高光谱数据的制图方法简介
第五讲高光谱数据分析

第五讲高光谱数据分析高光谱技术可提供空间域信息和光谱域信息,即“谱图合一”,且由图像数据反演出的像元光谱曲线可以与实验室所测的同类地物光谱曲线相类比,因此可以用于鉴别物质,比如鉴别矿物、岩石的类型,区分环境中各种污染物的成分以及农作物、森林的种类等。
一、提取波谱剖面廓线打开文件cup95eff.int,并RGB彩色显示band 183,band 193,band 207。
在主影像菜单栏中选择Tools/Profiles/Z profiles(Spectrum),打开并显示波谱曲线。
二、采集波谱曲线在Spectral Profile窗口中,选择Options->Collect Spectra,采集绘图窗口中的波谱曲线。
相应的,要将波谱曲线采集到另一个绘图窗口中,先打开一个新的绘图窗口,然后将Spectral Profile窗口中的波谱曲线保存到新的绘图窗口中。
具体步骤如下:1.从绘图窗口的菜单栏中选择Options->New Window:blank,打开一个新的绘图窗口。
2.在先前的绘制窗口中,点击鼠标右键,选择Plot Key,将波谱曲线的名字显示在绘图窗口的右边。
3.在第一条波谱曲线的名字上,点击并按住鼠标左键不放,将波谱曲线的名字拖到新的绘图窗口中,然后松开鼠标左键。
4.在主影像窗口或缩放窗口中移动当前光标像素定位器,从影像中选择一条新的波谱曲线。
重复上面点击拖拽的过程,在新绘图窗口中建立一系列的波谱曲线。
要改变不同波谱曲线的颜色和线形,选择新绘图窗口中的Edit-Data Parameters.每一条波谱曲线的名字/位置都将在Data Parameters对话框中列出。
三、动画显示数据在先前的灰阶影像显示的主影像窗口中,选择Tools-Animation生成动画显示。
弹出的Animation Input Parameters对话框中列出了可用波段列表中的所有波段。
从所有波段中选择一个子集来生成动画。
高光谱ENVI使用方法简介

高光谱制图—FLAASH大气校正
FLAASH是目前精度最高的大气辐射校正模型, 使用了 MODTRAN 4+ 辐射传输模型的代码,基 于像素级的校正 FLAASH可对Landsat, SPOT, AVHRR, ASTER, MODIS, MERIS, AATSR, IRS等多光谱、高光谱 数据、航空影像及自定义格式的高光谱影像进行 快速大气校正分析。能有效消除大气和光照等因 素对地物反射的影响,获得地物较为准确的反射 率和辐射率、地表温度等真实物理模型参数
高光谱制图—FLAASH大气校正(5)
如果要自动保存前面所输入的FLAASH参 数 如果需要生成相关诊断文件(如通道定义 文件等)
高光谱影像地理坐标定位
空间遥感平台在传感器采集数据的同时也精确地 记录了自身的几何信息,使用这些几何信息如星 历、姿态数据以及传感器探元与成像数据上像元 间的几何关系等,可以计算出影像上每一个像元 所对应的经纬度,其结果将作为影像数据的辅助 地理信息一并打包发布给用户。利用这些详细的 输入几何信息(Input Geometry)使得影像不需 要选择大量地面控制点就可以进行几何精纠正, 即ENVI所谓的地理坐标定位Georeference)。
比较N维散点图和二维散点图 利用N维散点图进行端元选取,理解使用菜 单Class Controls的使用 N维可视化仪同光谱剖面的链接,使用鼠 标中键来进行光谱曲线的绘制 光谱分析与N维可视化仪连接起来
高光谱影像分析-光谱切面
光谱切面包括水平切面、垂直切面和任意 方向切面。 切面是一幅ENVI影像,沿水平方向的切面, 样本数等于光谱波段数,行数等于采样数; 沿垂直方向的切面,样本数等于行数;对 于任意方向的切面,样本数等于沿ROI折 线的像元总数
ENVI高光谱数据分析操作手册

感兴趣区和掩膜的选择和使用可具体情况具体分析,运行一项或两项均可。
北京卓立汉光仪器有限公司
4. 滤波
打开图像,FilterConvolutions and Morphology。在Convolutions and Morphology Tools 中,选择 Convolutions滤波类型(高通滤波 器、低通滤波 器、拉普拉斯算子、方向滤波器、高斯高通滤波器、高斯低通滤波器、中值滤波 器、Sobel、Roberts、自定义卷积核)。
2.3.2.3. 保存波谱库
北京卓立汉光仪器有限公司 在Spectral Libraries Resampling Parameters对话框中,为Resample Wavelength To选择匹配源,一般选择图像文件为参考。 输出重采样波谱库.sli
北京卓立汉光仪器有限公司
3. 感兴趣区和掩膜
3.1. 感兴趣区(ROI)
Display 窗 口 中 , Overlay → Region of Interest , 在 ROI 对 话 框 中 , 单 击 ROI_Type→Polygon. 绘制窗口中,选择Image,绘制一个多边形,右键结束,可根据需要多绘制 几个。
主菜单→Basic Tools→Subset Data via ROIs,选择裁剪图像。 在Saptial Subset via ROIs Parameters中,设置参数。 Select Input ROIs,选择绘制的ROI。 Mask Pixel Outside of ROIs选择yes。
4.1. 设置参数
Kernel Size(卷积核大小):奇数。 Image Add Back(加回值):将原始图像中的部分加回到卷积滤波结果图像中, Editable Kernel(卷积核中各项的值)。
高光谱数据的制图方法简介
高光谱数据的制图方法简介ENVI软件在Spectral菜单中提供许多波谱制图方法,包括:二进制编码、波谱角制图、线性波段预测(LS-Fit)、线性波谱分匹配滤波、混合调制匹配滤波、包络线去除,以及波谱特征拟合等。
本文主要介绍几种高光谱数据处理的过程操作。
1.二进制编码二进制编码分类技术根据波段值落在波谱均值的下方或上方,将数据和端元分别编码为0和1。
在编码过程中,使用一个高级的(exclusive)OR函数,用于将需要编码的数据波谱与参照波谱相比较,从而生成一幅分类图像。
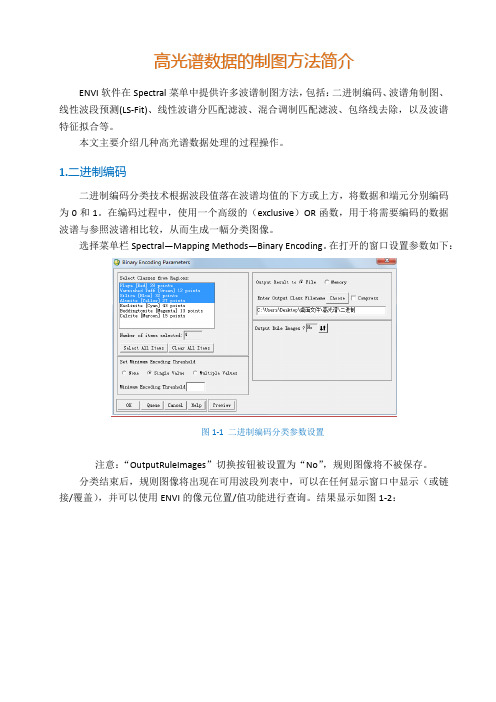
选择菜单栏Spectral—Mapping Methods—Binary Encoding。
在打开的窗口设置参数如下:图1-1 二进制编码分类参数设置注意:“OutputRuleImages”切换按钮被设置为“No”,规则图像将不被保存。
分类结束后,规则图像将出现在可用波段列表中,可以在任何显示窗口中显示(或链接/覆盖),并可以使用ENVI的像元位置/值功能进行查询。
结果显示如图1-2:图1-2 原影像图(左)与二进制编码分类结果图(右)2. 波谱角分类波谱角分类(SAM)是一种基于自身的波谱分类方法,这种方法将图像波谱与参照波谱在N-维空间进行匹配。
SAM用到的参照端元波谱可以来自于ASCII文件、波谱库、统计文件或直接从图像中抽取(如ROI均值波谱),本实验中用的是ROI均值波谱。
SAM把端元波谱(被认为是一个N维向量,N维波段数)和像元向量放在n维空间中进行角度比较。
较小的角度代表象元与参照波谱匹配紧密。
这一技术用于数据定标时,对照度和反照率的影响并不敏感。
选择菜单栏Spectral—Mapping Methods—Spectral Angle Mapper。
设置参数如图2-1,波谱角分类结果,如图2-2:图2-1 波谱角分类参数设置图2-2 波谱角分类结果影像3.LS-Fit(线性波段预测)LS-Fit使用一个最小方框(least squares)拟合技术来进行线性波段预测。
高光谱图像处理技术的使用方法与技巧

高光谱图像处理技术的使用方法与技巧高光谱图像处理技术是一种在特定波长范围内连续获取大量光谱信息的技术。
它不仅可以提供丰富的光谱数据,还能提供高分辨率的空间信息,因此在许多领域都有广泛的应用。
本文将介绍高光谱图像处理技术的使用方法与一些常用的技巧。
首先,高光谱图像的处理流程主要包括预处理、特征提取和分类三个步骤。
预处理是为了去除图像中的噪声和杂质,使得后续的特征提取和分类工作更加准确。
常见的预处理方法包括影像校正、光谱校正和噪声去除等。
影像校正是为了解决图像中的光照不均匀问题,常用的方法有常规平滑和直方图匹配等。
常规平滑方法可以通过滤波算法去除图像中的噪声和高频分量,提高图像的可视性。
而直方图匹配则可以通过调整图像的亮度和对比度,使得不同图像之间的光照条件保持一致。
光谱校正是为了解决不同设备采集的高光谱数据存在光谱偏移的问题。
通常可以通过使用已知光谱的参考物质进行校正,如大气校正和地物光谱响应校正等。
大气校正可以去除大气对光谱数据的影响,使得数据更加准确。
地物光谱响应校正则是为了减少不同地物对光谱数据的影响。
噪声去除是为了去除因设备等原因造成的图像噪声,提高图像的质量。
常见的噪声去除方法包括中值滤波、高斯滤波和小波分析等。
中值滤波是一种基于排序统计的方法,通过对图像中的像素排序并取中值来去除噪声。
高斯滤波则是一种常用的线性滤波方法,通过将像素的值与周围像素的值按照一定的权重进行加权平均,得到滤波后的像素值。
小波分析是一种基于频域的方法,通过对图像进行频域分解和重构来去除噪声。
接下来是特征提取。
高光谱图像的特征提取是为了从原始数据中提取出与目标信息相关的特征。
常用的特征提取方法包括光谱特征提取、纹理特征提取和形状特征提取等。
光谱特征提取是通过对高光谱数据进行光谱统计分析来获得与目标信息相关的参数。
常用的统计参数包括均值、方差、偏度和峰度等。
这些参数可以反映出光谱数据在不同波段上的分布情况。
纹理特征提取是为了从高光谱图像中提取出纹理信息。
专题六:高光谱数据介绍

光谱库
• ENVI中 的相关应用-标准波谱库: *.sli ,*.hdr
高光谱图像
• 对地物进行多波段成像所得到的一组二 维图像,每个波段对应的一个二维图像。 • 高光谱图像与自然图像的区别在于多了 一维光谱信息。
• 图像立方体 Spectral>Build 3D Cube
光谱空间及光谱角
• 光谱曲线图是区分不同地物的 主要方法 • 区分大量光谱时,需要用光谱 空间来表述。 • 以n=2为例,光谱向量(右图) • 多维光谱空间在可视化绘图是 困难的,数学构建上是可能的。 • 光谱间的相似性可以通过光谱 向量间的角度来判断——光谱 角。
光谱端元
将相关性很小的图像波段,如PCA、MNF 的前两个波段,作为X,Y构成二维散点图。 在理想状态下,根据线性混合模型数学描 述,三角形顶端为纯净像元。
在实际选择中,往往选择凸出部分,再获 取这个区域相应的平均波谱。
主要流程
• • • • 查看高光谱图像 打开常见图谱库 端元波谱提取(MNF) 高光谱分类—波谱角(SAM)
专题六:高光谱遥感 hyperspectral remote sensing
遥感的发展趋势
• 平台、传感器——数据
– 高(空间)分辨率 – 高光谱 – 高时间、高辐射 – 遥感反演 – 面向对象 – 光谱端元
• 信息处理方法
“天地一体化”
• 应用方面
– 实用化、商业化、国际化、一体化
背景
• 随着对地观测技术的迅速发展,图像的光谱 分辨率、空间分辨率和时间分辨率有了较显 著的提高,高光谱和高空间分辨率图像得到 了越来越多的应用。 • 精细的观测地物——地物的识别,地物的成 分信息
• 高光谱图像由成像光谱仪产生 • 测谱学和遥感成像技术的融合。
高光谱数据可视化python实现
高光谱数据可视化python实现在遥感领域,高光谱数据处理是一项重要的任务。
高光谱数据能够提供丰富的光谱信息,但由于数据的复杂性,我们需要使用适当的工具来处理和可视化这些数据。
本文将介绍如何使用Python语言来实现高光谱数据的可视化。
1. 准备工作在开始之前,我们需要准备一些高光谱数据。
这些数据可以来自卫星、无人机或其他测量设备。
高光谱数据通常包含数百个波段,每个波段都代表了不同的光谱信息。
我们可以使用Python中的numpy库来处理这些数据,并使用matplotlib库进行可视化。
2. 数据加载与处理首先,我们需要将高光谱数据加载到Python环境中。
可以使用numpy库的loadtxt函数来导入数据文件。
假设我们的数据文件是以逗号分隔的文本文件,每一行代表一个像素点,每个像素点的光谱信息以逗号分隔。
加载数据的代码如下:```import numpy as npdata = np.loadtxt('data.csv', delimiter=',')```加载完数据后,我们可以使用numpy库的各种方法来对数据进行处理。
例如,可以计算每个波段的平均值、最大值、最小值等统计指标。
通过这些统计指标,我们可以更好地了解数据的分布情况,为后续的可视化提供参考。
3. 数据可视化接下来,我们可以使用matplotlib库进行高光谱数据的可视化。
matplotlib是一个功能强大的绘图库,可以绘制各种类型的图形,包括折线图、散点图、柱状图等。
首先,我们可以使用matplotlib的plot函数来绘制每个波段的光谱曲线。
代码如下:```import matplotlib.pyplot as plt# 绘制光谱曲线for i in range(data.shape[1]):plt.plot(data[:, i])plt.xlabel('Wavelength')plt.ylabel('Reflectance')plt.title('Spectral Curve')plt.show()```上述代码中,我们使用for循环遍历数据的每个波段,然后使用plot函数将每个波段的光谱曲线绘制出来。
高光谱数据分析ENVI操作手册
高光谱数据分析ENVI操作手册1.常见参数选择主菜单→File→Preferences●用户自定义文件(User Defined Files)图形颜色文件,颜色表文件,ENVI的菜单文件,地图投影文件等。
需重启ENVI ●默认文件目录(Default Directories)默认数据目录,临时文件目录,默认输出文件目录,ENVI补丁文件、光谱库文件、备用头文件目录等,需重启ENVI。
●显示设置(Display Default)可以设置三窗口中各个分窗口的显示大小,窗口显示式样等。
其中可以设置数据显示拉伸方式(Display Default Stretch),默认为2%线性拉伸。
●其他设置(Miscollaneous)制图单位(Page Unit),默认为英寸(Inches),可设置为厘米(Centimeters)还有缓冲大小(cache size),可以设置为物理内存的50-75%左右。
Image Tile Size不能超过4M。
2.显示图像及其波谱2.1.打开文件●主菜单,Open Image File→文件名.raw。
●或Window→Available Bands List→File →Open Image File→文件名.raw。
2.2.显示图像●显示单波段灰度级图像:Gray color,选择的波段一般是图像显示最清晰的波段。
●显示伪彩色图像:RGB color,选择具有明显吸收谷、强烈反射作用和所含信息量较大的波段作为彩色合成RGB波段。
●显示真彩色图像:波段列表(Available Bands List)中,右键→Load TrueColor 。
●图像保存:Display窗口,File→Save Image As→Image File,选择输出格式、路径和名称,OK。
●动画显示:Display窗口,Tools→Animation,动态显示各波段图像,能很快的分辨出包含信息量较多的波段。
高光谱数据格式
高光谱数据格式摘要:一、高光谱数据简介二、高光谱数据格式概述1.数据结构2.数据存储方式3.数据处理与分析方法三、常见高光谱数据格式介绍1.HDF5格式2.ENVI格式3.ASCII格式4.其他格式四、高光谱数据在实际应用中的案例与优势五、总结与展望正文:一、高光谱数据简介高光谱数据是一种特殊的遥感数据,它通过获取连续波段的光谱信息,为地表目标物识别、环境监测、资源勘探等领域提供了强大的技术支持。
高光谱数据具有光谱分辨率高、波段数量多、数据量大等特点,可以帮助我们从不同角度和深度挖掘地表特征信息。
二、高光谱数据格式概述1.数据结构高光谱数据通常包括两部分:一是光谱数据,即波段强度信息;二是与之相关的元数据,如波段名称、波段宽度、光谱采样间隔等。
2.数据存储方式高光谱数据的存储方式有多种,如HDF5、ENVI、ASCII等格式。
这些格式在存储数据时,既有单一波段的文件,也有多波段的文件。
3.数据处理与分析方法高光谱数据处理与分析方法包括预处理、特征提取、分类和聚类等。
预处理主要包括去除噪声、辐射校正、大气校正等;特征提取是从光谱数据中提取有用信息,如光谱指数、连续波段组合等;分类和聚类是对高光谱数据进行地物识别和分类。
三、常见高光谱数据格式介绍1.HDF5格式HDF5(Hierarchical Data Format 5)是一种高效、可扩展的文件格式,适用于存储大量数据。
HDF5文件具有灵活的结构,可以存储多波段的高光谱数据,同时支持复杂的数据类型和复杂的数组结构。
2.ENVI格式ENVI(Environmental Visualization Infrastructure)是一种专为遥感数据设计的数据格式。
ENVI文件结构清晰,易于阅读和分析,支持多波段高光谱数据存储。
此外,ENVI还提供了一系列图像处理和分析工具,便于高光谱数据的处理。
3.ASCII格式ASCII格式是一种简单的文本格式,适用于存储单波段的高光谱数据。
高光谱数据可视化python实现 -回复
高光谱数据可视化python实现-回复标题:基于Python的高光谱数据可视化实现导言:高光谱数据是一种含有大量连续波段信息的数据,它具有广泛的应用价值,如农业、环境监测、地质勘探等领域。
可视化这些数据能够帮助我们更好地理解和分析数据,从而发现隐藏在其中的规律和信息。
本文将介绍如何使用Python实现高光谱数据的可视化,通过一步一步的详细实践,让读者熟悉高光谱数据可视化的实现过程。
第一步:获取高光谱数据首先,我们需要获取一组高光谱数据。
可以通过公开的数据集或者自行采集所需数据。
数据集通常包含多个波段,并以像素为单位存储。
这里我们以一个包含8个波段的高光谱遥感图像数据集为例。
第二步:导入所需库和数据集在Python中,我们可以使用多个库来处理和可视化高光谱数据。
常用的库包括NumPy、Pandas、Matplotlib和Seaborn。
首先,我们要确保这些库已经安装在本地环境中。
然后,我们可以使用以下代码导入数据集并加载所需库:pythonimport numpy as npimport pandas as pdimport matplotlib.pyplot as pltimport seaborn as sns# 导入高光谱数据集dataset = pd.read_csv('spectral_data.csv')第三步:数据探索与预处理在进行数据可视化前,我们需要对数据进行探索和预处理。
这包括查看数据的基本信息,检查数据是否存在缺失值或异常值,并对数据进行必要的处理。
python# 查看前几行数据print(dataset.head())# 查看数据形状print(dataset.shape)# 检查是否存在缺失值print(dataset.isnull().sum())# 检查数据的统计摘要print(dataset.describe())根据探索结果,我们可以根据需要对数据进行清洗、处理缺失值或异常值等操作。
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
高光谱数据的制图方法简介ENVI软件在Spectral菜单中提供许多波谱制图方法,包括:二进制编码、波谱角制图、线性波段预测(LS-Fit)、线性波谱分匹配滤波、混合调制匹配滤波、包络线去除,以及波谱特征拟合等。
本文主要介绍几种高光谱数据处理的过程操作。
1.二进制编码二进制编码分类技术根据波段值落在波谱均值的下方或上方,将数据和端元分别编码为0和1。
在编码过程中,使用一个高级的(exclusive)OR函数,用于将需要编码的数据波谱与参照波谱相比较,从而生成一幅分类图像。
选择菜单栏Spectral—Mapping Methods—Binary Encoding。
在打开的窗口设置参数如下:图1-1 二进制编码分类参数设置注意:“OutputRuleImages”切换按钮被设置为“No”,规则图像将不被保存。
分类结束后,规则图像将出现在可用波段列表中,可以在任何显示窗口中显示(或链接/覆盖),并可以使用ENVI的像元位置/值功能进行查询。
结果显示如图1-2:图1-2 原影像图(左)与二进制编码分类结果图(右)2. 波谱角分类波谱角分类(SAM)是一种基于自身的波谱分类方法,这种方法将图像波谱与参照波谱在N-维空间进行匹配。
SAM用到的参照端元波谱可以来自于ASCII文件、波谱库、统计文件或直接从图像中抽取(如ROI均值波谱),本实验中用的是ROI均值波谱。
SAM把端元波谱(被认为是一个N维向量,N维波段数)和像元向量放在n维空间中进行角度比较。
较小的角度代表象元与参照波谱匹配紧密。
这一技术用于数据定标时,对照度和反照率的影响并不敏感。
选择菜单栏Spectral—Mapping Methods—Spectral Angle Mapper。
设置参数如图2-1,波谱角分类结果,如图2-2:图2-1 波谱角分类参数设置图2-2 波谱角分类结果影像3.LS-Fit(线性波段预测)LS-Fit使用一个最小方框(least squares)拟合技术来进行线性波段预测。
它可以用于在数据集中找出异常波谱响应区。
LS-Fit先计算出输入数据的协方差,用它对所选的波段进行预测,预测值等于所用预测波段的线性组合再加上一个偏移值,在该过程中计算了实际波段和模拟波段之间的残差,并输出为一幅图像。
残差大的像元(无论正负)表示出现了不可预测的迹象(即一个吸收波段)。
模拟波段的图像也被包括在输出中。
被预测的波段可以根据现有统计或新的统计进行计算。
3.1用新的统计信息进行预测选择Spectral--Mapping Methods--LS-Fit(Linear Band Prediction)—Predict with new Statistics。
选择输入文件,根据需要选取空间子集。
将出现LS-Fit Parameters对话框。
设置参数如图3-1:图3-1 用新的统计信息进行预测的参数设置输出包含两个波段:模拟波段和残差图像。
残差图像中,值较大的像元,无论正负,都表明了所在位置的实际波段和模拟波段的差异。
预测结果如图3-2:图3-2 用新统计信息进行预测的模拟波段(左)和残差图像(右)3.2根据现有统计信息进行预测使用Predict from Existing Stats选项可以根据现有的统计文件对波段进行预测。
注意:只有在统计文件中包含协方差值的波段才能作为预测波段或模拟波段。
选择Spectral--Mapping Methods--LS-Fit(Linear Band Prediction)--Predict from Existing Stats。
选择输入文件,根据需要选取空间子集,选择与输入的数据文件相对应的统计文件,这里用到3.1中生成的统计文件。
在出现LS-Fit Parameters对话框,只有统计计算中用到的波段才可以被选为预测波段或模拟波段。
设置参数如图3-3:图3-3用现有的统计信息进行预测的参数设置输出包含的两个波段:模拟波段和残差图像。
残差图像中,值较大的像元,无论正负,都表明了所在位置的实际波段和模拟波段的差异。
预测结果如图3-4:图3-4 根据现有统计信息进行预测的模拟波段(左)和残差图像(右)由图3-2和图3-4得:两种预测方法结果类似,区别不大。
4.匹配滤波使用Matched Filtering选项可以进行局部分离,用于确定用户自定义端元的权重。
该方法并不需要图像中所有的端元都是已知的。
这项技术使已知端元的响应最大化,并抑制了未知背景合成的反应,因此“匹配”了已知信号。
它根据图像要素对波谱库或图像端元波谱的匹配程度,无需对图像中所有端元波谱进行了解,就可以快速探测出特定要素。
选择菜单栏Spectral--Mapping Methods--Matched Filtering。
当出现Matched Filter Input File selection 对话框时,选择输入文件,或根据需要选取任意空间和波谱子集或掩膜。
点击“OK”,将出现Endmember Collection:Matched Filter 对话框,选择相应的波谱,如图4-1图4-1 匹配滤波对应参数和端元选择匹配滤波的结果将以一系列灰阶图像的形式出现,每幅图像对应一个选择的端元。
浮点型结果提供了像元与参照波谱相对匹配程度的估计方法(1.0表示完全匹配),以及亚像元的权重。
图4-2 匹配滤波生成的一系列灰阶影像图5.混合调制匹配滤波使用Mixture Tuned Matched Filtering TM(MTMF )TM选项可以进行匹配滤波,混合调制匹配滤波需要输入经过MNF变换的文件或其它的isotropic数据,单位变化噪声。
MNF Rotation(Minimum Noise Fraction)工具用于判定图像数据内在的维数(即波段数),分离数据中的噪声,减少随后处理中的计算需求量。
Forward MNF变换用于估计第一次旋转中所用的噪声统计。
该选项包括:从输入的数据中估计噪声;运用以前计算的噪声统计;使用与数据集相关的“暗色图像”(dark Image)进行噪声统计。
本文应用“从输入的数据中估计噪声”的方法,选择菜单栏Transforms--MNF Rotation--Forward MNF--Estimate Noise Statistics From Data,选择要输入的文件以及子集,在出现的对话框保存统计文件:图5-1 Forward MNF Transform对话框保存设置ENVI处理完毕后,MNF波段将被导入到可用波段列表中,并显示MNF EigenValues 图表窗口如图5-2。
输出的MNF波段数等于选择输出的波段数,本实验选取了前50个波段。
特征值较大(大于1)的波段包含数据,特征值接近于1的波段包含噪声。
显示可用波段列表中的特征图像(MNF波段),并与MNF特征值图表相比较,可以判定出哪些波段包含数据,哪些波段主要包含噪声。
在随后的数据处理中,所选取的MNF波段的子集应该仅包括那些图像在空间上连续显示且特征值大于MNF图表中曲线陡坡转折处的特征值的波段。
图5-2 MNF EigenValues 图表窗口选择Spectral--Mapping Methods--Mixture Tuned Matched Filtering。
当出现Mixture Tuned Matched Filter Input File selection 对话框时,根据需要选择所需的MNF文件或其空间和波谱子集。
点击“OK”。
将出现Endmember Collection:Mixture Tuned Matched Filter 对话框。
输入要被匹配的波谱(MNF空间)。
当所需波谱选择完毕后,点击“Apply”。
将出现Mixture Tuned Matched Filter Parameters 对话框。
用箭头切换按钮选择“Compute New Covariance Stats”,选择输出到“Memory”或“File”。
在“Output Data Type”菜单中,选择输出数据类型:浮点型,点击“OK”,开始处理。
图5-3 混合调制匹配滤波结果图6.去除包络线包络线去除是将反射波谱标准化的一种方法,它允许从通用的基线对每个吸收特征进行比较。
包络线去除是一个在波谱顶部的凸起的外壳拟合,它用直线段连接局部的波谱最大值。
注意:使用不同的波谱子集将得到不同的结果,因此应当抽取包含吸收特征的感兴趣区作为子集。
通过将包络线区分为图像中每个像元的实际波谱而把它消除。
在最终图像中的包络线和匹配波谱处,波谱等于1.0,出现吸收特征的区域波谱小于1.0。
也可以对数据文件或绘图窗口中的单个波谱进行包络线去除。
选择菜单栏Spectral--Mapping Methods--Continuum Removal。
当出现Continuum Removal Input File对话框时,选择输入文件,若需要,选取任意子集或掩模。
为得到最好的结果,应当抽取包含吸收特征的感兴趣区作为子集。
点击“OK”。
当出现Continuum Removal Parameters对话框时,选择输出到“Memory”或“File”。
点击“OK”,开始处理。
结果如图7-1:图7-1 去包络线结果图(右)与原影像图(左)对比7.波谱特征拟合Spectral Feature Fitting TM(SFF TM)是一种基于吸收特征的方法,使用最小方块技术将图像波谱的拟合比选择的参照波谱。
在对数据集进行包络线去除以后,参照波谱被缩放,从而与图像波谱相匹配。
该方法将为每一个参照波谱输出一幅比例图像,它可以对与要素权重相关的吸收特征的强度进行度量。
波谱特征拟合在一个小方块范围内,在每个选择的波长处对图像和参照波谱进行比较,并为每个参照波谱评定平方根误差。
选择菜单栏Spectral--Mapping Methods--Spectral Feature Fitting。
当出现Spectral Feature Fitting Input File对话框时,选择经过包络线去除的输入文件,若需要,选取任意子集或掩膜。
为得到最好的结果,应当抽取包含吸收特征的感兴趣区作为子集。
在出现的Endmember Collection: Feature Fitting对话框中输入所需的参照波谱。
点击“Apply”。
当出现Spectral Feature Fitting Parameters对话框时,用箭头切换按钮选择“Output separate Scale and RMS Images”或“Output Combined (Scale/RMS) Image”,如图7-1,并选择输出位置。