第二节+数据库集群软件的安装
Hadoop集群MYSQL的安装指南

前言本篇主要介绍在大数据应用中比较常用的一款软件Mysql,我相信这款软件不紧紧在大数据分析的时候会用到,现在作为开源系统中的比较优秀的一款关系型开源数据库已经被很多互联网公司所使用,而且现在正慢慢的壮大中。
在大数据分析的系统中作为离线分析计算中比较普遍的两种处理思路就是:1、写程序利用mapper-Reducer的算法平台进行分析;2、利用Hive组件进行书写Hive SQL进行分析。
第二种方法用到的Hive组件存储元数据最常用的关系型数据库最常用的就是开源的MySQL了,这也是本篇最主要讲解的。
技术准备VMware虚拟机、CentOS 6.8 64 bit、SecureCRT、VSFTP、Notepad++软件下载我们需要从Mysql官网上选择相应版本的安装介质,官网地址如下:MySQL下载地址:/downloads/默认进入的页面是企业版,这个是要收费的,这里一般建议选择社区开源版本,土豪公司除外。
然后选择相应的版本,这里我们选择通用的Server版本,点击Download下载按钮,将安装包下载到本地。
下载完成,上传至我们要安装的系统目录。
这里,需要提示下,一般在Linux系统中大型公用的软件安装在/opt目录中,比如上图我已经安装了Sql Server On linux,默认就安装在这个目录中,这里我手动创建了mysql目录。
将我们下载的MySQL安装介质,上传至该目录下。
安装流程1、首先解压当前压缩包,进入目录cd /opt/mysql/tar -xf mysql-5.7.16-1.el7.x86_64.rpm-bundle.tar这样,我们就完成了这个安装包的解压。
2、创建MySql超级管理用户这里我们需要单独创建一个mySQL的用户,作为MySQL的超级管理员用户,这里也方便我们以后的管理。
groupaddmysql添加用户组useradd -g mysqlmysql添加用户id mysql查看用户信息。
oracle数据库集群搭建步骤

oracle数据库集群搭建步骤
Oracle数据库集群搭建步骤和方法包括:1.安装Oracle Grid Infrastructure;2.安装Oracle Database;3.创建Oracle Database实例;4.配置Oracle Database实例;5.创建Oracle Database 集群;6.配置Oracle Database集群;7.测试Oracle Database集群。
搭建步骤:
1、安装操作系统并升级到满⾜Oracle安装要求的版本。
创建安装所需要的组、⾜户以及软件的家⾜录。
2、设置GNS域名如果您打算部署GNS,并且完成⾜络地址在DNS和服务器上的配置。
设置所要求的存储。
将所有安装⾜件拷贝到⾜个节点上。
3、安装Oracle Grid 集群基础架构, 包括Oracle Clusterware和Oracle ASM (system and storage administration):为集群安装Oracle Grid?基础架构软件。
在安装过程中,Fixup脚本进⾜操作系统参数、SSH和⾜户环境变量等参数的附加调整。
升级Oracle Clusterware和Oracle ASM 到最新补丁。
4.安装Oracle RAC (databaseadministration)打补丁到最新版本。
完成安装后的调试。
大数据Hadoop集群安装部署文档

大数据Hadoop集群安装部署文档一、背景介绍大数据时代下,海量数据的处理和分析成为了一个重要的课题。
Hadoop是一个开源的分布式计算框架,能够高效地处理海量数据。
本文将介绍如何安装和部署Hadoop集群。
二、环境准备1.集群规模:本文以3台服务器组成一个简单的Hadoop集群。
2.操作系统:本文以Linux作为操作系统。
三、安装过程1.安装JavaHadoop是基于Java开发的,因此需要先安装Java。
可以通过以下命令安装:```sudo apt-get updatesudo apt-get install openjdk-8-jdk```2.安装Hadoop```export HADOOP_HOME=/opt/hadoopexport PATH=$PATH:$HADOOP_HOME/bin```保存文件后,执行`source ~/.bashrc`使配置生效。
3.配置Hadoop集群在Hadoop安装目录中的`etc/hadoop`目录下,有一些配置文件需要进行修改。
a.修改`hadoop-env.sh`文件该文件定义了一些环境变量。
可以找到JAVA_HOME这一行,将其指向Java的安装目录:```export JAVA_HOME=/usr/lib/jvm/java-8-openjdk-amd64```b.修改`core-site.xml`文件```<property><name>fs.defaultFS</name><value>hdfs://localhost:9000</value></property>```c.修改`hdfs-site.xml`文件```<property><name>dfs.replication</name><value>3</value></property>```其中,`dfs.replication`定义了数据的副本数,这里设置为34.配置SSH免密码登录在Hadoop集群中,各个节点之间需要进行通信。
DBTWin数据库集群安装使用说明

2. 选中“登录”选项。
无锡浙潮科技有限公司
5
DBTwin 数据库集群系统 5.0 安装使用手册
3. 选择“此帐户”,并输入管理员帐户名称“Administrator”和密码即可。 B. 修改数据库服务的启动帐户 在数据库服务器上的 Windows“服务”中,选中相应的数据库服务,参照修 改 DBTwin 网关服务的启动帐户的过程进行配置。
无锡浙潮科技有限公司
9
DBTwin 数据库集群系统 5.0 安装使用手册
3) 负载均衡算法:当前包含两个负载均衡算法:顺序轮流和网络响应时间。 客户可以根据实际情况进行选择。缺省为:网络响应时间。 4) 数据端口:缺省条件下,DBTwin 使用 8106 端口作为向客户端开放的数据 服务端口。 5)连通性检测次数:检测集群数据库是否脱离集群。 6)连通性检测间隔:检测集群数据库是否脱离集群。 7)删除 SP 配置文件:删除存储过程配置文件。 8)连接最长空闲时间:空闲的数据库连接在经过此时间后会被关闭,缺省为 0,即无限长时间。 9)连接最长滞留时间:连接关闭后,经过此时间后,相应的内部数据结构才 会被清除。 10)最长返回信息长度:SQL 请求能返回的信息的最大长度,缺省为 0,即无 限长。 11)TLS 会话缓冲时间:在此时间内,将复用 TLS 的内部参数,以加快登陆速 度,缺省为 30 分钟。 12)刷新间隔:刷新控制台显示的频率。 13)主机参与负载均衡:指示集群主数据库是否参与只读查询的负载均衡,缺 省为是。 14)重置集群数据库状态:清除数据库断开标志,此选项在测试时候较常用。
接 DBTwin 网关(缺省端口为 8106)。 4.执行:
--建立测试数据库 create database test_db
Hadoop集群安装详细步骤亲测有效

Hadoop集群安装详细步骤亲测有效第一步:准备硬件环境- 64位操作系统,可以是Linux或者Windows-4核或更高的CPU-8GB或更高的内存-100GB或更大的硬盘空间第二步:准备软件环境- JDK安装:Hadoop运行需要Java环境,所以我们需要先安装JDK。
- SSH配置:在主节点和从节点之间建立SSH连接是Hadoop集群正常运行的前提条件,所以我们需要在主节点上生成SSH密钥,并将公钥分发到从节点上。
第四步:配置Hadoop- core-site.xml:配置Hadoop的核心参数,包括文件系统的默认URI和临时目录等。
例如,可以将`hadoop.tmp.dir`设置为`/tmp/hadoop`。
- hdfs-site.xml:配置Hadoop分布式文件系统的参数,包括副本数量和块大小等。
例如,可以将副本数量设置为`3`。
- yarn-site.xml:配置Hadoop的资源管理系统(YARN)的参数。
例如,可以设置YARN的内存资源分配方式为容器的最大和最小内存均为1GB。
- mapred-site.xml:配置Hadoop的MapReduce框架的参数。
例如,可以设置每个任务容器的内存限制为2GB。
第五步:格式化Hadoop分布式文件系统在主节点上执行以下命令,格式化HDFS文件系统:```hadoop namenode -format```第六步:启动Hadoop集群在主节点上执行以下命令来启动Hadoop集群:```start-all.sh```此命令将启动Hadoop的各个组件,包括NameNode、DataNode、ResourceManager和NodeManager。
第七步:测试Hadoop集群可以使用`jps`命令检查Hadoop的各个进程是否正常运行,例如`NameNode`、`DataNode`、`ResourceManager`和`NodeManager`等进程都应该在运行中。
sequoiaDB安装及集群搭建数据库教程
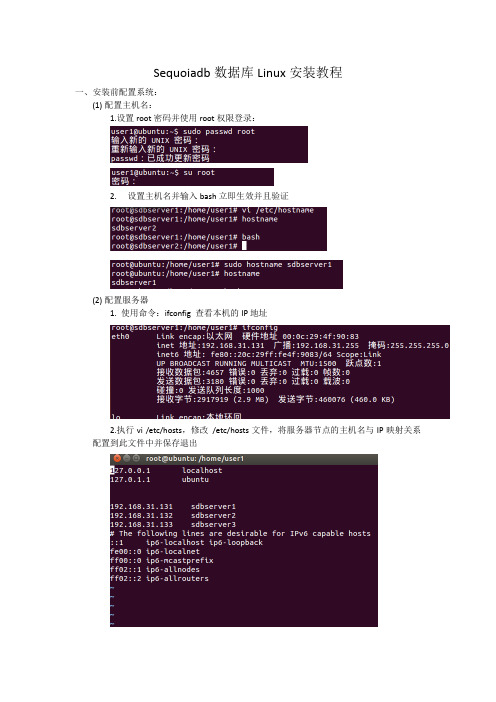
Sequoiadb数据库Linux安装教程一、安装前配置系统:(1)配置主机名:1.设置root密码并使用root权限登录:2.设置主机名并输入bash立即生效并且验证(2)配置服务器1. 使用命令:ifconfig 查看本机的IP地址2.执行vi /etc/hosts,修改/etc/hosts文件,将服务器节点的主机名与IP映射关系配置到此文件中并保存退出3.执行ping sdbserver1 -c 2,验证是否ping通4.调整ulimit:执行vi /etc/security/limits.conf,更改配置并保存退出5.调整内核参数:使用下列命令输出当前vm配置6.执行vi /etc/sysctl.conf,添加内核参数保存退出7.执行sudo /sbin/sysctl -p,使配置生效(3)关闭transparent_hugepage1.编辑/etc/rc.local,在第一行“#!/bin/sh”的下一行添加两行内容:echo never > /sys/kernel/mm/transparent_hugepage/enabledecho never > /sys/kernel/mm/transparent_hugepage/defrag2.执行命令,使配置生效:source /etc/rc.local3. 检查是否成功关闭transparent_hugepage。
分别执行如下两条命令,输出结果中都有“[never]”则表示成功关闭了transparent_hugepage,如果是“never”并且有“[always]”或者“[madvise]”则关闭失败:cat /sys/kernel/mm/transparent_hugepage/enabledcat /sys/kernel/mm/transparent_hugepage/defrag(4)关闭防火墙查看防火墙状态:ufw status 默认处于关闭状态(5) 关闭NUMA:1.以root权限编辑/boot/grub/grub.cfg ,找到"linux"引导行,该行类似如下(不同版本内容略有差异,但开头有“linux /boot/vmlinuz-”):2.在每个Linux引导行的末尾,空格添加“numa=off” ,保存并退出wq!。
hadoop集群安装配置的主要操作步骤-概述说明以及解释

hadoop集群安装配置的主要操作步骤-概述说明以及解释1.引言1.1 概述Hadoop是一个开源的分布式计算框架,主要用于处理和存储大规模数据集。
它提供了高度可靠性、容错性和可扩展性的特性,因此被广泛应用于大数据处理领域。
本文旨在介绍Hadoop集群安装配置的主要操作步骤。
在开始具体的操作步骤之前,我们先对Hadoop集群的概念进行简要说明。
Hadoop集群由一组互联的计算机节点组成,其中包含了主节点和多个从节点。
主节点负责调度任务并管理整个集群的资源分配,而从节点则负责实际的数据存储和计算任务执行。
这种分布式的架构使得Hadoop可以高效地处理大规模数据,并实现数据的并行计算。
为了搭建一个Hadoop集群,我们需要进行一系列的安装和配置操作。
主要的操作步骤包括以下几个方面:1. 硬件准备:在开始之前,需要确保所有的计算机节点都满足Hadoop的硬件要求,并配置好网络连接。
2. 软件安装:首先,我们需要下载Hadoop的安装包,并解压到指定的目录。
然后,我们需要安装Java开发环境,因为Hadoop是基于Java 开发的。
3. 配置主节点:在主节点上,我们需要编辑Hadoop的配置文件,包括核心配置文件、HDFS配置文件和YARN配置文件等。
这些配置文件会影响到集群的整体运行方式和资源分配策略。
4. 配置从节点:与配置主节点类似,我们也需要在每个从节点上进行相应的配置。
从节点的配置主要包括核心配置和数据节点配置。
5. 启动集群:在所有节点的配置完成后,我们可以通过启动Hadoop 集群来进行测试和验证。
启动过程中,我们需要确保各个节点之间的通信正常,并且集群的各个组件都能够正常启动和工作。
通过完成以上这些操作步骤,我们就可以成功搭建一个Hadoop集群,并开始进行大数据的处理和分析工作了。
当然,在实际应用中,还会存在更多的细节和需要注意的地方,我们需要根据具体的场景和需求进行相应的调整和扩展。
linux下mysql集群的安装

/usr/local/mysql-cluster-gpl-7.1.10-linux-i686-glibc23 /usr/local/mysql2.2执行安装脚本:shell> cd mysqlshell> scripts/mysql_install_db –user=mysql2.3修改权限:shell> chown –R root .shell> chown –R mysql datashell> chgrp –R mysql .2.4复制执行文件,加入系统启动项:shell> cp support-files/mysql.server /etc/rc.d/init.d/shell> chmod +x /etc/rc.d/init.d/mysql.servershell> chkconfig –add mysql.server管理节点的安装1.解压安装shell> cd /var/tmpxzvf mysql-cluster-gpl-7.1.10-linux-i686-glibc23.tar.gzshell> cd mysql-cluster-gpl-7.1.10-linux-i686-glibc23shell> cp bin/ndb_mgm* /usr/local/bin2.修改权限shell> cd /usr/local/binshell> chmod +x ndb_mgm*3.配置文件3.1创建数据节点和mysql节点的f配置文件shell> vi /etc/ff内容如下:[mysqld]# Options for mysqld process:ndbcluster # run NDB storage enginendb-connectstring=192.168.0.10 # location of management server [mysql_cluster]# Options for ndbd process:ndb-connectstring=192.168.0.10 # location of management server3.2创建管理节点的config.ini配置文件shell> vi config.iniconfig.ini内容如下:[ndbd default]# Options affecting ndbd processes on all data nodes:NoOfReplicas=2 # Number of replicasDataMemory=80M # How much memory to allocate for data storage IndexMemory=18M # How much memory to allocate for index storage# For DataMemory and IndexMemory, we have used the# default values. Since the "world" database takes up# only about 500KB, this should be more than enough for# this example Cluster setup.[tcp default]# TCP/IP options:portnumber=2202# port that is free for all the hosts in the cluster# Note: It is recommended that you do not specify the port# number at all and simply allow the default value to be used# instead[ndb_mgmd]# Management process options:hostname=192.168.0.10 # Hostname or IP address of MGM nodedatadir=/var/lib/mysql-cluster # Directory for MGM node log files [ndbd]# Options for data node "A":# (one [ndbd] section per data node)hostname=192.168.0.30 # Hostname or IP address datadir=/usr/local/mysql/data # Directory for this data node's data files[ndbd]# Options for data node "B":hostname=192.168.0.40 # Hostname or IP address datadir=/usr/local/mysql/data # Directory for this data node's data files[mysqld]# SQL node options:hostname=192.168.0.20 # Hostname or IP address# (additional mysqld connections can be# specified for this node for various# purposes such as running ndb_restore)4.启动集群1.启动管理服务器:(正常情况下,它们位于/usr/local/mysql/bin目录下)。
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
第二节 数据库集群软件的安装2.1操作系统安装注意事项本文档中所使用的操作系统是:Oracle Enterprise Linux R4 Update 8操作系统的安装步骤在这里就不写了,不是本文重点,每个学习oracle的朋友应该对系统的安装配置很熟悉的,这里只提出安装系统的时候注意所需要的软件的安装。
Rpm –qa |grep compatcompat‐boost‐1331‐1.33.1‐5.0.1.el4compat‐libgcc‐296‐2.96‐132.7.2compat‐openldap‐2.1.30‐12.el4compat‐dapl‐2.0.15‐1.el4compat‐gcc‐32‐c++‐3.2.3‐47.3compat‐libstdc++‐33‐3.2.3‐47.3compat‐db‐4.1.25‐9compat‐libcom_err‐1.0‐5compat‐libstdc++‐296‐2.96‐132.7.2compat‐gcc‐32‐3.2.3‐47.3系统安装完之后的设置过程中需要将防火墙关闭,Seliux 关闭以免出现不必要的麻烦 2.2安装集群前的系统配置第一台 配置:创建 Oracle 组和用户帐户接下来我们将创建用于安装和维护 Oracle 10g 软件的 Linux 组和用户帐户。
用户帐户名是‘oracle’,组是‘oinstall’和‘dba’。
仅在一个集群主机上以 root 用户身份执行以下命令:#/usr/sbin/groupadd oinstall#/usr/sbin/groupadd dba#/usr/sbin/useradd ‐m ‐g oinstall ‐G dba oracle#id oracle# id oracleuid=501(oracle) gid=501(oinstall) groups=501(oinstall),502(dba)用户 ID 和组 ID 在所有集群主机上必须相同。
使用从 id oracle 命令得到的信息,在其余集群主机上创建 Oracle 组和用户帐户:# /usr/sbin/groupadd ‐g 501 oinstall# /usr/sbin/groupadd ‐g 502 dba# /usr/sbin/useradd ‐m ‐u 501 ‐g oinstall ‐G dba oracle# id oracleuid=501(oracle) gid=501(oinstall) groups=501(oinstall),502(dba)设置 oracle 帐户的口令:# passwd oracleChanging password for user oracle.New password:Retype new password:passwd:all authentication tokens updated successfully.注意:以上的用户添加设置在oracle linux 不必配置,应为在 oracle linux 中已经在安装的时候被oracle默认添加了,但是在readhat linux 中需要手动设置添加。
2.3操作系统内核参数配置配置 Linux 内核参数 (10G)以 root 用户身份登录后执行下命令。
cat >> /etc/sysctl.conf <<EOFkernel.shmall = 2097152kernel.shmmax = 2147483648kernel.shmmni = 4096kernel.sem = 250 32000 100 128fs.file‐max = 65536net.ipv4.ip_local_port_range = 1024 65000net.core.rmem_default = 262144net.core.rmem_max = 262144net.core.wmem_default = 262144net.core.wmem_max = 262144EOF/sbin/sysctl ‐p=====================================为 oracle 用户设置 Shell 限制Oracle 建议对每个 Linux 帐户可以使用的进程数和打开的文件数设置限制。
要进行这些更改,以 root 用户的身份执行下列命令:cat >> /etc/security/limits.conf <<EOForacle soft nproc 2047oracle hard nproc 16384oracle soft nofile 1024oracle hard nofile 65536EOFcat >> /etc/pam.d/login <<EOFsession required /lib/security/pam_limits.soEOF配置 Hangcheck 计时器所有 RHEL 版本:modprobe hangcheck ‐timer hangcheck_tick=30 hangcheck_margin=180cat >> /etc/rc.d/rc.local >>EOFmodprobe hangcheck ‐timer hangcheck_tick=30 hangcheck_margin=180EOF2.4 oracle 软件环境配置2.4.1 创建安装目录mkdir ‐p /u01/app/oracle/10g/crsmkdir ‐p /u01/app/oracle/10g/db_1chown ‐R oracle:oinstall /u01/app/oracle/10g/crs /u01/app/oracle/10g/db_1sr/local/lib:/usr/X11R6/lib acle/10g/db_1/ocommon/nls/admin/dataCLE_OWNER=oracle:/bin:/usr/sbin:/us .111:0.0 #我物理机器的IP 地址 为方便使用XmanagerHOME/jlib:$ORACLE_HOME/rdbms/jlib $ORACLE_HOME/network/jlibexport PATH CLASSPATHchmod ‐R 775 /u01/app/oracle/10g/crs /u01/app/oracle/10g/db_1oracle 用户的环境变量编辑vi /home/oracle/.bash_profile添加如下内容:export ORACLE_SID=rac1export ORACLE_BASE=/u01/app/oracle/10g/export ORACLE_HOME=/u01/app/oracle/10g/db_1exportLD_LIBRARY_PATH=/u01/app/oracle/10g/db_1/lib:/lib:/usr/lib:/u export TNS_ADMIN=/u01/app/oracle/10g/db_1/network/adminexport ORA_NLS33=/u01/app/or export ORA exportPATH=/usr/kerberos/sbin:/usr/kerberos/bin:/usr/local/sbin:/usr/local/bin:/sbin r/bin:/root/bin:/u01/app/oracle/10g/db_1/bin:/u01/app/oracle/10g/crs_1/binexport DISPLAY=192.168.1export LD_LIBRARY_PATHexport PATH=$PATH:$ORACLE_HOME/binCLASSPATH=$CLASSPATH:$ORACLE_HOME/JRE:$ORACLE_CLASSPATH=$CLASSPATH:2.4.2/e 配置 tc/hosts0.0.1) 相关联。
如果出现这种情况,则从回st92.168.1.252 rac1‐ rac1‐vip192.168.1.253 rac2rac2‐privrac2‐vip程语。
输入您能记住的口令,然后再次输入该口当您完成以下步骤后,在 ~/.ssh 目录中将会有四个文件: id_rsa 、id_rsa.pub 、b 。
id_rsa 和 id_dsa 文件是您的专用密钥,千万不要告诉任何人。
录:ty for no passphrase):ved in /home/oracle/.ssh/id_rsa.e/oracle/.ssh/id_rsa.pub.3 oracle@ty for no passphrase):有些 Linux 发行版本将主机名与回送地址 (127.送地址中删除IP 地址的分配:127.0.0.1 localhost.localdomain localho 192.168.1.254 rac1192.168.2.254 rac1‐ rac1‐priv1192.168.2.253 rac2‐ 192.168.1.251 rac2‐ 2.4.3为用户等效性配置 SSH在安装 Oracle RAC 10g 期间,OUI 需要把文件复制到集群中的其他主机上并在其上执行序。
为了允许OUI 完成此任务,必须配置 SSH 以启用用户等效性。
用 SSH 建立用户等效性就提供了一种在集群中其他主机上复制文件和执行程序时不需要口令提示的安全方式。
第一步是生成 SSH 的公共密钥和专用密钥。
SSH 协议有两个版本;版本 1 使用 RSA ,版本 2 使用DSA ,因此我们将创建这两种类型的密钥,以确保 SSH 能够使用任一版本。
ssh ‐keygen 程序将根据传递给它的参数生成任一类型的公共密钥和专用密钥。
当您运行 ssh ‐keygen 时,将提示您输入一个用于保存密钥的位置。
当提示时只需按 Enter 接受默认值。
随后将提示您输入一个口令短令进行确认。
id_dsa 和 id_dsa.pu id_rsa.pub 和 id_dsa.pub 文件是您的公共密钥,必须将其复制到集群中其他每个主机上。
在每个主机上,以 oracle 用户身份登$ mkdir ~/.ssh$ chmod 755 ~/.ssh$ /usr/bin/ssh ‐keygen ‐t rsaGenerating public/private rsa key pair.Enter file in which to save the key (/home/oracle/.ssh/id_rsa):Enter passphrase (emp Enter same passphrase again:Your identification has been sa Your public key has been saved in /hom The key fingerprint is:c8:a2:20:7f:bd:b5:7b:41:fa:16:69:72:c2:e0:06:0$ /usr/bin/ssh ‐keygen ‐t dsaGenerating public/private dsa key pair.Enter file in which to save the key (/home/oracle/.ssh/id_dsa):Enter passphrase (empEnter same passphrase again:Your identification has been saved in /home/oracle/.ssh/id_dsa.Your public key has been saved in /home/oracle/.ssh/id_dsa.pub.The key fingerprint is:71:d0:96:6b:5b:06:f5:88:cc:50:cd:19:9b:a9:60:4e oracle@现在,必须将每个主机上的公共密钥文件 id_rsa.pub 和 id_dsa.pub 的内容复制到其他每个主机的~/.ssh/authorized_keys 文件中。