数据仓库习题集
数据库题库含参考答案

数据库题库含参考答案一、单选题(共98题,每题1分,共98分)1.在数据库应用系统生命周期模型中,规划与分析阶段的输出结果不包括()。
A、项目计划书B、需求规范说明书C、可行性分析报告D、系统范围与边界正确答案:B2.下列哪些属性不适合建立索引?()。
A、经常岀现在GROUP BY子句中的属性B、经常参与连接操作的属性C、经常出现在WHERE子句中的属性D、经常需要进行更新操作的属性正确答案:D3.下列属于数据仓库特点的是()。
A、一次处理的数据量小B、综合性和提炼性数据C、面向操作人员,支持日常操作D、重复性的、可预测的处理正确答案:B4.下述哪一个SQL语句用于实现数据存取的安全机制()。
A、COMMITB、ROLLBACKC、GRANTD、CREATE TABLE正确答案:C5.有教师表(教师号,姓名,职称.所在系)和授课表(教师号,课程号,授课学年,授课时数),同一门课程可由多个教师讲授,同一个教师也可讲授多门课程,査询从未被“教授”讲授过的课程的课程号,正确的语句是()。
A、SELECT课程号FROM授课表a JOIN教师表bON a 教师号=b.教师号WHERE职称!='教授'B、SELECT课程号FROM授课表a RIGHTOUTTER JOIN教师表bONa.教师号=b.教师号C、SELECT课程号FROM授课表WHERE课程号NOT IN (SELECT课程号FROM授课表a JOIN授课表b ON a 教师号=b.教师号WHERE职称!='教授')D、SELECT课程号FROM授课表WHERE课程号IN (SELECT课程号FROM授课表a JOIN授课表b ON a 教师号=b.教师号WHERE职称!=,教授,)正确答案:D6.下列有关范式的叙述中正确的是()。
A、如果关系模式RG 1NF,且R中主属性完全函数依赖于码,则R是2NFB、如果关系模式RG3NF, X、YCU,若X—Y,则R是BCNFC、如果关系模式ReBCNF,若X一一Y (Y4X)是平凡的多值依赖,则R 是4NFD、—个关系模式如果属于4NF,则一定属于BCNF;反之不成立正确答案:D7.下列说法正确的是( )。
数据仓库概念习题与答案(商务智能)

1、商务智能包括哪些核心技术?A.计算机技术B.数据挖掘C.数据仓库D.数据库正确答案:B、C2、将商务智能从一种想法变为企业实际应用的主要技术包括哪些?A.数据存储B.电子商务C.计算机软件D.计算机硬件正确答案:A、C、D3、数据和信息之间的关系正确的是一下哪些选项?A.数据是加工过的信息B.信息是数据C.数据和信息没有关系D.信息是加工过的数据正确答案:B、D4、设计数据库的目的是为了解决数据的存储和访问等基本问题,数据库在设计之初就要考虑满足以下操作。
A.大数据量访问B.批量数据读写C.多用户访问正确答案:C、D5、分析数据包括以下哪些内容?A.细节数据B.外部数据C.企业内部数据D.当前业务数据正确答案:A、B、C、D6、分析型数中有冗余是因为以下哪些原因?A.减少存储空间B.提高查询效率C.减少细节数据D.减少算计量正确答案:B、D7、在事务型处理环境下,操作具有以下哪些特点?A.响应时间短B.多是过程重复操作C.经常进行删除、增加、更新操作D.操作次数少正确答案:A、B、C8、数据仓库有哪些特点?A.数据随时间而变化B.面向主题C.数据不常改变正确答案:A、B、C、D9、以下说法哪些是正确的?A.服务于决策支持B.数据仓库建设有明确的起、止时间C.数据仓库是一个数据集合D.数据仓库建设是一个过程正确答案:A、C、D10、数据集成主要完成以下哪些工作?A.模型设计B.数据转换C.消除数据冲突D.多数据源数据抽取正确答案:B、C、D二、判断题1、管理就是决策,决策是企业管理的核心。
正确答案:对2、分析数据来自于某一个指定的业务数据库,并通过批量读取的方式写入数据仓库。
正确答案:错3、数据越详细具体包含的信息也就越多,因此,分析型数据应该是明细数据。
正确答案:错4、当前的数据才能代表最新的信息,因此,分析型数据应该是当前数据而不是历史数据。
正确答案:错5、在数据库设计时使用范式约减的目的是为了:防止出现数据的更新、查找、删除异常,同时减少数据的冗余。
数据库习题与答案

数据库习题与答案一、选择题1、以下哪个不是数据库的特征?A.共享性B.安全性C.完整性D.随意性答案:D.随意性解释:数据库具有共享性、安全性、完整性等特征,但随意性并不是数据库的特征。
2、下列哪个是关系型数据库的优点?A.易于使用和管理B.支持复杂查询C.可以存储大量数据D.以上都是答案:D.以上都是解释:关系型数据库具有易于使用和管理、支持复杂查询、可以存储大量数据等优点。
3、SQL是下列哪个数据库系统的标准语言?A. OracleB. MySQLC. SQL ServerD. DB2答案:A. Oracle解释:SQL是Oracle数据库系统的标准语言。
4、下列哪个是数据库系统的组成部分?A.数据库B.操作系统C.应用程序D.以上都是答案:D.以上都是解释:数据库系统由数据库、操作系统、应用程序等组成。
5、下列哪个是对数据库系统的正确描述?A.数据库系统可以取代文件系统B.数据库系统与文件系统完全不同C.数据库系统是一个层次结构D.数据库系统是一个客户-服务器结构答案:D.数据库系统是一个客户-服务器结构解释:数据库系统是一个客户-服务器结构,它由多个组成部分组成,包括数据库、操作系统、应用程序等。
与文件系统相比,数据库系统可以提供更高效、更可靠的数据存储和管理。
二、填空题1、________是指数据的结构化程度。
关系型数据库中的数据是按照__________组织的。
答案:数据结构化;表格形式解释:数据的结构化程度是指数据之间关系的清晰程度和组织方式。
在关系型数据库中,数据是按照表格形式组织的,每个表格由行和列组成,行表示记录,列表示字段。
2、SQL语言中,可以使用_________关键字来创建一个新的表格。
____________用于向表格中插入数据。
答案:CREATE TABLE;INSERT INTO解释:在SQL语言中,可以使用CREATE TABLE关键字来创建一个新的表格。
INSERT INTO用于向表格中插入数据。
数据库习题(含参考答案)

数据库习题(含参考答案)习题1一、问答题1. 什么是数据?数据有什么特征?数据和信息有什么关系?答:答:数据是用于载荷信息的物理符号。
数据的特征是:①数据有“型”和“值’之分;②数据受数据类型和取值范围的约束;③数据有定性表示和定量表示之分;④数据应具有载体和多种表现形式。
数据与信息的关系为:数据是信息的一种表现形式,数据通过能书写的信息编码表示信息。
信息有多种表现形式,它通过手势、眼神、声音或图形等方式表达,但是数据是信息的最佳表现形式。
由于数据能够书写,因而它能够被记录、存储和处理,从中挖掘出更深层的信息。
但是,数据不等于信息,数据只是信息表达方式中的一种。
正确的数据可表达信息,而虚假、错误的数据所表达的是谬误,不是信息。
2. 什么是数据库?数据库中的数据有什么特点。
答:答:数据库是数据管理的新方法和技术,它是一个按数据结构来存储和管理数据的计算机软件系统。
数据库中的数据具有的特点是:①数据库中的数据具有数据整体性,即数据库中的数据要保持自身完整的数据结构;②数据库中的数据具有数据共享性,不同的用户可以按各自的用法使用数据库中的数据,多个用户可以同时共享数据库中的数据资源。
3. 什么是数据库管理系统?它的主要功能是什么?答:答:数据库管理系统简称DBMS(Database Management System),它是专门用于管理数据库的计算机系统软件。
数据库管理系统能够为数据库提供数据的定义、建立、维护、查询和统计等操作功能,并完成对数据完整性、安全性进行控制的功能。
数据库管理系统的主要功能是数据存储、数据操作和数据控制功能。
其数据存储和数据操作是:数据库的定义功能,指为说明库中的数据情况而进行的建立数据库结构的操作;数据库建立功能,指将大批数据录入到数据库的操作,它使得库中含有需要保存的数据记录;数据库维护功能,指对数据的插入、删除和修改操作,其操作能满足库中信息变化或更新的需求;数据查询和统计功能,指通过对数据库的访问,为实际应用提供需要的数据。
数据库系统原理练习题库(附参考答案)

数据库系统原理练习题库(附参考答案)一、单选题(共100题,每题1分,共100分)1.属于数据库结构设计阶段的是A、程序设计B、功能设计C、事务设计D、逻辑结构设计正确答案:D2.人工管理阶段,计算机主要应用于A、数据集成B、科学计算C、过程控制D、故障恢复正确答案:B3.下列关于数据控制语言的说法中,正确的是A、REVOKE语句用于授予权限B、GRANT语句用于收回权限C、数据控制语言主要用于数据执行流程管理D、数据控制语言包括的主要SQL语句是GRANT和REVOKE正确答案:D4.下列属于关联分析算法的是A、AprioriB、GMMC、RedisD、HBase正确答案:A5.同一数据被反复存储的情况是A、删除异常B、插入异常C、更新异常D、数据冗余正确答案:D6.产生数据不一致的主要原因是并发操作破坏了事务的A、持续性B、一致性C、原子性D、隔离性正确答案:D7.DBMS提供【】来严格地定义模式。
A、模式描述语言B、子模式描述语言C、内模式描述语言D、程序设计语言正确答案:A8.关系数据库以【】作为数据的逻辑模型。
A、二维表B、关系C、关系模型D、数据库正确答案:C9.关于调用存储过程的说法,错误的是A、可以从交互式界面调用B、可以使用CALL语句来调用存储过程C、可以由嵌入式SQL调用D、不是所有的SQL接口都能调用存储过程正确答案:D10.可唯一标识实体的属性集称为A、键B、实体型C、域D、属性正确答案:A11.目的是为可实际运行的应用程序设计提供依据与指导,并作为设计评价的基础的是A、设计评价B、编制应用程序设计说明C、模型转换D、子模式设计正确答案:B12.在使用游标的过程中,需要注意的事项不包括A、游标不能单独在查询操作中使用B、在一个BEGIN···END语句块中每一个游标的名字并不是唯一的C、游标是被SELECT语句检索出来的结果集D、在存储过程或存储函数中可以定义多个游标正确答案:B13.对关系的描述不正确的是A、关系中的元组次序可交换B、关系可以嵌套定义C、关系是一张二维表D、关系是一个集合正确答案:B14.下列关于MySQL的说法中,正确的是A、在MySQL中,一个关系对应多个基本表B、在MySQL中,一个或多个基本表对应一个存储文件C、在MySQL中,一个表只能有一个索引D、在MySQL中,索引不能存放在存储文件中正确答案:B15.关系数据库是以【】的形式组织数据。
数据库设计综合练习题及答案
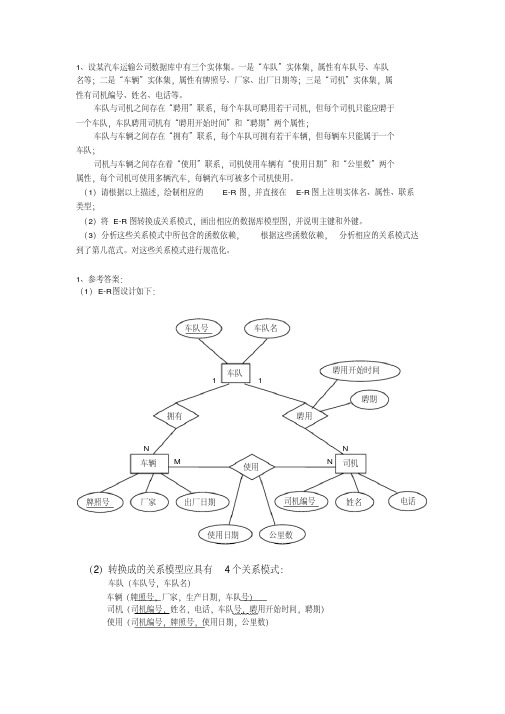
(3). 有若干比赛项目,包括:项目号,名称,比赛地点 (4). 每名运动员可参加多项比赛,每个项目可有多人参加 (5). 要求能够公布每个比赛项目的运动员名次与成绩 解题要求:
(1)请根据以上描述,绘制相应的 E-R 图,并直接在
E-R 图上注明实体名、属性、联系
类型;
(2)将 E-R 图转换成关系模型,画出相应的数据库模型图,并说明主键和外键。
聘用
聘期
N N 司机
牌照号
厂家
出厂日期
司机编号
姓名
电话
使用日期
公里数
(2)转换成的关系模型应具有 4 个关系模式:
车队(车队号,车队名) 车辆(牌照号,厂家,生产日期,车队号) 司机(司机编号,姓名,电话,车队号,聘用开始时间,聘期) 使用(司机编号,牌照号,使用日期,公里数)
相应的数据库模型图为:
车队与车辆之间存在“拥有”联系,每个车队可拥有若干车辆,但每辆车只能属于一个 车队;
司机与车辆之间存在着“使用”联系,司机使用车辆有“使用日期”和“公里数”两个 属性,每个司机可使用多辆汽车,每辆汽车可被多个司机使用。
(1)请根据以上描述,绘制相应的 E-R 图,并直接在 E-R 图上注明实体名、属性、联系 类型;
模式都是 3NF 模式。
因此,R 分解成 3NF关系模式集时, R={ R11,R12,R2 } 。
4、综合设计题 设有学生运动会模型:
(1). 有若干班级,每个班级包括: 班级号,班级名,专业号,专业名,人数 (2). 每个班级有若干运动员,运动员只能属于一个班,包括 : 运动员编号,姓名,性别,年 龄
商店与商品之间存在着“销售”联系,每个商店可销售若干种商品,每种商品可在若干 商店里销售,每个商店销售一种商品有月份和月销售量两个属性;
数据仓库-期末考试复习题

数据仓库-期末考试复习题复思考题(重点)一、单项选择题1)一般信息管理中,采用哪种方式的概念模型最多A。
ce模型B.实体-关系模型C.02O模型D.B/S模型(2)在关系表中,下列哪种属性不能承担主列关键字(Key)?A.身份证号B.银行卡号C.加密电文D.企业标识码(3)数据仓库的生命周期中,不包含下列哪个阶段?A.规划分析阶段B.设计实施阶段C.使用维护阶段D.反馈提升阶段(4)多维切片是指:A.在多个维度上观察全员操作B.多个成员的操作片段C.旋转数据集的部分维度D.在线分析或联机分析(5)一般信息管理中,采用哪种方式的分布式物理模型最多A。
ce模型 B.实体-关系模型C.02O模型D.B/S模型(6)在关系表中,下列哪种属性可以成为外键(Key)?A.客户信用程度B.银行卡行号C.加密的身份证号D.实体商户地址(7)数据仓库的生命周期中,不包含下列哪个阶段排在第三阶段?A.规划分析阶段 B.设计实施阶段 C.使用维护阶段D.反馈提升阶段(8)多维报表是指:A.在多个维度上观察全员操作B.分歧维度花式分歧叠加展示C.旋转数据集的部分维度D.在线阐发或联机阐发(9)数据表的多维索引的感化是:A.使数据表更节省存储空间B.加快数据存储速率C.表格花式美观大方C.加快数据查找效率10)de布局中的MAP职能是?A.钻取B.汇聚C.分发D.结晶11)下列哪种客户需求能够直接成为数据堆栈的多维报表?A.客户销售业绩清单B.客户根本名册C.客户关系图表D.客户反馈信息(12)数据堆栈开辟强调哪种主体特征?A.信息安全性B.业务流程C.操作事务性D.数据实时性(13)数据仓库与数据库系统相比,更加提倡:A.空间换时间B.数据范式更严格C.冗余度更小C.更加适用于分布式结构(14)透视表属于OLAP中的哪种能力范畴?A.存储本领B.展示本领C.稳定性本领D.安全性本领(15)OLAP的系统布局分为:A.胖客户端系统和瘦客户端系统B。
数据库习题集及答案参考

数据库系统概论习题集数据库基本概况一、选择题1. DBS是采用了数据库技术的计算机系统,它是一个集合体,包含数据库、计算机硬件、软件和()。
A. 系统分析员B. 程序员C. 数据库管理员D. 操作员2. 数据库(DB),数据库系统(DBS)和数据库管理系统(DBMS)之间的关系是()。
A. DBS包括DB和DBMSB. DBMS包括DB和DBSC. DB包括DBS和DBMSD. DBS就是DB,也就是DBMS3. 下面列出的数据库管理技术发展的三个阶段中,没有专门的软件对数据进行管理的是()。
I.人工管理阶段II.文件系统阶段III.数据库阶段A. I 和IIB. 只有IIC. II 和IIID. 只有I4. 下列四项中,不属于数据库系统特点的是()。
A. 数据共享B. 数据完整性C. 数据冗余度高D. 数据独立性高5. 数据库系统的数据独立性体现在()。
A.不会因为数据的变化而影响到应用程序B.不会因为系统数据存储结构与数据逻辑结构的变化而影响应用程序C.不会因为存储策略的变化而影响存储结构D.不会因为某些存储结构的变化而影响其他的存储结构6. 描述数据库全体数据的全局逻辑结构和特性的是()。
A. 模式B. 内模式C. 外模式D. 用户模式7. 要保证数据库的数据独立性,需要修改的是()。
A. 模式与外模式B. 模式与内模式C. 三层之间的两种映射D. 三层模式8. 要保证数据库的逻辑数据独立性,需要修改的是()。
A. 模式与外模式的映射B. 模式与内模式之间的映射C. 模式D. 三层模式9. 用户或应用程序看到的那部分局部逻辑结构和特征的描述是(),它是模式的逻辑子集。
A.模式B. 物理模式C. 子模式D. 内模式10.下述()不是DBA数据库管理员的职责。
A.完整性约束说明B. 定义数据库模式C.数据库安全D. 数据库管理系统设计选择题参考答案:(1) C (2) A (3) D (4) C (5) B (6) A (7) C (8) A (9) C (10) D二、简答题1.试述数据、数据库、数据库系统、数据库管理系统的概念。
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
一、选择填空.数据仓库的特点分别是面向主题、集成、相对稳定、反映历史变化。
、粒度是对数据仓库中数据的综合程度高低的一个衡量。
粒度越小,细节程度越高,综合程度越低,回答查询的种类越多。
维度可以根据其变化快慢分为元变化维度、缓慢变化维度和剧烈变化维度三类。
连续型属性的数据样本之间的距离有欧氏距离、曼哈顿距离和明考斯基距离。
在数据挖掘的分析方法中,直接数据挖掘包括(ACD)A 分类B 关联C 估值D 预言数据仓库的数据ETL过程中,ETL软件的主要功能包括(ABC)A 数据抽取B 数据转换C 数据加载D 数据稽核数据分类的评价准则包括( ABCD )A 精确度B 查全率和查准率C F-MeasureD 几何均值层次聚类方法包括( BC )A 划分聚类方法B 凝聚型层次聚类方法C 分解型层次聚类方法D 基于密度聚类方法贝叶斯网络由两部分组成,分别是( A D )A 网络结构B 先验概率C 后验概率D 条件概率表置信度(confidence)是衡量兴趣度度量( A )的指标。
A、简洁性B、确定性C.、实用性D、新颖性关于OLAP和OLTP的区别描述,不正确的是: (C)A. OLAP主要是关于如何理解聚集的大量不同的数据.它与OTAP应用程序不同.B. 与OLAP应用程序不同,OLTP应用程序包含大量相对简单的事务.C. OLAP的特点在于事务量大,但事务内容比较简单且重复率高.D. OLAP是以数据仓库为基础的,但其最终数据来源与OLTP一样均来自底层的数据库系统,两者面对的用户是相同的简单地将数据对象集划分成不重叠的子集,使得每个数据对象恰在一个子集中,这种聚类类型称作( B )A、层次聚类B、划分聚类C、非互斥聚类D、模糊聚类将原始数据进行集成、变换、维度规约、数值规约是在以下哪个步骤的任务?(C)A. 频繁模式挖掘B. 分类和预测C. 数据预处理D. 数据流挖掘为数据的总体分布建模;把多维空间划分成组等问题属于数据挖掘的哪一类任务?(B)A. 探索性数据分析B. 建模描述C. 预测建模D. 寻找模式和规则6.在数据挖掘的分析方法中,直接数据挖掘包括(ACD)A 分类B 关联C 估值D 预言7.数据仓库的数据ETL过程中,ETL软件的主要功能包括(ABC)A 数据抽取B 数据转换C 数据加载D 数据稽核8.数据分类的评价准则包括( ABCD )A 精确度B 查全率和查准率C F-MeasureD 几何均值9.层次聚类方法包括( BC )A 划分聚类方法B 凝聚型层次聚类方法C 分解型层次聚类方法D 基于密度聚类方法10.贝叶斯网络由两部分组成,分别是( A D )A 网络结构B 先验概率C 后验概率D 条件概率表二、判断题1. 数据挖掘的主要任务是从数据中发现潜在的规则,从而能更好的完成描述数据、预测数据等任务。
(对)2. 数据挖掘的目标不在于数据采集策略,而在于对于已经存在的数据进行模式的发掘。
(对)3. 图挖掘技术在社会网络分析中扮演了重要的角色。
(对)4. 模式为对数据集的全局性总结,它对整个测量空间的每一点做出描述;模型则对变量变化空间的一个有限区域做出描述。
(错)5. 寻找模式和规则主要是对数据进行干扰,使其符合某种规则以及模式。
(错)6. 离群点可以是合法的数据对象或者值。
(对)7. 离散属性总是具有有限个值。
(错)8. 噪声和伪像是数据错误这一相同表述的两种叫法。
(错)9. 用于分类的离散化方法之间的根本区别在于是否使用类信息。
(对)10. 特征提取技术并不依赖于特定的领域。
(错)11. 序列数据没有时间戳。
(对)12. 定量属性可以是整数值或者是连续值。
(对)13. 可视化技术对于分析的数据类型通常不是专用性的。
(错)14. DSS主要是基于数据仓库.联机数据分析和数据挖掘技术的应用。
(对)15. OLAP技术侧重于把数据库中的数据进行分析、转换成辅助决策信息,是继数据库技术发展之后迅猛发展起来的一种新技术。
(对)16. 商业智能系统与一般交易系统之间在系统设计上的主要区别在于:后者把结构强加于商务之上,一旦系统设计完毕,其程序和规则不会轻易改变;而前者则是一个学习型系统,能自动适应商务不断变化的要求。
(对)17. 数据仓库中间层OLAP服务器只能采用关系型OLAP (错)18.数据仓库系统的组成部分包括数据仓库,仓库管理,数据抽取,分析工具等四个部分. (错)19. Web数据挖掘是通过数据库仲的一些属性来预测另一个属性,它在验证用户提出的假设过程中提取信息. (错)21. 关联规则挖掘过程是发现满足最小支持度的所有项集代表的规则。
(错)22. 利用先验原理可以帮助减少频繁项集产生时需要探查的候选项个数(对)。
23. 先验原理可以表述为:如果一个项集是频繁的,那包含它的所有项集也是频繁的。
(错24. 如果规则不满足置信度阈值,则形如的规则一定也不满足置信度阈值,其中是X的子集。
(对)25. 具有较高的支持度的项集具有较高的置信度。
(错)26. 聚类(clustering)是这样的过程:它找出描述并区分数据类或概念的模型(或函数),以便能够使用模型预测类标记未知的对象类。
(错)27. 分类和回归都可用于预测,分类的输出是离散的类别值,而回归的输出是连续数值。
(对)28. 对于SVM 分类算法,待分样本集中的大部分样本不是支持向量,移去或者减少这些样本对分类结果没有影响。
(对)29. Bayes 法是一种在已知后验概率与类条件概率的情况下的模式分类方法,待分样本的分类结果取决于各类域中样本的全体。
(错)30.分类模型的误差大致分为两种:训练误差(training error )和泛化误差(generalization error ). (对)31. 在决策树中,随着树中结点数变得太大,即使模型的训练误差还在继续减低,但是检验误差开始增大,这是出现了模型拟合不足的问题。
(错)32. SVM 是这样一个分类器,他寻找具有最小边缘的超平面,因此它也经常被称为最小边缘分类器(minimal margin classifier ) (错)33. 在聚类分析当中,簇内的相似性越大,簇间的差别越大,聚类的效果就越差。
(错)34. 聚类分析可以看作是一种非监督的分类。
(对)35. K 均值是一种产生划分聚类的基于密度的聚类算法,簇的个数由算法自动地确定。
(错36. 给定由两次运行K 均值产生的两个不同的簇集,误差的平方和最大的那个应该被视为较优。
(错)37. 基于邻近度的离群点检测方法不能处理具有不同密度区域的数据集。
(对)38. 如果一个对象不强属于任何簇,那么该对象是基于聚类的离群点。
(对)39. 从点作为个体簇开始,每一步合并两个最接近的簇,这是一种分裂的层次聚类方法。
(错)40. DBSCAN 是相对抗噪声的,并且能够处理任意形状和大小的簇。
(对)三、计算题1.一个食品连锁店每周的事务记录如下表所示,其中每一条事务表示在一项收款机业务中卖出的项目,假定sup min =40%,conf min =40%,使用Apriori 算法计算生成的关联规则,标明每趟数据库扫描时的候选集和大项目集。
(15分)事务项目事务项目 T1 T2T3面包、果冻、花生酱面包、花生酱面包、牛奶、花生酱 T4T5啤酒、面包啤酒、牛奶解:(1)由I={面包、果冻、花生酱、牛奶、啤酒}的所有项目直接产生1-候选C 1,计算其支持度,取出支持度小于sup min 的项集,形成1-频繁集L 1,如下表所示:项集C1 支持度项集L1支持度{面包}{花生酱}{牛奶} {啤酒}4/53/52/52/5{面包}{花生酱}{牛奶}{啤酒}4/53/52/52/5(2)组合连接L1中的各项目,产生2-候选集C2,计算其支持度,取出支持度小于sup min的项集,形成2-频繁集L2,如下表所示:项集C2支持度项集L2支持度{面包、花生酱} 3/5{面包、花生酱} 3/5至此,所有频繁集都被找到,算法结束,所以,confidence({面包}→{花生酱})=(4/5)/(3/5)=4/3> conf minconfidence({ 花生酱}→{面包})=(3/5)/(4/5)=3/4> conf min所以,关联规则{面包}→{花生酱}、{ 花生酱}→{面包}均是强关联规则。
2.给定以下数据集(2 ,4,10,12,15,3,21),进行K-Means聚类,设定聚类数为2个,相似度按照欧式距离计算。
(15分)解:(1)从数据集X中随机地选择k个数据样本作为聚类的出示代表点,每一个代表点表示一个类别,由题可知k=2,则可设m1=2,m2=4:(2)对于X中的任意数据样本xm(1<xm<total),计算它与k个初始代表点的距离,并且将它划分到距离最近的初始代表点所表示的类别中:当m1=2时,样本(2 ,4,10,12,15,3,21)距离该代表点的距离分别为2,8,10,13,1,19。
当m2=4时,样本(2 ,4,10,12,15,3,21)距离该代表点的距离分别为-2,6,8,11,-1,17。
最小距离是1或者-1将该元素放入m1=2的聚类中,则该聚类为(2,3),另一个聚类m2=4为(4,10,12,15,21)。
(3)完成数据样本的划分之后,对于每一个聚类,计算其中所有数据样本的均值,并且将其作为该聚类的新的代表点,由此得到k个均值代表点:m1=2.5,m2=12:(4)对于X中的任意数据样本xm(1<xm<total),计算它与k个初始代表点的距离,并且将它划分到距离最近的初始代表点所表示的类别中:当m1=2.5时,样本(2 ,4,10,12,15,3,21)距离该代表点的距离分别为-0.5,0.5,1.5,7.5,9.5,12.5,18.5。
当m2=12时,样本(2 ,4,10,12,15,3,21)距离该代表点的距离分别为-10,-9,-8,2,3,9。
最小距离是1.5将该元素放入m1=2.5的聚类中,则该聚类为(2,3,4),另一个聚类m2=12为(10,12,15,21)。
(5)完成数据样本的划分之后,对于每一个聚类,计算其中所有数据样本的均值,并且将其作为该聚类的新的代表点,由此得到k个均值代表点:m1=3,m2=14.5:(6)对于X中的任意数据样本xm(1<xm<total),计算它与k个初始代表点的距离,并且将它划分到距离最近的初始代表点所表示的类别中:当m1=3时,样本(2 ,4,10,12,15,3,21)距离该代表点的距离分别为-1,1,7,9,12,18,。
当m2=14.5时,样本(2 ,4,10,12,15,3,21)距离该代表点的距离分别为-12.58,-11.5,-10.5,-4.5,-2.5,0.5,6.5。