R语言可视化分析案例报告 附代码数据
【原创】R语言Shiny表格数据分析可视化案例报告(附代码数据)

【原创】R语⾔Shiny表格数据分析可视化案例报告(附代码数据)
R语⾔Shiny表格数据分析可视化案例报告
表格是⼯作和⽣活中常见的数据呈现⽅式,例如公司的很多报表就需要⽤到表格。
当我们展⽰数据的时候,⽤户当然不希望只看到⼀个静态的页⾯,所以就需要⼀些简单的交互功能:排序、查找、筛选等等。
基础的需求并不难实现,但当我们使⽤其他⽹页技术做这件事情的时候,既要做前端,也要做后端,代码量也不会少。
对技术⼩⽩来说,使⽤ R Shiny 做这样的事情就很容易了。
Shiny 是 R 社区⾥⾯⼀个⾮常出名的包,⽤来制作各类交互式⽹络应⽤,我们熟知的谢益辉就是其中的⼀位作者。
先睹为快看看 Shiny 能做出什么样的效果:
可以看出来, Shiny 简直天⽣就是为了交互⽽存在的。
Shiny 也提供了⾮常丰富的 widgets ,⼏乎覆盖了我们对 UI 的全部需求:
DT 也是谢⽼⼤写的包,是 JavaScript DataTables 库的R接⼝,R的数据对象可以直接通过 DT 呈现为HTML的表格。
不仅如此, DT 本⾝还⾃动⽀持筛选、分页、排序等功能,⾮常的强⼤。
⼀⾔以蔽之, Shiny + DT 是交互式呈现表格的⾮常好的⼀个⽅案。
下⾯以我最近做的⼀个表格为例,最终效果是这样的:。
【最新】R语言数据可视化 PPT课件教案讲义(附代码数据)图文

中级图形
basic 3d scatter plot
mpg
25
30
35
500 400 300 200 100 2 3 4 5 6 0
10
15
1
wt
disp
20
中级图形
气泡图 概念:用点的大小表示第三个变量的值 函数:symbols() symbols(x,y,circle=radius)
中级图形
scatter plot matrix via var package
100 200 300 400 2 3 4 5
100 20Leabharlann 300 400dispdrat
5
wt
2
3
4
10
15
20
25
30
3.0
3.5
4.0
4.5
5.0
3.0 3.5 4.0 4.5 5.0
10 15
20
25 30
mpg
中级图形
分组散点图 概念:以某个因子为条件绘制两个变量的散点图
> library(car) > library(ggplot2) > attach(mtcars) > scatterplot(mpg~wt|cyl)
> scatterplot(mpg~wt|cyl,data=mtcars,lwd=2,main="scatter plot of mpg vs. weight by # cylinders",xlab="height of car",ylab="miles per gallon",legend.plot=TRUE,id.method="identity",labels=s(mtcars),bo xplots="xy")
【最新】R语言关联分析模型报告案例附代码数据

【最新】R语⾔关联分析模型报告案例附代码数据【原创】附代码数据有问题到淘宝找“⼤数据部落”就可以了关联分析⽬录⼀、概括 (1)⼆、数据清洗 (1)2.1公⽴学费(NPT4_PUB) (1)2.2毕业率(Graduation.rate) (1)2.3贷款率(GRAD_DEBT_MDN_SUPP) (2)2.4偿还率(RPY_3YR_RT_SUPP) (2)2.5毕业薪⽔(MD_EARN_WNE_P10)。
(3)2.6 私⽴学费(NPT4_PRIV) (3)2.7 ⼊学率(ADM_RATE_ALL) (4)三、Apriori算法 (4)3.1 相关概念 (5)3.2 算法流程 (6)3.3 优缺点 (7)四、模型建⽴及结果 (8)4.1 公⽴模型 (8)4.2 私⽴模型 (11)⼀、概括对7703条样本数据,分别根据公⽴学费和私⽴学费差异,建⽴公⽴模型和私⽴模型,进⾏关联分析。
⼆、数据清洗2.1公⽴学费(NPT4_PUB)此字段,存在4个负值,与实际情况不符,故将此四个值重新定义为NULL。
重新定义后,NULL值的占⽐为75%,占⽐很⼤,不能直接将NULL值删除或者进⾏插补,故将NULL单独作为⼀个取值分组。
对⾮NULL的值按照等⽐原则进⾏分组,分组结果如下:A:[0,5896]B:(5896,7754]C:(7754, 9975]D:(9975, 13819]E:(13819, +]分组后取值分布为:2.2毕业率(Graduation.rate)将PrivacySuppressed值重新定义为NULL,重新定义后,NULL值的占⽐为20%,占⽐较⼤,不适合直接删除或进⾏插补,故将NULL单独作为⼀个取值分组。
对⾮NULL值根据等⽐原则进⾏分组,分组结果如下:A:[0,0.29]B:(0.29,0.47]C:(0.47, 0.61]D:(0.61, 0.75]E:(0.75, +]分组后取值分布为:2.3贷款率(GRAD_DEBT_MDN_SUPP)将PrivacySuppressed值重新定义为NULL,重新定义后,NULL值的占⽐为20%,占⽐较⼤,不适合直接删除或进⾏插补,故将NULL单独作为⼀个取值分组。
R语言主成分分析实例和代码

R语言进行主成分分析实例1、基于princomp函数进行实例说明:(中学生身体四项指标的主成分分析)在某中学随机抽取某年级30名学生,测量其身高(X1)、体重(X2)、胸围(X3)和坐高(X4),数据如下。
试对这30名中学生身体四项指标数据做主成分分析将上面这些数据保存在students_data.csv中data <- read.csv('D:/students_data.csv', header = T)注:header = T表示将students_data.csv中的第一行数据设置为列名,这种情况下,students_data.csv中的第二行到最后一行数据作为data中的有效数据。
header = F表示不将students_data.csv中的第一行数据设置为列名,这种情况下,students_data.csv 中的第一行到最后一行数据作为data中的有效数据。
第二步:进行主成分分析student.pr <- princomp(data, cor = T)注:cor = T的意思是用相关系数进行主成分分析。
Screeplot(student.pr,type=”line”,main=”碎石图”,lwd=2)第三步:观察主成分分析的详细情况summary(student.pr, loadings = T)执行完这一步的具体结果如下:说明:结果中的Comp.1、Comp.2、Comp.3和Comp.4是计算出来的主成分,Standard deviation代表每个主成分的标准差,Proportion of Variance代表每个主成分的贡献率,Cumulative Proportion代表各个主成分的累积贡献率。
每个主成分都不属于X1、X2、X 3和X4中的任何一个。
第一主成分、第二主成分、第三主成分和第四主成分都是X1、X2、X3和X4的线性组合,也就是说最原始数据的成分经过线性变换得到了各个主成分。
【原创】r语言层次聚类案例附代码数据

####################################################################### ############ 聚类分析####################################################################### a=cbind(农业总产值 ,林业总产值, 牧业总产值, 渔业总产值, 农村居民家庭拥有生产性固定资产原值, 农村居民家庭经营耕地面积)# ⭞↚⭞Ѡ⭞䠅㚐㊱rownames(a)=mydata$地区detach(mydata)hc1=hclust(dist(scale(a)),"ward.D2")cbind(hc1$merge,hc1$height)### [,1] [,2] [,3]## [1,] -22 -24 0.1562347## [2,] -2 -29 0.4954046## [3,] -12 -20 0.6158525## [4,] -4 1 0.7459837## [5,] -5 -7 0.8431761## [6,] -27 4 0.8502919## [7,] -28 -30 0.9238256## [8,] 2 7 0.9982795## [9,] -1 -9 1.0586066## [10,] -14 3 1.0996796## [11,] -16 -23 1.1292437## [12,] -25 10 1.2758523## [13,] -13 -19 1.4055256## [14,] -3 11 1.4555952## [15,] -21 6 1.6495578## [16,] -10 -17 1.7462669## [17,] 9 15 1.7988319## [18,] -18 12 1.8498860## [19,] -6 -11 1.9536216## [20,] -8 5 2.1881307## [21,] -15 16 2.5009589## [22,] -31 20 2.7312571## [23,] 13 18 3.0129164## [24,] 8 17 3.0616119## [25,] 19 23 3.2580779## [26,] 14 21 4.3774794## [27,] -26 22 5.2122229## [28,] 25 26 6.0403304## [29,] 24 27 8.3310723## [30,] 28 29 11.4082257plot(hc1,hang=-2,ylab="欧氏距离",main="ward ")cutree(hc1,3)## 北京天津河北山西内蒙辽宁吉林黑龙江上海江苏## 1 1 2 1 3 2 3 3 1 2## 浙江安徽福建江西山东河南湖北湖南广东广西## 2 2 2 2 2 2 2 2 2 2## 海南重庆四川贵州云南西藏陕西甘肃青海宁夏## 1 1 2 1 2 3 1 1 1 1## 新疆## 3library(NbClust)# 加载包res<-NbClust(a, distance ="euclidean", min.nc=2, max.nc=8,method ="complete", index ="ch")res$All.index## 2 3 4 5 6 7 8## 22.4859 64.2952 95.0505 91.2070 112.2167 126.6607 125.0580res$Best.nc## Number_clusters Value_Index## 7.0000 126.6607res$Best.partition## 北京天津河北山西内蒙辽宁吉林黑龙江上海江苏## 1 2 2 3 4 5 5 4 6 1## 浙江安徽福建江西山东河南湖北湖南广东广西## 5 1 1 3 2 1 3 3 3 1## 海南重庆四川贵州云南西藏陕西甘肃青海宁夏## 1 1 1 1 2 7 1 2 5 5## 新疆## 4####################################################################### ############ 因子分析####################################################################### x=ascale(x,center=T,scale=T)## 农业总产值林业总产值牧业总产值渔业总产值## 北京 -1.22777296 -0.68966546 -1.0576108 -0.717868590## 天津 -1.20072019 -1.32628581 -1.1287831 -0.587405030## 河北 1.44015787 -0.40768816 1.2735925 -0.276307864## 山西 -0.60736290 -0.39313054 -0.8459665 -0.730089499## 内蒙 -0.31173176 -0.16449038 0.3536925 -0.682760278## 辽宁 0.02317599 0.21376291 1.0886323 0.905582647## 吉林 -0.31664133 -0.16033106 0.3705164 -0.661159286## 黑龙江 0.73000004 0.28496065 0.6928325 -0.543827843## 上海 -1.22304555 -1.24358878 -1.1769433 -0.598687930## 江苏 1.32304764 -0.14014613 0.5106958 2.558246143## 浙江 -0.25945707 0.37842297 -0.4799669 1.088655075## 安徽 0.32193142 1.20245730 0.3549653 0.277626262## 福建 -0.22816878 1.77681021 -0.5790521 1.668371030## 江西 -0.46544975 1.43990544 -0.1820088 0.139953438## 山东 2.22835882 -0.05133246 2.0610374 2.643122498## 河南 2.22683767 0.36264203 2.0166955 -0.521101240## 湖北 0.88705181 -0.13647615 0.6684891 0.925656025## 湖南 1.03609706 1.81987138 0.8945726 -0.002409428## 广东 0.65132842 1.36442604 0.3760463 1.697020485## 广西 0.19109441 1.64358969 0.2862654 0.136415807## 海南 -0.95958625 0.32594217 -0.9698633 -0.119446069## 重庆 -0.61246376 -0.82851329 -0.6191076 -0.632081027## 四川 1.13921636 0.49292656 2.0375425 -0.313747797## 贵州 -0.59146827 -0.69749477 -0.6664339 -0.677051827## 云南 -0.10569354 1.40222691 0.0524867 -0.583545796## 西藏 -1.33060989 -1.32909946 -1.1967954 -0.752065694## 陕西 0.01099770 -0.64550329 -0.4072439 -0.713500151## 甘肃 -0.48272891 -1.11489458 -0.9441448 -0.747831257## 青海 -1.27264229 -1.30451055 -1.0825979 -0.751154486## 宁夏 -1.16021392 -1.24089745 -1.1284759 -0.716850181## 新疆 0.14646191 -0.83389594 -0.5730687 -0.711758136## 农村居民家庭拥有生产性固定资产原值农村居民家庭经营耕地面积## 北京 -0.521919855 -0.69519658 ## 天津 -0.036498322 -0.33578982 ## 河北 0.004069841 -0.23262677 ## 山西 -0.824825602 -0.02962851 ## 内蒙 1.179852466 2.59936535## 辽宁 0.730243656 0.39633505## 吉林 0.724094855 1.89053536## 黑龙江 1.396721068 3.65096289## 上海 -1.404513394 -0.77506475 ## 江苏 -0.340308064 -0.44560856 ## 浙江 0.499884752 -0.68188522 ## 安徽 -0.279565363 -0.23262677 ## 福建 -0.618739413 -0.61865625 ## 江西 -0.805278639 -0.33911766 ## 山东 0.133404538 -0.31582278 ## 河南 -0.500048919 -0.32247846 ## 湖北 -0.721961668 -0.29252790 ## 湖南 -0.917381131 -0.45559208 ## 广东 -0.957062704 -0.68521306 ## 广西 -0.615649655 -0.40567447 ## 海南 -0.663204069 -0.58537785 ## 重庆 -0.570175555 -0.43229719 ## 四川 -0.420353046 -0.48221480 ## 贵州 -0.604823220 -0.46890344 ## 云南 0.118332502 -0.32913414 ## 西藏 3.590383141 -0.23262677 ## 陕西 -0.572497480 -0.35575687 ## 甘肃 0.165991341 0.04358397## 青海 0.415065901 -0.25259382 ## 宁夏 0.655330865 0.36638449## 新疆 1.761431173 1.05524743 ## attr(,"scaled:center")## 农业总产值林业总产值## 1514.206129 111.20612 9## 牧业总产值渔业总产值## 877.092581 280.83903 2## 农村居民家庭拥有生产性固定资产原值农村居民家庭经营耕地面积## 17865.076774 2.58903 2## attr(,"scaled:scale")## 农业总产值林业总产值## 1097.854553 81.74416 7## 牧业总产值渔业总产值## 683.552567 373.13101 0## 农村居民家庭拥有生产性固定资产原值农村居民家庭经营耕地面积## 9767.757883 3.00495 2cor(x)### 农业总产值林业总产值牧业总产值## 农业总产值 1.00000000 0.4304367 0.9148545 ## 林业总产值 0.43043666 1.0000000 0.4593615 ## 牧业总产值 0.91485445 0.4593615 1.0000000 ## 渔业总产值 0.51598365 0.4351225 0.4103977 ## 农村居民家庭拥有生产性固定资产原值 -0.16652881 -0.3495913 -0.1017802## 农村居民家庭经营耕地面积 0.04040478 -0.0961515 0.1426829## 渔业总产值## 农业总产值 0.5159836## 林业总产值 0.4351225## 牧业总产值 0.4103977## 渔业总产值 1.0000000## 农村居民家庭拥有生产性固定资产原值 -0.2131248## 农村居民家庭经营耕地面积 -0.2669966## 农村居民家庭拥有生产性固定资产原值## 农业总产值 -0.1665288 ## 林业总产值 -0.3495913 ## 牧业总产值 -0.1017802 ## 渔业总产值 -0.2131248 ## 农村居民家庭拥有生产性固定资产原值 1.0000000 ## 农村居民家庭经营耕地面积 0.5316341 ## 农村居民家庭经营耕地面积## 农业总产值 0.04040478## 林业总产值 -0.09615150## 牧业总产值 0.14268286## 渔业总产值 -0.26699659## 农村居民家庭拥有生产性固定资产原值 0.53163410## 农村居民家庭经营耕地面积 1.00000000FA=factanal(x,3,scores="regression")FA#### Call:## factanal(x = x, factors = 3, scores = "regression")#### Uniquenesses:## 农业总产值林业总产值## 0.134 0.64 9## 牧业总产值渔业总产值## 0.005 0.00 5## 农村居民家庭拥有生产性固定资产原值农村居民家庭经营耕地面积## 0.005 0.61 0#### Loadings:## Factor1 Factor2 Factor3## 农业总产值 0.902 0.231## 林业总产值 0.460 -0.274 0.253## 牧业总产值 0.989 0.100## 渔业总产值 0.335 -0.172 0.924## 农村居民家庭拥有生产性固定资产原值 -0.185 0.980## 农村居民家庭经营耕地面积 0.120 0.569 -0.227#### Factor1 Factor2 Factor3## SS loadings 2.164 1.396 1.032## Proportion Var 0.361 0.233 0.172## Cumulative Var 0.361 0.593 0.765#### The degrees of freedom for the model is 0 and the fit was 0.0338A=FA$loadings#D=diag(FA$uniquenesses)#cancha=cor(x)-A%*%t(A)-Dsum(cancha^2)## [1] 0.01188033FA$scores## Factor1 Factor2 Factor3## 北京 -0.9595745 -0.700059511 -0.55760316## 天津 -1.0947804 -0.236528598 -0.28377148## 河北 1.3398849 0.269241913 -0.72734450## 山西 -0.6949304 -0.952525400 -0.71168863## 内蒙 0.3022926 1.274620864 -0.61477840## 辽宁 0.9086974 0.898645857 0.80686141## 吉林 0.3617131 0.823049845 -0.69568729## 黑龙江 0.6377695 1.558056539 -0.53064438## 上海 -1.0020542 -1.600313046 -0.58279912## 江苏 0.2978404 -0.338175607 2.58332275## 浙江 -0.6586307 0.351125849 1.47562686## 安徽 0.3633716 -0.220261996 0.12915299## 福建 -0.7017677 -0.799773443 1.90201088## 江西 -0.1252221 -0.843258690 0.03964935## 山东 1.8098550 0.433178408 2.27098864## 河南 2.1841524 -0.072629248 -1.35570609## 湖北 0.6625677 -0.618906179 0.64211420## 湖南 1.0200226 -0.733225411 -0.50075826## 广东 0.3057090 -0.945233885 1.54225085## 广西 0.3420343 -0.562216144 -0.07785160## 海南 -0.9131785 -0.847172077 0.04381513## 重庆 -0.5087268 -0.661768675 -0.62025496## 四川 2.1397385 -0.003827953 -1.11031362## 贵州 -0.5463126 -0.703696201 -0.66210885## 云南 0.1044516 0.146947680 -0.63418799## 西藏 -1.5214222 3.342858193 0.36144124## 陕西 -0.2687306 -0.616728372 -0.78286620## 甘肃 -0.8904189 0.010720625 -0.48059064## 青海 -1.0791206 0.225711752 -0.37974261## 宁夏 -1.1481591 0.456190239 -0.27546552## 新疆 -0.6670714 1.665952673 -0.21307102FA=factanal(x,3,scores="regression")#FA#### Call:## factanal(x = x, factors = 3, scores = "regression")#### Uniquenesses:## 农业总产值林业总产值## 0.134 0.64 9## 牧业总产值渔业总产值## 0.005 0.00 5## 农村居民家庭拥有生产性固定资产原值农村居民家庭经营耕地面积## 0.005 0.61 0#### Loadings:## Factor1 Factor2 Factor3## 农业总产值 0.902 0.231## 林业总产值 0.460 -0.274 0.253## 牧业总产值 0.989 0.100## 渔业总产值 0.335 -0.172 0.924## 农村居民家庭拥有生产性固定资产原值 -0.185 0.980## 农村居民家庭经营耕地面积 0.120 0.569 -0.227#### Factor1 Factor2 Factor3## SS loadings 2.164 1.396 1.032## Proportion Var 0.361 0.233 0.172## Cumulative Var 0.361 0.593 0.765#### The degrees of freedom for the model is 0 and the fit was 0.0338 biplot(FA$scores,FA$loadings)######################################################################## ########## 主成分分析####################################################################### # mydata<-read.csv("cosume.csv",header=TRUE)x=aPCA=princomp(x)# 分分析summary(PCA)## Importance of components:## Comp.1 Comp.2 Comp.3 Comp.4## Standard deviation 9611.2440729 1.248877e+03 3.201426e+02 2.211289e+02## Proportion of Variance 0.9817713 1.657641e-02 1.089277e-03 5.1968 75e-04## Cumulative Proportion 0.9817713 9.983477e-01 9.994370e-01 9.9995 67e-01## Comp.5 Comp.6## Standard deviation 6.377898e+01 2.299907e+00## Proportion of Variance 4.323210e-05 5.621753e-08## Cumulative Proportion 9.999999e-01 1.000000e+00plot(PCA)screeplot(PCA,type="lines")# ⻄⭞ഴPCA$loadings##### Loadings:## Comp.1 Comp.2 Comp.3 Comp.4 Comp. 5## 农业总产值 0.847 0.529 ## 林业总产值 -0.994 ## 牧业总产值 0.510 0.340 -0.786 ## 渔业总产值 0.147 -0.939 -0.304 ## 农村居民家庭拥有生产性固定资产原值 1.000 ## 农村居民家庭经营耕地面积## Comp.6## 农业总产值## 林业总产值## 牧业总产值## 渔业总产值## 农村居民家庭拥有生产性固定资产原值## 农村居民家庭经营耕地面积 1.000#### Comp.1 Comp.2 Comp.3 Comp.4 Comp.5 Comp.6## SS loadings 1.000 1.000 1.000 1.000 1.000 1.000## Proportion Var 0.167 0.167 0.167 0.167 0.167 0.167## Cumulative Var 0.167 0.333 0.500 0.667 0.833 1.000diag(1/sqrt(diag(cor(x))))%*%eigen(cor(x))$vectors%*%diag(sqrt(eigen(co r(x))$values))# ⭞⭞䠅фѱᡆ分的⭞ީ⭞䱫## [,1] [,2] [,3] [,4] [,5]## [1,] 0.8748914 0.33002393 -0.05962134 -0.2919961 0.03333473## [2,] 0.7199843 -0.09695761 0.39747812 0.5280225 0.18691501## [3,] 0.8358325 0.42778470 0.06215717 -0.2657004 0.10009450## [4,] 0.7239860 -0.13749802 -0.54651176 0.3113087 -0.24595467## [5,] -0.4283184 0.72257821 -0.37626680 0.2240839 0.32017966## [6,] -0.1942551 0.86197649 0.26492953 0.1648656 -0.34904716## [,6]## [1,] 0.189001599## [2,] 0.022088666## [3,] -0.184133750## [4,] -0.029268951## [5,] 0.010900009## [6,] 0.007698218print(-loadings(PCA),cutoff=0.001)#### Loadings:## Comp.1 Comp.2 Comp.3 Comp.4 Comp. 5## 农业总产值 0.019 -0.847 0.041 -0.529 0.027 ## 林业总产值 0.003 -0.026 0.036 0.096 0.994 ## 牧业总产值 0.007 -0.510 -0.340 0.786 -0.077 ## 渔业总产值 0.008 -0.147 0.939 0.304 -0.068 ## 农村居民家庭拥有生产性固定资产原值 -1.000 -0.021 0.006 -0.002 0.002 ## 农村居民家庭经营耕地面积 -0.003 0.003 ## Comp.6## 农业总产值## 林业总产值 0.003## 牧业总产值 0.001## 渔业总产值 -0.002## 农村居民家庭拥有生产性固定资产原值## 农村居民家庭经营耕地面积 -1.000#### Comp.1 Comp.2 Comp.3 Comp.4 Comp.5 Comp.6## SS loadings 1.000 1.000 1.000 1.000 1.000 1.000## Proportion Var 0.167 0.167 0.167 0.167 0.167 0.167## Cumulative Var 0.167 0.333 0.500 0.667 0.833 1.000####################################################################### ##### 条形图####################################################################### country<-mydata$地区percent<-mydata$农业总产值d<-data.frame(country,percent)# png("d:\\test2.png",width=2048,height=2048)f<-function(name,value) {xsize=200plot(0, 0,xlab="",ylab="",axes=FALSE,xlim=c(-xsize,xsize),ylim=c(-xsize,xsize))for(i in 1:length(name)){info =name[i]percent =value[i]k =(1:(360*percent/100)*10)/10r=xsize*(length(name)-i+1)/length(name)#print(r)x=r*sin(k/180*pi)y=r*cos(k/180*pi)text(-18,r,info,pos=2,cex=0.7)text(-9,r,paste(percent,"%"),cex=0.7)lines(x,y,col="red")}}f(country,percent)####################################################################### ###### 柱状图####################################################################### library(RColorBrewer)pv<-percentid<-countrycol<-c(brewer.pal(9, "YlOrRd")[1:9],brewer.pal(9, "Blues")[1:9]) barplot(pv,col=col,horiz =TRUE,xlim=c(-8000.00,5000))title(main=list("农业总产值",cex=2),sub="",ylab="地区")text(y=seq(from=0.7,length.out=31,by=1.2),x=-450.00,labels=id)legend("topleft",legend=rev(id),pch=10,col=rev(col),ncol=2)。
R语言arima模型时间序列分析报告(附代码数据)

R语言arima模型时间序列分析报告(附代码数据)【原创】定制撰写数据分析可视化项目案例调研报告(附代码数据)有问题到淘宝找“大数据部落”就可以了R语言arima模型时间序列分析报告library(openxlsx)data=read.xlsx("hs300.xlsx")XXX收盘价(元)`date=data$日期date=as.Date(as.numeric(date),origin="1899-12-30")#1998-07-05#绘制时间序列图plot(date,timeseries)timeseriesdiff<-diff(timeseries,differences=1)plot(date[-1],timeseriesdiff)【原创】定制撰写数据分析可视化项目案例调研报告(附代码数据)有问题到淘宝找“大数据部落”就可以了#时间序列分析之ARIMA模型预测#我们可以通过键入下面的代码来得到时间序列(数据存于“timeseries”)的一阶差分,并画出差分序列的图:#时间序列分析之ARIMA模型预测#从一阶差分的图中可以看出,数据仍是不平稳的。
我们继续差分。
【原创】定制撰写数据分析可视化项目案例调研报告(附代码数据)有问题到淘宝找“大数据部落”就可以了#时间序列分析之ARIMA模型预测#二次差分(上面)后的时间序列在均值和方差上确实看起来像是平稳的,随着时间推移,时间序列的水平和方差大致保持不变。
因此,看起来我们需要对data进行两次差分以得到平稳序列。
#第二步,找到合适的ARIMA模型#如果你的时间序列是平稳的,或者你通过做n次差分转化为一个平稳时间序列,接下来就是要选择合适的ARIMA模型,这意味着需要寻找ARIMA(p,d,q)中合适的p值和q值。
为了得到这些,通常需要检查[平稳时间序列的(自)相关图和偏相关图。
#我们使用R中的“acf()”和“pacf”函数来分别(自)相关图和偏相关图。
R语言实验报告范文

R语言实验报告范文实验报告:基于R语言的数据分析摘要:本实验基于R语言进行数据分析,主要从数据类型、数据预处理、数据可视化以及数据分析四个方面进行了详细的探索和实践。
实验结果表明,R语言作为一种强大的数据分析工具,在数据处理和可视化方面具有较高的效率和灵活性。
一、引言数据分析在现代科学研究和商业决策中扮演着重要角色。
随着大数据时代的到来,数据分析的方法和工具也得到了极大发展。
R语言作为一种开源的数据分析工具,被广泛应用于数据科学领域。
本实验旨在通过使用R语言进行数据分析,展示R语言在数据处理和可视化方面的应用能力。
二、材料与方法1.数据集:本实验使用了一个包含学生身高、体重、年龄和成绩的数据集。
2.R语言版本:R语言版本为3.6.1三、结果与讨论1.数据类型处理在数据分析中,需要对数据进行适当的处理和转换。
R语言提供了丰富的数据类型和操作函数。
在本实验中,我们使用了R语言中的函数将数据从字符型转换为数值型,并进行了缺失值处理。
同时,我们还进行了数据类型的检查和转换。
2.数据预处理数据预处理是数据分析中的重要一步。
在本实验中,我们使用R语言中的函数处理了异常值、重复值和离群值。
通过计算均值、中位数和四分位数,我们对数据进行了描述性统计,并进行了异常值和离群值的检测和处理。
3.数据可视化数据可视化是数据分析的重要手段之一、R语言提供了丰富的绘图函数和包,可以用于生成各种类型的图表。
在本实验中,我们使用了ggplot2包绘制了散点图、直方图和箱线图等图表。
这些图表直观地展示了数据的分布情况和特点。
4.数据分析数据分析是数据分析的核心环节。
在本实验中,我们使用R语言中的函数进行了相关性分析和回归分析。
通过计算相关系数和回归系数,我们探索了数据之间的关系,并对学生成绩进行了预测。
四、结论本实验通过使用R语言进行数据分析,展示了R语言在数据处理和可视化方面的强大能力。
通过将数据从字符型转换为数值型、处理异常值和离群值,我们获取了可靠的数据集。
【原创】R语言数据可视化分析报告(附代码数据)
Vis 3这个图形是用另一个数据集菱形建立的,也是内置在ggplot2包中的数据集。
library(ggthemes)
ggplot(diamonds)+geom_density(aes(price,fill=cut,color=cut),alpha=0.4,size=0.5)+labs(title='Diamond Price Density',x='Diamond Price (USD)',y='Density')+theme_economist()
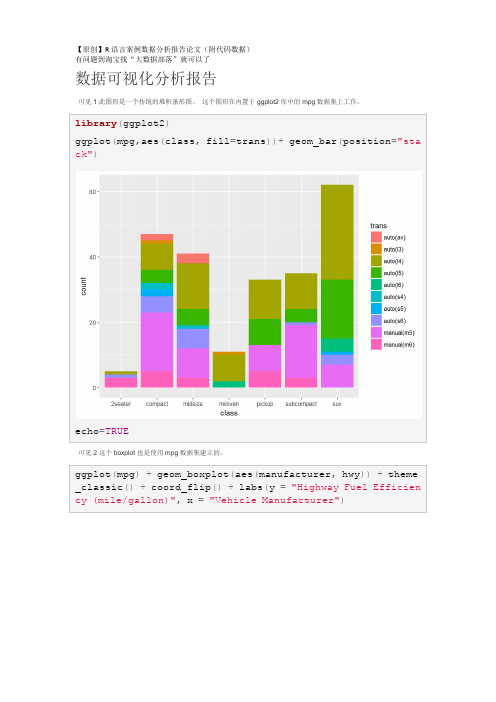
library(ggplot2)
ggplot(mpg,aes(class,fill=trans))+geom_bar(position="stack")
echo=TRUE
可见2这个boxplot也是使用mpg数据集建立的。
ggplot(mpg)+geom_boxplot(aes(manufacturer,hwy))+theme_classic()+coord_flip()+labs(y="Highway Fuel Efficiency (mile/gallon)",x="Vehicle Manufacturer")
echo=TRUE
另外,我正在使用ggplot2软件包来将线性模型拟合到框架内的所有数据上。
ggplot(iris,aes(Sepal.Length,Petal.Length))+geom_point()+geom_smooth(method=lm)+theme_minimal()+theme(panel.grid.major=element_line(size=1),panel.grid.minor=element_line(size=0.7))+labs(title='relationship between Petal and Sepal Length',x='Iris Sepal Length',y='Iris Petal Length')
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
library(ggplot2)
ggplot(data=mtcars,
aes(x=factor(1),fill=factor(carb)))+
ylab("Percentage of Car Amount by Carb Type")+xlab("")+
## Max. :33.90 Max. :8.000 Max. :472.0 Max. :335.0
## drat wt qsec vs
## Min. :2.760 Min. :1.513 Min. :14.50 Min. :0.0000
## 1st Qu.:3.080 1st Qu.:2.581 1st Qu.:16.89 1st Qu.:0.0000
## Median :3.695 Median :3.325 Median :17.71 Median :0.0000
## Mean :3.597 Mean :3.217 Mean :17.85 Mean :0.4375
## 3rd Qu.:3.920 3rd Qu.:3.610 3rd Qu.:18.90 3rd Qu.:1.0000
ggplot(mtcars,
aes(x=factor(cyl),fill=factor(gear)))+
xlab("cyl amount'")+
ylab("gear amount'")+
geom_bar(color="black")
4. Draw a scatter plot showing the relationship betweenwtandmpg.
5. Visualization of Hourse Power and Mile Per Gallon.
ggplot(mtcars,aes(x=hp,y=mpg))+
xlab("Hourse Power")+ylab("Mile Per Gallon")+
geom_point()+
geom_line()+
geom_bar(width=1)+
coord_polar(theta="y")
2. 绘制一个条形图,显示mtcars中每个齿轮类型的数量。
ggplot(data=mtcars,aes(x=gear))+geom_bar(stat="count")
3. 接下来显示每个齿轮类型的数字的堆积条形图以及它们如何被cyl进一步划分出来。
R语言可视化报告
Mtcars概要
summary(mtcars)
## mpg cyl disp hp
## Min. :10.40 Min. :4.000 Min. : 71.1 Min. : 52.0
## 1st Qu.:15.43 1st Qu.:4.000 1st Qu.:120.8 1st Qu.: 96.5
## Max. :4.930 Max. :5.424 Max. :22.90 Max. :1.0000
## am gear carb
## Min. :0.0000 Min. :3.000 Min. :1.000
## 1st Qu.:0.0000 1st Qu.:3.000 1st Qu.:2.000
ggtitle("'hp' and 'mpg' relation")+
stat_smooth(method="loess",formula=y~x,size=1,col="red")
ggplot(mtcars,aes(x=wt,y=mpg))+
xlab("Car Weight")+ylab("Mห้องสมุดไป่ตู้le Per Gallon")+
geom_point()+
geom_line()+
ggtitle("'wt' and 'mpg' relation")+
stat_smooth(method="loess",formula=y~x,size=1,col="green")
## Median :19.20 Median :6.000 Median :196.3 Median :123.0
## Mean :20.09 Mean :6.188 Mean :230.7 Mean :146.7
## 3rd Qu.:22.80 3rd Qu.:8.000 3rd Qu.:326.0 3rd Qu.:180.0
## Median :0.0000 Median :4.000 Median :2.000
## Mean :0.4062 Mean :3.688 Mean :2.812
## 3rd Qu.:1.0000 3rd Qu.:4.000 3rd Qu.:4.000
## Max. :1.0000 Max. :5.000 Max. :8.000