解决⽅案,单击第⼀个⽅案(Addunimplementedmethods),再点击保存(或按Ctrl+S),SipCommRouter.java的错误会消失;SipManager.java的错误也是这样改的(注意它⾥⾯有2处错误),改正后保存,错误会全部消失(包裹src的错误);第六步:删除clustering插件的plug.xml⽂件,双击src--->双击plugins---->双击clustering----->删除plug.xml;然后再右键点击openfire⼯程--->buildpath---->configurationbuildpath会出现界⾯:单击AddFolder...然后把src/i18n和src/resources/jar勾上,单击OK,第七步:使⽤ant编译,单击window->showview->ant,会出现如下图右侧的界⾯,在空⽩区域右击,选择AddBuildfiles...(或者直接单击蜘蛛快捷图标)出现如下窗⼝项⽬名->buil->build.xml,双击build.xml再次右击右侧空⽩区域,选择RefreshBuildfiles进⾏刷新,最后,单击ant窗⼝⾥⾯的run(也就是绿圆⾥有⼀个⽩⾊三⾓形的图标);等Console窗⼝⾥不再弹出编译信息时,再次单击ant窗⼝⾥⾯的run,Console窗⼝最后倒数第⼆⾏会出现BUILDSUCCESSFUL的提⽰;如下图:第⼋步:右击项⽬名openfire,选择Refresh进⾏刷新,会发现多出了两个⽂件夹target和work。
大数据处理平台Spark的安装和配置方法

大数据处理平台Spark的安装和配置方法大数据处理平台Spark是一种快速且可扩展的数据处理框架,具有分布式计算、高速数据处理和灵活性等优势。
为了使用Spark进行大规模数据处理和分析,我们首先需要正确安装和配置Spark。
本文将介绍Spark的安装和配置方法。
一、环境准备在开始安装Spark之前,需要确保我们的系统符合以下要求:1. Java环境:Spark是基于Java开发的,因此需要先安装Java环境。
建议使用Java 8版本。
2. 内存要求:Spark需要一定的内存资源来运行,具体要求取决于你的数据规模和运行需求。
一般情况下,建议至少有8GB的内存。
二、下载Spark1. 打开Spark官方网站(不提供链接,请自行搜索)并选择合适的Spark版本下载。
通常情况下,你应该选择最新的稳定版。
2. 下载完成后,将Spark解压到指定的目录。
三、配置Spark1. 打开Spark的安装目录,找到conf文件夹,在该文件夹中有一份名为spark-defaults.conf.template的示例配置文件。
我们需要将其复制并重命名为spark-defaults.conf,然后修改该文件以配置Spark。
2. 打开spark-defaults.conf文件,你会看到一些示例配置项。
按照需求修改或添加以下配置项:- spark.master:指定Spark的主节点地址,如local表示使用本地模式,提交到集群时需修改为集群地址。
- spark.executor.memory:指定每个Spark执行器的内存大小,默认为1g。
- spark.driver.memory:指定Spark驱动程序的内存大小,默认为1g。
3. 如果需要配置其他参数,可以参考Spark官方文档中的配置指南(不提供链接,请自行搜索)。
4. 保存并退出spark-defaults.conf文件。
四、启动Spark1. 打开命令行终端,进入Spark的安装目录。
openfire环境搭建
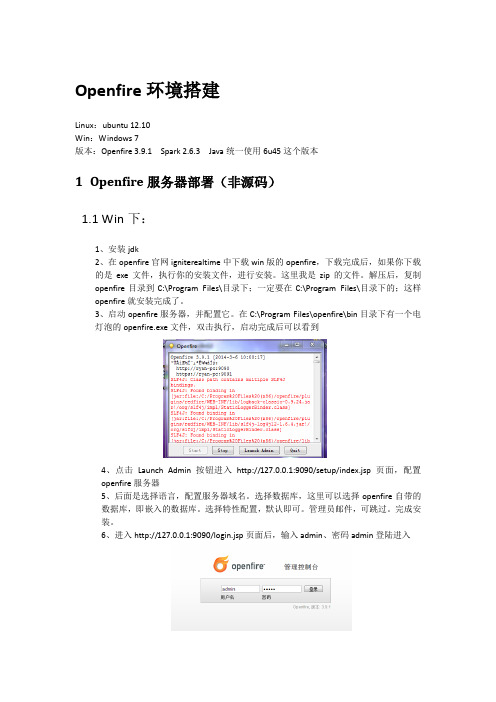
Openfire环境搭建Linux:ubuntu 12.10Win:Windows 7版本:Openfire 3.9.1 Spark 2.6.3 Java统一使用6u45这个版本1Openfire服务器部署(非源码)1.1 Win下:1、安装jdk2、在openfire官网igniterealtime中下载win版的openfire,下载完成后,如果你下载的是exe文件,执行你的安装文件,进行安装。
这里我是zip的文件。
解压后,复制openfire目录到C:\Program Files\目录下;一定要在C:\Program Files\目录下的;这样openfire就安装完成了。
3、启动openfire服务器,并配置它。
在C:\Program Files\openfire\bin目录下有一个电灯泡的openfire.exe文件,双击执行,启动完成后可以看到4、点击Launch Admin按钮进入http://127.0.0.1:9090/setup/index.jsp页面,配置openfire服务器5、后面是选择语言,配置服务器域名。
选择数据库,这里可以选择openfire自带的数据库,即嵌入的数据库。
选择特性配置,默认即可。
管理员邮件,可跳过。
完成安装。
6、进入http://127.0.0.1:9090/login.jsp页面后,输入admin、密码admin登陆进入7、进入后可以看到:1.2 Ubuntu下:1、先去甲骨文官网下载安装jdk(选择Linux x64 或者Linux x86对应链接,注意不要选择rpm.bin的,选择.bin,6u45对应的是jdk-6u45-linux-i586.bin),也不要使用ubuntu自带的openjdk2、安装全程需要root权限,首先获取root权限sudo –s5、然后就是要告诉系统,我们使用的sun的JDK,而非OpenJDK了(注意下面的2行命令--install后面一共四个参数分别是链接名称路径优先级,我们只要修改对应的6、openfire官网下载Linux版的openfire:openfire_3.9.1_all.deb(这个直接双击通过ubuntu软件中心安装),经过以上软件已经完成安装,此时需要修改一下openfire的启动文件如果openfire没有启动,可以通过/etc/init.d/openfire start启动服务。
Spark的安装及其配置

Spark的安装及其配置1.Spark下载2.上传解压,配置环境变量配置bin⽬录解压:tar -zxvf spark-2.4.5-bin-hadoop2.7.tgz -C /usr/local/soft/改名:mv spark-2.4.5-bin-hadoop2.7/ spark-2.4.5配置环境变量:vim /etc/profile添加环境变量:export SPARK_HOME=/usr/local/soft/spark-2.4.5export PATH=PATH:SPARK_HOME/bin保存配置:source /etc/profile3.修改配置⽂件 conf修改spark-env.sh: cp spark-env.sh.template spark-env.sh增加配置:export SPARK_MASTER_IP=masterexport SPARK_MASTER_PORT=7077export SPARK_WORKER_CORES=2export SPARK_WORKER_INSTANCES=1export SPARK_WORKER_MEMORY=2gexport JAVA_HOME=/usr/local/soft/jdk1.8.0_171修改:cp slaves.template slaves增加:node1node24.发放到其他节点xsync spark-2.4.5(xsync是⾃⼰写的脚本,在安装Hadoop的时候写过)4、在主节点执⾏启动命令启动集群,在master中执⾏./sbin/start-all.sh5.检验安装的Spark1. standalone client模式⽇志在本地输出,⼀班⽤于上线前测试(bin/下执⾏)需要进⼊到spark-examples_2.11-2.4.5.jar 包所在的⽬录下执⾏cd /usr/local/soft/spark-2.4.5/examples/jarsspark-submit --class org.apache.spark.examples.SparkPi --master spark://master:7077 --executor-memory 512m --total-executor-cores 1 spark-examples_2.11-2.4.5.jar 1002. standalone cluster模式上线使⽤,不会再本地打印⽇志spark-submit --class org.apache.spark.examples.SparkPi --master spark://master:7077 --driver-memory 512m --deploy-mode cluster --supervise --executor-memory 512M --total-executor-cores 1 spark-examples_2.11-2.4.5.jar 100spark-shell spark 提供的⼀个交互式的命令⾏,可以直接写代码spark-shell master spark://master:70776.整合yarn在公司⼀般不适⽤standalone模式,因为公司⼀般已经有yarn 不需要搞两个资源管理框架停⽌spark集群在spark sbin⽬录下执⾏ ./stop-all.shspark整合yarn只需要在⼀个节点整合, 可以删除node1 和node2中所有的spark ⽂件1、增加hadoop 配置⽂件地址vim spark-env.sh增加export HADOOP_CONF_DIR=/usr/local/soft/hadoop-2.7.6/etc/hadoop2、往yarn提交任务需要增加两个配置 yarn-site.xml(/usr/local/soft/hadoop-2.7.6/etc/hadoop/yarn-site.xml)先关闭yarnstop-yarn.sh<property><name>yarn.nodemanager.pmem-check-enabled</name><value>false</value></property><property><name>yarn.nodemanager.vmem-check-enabled</name><value>false</value></property>4、同步到其他节点,重启yarnscp -r yarn-site.xml node1:`pwd`scp -r yarn-site.xml node2:`pwd`启动yarnstart-yarn.shcd /usr/local/soft/spark-2.4.5/examples/jars3.spark on yarn client模式⽇志在本地输出,⼀班⽤于上线前测试spark-submit --class org.apache.spark.examples.SparkPi --master yarn-client --executor-memory 512M --num-executors 2 spark-examples_2.11-2.4.5.jar 1004.spark on yarn cluster模式上线使⽤,不会再本地打印⽇志减少iospark-submit --class org.apache.spark.examples.SparkPi --master yarn-cluster --executor-memory 512m --num-executors 2 --executor-cores 1 spark-examples_2.11-2.4.5.jar 100获取yarn程序执⾏⽇志执⾏成功之后才能获取到yarn logs -applicationId application_1560967444524_0003在idea中使⽤spark做wordCountimport org.apache.spark.rdd.RDDimport org.apache.spark.{SparkConf, SparkContext}object Demo1WordCount {def main(args: Array[String]): Unit = {// Spark配置⽂件对象val conf: SparkConf = new SparkConf()// 设置Spark程序的名字conf.setAppName("Demo1WordCount")// 设置运⾏模式为local模式即在idea本地运⾏conf.setMaster("local")// Spark的上下⽂环境,相当于Spark的⼊⼝val sc: SparkContext = new SparkContext(conf)// 词频统计// 1、读取⽂件/*** RDD : 弹性分布式数据集(可以先当成scala中的集合去使⽤)*/val linesRDD: RDD[String] = sc.textFile("spark/data/words")// 2、将每⼀⾏的单词切分出来// flatMap: 在Spark中称为算⼦// 算⼦⼀般情况下都会返回另外⼀个新的RDDval wordsRDD: RDD[String] = linesRDD.flatMap(line => line.split(","))// 3、按照单词分组val groupRDD: RDD[(String, Iterable[String])] = wordsRDD.groupBy(word => word)// 4、统计每个单词的数量val countRDD: RDD[String] = groupRDD.map(kv => {val word: String = kv._1val words: Iterable[String] = kv._2// words.size直接获取迭代器的⼤⼩// 因为相同分组的所有的单词都会到迭代器中// 所以迭代器的⼤⼩就是单词的数量word + "," + words.size})// 5、将结果进⾏保存countRDD.saveAsTextFile("spark/data/wordCount")}}Processing math: 100%。
Openfire安装配置

一、环境操作系统:Windows XP SP3Web服务器:Tomcat 6.0.18.0Java Version:1.6.0_21Jvm Version:1.6.0_21-b07Openfire服务器:Openfire 3.7.0 Openfire Plugin:Fastpath Service 4.2.0Fastpath Webchat 4.0.0二、Opernfire环境安装配置1. Openfire下载目前最新版为3.7.0下载地址:/downloads/index.jsp分为两个版本,一个是包含了JRE的安装版本,另外一个是不包含JRE的版本。
也可以分别通过下面两个链接直接下载。
/downloadServlet?filename=openfire/openfire_3_7_0.exe/downloadServlet?filename=openfire/openfire_3_7_0.zip2. Openfire安装将下载的openfire_3_7_0.zip解压。
Openfire的全路径中不能有中文字符,最好主机名也是标准点的英文名称。
3. 运行Openfire服务器直接运行服务器文件。
安装目录\Openfire\bin\openfire.exe。
出现启动界面点击“Launch Admin”,或者在浏览器地址栏输入http://127.0.0.1:9000,进入Opernfire 管理控制台。
初次会进入Openfire设置界面,对Openfire进行初始设置。
3. Openfire初始设置3.1 语言选择:中文(简体)3.2 服务器设置:设置域及服务器管理端口3.3 数据库设置:有两个选项,分别是标准数据库连接和嵌入的数据库。
3.3.1 标准数据库连接,可以使用其他外部的数据库,目前支持5种外部数据库(MySQL、Oracle、Microsoft SQLServer、PostgreSQL、IBM DB2)3.3.2 嵌入的数据库,使用Openfire自带的嵌入式的数据库设置管理员账户的电子邮箱以及管理员登录管理控制台时的密码。
Spark安装及环境配置

Spark安装及环境配置前篇⽂章介绍了scala的安装与配置、接下来介绍⼀下spark的安装及环境配置。
1、Apache spark下载下载时需要注意的是在第1步选择完spark版本之后的第2步“choose a package type”时,spark与hadoop版本必须配合使⽤。
因为spark会读取hdfs⽂件内容⽽且spark程序还会运⾏在HadoopYARN上。
所以必须按照我们⽬前安装的hadoop版本来选择package type。
我们⽬前使⽤的hadoop版本为hadoop2.7.5,所以选择Pre-built for Apache Hadoop 2.7 and later。
点击第3步Download Spark后的连接 spark-2.1.2-bin-hadoop2.7.tgz进⼊下图所⽰的页⾯。
在国内我们⼀般选择清华的服务器下载,这下载速度⽐较快,连接地址如下:2、安装spark通过WinSCP将spark-2.1.2-bin-hadoop2.7.tgz上传到master虚拟机的Downloads⽬录下,然后解压到⽤户主⽬录下并更改解压后的⽂件名(改⽂件名⽬的是名字变短,容易操作)。
解压过程需要⼀点时间,耐⼼等待哈。
解压完成后通过ls命令查看当前⽤户主⽬录,如下图所⽰增加了spark-2.1.2-bin-hadoop2.7⽂件⽬录通过mv命令更改spark-2.1.2-bin-hadoop2.7名为spark3、配置spark环境变量通过命令vim .bashrc编辑环境变量在⽂件末尾增加如下内容,然后保存并退出重新加载环境变量配置⽂件,使新的配置⽣效(仅限当前终端,如果退出终端新的环境变量还是不能⽣效,重启虚拟机系统后变可永久⽣效)通过spark-shell展⽰spark是否正确安装,Spark-shell是添加了⼀些spark功能的scala REPL交互式解释器,启动⽅式如下图所⽰。
学习笔记——spark安装配置

学习笔记——spark安装配置今天安装配置了spark,主要是按照林⼦⾬⽼师的教程安装的。
其中在下载sbt和⽤sbt将程序进⾏打包时花费了⼤量的时间(可能是因为⽹络不佳吧)。
⼀.安装1.从选择版本进⾏下载。
若已装有hadoop则第⼆项选择如图所⽰。
2.解压安装后,还需要修改Spark的配置⽂件spark-env.shcd /usr/local/sparkcp ./conf/spark-env.sh.template ./conf/spark-env.sh编辑spark-env.sh⽂件(vim ./conf/spark-env.sh),在第⼀⾏添加以下配置信息:export SPARK_DIST_CLASSPATH=$(/usr/local/hadoop/bin/hadoop classpath)3.通过运⾏Spark⾃带的⽰例,验证Spark是否安装成功。
cd /usr/local/sparkbin/run-example SparkPi执⾏时会输出⾮常多的运⾏信息,输出结果不容易找到,可以通过 grep 命令进⾏过滤(命令中的 2>&1 可以将所有的信息都输出到 stdout 中,否则由于输出⽇志的性质,还是会输出到屏幕中):bin/run-example SparkPi 2>&1 | grep "Pi is"验证结果:⼆.在spark shell中运⾏代码使⽤命令进⼊spark-shell环境,可以通过下⾯命令启动spark-shell环境cd /usr/local/sparkbin/spark-shell启动spark-shell后,就会进⼊“scala>”命令提⽰符状态,如下图所⽰可以使⽤命令“:quit”退出Spark Shell,或者,也可以直接使⽤“Ctrl+D”组合键,退出Spark Shell。
Openfire_spark_安装手册

Openfire+Spark安装手册王保政QQ:29803446Msn:baozhengw999@关键字:快速开发平台openjweb 增删改查即时通信2009-8-29目录第一章JA VA领域的IM解决方案 (3)第二章安装OPENFIRE3.6.4 (3)2.1配置机器的域名 (3)2.2安装OPENFIRE (3)2.2.1 安装 (3)2.2.2 运行数据库脚本 (4)2.2.3 数据库驱动jar包 (6)2.2.4 openfire初始化配置 (6)2.3设置用户 (12)第三章安装SPARK客户端 (13)第四章配置MSN网关 (15)4.1服务端配置MSN网关 (15)第五章RED5视频配置 (18)5.1部署RED5.WAR (18)5.2 SPARK客户端配置视频插件 (19)第六章使用SMACK开发即时通信功能 (22)第一章Java领域的IM解决方案Java领域的即时通信的解决方案可以考虑openfire+spark+smack。
当然也有其他的选择。
Openfire是基于Jabber协议(XMPP)实现的即时通信服务器端版本,目前建议使用3.6.4版本,这个版本是当前最新的版本,而且网上可以找到下载的源代码。
即时通信客户端可使用spark2.5.8,这个版本是目前最新的release版本,经过测试发现上一版本在视频支持,msn网关支持上可能有问题,所以选择openfire3.6.4+spark2.5.8是最合适的选择。
Smack是即时通信客户端编程库,目前我已测通通过jsp使用smack的API向openfire 注册用户发送消息,并且可以通过监听器获得此用户的应答消息。
通过smack向msn用户和QQ用户,gtalk用户发送消息应该也可以实现,关于向gtalk 用户发送消息的例子较多。
这个留待以后研究。
至少目前可以通过程序向spark发消息了。
对于局域网内部应用足以解决系统与用户交互的问题,甚至可以做自动应答机器人。
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
Openfire+Spark+Spark Web安装配置
一.安装环境
操作系统:Windows XP Prefessional SP2
服务器软件:Openfire 3.4.2
Openfire Enterprise 3.4.2
客户端软件:Spark 2.5.7
Spark Fastpath Webchat 3.4.1
JDK:J2SE 5.0 (1.5.0_03)
二.安装Jabber服务器软件
2.1 软件下载
Jabber官网地址:/
常用Jabber服务器软件:/software/servers.shtml
本文以Openfire(Wildfire)为服务器,一款基于GPL协议开源软件,支持各种操作系统,软件需要java环境支持,不过软件本身自带了环境包,你可以根据你的需要下载不同的版本。
下载地址:/downloads/index.jsp#openfire Windows无java环境版本地址:
/downloadServlet?filename=openfire/openfire_3_4_ 2.zip
最新版本:Openfire 3.4.2
2.2Windows版本安装
将openfire_3_2_2.zip解压缩到D:\。
特别要注意,openfire的全路径中不能有中文字符,最好主机名也是标准点的英文名称。
直接运行安装文件,
D:\Openfire\bin\openfire.exe
2.3openfire服务器配置
浏览器地址栏中输入http://localhost:9090/即可开始即时通讯服务器配置。
(1)语言选择:中文简体
(2)服务器设置:选择域及端口,建议默认
(3)数据库设置:选“标准数据库”
(4)标准数据库设置:将oracle驱动放在openfire的lib目录下。
在数据库驱动选项栏选择Oracle。
数据库URL填入你的数据库地址,端口和数据库名称,以及用户名和密码(需要在安装前创建),最大连接数,最小连接数和连接超时时间可自行调整。
继续之后Openfire会在你指定的Oracle库中创建表并初始化。
如果出现A connection to the database could not be made. View the error message by opening the "/logs/error.log" log file, then go back to fix the problem这样的错误提示,请确认你的oracle监听有没有问题,你的用户有没有足够的权限,实在不行把监听和服务命名删掉重新配置下。
(5)特性设置:默认为初使设置(应为初始设置,翻译有误)
(6)管理员帐户设置:填入系统管理员信息
(7)安装完成
(8)Openfire管理控制台:至此,Openfire安装完毕。
你可以继续登录到管理控制台,进行更为详细的设置。
(9)添加新帐户:
打开管理控制台的用户/组标签页,可以看到当前服务器上已有用户的摘要信息。
选择左侧菜单栏中的新建用户,输入用户名和登陆密码,点击创建用户完成新用户的添加。
在客户端就可以用test这个用户登录了。
三.Jabber客户端安装配置
3.1软件下载
客户端软件列表请参考:/software/clients.shtml
我们将使用Spark,因为Spark和Openfire能够很好的相互支持。
软件下载地址:/downloads/index.jsp#spark
Windows含java环境版:
/downloadServlet?filename=spark/spark_2_5_8 .exe
目前最新的版本为:Spark 2.5.8
3.2 Windows安装
(1)下载for windows的版本,运行spark_2_5_8.exe,一直点下一步,就可以安装成功了,默认安装路径C:\Program Files\Spark
(2)选择登陆界面的高级选项:服务器填入你的服务器地址,端口默认为5222,点击确定。
3)用我们在Openfire管理控制台中添加的test用户登录。
(4)登陆后界面
(5)注册一个新帐号:
在spark登陆界面点击帐户,在建立新帐户界面中输入相关信息,点击创建账户。
(4)注册成功后,就可以用test2登录。
四、Jabber连接与MSN、ICQ等IM通讯
Jabber最有优势的就是其通信协议,可以和其他给予XMPP协议的即时通讯软件连接。
如:MSN 、Yahoo Messager、ICQ,GT alk等。
4.1 下载Openfire网关插件IM Gateway
下载地址:/projects/openfire/plugins.jsp
在这里可以下载到openfire的所有插件,我们需要的是
4.2 安装gateway
Gateway的安装非常简单,你只需要把gateway.jar拷贝到openfire/plugins目录下,重启Openfire服务,即可安装成功。
4.3 配置gateway
安装成功后,打开Openfire的管理控制台(例如:http://localhost:9090/),即可在左侧菜单栏下方看到gateway的安装选项(目前没有中文版),如图:
点击Settings,然后在你需要激活的服务上打勾即可。
4.4 Spark客户端配置
重新用Spark登录Openfire,在Spark菜单栏下多了一些选项。
点击MSN的图标,选择输入登入资讯。
填入你的MSN帐号和密码,就可登录MSN了。
五.Spark Webchat的安装
Spark Webchat是基于web的Spark,需要Openfire企业版的支持。
5.1 软件下载
Openfire企业安装版下载地址:
/evaluation!input.jspa?type=of
需要添加一些基本信息,点击“Submit and Download”,在此页面中可以下载到试用版,30天25用户授权,过期后5用户授权,或者复制许可证号。
企业版插件及Spark Fastpath Webchat插件下载地址:
/projects/openfire/plugins.jsp
4.2 Windows版本安装
两种企业版安装方式:
(1)直接运行Openfire企业安装版,openfire_enterprise_3_4_2.exe,并进行相关配置。
(2)基于之前安装过的Openfire安装:将enterprise.jar复制到
D:\openfire\plugins\下,重新启动openfire。
进入管理控制台的Enterprise 标签页,并复制许可证号到这里。
5.3 Sparkweb使用
(1)点击左侧菜单栏的SparkWeb,出现登陆界面。
(2)Spark web主界面
(3)添加联系人
(4)发送信息
(5)接收到信息
Spark web不能保存聊天记录,不能传递文件,当然更不可能支持声音视频等。