乒乓操作
乒乓ram介绍

乒乓ram简介在现在的数据采集分析系统中,随着采集数据的速度剧增,每次都对这些庞大的数据量直接进行分析,这将会占用很多的CPU,使得CPU不能及时的去做其它的事情。
我们可以在传输这些数据的时候提供适当的通道,建立一个缓冲电路,来实现数据流的无缝缓存和处理,提高系统的处理速度和性能。
输入输出缓存电路一般有三种结构和形式:①双口ram结构:双口RAM是在一个SRAM存储器上具有两套完全独立的数据线、地址线、读写控制线、并允许两个独立的系统同时对该存储器进行随机访问。
②FIFO结构:FIFO(First In First Out)是一种先进先出的数据缓存器,可以进行双端操作,但是数据必须先进先出,不能进行随机性的访问。
从容量大小来看,双口RAM比FIFO要大一些,但总的来说,这两种缓冲结构的存储容量还是相对较小,对高速图像处理系统而言,还不是特别适合。
③乒乓ram结构:这种结构是将输入数据流通过输入数据选择单元等时地将数据流分配到两个ram缓冲区。
通过两个ram读和写的切换,来实现数据的流水式传输。
综上所述,乒乓缓存结构实际上相当于一个双口RAM,但它与普通的双口RAM又有所不同。
普通双口RAM是单个存储体构成的IC,乒乓ram结构则由包含两个相互独立存储体的多片IC构成,从而使其在结构、速度、容量等方面具有更大的灵活性;若双口在访问同一地址时,普通双口SAM指向的必定是存储体内的同一存储单元,而乒乓ram结构则分别指向属于SRAM1和SRAM2的两个不同的存储单元,更易操作。
乒乓缓存结构的上述特点决定了可以相对较便宜的高速大容量SRAM、外围逻辑器件构成比双口RAM以及高速FIFO更适合视频处理的系统所需要的缓冲存储器。
乒乓ram结构的上述特点决定了可以相对较便宜的高速大容量RAM、外围逻辑器件构成比双口RAM以及高速FIFO更适合大数据传输系统所需要的缓冲存储器。
乒乓ram控制原理"乒乓操作"是一个常用的数据流控制处理技巧。
一种基于VHDL的乒乓操作控制法的研究

文献标识码 :B
Re e r h o p ln o t o e ho s d o s a c n pi e i e c n r lm t d ba e n VHDL
L n H u S e qa g i i u Zh n in
( ・ rme to e h nc l n e tia gn e ig,Xime De t n fM c a ia d Elcrc lEn ie rn a a n Uniest v riy,Xim e 6 0 0 a n3 1 0 )
维普资讯
嘞
一
E TN MSENTHLY L RI 子测量技术 NO E 0电E RE C0G C C A MT U E
第89 2年月 0 9 3 第期 0 1 卷
种 基 于 V L 的 乒 乓 操 作 控 制 法 的研 究 * HD
林 辉 苏振 强
c an l rq ec D t n es n h ei f hs o i srcue s ecie.Moev re h ss r u nte h n e F eu ny/ aac v ri .T e s no i lgc t tr sr d o o d g t u id b ro e,mp ae e t a p o h
s ltdi i ae QUARTERS_ . n e tdi y ln hp mu n .5 1a d tse nc co eic i. i
Kewo d : VH DL;pn - a g o eain rgn lv le Sh lig;d u l-d e in l y rs igp n p rt ;o iia au ’ odn o o bee g d s a g
2 1 选
( A ) DR P M
一种基于VHDL的乒乓操作控制法的研究

了在 V HDL 中 , 如何通过脉冲信号边沿 ( 上升沿 或下降沿 ) 的脉 冲化 , 信 号延迟分 析和初 始值保 持等方 法来实 现这种 由双沿信号产生 的逻辑控制信号的方法。这样就 解决了 在 V H DL 一个 P ROCESS 过程 语句中 不能实 现双沿 判断的 缺点。这种控制方法延时 小 , 整个过程的动作衔接紧密 , 自动化程度较高。同时 , 可以通过提高采 集时钟 CL K 的频率 来进一 步减小延时。本方法在 QU AR T ERS 设计的 要求。 中图分 类号 : T N3 文献标识码 : B 5. 1 软件中通过时序仿真 , 并下载到 cyclone 芯片中验证 , 完全能满足
关键词 : VH DL ; 乒乓操作 ; 初始值保持 ; 双沿
Research on pipeline control method based on VHDL
L in H ui Su Zhenqiang
( D epart men t of M echanical an d El ect rical Engin eering, X iamen U n iversit y, Xiamen 361000)
图6
将 a 下降沿脉化后的 控制信号
3. 3 控制信号的产生 将门信号 b 的下降沿脉冲化后, 原来的双沿信号控制 转化为了一沿和一电平控制 , 这在 VH DL 中是很容易实现 的。规定 A 通道先动作 , con 初始必须保持为 0, 然后 a 的 下降沿使 con 为 1, con 为 1 驱使通道 B 开始动作 , 然后 b 的下降沿通过沿化脉冲 b1, 使 con 为 0, con 为 0 又驱使通 道 A 动作, 如此反复 , 以达到实时动态的流水控制, 以达到 速度的最优化。 控制信号 con 的产生程序如下[ 8] : process( a, b1) begin if b1= '1' then con< = '1'; els if a'event and a= '0' then con< = '0'; end if; end process; 经过以上 3 个步骤 , 就可以正确地得到控制信号 con, 然后反馈到通道 A 和通道 B , 进行流水控制。 用 QU ARTERS 5. 1 软件进行仿真, 仿真如图 7 所 示, 规定 A 通道先动作, 可以看出开始 con 为 0, 保持了初 始值( con 默认初始值为 0) 。A 通道先送出门信号。 con 为 1 后 , 控制 B 通道运行, 此时 , B 通道输出门信号。如此 循环。可以看到, 两通道间动作连接紧密。 将此方法用到双通道频率测量系统中 , 如图 8 所示, 其中 w aveA, w aveB 分别代表通道 A , B 的输入频率, c16a| a, c16b| a, con1b 分别代表 a, b, con 信号 , 这样由 con 控制 的 a, b 信号输出连接紧密的乒乓式的门信号 , 就可以送入 到核心计数器进行各自的计数控制。其过程流畅, 动作紧 凑, 完全能达到预期的目标。
FPGA乒乓操作及串并转换设计篇
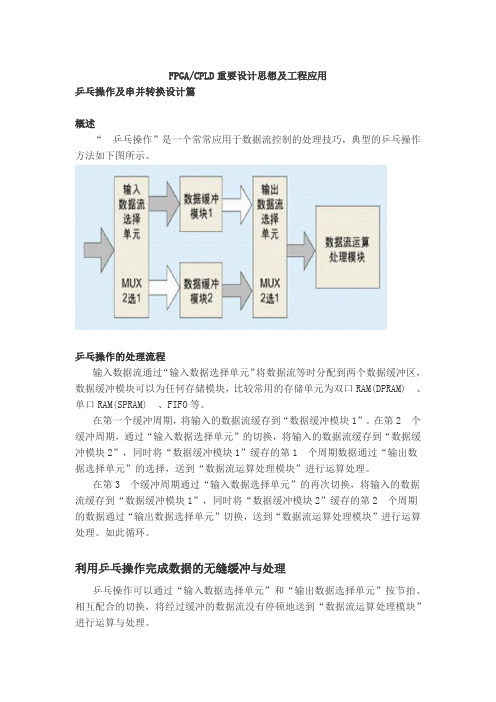
FPGA/CPLD重要设计思想及工程应用乒乓操作及串并转换设计篇概述“乒乓操作”是一个常常应用于数据流控制的处理技巧,典型的乒乓操作方法如下图所示。
乒乓操作的处理流程输入数据流通过“输入数据选择单元”将数据流等时分配到两个数据缓冲区,数据缓冲模块可以为任何存储模块,比较常用的存储单元为双口RAM(DPRAM) 、单口RAM(SPRAM) 、FIFO等。
在第一个缓冲周期,将输入的数据流缓存到“数据缓冲模块1”。
在第2 个缓冲周期,通过“输入数据选择单元”的切换,将输入的数据流缓存到“数据缓冲模块2”,同时将“数据缓冲模块1”缓存的第1 个周期数据通过“输出数据选择单元”的选择,送到“数据流运算处理模块”进行运算处理。
在第3 个缓冲周期通过“输入数据选择单元”的再次切换,将输入的数据流缓存到“数据缓冲模块1”,同时将“数据缓冲模块2”缓存的第2 个周期的数据通过“输出数据选择单元”切换,送到“数据流运算处理模块”进行运算处理。
如此循环。
利用乒乓操作完成数据的无缝缓冲与处理乒乓操作可以通过“输入数据选择单元”和“输出数据选择单元”按节拍、相互配合的切换,将经过缓冲的数据流没有停顿地送到“数据流运算处理模块”进行运算与处理。
把乒乓操作模块当做一个整体,站在这个模块的两端看数据,输入数据流和输出数据流都是连续不断的,没有任何停顿,因此非常适合对数据流进行流水线式处理。
所以乒乓操作常常应用于流水线设计中,完成数据的无缝缓冲与处理。
串并转换串并转换是FPGA 设计的一个重要技巧,它是高速数据流处理的常用手段,串并转换的实现方法多种多样,根据数据的排序和数量的要求,可以选用寄存器、双口RAM(DPRAM) 、单口RAM(SPRAM) 、FIFO 等实现。
若想数据的缓冲区开得很大,可以通过DPRAM 实现了数据流的串并转换,对于数量比较小的设计可以采用寄存器完成串并转换。
如无特殊需求,系统中应该用同步时序设计完成串并之间的转换。
数据乒乓操作原理

数据乒乓操作原理数据乒乓操作原理数据乒乓操作是指在数据库中进行读取和修改数据的过程中,使用缓存机制来提高性能和效率的一种技术。
本文将详细介绍数据乒乓操作的原理。
一、什么是数据乒乓操作?在数据库中,读取和修改数据通常都需要进行I/O操作,而I/O操作是比较耗时的。
为了提高性能和效率,我们可以使用缓存机制来避免频繁进行I/O操作。
而数据乒乓操作就是利用缓存机制来实现对数据库的读取和修改。
二、数据乒乓操作的原理1. 缓存机制在进行数据乒乓操作时,我们首先需要了解缓存机制。
缓存就是将一些经常使用的数据保存在内存中,当需要访问这些数据时,直接从内存中读取,避免频繁进行磁盘IO操作。
2. 数据库连接池为了防止频繁地打开和关闭数据库连接造成性能损失,我们可以使用数据库连接池来管理数据库连接。
连接池会维护一定数量的数据库连接,并且提供对这些连接的管理和分配。
3. 读写分离为了进一步提高性能和效率,在进行数据读取时,我们可以采用读写分离策略。
读写分离是指将数据库的读操作和写操作分别放在不同的服务器上进行,这样可以减轻单台服务器的压力,提高系统的响应速度。
4. 数据乒乓操作在进行数据乒乓操作时,我们可以将数据库中的数据复制到缓存中,并且设置一个缓存过期时间。
当需要访问数据时,首先从缓存中读取,如果缓存中不存在该数据或者已经过期,则从数据库中读取,并且将数据更新到缓存中。
在进行修改操作时,我们首先对缓存中的数据进行修改,并且记录下来需要更新到数据库中的操作。
当达到一定条件(如时间间隔、修改次数等)时,才会将缓存中的修改操作批量提交到数据库中。
三、数据乒乓操作的优点1. 提高性能和效率通过使用缓存机制、连接池和读写分离等技术手段,可以大大提高系统性能和效率。
2. 减少I/O操作由于使用了缓存机制,在访问数据时可以避免频繁进行I/O操作,减少了系统负担和响应时间。
3. 提高并发能力通过使用连接池和读写分离等技术手段,可以提高系统的并发能力。
基于乒乓操作的计费系统算法及DSP+FPGA实现

20 年 9 06 月
襄樊学 院学报
J un l f a ga v ri o ra n fnUniest o Xi y
S p. 0 6 e t2 0 ,
第 2 卷 作的计 费 系统算法及 D P F G 实现 S+ P A
2DS + P A设计实现 P FG
目前 D P F G S + P A结构的优越性得到了重视. 与通用集成电路相 比, SC芯片具有体积小 、 AI 重量轻 、 功 耗低 、 可靠性高等几个方面的优势 ,而且在大批量应用时 , 可降低成本 ,现场可编程门阵列(P A 是在专用 FG ) AI SC的基础上发展出来的 , 它克服 了专用 A I SC不够灵活的缺点. 与其他中小规模集成电路相 比, 其优点主
数据流进行流水线式处理 ,所 以乒乓操作能完成数据的无缝缓冲与处理. 乒乓操作的第 2个优点是可以节约 缓 冲区空间 ,比如在 WC MA基带应用中,1 D 个帧是 由 1 个时隙组成的,有时需要将 1 5 整帧的数据延时一 个时隙后处理 ,比较直接的办法是将这帧数据缓存起来 ,然后延时 1个时隙进行处理. 这时缓冲区的长度是 1 整帧数据长 ,假设数据速率是 38 p ,1 . Mb s 帧长 1 s 4 0m ,则此时需要缓冲区长度是 3 0 位. 8 0 如果采用乒 4 乓操作 ,只需定义 2 个缓冲 1 个时隙数据的 R M( E R M 即可) 当向一块 R M 写数据的时候 ,从另一 A 单 lA . A 块 R M 读数据 , A 然后送到处理单元处理 ,此时每块 R M 的容量仅需 2 6 位 即可 ,2 R M 加起来也只 A 0 5 块 A 有 5 2 位的容量. 0 1 同时 ,巧妙运用乒 乓操作还可以达到用低速模块处理高速数据流的效果.
FPGA设计的四种常用思想与技巧乒乓操作

FPGA设计的四种常用思想与技巧乒乓操作FPGA(Field-Programmable Gate Array)是一种可编程逻辑器件,可以根据需要重新配置其内部硬件电路。
在FPGA设计中,有许多常用的思想和技巧,其中之一就是乒乓操作。
乒乓操作是指通过交替使用两个资源或状态来实现其中一种功能或优化设计的一种方法。
本文将介绍FPGA设计中的四种常用思想与技巧乒乓操作。
1.数据缓冲乒乓操作:数据缓冲乒乓操作是指在设计中使用两个缓冲区交替存储数据。
一个缓冲区用于接收数据,另一个缓冲区用于处理数据。
当一个缓冲区正在接收数据时,另一个缓冲区可以同时进行数据处理。
这种乒乓操作可以提高数据处理的效率,减少数据处理的延迟。
2.时钟域乒乓操作:时钟域乒乓操作是指在设计中使用两个时钟域交替操作。
一个时钟域用于采样输入数据,另一个时钟域用于处理数据。
这种乒乓操作可以实现不同时钟域之间的数据交换和同步。
例如,可以将输入数据从一个时钟域同步到另一个时钟域,然后再进行处理。
这种乒乓操作可以解决时钟域之间的异步问题,提高设计的可靠性和性能。
3.状态机乒乓操作:状态机乒乓操作是指在设计中使用两个状态机交替执行其中一种功能。
一个状态机用于执行一些任务,另一个状态机用于处理其他任务。
这种乒乓操作可以实现多任务的并行处理。
例如,可以将一个状态机用于处理输入数据,另一个状态机用于处理输出数据。
这种乒乓操作可以提高设计的并行度,加快任务的执行速度。
4.存储器乒乓操作:存储器乒乓操作是指在设计中使用两个存储器交替读写数据。
一个存储器用于读取数据,另一个存储器用于写入数据。
这种乒乓操作可以实现数据的连续读写,提高存储器的访问效率。
例如,可以将一个存储器用于读取输入数据,另一个存储器用于写入输出数据。
这种乒乓操作可以减少存储器的读写延迟,提高数据的传输速度。
综上所述,FPGA设计中的乒乓操作是一种常用的思想和技巧,可以提高设计的效率和性能。
通过数据缓冲乒乓操作、时钟域乒乓操作、状态机乒乓操作和存储器乒乓操作,可以实现数据的并行处理、时钟域的同步、多任务的执行和存储器的高效访问。
verilog乒乓操作的工作原理

verilog乒乓操作的工作原理Verilog乒乓操作的工作原理:Verilog是一种硬件描述语言(HDL),用于描述数字电路。
乒乓操作是Verilog中的一种重要操作,用于实现信号或数据的交换。
乒乓操作可以通过两个变量之间的交换,实现数据传输,并且在硬件电路中具有高效的执行速度。
乒乓操作的工作原理是通过使用一个中间变量来完成变量值的交换。
在Verilog中,我们通常使用临时变量(temp)来实现乒乓操作。
下面是一个乒乓操作的示例代码:```verilogmodule PingPong;reg [7:0] a, b, temp;// 乒乓操作的过程always @(posedge clk) begintemp <= a; // 将变量a的值赋给tempa <= b; // 将变量b的值赋给ab <= temp; // 将temp的值赋给变量b,实现了a和b的值交换endinitial begin// 初始化a和b的值a = 8'b10101010;b = 8'b01010101;#10; // 等待10个时钟周期$display("a的值:%b", a);$display("b的值:%b", b);endendmodule```在上述代码中,我们使用了一个8位的临时变量temp来完成变量a和变量b的交换。
在always块中,当时钟的上升沿到来时,乒乓操作被执行。
首先,我们将变量a的值赋给temp,然后将变量b的值赋给a,最后将temp的值赋给b,实现了a和b的交换。
通过不断重复这个过程,我们可以实现连续的交换操作。
在initial块中,我们对变量a和变量b进行了初始化,并等待了10个时钟周期。
最后,通过$display函数输出了交换后的a和b的值。
乒乓操作是一种非常常用的操作,在数字电路设计中起到了重要的作用。
通过Verilog的语法,我们可以方便地描述和实现乒乓操作,并在硬件电路中实现高效的数据传输。
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
唉。
写好testbench后一定要将顶层模块写进,不然怎么会有结果呢!!其实乒乓操作用面积换速度。
具体如何应用于实际中,不知道,只是知道怎么回事。
比如串并转换中,必须先对串入数据进行处理,然后将其送出。
这在通讯中应该会用到吧。
如果处理发现错误则丢弃数据,那么在处理数据的时候就不能够允许数据更改,这样就限制了速度。
(当然也可以用寄存器将结果先寄存处理)。
不过写这个对Verilog又有了进一步的了解:
1.模块化!写程序前要想清楚如何划分模块,模块之间的接口。
这样方便仿真出错时候查错误,而且会使模块内部逻辑关系变简单。
2.非阻塞赋值是beginend执行完后就改变数据,因此,对于某些信号我们可以根据触发条件进行选择。
如模块2选一输入中的oden 1和oden2的选择
module sp_top(clk,nrst,serial_in,data_out,serial_en1,serial_en2,oden1,oden2);
input clk,nrst,serial_in;
output[3:0] data_out;
output serial_en1,serial_en2;
output oden1,oden2;
wire oden1,oden2;
wire serial_en1,serial_en2;
wire[3:0] parallel_out1,parallel_out2;
sp_imux21 Ssp_imux21(nrst,oden1,oden2,serial_en1,serial_en2);
sp_buf Ssp_buf1(serial_en1,clk,nrst,serial_in,oden1,parallel_out1);
sp_buf Ssp_buf2(serial_en2,clk,nrst,serial_in,oden2,parallel_out2);
sp_omux21 Ssp_omux21(clk,oden1,oden2,nrst,parallel_out1,parallel_out2,data_out);
endmodule
//sp_mux41:serial to parallel data_buf choose
module sp_imux21(nrst,oden1,oden2,serial_en1,serial_en2);
input nrst;
input oden1,oden2;
output serial_en1,serial_en2;
reg serial_en1,serial_en2;
always@(posedge oden1 or posedge oden2 or negedgenrst)
if(!nrst) begin serial_en1=1'b1;serial_en2=1'b0;end
else if(oden1) begin serial_en1<=1'b0;serial_en2<=1'b1;end
else if(oden2) begin serial_en1<=1'b1;serial_en2<=1'b0;end
// else serial_en<=serial_en;
endmodule
//sp_buf:serial to parallel data input buffer
module sp_buf(iden,clk,nrst,serial_in,oden,parallel_out);
input iden;//data input enable
input clk,nrst;
input serial_in;
output oden;//output enable
output[3:0] parallel_out;
reg oden;
reg[1:0] count;
reg [3:0] parallel_out;
reg [3:0] inbuf_r;
always@(posedge clk or negedgenrst)
begin
if(!nrst) begin oden<=1'b0;count<=1'b0;inbuf_r=4'dz;end
else if(iden)
begin
inbuf_r<={inbuf_r[2:0],serial_in};
count<=count+1'b1;
if(count==2'd3) oden<=1'b1;
else oden<=1'b0;
end
else begin oden<=1'b0;end
end
always@(posedge oden or negedgenrst)
begin
if(!nrst) parallel_out<=4'dz;
else if(oden)
parallel_out<=inbuf_r;
// else parallel_out<=4'dz;
end
endmodule
//sp_omux21:serial input and parallel output output mux
module sp_omux21(clk,oden1,oden2,nrst,parallel_in1,parallel_in2,data_out); input clk,oden1,oden2,nrst;
input[3:0] parallel_in1,parallel_in2;
output[3:0] data_out;
reg[3:0] data_out;
always@(posedge clk or negedgenrst)
begin
if(!nrst) data_out<=4'dz;
else if(oden1) data_out<=parallel_in1;
else if(oden2) data_out<=parallel_in2;
end
endmodule
`timescale 1ns/1ns
module sp_tb;
reg clk,nrst,serial_in;
wire [3:0] data_out;
wire den1,den2;
wire serial_en1,serial_en2;
reg[28:0] serial_in_buf;
initial
begin
clk=1'b0;
nrst=1'b0;
serial_in_buf=28'b1110_0100_1010_1110_0101_1001_0011;
#2 nrst=1'b1;
#5 nrst=1'b0;
#10 nrst=1'b1;
end
always #5 clk<=~clk;
always@(posedge clk or negedgenrst)
begin
if(!nrst) begin
serial_in=1'bz;
serial_in_buf=28'b1110_0100_1010_1110_0101_1001_0011;
end
else
begin
serial_in=serial_in_buf[27];
serial_in_buf=(serial_in_buf<<1);
end
end
sp_top Ssp_top(clk,nrst,serial_in,data_out,serial_en1,serial_en2,den1,den2); endmodule。