数据库集群技术指标
集群监控指标

集群监控指标主要包括以下几类:
1. Load:系统的Load被定义为特定时间间隔内运行队列中的平均线程数。
Load主要反映了系统的繁忙程度,每个CPU核维护着一个运行队列,队列中的线程数越多,意味着CPU越繁忙。
一个正常运行的队列中的线程数不大于3表示CPU运行正常,如果大于5表明CPU运行超负荷。
可以通过top和uptime命令来查看系统的Load 值。
2. CPU使用率:通过top指令查看CPU的使用率。
3. 网络I/O:可以通过sar指令查看每个节点的网络流量,如汇报网络状态(n表示)、查看各个网卡的网络流量(DEV表示)。
4. 磁盘I/O:对于数据库应用和分布式文件存储系统,I/O指标在一定程度上反映了服务的繁忙程度,可以通过iostat -d -k指令查看磁盘I/O状态。
5. 内存使用:可以通过free -g指令查看系统内存。
6. 应用心跳:成熟稳健的系统往往需要对集群运行时的各个指标进行收集,如系统的Load、CPU利用率、I/O繁忙程度、网络traffic、内存利用率、应用心跳等,对这些信息进行实时监控,如发现异常情况,能够第一时间通知到相应的开发和运维人员进行处理。
这些监控指标都从不同的方面描绘了集群的运行状态,对集群的健康运行具有重要意义。
以上各项指标的具体含义和获取方式可能会
因实际环境和需求有所不同,需要根据实际情况进行理解和调整。
数据库技术指标

2.3 支持哈希、范围、与多维数据分区等多种分区方式,同时支持多种分区方式的混合使用,以便支持超大数据量的高负载查询,可实现单表上的TB级数据量Βιβλιοθήκη 数据库技术要求数据库技术要求
1 成熟性要求
1.1 应支持当前最流行的数据库技术标准,如:ANSI/ISO SQL89、ANSI/ISO SQL92、ANSI/ISO SQL99、ODBC3。0、X/Open、CLI、JDBC,XQuery等
1.2 支持多语种,如英文、中文、日文、法文等,必须完全支持中文国家标准的中文字符的存储处理
1.3 支持XML数据的灵活处理与存储,支持XPath访问XML数据,支领灵活的XML Schema的变更和校验,支持XQuery与SQL的混合查询,支持XML高效索引的创建与存取,优化器能够自动根据查询代价判断索引的使用,无需用户手动指定与定制
2 高效性要求
2.1 应支持大数据量处理的数据分区等优化大数据量处理的技术,分区方式不受CPU数量、节点数量等影响,并具有智能的分区管理和重新分区功能,自动均衡数据分布
4.3 应支持随意存取控制、身份识别、角色划分、追踪审计等安全机制
5 开放性要求
5.1 应支持主流厂商的硬件和操作系统平台,如IBM RS6000/AIX、HP (PA/IA64)/HP-UX、SUN/Solaris、Windows 2000/XP/2003、Linux(x86-32/x86-64/PPC/S390)等
2.4 支持数据库行级数据压缩功能,该压缩功能应无须用户手动干预即可灵活支持对已有数据及新插入数据的全面压缩,同时实现高效的压缩比
图数据库功能和指标要求
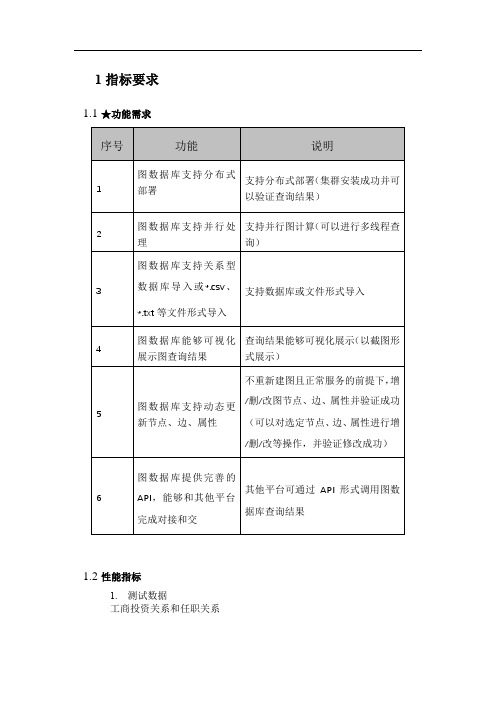
两步最短路径
4
随机选择3组节点,平均耗时<10秒
随机选择3组节点,平均耗时<1秒
10
三步最短路径
4
随机选择3组节点,平均耗时<20秒
随机选择3组节点,平均耗时<1秒
11
十步最短路径
3
随机选择3组节点,平均耗时<50秒
随机选择3组节点,平均耗时<5秒
评分标准
测试项中每项测试不达到得分线得0分,达到得分线不达到优异线得该测试项总分的1/2,达到优异线得该测试项满分。
序号
测试项
分值
评分标准
得分线
优异线
1
数据导入速率
6
加载速率:5GB/h
加载速率:40GB/h
2
实时数据更新速率
2
实ห้องสมุดไป่ตู้数据更新速率:10TPS
实时数据更新速率:1000TPS
3
加载数据占用内存
6
压缩比(原始数据大小/内存占用)≥1
压缩比(原始数据大小/内存占用)≥1.5
4
PageRank(迭代10次
4
5
图数据库支持动态更新节点、边、属性
不重新建图且正常服务的前提下,增/删/改图节点、边、属性并验证成功(可以对选定节点、边、属性进行增/删/改等操作,并验证修改成功)
6
图数据库提供完善的API,能够和其他平台完成对接和交
其他平台可通过API形式调用图数据库查询结果
一.2
1.测试数据
工商投资关系和任职关系
技术部分合计
45
注解
POC测试仅测试厂商对应测试项每项的结果数据,由评标委员会成员对poc测试结果进行评分
一
一.1
序号
数据库技术实践中的常见问题及解决方法

数据库技术实践中的常见问题及解决方法在数据库技术的实践过程中,常常会遇到各种问题。
本文将探讨数据库技术实践中的一些常见问题,并提供相应的解决方法。
一、性能问题数据库性能是一个重要的关注点,当数据库性能下降时,可能会导致系统响应变慢或出现崩溃。
常见的数据库性能问题包括慢查询、高并发、大数据量、索引失效等。
针对这些问题,可以采取以下解决方法:优化SQL查询语句:通过分析慢查询日志,找出执行时间较长的SQL语句,并针对性地进行优化。
优化的方式包括添加索引、调整查询顺序、减少不必要的查询等。
增加硬件资源:当数据库并发量较大或数据量较大时,可以考虑增加硬件资源,如增加内存、使用更高性能的硬盘等。
这样可以提高数据库的处理能力,提升系统的响应速度。
合理设计数据库结构:在数据库设计阶段,应该考虑到数据的读取和写入操作的频率,合理设计数据库的表结构和索引。
通过优化数据库结构,可以提高查询效率,减少不必要的IO操作。
二、数据安全问题数据库中存储着重要的数据资产,数据安全是数据库管理者必须重视的问题。
常见的数据安全问题包括数据泄露、数据被篡改、数据丢失等。
以下是一些解决方法:数据备份与恢复:定期进行数据库备份,并测试备份的完整性,以便在数据丢失时可以及时恢复。
备份可以选择全量备份或增量备份,根据业务需求确定备份频率。
数据访问控制:合理设置数据库用户权限,只给予必要的数据访问权限。
禁止使用默认用户名和密码,并定期修改数据库密码。
使用加密技术:对于重要的敏感数据,可以采用加密技术进行保护。
加密可以应用在数据传输过程中,也可以应用在数据存储过程中。
三、容灾与高可用问题在数据库运营过程中,需要考虑容灾和高可用性的问题,以确保系统的稳定性和可用性。
以下是一些解决方法:数据库复制:采用数据库复制技术,将主数据库的数据同步到一个或多个备份数据库。
当主数据库发生故障时,可以快速切换到备份数据库,确保系统的连续性。
数据库集群:采用数据库集群技术,将数据库分布在多台服务器上,实现负载均衡和故障切换。
大数据平台参数-技术指标要求
大数据平台的Spark组件,支持多租户并行执行,租户任务提交到不同的队列执行,租户间资源隔离
16.
提供基于Hadoop的SQL引擎,支持多租户,使用MPP架构,实现SQL的解析、计划、优化、执行,数据的并行查询,支持JDBC、ODBC标准接口,兼容Hive的ORC文件存储格式,兼容标准SQL 2003语法,以Hive-Test-benchmark测试集上的64个SQL语句为准和tpc-ds测试集上的99个SQL语句为准。
3.
提供访问HDFS的REST接口,通过REST接口创建、删除、上传、下载文件等常规HDFS操作。
4.
大数据平台的支持HDFS联邦,使得HDFS可以创建多个NameService(即多对NameNode),从而提高了集群的扩展性和隔离性。
5.
HDFS冷热数据迁移功能,只需要定义age,基于access time的规则。由HDFS冷热数据迁移工具来匹配基于age的规则的数据,设置存储策略和迁移数据。以这种方式,提高了数据管理效率和集群资源效率。
11.
大数据平台的HBase组件,支持聚簇表/聚簇索引框架的功能
12.
大数据平台提供小文件存储方案,支持海量图片、视频、文档等KB级的数据高并发读写。
13.
大数据平台的Spark组件支持2.0及以上版本
14.
大数据平台的Spark SQL兼容部分Hive语法(以Hive-Test-benchmark测试集上的64个SQL语句为准)和标准SQL语法(以tpc-ds测试集上的99个SQL语句为准)。
提供统一的客户端工具。
22.
大数据平台的流处理组件,集成storm和sparkstreaming,Flink,用户可根据业务需要自主选择
hadoop 量化技术指标

hadoop 量化技术指标
1. 数据总量:衡量Hadoop集群处理大数据的能力,通常以TB、PB等单位进行计算。
2. 单节点存储的数据容量:衡量单个Hadoop节点的硬件配置
以及存储能力,通常以TB为单位。
3. 节点数量:衡量Hadoop集群规模,通常以节点个数来表示。
4. 平均响应时间:衡量Hadoop集群对于各种处理请求的响应
速度。
5. 计算能力:衡量Hadoop集群处理计算密集型任务的能力,
通常以CPU、内存等为指标。
6. 网络带宽:衡量Hadoop集群节点之间传输数据的速度,通
常以GB/s为单位。
7. 故障恢复时间:衡量Hadoop集群在发生故障后,重新恢复
正常工作的速度,通常以分钟或小时为单位。
8. 可扩展性:衡量Hadoop集群的扩展能力,通常以节点添加
时对整个集群的影响程度为指标。
9. 数据冗余度:衡量Hadoop集群对数据备份的实现方式以及
备份数量,通常以数据备份的副本数为指标。
10. 安全性:衡量Hadoop集群对数据安全的保护,通常包括
访问控制、加密性、认证等多个指标。
hadoop集群 cpu标准

Hadoop集群CPU标准对于大规模数据处理和存储领域,Hadoop集群已经成为了一个非常受欢迎的解决方案。
而作为Hadoop集群中最核心的组件之一,CPU 标准也显得格外重要。
在本文中,我们将深入探讨Hadoop集群中CPU标准的相关内容,帮助读者更全面地了解这一主题。
1. 什么是Hadoop集群CPU标准?Hadoop集群CPU标准指的是在Hadoop集群中用于计算和处理数据的CPU配置要求。
在构建Hadoop集群时,选择合适的CPU标准可以对整个集群的性能有着很大的影响。
合理地选择和配置CPU标准是非常重要的。
2. Hadoop集群CPU标准的深度评估在深度评估Hadoop集群CPU标准时,我们需要考虑的因素包括但不限于:- CPU的性能:包括主频、核心数、缓存大小等指标。
不同的处理器性能对Hadoop集群的计算能力有着直接的影响。
- CPU的架构:x86架构、ARM架构等不同的架构对于Hadoop集群的兼容性和性能也有着一定的影响。
- CPU的功耗:在构建Hadoop集群时,需要考虑到CPU的功耗问题,尽量选择能够提供高性能又能够保持低功耗的CPU。
3. Hadoop集群CPU标准的广度评估在广度评估Hadoop集群CPU标准时,我们需要考虑的因素包括但不限于:- 不同厂商的CPU:如Intel、AMD等生产商提供的CPU在性能、兼容性等方面会有所不同,需要根据实际情况做出选择。
- 不同的工作负载:Hadoop集群中可能会存在不同的工作负载,有些是计算密集型的,有些是I/O密集型的,需要选择不同的CPU标准满足不同的工作负载。
4. 总结和回顾通过对Hadoop集群CPU标准的全面评估,我们可以得出以下结论:- 在选择Hadoop集群CPU标准时,需要综合考虑CPU的性能、架构和功耗等因素。
- 针对不同的工作负载,需要选择不同的CPU标准以满足需求。
- 在实际应用中,需要根据具体情况灵活调整CPU标准,以达到最佳的性能和能效比。
mysql tps指标

mysql tps指标TPS(Transactions Per Second)是衡量数据库性能的重要指标,表示数据库每秒可以处理的事务数量。
事务是指数据库中一系列操作的逻辑单元,这些操作要么全部完成,要么全部不完成。
TPS越高,表示数据库的性能越好,能够支持更高的并发访问和数据处理能力。
要提高TPS,需要从多个方面进行优化:1.硬件和系统优化:使用高性能的硬件,如更快的CPU、更多的内存和更快的存储设备,可以提高数据库的处理速度。
同时,通过优化操作系统和网络配置,可以提高系统的稳定性和响应速度。
2.数据库参数优化:调整数据库参数,如缓冲区大小、连接数、线程数等,可以提升数据库的性能。
需要根据实际的业务需求和硬件环境来合理配置这些参数。
3.SQL语句优化:编写高效的SQL语句可以显著提高数据库的性能。
通过对SQL语句进行优化,如使用索引、避免全表扫描、减少JOIN操作等,可以加快查询速度并减少事务的处理时间。
4.数据库设计优化:合理设计数据库结构,如规范化、使用合适的数据类型、分区等,可以提高数据存储和检索的效率。
5.缓存技术:使用缓存技术可以减少对数据库的访问次数,从而提高系统的响应速度。
常见的缓存技术包括内存缓存、分布式缓存等。
6.负载均衡:通过负载均衡技术可以将数据库的访问流量分散到多个服务器上,从而降低单个服务器的负载压力,提高系统的并发处理能力。
7.数据库集群:使用数据库集群可以将多个数据库服务器组成一个整体,通过负载均衡和数据分片等技术实现高性能和高可用性。
总之,提高TPS需要综合考虑多个方面,包括硬件和系统、数据库参数、SQL语句、数据库设计、缓存技术、负载均衡和数据库集群等。
需要根据具体的业务场景和需求来制定合适的优化方案。
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
1.DBTwin技术指标
A.非入侵部署
与所有的系统服务一样,DBTwin也是通过唯一的入口-一对(IP,port)来向外提供数据服务。
因此,应用程序及其数据库接口不需作任何修改。
支持所有的数据库接口:、ADO、RDO、DAO、OLE DB、ODBC、DB-LIBRARY等。
B.支持数据库
Microsoft SQL Server2005/2008的标准版和企业版。
C.事务处理同步复制
通过常用的宽带网络,快速的事务处理同步复制
D.高系统可用性
自动的错误恢复,真正把意料之内和意料之外的停机时间缩至最短。
网关在错误恢复期间的停止服务间隙达到小于10秒。
E.零单点错误源
从DBTwin网关这一部件开始,整个数据库系统是完全、彻底地物理冗余。
F.数据“零”丢失
DBTwin使得系统同时拥有多个实时一致的数据集,这样从理论上讲,就真正消除了数据丢失的任何可能性。
数据库可靠性达到目5个9,即99.999%。
G.动态负载均衡
DBTwin对只读数据库查询操作可以进行自动的判别和动态负载均衡,这是当前唯一实现的针对数据库的动态负载均衡技术,此技术可以大大改善整个数据库系统的性能。
性能提升在30%~300%之间,具体提升比例取决于应用系统及网络结构和软硬的配置。
H.可伸缩性
可伸缩的数据库性能(负载均衡+非入侵式的数据库阵列扩展),使得数据库具有可伸缩性。
需要更多的数据库性能的时候,只要增加数据库服务器就可以了。
I.容灾能力
具备即时的灾难恢复能力。
J.DBTwin自身的双机容错
DBTwin支持自身的双机主备容错切换,也可以采用第三方的HA方案解决DBTwin 自身的容错问题。
DBTwin备份(复制)软件镜像1专为数据库设计是否否
2支持数据库集群是部分支持部分支持
3支持并发数据库操作是否否
4支持动态负载均衡是部分支持部分支持
5工作方式并行串行串行
6支持多份数据集是是是
7支持多份一致数据集是否否
7单点错误源无有有
8支持业务连续性程度高低中
9数据丢失可能性零高高
10错误恢复自动化程度高低中
2.DBTwin与备份/复制软件,及数据库镜像的功能、特点比较。