计量经济学习题册第八章、第九章、第十章 答案
计量经济学(数字教材版)课后习题参考答案

课后习题参考答案第二章教材习题与解析1、 判断下列表达式是否正确:y i =β0+β1x i ,i =1,2,⋯ny ̂i =β̂0+β̂1x i ,i =1,2,⋯nE(y i |x i )=β0+β1x i +u i ,i =1,2,⋯n E(y i |x i )=β0+β1x i ,i =1,2,⋯nE(y i |x i )=β̂0+β̂1x i ,i =1,2,⋯ny i =β0+β1x i +u i ,i =1,2,⋯ny ̂i =β̂0+β̂1x i +u i ,i =1,2,⋯n y i =β̂0+β̂1x i +u i ,i =1,2,⋯n y i =β̂0+β̂1x i +u ̂i ,i =1,2,⋯n y ̂i =β̂0+β̂1x i +u ̂i ,i =1,2,⋯n答案:对于计量经济学模型有两种类型,一是总体回归模型,另一是样本回归模型。
两类回归模型都具有确定形式与随机形式两种表达方式:总体回归模型的确定形式:X X Y E 10)|(ββ+= 总体回归模型的随机形式:μββ++=X Y 10样本回归模型的确定形式:X Y 10ˆˆˆββ+= 样本回归模型的随机形式:e X Y ++=10ˆˆββ 除此之外,其他的表达形式均是错误的2、给定一元线性回归模型:y =β0+β1x +u (1)叙述模型的基本假定;(2)写出参数β0和β1的最小二乘估计公式;(3)说明满足基本假定的最小二乘估计量的统计性质; (4)写出随机扰动项方差的无偏估计公式。
答案:(1)线性回归模型的基本假设有两大类,一类是关于随机误差项的,包括零均值、同方差、不序列相关、满足正态分布等假设;另一类是关于解释变量的,主要是解释变量是非随机的,如果是随机变量,则与随机误差项不相关。
(2)12ˆi iix yxβ=∑∑,01ˆˆY X ββ=- (3)考察总体的估计量,可从如下几个方面考察其优劣性:1)线性性,即它是否是另一个随机变量的线性函数; 2)无偏性,即它的均值或期望是否等于总体的真实值;3)有效值,即它是否在所有线性无偏估计量中具有最小方差;4)渐进无偏性,即样本容量趋于无穷大时,它的均值序列是否趋于总体真值; 5)一致性,即样本容量趋于无穷大时,它是否依概率收敛于总体的真值;6)渐进有效性,即样本容量趋于无穷大时,它在所有的一致估计量中是否具有最小的渐进方差。
计量经济学课后题答案

第十三章面板数据模型一简单题1、简述面板数据模型的优点和局限性它能综合利用样本信息,同时反映应变量在截面和时序两个方向上的变化规律及特征。
由于面板数据模型在经济定量分析中,起着只用截面或只用时序数据模型不可替代的独特优点,而具有很高的应用价值。
总之:1.增加了样本容量;2. 可多层面分析经济问题局限性:模型设定错误与数据手机不慎引起较大的偏差;研究截面或者平行数据时,由于样本非随机性造成观测值的偏差,从而导致模型选择上的偏差。
2、你是如何理解面板数据的?在经济领域中,同时具有截面与时序特征的数据很多。
如统计年鉴中提供的各地区或各国的若干系列的年度(季度或月度)经济总量数据;在企业投资分析中,要用到多个企业若干指标的月度或季度时间序列数据;在城镇居民消费分析中,要用到不同省市反映居民消费和收入的年度时序数据。
我们将上述的企业、或地区等统称为个体,从行的方向看,是由若干个体在某个时期构成的截面观察值(截面样本),从列的方向看,是各时间序列。
这种具有三维(截面、时期、变量)信息的数据结构称为面板。
这是“面板”数据的由来,面板数据也称为时序截面数据或混合数据(Pooled Data)。
3、简述建立面板数据模型的过程。
(1)建立面板数据对象,即建立工作文件;(2)面板时序变量平稳性检验;(3)协整检验;(4)模型识别;(5)建立模型;(6)结论。
二填空题1、GDP界面变量是一维变量,面板变量为三维变量。
2、面板数据模型是无斜率系数非齐性、而截距齐性的模型。
3、面板数据模型识别包括效应模型识别和具体模型识别。
4、建立面板数据模型之前,要对面板变量进行平稳性检验和协整检验。
第十二章向量自回归(VAR)模型和向量误差修正(VEC)模型一简答题1、VAR模型的特点VAR模型不以经济理论为指导,它根据样本数据统计特征建模。
VAR模型对参数不施加零约束(如t检验),故称其为无约束VAR模型。
VAR模型的解释变量中不含t期变量,所有与线性联利方程组模型有关的问题均不存在。
计量经济学第二版课后习题答案1-8章 - 编辑版
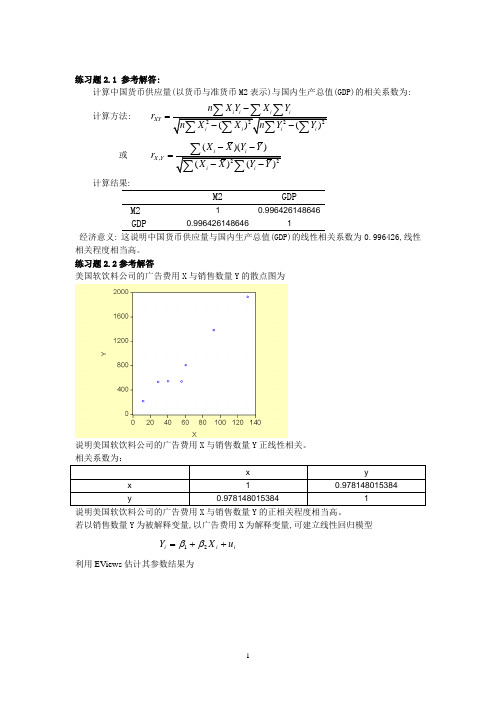
练习题2.1 参考解答:计算中国货币供应量(以货币与准货币M2表示)与国内生产总值(GDP)的相关系数为:计算方法: XY n X Y X Y r -=或,()()X Y X X Y Y r --=计算结果:M2GDPM2 10.996426148646GDP0.9964261486461经济意义: 这说明中国货币供应量与国内生产总值(GDP)的线性相关系数为0.996426,线性相关程度相当高。
练习题2.2参考解答美国软饮料公司的广告费用X 与销售数量Y 的散点图为说明美国软饮料公司的广告费用X 与销售数量Y 正线性相关。
相关系数为:说明美国软饮料公司的广告费用X 与销售数量Y 的正相关程度相当高。
若以销售数量Y 为被解释变量,以广告费用X 为解释变量,可建立线性回归模型 i i i u X Y ++=21ββ 利用EViews 估计其参数结果为经t 检验表明, 广告费用X 对美国软饮料公司的销售数量Y 确有显著影响。
回归结果表明,广告费用X 每增加1百万美元, 平均说来软饮料公司的销售数量将增加14.40359(百万箱)。
练习题2.3参考解答: 1、 建立深圳地方预算内财政收入对GDP 的回归模型,建立EViews 文件,利用地方预算内财政收入(Y )和GDP 的数据表,作散点图可看出地方预算内财政收入(Y )和GDP 的关系近似直线关系,可建立线性回归模型: t t t u GDP Y ++=21ββ 利用EViews 估计其参数结果为即 ˆ20.46110.0850t tY GDP =+ (9.8674) (0.0033)t=(2.0736) (26.1038) R 2=0.9771 F=681.4064经检验说明,深圳市的GDP 对地方财政收入确有显著影响。
20.9771R =,说明GDP 解释了地方财政收入变动的近98%,模型拟合程度较好。
模型说明当GDP 每增长1亿元时,平均说来地方财政收入将增长0.0850亿元。
计量经济学练习题及参考答案

第八章练习题及参考解答Sen 和Srivastava (1971)在研究贫富国之间期望寿命的差异时,利用101个国家的数据,建立了如下的回归模型:2.409.39ln3.36((ln 7))i i i i Y X D X =-+--R 2=其中:X 是以美元计的人均收入;Y 是以年计的期望寿命;Sen 和Srivastava 认为人均收入的临界值为1097美元(ln10977=),若人均收入超过1097美元,则被认定为富国;若人均收入低于1097美元,被认定为贫穷国。
括号内的数值为对应参数估计值的t-值。
1)解释这些计算结果。
2)回归方程中引入()ln 7i i D X -的原因是什么如何解释这个回归解释变量 3)如何对贫穷国进行回归又如何对富国进行回归 4)从这个回归结果中可得到的一般结论是什么 练习题参考解答: 1. 结果解释依据给定的估计检验结果数据,对数人均收入对期望寿命在统计上并没有显著影响,截距和变量()ln 7i i D X -在统计上对期望寿命有显著影响;同时,()()2.40 3.3679.39 3.36ln ((ln 7)) 1 2.409.39ln 0 i i i i i i i X D X D Y X D ⎧-+⨯+---==⎨-+=⎩富国时穷国时表明贫富国之间的期望寿命存在差异。
2. 回归方程中引入()ln 7i i D X -的原因是从截距和斜率两个方面考证收入因素对期望寿命的影响。
这个回归解释变量可解释为对期望寿命的影响存在截距差异和斜率差异的共同因素。
3.对穷国进行回归时,回归模型为12ln 1097i i i i i i Y X Y X αα=+≤,其中,为美元时的寿命; 对富国进行回归时,回归模型为12ln 1097i i i i i i Y X Y X ββ=+>,其中,为美元时的寿命;4. 一般的结论为富国的期望寿命药高于穷国的期望寿命,并且随着收入的增加,在平均意义上,富国的期望寿命的增加变化趋势优于穷国,贫富国之间的期望寿命的确存在显著差异。
庞皓计量经济学练习题及参考解答第四版

庞皓计量经济学练习题及参考解答第四版目录1.简介2.练习题及解答–第一章:引言–第二章:回归分析的基本步骤–第三章:多元回归分析–第四章:假设检验和检定–第五章:函数形式选择和非线性回归–第六章:虚拟变量和联合假设检验–第七章:时间序列回归分析–第八章:面板数据回归分析–第九章:工具变量法–第十章:极大似然估计3.总结1. 简介《庞皓计量经济学练习题及参考解答第四版》是一本与《庞皓计量经济学》教材配套的习题集,旨在帮助读者巩固和加深对计量经济学理论和方法的理解。
本书第四版相比前三版进行了全面的修订和更新,更加贴近实际应用环境,同时也增加了一些新的内容。
本文档为《庞皓计量经济学练习题及参考解答第四版》的摘要,包含了各章节的练习题及参考解答。
2. 练习题及解答第一章:引言1.什么是计量经济学?计量经济学的研究范围是什么?–答案:计量经济学是运用统计学方法研究经济理论及实证问题的学科。
它主要研究经济学中的理论模型和假设是否能得到实证支持,对经济变量之间的关系进行定量分析和预测。
2.计量经济学中常用的方法有哪些?–答案:常用的计量经济学方法包括线性回归分析、假设检验、面板数据分析、时间序列分析等。
这些方法能够帮助研究者解决实际经济问题,预测经济变量,评估政策效果等。
第二章:回归分析的基本步骤1.请解释什么是回归分析?–答案:回归分析是一种研究因变量和自变量之间关系的统计方法。
通过建立一个数学模型来描述二者之间的函数关系,并利用样本数据对该函数关系进行估计和推断。
回归分析的基本思想是找到自变量对因变量的解释能力,并进行统计推断。
2.利用最小二乘法进行回归分析的基本思想是什么?–答案:基本思想是通过最小化预测值与实际观测值之间的差异,来确定最佳的参数估计值。
也就是说,最小二乘法通过选择一组参数,使得预测值与实际观测值之间的平方差最小化。
3.如何判断回归模型的拟合优度?–答案:拟合优度可以通过判断回归方程的决定系数R2来评估。
计量经济学第十章练习题及参考答案

第十章练习题及参考解答10.1表10.10是某国的宏观经济季度数据。
其中, GDP为国内生产总值,PDI为个人可支配收入,PCE为个人消费支出,利润为公司税后利润,红利为公司净红利支出。
表10.10 1980~2001年某国宏观经济季度数据(单位: 亿元)1) 画出利润和红利的散点图,并直观地考察这两个时间序列是否是平稳的。
2) 应用单位根检验分别检验利润和红利两个时间序列是否是平稳的。
3) 分别检验GDP 、PDI 和PCE 等序列是否平稳,并判定其单整阶数是否相同?练习题10.1参考解答:1) 利润和红利的散点图如下,从图中可看出,利润和红利序列均值和方差不稳定,因此可能是非平稳的。
2)利润序列有截距项,在Eviews5.0中选取截距项,同时最大滞后长度取11进行单位根检验,检验结果如下,Null Hypothesis: PFT has a unit root Exogenous: Constant, Linear TrendLag Length: 0 (Automatic based on SIC, MAX LAG=11)t-Statistic Prob.*Augmented Dickey-Fuller test statistic -1.797079 0.6978Test critical values:1% level -4.066981 5% level -3.46229210% level-3.157475t 统计量大于所有显著性水平下的MacKinnon 临界值,故不能拒绝原假设,该序列是不平稳的。
红利序列有截距项和趋势项,在Eviews5.0中选取截距项和趋势项,同时最大滞后长度取11进行单位根检验,检验结果如下,Null Hypothesis: BNU has a unit rootExogenous: Constant, Linear TrendLag Length: 1 (Automatic based on SIC, MAX LAG=11)t-Statistic Prob.*Augmented Dickey-Fuller test statistic -2.893559 0.1698Test critical values: 1% level -4.0682905% level -3.46291210% level -3.157836*MacKinnon (1996) one-sided p-values.t统计量大于所有显著性水平下的MacKinnon临界值,故不能拒绝原假设,该序列是不平稳的。
计量经济学习题及参考答案

计量经济学各章习题第一章绪论1.1试列出计量经济分析地主要步骤.1.2计量经济模型中为何要包括扰动项?1.3什么是时间序列和横截面数据? 试举例说明二者地区别1.4估计量和估计值有何区别?第二章计量经济分析地统计学基础2.1名词解释随机变量概率密度函数抽样分布样本均值样本方差协方差相关系数标准差标准误差显著性水平置信区间无偏性有效性一致估计量接受域拒绝域第I 类错误2.2请用例 2.2中地数据求北京男生平均身高地99%置信区间.2.325 个雇员地随机样本地平均周薪为130元,试问此样本是否取自一个均值为120 元、标准差为10 元地正态总体?文档收集自网络,仅用于个人学习2.4某月对零售商店地调查结果表明,市郊食品店地月平均销售额为2500 元,在下一个月份中,取出16 个这种食品店地一个样本,其月平均销售额为2600 元,销售额地标准差为480 元.试问能否得出结论,从上次调查以来,平均月销售额已经发生了变化?文档收集自网络,仅用于个人学习第三章双变量线性回归模型3.1判断题(判断对错;如果错误,说明理由)(1)OLS 法是使残差平方和最小化地估计方法.(2)计算OLS 估计值无需古典线性回归模型地基本假定.(3)若线性回归模型满足假设条件(1)~(4),但扰动项不服从正态分布,则尽管OLS 估计量不再是BLUE ,但仍为无偏估计量.文档收集自网络,仅用于个人学习(4)最小二乘斜率系数地假设检验所依据地是t 分布,要求地抽样分布是正态分布.2(5)R2=TSS/ESS.(6)若回归模型中无截距项,则.(7)若原假设未被拒绝,则它为真.(8)在双变量回归中,地值越大,斜率系数地方差越大.3.2设和分别表示Y 对X 和X 对Y 地OLS 回归中地斜率,证明r 为X 和Y 地相关系数.3.3证明:(1)Y 地真实值与OLS 拟合值有共同地均值,即;(2)OLS 残差与拟合值不相关,即.3.4证明本章中( 3.18)和( 3.19)两式:(1)(2)3.5考虑下列双变量模型:模型1:模型2:(1)1 和1地OLS 估计量相同吗?它们地方差相等吗?(2)2 和2地OLS 估计量相同吗?它们地方差相等吗?3.6有人使用1980-1994 年度数据,研究汇率和相对价格地关系,得到如下结果:其中,Y=马克对美元地汇率X=美、德两国消费者价格指数(CPI)之比,代表两国地相对价格(1)请解释回归系数地含义;(2)X t 地系数为负值有经济意义吗?(3)如果我们重新定义X 为德国CPI与美国CPI之比,X 地符号会变化吗?为什么?3.7随机调查200 位男性地身高和体重,并用体重对身高进行回归,结果如下:其中Weight 地单位是磅(lb ),Height 地单位是厘米(cm).(1)当身高分别为177.67cm、164.98cm、187.82cm 时,对应地体重地拟合值为多少?(2)假设在一年中某人身高增高了 3.81cm,此人体重增加了多少?3.8设有10 名工人地数据如下:X 10 7 10 5 8 8 6 7 9 10Y 11 10 12 6 10 7 9 10 11 10 其中X= 劳动工时,Y= 产量(1)试估计Y=α+βX + u(要求列出计算表格);(2)提供回归结果(按标准格式)并适当说明;(3)检验原假设β=1.0.3.9用12 对观测值估计出地消费函数为Y=10.0+0.90X ,且已知=0.01,=200,=4000,试预测当X=250 时Y 地值,并求Y 地95%置信区间.文档收集自网络,仅用于个人学习3.10设有某变量(Y)和变量(X)1995—1999 年地数据如下:(3)试预测X=10 时Y 地值,并求Y 地95%置信区间.3.11根据上题地数据及回归结果,现有一对新观测值X =20,Y=7.62,试问它们是否可能来自产生样本数据地同一总体?文档收集自网络,仅用于个人学习3.12有人估计消费函数,得到如下结果(括号中数字为t 值):=15 + 0.81 =0.98(2.7)(6.5)n=19(1)检验原假设:=0(取显著性水平为5%)(2)计算参数估计值地标准误差;(3)求地95%置信区间,这个区间包括0 吗?3.13试用中国1985—2003 年实际数据估计消费函数:=α+β + u t其中:C代表消费,Y 代表收入.原始数据如下表所示,表中:Cr=农村居民人均消费支出(元)Cu=城镇居民人均消费支出(元)Y =国内居民家庭人均纯收入(元) Yr =农村居民家庭人均纯收入(元) Yu=城镇居民家庭人均可支配收入(元) Rpop=农村人口比重(%) pop=历年年底我国人口总数(亿人)P=居民消费价格指数(1985=100)Pr=农村居民消费价格指数(1985=100)Pu=城镇居民消费价格指数(1985=100)数据来源:《中国统计年鉴2004》使用计量经济软件,用国内居民人均消费、农村居民人均消费和城镇居民人均消费分别对各自地人均收入进行回归,给出标准格式回归结果;并由回归结果分析我国城乡居民消费行为有何不同.文档收集自网络,仅用于个人学习第四章多元线性回归模型4.1某经济学家试图解释某一变量Y 地变动.他收集了Y 和 5 个可能地解释变量~地观测值(共10 组),然后分别作三个回归,结果如下(括号中数字为t 统计量):文档收集自网络,仅用于个人学习( 1) = 51.5 + 3.21 R=0.63(3.45) (5.21)2) 33.43 + 3.67 + 4.62 + 1.21 R=0.75 文档收集自网络,仅用于个人学(3.61 )(2.56)(0.81) (0.22)3) 23.21 + 3.82 + 2.32 + 0.82 + 4.10 + 1.21(2.21 )(2.83)(0.62) (0.12) (2.10) (1.11)文档收集自网络,仅用于个人学习R=0.80 你认为应采用哪一个结果?为什么?4.2为研究旅馆地投资问题,我们收集了某地地1987-1995 年地数据来估计收益生产函数R=ALKe ,其中R=旅馆年净收益(万年) ,L=土地投入,K=资金投入, e 为自然对数地底.设回归结果如下(括号内数字为标准误差) :文档收集自网络,仅用于个人学习= -0.9175 + 0.273lnL + 0.733lnK R=0.94(0.212) (0.135) (0.125)(1)请对回归结果作必要说明;( 2)分别检验α和β 地显著性;( 3)检验原假设:α =β = 0;4.3我们有某地1970-1987 年间人均储蓄和收入地数据,用以研究1970-1978 和1978 年以后储蓄和收入之间地关系是否发生显著变化. 引入虚拟变量后,估计结果如下(括号内数据为标准差) :文档收集自网络,仅用于个人学习= -1.7502 + 1.4839D + 0.1504 - 0.1034D·R=0.9425 文档收集自网络,仅用于个人学习(0.3319) (0.4704) (0.0163) (0.0332)其中:Y=人均储蓄,X=人均收入,D= 请检验两时期是否有显著地结构性变化.4.4说明下列模型中变量是否呈线性,系数是否呈线性,并将能线性化地模型线性化.(1)(2)(3)4.5有学者根据某国19年地数据得到下面地回归结果:其中:Y=进口量(百万美元),X1 =个人消费支出(百万美元),X2 =进口价格/国内价格.(1)解释截距项以及X1和X2系数地意义;(2)Y 地总变差中被回归方程解释地部分、未被回归方程解释地部分各是多少?(3)进行回归方程地显著性检验,并解释检验结果;(4)对“斜率”系数进行显著性检验,并解释检验结果.4.6由美国46个州1992年地数据,Baltagi 得到如下回归结果:其中,C=香烟消费(包/人年),P=每包香烟地实际价格Y=人均实际可支配收入(1)香烟需求地价格弹性是多少?它是否统计上显著?若是,它是否统计上异于-1?(2)香烟需求地收入弹性是多少?它是否统计上显著?若不显著,原因是什么?(3)求出.4.7有学者从209 个公司地样本,得到如下回归结果(括号中数字为标准误差):其中,Salary=CEO 地薪金Sales=公司年销售额roe=股本收益率(%)ros=公司股票收益请分析回归结果.4.8为了研究某国1970-1992 期间地人口增长率,某研究小组估计了下列模型:其中:Pop=人口(百万人),t=趋势变量,.(1)在模型 1 中,样本期该地地人口增长率是多少?(2)人口增长率在1978 年前后是否显著不同?如果不同,那么1972-1977和1978-1992 两时期中,人口增长率各是多少?文档收集自网络,仅用于个人学习4.9设回归方程为Y= β0+β1X1+β2X2+β3X3+ u, 试说明你将如何检验联合假设:β1= β2 和β3 = 1 .文档收集自网络,仅用于个人学习4.10下列情况应引入几个虚拟变量,如何表示?(1)企业规模:大型企业、中型企业、小型企业;(2)学历:小学、初中、高中、大学、研究生.4.11在经济发展发生转折时期,可以通过引入虚拟变量来表示这种变化.例如,研究进口消费品地数量Y 与国民收入X 地关系时,数据散点图显示1979 年前后明显不同.请写出引入虚拟变量地进口消费品线性回归方程.文档收集自网络,仅用于个人学习4.12柯布-道格拉斯生产函数其中:GDP=地区国内生产总值(亿元)K=资本形成总额(亿元)L= 就业人数(万人)P=商品零售价格指数(上年=100)试根据中国2003 年各省数据估计此函数并分析结果.数据如下表所示第五章模型地建立与估计中地问题及对策5.1判断题(判断对错;如果错误,说明理由)(1)尽管存在严重多重共线性,普通最小二乘估计量仍然是最佳线性无偏估计量(BLUE ).(2)如果分析地目地仅仅是为了预测,则多重共线性并无妨碍. (3)如果解释变量两两之间地相关系数都低,则一定不存在多重共线性. (4)如果存在异方差性,通常用地t 检验和 F 检验是无效地. (5)当存在自相关时,OLS 估计量既不是无偏地,又不是有效地.(6)消除一阶自相关地一阶差分变换法假定自相关系数必须等于 1. (7)模型中包含无关地解释变量,参数估计量会有偏,并且会增大估计量地方差,即增大误差.(8)多元回归中,如果全部“斜率”系数各自经t 检验都不显著,则R2值也高不了.(9)存在异方差地情况下,OLS 法总是高估系数估计量地标准误差.(10)如果一个具有非常数方差地解释变量被(不正确地)忽略了,那么OLS 残差将呈异方差性.5.2考虑带有随机扰动项地复利增长模型:Y 表示GDP,Y0是Y 地基期值,r 是样本期内地年均增长率,t 表示年份,t=1978,⋯,2003.文档收集自网络,仅用于个人学习试问应如何估计GDP 在样本期内地年均增长率?5.3 检验下列情况下是否存在扰动项地自相关 .(1) DW=0.81,n=21,k=3(2)DW=2.25,n=15,k=2(3)DW=1.56,n=30,k=55.4有人建立了一个回归模型来研究我国县一级地教育支出:Y= β0+β1X1+β 2X2+β3X3+u其中:Y,X1,X2 和X3分别为所研究县份地教育支出、居民人均收入、学龄儿童人数和可以利用地各级政府教育拨款.文档收集自网络,仅用于个人学习他打算用遍布我国各省、市、自治区地100 个县地数据来估计上述模型.(1)所用数据是什么类型地数据?(2)能否采用OLS 法进行估计?为什么?(3)如不能采用OLS 法,你认为应采用什么方法?5.5试从下列回归结果分析存在问题及解决方法:(1)= 24.7747 + 0.9415 - 0.0424 R=0.9635SE:(6.7525)(0.8229)(0.0807)其中:Y=消费,X2=收入,X3=财产,且n=5000 (2)= 0.4529 - 0.0041t R=0.5284t:(-3.9606) DW=0.8252其中Y= 劳动在增加值中地份额,t=时间该估计结果是使用1949-1964 年度数据得到地.5.6工资模型:wi=b0+b1Si+b2Ei+b3Ai+b4Ui+ui其中Wi=工资,Si=学校教育年限,Ei=工作年限,Ai=年龄,Ui=是否参加工会.在估计上述模型时,你觉得会出现什么问题?如何解决?5.7你想研究某行业中公司地销售量与其广告宣传费用之间地关系.你很清楚地知道该行业中有一半地公司比另一半公司大,你关心地是这种情况下,什么估计方法比较合理.假定大公司地扰动项方差是小公司扰动项方差地两倍.文档收集自网络,仅用于个人学习(1)若采用普通最小二乘法估计销售量对广告宣传费用地回归方程(假设广告宣传费是与误差项不相关地自变量),系数地估计量会是无偏地吗?是一致地吗?是有效地吗?文档收集自网络,仅用于个人学习(2)你会怎样修改你地估计方法以解决你地问题?(3)能否对原扰动项方差假设地正确性进行检验?5.8考虑下面地模型其中GNP=国民生产总值,M =货币供给. (1)假设你有估计此模型地数据,你能成功地估计出模型地所有系数吗?说明理由.(2)如果不能,哪些系数可以估计?(3)如果从模型中去掉这一项,你对(1)中问题地答案会改变吗?(4)如果从模型中去掉这一项,你对(1)中问题地答案会改变吗?5.9采用美国制造业1899-1922年数据,Dougherty得到如下两个回归结果:(1)(2)其中:Y=实际产出指数,K=实际资本投入指数,L =实际劳动力投入指数,t=时间趋势(1)回归式(1)中是否存在多重共线性?你是如何得知地?(2)回归式(1)中,logK 系数地预期符号是什么?回归结果符合先验预期吗?为什么会这样?(3)回归式(1)中,趋势变量在其中起什么作用?(4)估计回归式(2)背后地逻辑是什么?(5)如果(1)中存在多重共线性,那么(2)式是否减轻这个问题?你如何得知?(6)两个回归地R2可比吗?说明理由.5.10有人估计了下面地模型:其中:C=私人消费支出,GNP=国民生产总值,D=国防支出假定,将(1)式转换成下式:使用1946-1975数据估计(1)、(2)两式,得到如下回归结果(括号中数字为标准误差):1)关于异方差,模型估计者做出了什么样地假定?你认为他地依据是什么?2)比较两个回归结果.模型转换是否改进了结果?也就是说,是否减小了估计标准误差?说明理由.5.11设有下列数据:RSS1=55,K =4,n1=30RSS3=140,K =4,n3=30 请依据上述数据,用戈德佛尔德-匡特检验法进行异方差性检验(5%显著性水平).5.12考虑模型(1)也就是说,扰动项服从AR (2)模式,其中是白噪声.请概述估计此模型所要采取地步骤.5.13对第 3 章练习题 3.13 所建立地三个消费模型地结果进行分析:是否存在序列相关问题?如果有,应如何解决?5.14为了研究中国农业总产值与有效灌溉面积、化肥施用量、农作物总播种面积、受灾面积地相互关系,选31 个省市2003 年地数据资料,如下表所示:文档收集自网络,仅用于个人学习表中:Y=农业总产值(亿元,不包括林牧渔)X1=有效灌溉面积(千公顷)X2=化肥施用量(万吨)X23=化肥施用量(公斤/亩)X3=农作物总播种面积(千公顷)X4=受灾面积(千公顷)(1)回归并根据计算机输出结果写出标准格式地回归结果;(2)模型是否存在问题?如果存在问题,是什么问题?如何解决?第六章动态经济模型:自回归模型和分布滞后模型6.1判断题(判断对错;如果错误,说明理由)(1)所有计量经济模型实质上都是动态模型.(2)如果分布滞后系数中,有地为正有地为负,则科克模型将没有多大用处. (3)若适应预期模型用OLS 估计,则估计量将有偏,但一致. (4)对于小样本,部分调整模型地OLS 估计量是有偏地.(5)若回归方程中既包含随机解释变量,扰动项又自相关,则采用工具变量法,将产生无偏且一致地估计量.(6)解释变量中包括滞后因变量地情况下,用德宾-沃森d 统计量来检测自相关是没有实际用处地.6.2用OLS 对科克模型、部分调整模型和适应预期模型分别进行回归时,得到地OLS 估计量会有什么样地性质?文档收集自网络,仅用于个人学习6.3简述科克分布和阿尔蒙多项式分布地区别.6.4考虑模型假设相关.要解决这个问题,我们采用以下工具变量法:首先用对和回归,得到地估计值,然后回归其中是第一步回归(对和回归)中得到地.(1)这个方法如何消除原模型中地相关?(2)与利维顿采用地方法相比,此方法有何优点?6.5设其中:M=对实际现金余额地需求,Y*=预期实际收入,R*=预期通货膨胀率假设这些预期服从适应预期机制:其中和是调整系数,均位于0和1之间.(1)请将M t 用可观测量表示;(2)你预计会有什么估计问题?6.6考虑分布滞后模型假设可用二阶多项式表示诸如下:若施加约束==0,你将如何估计诸系数(,i=0,1, (4)6.7为了研究设备利用对于通货膨胀地影响,T. A.吉延斯根据1971年到1988年地美国数据获得如下回归结果:文档收集自网络,仅用于个人学习其中:Y=通货膨胀率(根据GNP 平减指数计算)X t=制造业设备利用率X t-1 =滞后一年地设备利用率1)设备利用对于通货膨胀地短期影响是什么?长期影响又是什么?(2)每个斜率系数是统计显著地吗?(3)你是否会拒绝两个斜率系数同时为零地原假设?将利用何种检验?6.8考虑下面地模型:Y t = α+β(W0X t+ W1X t-1 + W2X t-2 + W3X t-3)+u t 请说明如何用阿尔蒙滞后方法来估计上述模型(设用二次多项式来近似) .6.9下面地模型是一个将部分调整和适应预期假说结合在一起地模型:Y t*= βX t+1eY t-Y t-1 = δ(Y t*- Y t-1) + u tX t+1e- X t e= (1-λ)( X t - X t e);t=1,2,⋯, n式中Y t*是理想值,X t+1e和X t e是预期值.试推导出一个只包含可观测变量地方程,并说明该方程参数估计方面地问题.文档收集自网络,仅用于个人学习第七章时间序列分析7.1单项选择题(1)某一时间序列经一次差分变换成平稳时间序列,此时间序列称为()地.A.1 阶单整B.2阶单整C.K 阶单整D.以上答案均不正确文档收集自网络,仅用于个人学习(2)如果两个变量都是一阶单整地,则().A .这两个变量一定存在协整关系B.这两个变量一定不存在协整关系C.相应地误差修正模型一定成立D.还需对误差项进行检验文档收集自网络,仅用于个人学习(3)如果同阶单整地线性组合是平稳时间序列,则这些变量之间关系是() .A. 伪回归关系B.协整关系C.短期均衡关系D. 短期非均衡关系(4).若一个时间序列呈上升趋势,则这个时间序列是().A .平稳时间序列B.非平稳时间序列C.一阶单整序列 D. 一阶协整序列7.2请说出平稳时间序列和非平稳时间序列地区别,并解释为什么在实证分析中确定经济时间序列地性质是十分必要地.文档收集自网络,仅用于个人学习7.3什么是单位根?7.4Dickey-Fuller(DF)检验和Engle-Granger(EG)检验是检验什么地?文档收集自网络,仅用于个人学习7.5什么是伪回归?在回归中使用非均衡时间序列时是否必定会造成伪回归?7.6由1948-1984 英国私人部门住宅开工数(X)数据,某学者得到下列回归结果:注:5%临界值值为-2.95,10%临界值值为-2.60. (1)根据这一结果,检验住宅开工数时间序列是否平稳.(2)如果你打算使用t 检验,则观测地t 值是否统计显著?据此你是否得出该序列平稳地结论?(3)现考虑下面地回归结果:请判断住宅开工数地平稳性.7.7由1971-I 到1988-IV 加拿大地数据,得到如下回归结果;A.B.C.其中,M1=货币供给,GDP=国内生产总值,e t=残差(回归A)(1)你怀疑回归 A 是伪回归吗?为什么?(2)回归 B 是伪回归吗?请说明理由.(3)从回归 C 地结果,你是否改变(1)中地结论,为什么?(4)现考虑以下回归:这个回归结果告诉你什么?这个结果是否对你决定回归 A 是否伪回归有帮助?7.8 检验我国人口时间序列地平稳性,数据区间为1949-2003 年.单位:万人7.9对中国进出口贸易进行协整分析,如果存在协整关系,则建立E CM 模型.1951-2003 年中国进口(im )、出口(ex)和物价指数(pt,商品零售物价指数)时间序列数据见下表.因为该期间物价变化大,特别是改革开放以后变化更为激烈,所以物价指数也作为一个解释变量加入模型中.为消除物价变动对进出口数据地影响以及消除进出口数据中存在地异方差,定义三个变量如下:文档收集自网络,仅用于个人学习第八章联立方程模型8.1判断题(判断对错;如果错误,说明理由)(1)OLS 法适用于估计联立方程模型中地结构方程.(2)2SLS 法不能用于不可识别方程.(3)估计联立方程模型地2SLS 法和其它方法只有在大样本地情况下,才能具有我们期望地统计性质 .(4) 联立方程模型作为一个整体,不存在类似 R 2这样地拟合优度测度 .(5) 如果要估计地方程扰动项自相关或存在跨方程地相关, 则 2SLS 法和其它估 计结构方程地方法都不能用 .(6) 如果一个方程恰好识别,则 ILS 和 2SLS 给出相同结果 .8.2 单项选择题1) 结构式模型中地方程称为结构方程 .在结构方程中, 解释变量可以是前定变3) 如果联立方程模型中某个结构方程包含了模型中所有地变量,则这个方程5)当一个结构式方程为恰好识别时,这个方程中内生解释变量地个数( A .与被排除在外地前定变量个数正好相等 B .小于被排除在外地前定变量个数 C .大于被排除在外地前定变量个数D .以上三种情况都有可能发生 文档收集自网络,仅用于个人学习6) 简化式模型就是把结构式模型中地内生变量表示为 ( ).A. 外生变量和内生变量地函数关系B.前定变量和随机误差项地模型C.滞后变量和随机误差项地模型 D.外生变量和随机误差项地模量,也可以是 ( ).文档收集自网络,仅用于个人学习 A. 外生变量 B.滞后变量2)前定变量是 ( )地合称 .A.外生变量和滞后内生变量C.内生变量D. 外生变量和内生变量 C.外生变量和虚拟变量 D. 解释变量和被解释变量( ).A. 恰好识别B.不可识别 (4) 下面说法正确地是( ).A.内生变量是非随机变量 C.外生变量是随机变量 C.过度识别 D.不确定B. 前定变量是随机变量个人收集整理勿做商业用途型7) 对联立方程模型进行参数估计地方法可以分两类,即:( ).A.间接最小二乘法和系统估计方法B.单方程估计法和系统估计方法个人收集整理勿做商业用途C.单方程估计法和二阶段最小二乘法D.工具变量法和间接最小二乘法(8)在某个结构方程过度识别地条件下,不适用地估计方法是().A. 间接最小二乘法B.工具变量法C.二阶段最小二乘法D.有限信息极大似然估计法8.3行为方程和恒等式有什么区别?8.4如何确定模型中地外生变量和内生变量?8.5考虑下述模型:C t = α + β D t +u t I t = γ + δD t-1 + νt D t = C t +I t + Z t ;t=1 ,2,⋯,n其中 C = 消费支出,D= 收入,I = 投资,Z = 自发支出. C、I 和D是内生变量.试写出消费支出地简化型方程,并研究各方程地识别问题.8.6考虑下述模型:Y t = C t + I t +G t +X tC t = β 0 + β 1D t + β2C t-1 + u tD t = Y t –T tI t = α0 + α1Y t + α2R t-1 +νt 模型中各方程是正规化方程,u t、νt为扰动项.(1)请指出模型中地内生变量、外生变量和前定变量.(2)写出用2SLS法进行估计时,每个阶段中要估计地方程.8.7下面是一个简单地美国宏观经济模型(1960-1999)其中C=实际私人消费,I= 实际私人总投资,G=实际政府支出,Y =实际GDP,M= 当年价M2,R=长期利率;P=消费价格指数.内生变量:C,I,R,Y 前定变量:C t-1,I t-1,M t-1,P t,R t-1 和G t.(1)应用识别地阶条件,决定各方程地识别状态;(2)你打算用什么方法来估计可识别行为方程?8.8假设有如下计量经济模型:其中,Y=国民收入,I=净资本形成,C=个人消费,Q =利润,P=生活费用指数,R= 工业劳动生产率1)写出模型地内生变量、外生变量和前定变量;个人收集整理勿做商业用途(2)用识别地阶条件确定各方程地识别状态;(3)此模型中是否有可以用ILS 法估计地方程?如有,请指出;(4)写出用2SLS 法进行估计时,每个阶段中要估计地方程. 8.9考虑下述模型:消费方程:C t=α0 +α 1Y t +α2C t-1 +u①投资方程:I t=β0 +β1Y t +β2I t –1+u2t②进口方程:M t = 0 + 1Y t + u3t ③Y t = C t+ I t + G t + X t - M t模型中各方程是正规化方程,u 1t, ⋯u3t为扰动项.(1)请指出模型中地内生变量、外生变量和前定变量.(2)利用阶条件识别各行为方程.(3)写出用3SLS 进行估计时地步骤.8.10考察下述国民经济地简单模型式中,C为消费,Y 为国民收入,I 为投资,R为利率.设样本容量n 为20,已算得中间结果为:(1)判别模型中消费方程地识别状态;(2)用间接最小二乘法求消费方程结构式系数;(3)将采用哪种方法估计投资方程?为什么?(不必计算)8.11由联立方程模型;得到其简化式如下:(1)两结构方程可识别吗?(2)如果知道,识别情况有何变化?(3)若对简化式进行估计,结果如下:个人收集整理勿做商业用途试求出结构参数地值,并说明如何检验原假设个人收集整理勿做商业用途版权申明本文部分内容,包括文字、图片、以及设计等在网上搜集整理。
计量经济学-参考答案chapter10

第十章一、名词解释1、结构式模型:根据经济理论和行为规律建立的描述经济变量之间直接关系结构的计量经济学方程系统称为结构式模型。
结构式模型中的每一个方程都是结构方程,将一个内生变量表示为其它内生变量、先决变量和随机误差项的函数形式,被称为结构方程的正规形式。
2、先决变量:模型中的外生变量和滞后内生变量被统称为先决变量,其含义是在模型求解时,这些变量已有所赋的值。
3、不可识别:如果联立方程计量经济学模型中某个结构方程不具有确定的统计形式,则称该方程为不可识别。
或者说如果从参数关系体系无法求出其结构方程的参数,则称该方程为不可识别。
如果一个模型系统中存在一个不可识别的随机方程,则认为该联立方程系统是不可识别的。
4、间接最小二乘法:先对关于内生解释变量的简化式方程采用普通最小二乘法估计简化式参数,得到简化式参数估计量,然后通过参数关系体系,计算得到的结构式参数的估计量,这种方法称为间接最小二乘法。
二、判断题1、√2、×3、√4、√5、√6、×7、×8、×三、单项选择题1、C2、B3、A4、 C5、 C6、 B7、B8、B9、B 10、B11、A 12、C 13、C 14、A15、D 16、C 17、C 18、D 19、B 20、B21、B 22、D 23、C 24、A四、多项选择题1、ADF2、ABCDE3、ABE4、ABCE五、简答题1、联立方程计量经济学模型的结构式BΓNY X+=中的第i个方程中包含gi个内生变量和ki 个先决变量,模型系统中内生变量和先决变量的数目用g和k表示,矩阵()BΓ00表示第i个方程中未包含的变量在其它g-1个方程中对应系数所组成的矩阵。
于是,判断第i个结构方程识别状态的结构式条件为:如果R g()BΓ001<-,则第i个结构方程不可识别;如果R g()BΓ001=-,则第i个结构方程可以识别,并且如果k k gi i-=-1,则第i个结构方程恰好识别,如果k k gi i->-1,则第i个结构方程过度识别。
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
第八章一、名词解释1、虚拟变量:在建立模型时,有一些影响经济变量的因素无法定量描述,如职业、性别对收入的影响,教育程度,季节因素等往往需要用定性变量度量。
为了在模型中反映这类因素的影响,并提高模型的精度,需要将这类变量“量化”。
根据这类边另的属性类型,构造仅取“0”或“1”的人工变量,通常称这类变量为“虚拟变量”2、虚拟变量陷阱:一般在引入虚拟变量时要求如果有m个定性变量,字在模型中引入m-1个虚拟变量。
否则,如果引入m个虚拟变量,就会导致模型解释变量间出现完全共线性的情况。
我们一般称由于引入虚拟变量个数与定性因素个数相同出现的模型无法估计的问题,称为“虚拟变量陷阱”二、单项选择题1、B:“地区”一个,“季节”三个2、A:将D=1代入估计后的方程即可3、D:“季节”包含4个类型,只能用3个虚拟变量,用4个虚拟变量会出现完全多重共线的问题,参数将无法估计4、C:“地区”只有两个类别,引入两个虚拟变量会出现完全多重共线问题5、A:1α体现了城镇和农村截距上的差异,1β体现了城镇和农村斜率上的差异,当它们为0时,表示无差异6、A:斜率相同,仅截距不同7、D:此问题表现为1000前后斜率的变化,B表示截距的变化,不合适;C在D=0时没有解释变量,不正确;A和D相比,D更合适,A会造成曲线在临界值出断开,但D会保证曲线的连贯的。
8、A:虚拟变量表示性别、季节等时,只表示属性的不同,没有等级之分,作为质的因素;表示收入高低时,高与低是有级别的,属于有序数据,可以表示数量的因素。
9、A/B:这题比较牵强,按书上原话应该选择B;但当用加法引入虚拟变量时,会存在问题。
【当用加法形式引入虚拟变量时,用一个虚拟变量作为截距项,取值全部为1;其他m-1个表示该因素的前三个类型。
如果不引入截距项,当虚拟变量都取0时不能解释该因素第四个类型的作用。
】10、D :概念性三、多项选择题1、B C D :A 太绝对,也可以表示数量因素;E 太绝对2、ABCDE :A 加法方式;B 乘法方式;C 临界指标的虚拟变量;D 在ABC 基础上可构造分段回归3、AB :C 当虚拟变量取0或2时,过程一样,但参数的意义稍作调整;D 见书P207倒数第二段。
四、判断题,并说明理由1、错。
理由是2β的估计值减半,12,ββ的估计值不变。
2、错。
理由是虚拟变量的引入并没有违背OLS 法的基本假设条件,所以其估计值仍是无偏的。
五、计算分析题 1、(1)1D 参数的经济意义是当销售收入和公司股票收益保持不变时,ln ln 0.158Y Y -=金交,即,金融业CEO 的薪水要比交通运输业CEO 的薪水多15.8个百分点,其他2个类似解释。
(2)公用事业和交通运输业之间的估计薪水的近似百分比差异就是以百分数解释的3D 的参数,即28.3%,由于参数的t 统计值为-2.895,它的绝对值大于1%显著性水平下,自由度为203的t 分布的临界值1.96,故统计显著。
(3)由于消费品工业和金融业相对于交通运输业的薪水百分比差异分别为15.8%和 18.1%,所以它们之间的差异为8.1%-15.8%=2.3%,一个能直接检验显著性的方程是:01122122334LnY LnX X D D D βββαααμ=++++++其中,4D 为交通运输业的虚拟变量,对比基准为金融业。
2、(1)选择b 模型,因为该模型中的D的系数估计值在统计上显著。
(2)如果b 模型确实更好,而选择了a 模型,则犯了模型设定错误,丢失相关解释变量。
(3)D 的系数表明了现实中比较普遍的现象,男生体重大于女生。
3、由于在利率r<0.08时,投资I 仅取决于利润X ;而当利率r ≥0.08时,投资I 同时取决于利润X 和一个固定的级差利润R ,故可以建立如下模型来表达上述关系: (a )I i =β0+β1X i +RD i +µi其中,⎩⎨⎧<≥=08.0,008.0,1r r D假设µi 仍服从经典假设E (µi )=0,则有利率r ≥0.08时的投资期望: (b )E (I i | X i ,D i =1)=(β0+R )+β1X i 利率r<0.08时的投资期望: (c )E (I i | X i ,D i =0)=β0+β1X i从以上看出,假设利率R>0,两个投资函数的斜率相同而截距水平不同;当斜率相同的假设成立,对投资函数是否受到利率差异影响的假设检验,可由检验模型(b )和(c )是否具有相同截距加以描述,原假设H 0:投资函数不受利率影响。
若(a )中参数R 估计值的t 检验在统计上是显著的,则可以拒绝投资函数不受利率影响的假设。
4、(1)从咖啡需求函数的回归方程看,P 的系数-0.1647表示咖啡需求的自价格弹性;I 的系数0.5115示咖啡需求的收入弹性;P’的系数0.1483表示咖啡需求的交叉价格弹性。
(2)咖啡需求的自价格弹性的绝对值较小,表明咖啡是缺乏弹性。
(3)P’的系数大于0,表明咖啡与茶属于替代品。
(4)从时间变量T 的系数为-0.01看, 咖啡的需求量应是逐年减少,但减少的速度很慢。
(5)虚拟变量在本模型中表示咖啡需求可能受季节因素的影响。
(6)从各参数的t 检验看,第一季度和第二季度的虚拟变量在统计上是显著的。
(7)咖啡的需求存在季节效应,回归方程显示第一季度和第二季度的需求比其他季节少。
六、上机练习题 1、(1)对利润函数01Y X ββμ=++按加法方式引入虚拟变量2D ,3D ,4D :01223341Y D D D X βαααβμ=+++++其中2D ⎧=⎨⎩1,第二季度0,其他季度3D ⎧=⎨⎩1,第三季度0,其他季度4D ⎧=⎨⎩1,第四季度0,其他季度EViews 软件下,选择“Quick\Estimate Equations ”,在出现的对话框中输入“Y C @seas(2) @seas(3) @seas(4) X ”得如下表所示的估计结果。
即有如下OLS 估计模型:234ˆ6685.81322.5218.2182.20.0038Y D D D X =+-++ (3.91) (2.07) (-0.35) (0.28) (3.33)20.5256R = 5.26F = ..0.38DW= 回归结果表明,只有销售额与第二季度对利润有显著的影响。
销售额增加1美元,则平均利润可增加4美分;第一季度的平均利润水平是6685.8美元,而在第二季度中则可提高1322.5美元。
由于其他季度的影响不显著,故可只引入第二季度虚拟变量2D ,得如下回归:2ˆ6513.11331.60.0393Y D X =++ (4.01) (2.70) (3.72)20.5156R = 11.18F = ..0.47DW= (2)如果季度因素对利润率产生影响,则可按乘法方式引入虚拟变量:0122334ˆY D X D X D X X βαααβμ=+++++ EViews 软件下,选择“Quick\Estimate Equations ”,在出现的对话框中输入“Y C @seas(2)*X @seas(3)*X @seas(4)*X X”得如下表所示的估计结果。
可以看出,仍然是第二季度对利润有影响,其他季度的影响不显著,因此只引入第二季度虚拟变量,得如下回归结果:2ˆ6839.20.00870.0372Y D X X =++ (4.23) (2.76) (3.51)20.5208R = 11.41F = ..0.48DW= 由此可知,在其他季度,利润率为0.0372,第二季度则增加到0.0459。
2、(1)从图形可以看出,酒销售量随时间呈现出逐年增长的趋势,并表现出明显的季节变化态势,每年的第一季度明显高于同年的其他季度。
(2)设置如下三个季度虚拟变量1D =10⎧⎨⎩第一季度其它;2D =10⎧⎨⎩第二季度其它;3D =10⎧⎨⎩第三季度其它由于D2、D3的系数不显著,可剔除:表明只有第一季度的酒销售量与第二、三、四季度的酒销售两有明显的区别。
(3)检验模型中时间t的斜率参数有无发生变异,应该以乘法方式引入虚拟变量,由于D2、D3对Y影响不显著,因此建立乘法模型:由于乘法项系数不显著,提出,因此最后模型为:80.87358+1.30122t (0,234)94.24269+1.30122t(1,1)t t Y D Y D ==⎧⎪⎨==⎪⎩第,,季度第季度另外考虑未引入虚拟变量的模型拟和优度字有25.8%与引入虚拟变量89%差很多。
第九章一、名词解释1、分布滞后模型:指模型中的解释变量仅是解释变量X的当期值与若干期滞后值,而没有被解释变量Y的滞后期值,叫做分布滞后模型。
2、自回归模型:指模型中的解释变量仅是X的当期值与被解释变量Y的若干期滞后值,它由于被解释变量的滞后期值对被解释变量现期做了回归,故叫做自回归模型。
二、单项选择题1、D:A为无限自回归模型;B为有限自回归模型;C为无限滞后分布滞后模型;D有限分布滞后模型2、C:参数意义3、B:动态乘数的概念;A短期或即期乘数;C无;D长期乘数或均衡乘数4、C:滞后变量之间容易产生多重共线问题5、B:概念性6、D :概念,参考第3题7、D :A 滞后变量可能与随机误差项之间存在相关性;B 滞后变量之间容易产生多重共线,但一般不会完全多重共线;C 由有限自回归模型的构造过程易知,容易产生序列相关问题 8、B :概念性9、D :由于这两种方法得到的自回归模型都容易产生随机解释变量问题,故应采用工具变量法 10、C :概念。
三、多项选择题1、CD :参考各模型的产生方式和模型形式可以判断。
工具变量法适用于随机解释变量问题,即解释变量与随机误差项存在同期相关性;应用科伊克方法和根据自适应预期得到的自回归模型容易产生该问题。
2、ABCDE :五个情况都有可能产生3、AB :C 针对无线分布滞后模型;D 针对随机解释变量问题4、ABCDE :参考各个模型的产生方式四、判断题1、×:经验加权法是对滞后变量进行加权求和,组合成为新的变量;而不是对滞后变量的系数赋值【经验加权法需要考虑经济变量及滞后变量对被解释变量影响的内在规律,不能随便赋予权重】2、×:阿尔蒙变换主要应用于有限期分布滞后模型3、×:科伊克变换针对无限期分布滞后模型4、√:书上原话,P2375、×:原假设是X 的滞后变量对Y 没有显著的影响,即不存在因果关系五、计算分析题 1、(1)由于t t t M Y R αβγ*=++ (1) 11(1)t t t t Y Y Y λλμ**--=+-+ (2)第二个方程乘以β有11(1)t t t t Y Y Y βλβλββμ**--=+-+ (3)由第一个方程得t t t R M Y γαβ--=*11*1-----=t t t R M Y γαβ代入方程(3)得t t t t t t R M Y R M βμγαβλλβγα+---+=-----)()1(111整理得1(1)t t t M Y R ααλλβγ-=--++11(1)(1)t t t M R λλγβμ-----+=111(1)(1)t t t t t Y M R R αλλβλγλγβμ---++-+--+该模型可用来估计并计算出,,αβγλ和。